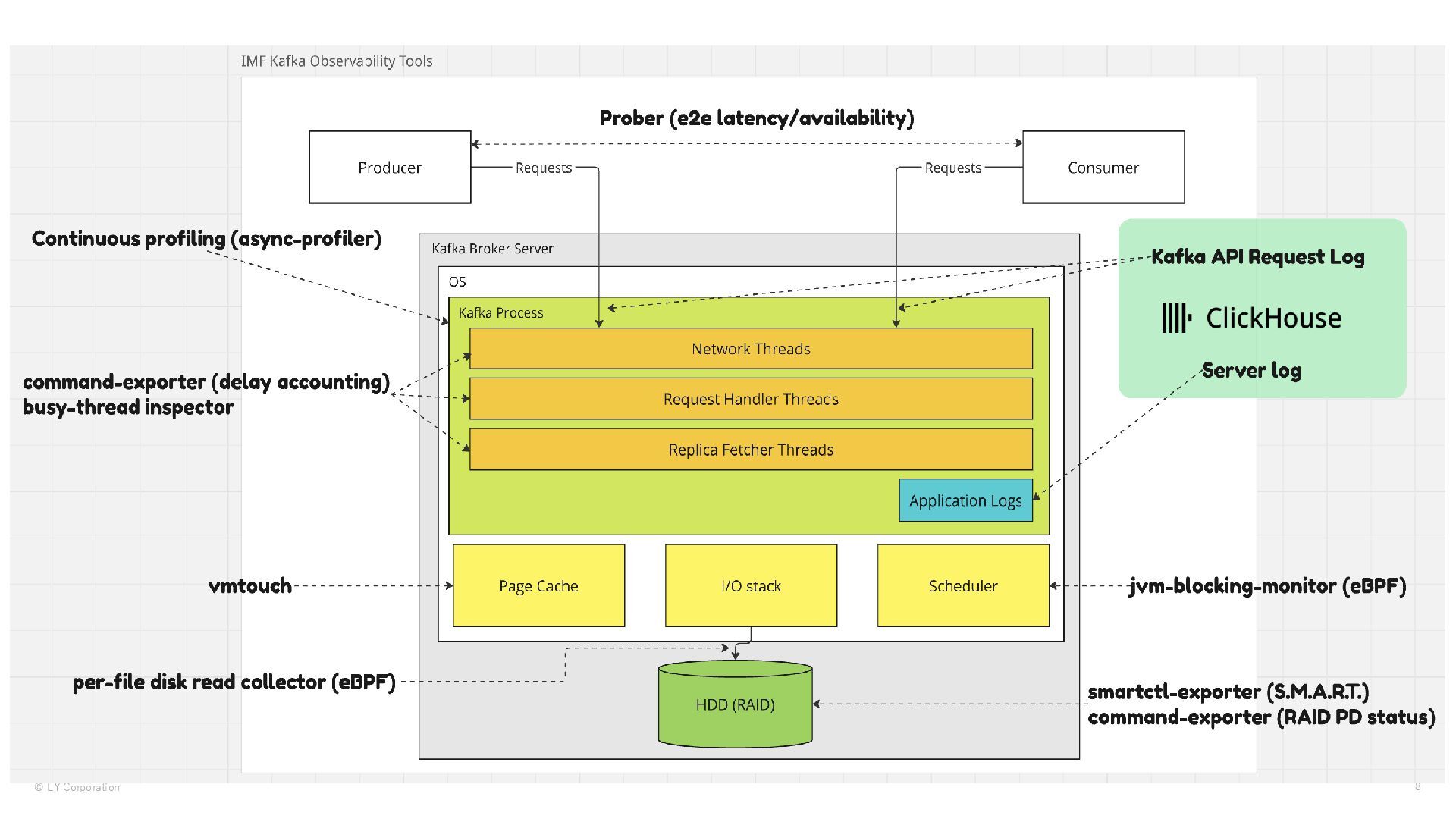
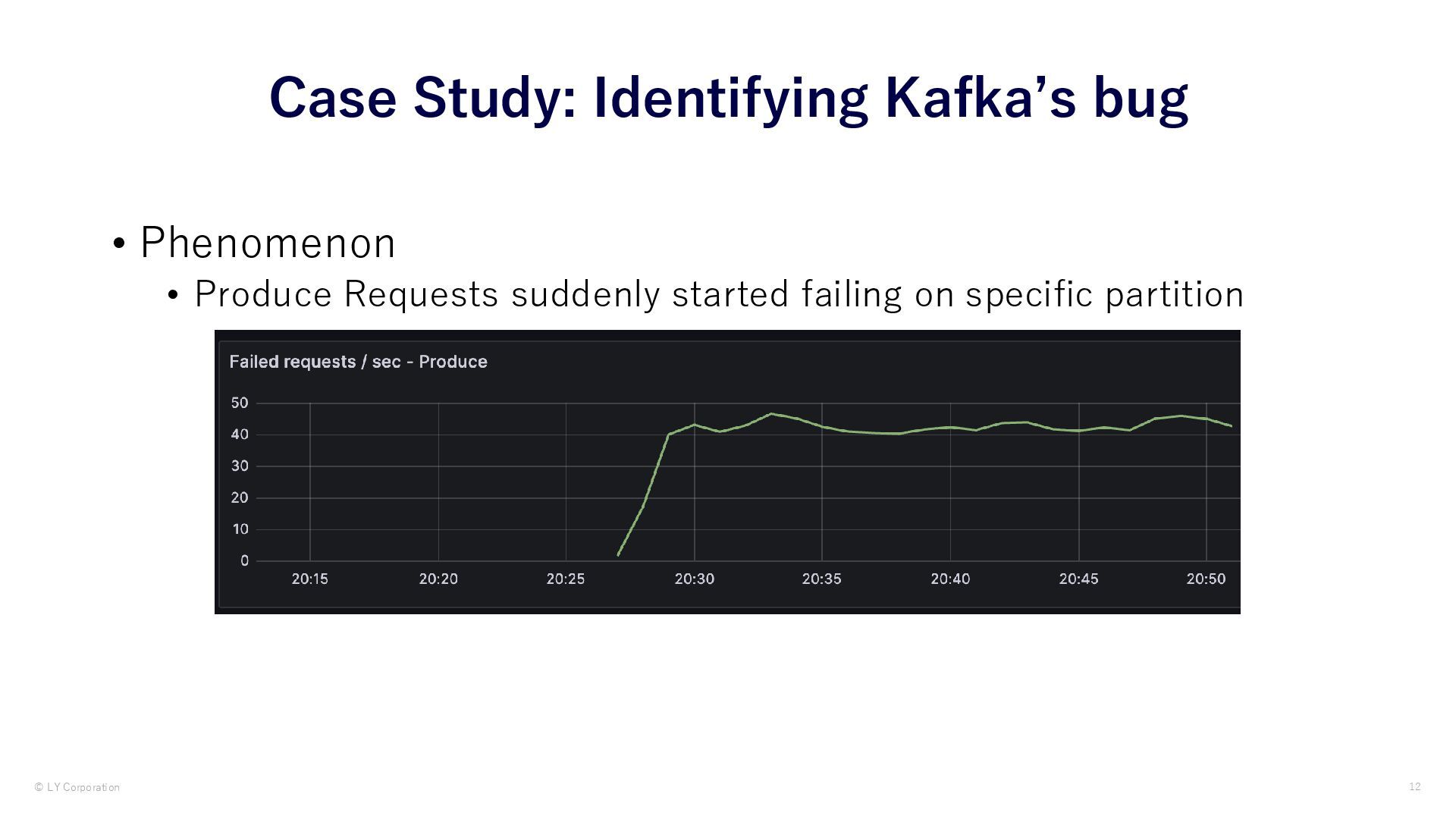
Despite Kafka is mature software, at LY scale, we sometimes hit issues that no one have encountered before.
