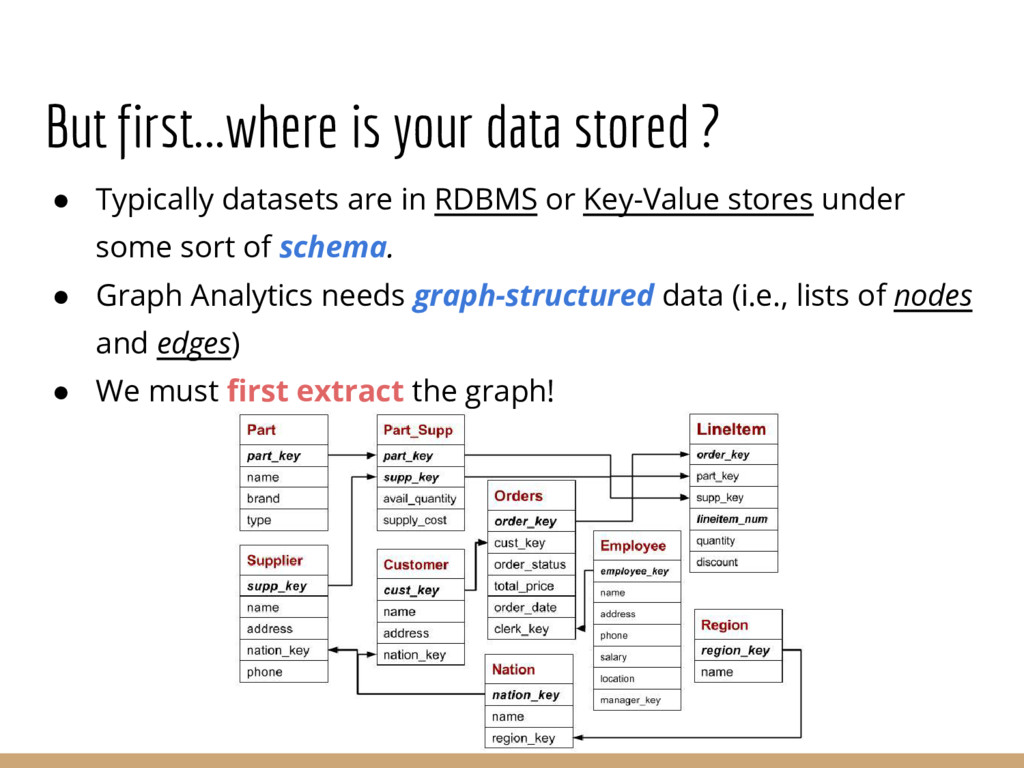
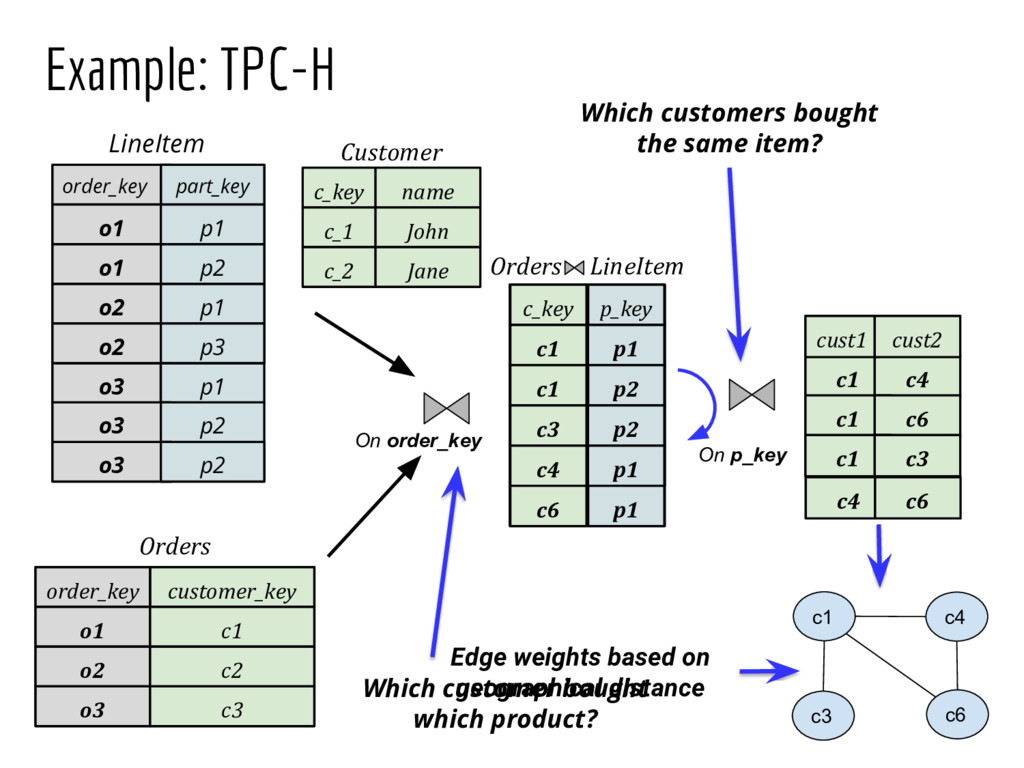
