team) • Joined Treasure Data almost 5 years ago • Hive, Presto, PlazmaDB, Mobile SDKs, Datatank, Workflow, … Event Collector, Bigdam (Pig, Impala…) • Favorite language: OCaml • RE OSS dev • MessagePack-Java, Digdag, Fluency
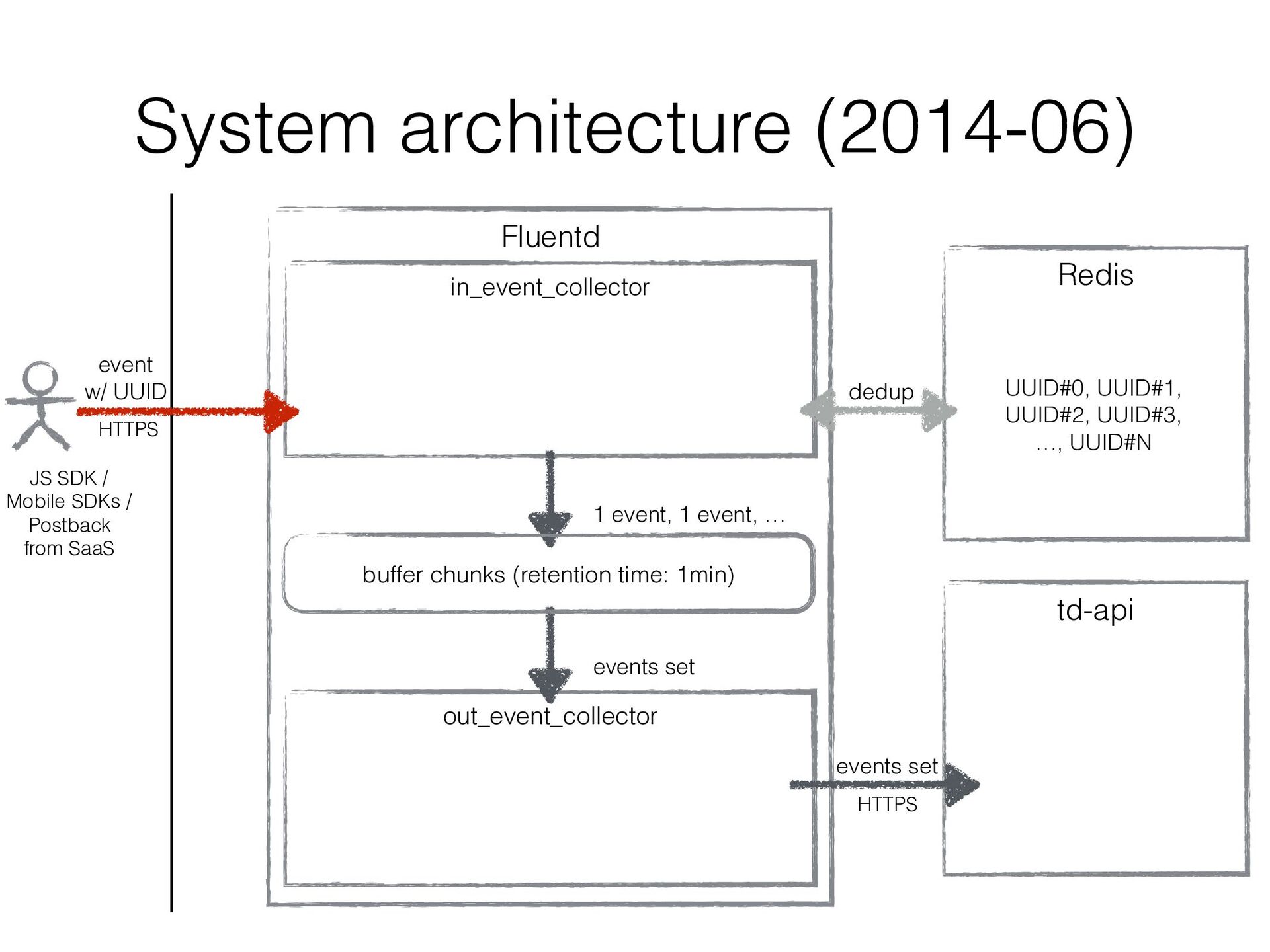
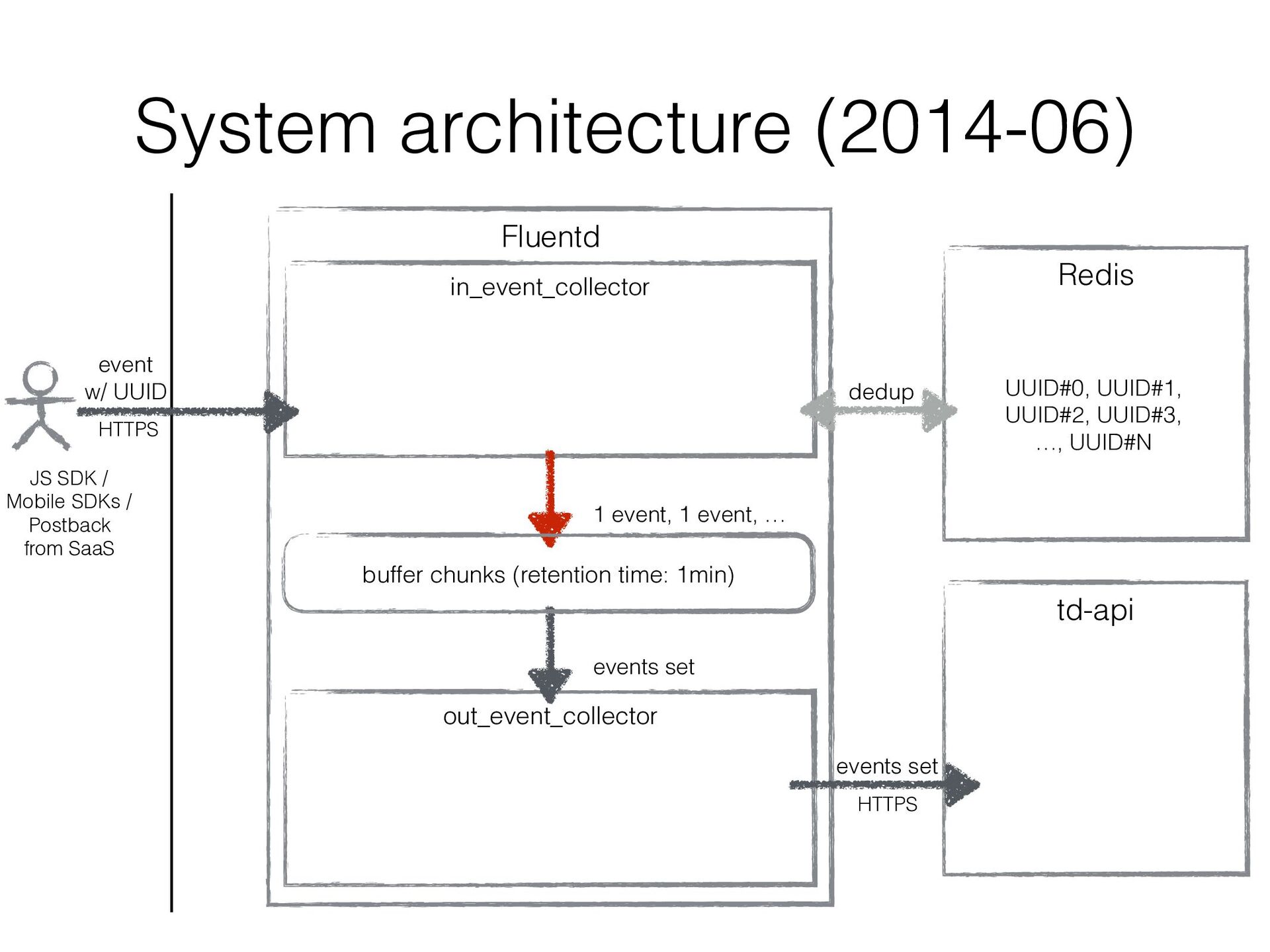
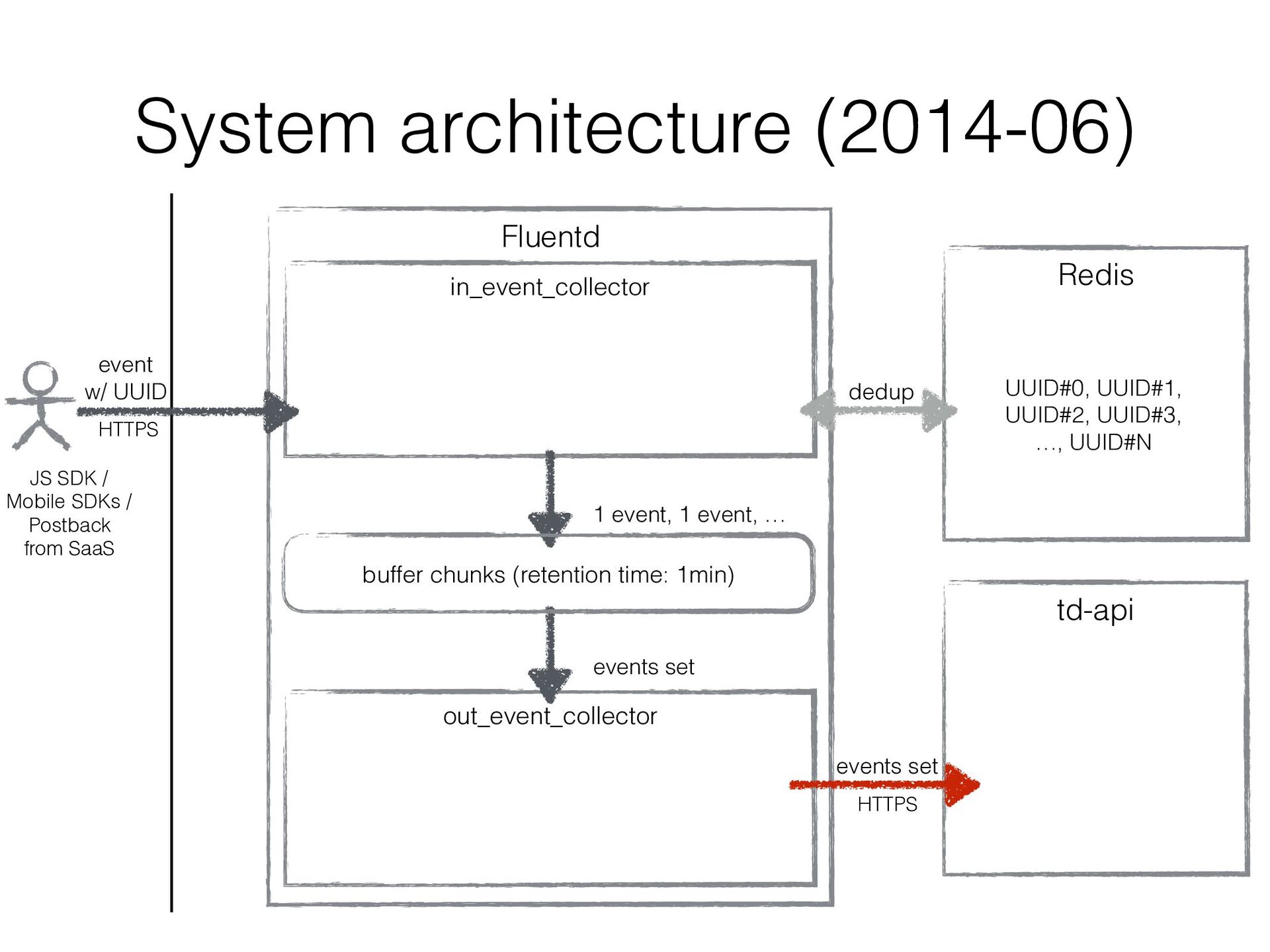
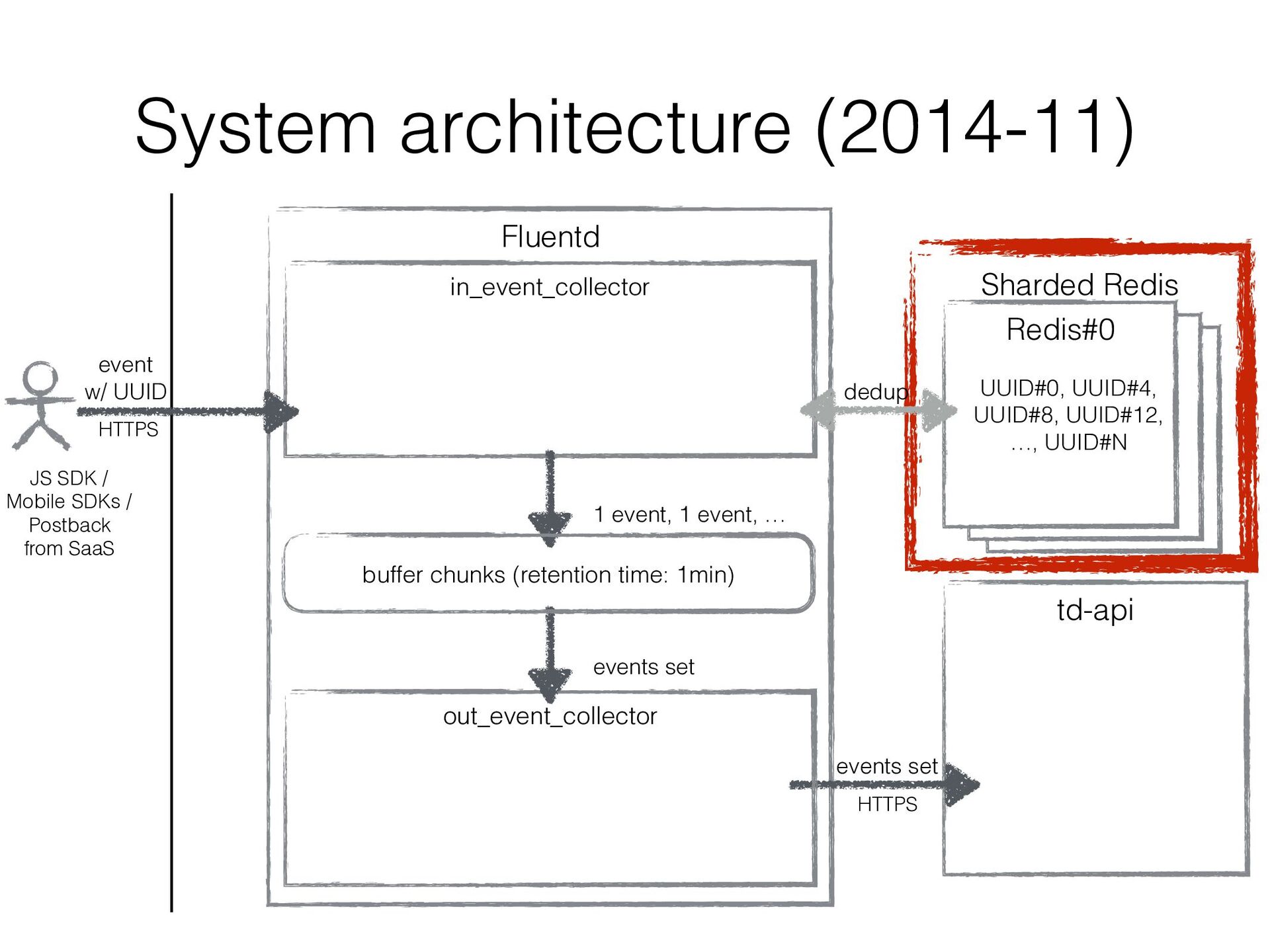
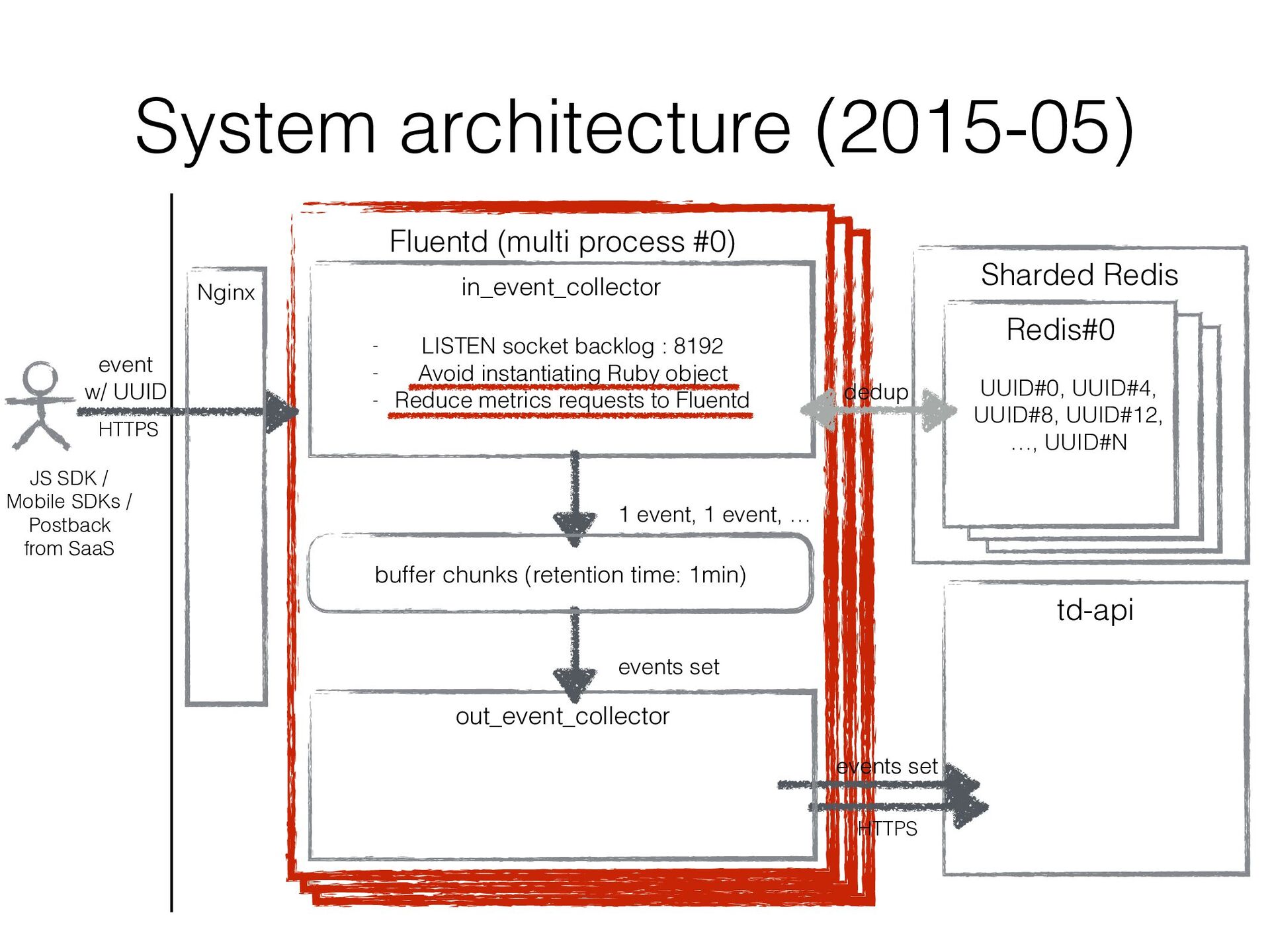
