and good performance • No disk IO • Pipelined execution (not Map Reduce) • Compile a query plan down to byte code • Off heap memory • Suitable for ad-hoc query
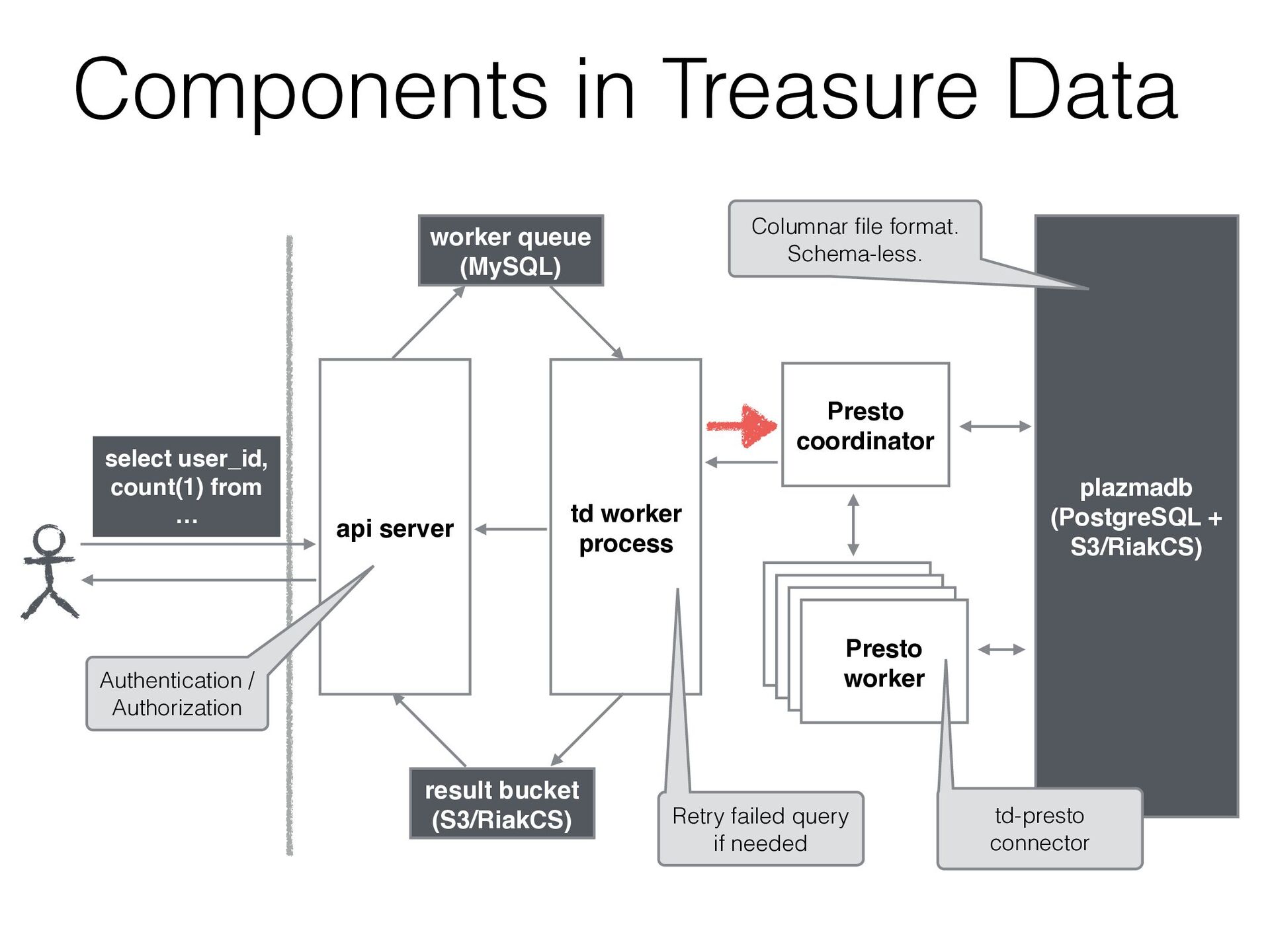
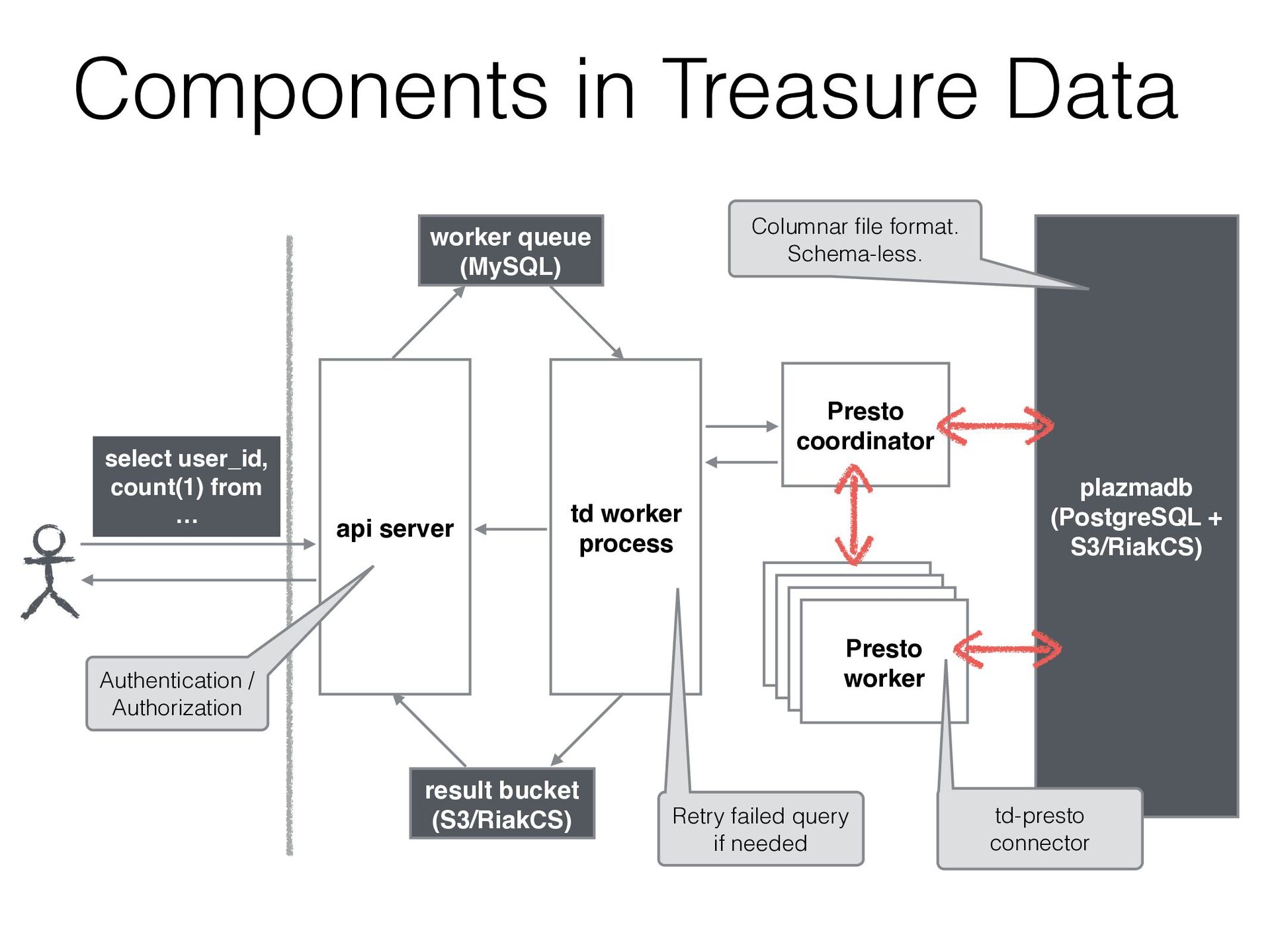
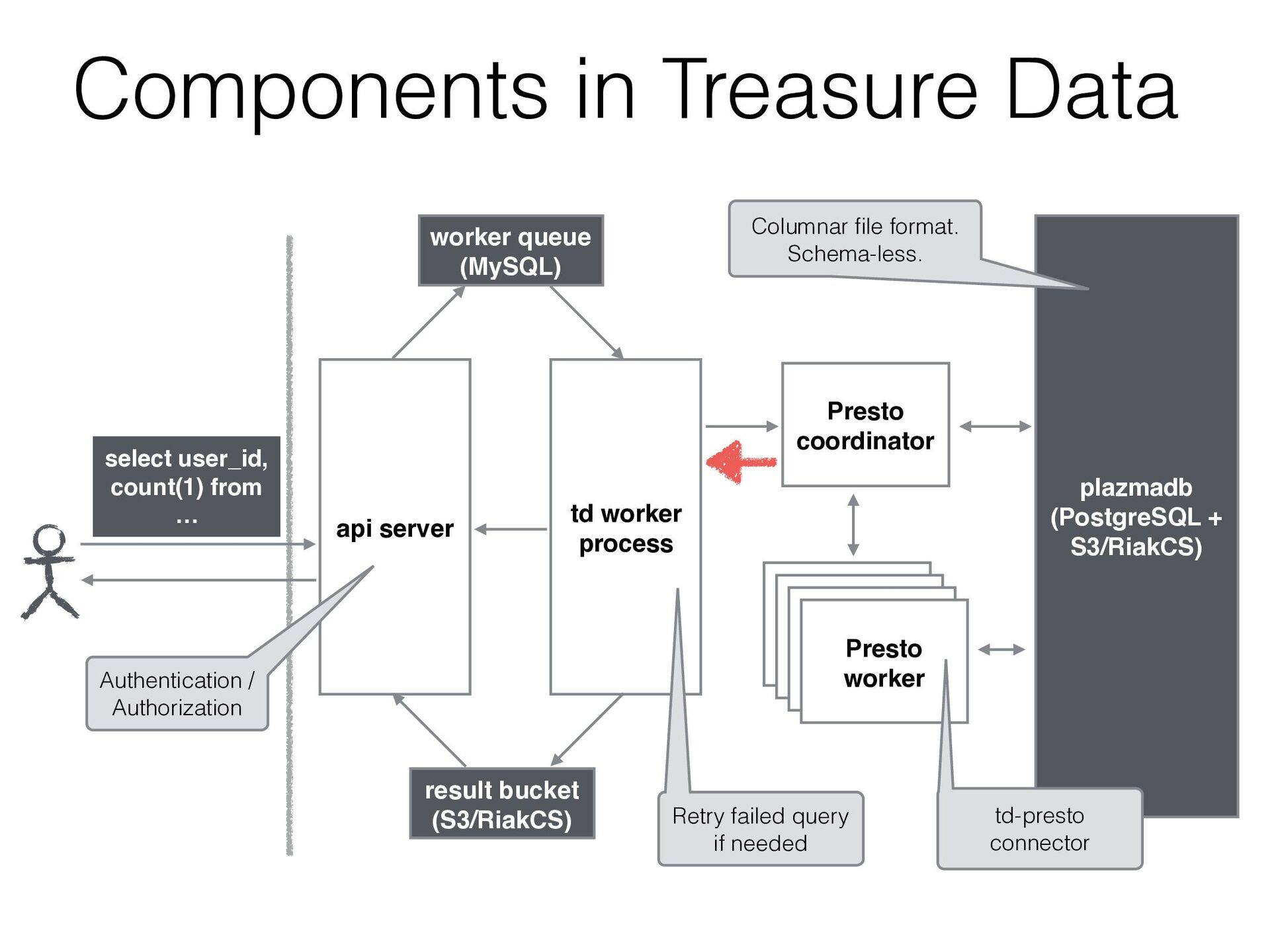
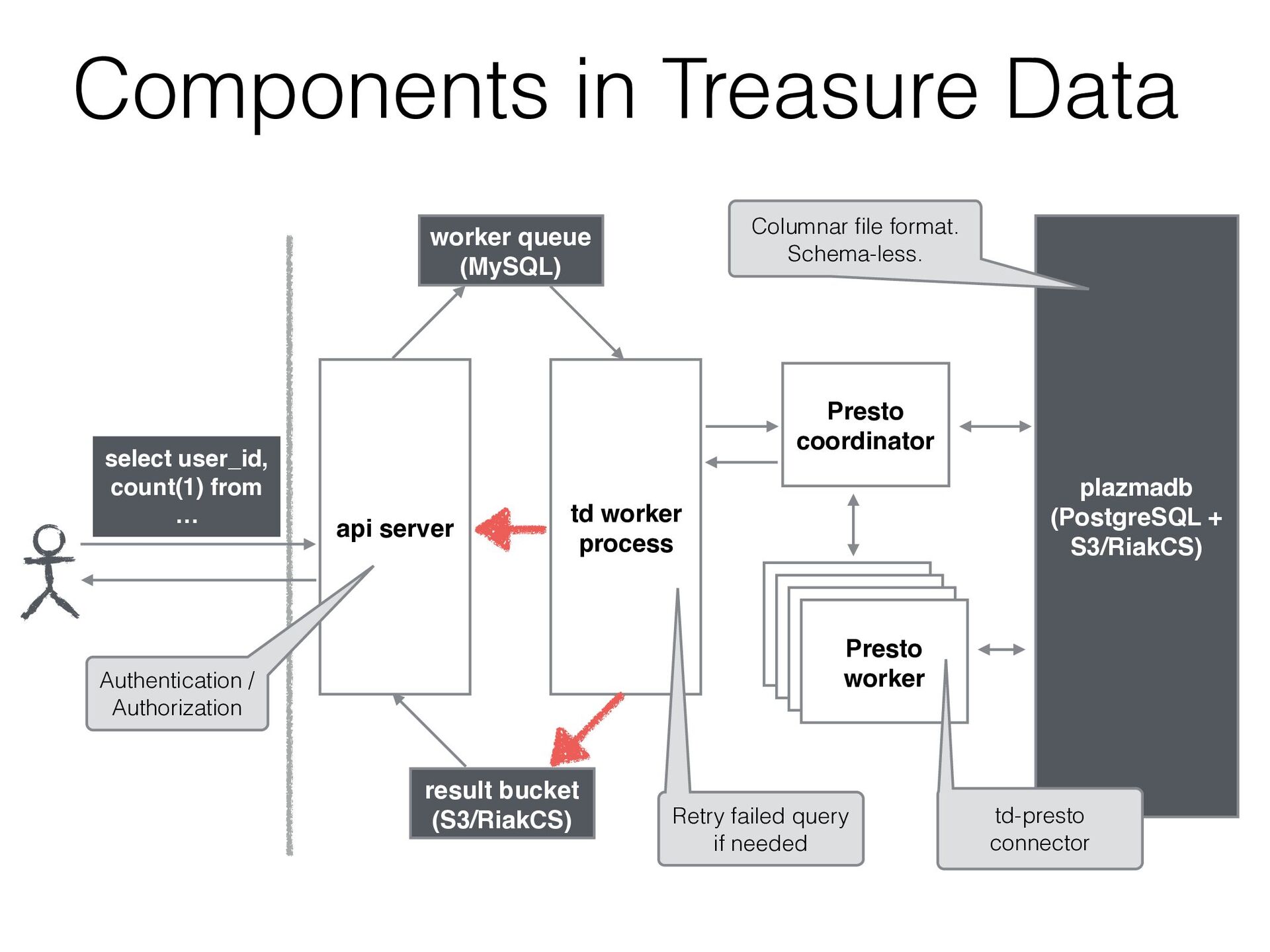
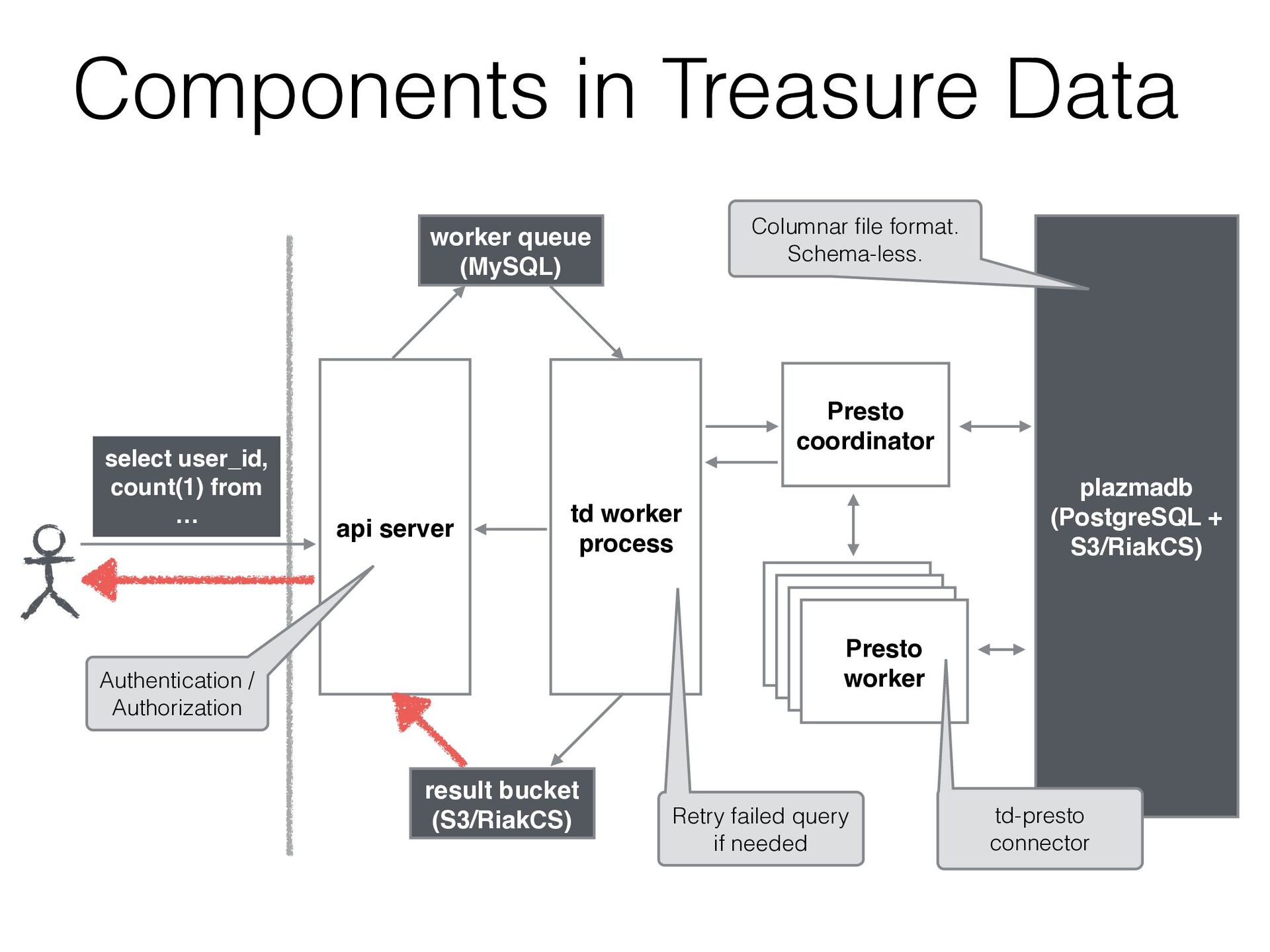
JMX / Kafka / MySQL / PostgreSQL / System / TPCH • We can add a new connector by extending SPI • Treasure Data has been developed a connector to access our storage
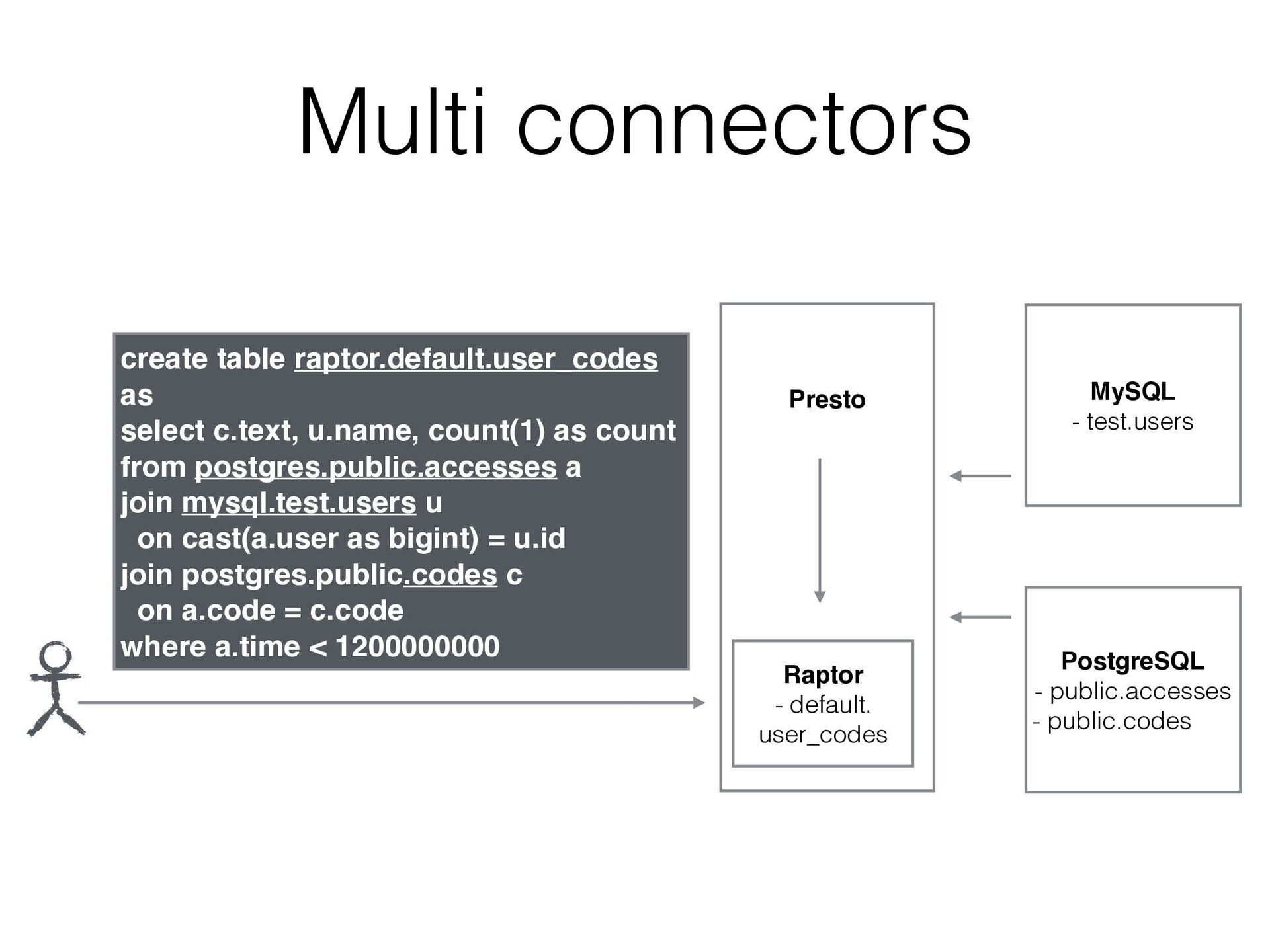
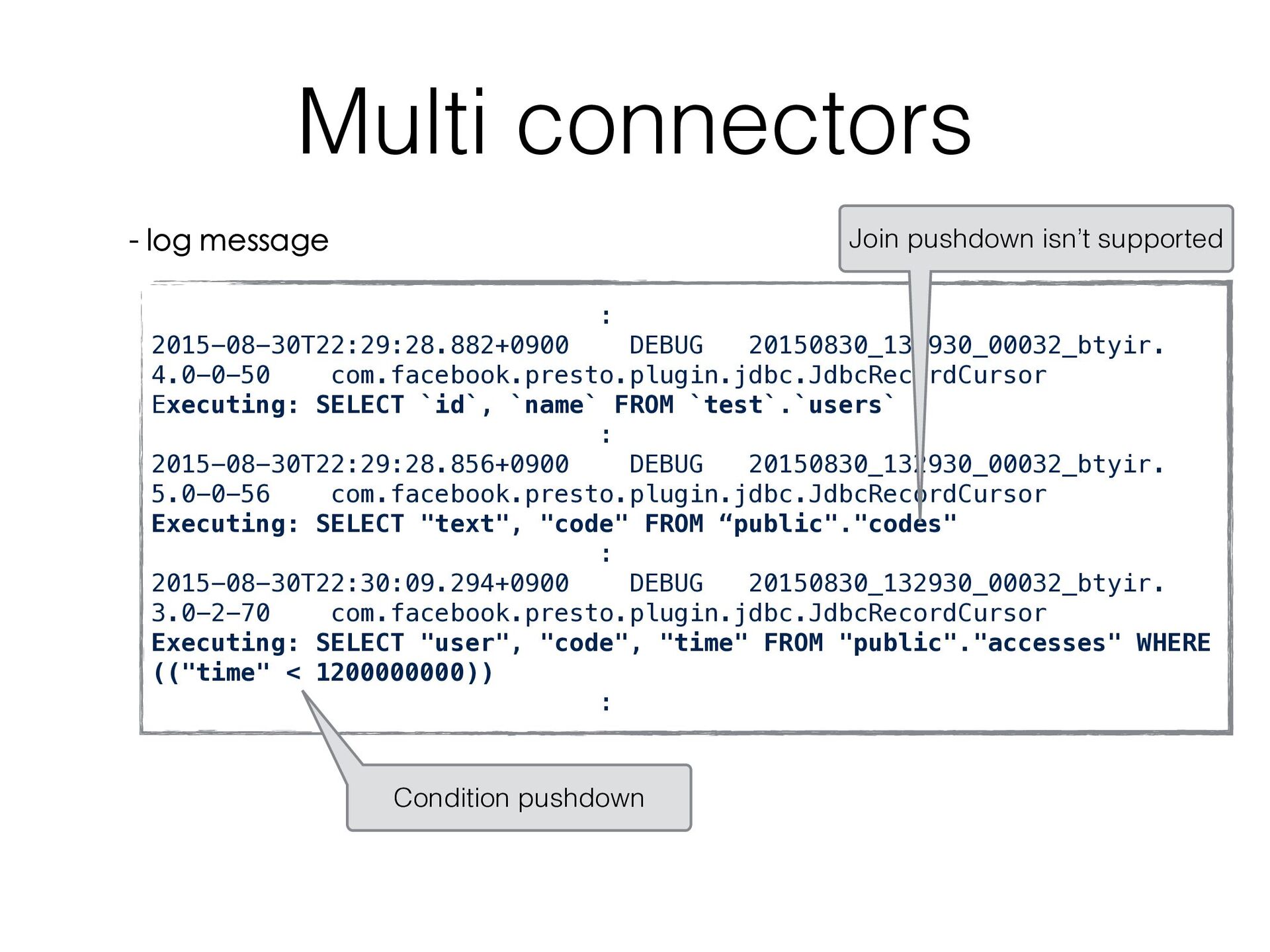