Observability is the core of our platform to detect such kind of issues.
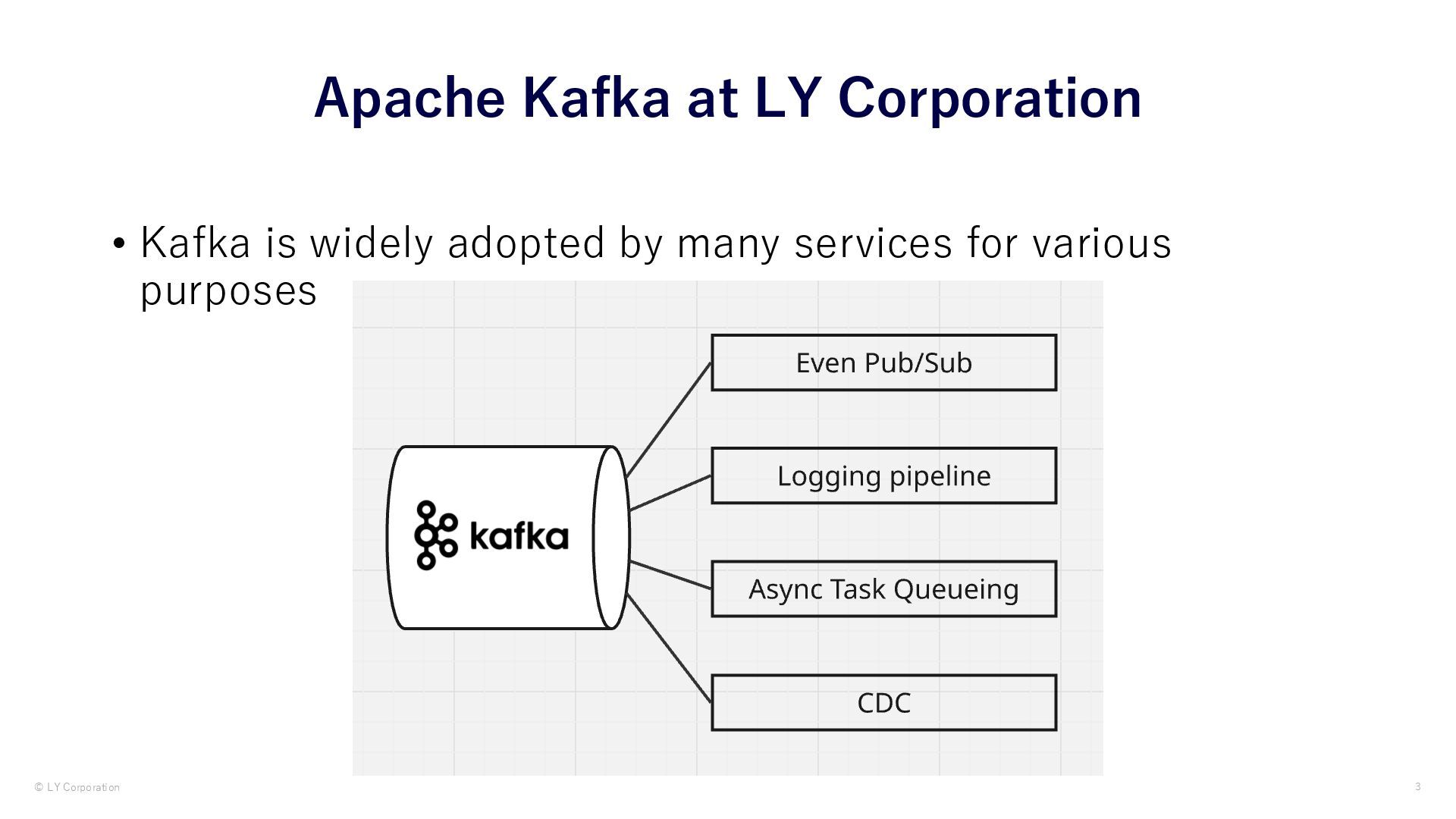