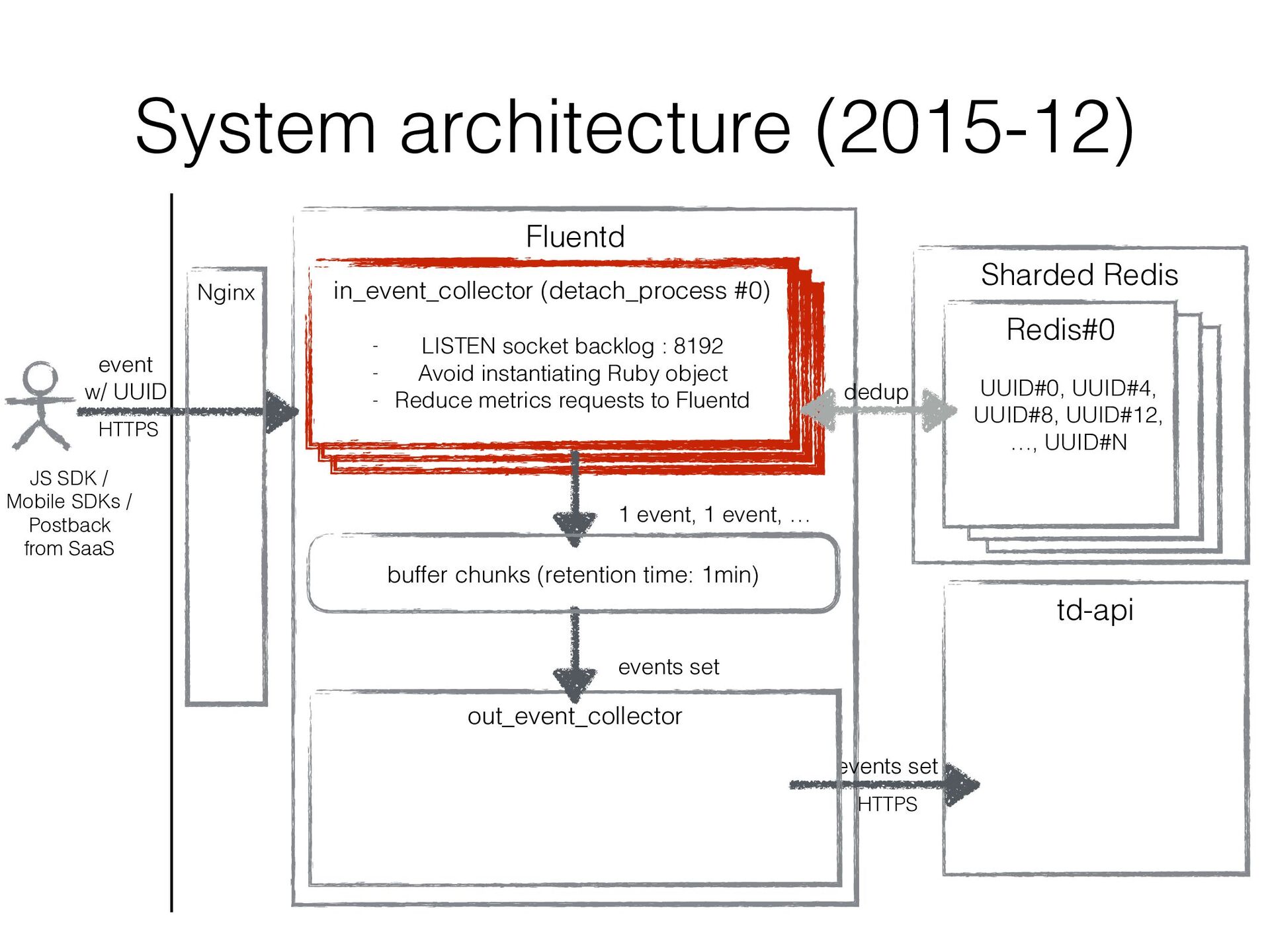
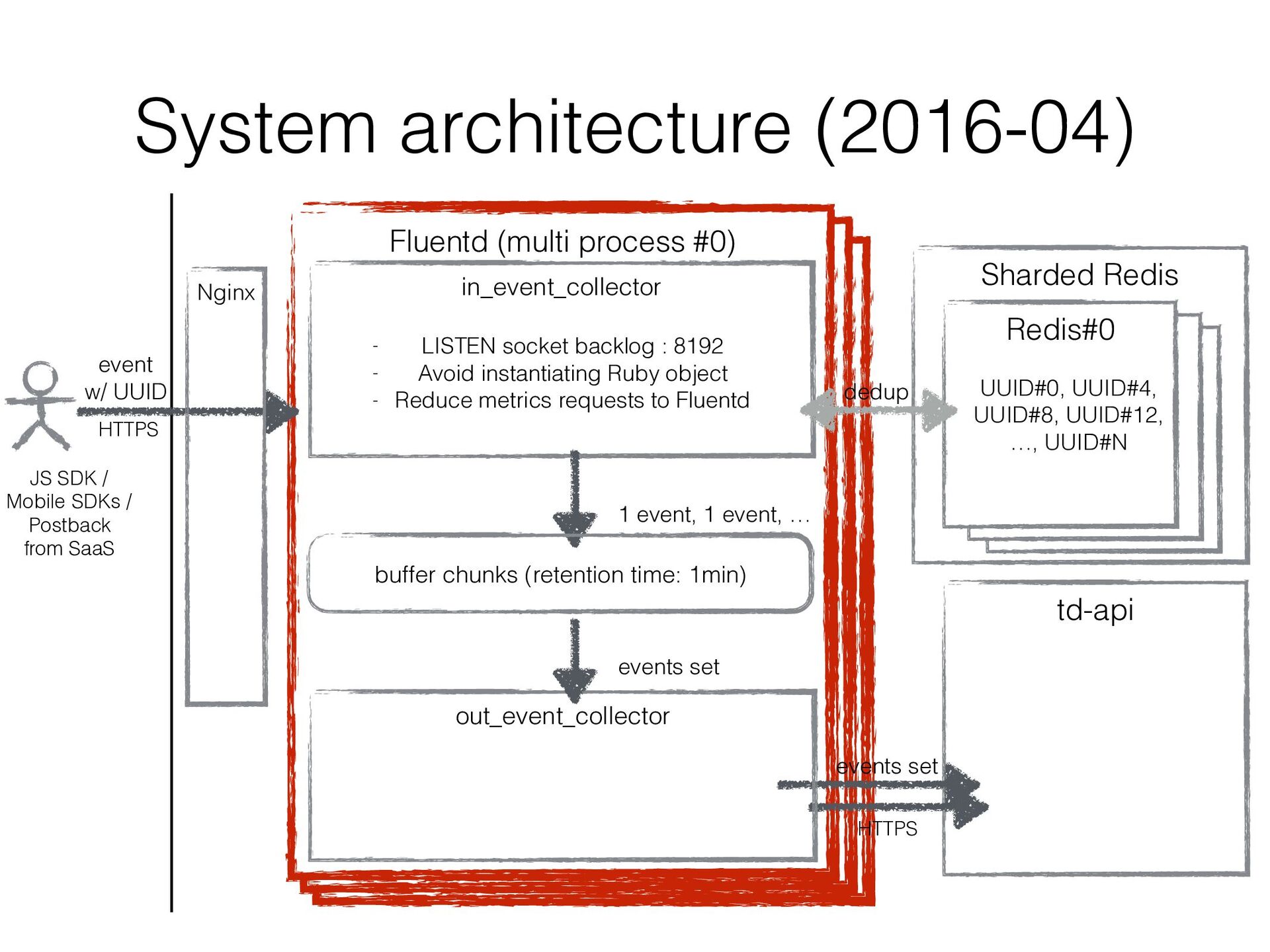
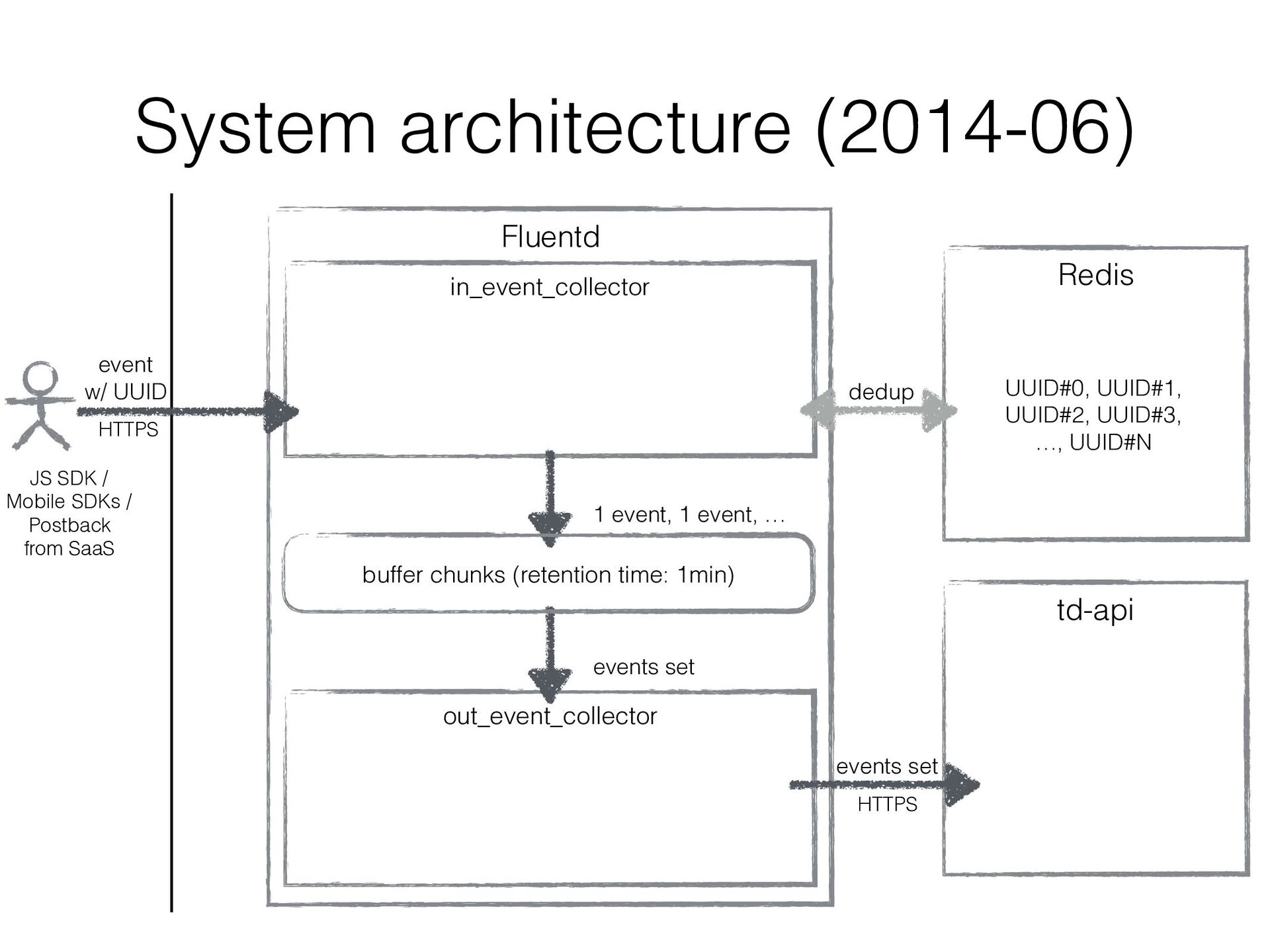
JavaScript SDK, Mobile SDKs, etc… • Buffers events for several minutes in local disk and uploads them to the existing import endpoint in Treasure Data • Existing original data ingestion endpoint td-api isn’t good at handling frequent small uploads • Consists of