Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
タウンワークにおける機械学習API@GKEの導入
Search
kosuke-kitahara
October 26, 2018
Technology
10
3.4k
タウンワークにおける機械学習API@GKEの導入
kosuke-kitahara
October 26, 2018
Tweet
Share
Other Decks in Technology
See All in Technology
僕、S3 シンプルって名前だけど全然シンプルじゃありません よろしくお願いします
yama3133
1
230
モジュラモノリス導入から4年間の総括:アーキテクチャと組織の相互作用について / Architecture and Organizational Interaction
nazonohito51
1
230
"作る"から"使われる"へ:Backstage 活用の現在地
sbtechnight
0
190
JAWSDAYS2026_A-6_現場SEが語る 回せるセキュリティ運用~設計で可視化、AIで加速する「楽に回る」運用設計のコツ~
shoki_hata
0
3k
Oracle Cloud Infrastructure IaaS 新機能アップデート 2025/12 - 2026/2
oracle4engineer
PRO
0
170
The_Evolution_of_Bits_AI_SRE.pdf
nulabinc
PRO
0
240
2026年もソフトウェアサプライチェーンのリスクに立ち向かうために / Product Security Square #3
flatt_security
1
650
Cortex Code CLI と一緒に進めるAgentic Data Engineering
__allllllllez__
0
420
楽しく学ぼう!ネットワーク入門
shotashiratori
1
460
(Test) ai-meetup slide creation
oikon48
3
450
内製AIチャットボットで学んだDatadog LLM Observability活用術
mkdev10
0
130
バクラク最古参プロダクトで重ねた技術投資を振り返る
ypresto
0
170
Featured
See All Featured
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
1
320
Building a Modern Day E-commerce SEO Strategy
aleyda
45
8.9k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.8k
How STYLIGHT went responsive
nonsquared
100
6k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
1.9k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.6k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
0
180
Scaling GitHub
holman
464
140k
From π to Pie charts
rasagy
0
150
Mind Mapping
helmedeiros
PRO
1
120
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
300
Transcript
タウンワークにおける機械学 習API@GKEの導入 リクルートジョブズ 商品本部 データマネジメント部 コアテクノロジーグループ 北原 康佑 (@KosukeKitahara)
[email protected]
Background: - 香川高専 詫間キャンパス 情報工学科 - 東京農工大学大学院 情報工学科 - リクルートホールディングス 入社 (2017) - データサイエンティスト/MLエンジニア/サーチエンジニア
Research Area: - Neuroscience 今やっていること: - タウンワークの検索ロジック/APIの開発 About Me
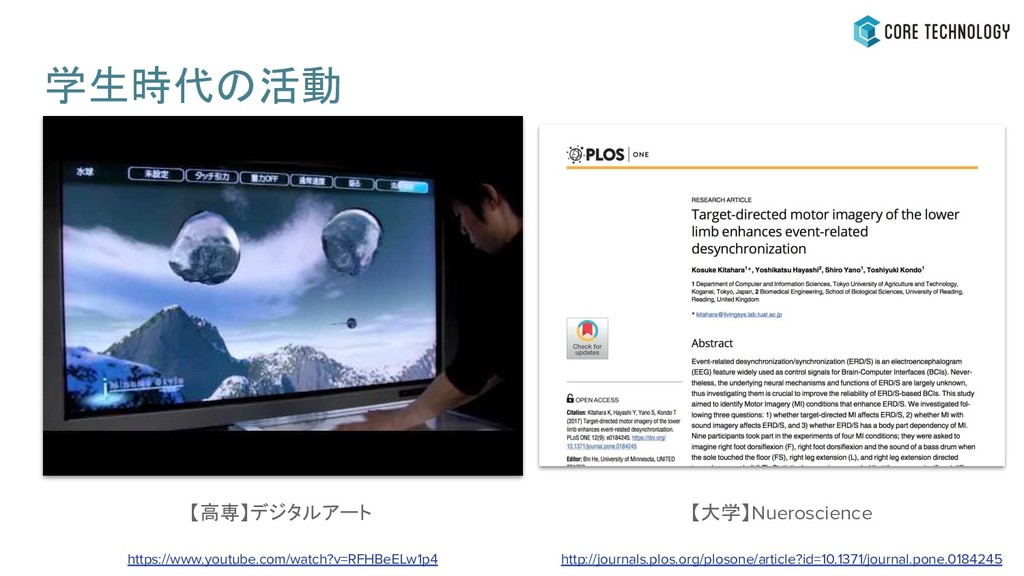
学生時代の活動 【大学】Nueroscience http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0184245 【高専】デジタルアート https://www.youtube.com/watch?v=RFHBeELw1p4
本日のアジェンダ 機械学習API@GKEについて (10 min) - タウンワークの紹介 - ジョブーブの相談部屋について - タウンワークのドメイン特性
- 誰の何を解決するのか? - ロジックについて - アーキテクチャ@GKEの紹介 MLエンジニアが価値を発揮するためには (10 min) - ML組織のぶち当たる壁と乗り越え方 - 効果観点の検証 -> 実運用時の課題&ベストプラクティス まとめ&質疑応答 (10 min)
機械学習API@GKEの導入について
・日本最大級の求人情報提供サービス ・アルバイトパート系の求人が多数 タウンワークのご紹介
① 日常的に利用するものではないため、ユーザーのアクション数が少ない → データが少ない ② 初訪問時に具体的なニーズが顕在化していないユーザーが多い → ディレクトリ型検索が難しい タウンワークのドメイン特性
① 日常的に利用するものではないため、ユーザーのアクション数が少ない → データが少ない ② 初訪問時に具体的なニーズが顕在化していないユーザーが多い → ディレクトリ型検索が難しい タウンワークのドメイン特性 受動的な検索でニーズを顕在化
Problems & Segment Problems: ・ユーザーが理想のバイトを理解していない 自分のやりたいことがふわっとしていて、それをどうやって調べたらいいかユーザー本人もわからない ・ディレクトリ型検索の「能動的な選択」は難しい Segment: ・バイトはしたいが、自分自身も、自分のやりたいバイトをはっきりと認知して いない ユーザー
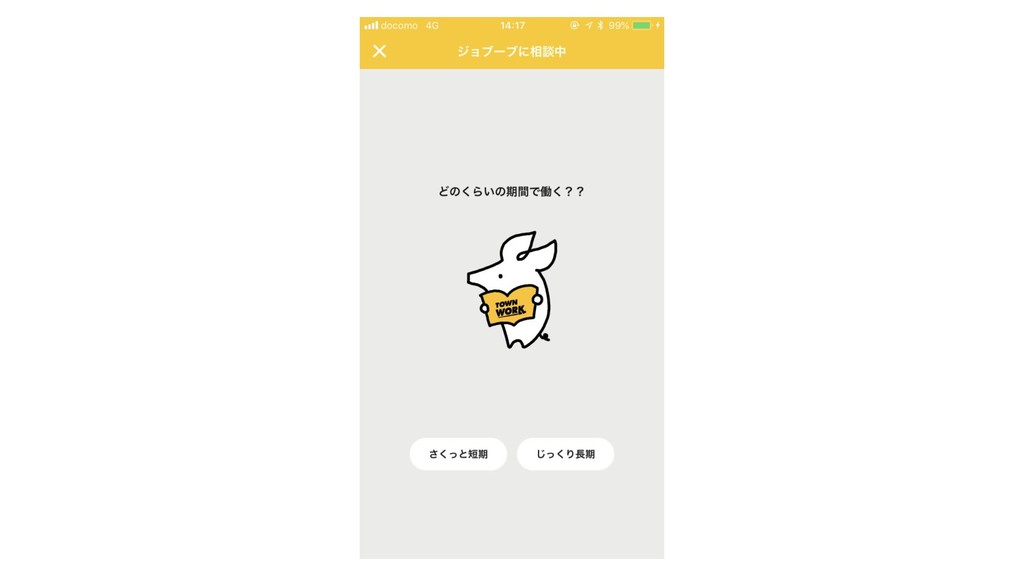
Solution: ・ユーザーが持つ潜在的なニーズを引き出すサポートをする ・受動的な検索体験を提供 Product: ・ジョブーブの相談部屋 Solution & Product
Solution: ・ユーザーが持つ潜在的なニーズを引き出すサポートをする ・受動的な検索体験を提供 Product: ・ジョブーブの相談部屋 Solution & Product
None
ロジックのイメージ 対話ロジック 自分にはどんな仕事が 向いているだろう? この仕事好きかも...!!