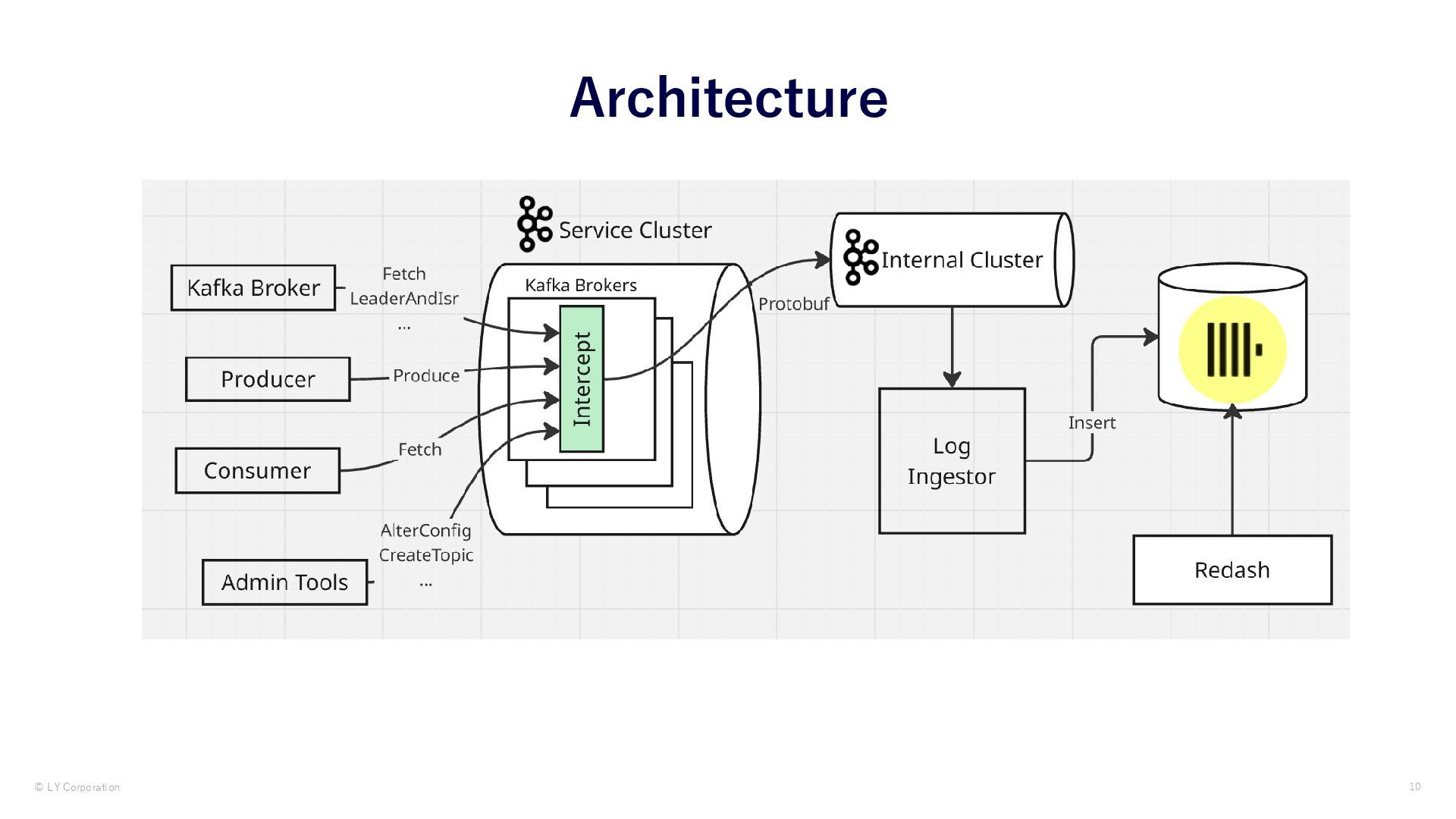
We introduce the excerpt of our