Fluentd in/out plugins (similar to in_http / out_tdlog) to rely on Fluentd’s buffering mechanizm • It’s been developed ad hoc and improved ad hoc…
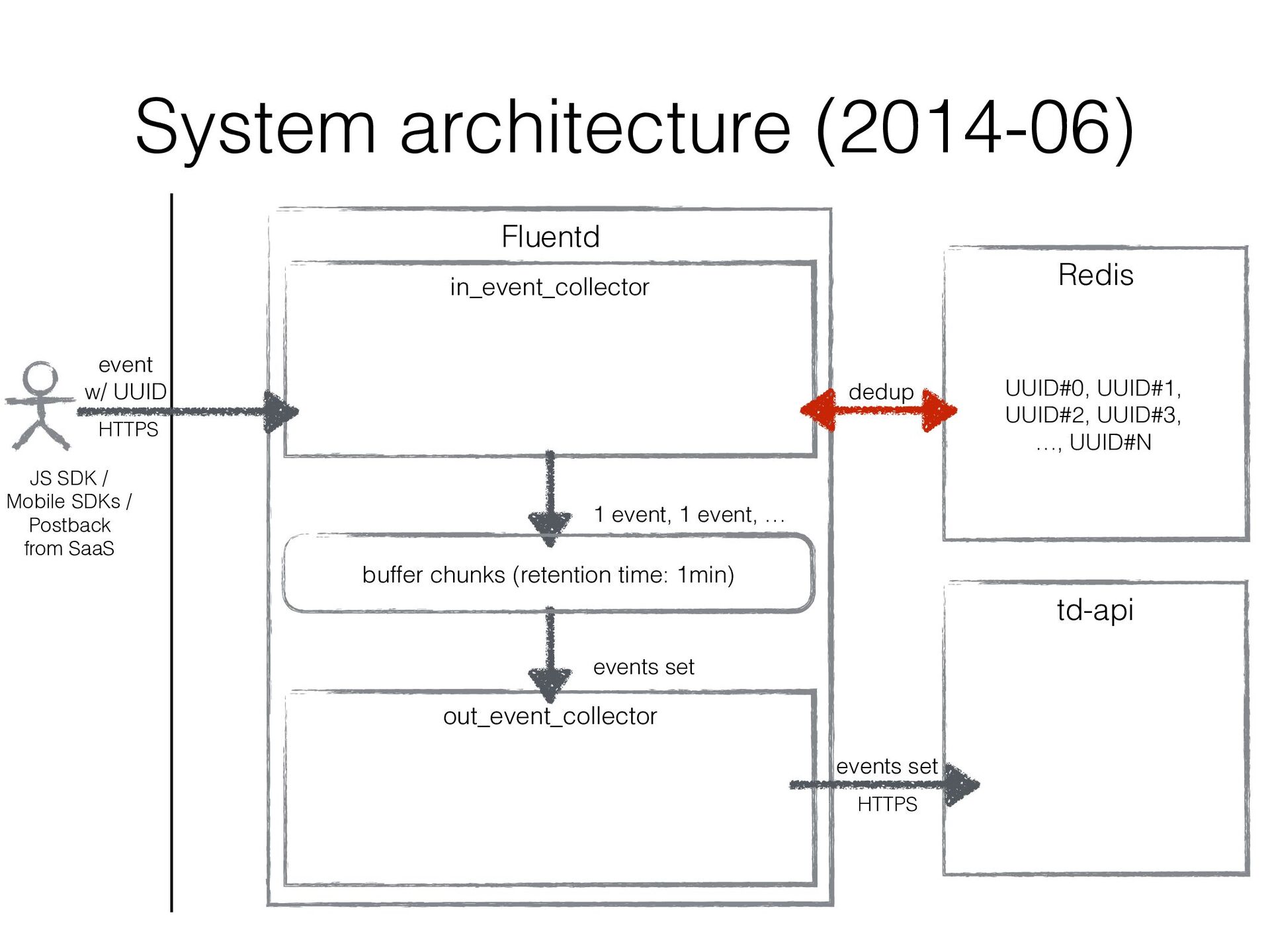
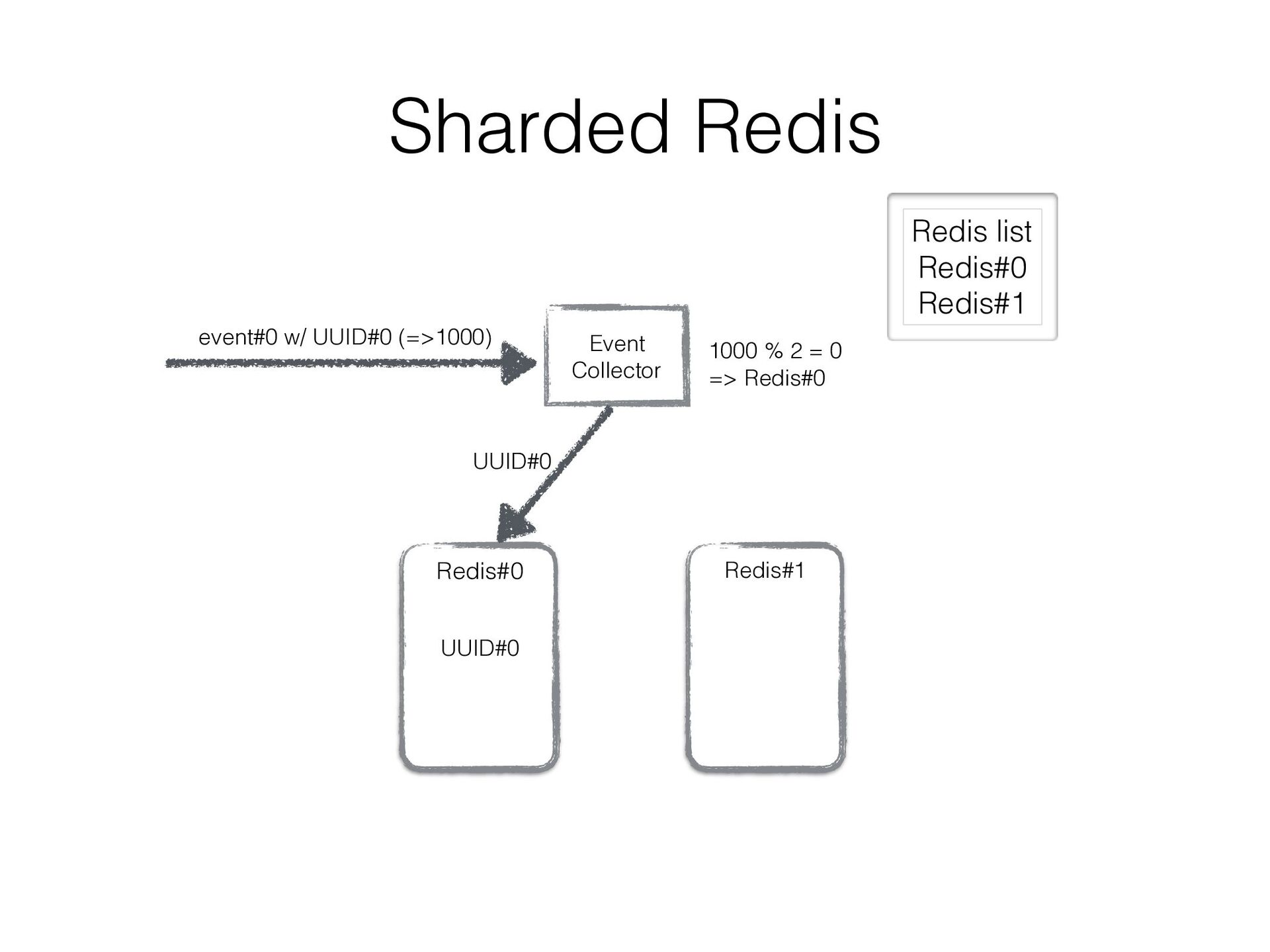
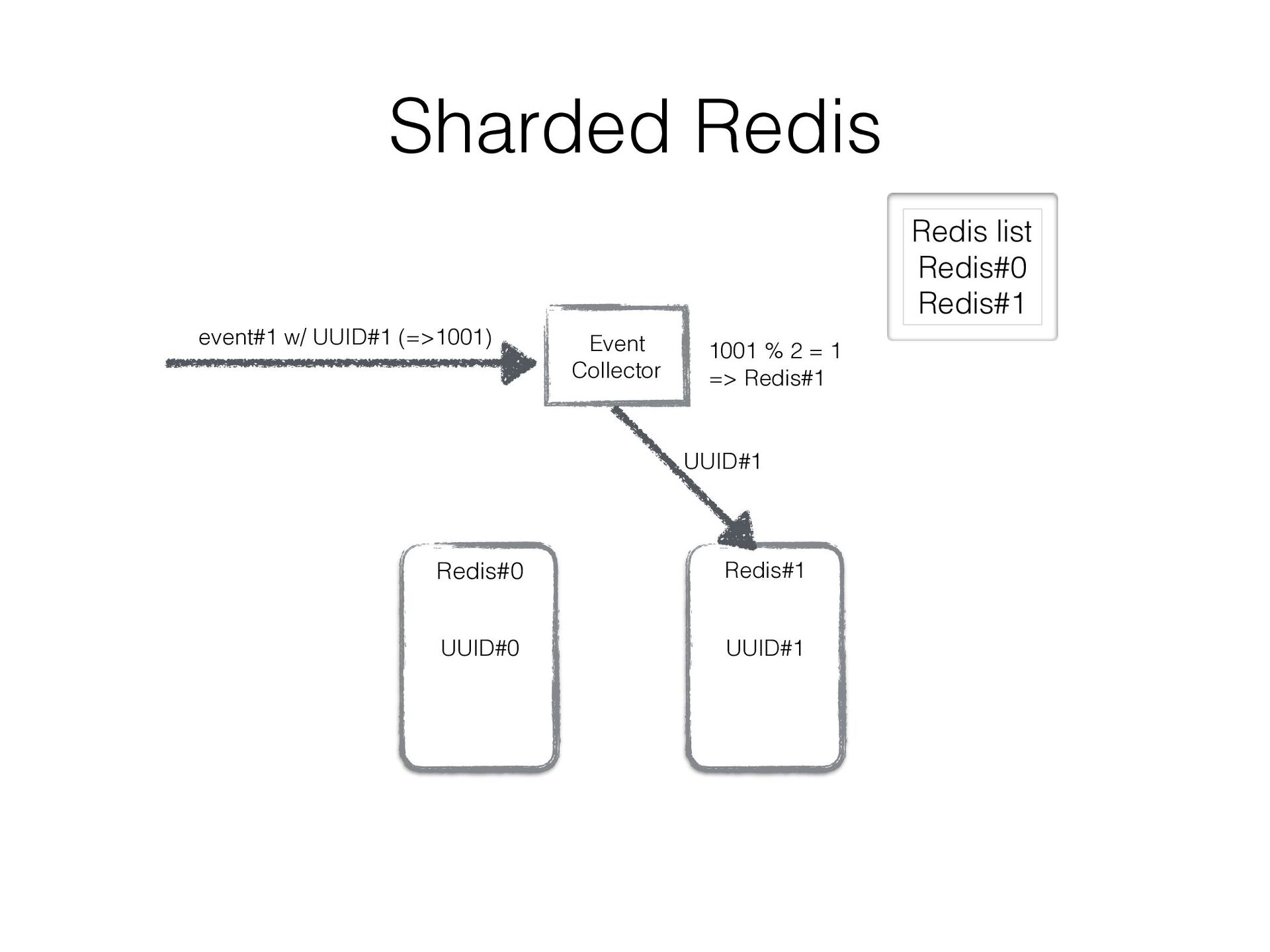
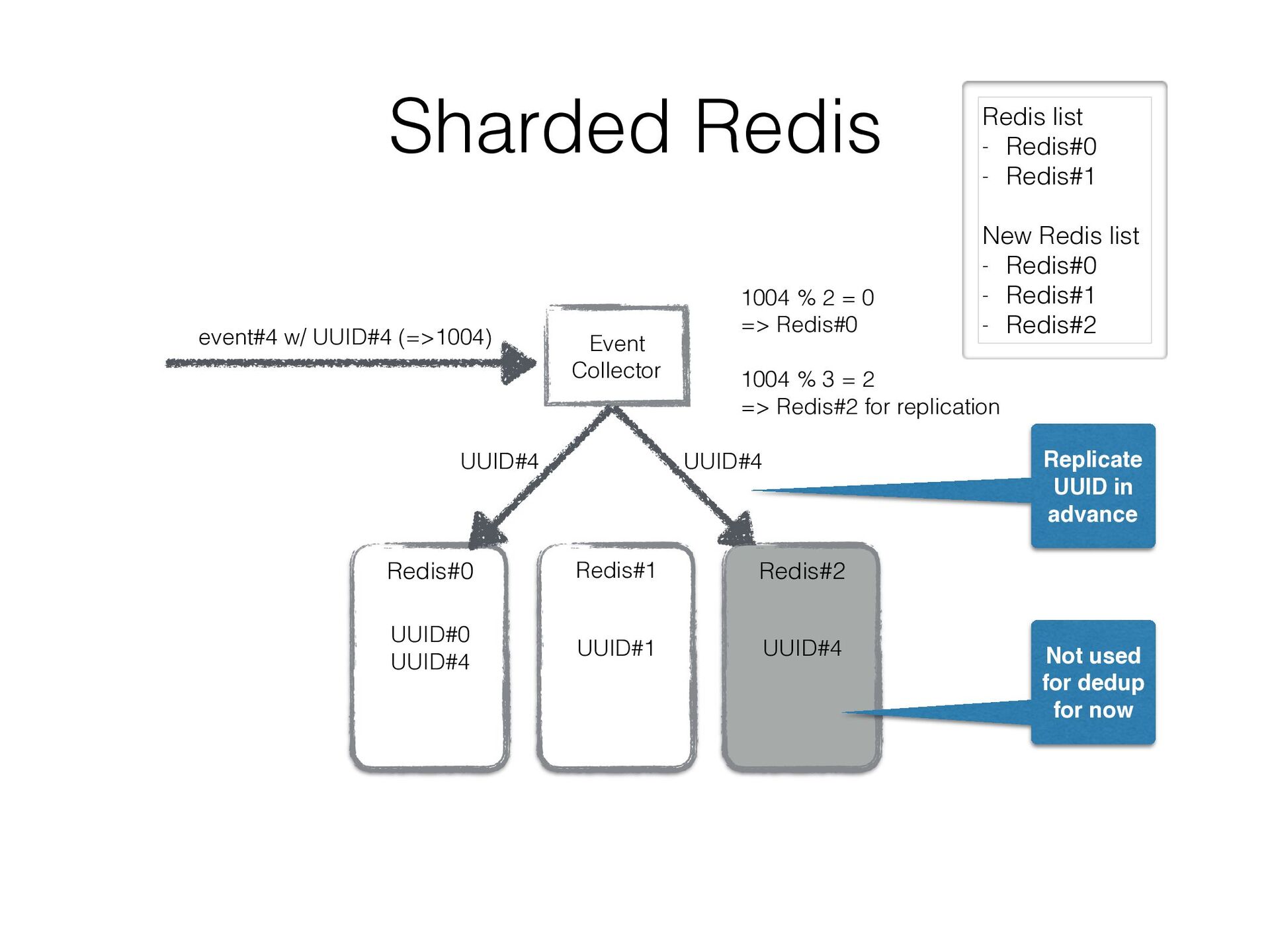
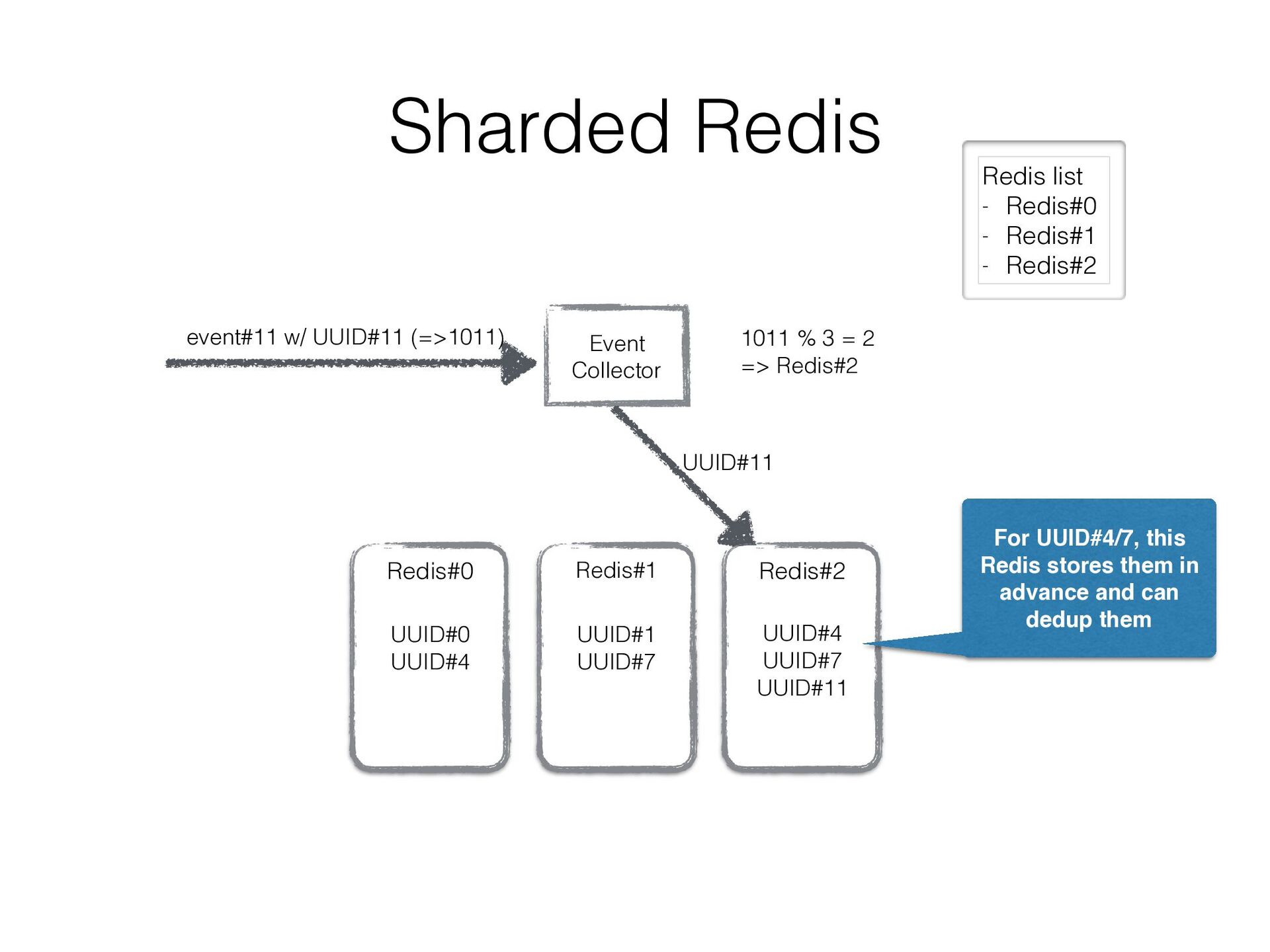