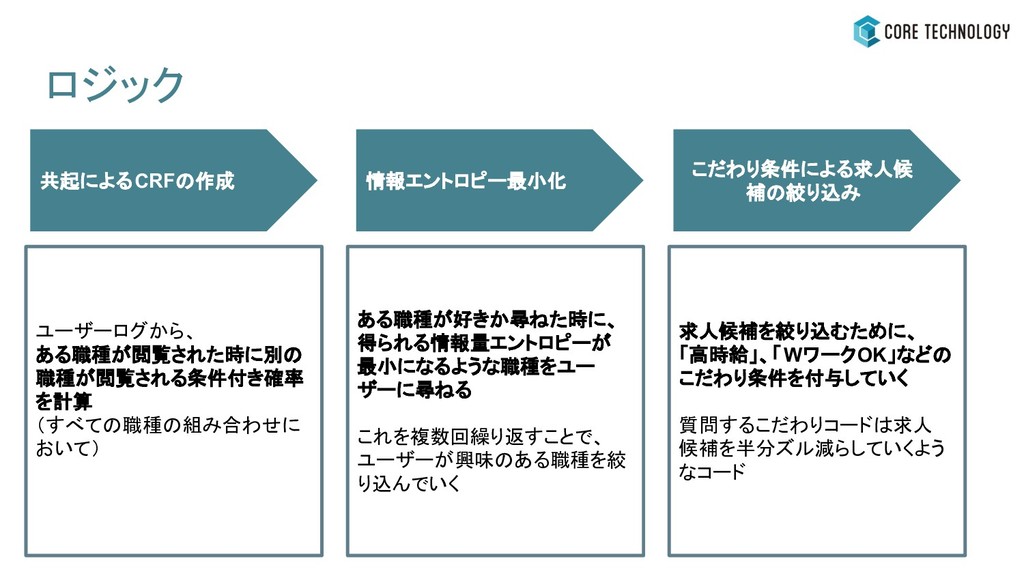
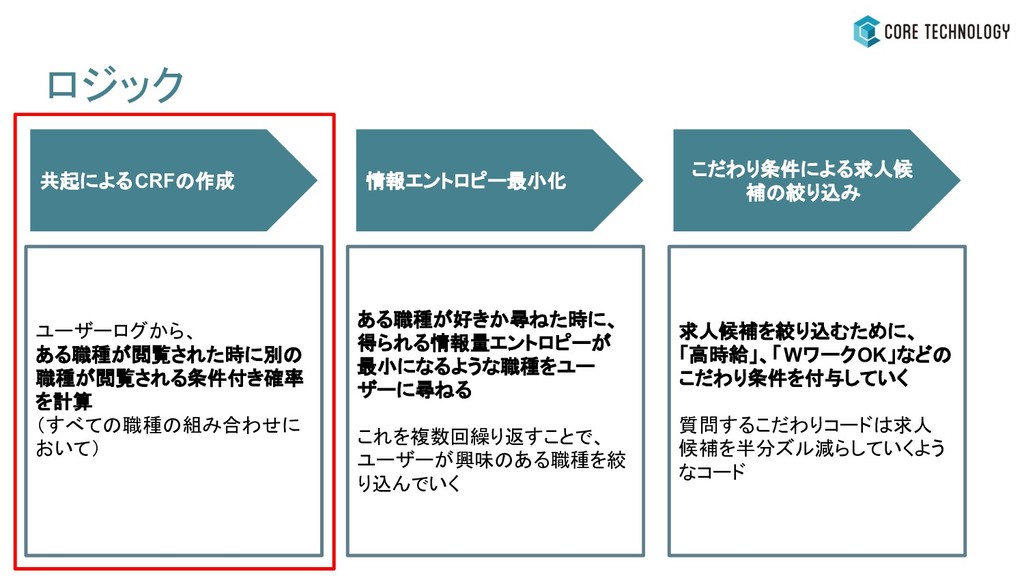
・条件付き確率場(CRF) ・情報エントロピーの最小化 自分にはどんな仕事が 向いているだろう? 対話ロジック この仕事好きかも...!! ロジックのイメージ
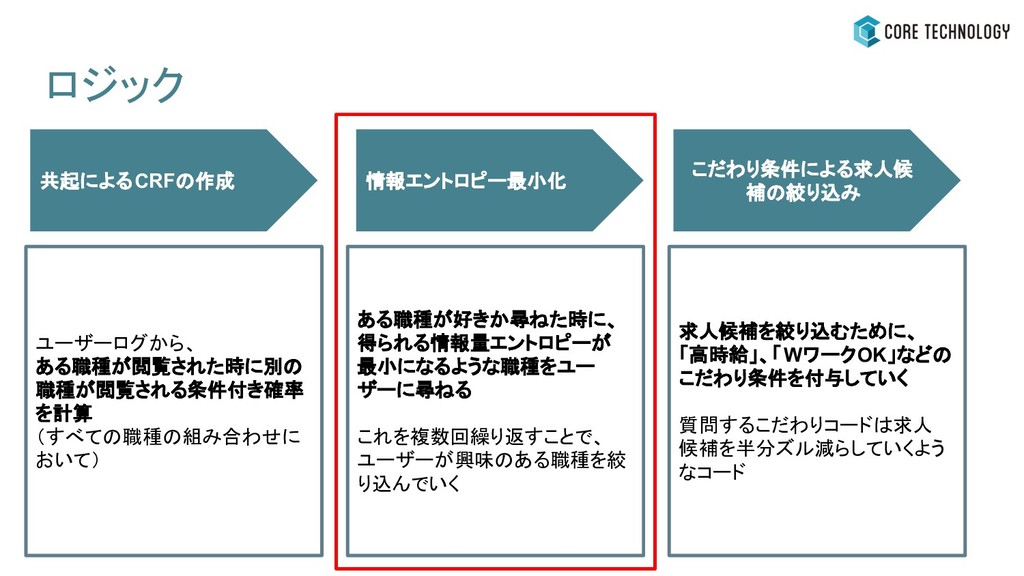
ある職種が好きか尋ねた時に、 得られる情報量エントロピーが 最小になるような職種をユー ザーに尋ねる これを複数回繰り返すことで、 ユーザーが興味のある職種を絞 り込んでいく ユーザーログから、 ある職種が閲覧された時に別の 職種が閲覧される条件付き確率
を計算 (すべての職種の組み合わせに おいて) ロジック 情報エントロピー最小化 こだわり条件による求人候 補の絞り込み 共起によるCRFの作成 求人候補を絞り込むために、 「高時給」、「WワークOK」などの こだわり条件を付与していく 質問するこだわりコードは求人 候補を半分ズル減らしていくよう なコード
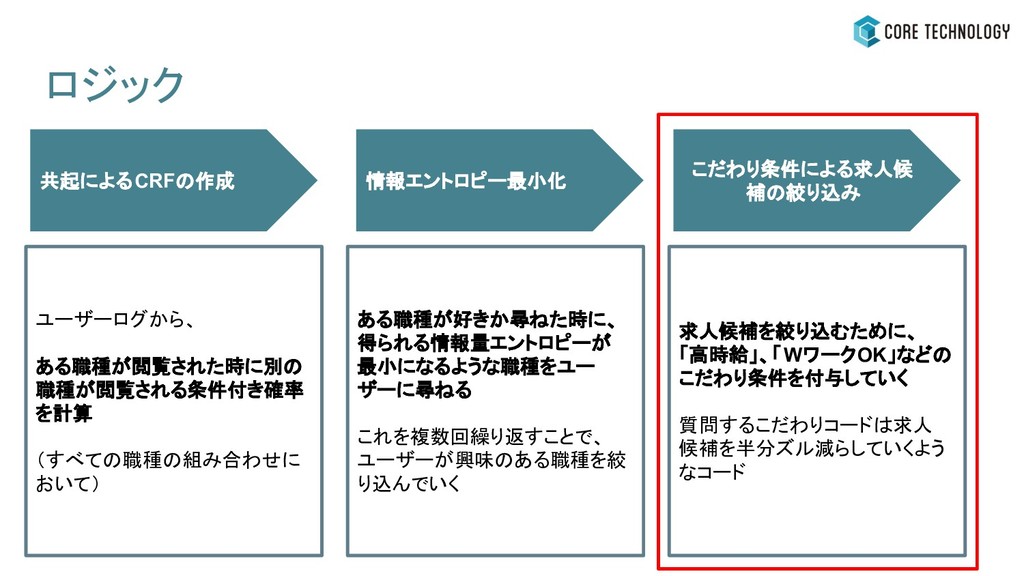
ロジック ある職種が好きか尋ねた時に、 得られる情報量エントロピーが 最小になるような職種をユー ザーに尋ねる これを複数回繰り返すことで、 ユーザーが興味のある職種を絞 り込んでいく 情報エントロピー最小化 ユーザーログから、
ある職種が閲覧された時に別の 職種が閲覧される条件付き確率 を計算 (すべての職種の組み合わせに おいて) こだわり条件による求人候 補の絞り込み 共起によるCRFの作成 求人候補を絞り込むために、 「高時給」、「WワークOK」などの こだわり条件を付与していく 質問するこだわりコードは求人 候補を半分ズル減らしていくよう なコード
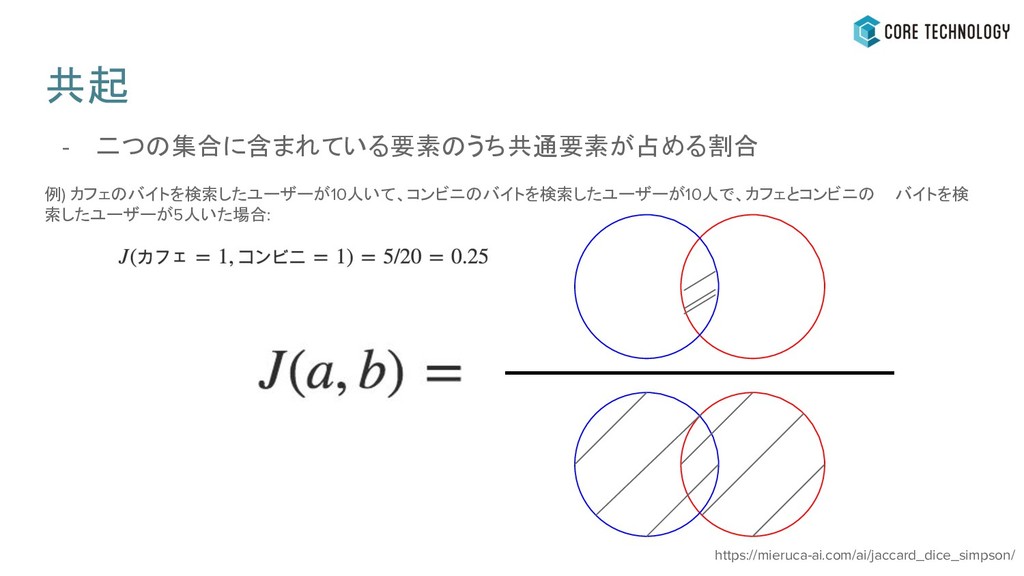
- 二つの集合に含まれている要素のうち共通要素が占める割合 例) カフェのバイトを検索したユーザーが10人いて、コンビニのバイトを検索したユーザーが10人で、カフェとコンビニの バイトを検 索したユーザーが5人いた場合: 共起 https://mieruca-ai.com/ai/jaccard_dice_simpson/
