Permutation invariance / equivariance of nodes ✴ Rapid progress during the last year (2019) ‣ Three papers from Maron+ are great ✴ This talk from ICML 2019 workshop is a good tutorial ‣ http://irregulardeep.org/Graph-invariant-networks-ICML- talk/ 2
set of edges (directed / undirected, weighted / unweighted) ✴ : Number of nodes ( ) ✴ : neighbor (a set of nodes adjacent to ) ✴ : network ✴ : (fixed) output feature dimension ✴ V E n = |V| N(v) v f d [n] = {1,2,...,n} 3
models can be formulated in the following way ✴ Massage passing phase ‣ ‣ ✴ Readout phase ‣ Performed SOTA on molecular property prediction task. mt+1 v = ∑ w∈N(v) Mt (ht v , ht w , evw ) ht+1 v = Ut (ht v , mt+1 v ) y = R({hT v |v ∈ V}) 7 : hidden state of in -th layer : edge feature : learned functions ht v v t evw Mt , Ut , R
AAAI 2019] analyzed MPGNNs power in terms of graph isomorphism ‣ MPGNNs are as strong as Weisfeiler-Lehman graph isomorphism test (WL-test) • Strong heuristics to check graph isomorphism ‣ Graph Isomorphism Network • As strong as WL-test • Simple and run in O(|E|) 8
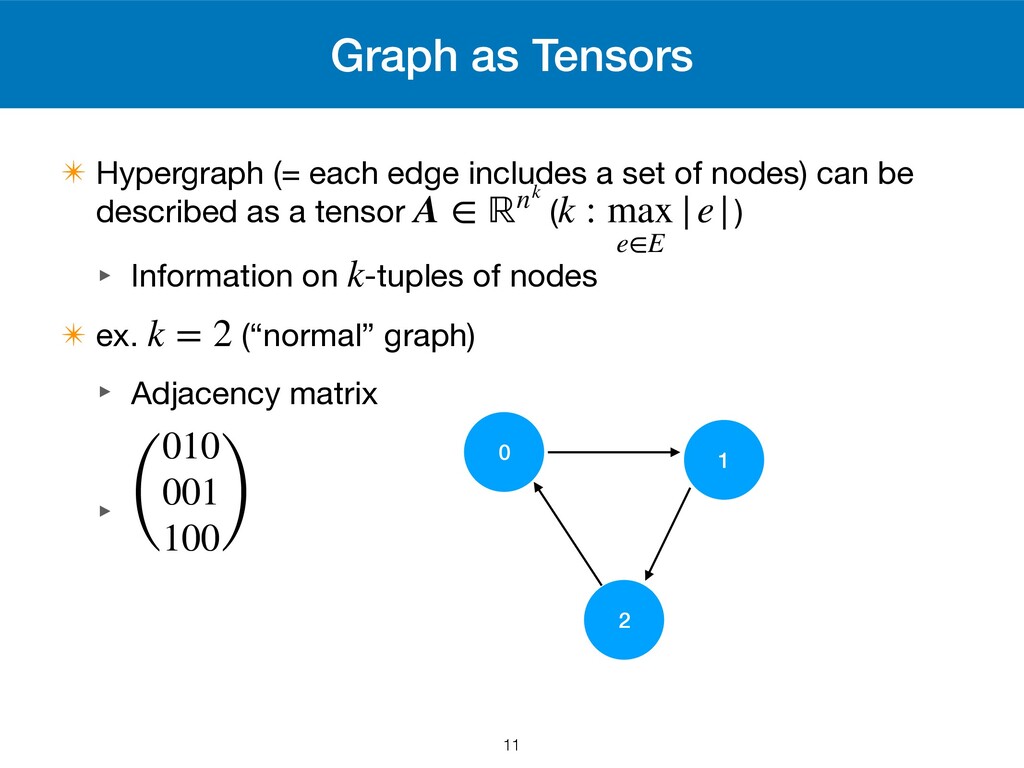
set of nodes) can be described as a tensor ( ) ‣ Information on -tuples of nodes ✴ ex. (“normal” graph) ‣ Adjacency matrix ‣ A ∈ ℝnk k : max e∈E |e| k k = 2 ( 010 001 100 ) 11 0 2 1
be reordering operator ‣ is a permutation of in each dimension ✴ Invariance of ‣ ✴ Equivariance of ‣ P ⋆ P ⋆ A A f : ℝnk → ℝ f(P ⋆ A) = f(A) f : ℝnk → ℝnl f(P ⋆ A) = P ⋆ f(A) 13 http://irregulardeep.org/An-introduction-to-Invariant-Graph-Networks-(1-2)/
network model, it’s natural to construct the architecture below ‣ : Equivariant linear layer + nonlinear activation function ‣ : Invariant linear layer ‣ : Multilayer perceptron Li H M 14 http://irregulardeep.org/An-introduction-to-Invariant-Graph-Networks-(1-2)/ ℝnk0 ℝnk1 ℝnk2 ℝnkL ℝ ℝ
network model, it’s natural to construct the architecture below ‣ : Equivariant linear layer + nonlinear activation function ‣ : Invariant linear layer ‣ : Multilayer perceptron ✴ Can we collect all equivariant linear layers? Li H M 15 http://irregulardeep.org/An-introduction-to-Invariant-Graph-Networks-(1-2)/ ℝnk0 ℝnk1 ℝnk2 ℝnkL ℝ ℝ
