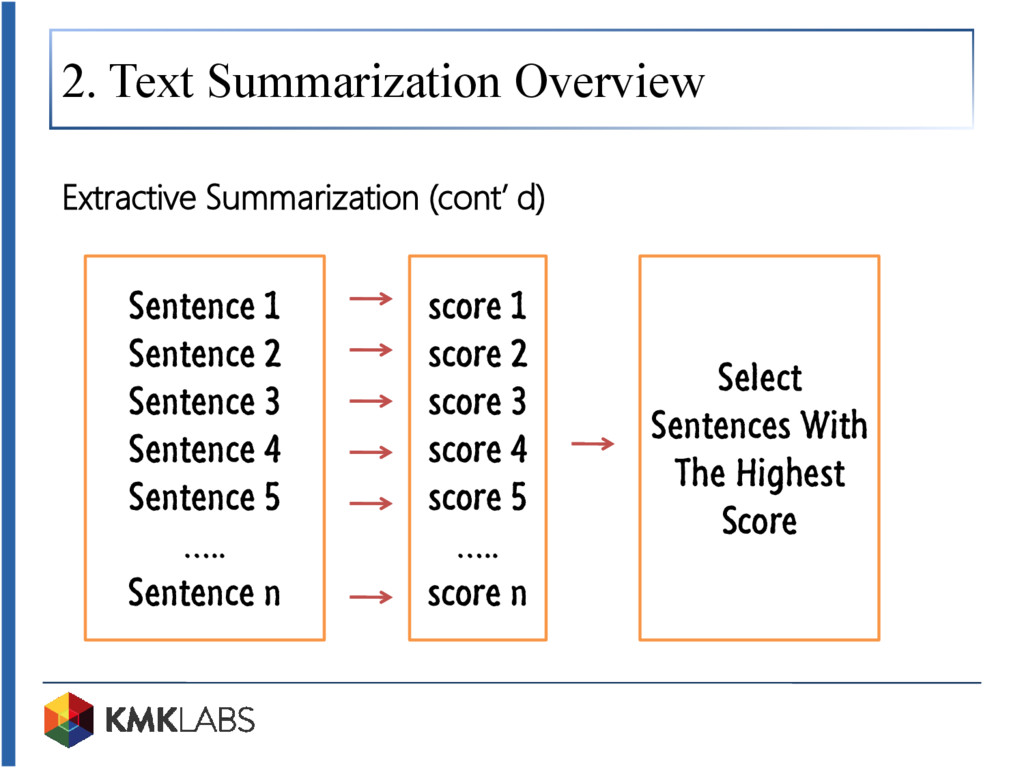
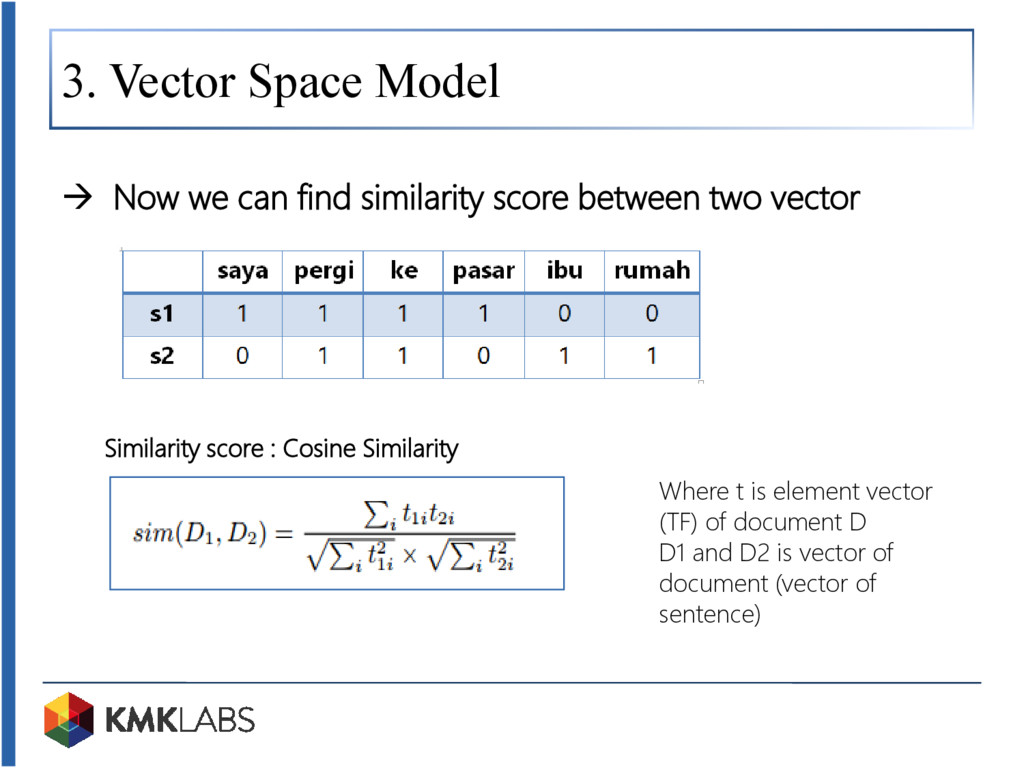
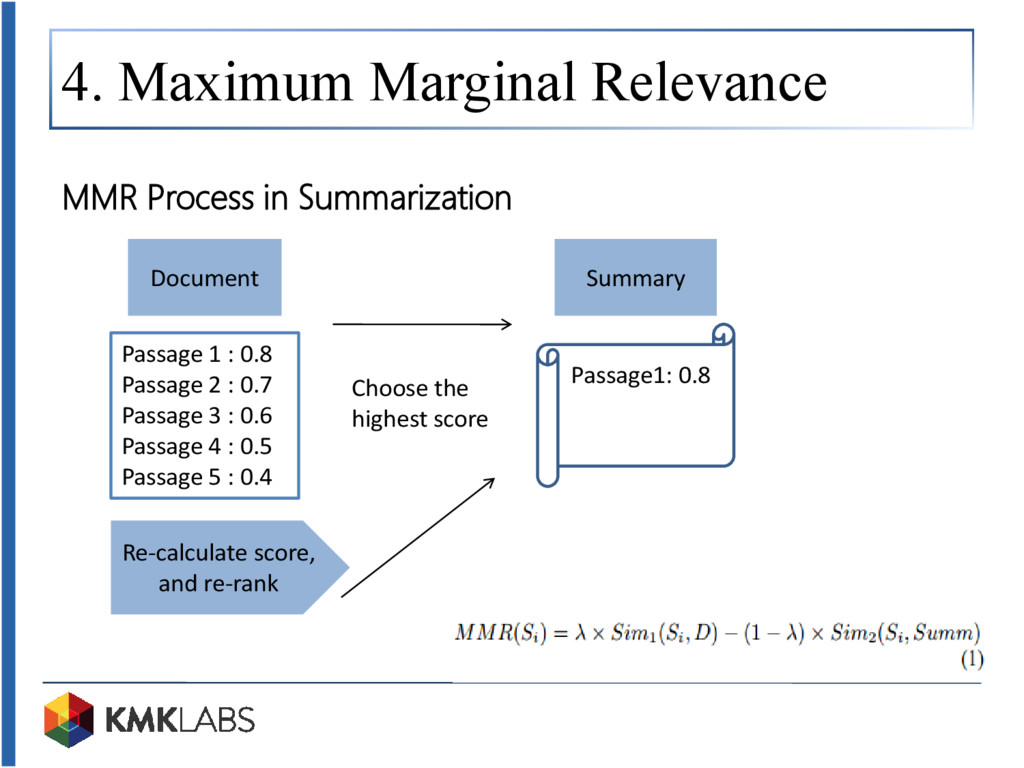
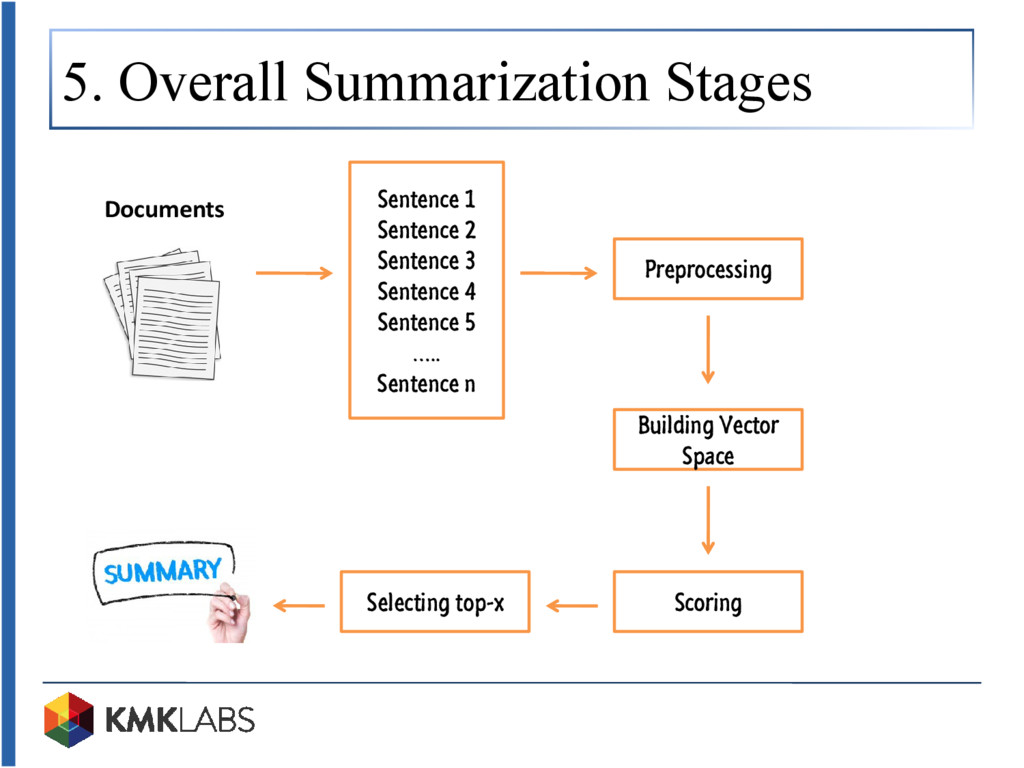
Tech talk kali ini mengupas algoritma peringkasan teks otomatis yang lazim dibahas pada ranah NLP (Natural Language Processing). Sistem peringkasan teks merupakan sebuah sistem yang mampu meringkas dokumen menjadi kalimat-kalimat yang tergolong kepada inti sari atau topik pembicaraan dokumen. Sistem ini memungkinkan kita untuk mendapatkan kunci informasi dari sebuah dokumen secara cepat tanpa mengharuskan kita untuk membaca isi dokumen secara manual. Adapun sistem peringkasan yang dijelaskan pada tech talk kali ini adalah Maximum Marginal Relevance (MMR) yang tergolong kepada kategori peringkasan ekstraktif (memilih kalimat yang ada pada dokumen sebagai kalimat pokok dari isi dokumen). MMR dilakukan dengan melakukan pembobotan untuk setiap kalimat yang ada pada dokumen. Adapun pada tech talk ini, pembobotan dilakukan menggunakan vector space model berupa Term Frequency (TF) dan Cosine Similarity sebagai pengukuran similarity nya.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}