共起によるCRFの作成 ・先ほどの共起をベイズの定理を用いて条件付き確率に直す ・全中職種xiの条件付き確率に対してユーザーがその求人を好む確率を共起を用いて 計算する (x_i = 1: 職種x_iが好き, x_i =
0: 職種x_iが好きじゃない) 例) x_1 (カフェ) が好き ∩ x_2 (コンビニ) が好きじゃない ∩ x_3 (レストラン)が好き、な時に x_i (居酒屋)が好きな確率
ある職種が好きか尋ねた時に、 得られる情報量エントロピーが 最小になるような職種をユー ザーに尋ねる これを複数回繰り返すことで、 ユーザーが興味のある職種を絞 り込んでいく ロジック 情報エントロピー最小化 ユーザーログから、
ある職種が閲覧された時に別の 職種が閲覧される条件付き確率 を計算 (すべての職種の組み合わせに おいて) こだわり条件による求人候 補の絞り込み 共起によるCRFの作成 求人候補を絞り込むために、 「高時給」、「WワークOK」などの こだわり条件を付与していく 質問するこだわりコードは求人 候補を半分ズル減らしていくよう なコード
- 聞いて非常に驚く情報 ・・・ 情報量が大きい - 聞いても驚かない情報 ・・・ 情報量が小さい 情報量 http://web.tuat.ac.jp/~s-hotta/info/slide5.pdf
- 情報量の平均(期待値) 平均情報量 (= 情報エントロピー) http://web.tuat.ac.jp/~s-hotta/info/slide5.pdf 事象系Aのすべての事象の生起確率が等しい(一様分布)のとき、 情報エントロピーが最大となる = 何が起こるか全くわからない状態
情報エントロピーの一例 http://web.tuat.ac.jp/~s-hotta/info/slide5.pdf
情報エントロピーを最小化するとは? ・エントロピー最小 = ユーザーの好みが完全に特定された状態 例) カフェが好き(x_{カフェ} = 1)で、それ以外の職種が好きじゃない時に、エントロピーが 最小になる →
人によって、カフェもコンビニも好きということはあり得るが、エントロピーを最小化して いくことでユーザーの好みを絞り込むことができる
仮にその職種をユーザーが好むことが判明した場合に、情報エントロピーが最小になる ような職種x_jが気になるかどうか質問する 情報エントロピーの最小化