an invariant linear layer ‣ Dimension is ✴ Let be an equivariant linear layer ‣ Dimension is ✴ Where is -th Bell number ‣ Number of ways to partition distinguished elements f : ℝnk → ℝ b(k) f : ℝnk → ℝnl b(k + l) b(k) k k 16 k 1 2 3 4 5 6 7 8 9 b(k) 1 2 5 15 52 203 877 4140 21147 https://en.wikipedia.org/wiki/Bell_number
Consider coefficient matrix and solve the fixed- point equations ‣ (for all permutation ) 2. Let be an equivalence relation over , such that ‣ and consider equivalence class 3. From each , we can construct orthogonal basis ‣ f : ℝnk → ℝnl b(k + l) X ∈ ℝnk×nl Q ⋆ X = X Q ∼ [n]l a ∼ b : ai = aj ⇔ bi = bj (∀i, j ∈ [l]) [n]l/ ∼ γ ∈ [n]l/ ∼ Bγ a = { 1 (a ∈ γ) 0 (otherwise) 17
an invariant linear layer ‣ Dimension is ✴ Let be an equivariant linear layer ‣ Dimension is ✴ Dimension doesn’t depend on ‣ IGN can be applied to graphs of different sizes ✴ We call IGN with max tensor order as -IGN f : ℝnk → ℝ b(k) f : ℝnk → ℝnl b(k + l) n k k 18
function with high-order tensor. ✴ [Maron+ ICML 2019] ‣ Show invariant case by [Yarotsky+ 2018]’s polynomial ✴ [Keriven+ NeurIPS 2019] ‣ Show equivariant case (output tensor order is ) by extended Stone-Weierstrass theorem ✴ [Maehara+ 2019] ‣ Show equivariant case (for high output tensor order) by homomorphism number 1 20
function with high-order tensor. ✴ [Maron+ ICML 2019] ‣ Show invariant case by [Yarotsky+ 2018]’s polynomial ✴ [Keriven+ NeurIPS 2019] ‣ Show equivariant case (output tensor order is ) by extended Stone-Weierstrass theorem ✴ [Maehara+ 2019] ‣ Show equivariant case (for high output tensor order) by homomorphism number Architecture with high order-tensor is not practical. 1 21
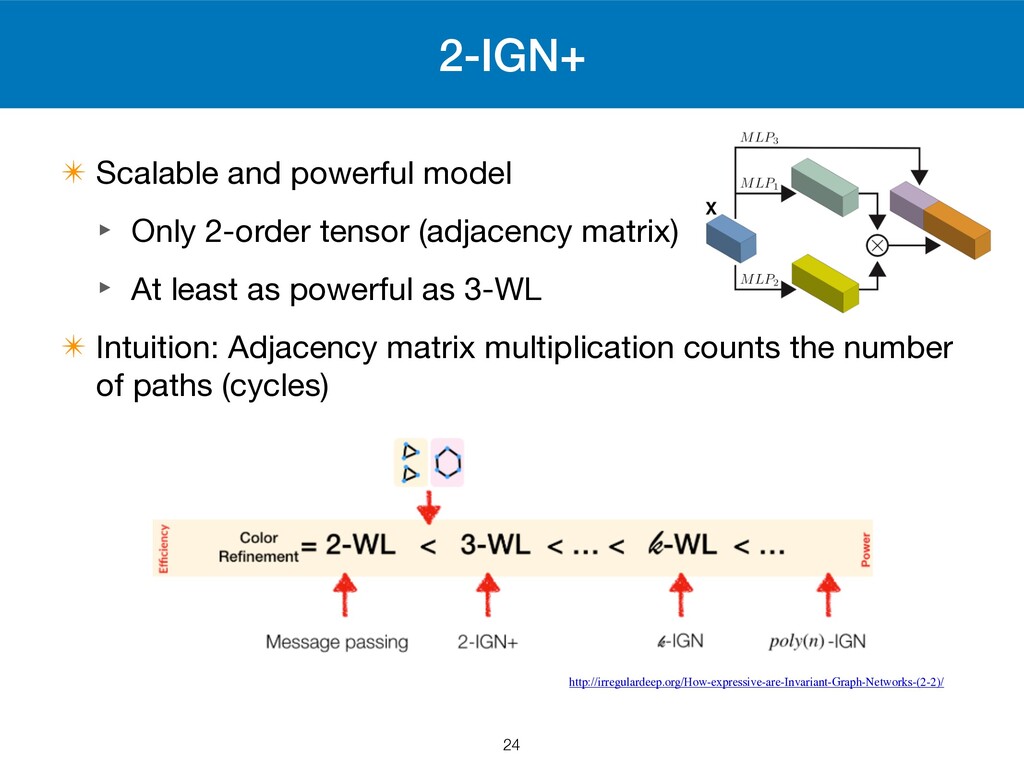
correspondence between -IGN and -WL ✴ Proposed a strong and scalable model 2-IGN+ k k 22 http://irregulardeep.org/How-expressive-are-Invariant-Graph-Networks-(2-2)/
✴ There exist a known hierarchy of -WL ‣ -WL is strictly stronger than -WL ✴ -IGN is at least as strong as -WL (Their contribution) k k (k + 1) k k k 23 http://irregulardeep.org/How-expressive-are-Invariant-Graph-Networks-(2-2)/
(adjacency matrix) ‣ At least as powerful as 3-WL ✴ Intuition: Adjacency matrix multiplication counts the number of paths (cycles) 24 http://irregulardeep.org/How-expressive-are-Invariant-Graph-Networks-(2-2)/