public.codes Raptor - default. user_codes create table raptor.default.user_codes as select c.text, u.name, count(1) as count from postgres.public.accesses a join mysql.test.users u on cast(a.user as bigint) = u.id join postgres.public.codes c on a.code = c.code where a.time < 1200000000
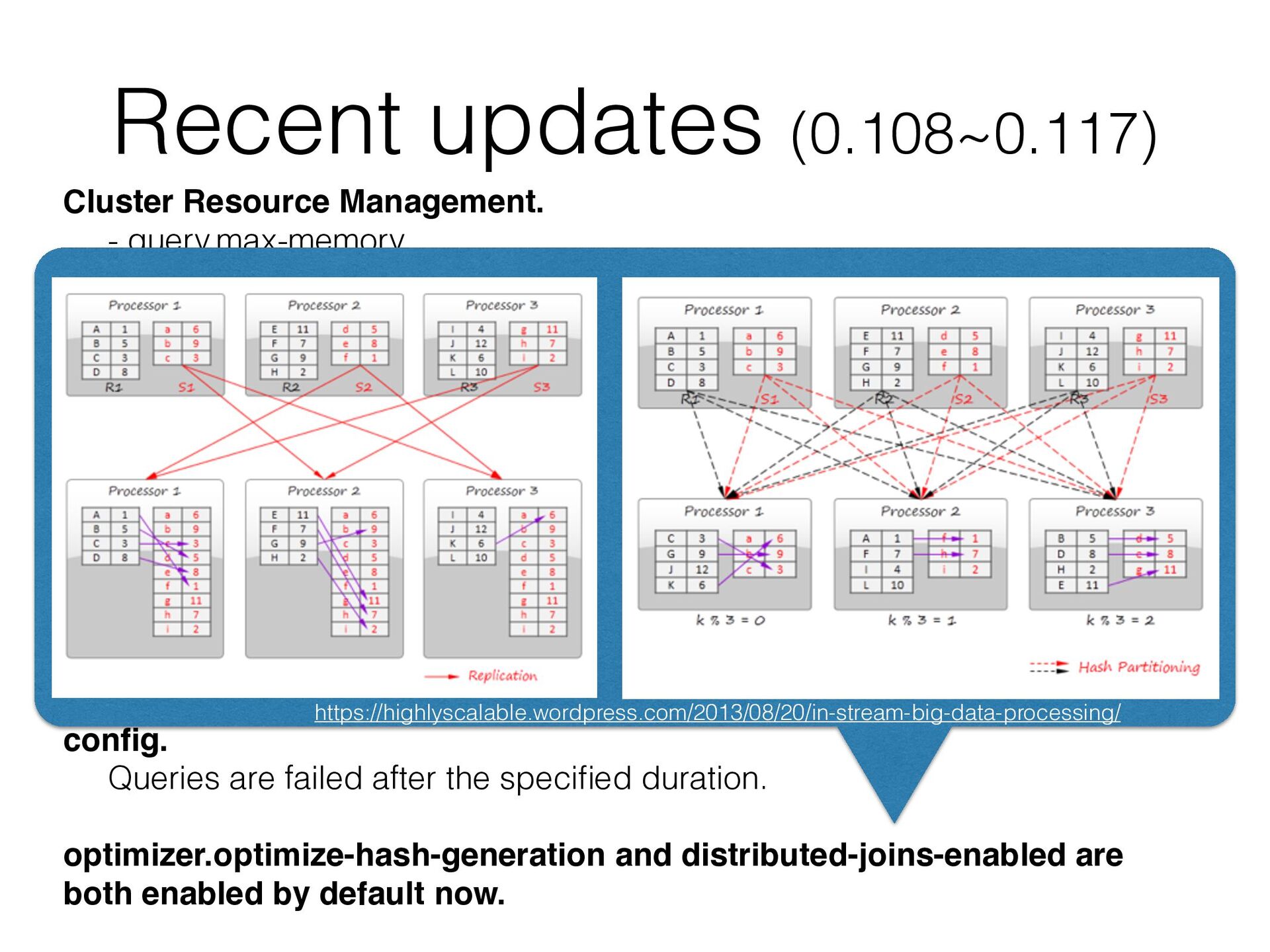
- resources.reserved-system-memory “Big Query” option was removed Semi-joins are hash-partitioned if distributed_join is turned on. Add support for partial cast from JSON. For example, json can be cast to array<json>, map<varchar, json>, etc. Use JSON_PARSE() and JSON_FORMAT() instead of CAST Add query_max_run_time session property and