ある職種が好きか尋ねた時に、 得られる情報量エントロピーが 最小になるような職種をユー ザーに尋ねる これを複数回繰り返すことで、 ユーザーが興味のある職種を絞 り込んでいく ロジック 情報エントロピー最小化 ユーザーログから、
ある職種が閲覧された時に別の 職種が閲覧される条件付き確率 を計算 (すべての職種の組み合わせに おいて) こだわり条件による求人候 補の絞り込み 共起によるCRFの作成 求人候補を絞り込むために、 「高時給」、「WワークOK」などの こだわり条件を付与していく 質問するこだわりコードは求人 候補を半分ズル減らしていくよう なコード
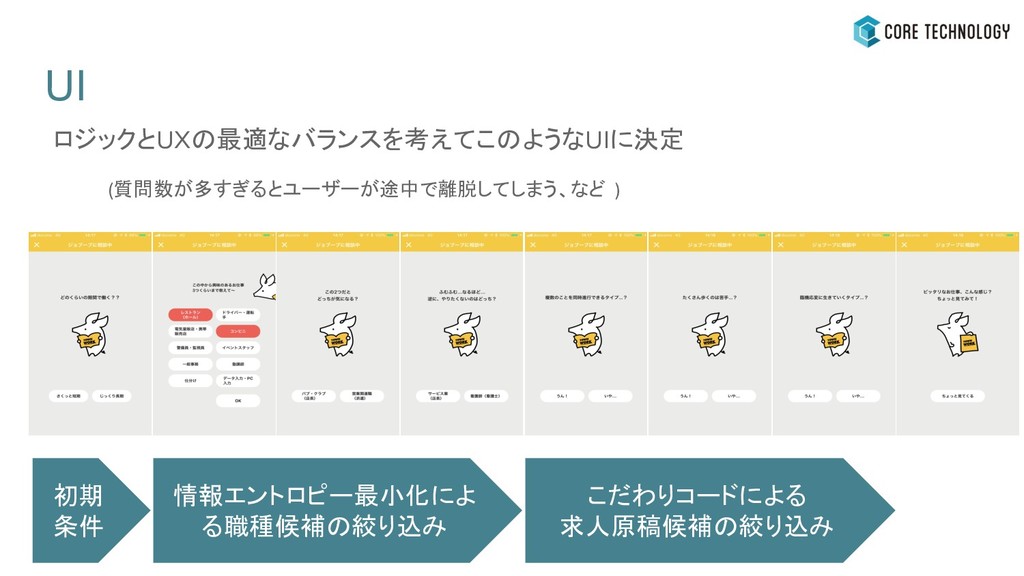
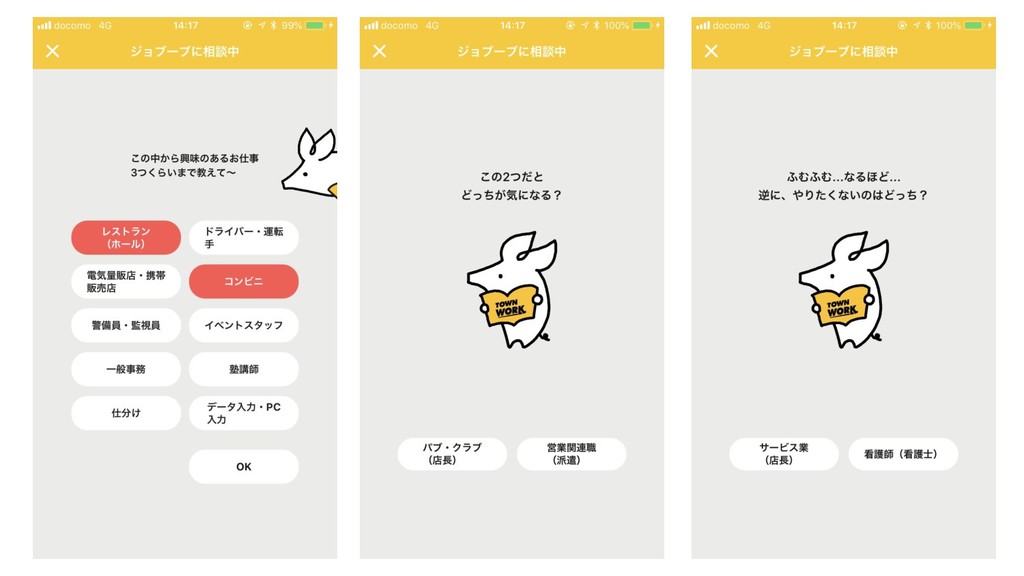
なぜ半分ずつ原稿を減らしているのか? 原稿数を限られた質問回数の中で適切な数に減らす必要あり ・減らす原稿が多すぎる場合 : 求人原稿候補が少なくなり過ぎてしまう ・減らす原稿が少なすぎる場合 : 求人原稿候補が多くなり過ぎてしまう → 半分ずつ減らすような質問をしよう
こだわりコードによる 求人原稿候補の絞り込み 初期 条件 情報エントロピー最小化によ る職種候補の絞り込み UI ロジックとUXの最適なバランスを考えてこのようなUIに決定 (質問数が多すぎるとユーザーが途中で離脱してしまう、など )
None
None
None
None
インフラについて
Kubernetes コンテナ化アプリケーションの自動デプロイ、スケーリング、アプリ・コンテナの運用等を 迅速かつ効率よくできるようにしたオープンソースのプラットフォーム https://qiita.com/MahoTakara/items/85096f8b2632c802ab22
Google Kubernetes Engine (GKE) Kubernetesの技術を組み込んだ、コンテナ化されたアプリケーションをデプロイするた めのマネージド環境 ・簡単かつ頻繁に公開 ・高い信頼性と自己回復力 ・リソースに合わせたデプロイ ・無理なくスケールして需要に対応
https://cloud.google.com/kubernetes-engine/
