DevOpsDays Kansas City 2016
Human Factors applies knowledge of human performance to the design of technology. DevOps changes the way we create and deliver software and infrastructure through the development of a myriad of new tools. Are the tools making the best use of how people work? What will it take to make more progress?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DevOps “Practice”[1] A team from Brazil conducted a literature research](https://files.speakerdeck.com/presentations/3f7fbcd6c50041d0b33d2ad119396fb9/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Human Information Processing [2] What does it mean to be](https://files.speakerdeck.com/presentations/3f7fbcd6c50041d0b33d2ad119396fb9/slide_15.jpg){kind=link}
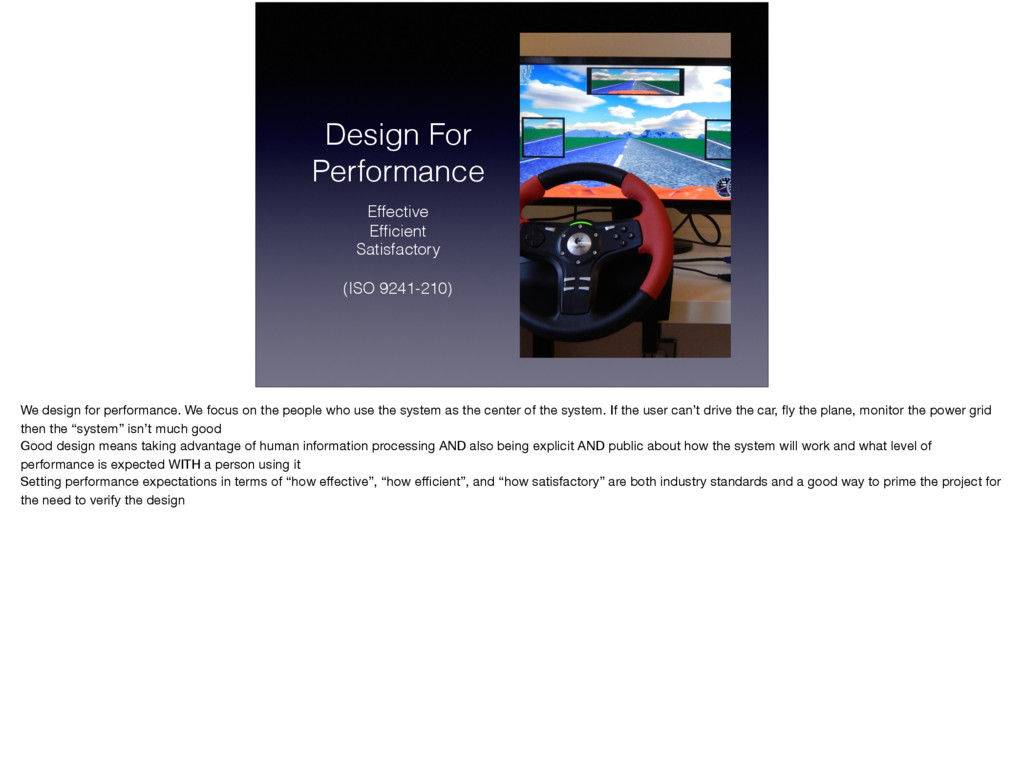{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Design For Resilience [3] • Rebound • Robustness • Graceful](https://files.speakerdeck.com/presentations/3f7fbcd6c50041d0b33d2ad119396fb9/slide_20.jpg){kind=link}
![Search For Surprises [4] • Reduce Complexity • Reveal Effects](https://files.speakerdeck.com/presentations/3f7fbcd6c50041d0b33d2ad119396fb9/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}