in a sharded Redis cluster • We created a bit intelligent Redis client that can • fail over to secondary Redis instance • double-write UUIDs to another Redis instance as well as current assigned one so that re- partitioning can be done w/o duplicated data
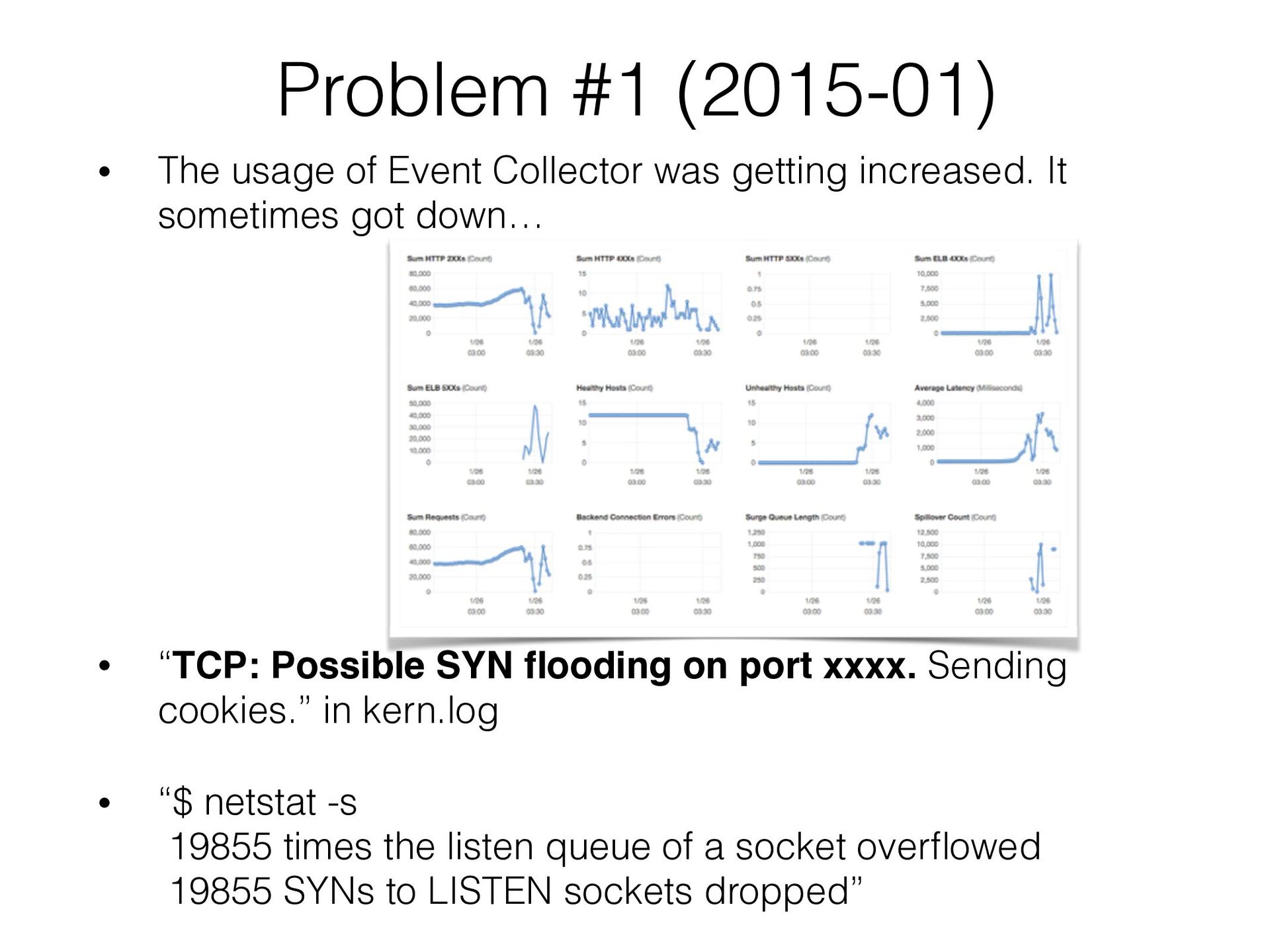
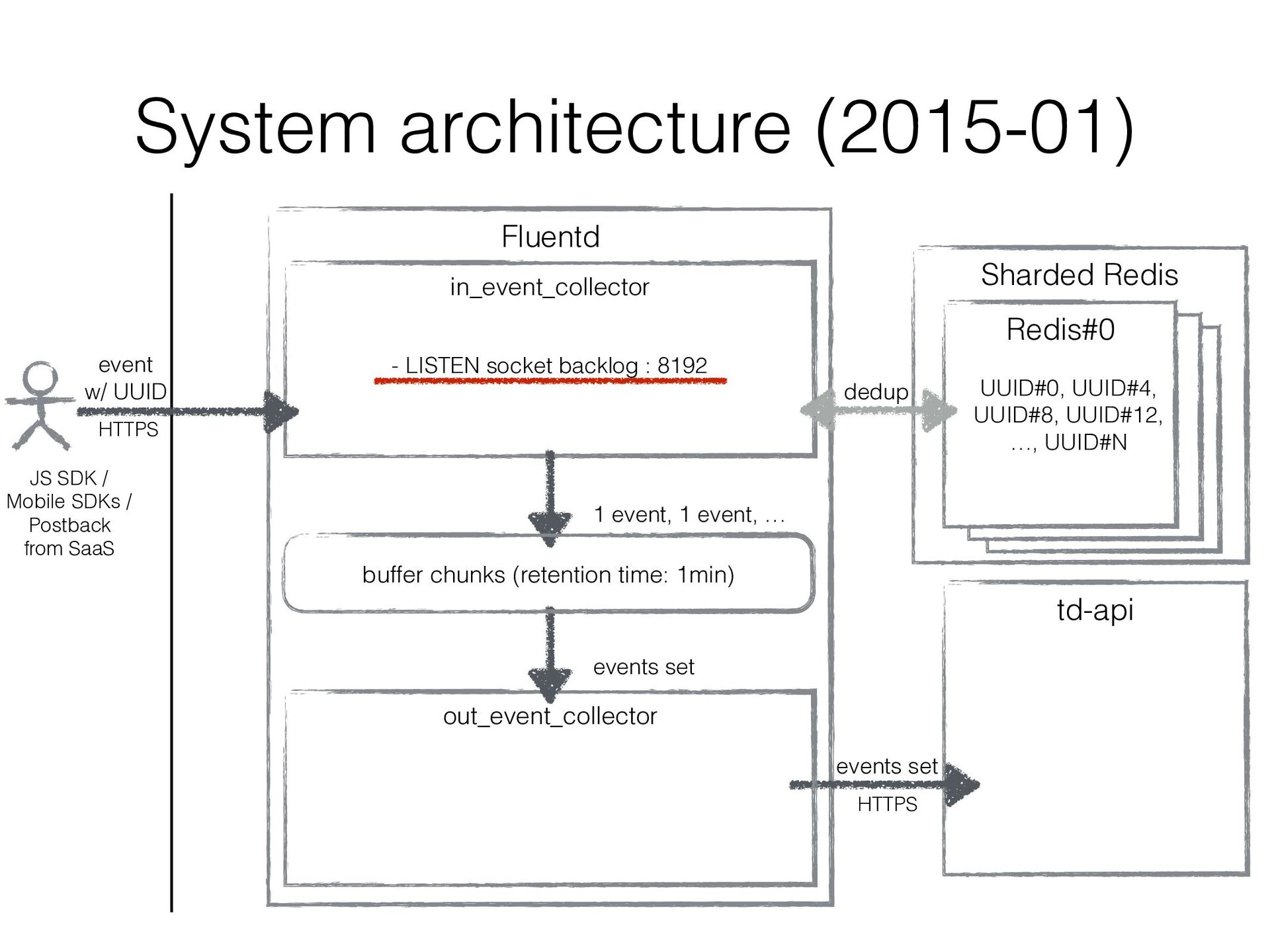
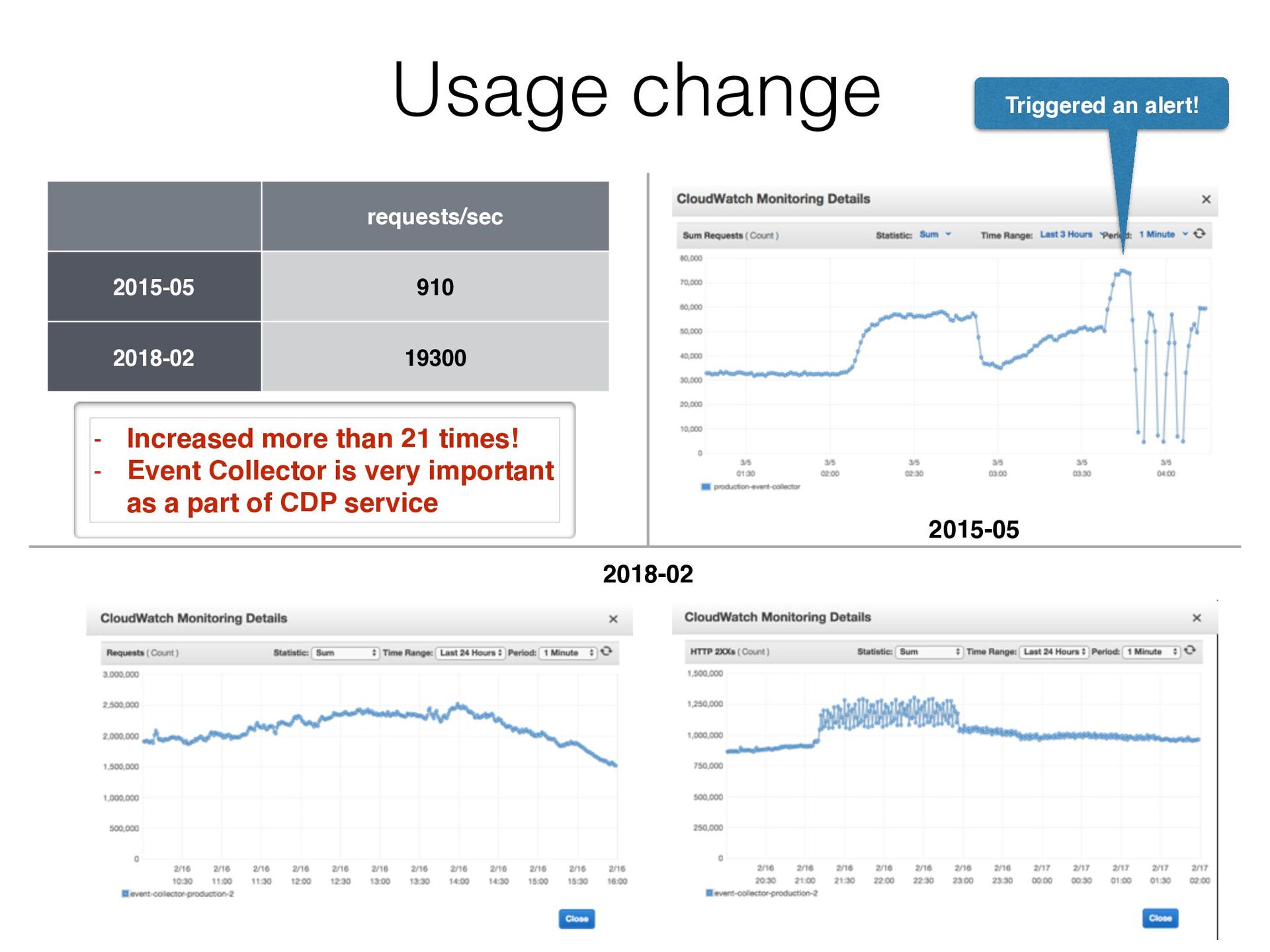
getting increased. It sometimes got down… • “TCP: Possible SYN flooding on port xxxx. Sending