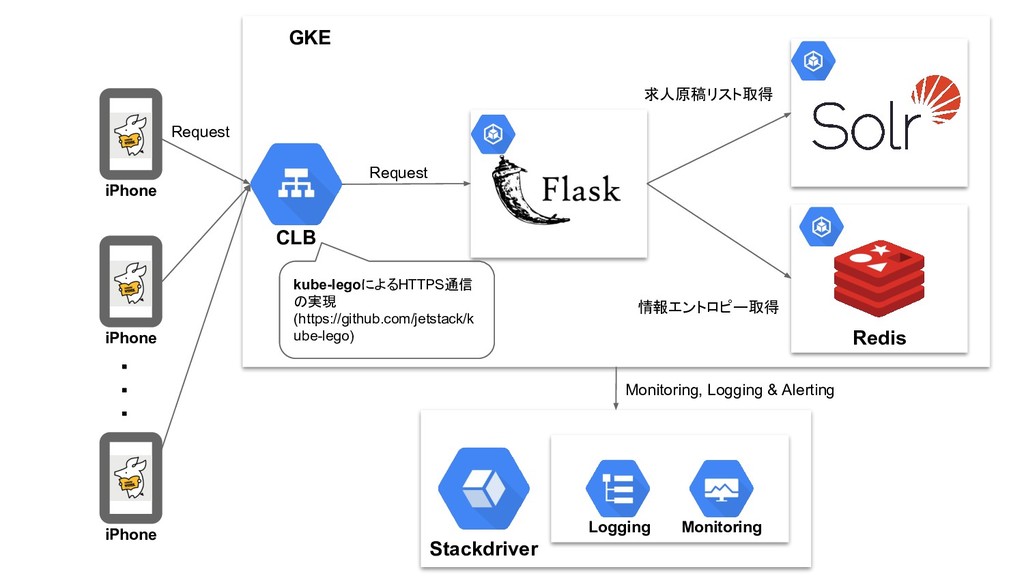
Stackdriver Logging Monitoring CLB Redis iPhone iPhone iPhone ・ ・
・ GKE Monitoring, Logging & Alerting Request Request 情報エントロピー取得 求人原稿リスト取得
Stackdriver Logging Monitoring CLB Redis iPhone iPhone iPhone ・ ・
・ GKE Monitoring, Logging & Alerting Request Request kube-legoによるHTTPS通信 の実現 (https://github.com/jetstack/k ube-lego) 情報エントロピー取得 求人原稿リスト取得
ロジック コンバージョン率 リフト A 1.00 - B (今回の ロジック) 1.06
106% 効果 ロジックAのコンバージョン率を 1.0とした場合
ここまでさらっとお話ししてきましたが
機械学習組織が価値を発揮するためには
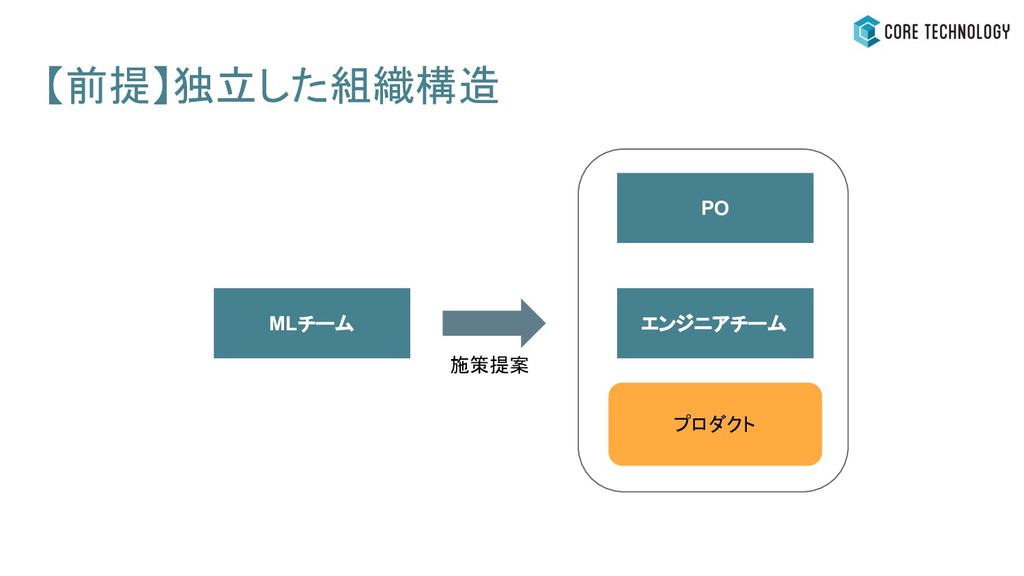
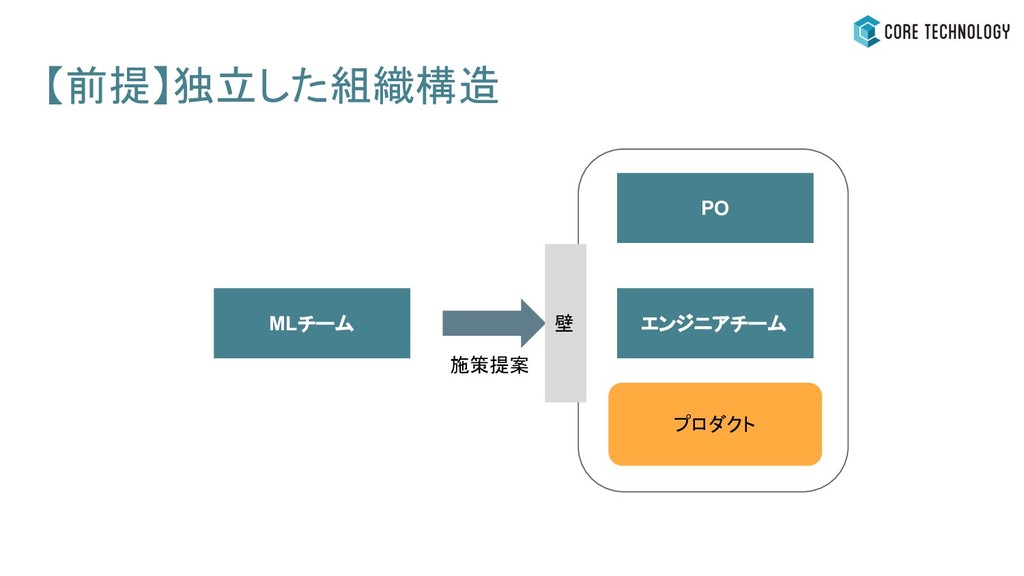
【前提】独立した組織構造 MLチーム エンジニアチーム PO プロダクト
【前提】独立した組織構造 MLチーム エンジニアチーム PO プロダクト 施策提案
【前提】独立した組織構造 MLチーム エンジニアチーム PO プロダクト 施策提案 壁
- 独立した組織構造になっていて声が届きにくい - How寄りの施策はなかなかできない - How寄りの施策を提案しがち - エンジニアチームはアジャイル開発体制を敷いており - ROIや工数管理の観点でなかなか着手優先度が上がらない
MLエンジニアが施策を提案するときの壁
- 独立した組織構造になっていて声が届きにくい - How寄りの施策はなかなかできない - How寄りの施策を提案しがち - エンジニアチームはアジャイル開発体制を敷いており - ROIや工数管理の観点でなかなか着手優先度が上がらない
MLエンジニアが施策を提案するときの壁 どうやってこの壁を乗り越えたか?
