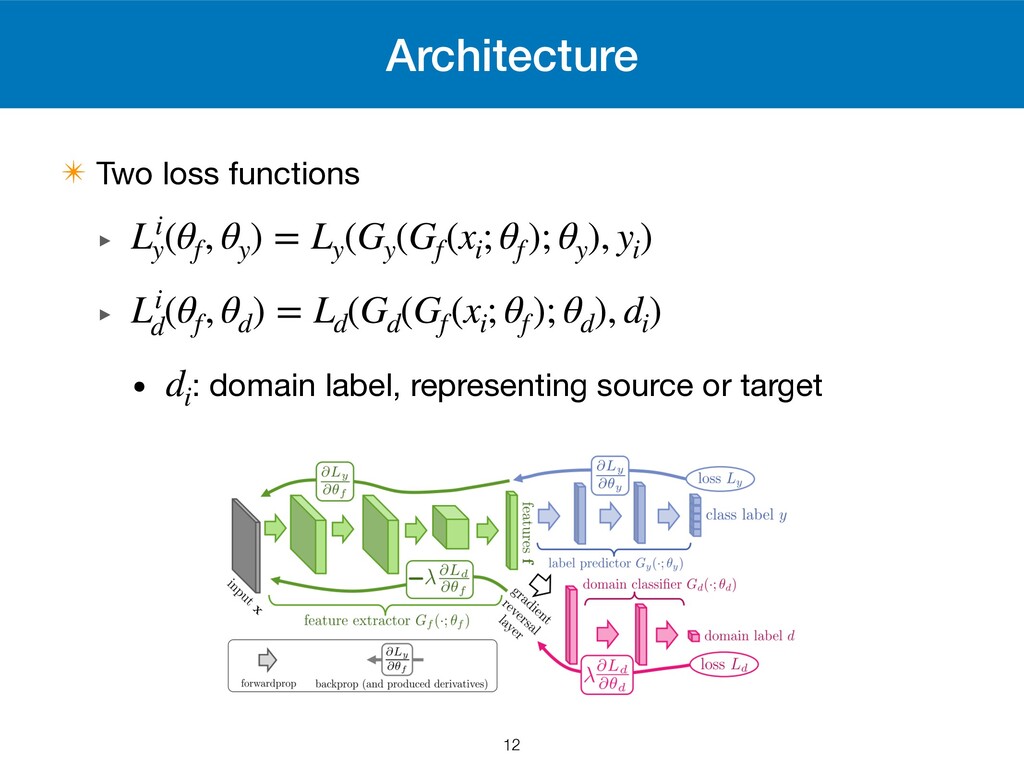
of the most common method for deep domain adaptation ✴ Find a representation that is ‣ discriminative for the original task ‣ indiscriminate between domains in an adversarial way ✴ Applicable to arbitral neural architectures 3
over , and a hypothesis class , ‣ “How distinguishable two classes are by ” ✴ Empirical H-divergence DX S DX T X H dH (DX S , DX T ) = 2 sup h∈H |Prx∼DX S [h(x) = 1] − Prx∼DX T [h(x) = 1]| H ˜ dH (S, H) = 2(1 − min h∈H ( 1 n n ∑ i=1 I[h(xi ) = 0] + 1 n′ N ∑ i=n+1 I[h(xi ) = 1])) 7
empirical H-divergence ✴ With probability , for every ‣ ✴ What we can control ‣ Source risk • Ordinal classification ‣ Empirical H-divergence • Find a feature representation where two domains are indistinguishable by 1 − δ h ∈ H RDT (h) ≤ RS (h) + ˜ dH (S, T)+complexity(H) + . . . H 9
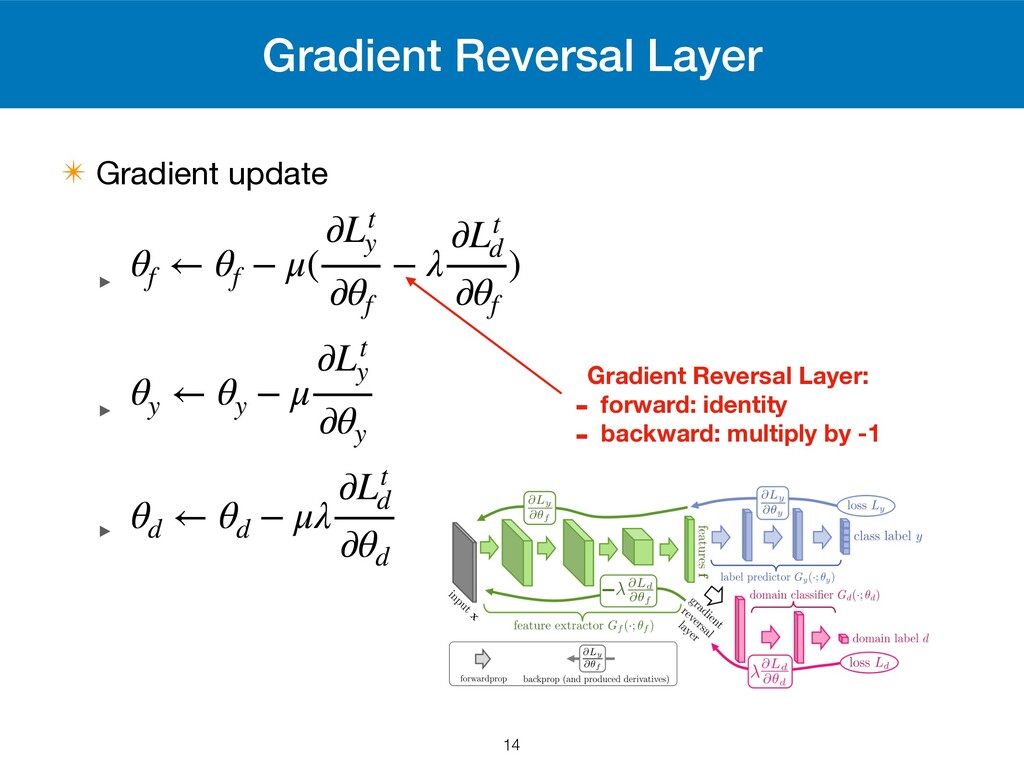
We want to ‣ minimize by and ‣ maximize by E(θf , θy , θd ) = 1 n n ∑ i=1 Li y (θf , θy ) − λ( 1 n n ∑ i=1 Li d (θf , θd ) + 1 n′ N ∑ i=n+1 Li d (θf , θd )) E θf θy E θd 13 Source risk H-divergence
divergence at the same time ✴ Applicable to arbitrary neural network architecture ✴ Significant improvement from previous methods in various tasks (image classification, person re-identification) 16
![Domain Adversarial Training of Neural Networks [Ganin+ JMLR 2016] Kenshin](https://files.speakerdeck.com/presentations/a08ea80df9c4468ca0b336cdce79fa2b/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![H-divergence [Ben-David+ NIPS 2006] ✴ Discrepancy measure ✴ Given and](https://files.speakerdeck.com/presentations/a08ea80df9c4468ca0b336cdce79fa2b/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}