Weʼve Been and Where Weʼre Going (⾃然⾔語処理界隈の)これまでの歩みとこれからの⾏く末を把握する 重視されていた視点 • Reflect on the progress of the field or a sub-topic area from a larger spectrum and make connections and/or comparisons between the past and the present to provide a holistic view on where we stand today with respect to the past; • Examine, analyze, and interpret SOTA models and results to shed light on limitations as well as key advances that may have lasting impact; • Bring novel ideas for advancing the field, e.g., to enable and measure a machineʼs ability in language processing beyond laboratory benchmarks; 3
• QQPタスクのMFTテストタイプに絞り、2hで検証 • 結果 • 枠組みについて教えることで、より多くの⾔語能⼒を思いついた(Group ii., iii. vs Group i.) • データ作成テンプレートを与えることで、多くのテストケースを作成出来た(Group iii. vs Group i., ii.) 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
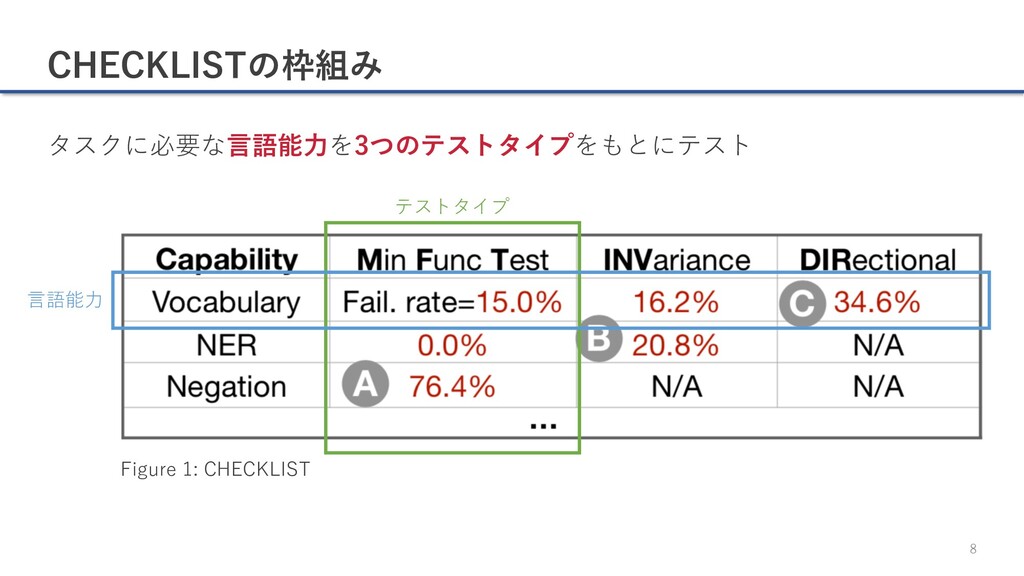{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
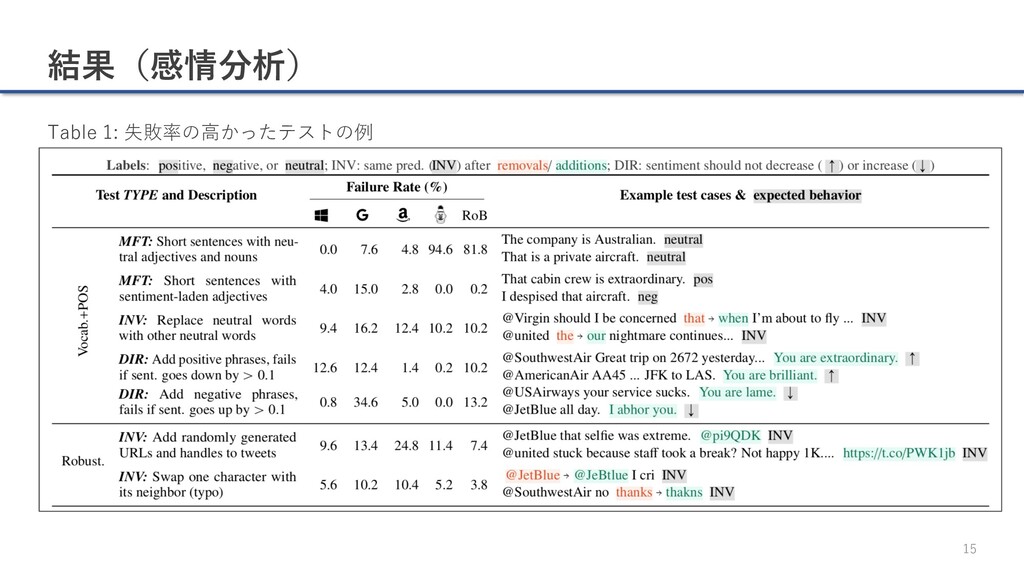{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
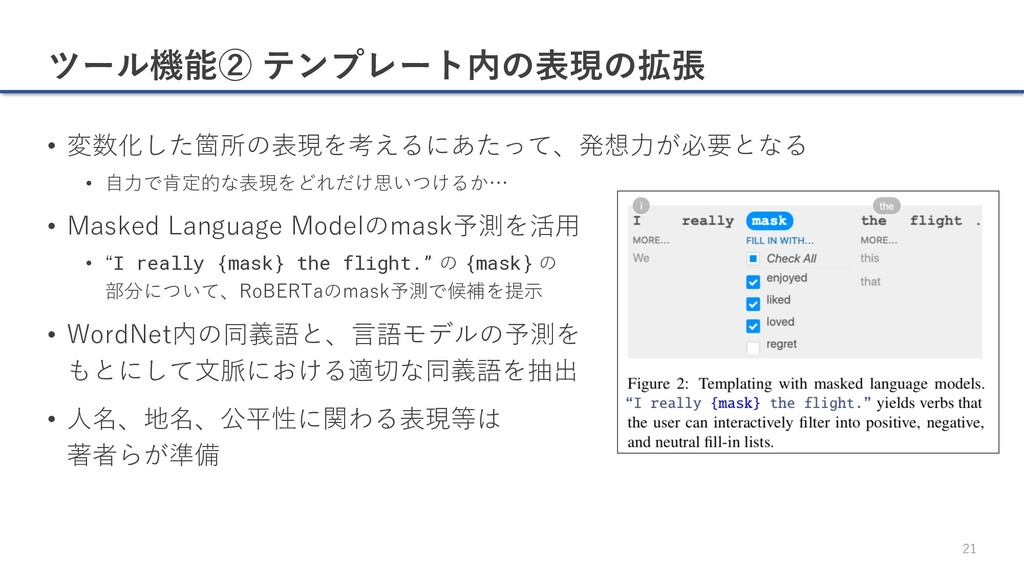{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}