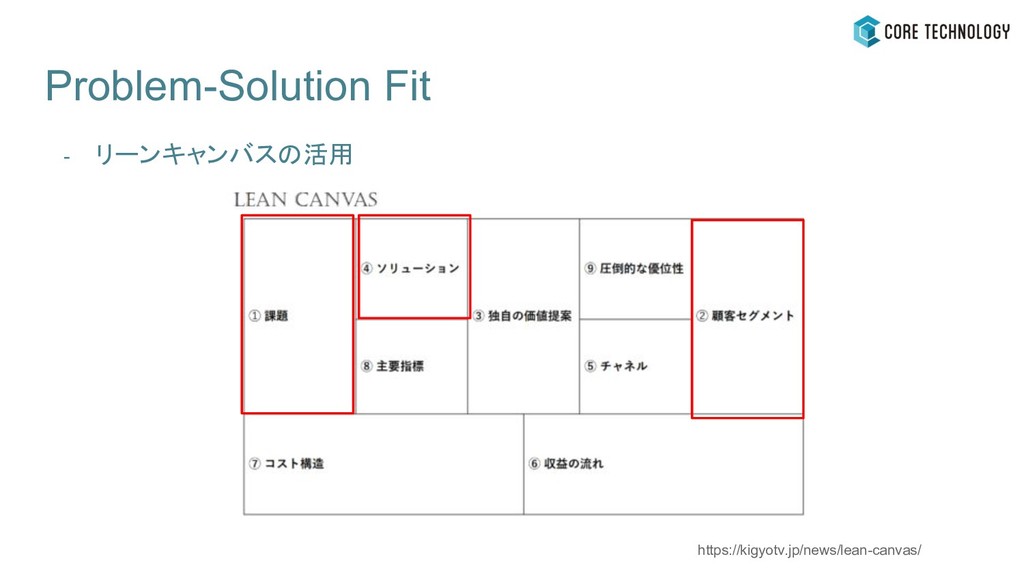
Problem-Solution Fit - リーンキャンバスの活用 https://kigyotv.jp/news/lean-canvas/
Problem-Solution Fit - リーンキャンバスの活用 https://kigyotv.jp/news/lean-canvas/
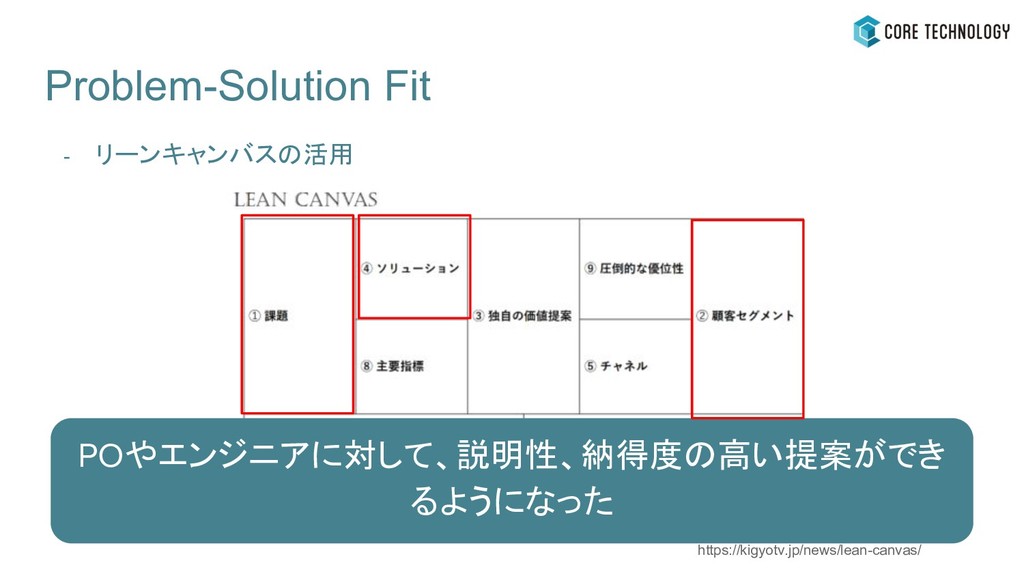
Problem-Solution Fit - リーンキャンバスの活用 https://kigyotv.jp/news/lean-canvas/ POやエンジニアに対して、説明性、納得度の高い提案ができ るようになった
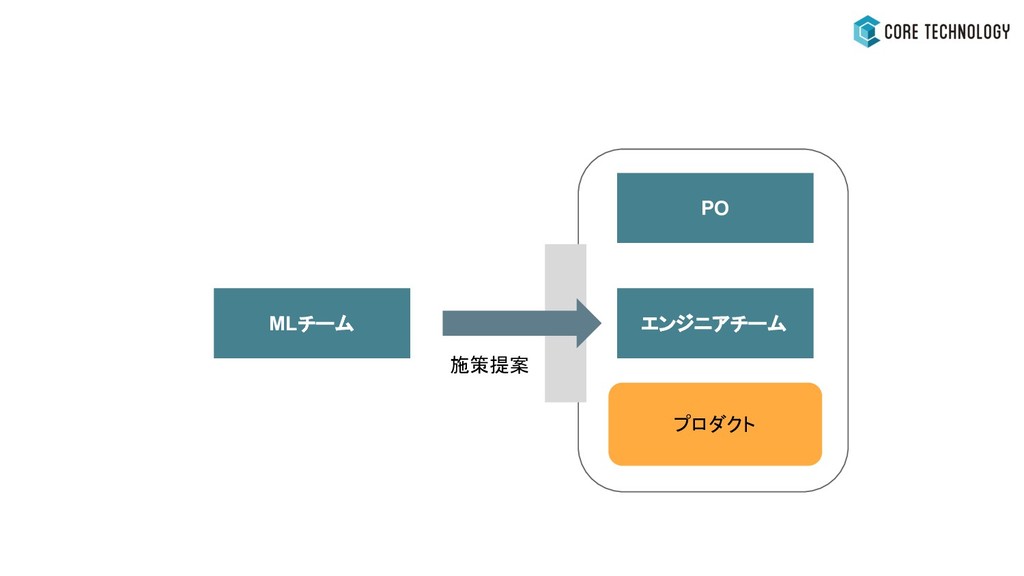
MLチーム エンジニアチーム PO プロダクト 施策提案 壁
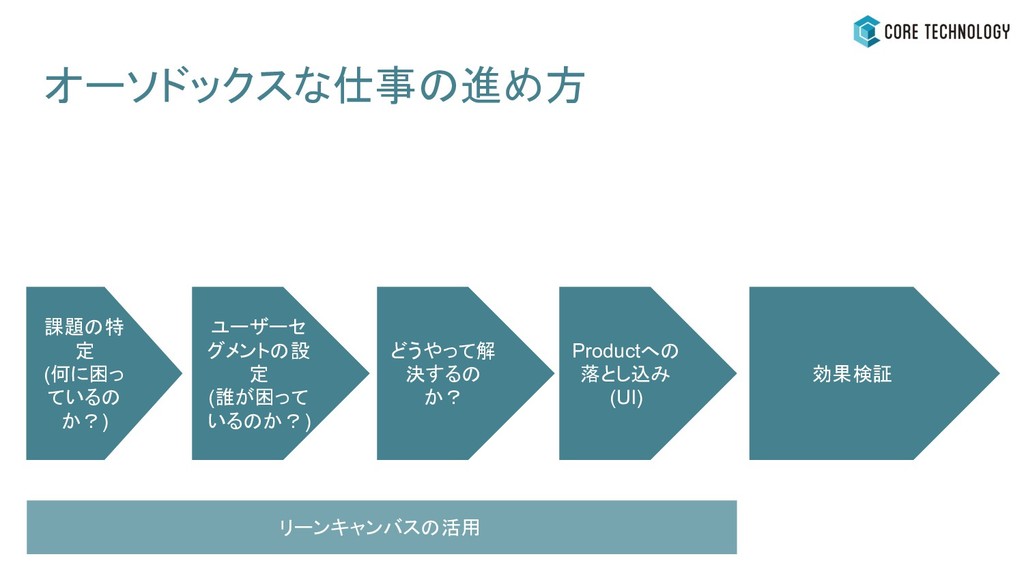
オーソドックスな仕事の進め方 課題の特 定 (何に困っ ているの か?) ユーザーセ グメントの設 定 (誰が困って
いるのか?) どうやって解 決するの か? Productへの 落とし込み (UI) リーンキャンバスの活用 効果検証
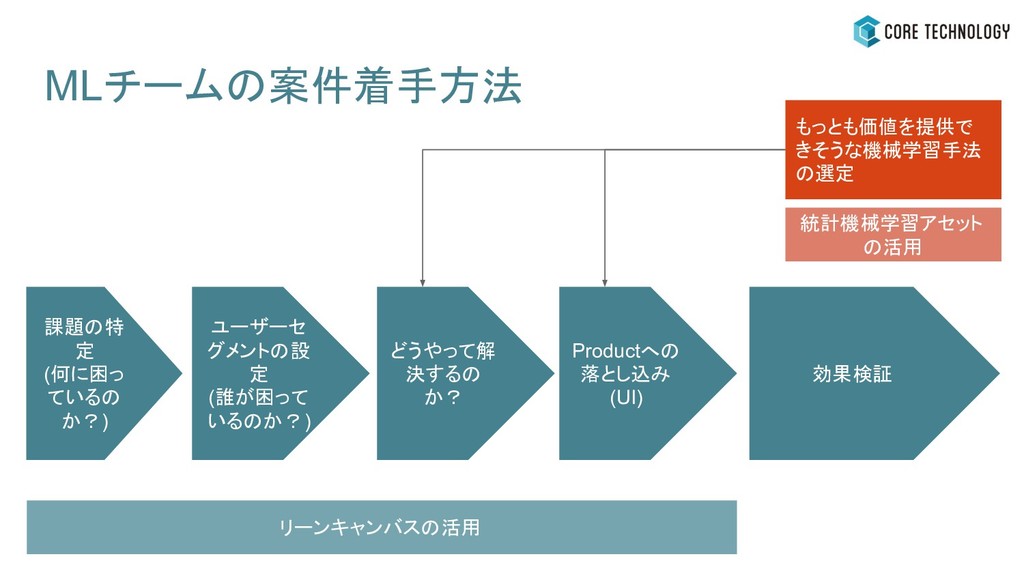