success. ✴ Due to the theoretical limitation of message passing GNN’s representation power, Invariant Graph Network was invented. ✴ Invariant Graph Network can approximate any invariant function, but needs high-order tensor. ✴ Scalable models of Invariant Graph Network are studied for practical use. 26
technique doesn’t affect representation power but affects any of these? ✴ Beyond invariance (equivariance) ‣ [Sato+ NeurIPS 2019] connected the theory of GNN and distributed local algorithm ‣ Sometimes we need non-invariant (non-equivariant) function? ✴ Scalable model of IGN ‣ 2-IGN+ requires while MPNNs run in ‣ Polynomial invariant / equivariant layer O(n3) O(|E|) 27
Nimrod & Lipman, Yaron. (2019). On the Universality of Invariant Networks. ✴ Keriven, Nicolas & Peyré, Gabriel. (2019). Universal Invariant and Equivariant Graph Neural Networks. ✴ Maehara, Takanori & NT, Hoang. (2019). A Simple Proof of the Universality of Invariant/Equivariant Graph Neural Networks. ✴ Maron, Haggai & Ben-Hamu, Heli & Serviansky, Hadar & Lipman, Yaron. (2019). Provably Powerful Graph Networks. ✴ R. Sato, M. Yamada, and H. Kashima. Approximation Ratios of Graph Neural Networks for Combinatorial Problems. In NeurIPS 2019. 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Message Passing Neural Networks (MPNNs) [Gilmer+ ICML 2017] Many proposed](https://files.speakerdeck.com/presentations/3b7cb77c79a7446fb072f1e89fb368cb/slide_6.jpg){kind=link}
![Expressive Power of MPNNs ✴ [Xu+ ICLR 2019] and [Morris+](https://files.speakerdeck.com/presentations/3b7cb77c79a7446fb072f1e89fb368cb/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Invariant Graph Networks [Maron+ ICLR 2019] ✴ Imitating other neural](https://files.speakerdeck.com/presentations/3b7cb77c79a7446fb072f1e89fb368cb/slide_13.jpg){kind=link}
![Invariant Graph Networks [Maron+ ICLR 2019] ✴ Imitating other neural](https://files.speakerdeck.com/presentations/3b7cb77c79a7446fb072f1e89fb368cb/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Provably Powerful Graph Networks [Maron+ NeurIPS 2019] ✴ Proved the](https://files.speakerdeck.com/presentations/3b7cb77c79a7446fb072f1e89fb368cb/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}