query.max-run-time config. Queries are failed after the specified duration. optimizer.optimize-hash-generation and distributed-joins-enabled are both enabled by default now.
- resources.reserved-system-memory “Big Query” option was removed Semi-joins are hash-partitioned if distributed_join is turned on. Add support for partial cast from JSON. For example, json can be cast to array<json>, map<varchar, json>, etc. Use JSON_PARSE() and JSON_FORMAT() instead of CAST Add query_max_run_time session property and query.max-run-time config. Queries are failed after the specified duration. optimizer.optimize-hash-generation and distributed-joins-enabled are both enabled by default now. https://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/
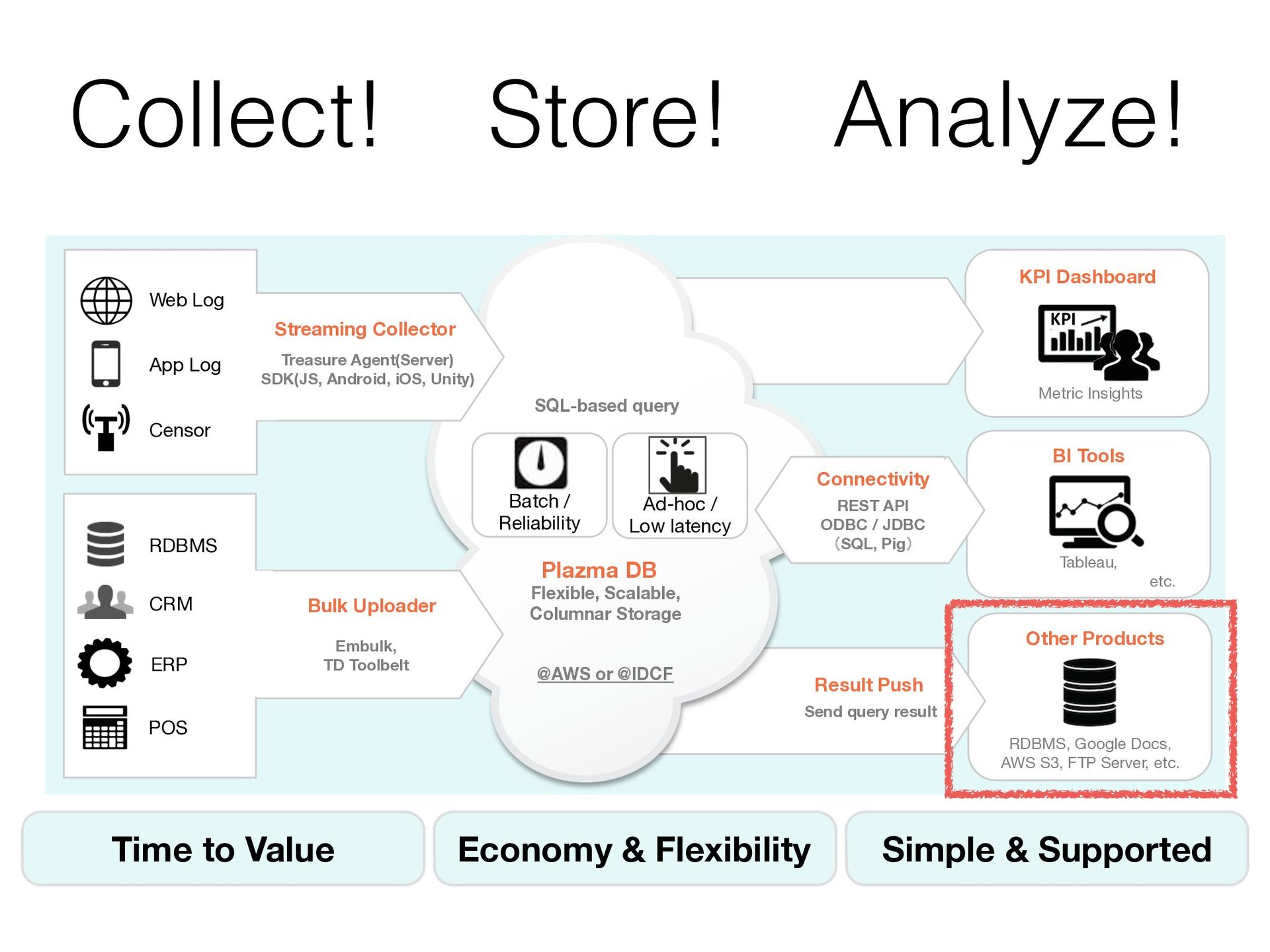
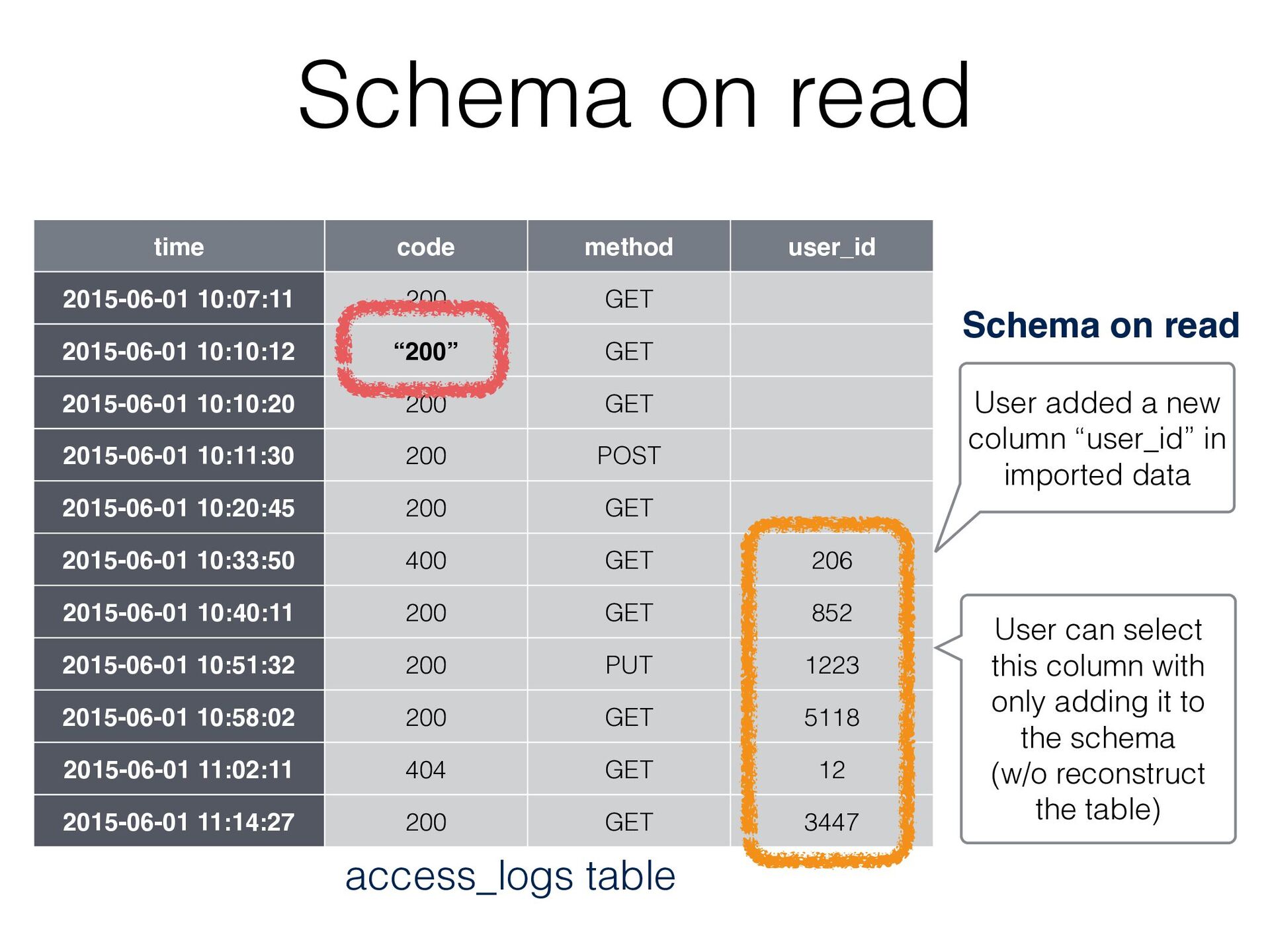
GET 2015-06-01 10:10:12 “200” GET 2015-06-01 10:10:20 200 GET 2015-06-01 10:11:30 200 POST 2015-06-01 10:20:45 200 GET 2015-06-01 10:33:50 400 GET 206 2015-06-01 10:40:11 200 GET 852 2015-06-01 10:51:32 200 PUT 1223 2015-06-01 10:58:02 200 GET 5118 2015-06-01 11:02:11 404 GET 12 2015-06-01 11:14:27 200 GET 3447 access_logs table User added a new column “user_id” in imported data User can select this column with only adding it to the schema (w/o reconstruct the table) Schema on read