cookies.” in kern.log • “$ netstat -s 19855 times the listen queue of a socket overflowed 19855 SYNs to LISTEN sockets dropped”
2 performance bottlenecks were: • sending metrics per request to another Fluentd ➡ Aggregated 5 seconds range metrics in memory to reduce the number of messages to another Fluentd • parsing UserAgent ➡ Cached 100 UserAgentParser (ua-parser) instances with LRU eviction • The performance was improved 50 times
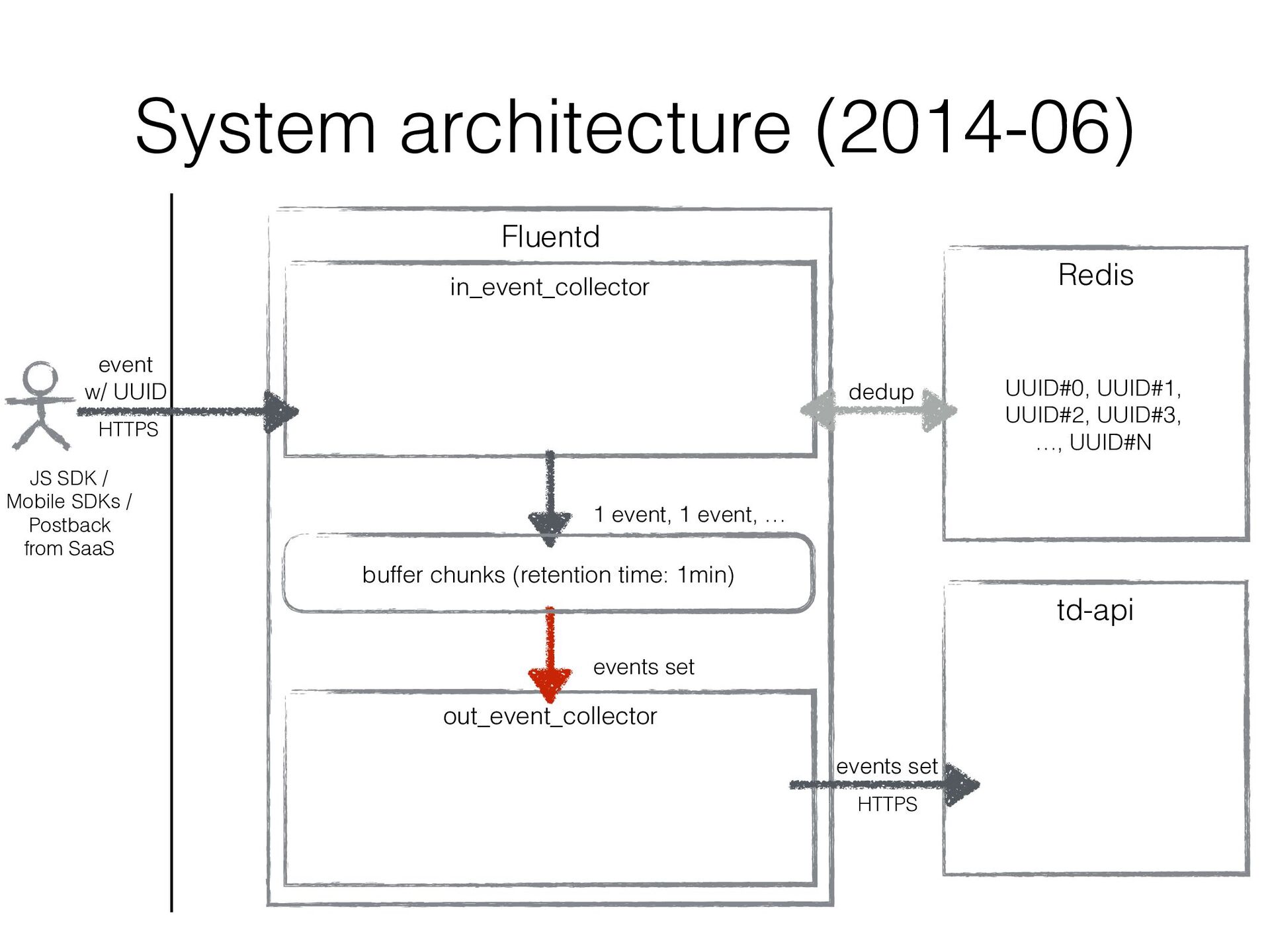
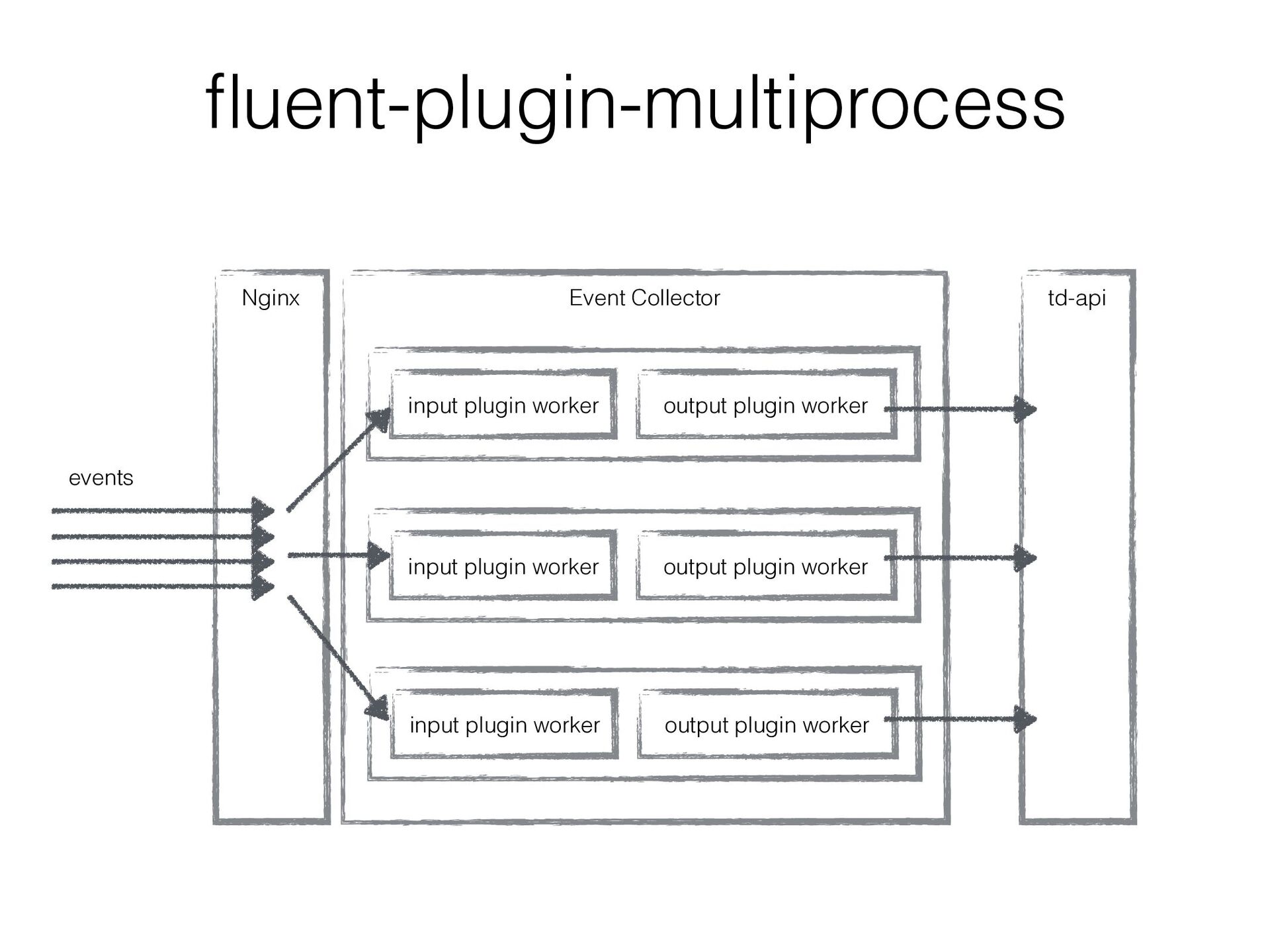
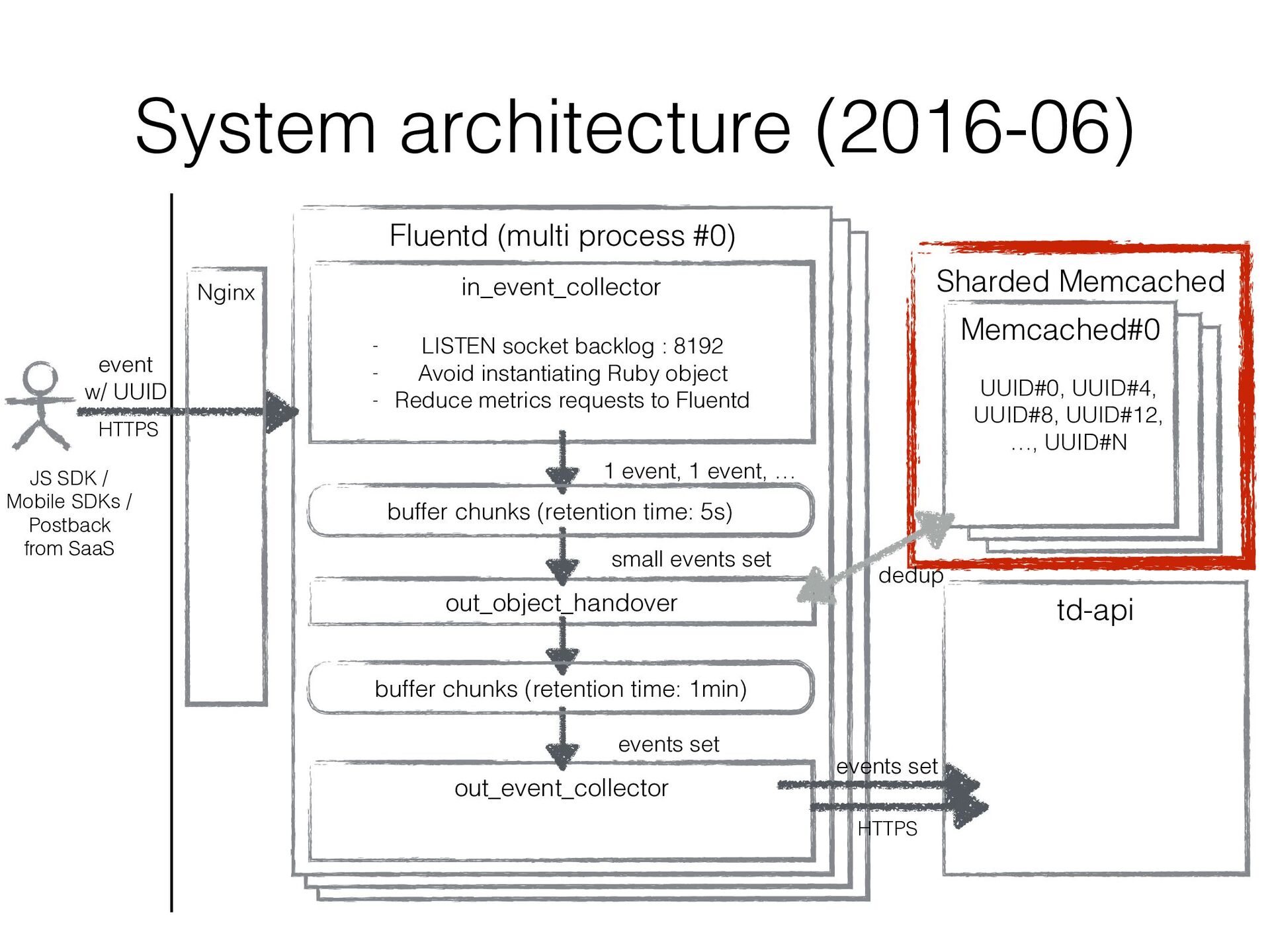
plugin workers of Event Collector can run in multi processes • The performance improved 6 times with it • Drawback: • The number of output plugin workers also increased • As a result, the number of uploaded chunks to td-api increased significantly. td-api