observability infrastructure of Kafka platform.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
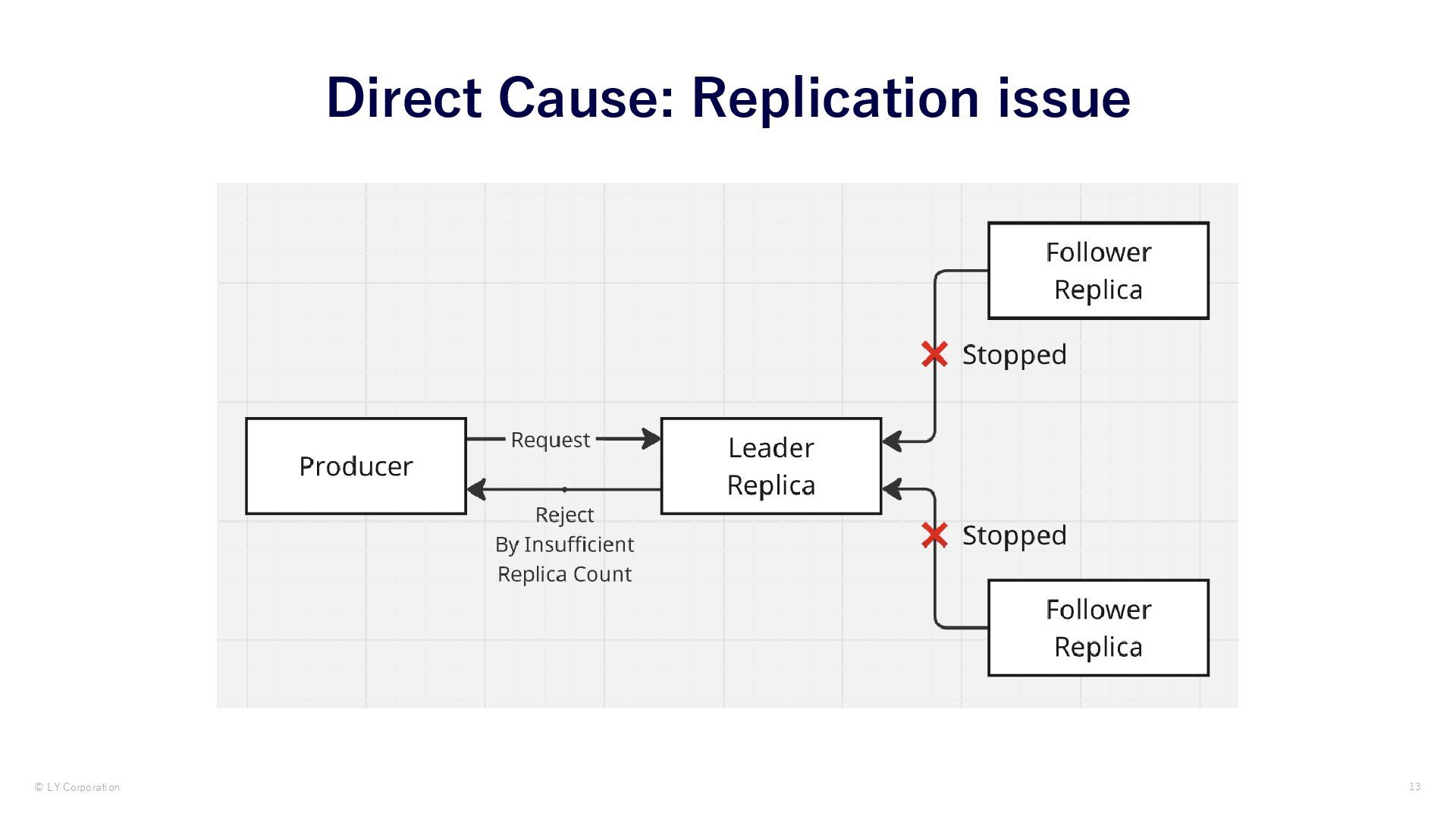{kind=link}
{kind=link}
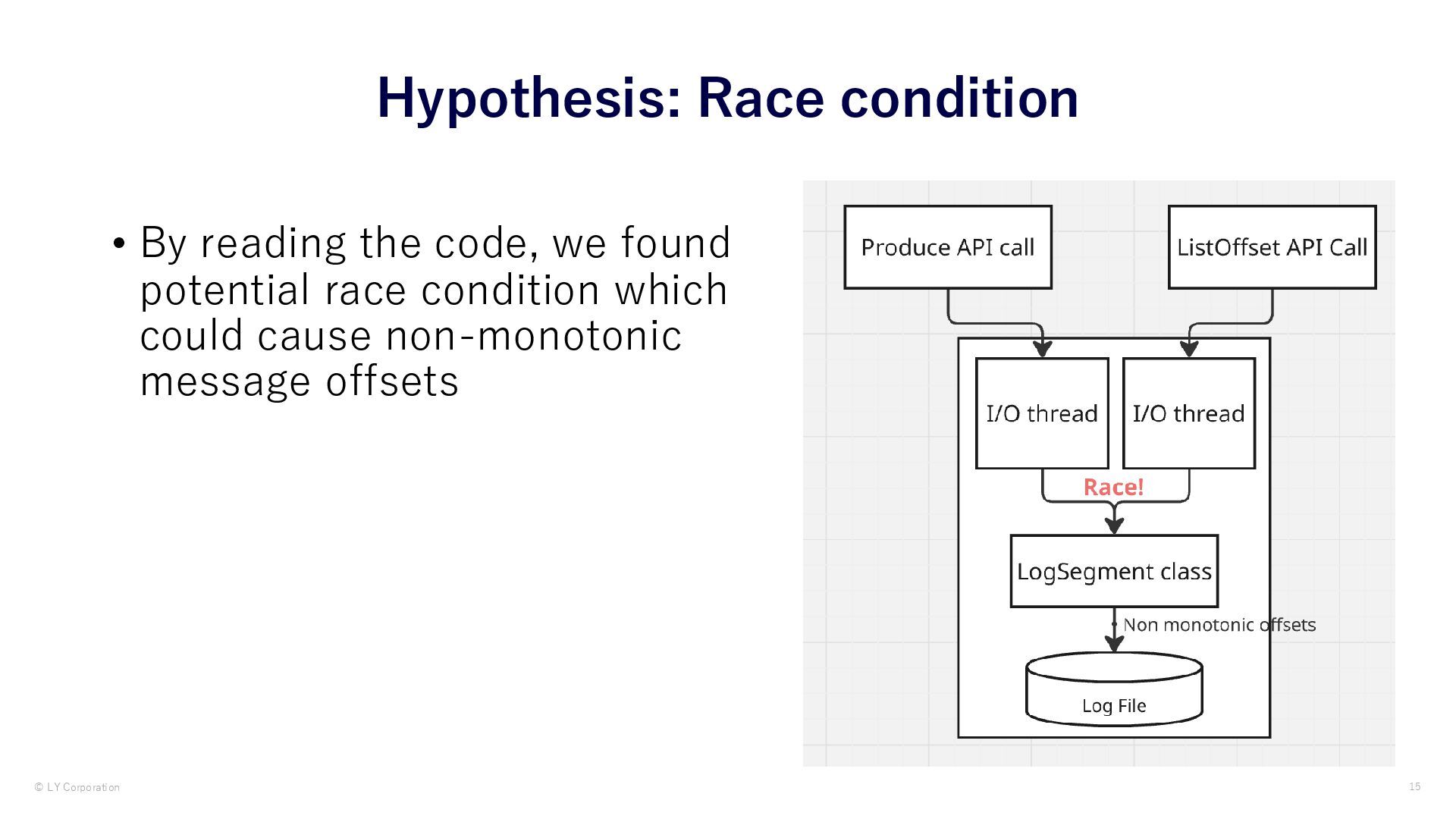