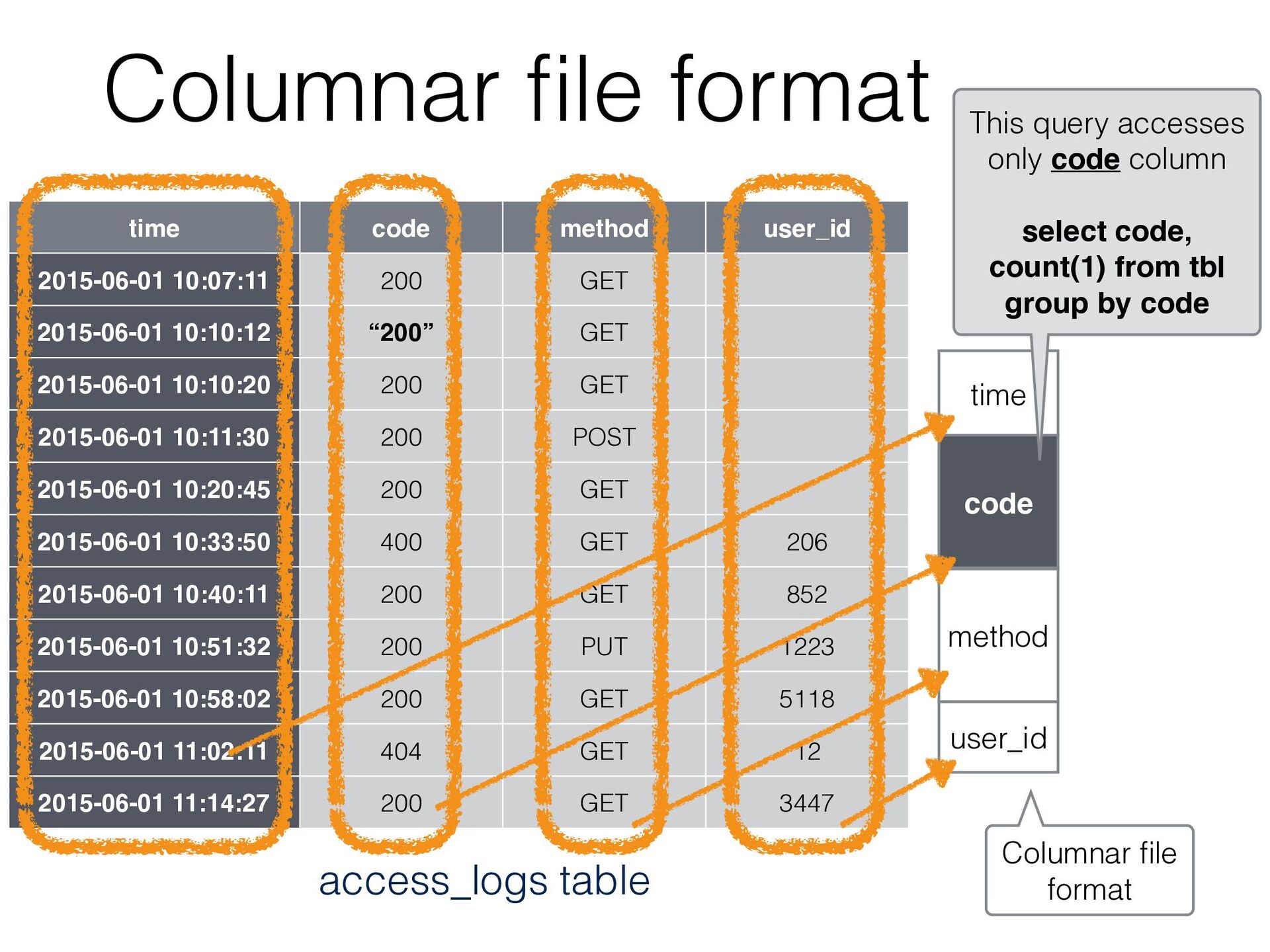
GET 2015-06-01 10:10:12 “200” GET 2015-06-01 10:10:20 200 GET 2015-06-01 10:11:30 200 POST 2015-06-01 10:20:45 200 GET 2015-06-01 10:33:50 400 GET 206 2015-06-01 10:40:11 200 GET 852 2015-06-01 10:51:32 200 PUT 1223 2015-06-01 10:58:02 200 GET 5118 2015-06-01 11:02:11 404 GET 12 2015-06-01 11:14:27 200 GET 3447 access_logs table time code method user_id Columnar file format This query accesses only code column select code, count(1) from tbl group by code
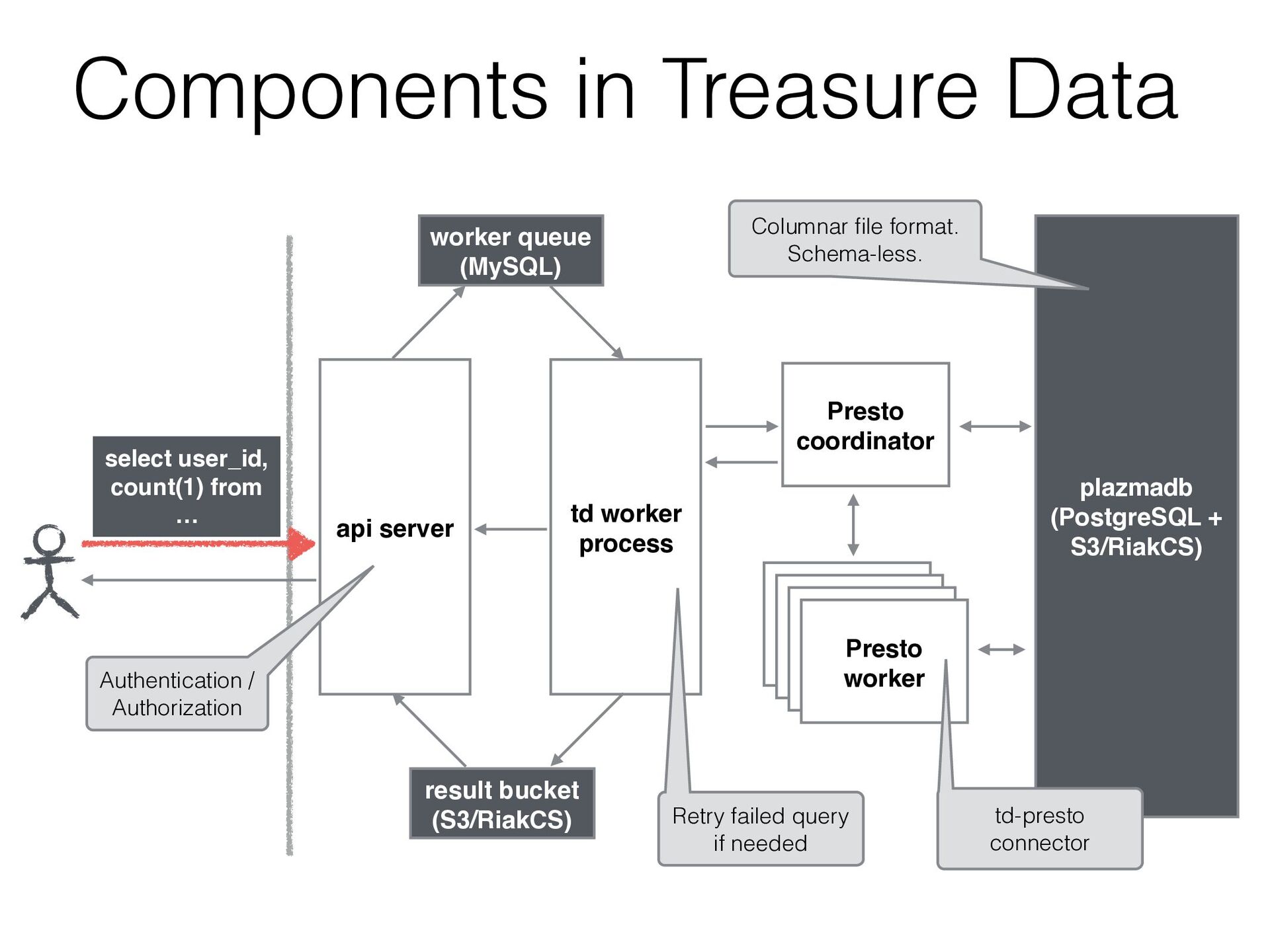
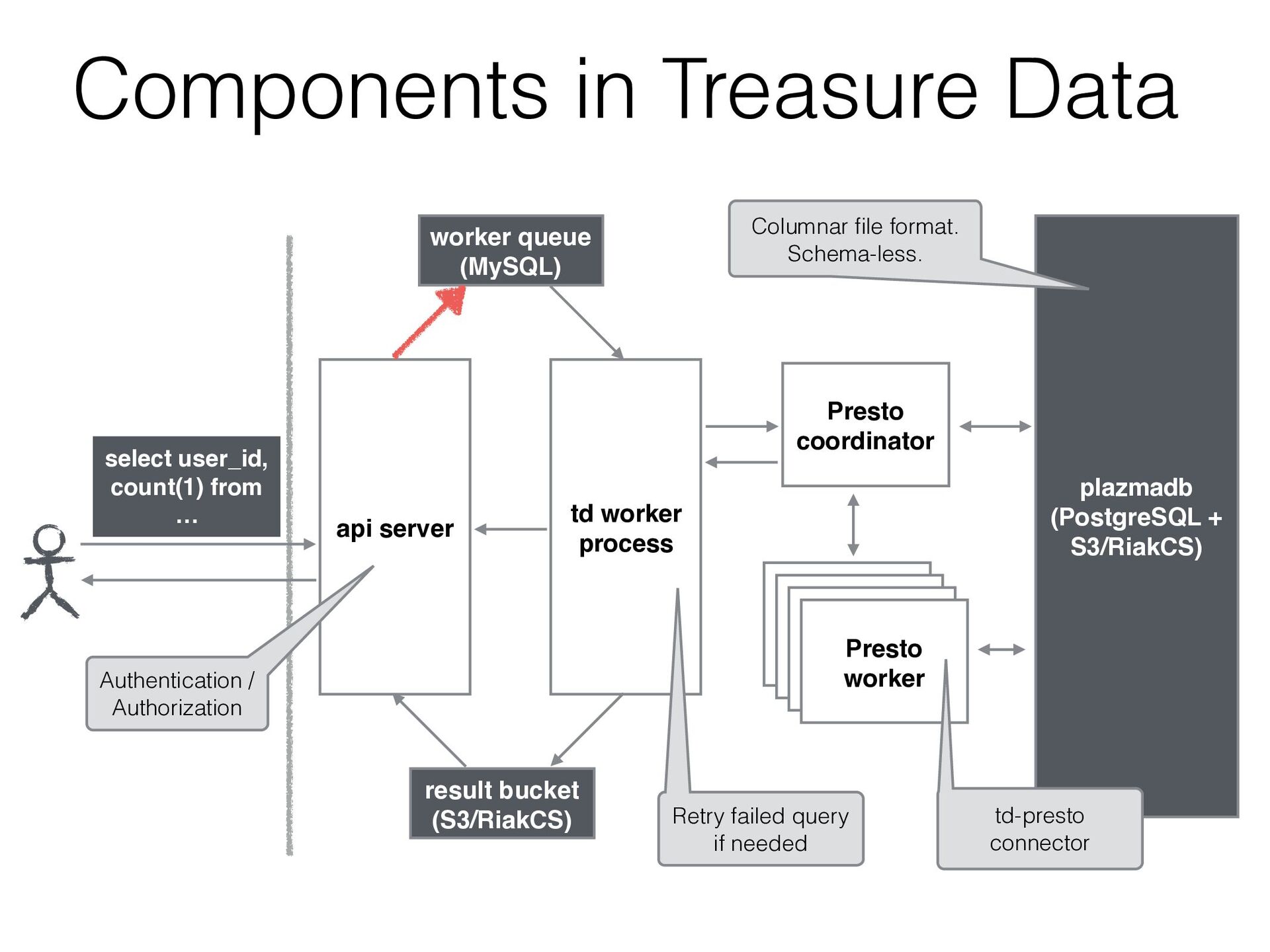