sometimes suffered from a lot of tiny uploaded chunk files… • In other words, td-api was a bottleneck in Event Collector’s scalability
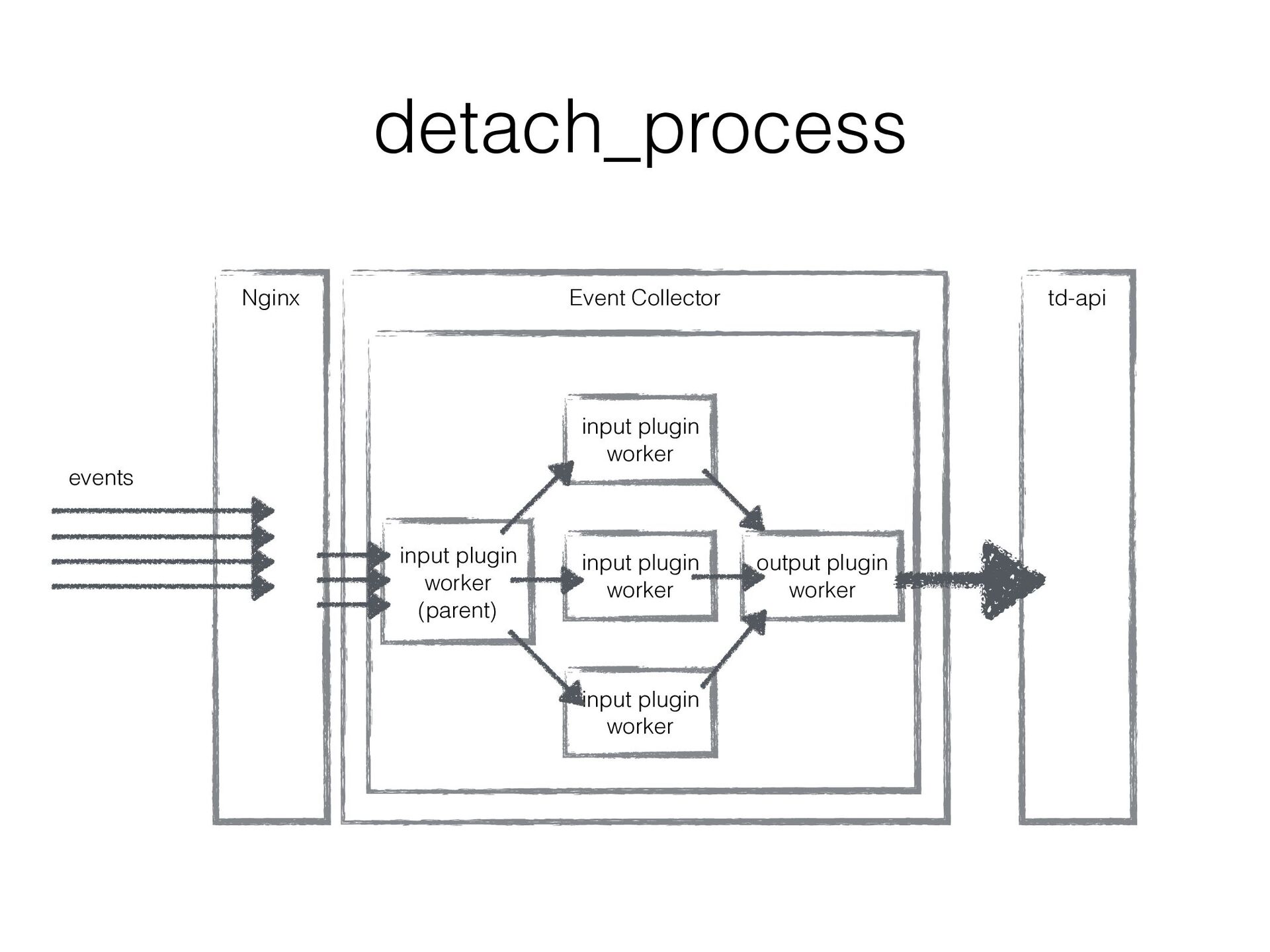
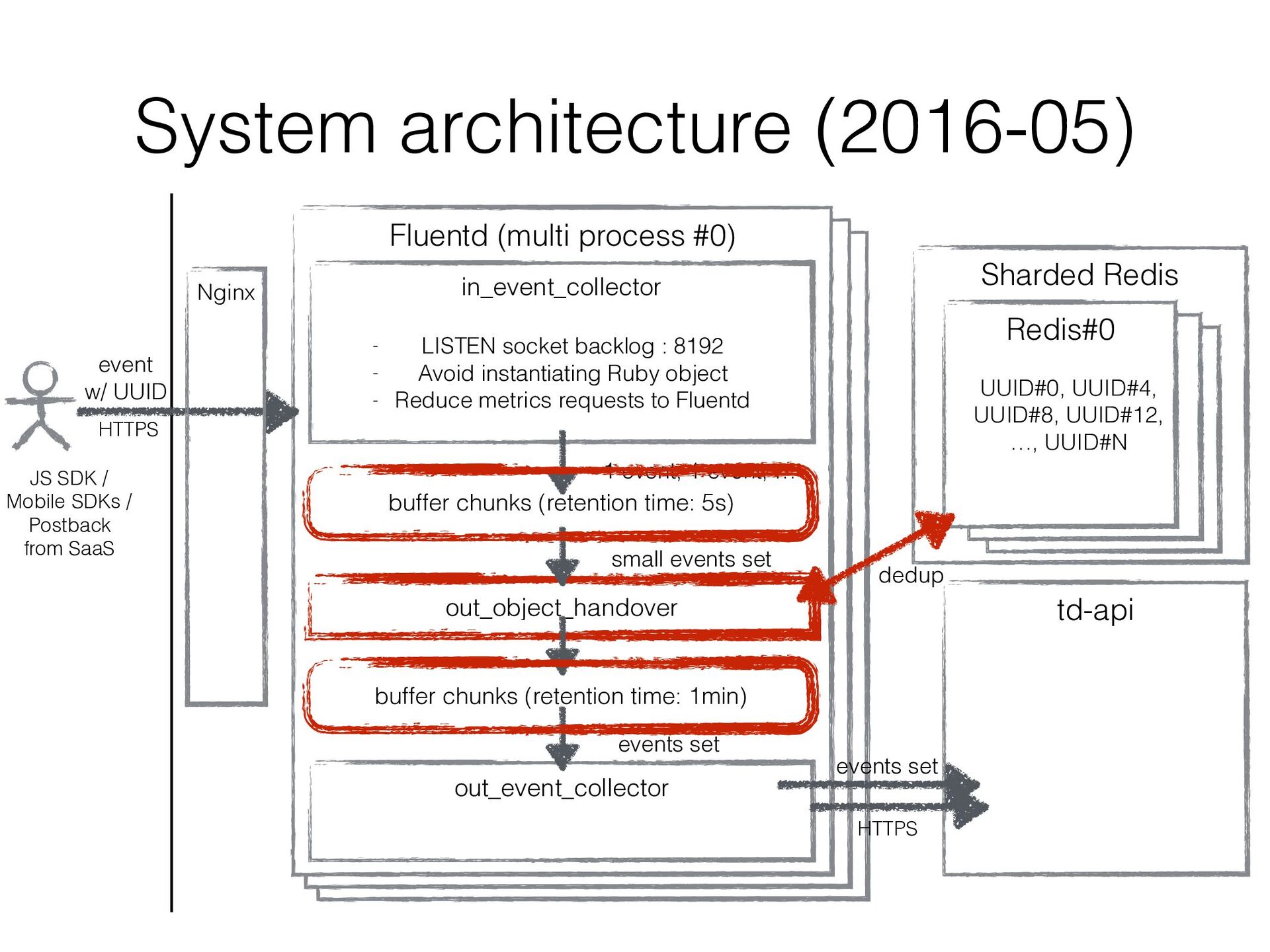
plugins • With it, multiple input_plugin workers can run in multi processes keeping the number of output_plugin workers to 1 • The number of uploaded chunk files to td-api would be reduced!