MLチームの案件着手方法 もっとも価値を提供で きそうな機械学習手法 の選定 統計機械学習アセット の活用 課題の特 定 (何に困っ ているの
か?) ユーザーセ グメントの設 定 (誰が困って いるのか?) どうやって解 決するの か? Productへの 落とし込み (UI) リーンキャンバスの活用 効果検証
- Amazon Alexa、Google Homeの登場 - 情報検索のトップカンファレンスであるSIGIRや機械学習のトップカンファレンスであ るKDDでも会話型システムのWorkshopやSessionが組まれている - Workshop @KDD
2018 (https://cai.kdd2018.a.intuit.com/) - Workshop & Session@SIGIR 2018(http://sigir.org/sigir2018/program/program-at-a-glance/) [余談] 会話型システムの流行
【方針】効果検証速度を重視 Proof of Concept (PoC) - 効果観点の検証 - - 効果検証ができること
効果観点 - Fail Safeであること(安全に切り戻せるか) - 社内で定められたセキュリティーは担保されているか システム観点
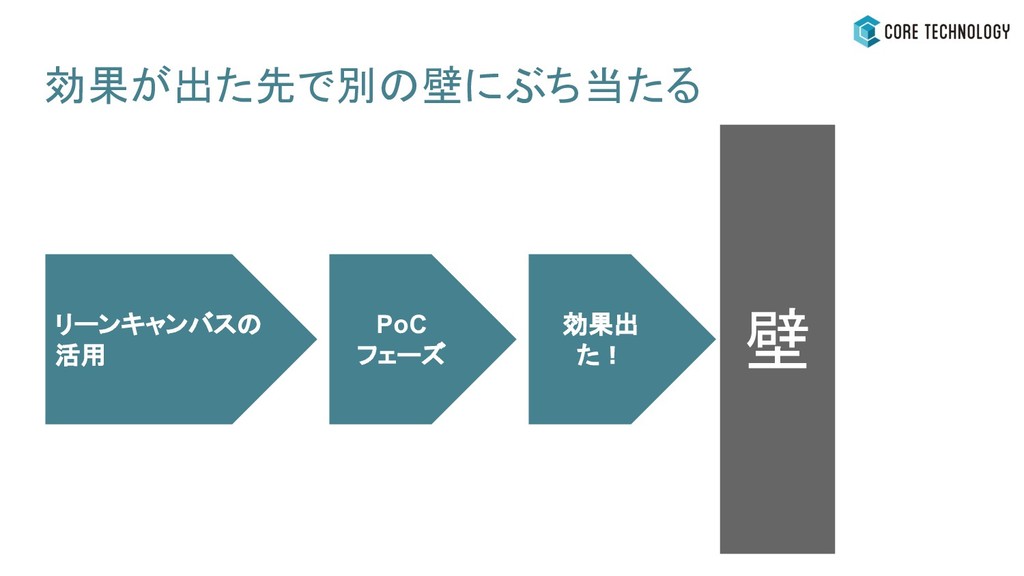
リーンキャンバスの 活用 PoC フェーズ 効果出 た!