{kind=link}
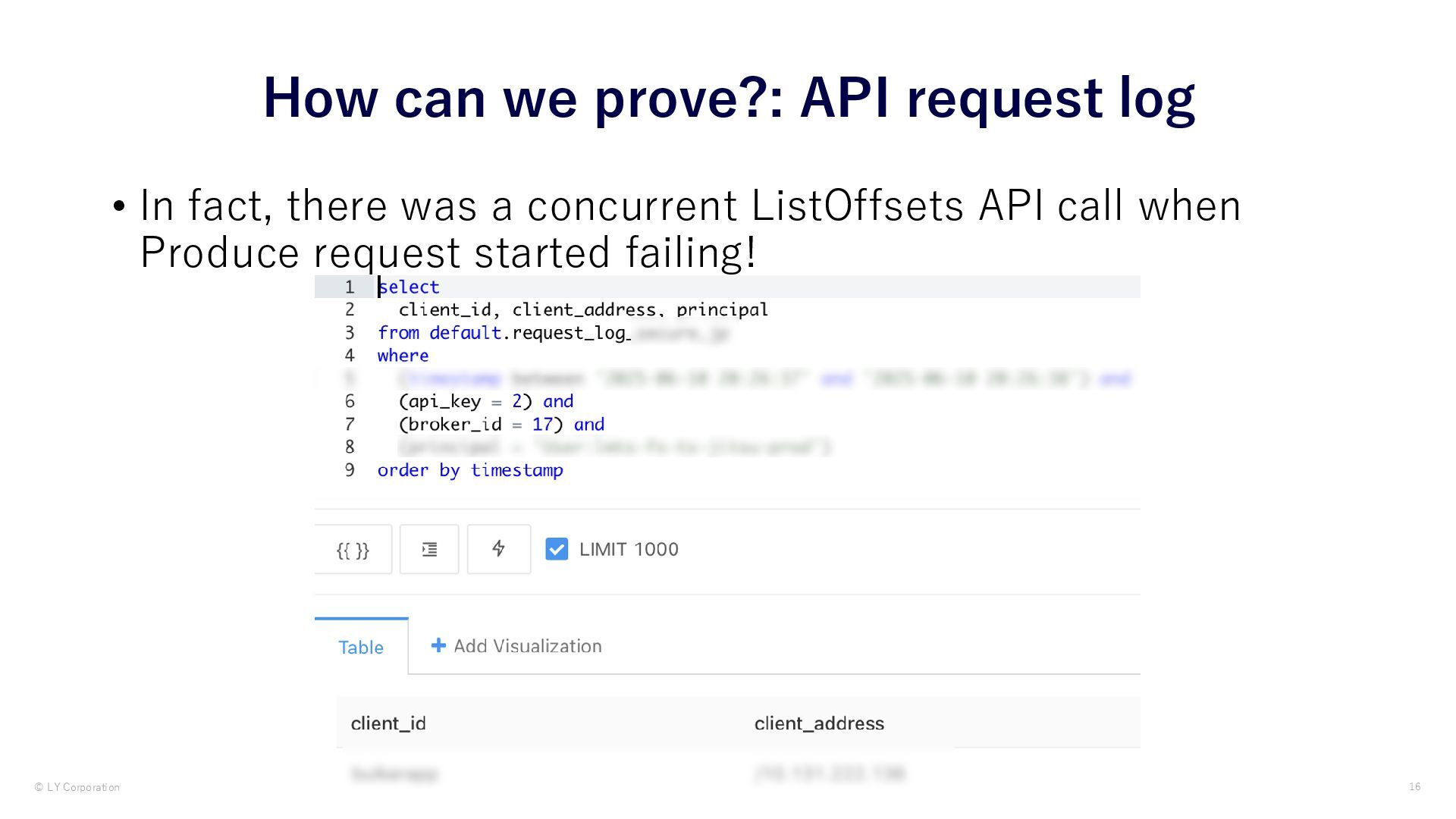{kind=link}
{kind=link}
{kind=link}