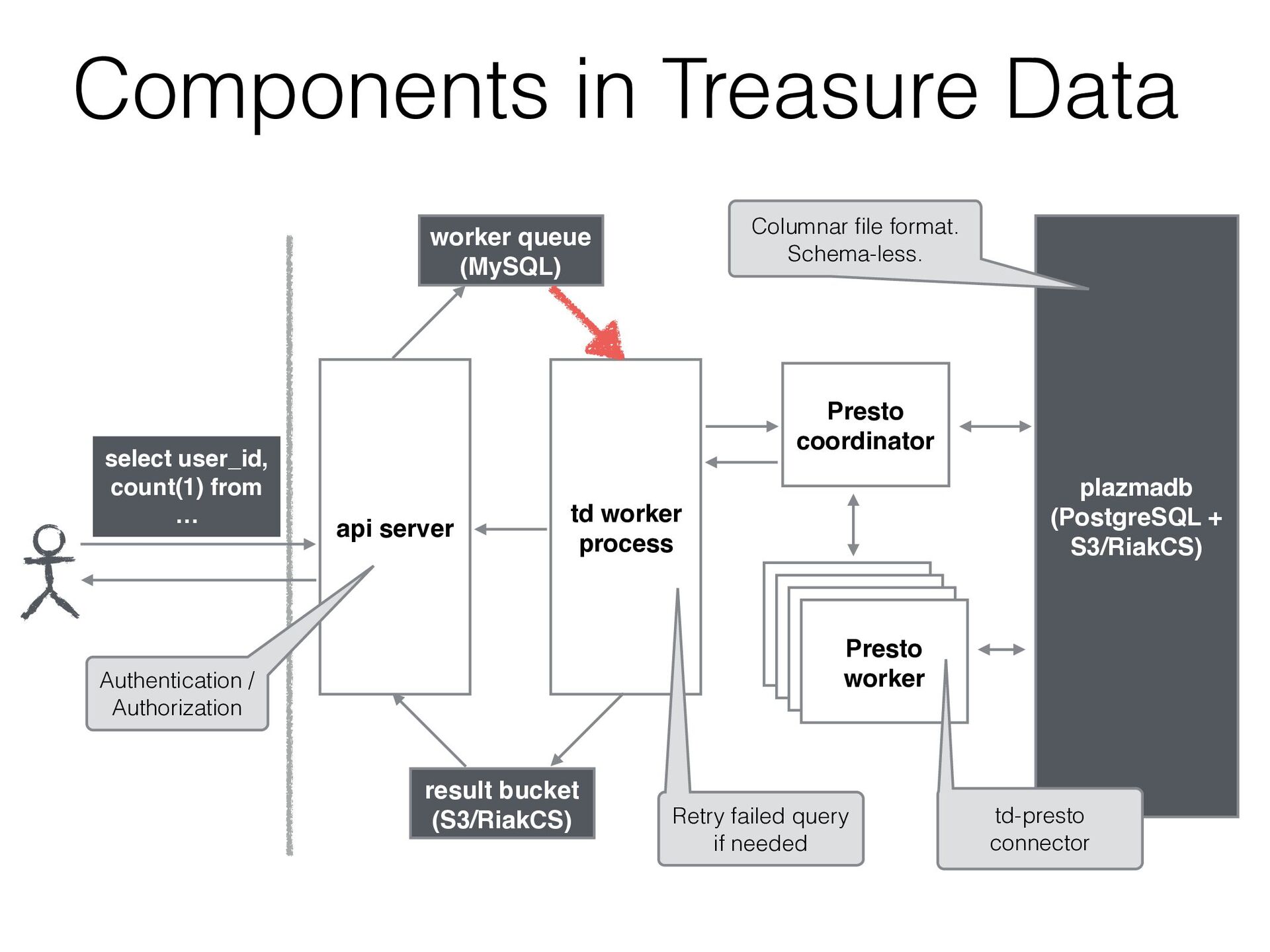
issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
{kind=link}
{kind=link}
{kind=link}
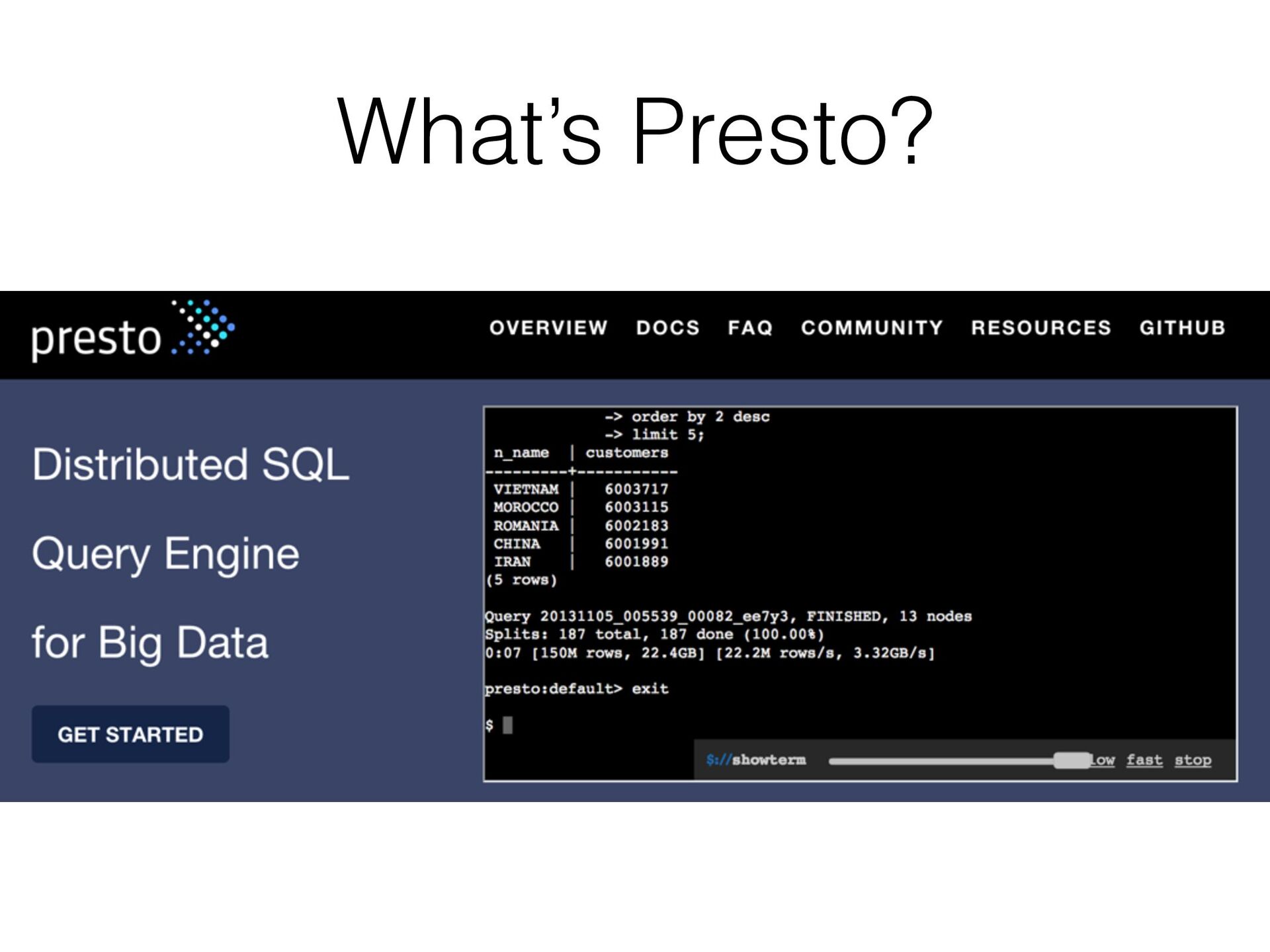{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
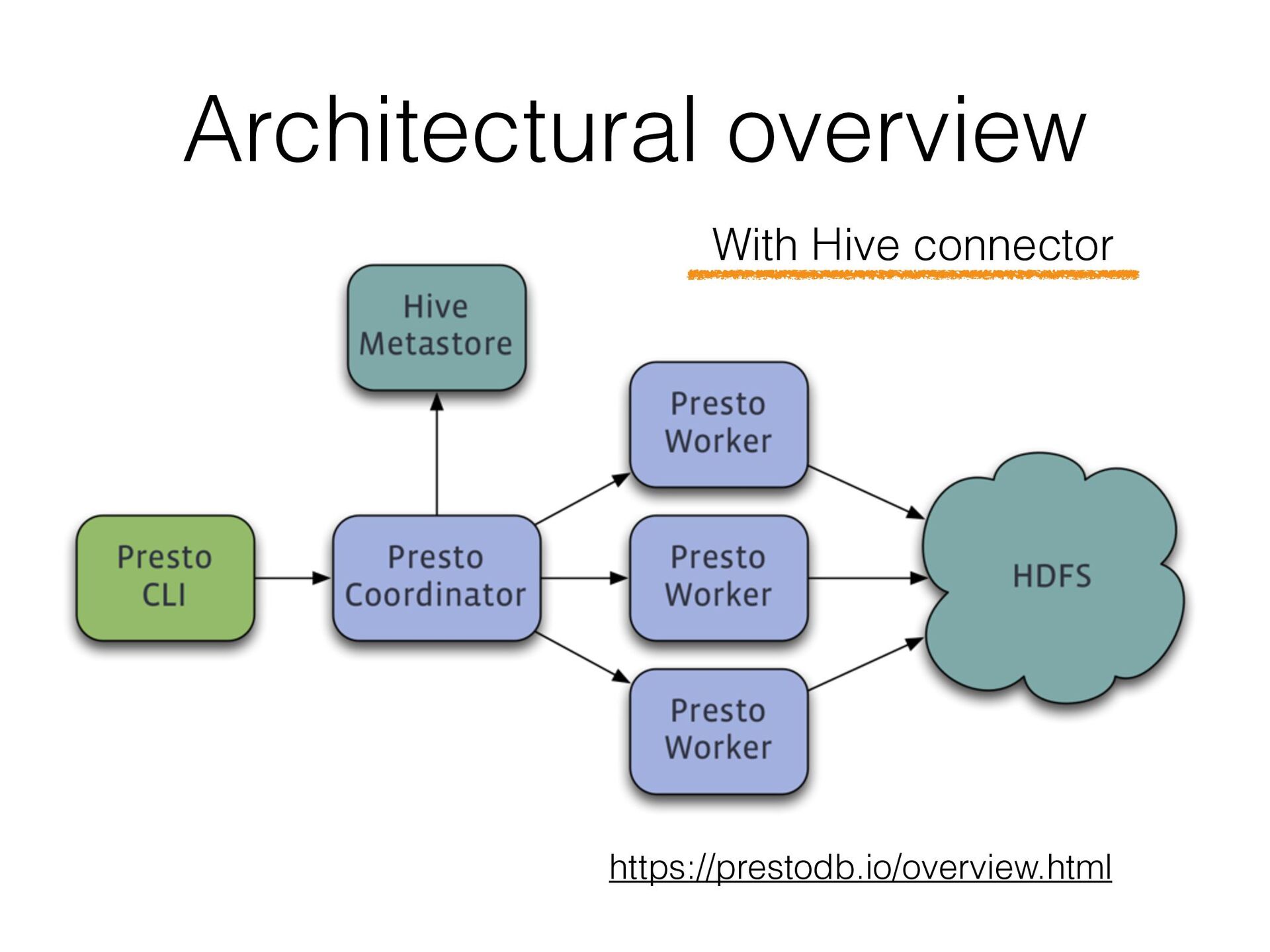{kind=link}
![Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 :=](https://files.speakerdeck.com/presentations/7e5c0590f055403d89590bee2fea4f91/slide_10.jpg){kind=link}
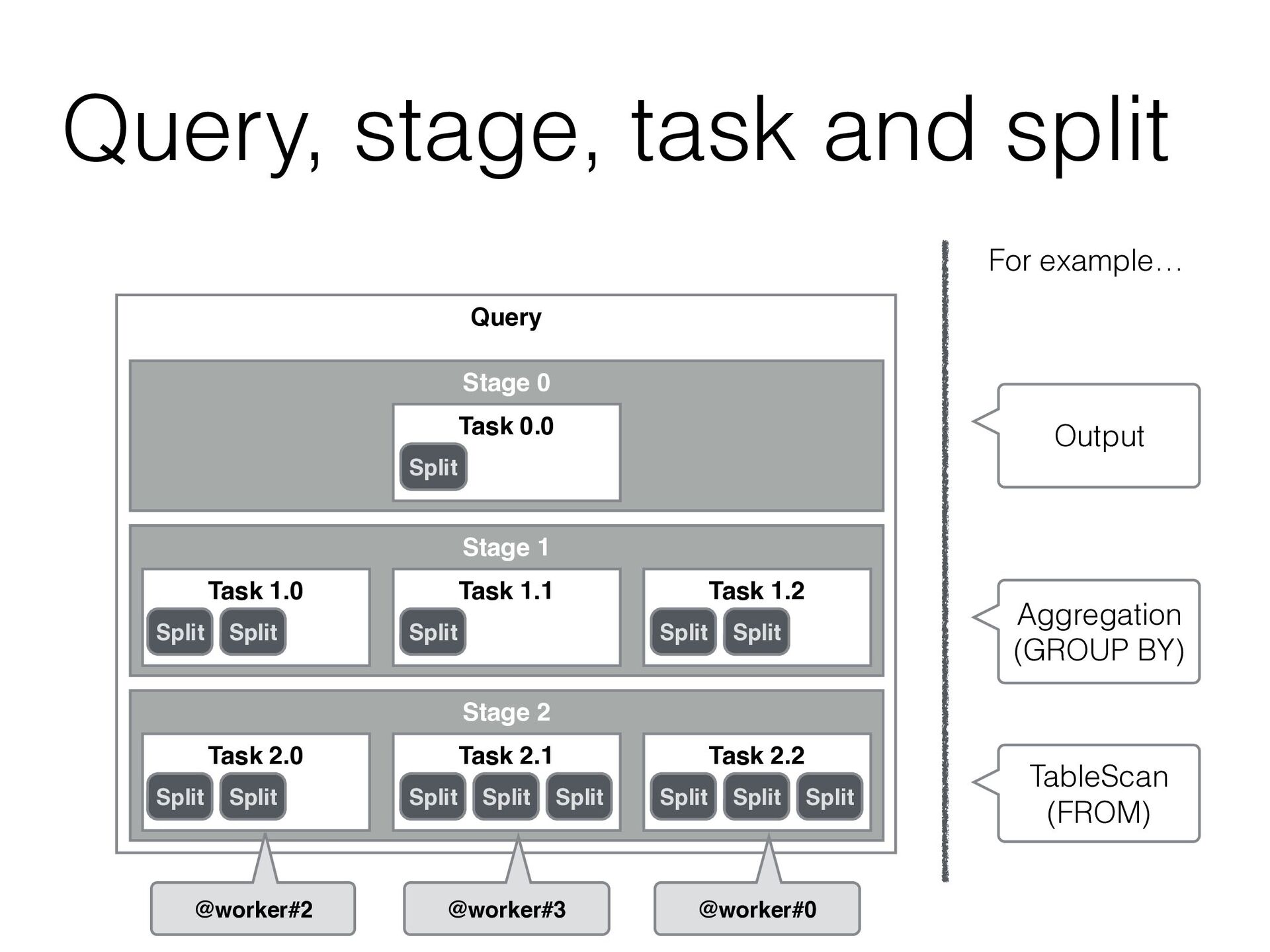{kind=link}
![Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 :=](https://files.speakerdeck.com/presentations/7e5c0590f055403d89590bee2fea4f91/slide_12.jpg){kind=link}
![Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 :=](https://files.speakerdeck.com/presentations/7e5c0590f055403d89590bee2fea4f91/slide_13.jpg){kind=link}
![Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 :=](https://files.speakerdeck.com/presentations/7e5c0590f055403d89590bee2fea4f91/slide_14.jpg){kind=link}
![Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 :=](https://files.speakerdeck.com/presentations/7e5c0590f055403d89590bee2fea4f91/slide_15.jpg){kind=link}
![Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 :=](https://files.speakerdeck.com/presentations/7e5c0590f055403d89590bee2fea4f91/slide_16.jpg){kind=link}
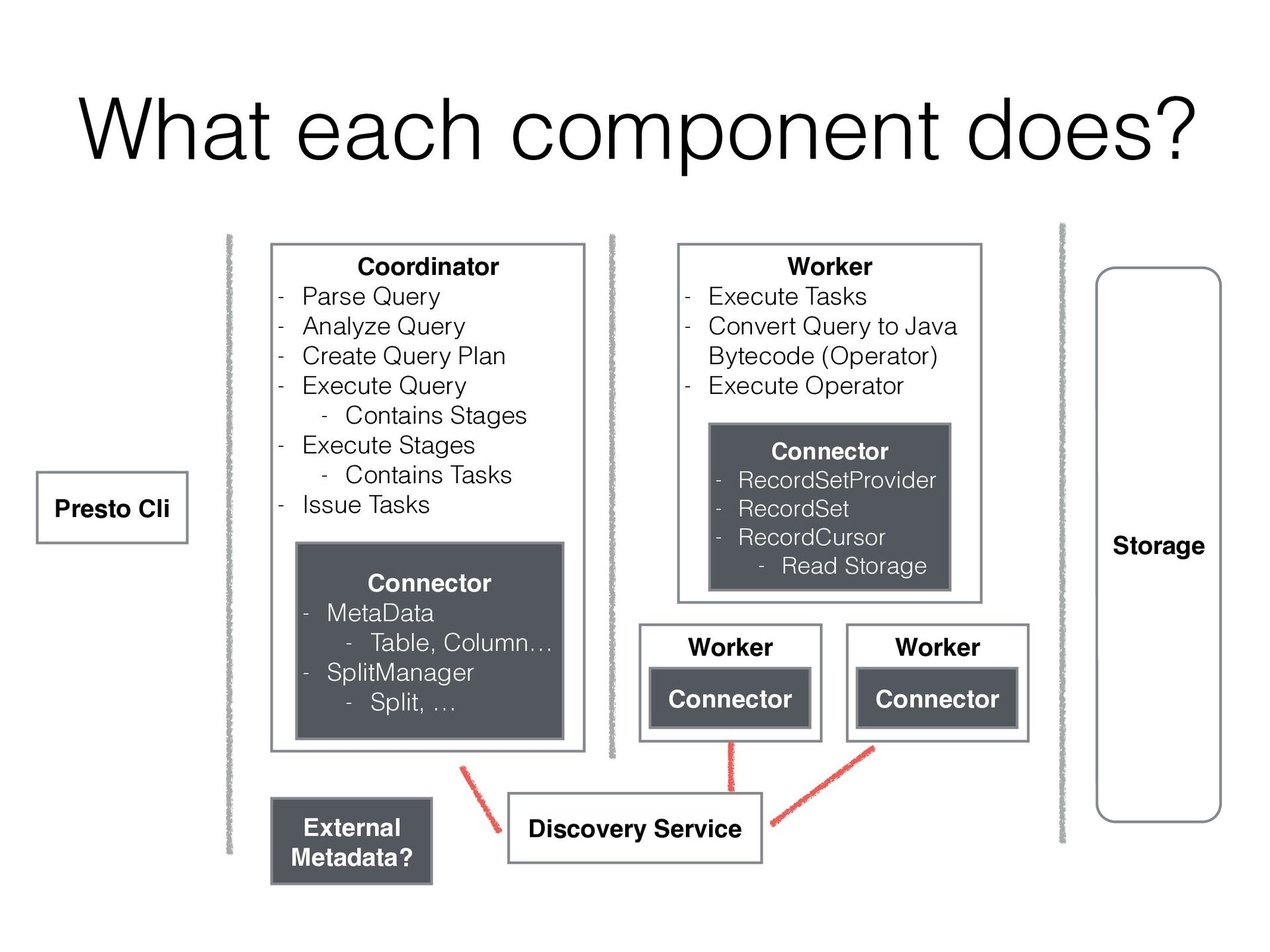{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
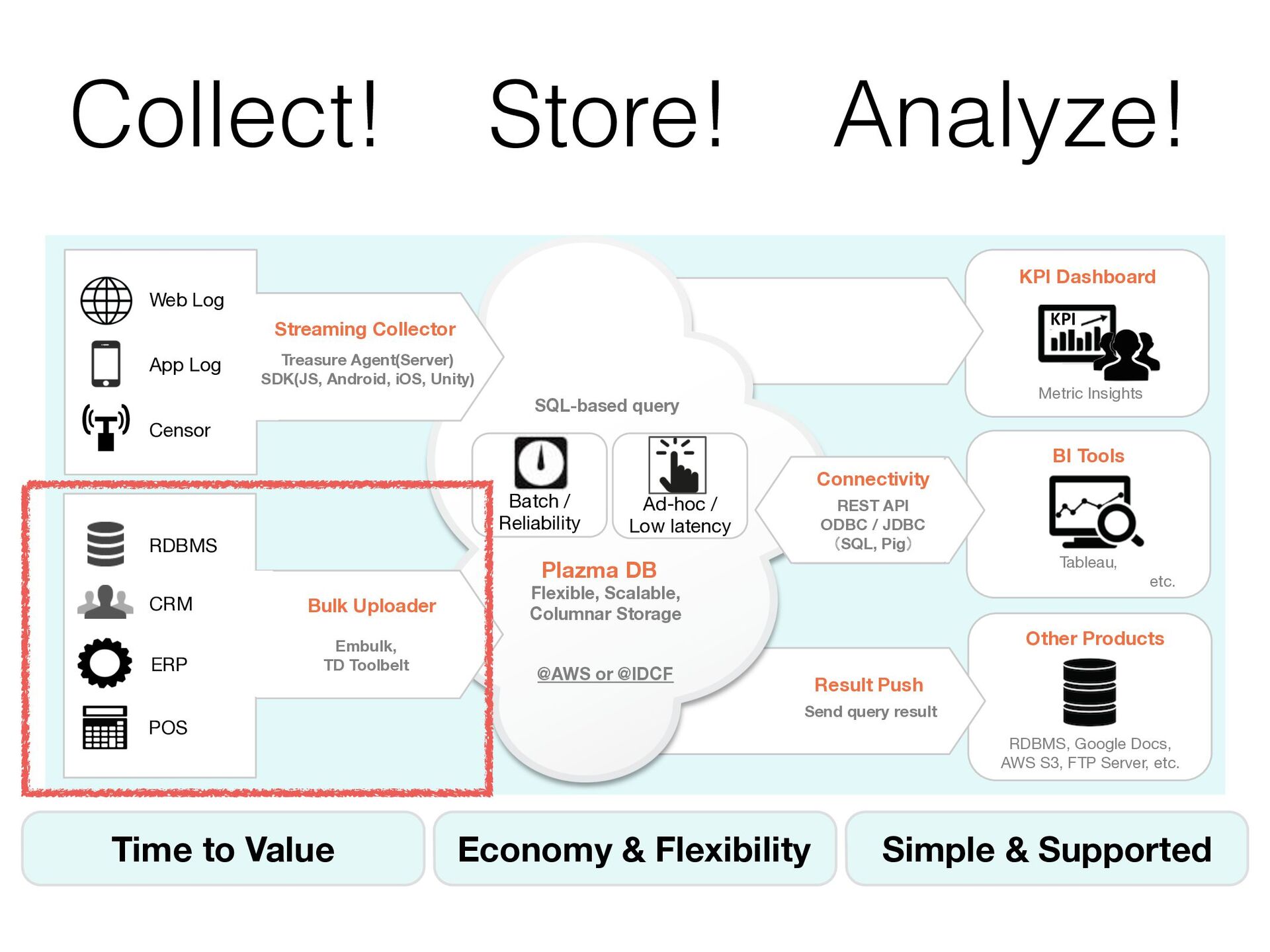{kind=link}
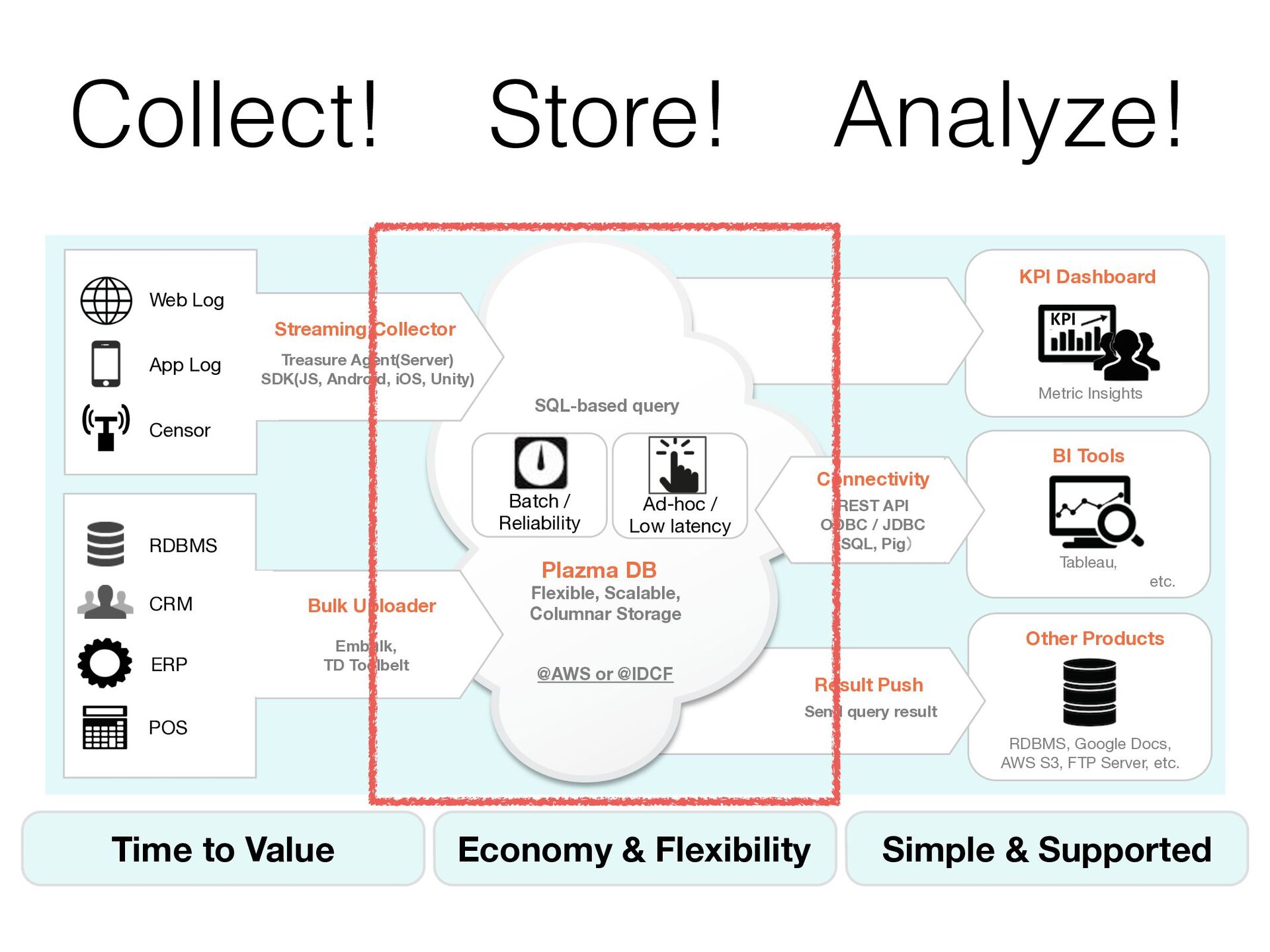{kind=link}
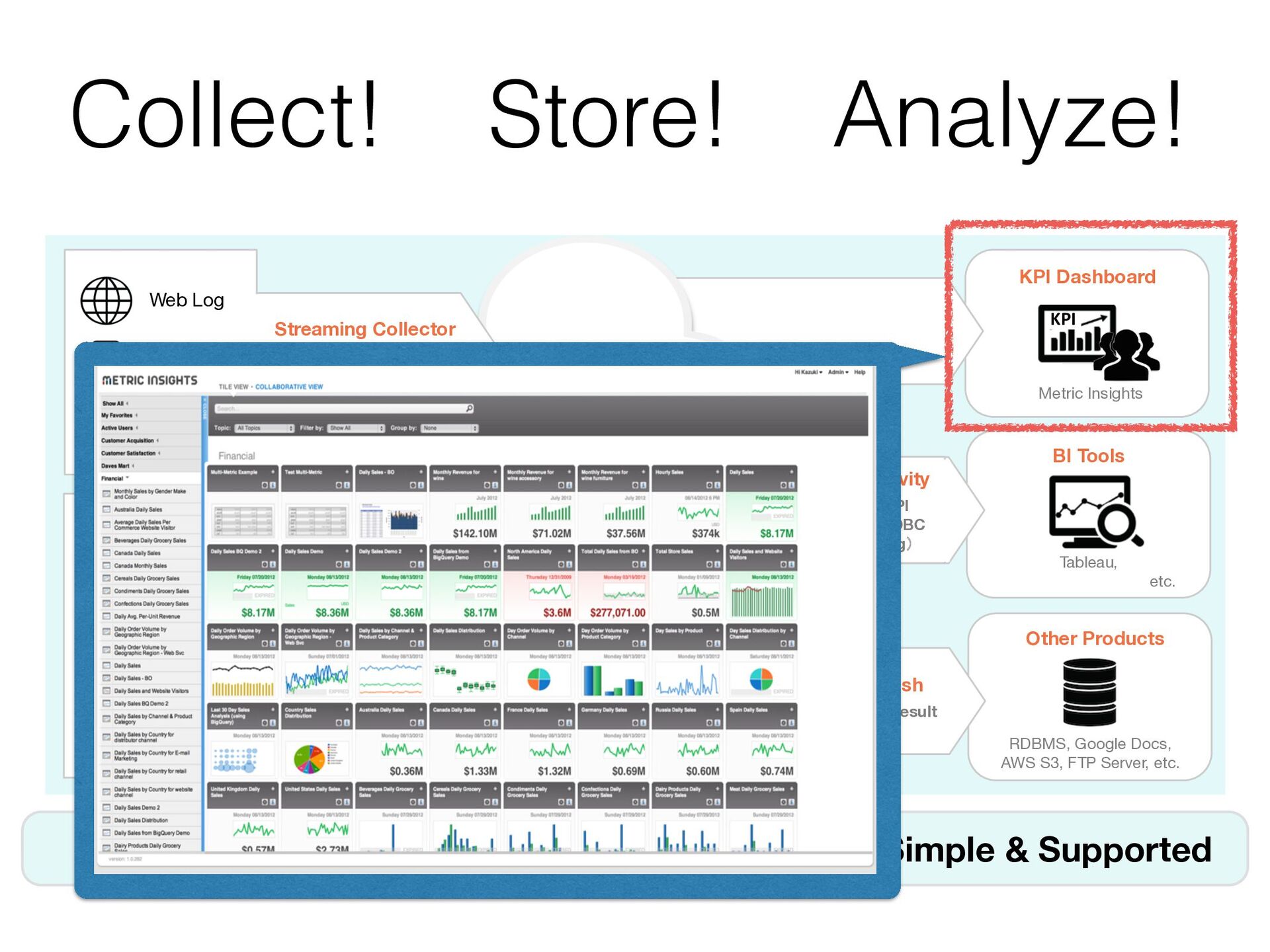{kind=link}
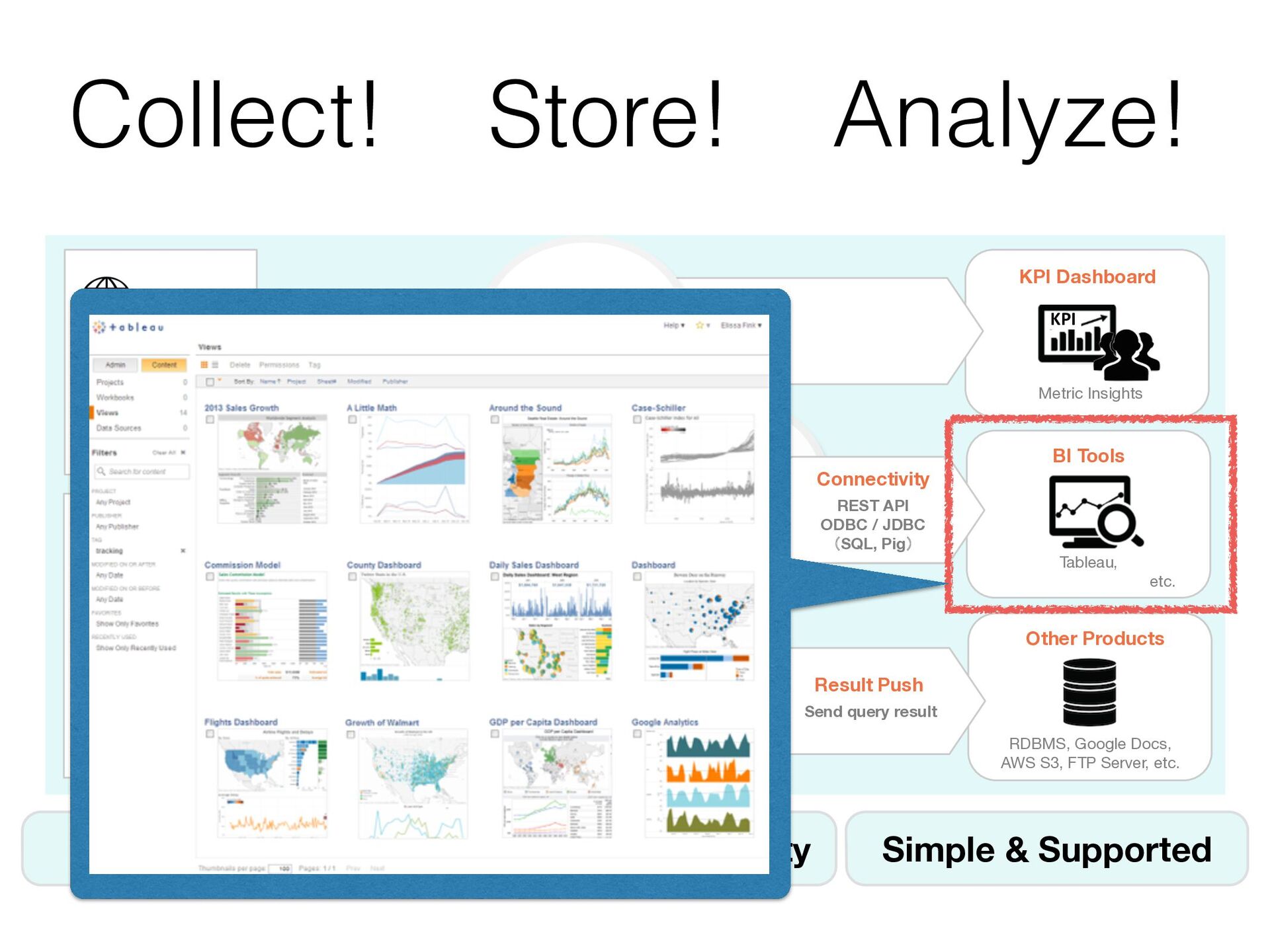{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
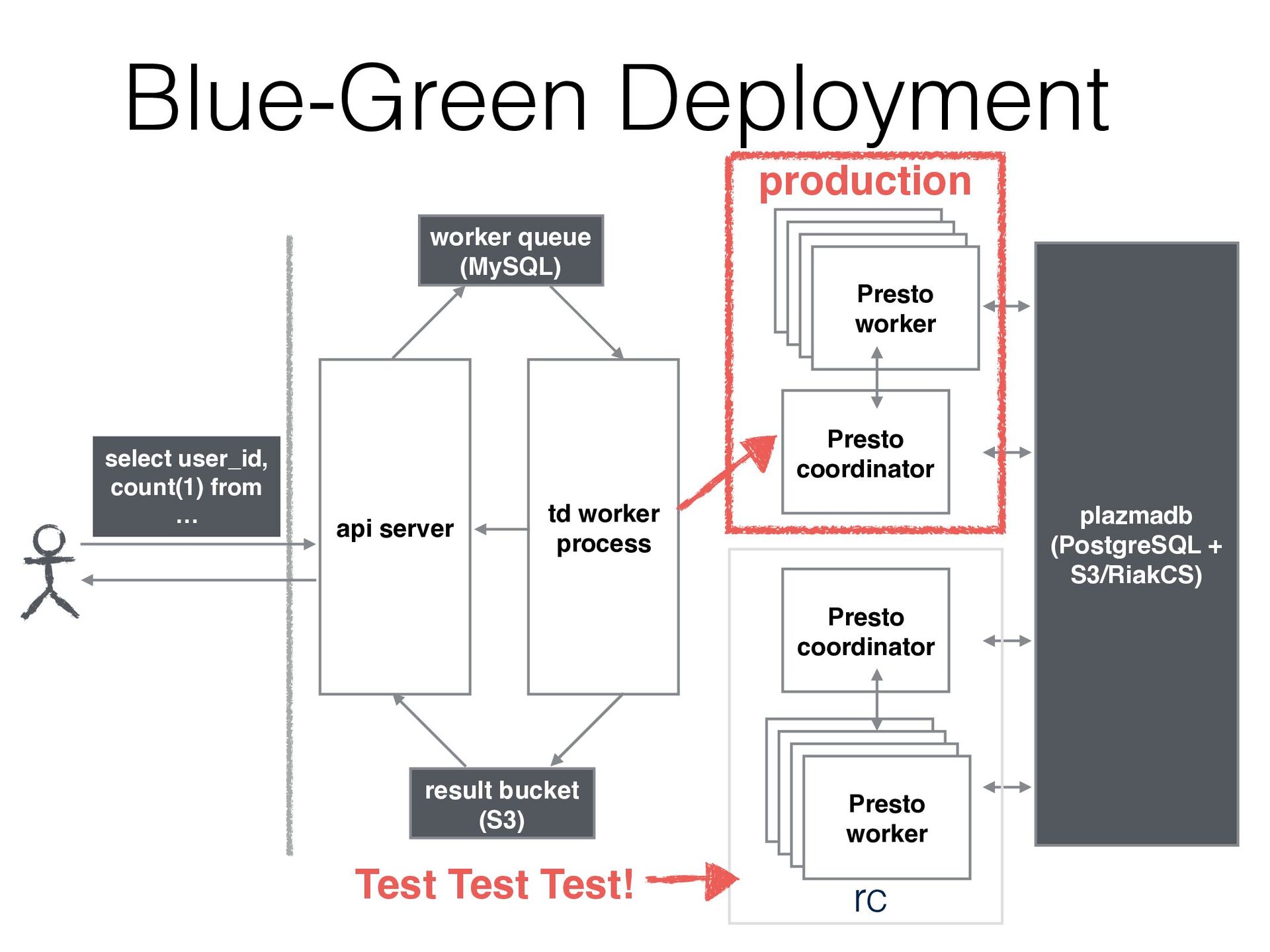{kind=link}
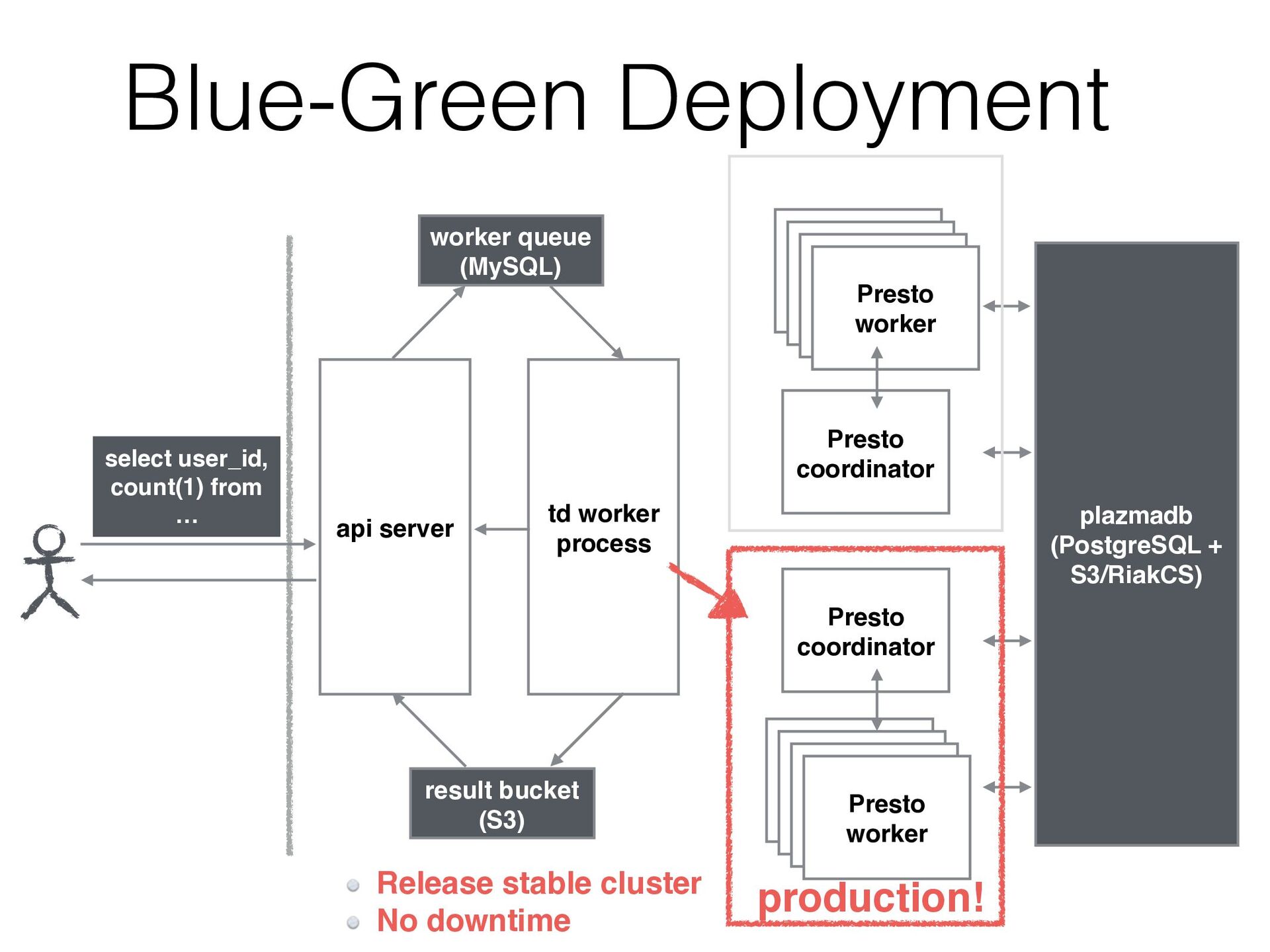{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
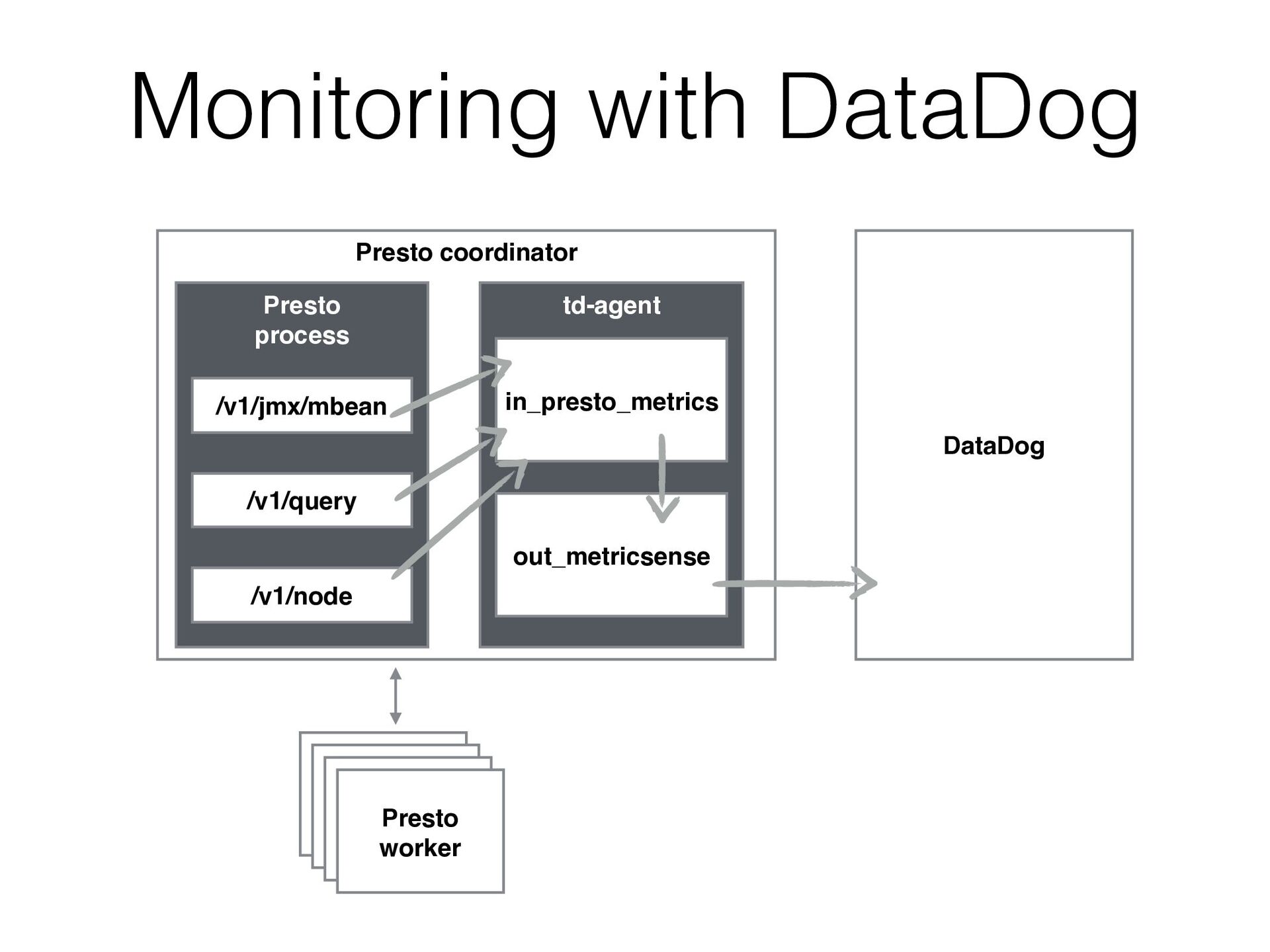{kind=link}
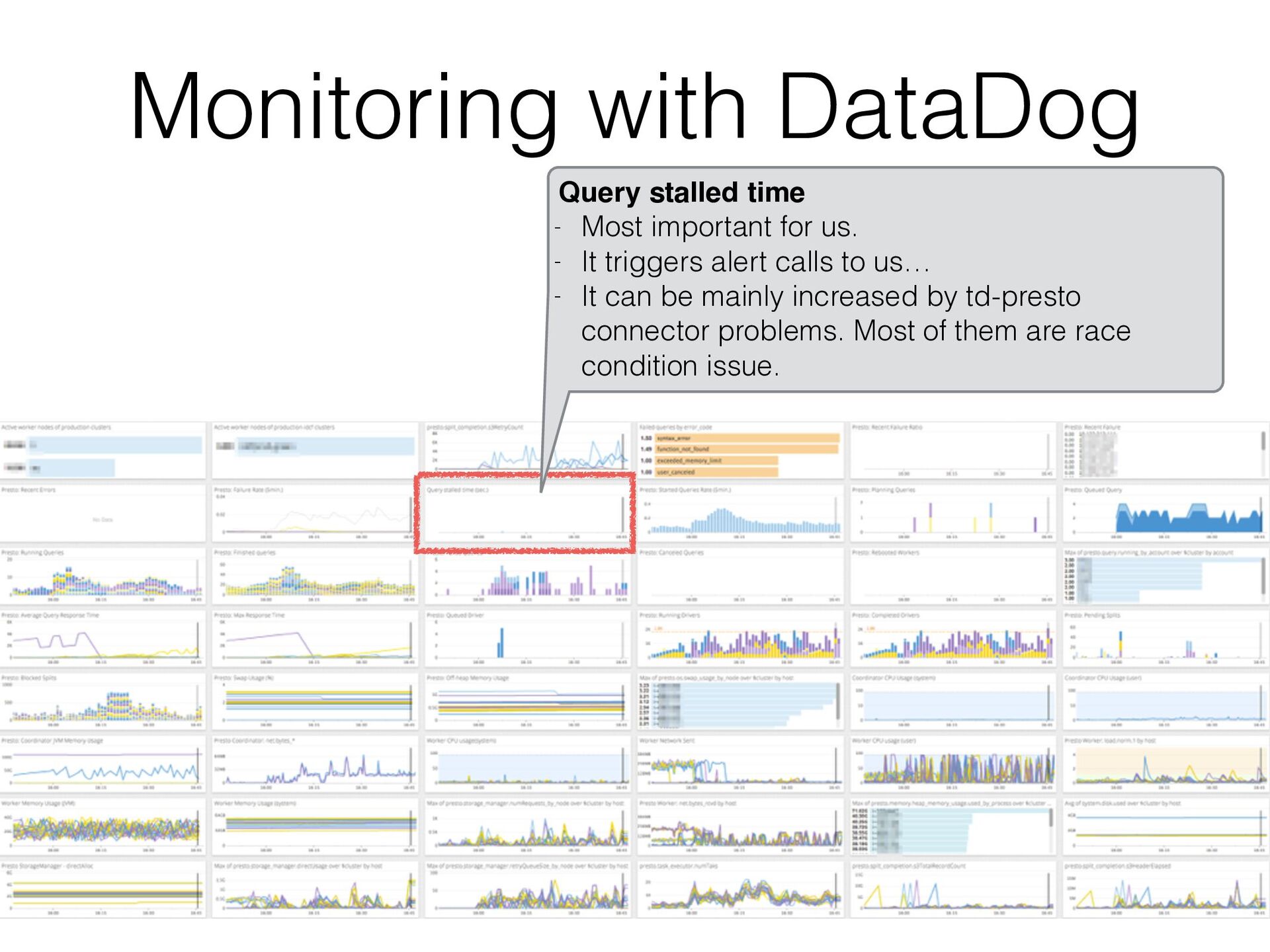{kind=link}
{kind=link}
{kind=link}
{kind=link}