リーンキャンバスの 活用 PoC フェーズ 効果出 た! 効果が出た先で別の壁にぶち当たる 壁
- 障害発生時のレポートフローの整備 - 障害発生時の切り戻し方 - 誰が対応するか - 休日対応するかどうか PoCフェーズと実運用フェーズの間の壁 -
効果検証ができること 効果観点 - Fail Safeであること(安全に切り戻せるか) - 社内で定められたセキュリティーは担保されているか - Alerting, Monitoringはきちんと行われているか システム観点 運用観点
- 障害発生時のレポートフローの整備 - 障害発生時の切り戻し方 - 誰が対応するか - 休日対応するかどうか PoCフェーズと実運用フェーズの間の壁 -
効果検証ができること 効果観点 - Fail Safeであること(安全に切り戻せるか) - 社内で定められたセキュリティーは担保されているか - Alerting, Monitoringはきちんと行われているか システム観点 運用観点 PoCと比較してシステム/運用観点が多く発生
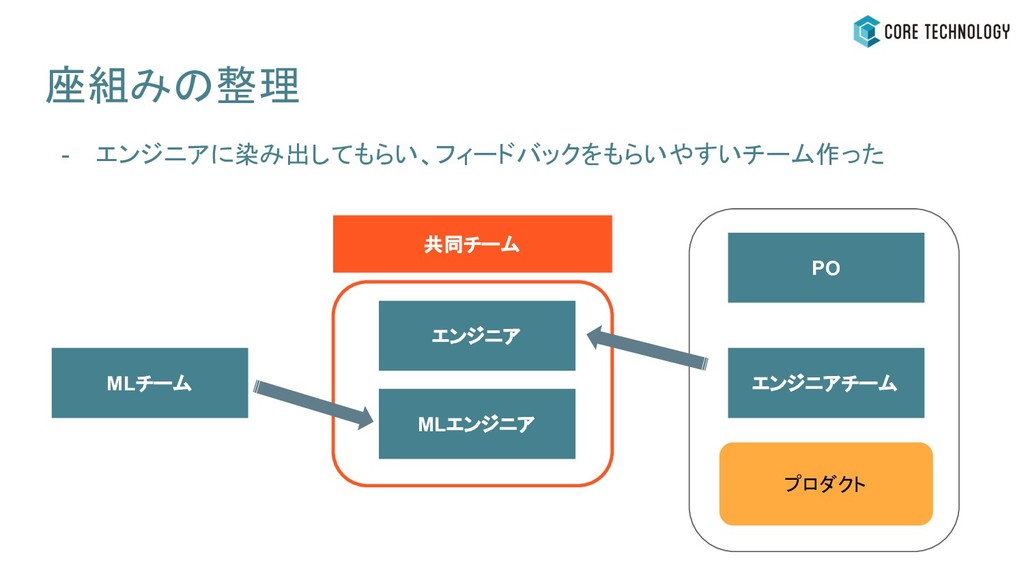
座組みの整理 - エンジニアに染み出してもらい、フィードバックをもらいやすいチーム作った MLチーム エンジニアチーム PO プロダクト エンジニア MLエンジニア 共同チーム
連携試験を実施してもらう API わたし エンジニア
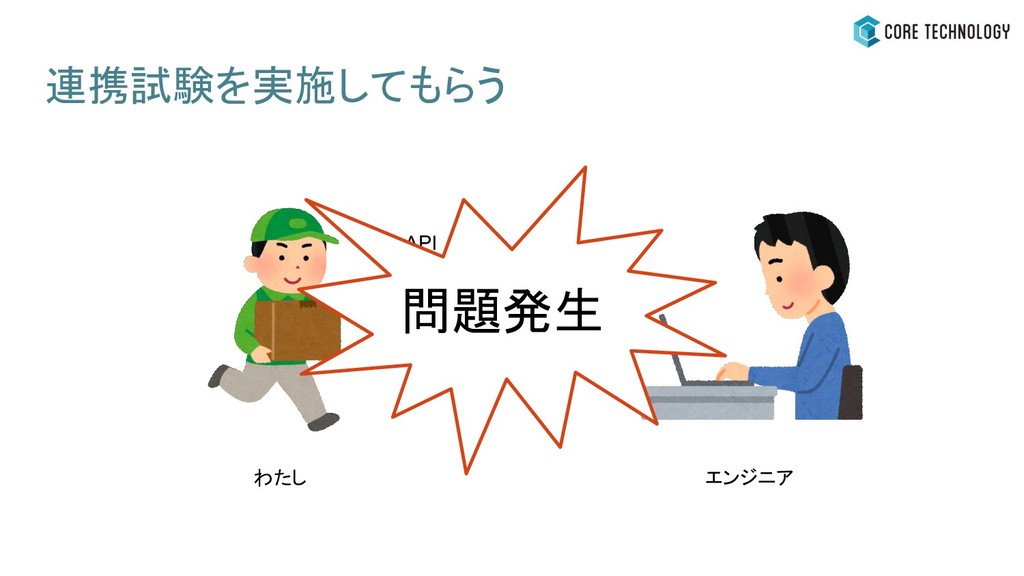
連携試験を実施してもらう API わたし エンジニア 問題発生
問題発生 - 連携試験ができなかった - 「エラー起きたけど、これってなんでエラーなんですか?」
問題発生 - 連携試験ができなかった - 「エラー起きたけど、これってなんでエラーなんですか?」 エンジニアの思うFail Safeと、MLエンジニアの思うFail Safeが違う
Fail Safeの認識の違い - エンジニア - エラー発生時のこけ方が色々 (4xx, 5xx, エラーオブジェクトの活用) -
MLエンジニア - こけ方が一つしかない
「Fail Safeであれば良い」が呪いに - 障害発生時のレポートフローの整備 - 障害発生時の切り戻し方 - 誰が対応するか - 休日対応するかどうか
- 効果検証ができること 効果観点 - Fail Safeであること(安全に切り戻せるか) - 社内で定められたセキュリティーは担保されているか - Alerting, Monitoringはきちんと行われているか システム観点 運用観点
こけかたを学ぶ必要が出てくる - 知識獲得 - エンジニアからテストについて学ぶ - 勧められた本をきちんと読む - 知識活用 -
Decision Tableを用いてテスト作成 - それをエンジニアにフィードバックをもらいながら修正 - 重要なこと - ある程度リテラシーを揃えた上で会話を行うことで議論がスムーズになるため、テ ストに関してソフトウェア工学一般の知識を身につけること - エンジニアとのより密なコミュニケーション
より密なチームに MLチーム エンジニアチーム PO プロダクト エンジニア MLエンジニア 共同チーム
リリースできた
MLエンジニアが価値を発揮するためには - スキルの獲得 - 統計機械学習の知識 - テストに関するソフトウェア工学一般の知識 - 説明責任と相手を納得させる能力 -
リーンキャンバスの活用 - Problem-Solution Fitをしっかり - How寄りの施策は他者が動いてくれない - 組織構造の見直し - 機械学習組織ははみ出しがち - エンジニアと密なコミュニケーションでフィードバックをもらえる座組みに
- ML APIをGKEに構築 - 対話型検索による新たな UXの提供 - CRFと情報エントロピーを活用したユーザーの嗜好の推定 - MLエンジニアが価値を発揮するには
- スキルの獲得 - テストに関するソフトウェア工学一般の知識 - Problem-Solution Fitをしっかり - 組織構造の見直し - エンジニアと密なコミュニケーションでフィードバックをもらえる座組みに まとめ
- Embeddingとか活用してみたい - 「MLエンジニアが最大限価値を発揮するためには」、「会社としてMLエンジニアを最大 限活かすためには」、これらのテーマについていろんな方の情報を聞いて整理したい Future Works
- Embeddingとか活用してみたい - 「MLエンジニアが最大限価値を発揮するためには」、「会社としてMLエンジニアを最大 限活かすためには」、これらのテーマについていろんな方の情報を聞いて整理したい Future Works この後の時間でぜひ意見交換、議論させてください!!
We Are Hiring !! リクルートジョブズ コアテクノロジーグループでは、 - データエンジニア - MLエンジニア を募集しています!
ご興味のある方はリクルートジョブズのサイトへいらしてください。
![タウンワークにおける機械学 習API@GKEの導入 リクルートジョブズ 商品本部 データマネジメント部 コアテクノロジーグループ 北原 康佑 (@KosukeKitahara) [email protected]](https://files.speakerdeck.com/presentations/a359355c4493490bb6f6707c339dfd0c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}