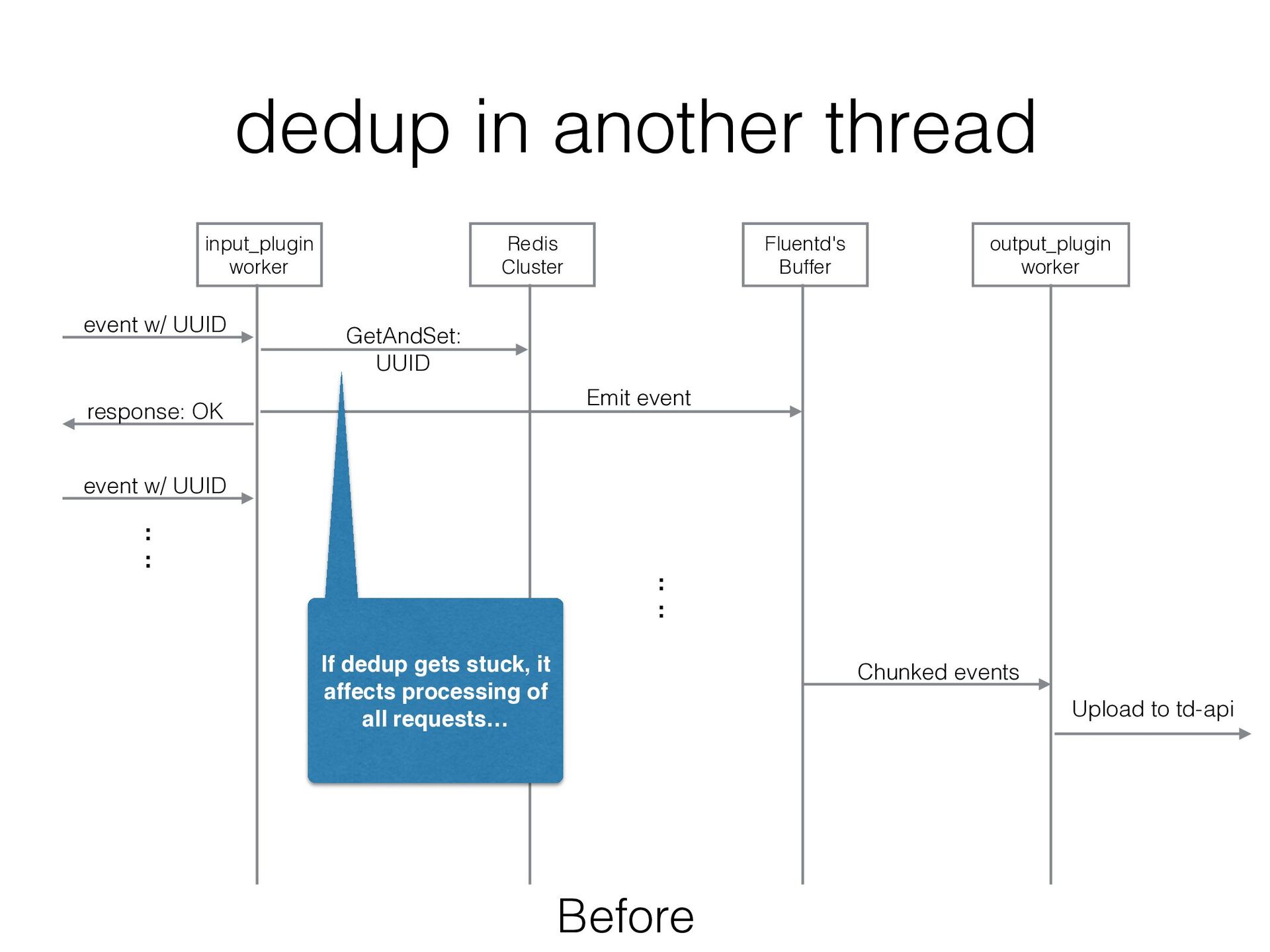
got a bottleneck • When dedup with Redis cluster for requests from Mobile SDK got stuck, processing requests from JavaScript SDK / Postback from SaaS were stuck too…
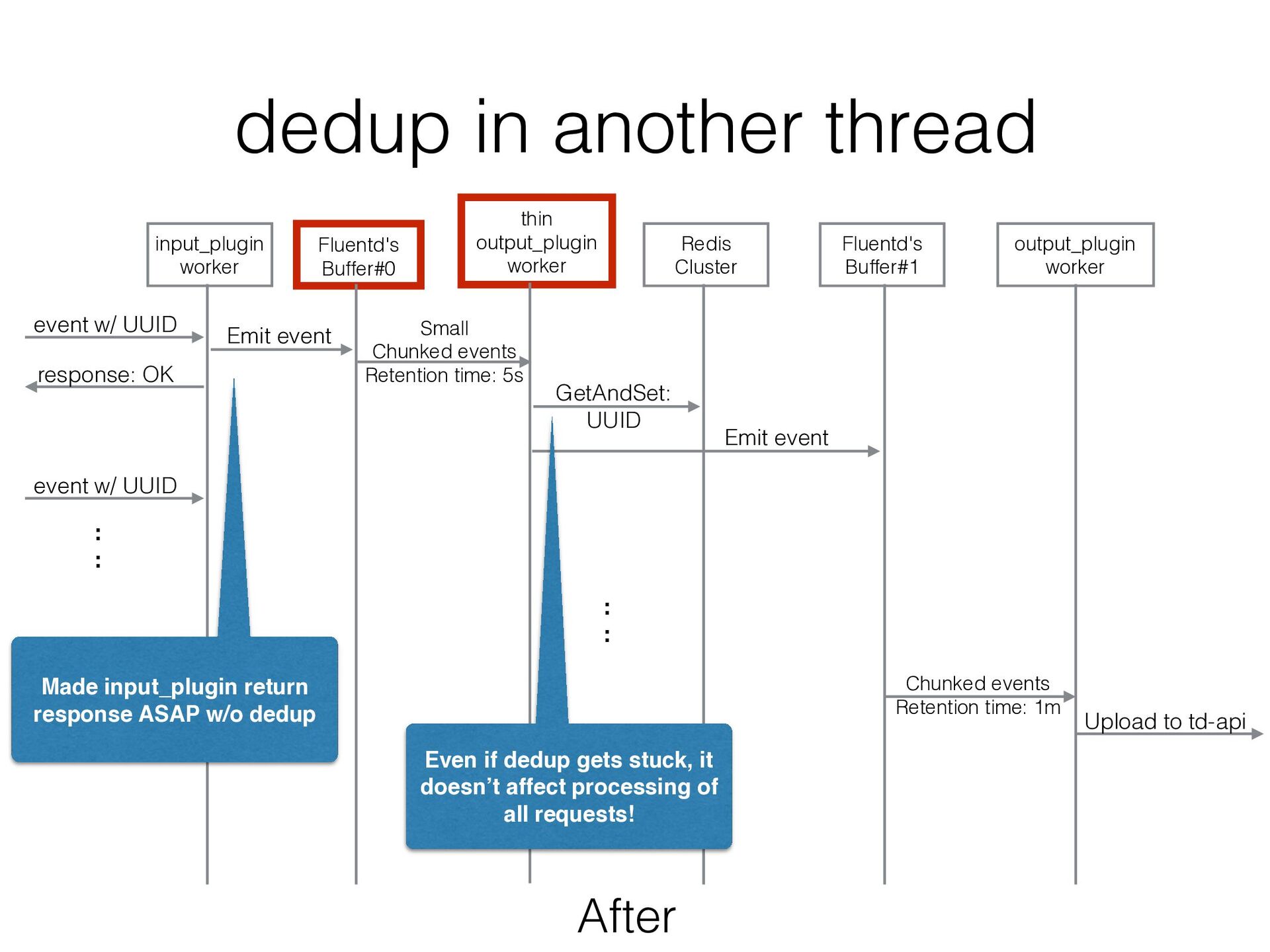
a different thread from input_plugin worker, input_plugin worker can continue to process requests even when accesses to Redis gets stuck • existing output_plugin runs in another thread, so it might be an option to dedup in it • But output_plugin handles large chunk files. So if it retries around the end of a chunk file, all records in the chunk file are handled as duplicated records. • We needed to mitigate the impact of this case • Let’s insert a new thin output plugin worker!
Before event w/ UUID GetAndSet: UUID Fluentd's Buffer Emit event response: OK : : event w/ UUID Chunked events Upload to td-api If dedup gets stuck, it affects processing of all requests… : :
be delayed • Even we upgrade the instance type of Redis cluster, Redis runs on a single core and can’t use benefits of multicores… • Actually, we used Redis as just a KVS. The complex data types of Redis wasn’t needed in the end
problems didn’t occur during the migration thanks to the double write feature • Based on benchmark results using actual access pattern of Event Collector, the performance improved twice and the memory consumption of dedup cluster was reduced down to 68% comparing to Redis
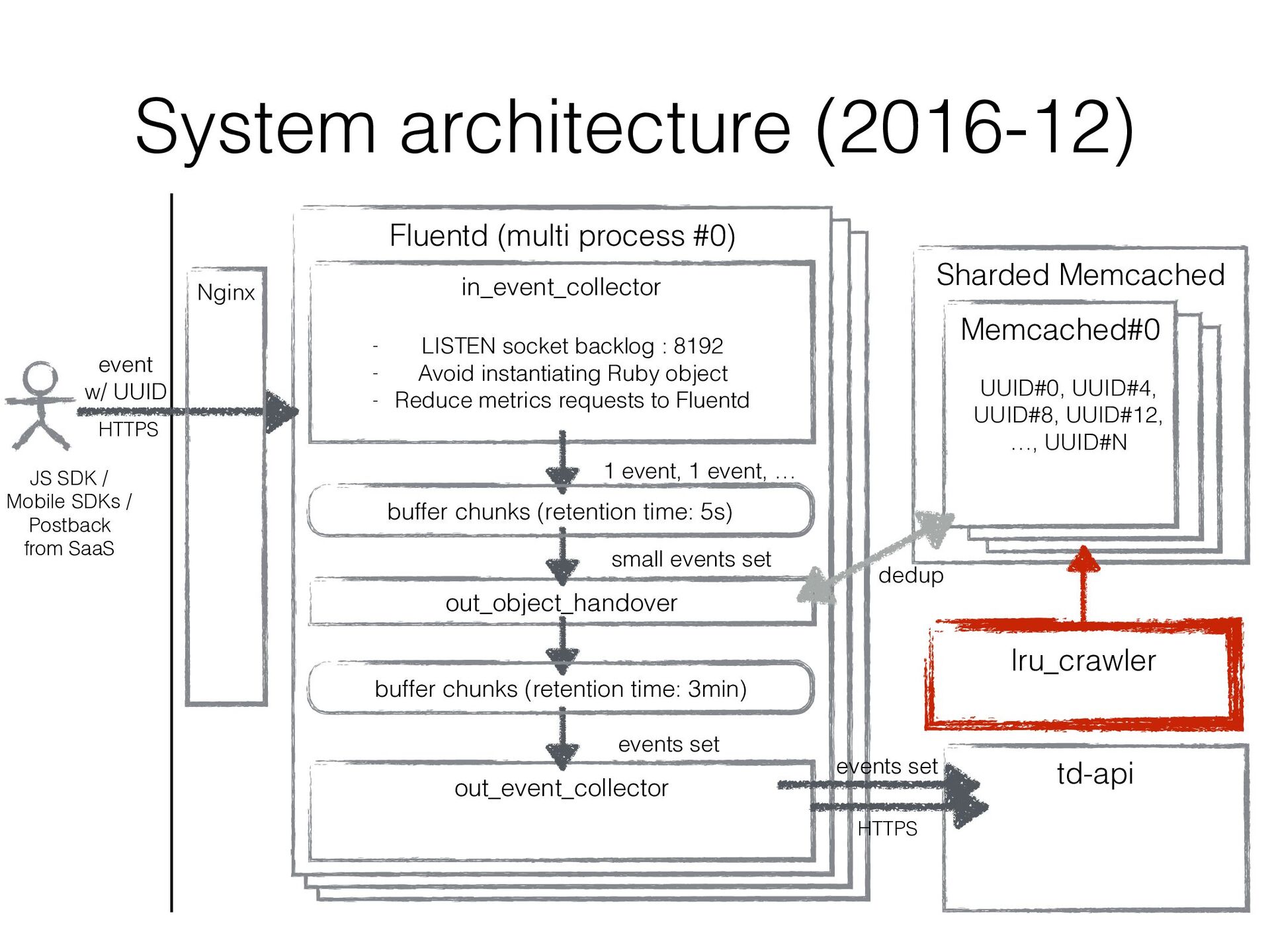
on the dedup cluster for one of our customers while using default 1 hour TTL for other customers’ requests • It sounded easy since Memcached’s APIs support TTL • But the Memcached dedup cluster stopped reclaiming expired entries that had 1 hour TTL and memory consumptions got increased drastically…
found the cause • Memcached removes expired entries as far as it continues to find expired entries in a row. It works fine when all entries have similar TTL • But, if Memcached has 1 hour TTL and 36 hours TTL entries, it stops reclaiming when it finds a 36 hours TTL entry even it has expired 1 hour TTL entries a lot behind
• Let’s call “lru_crawler crawl all” repeatedly! - Takes a single, or a list of, numeric classids (ie: 1,3,10). This instructs the crawler to start at the tail of each of these classids and run to the head. The crawler cannot be stopped or restarted until it completes the previous request. The special keyword "all" instructs it to crawl all slabs with items in them. https://github.com/memcached/memcached/blob/master/doc/protocol.txt
local disk isn’t replicated • Uploads of many small chunk files to td-api • Aggregation those small ones with in_forward plugin is an option, though... • Further performance improvement
local disk isn’t replicated ➡ Bigdam will resolve it! • Uploads of many small chunk files to td-api • Aggregation those small ones with in_forward plugin is an option, though... • Further performance improvement
local disk isn’t replicated ➡ Bigdam will resolve it! • Uploads of many small chunk files to td-api • Aggregation those small ones with in_forward plugin is an option, though... ➡ Bigdam will resolve it! • Further performance improvement
local disk isn’t replicated ➡ Bigdam will resolve it! • Uploads of many small chunk files to td-api • Aggregation those small ones with in_forward plugin is an option, though... ➡ Bigdam will resolve it! • Further performance improvement ➡ Bigdam will resolve it!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}