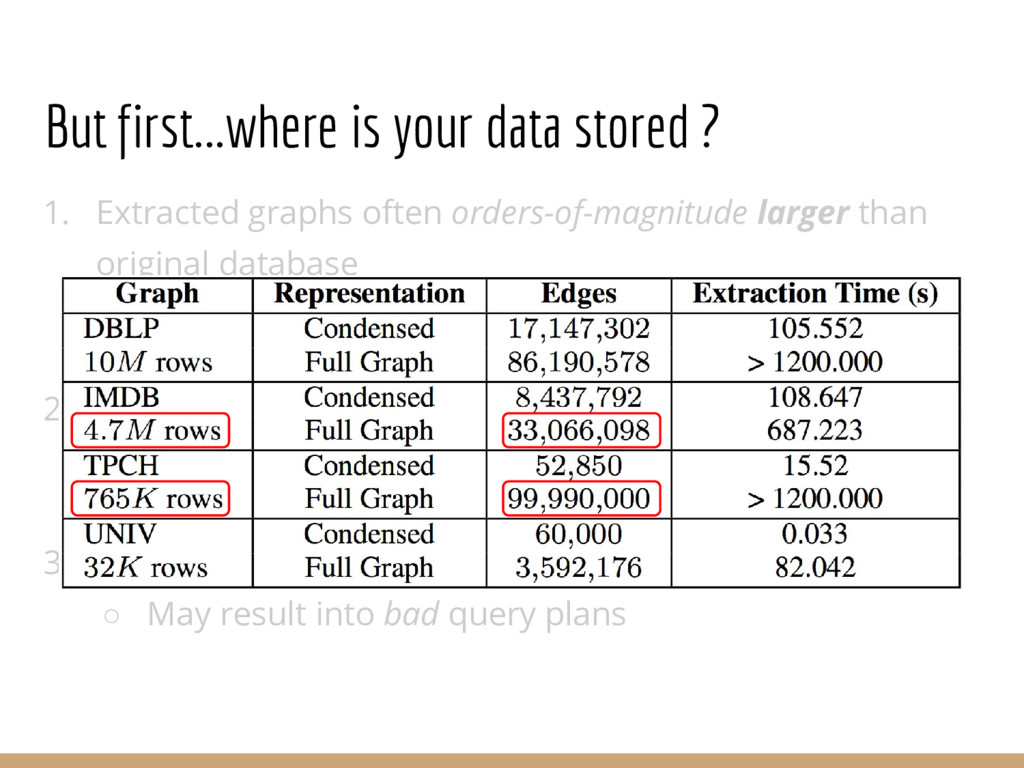
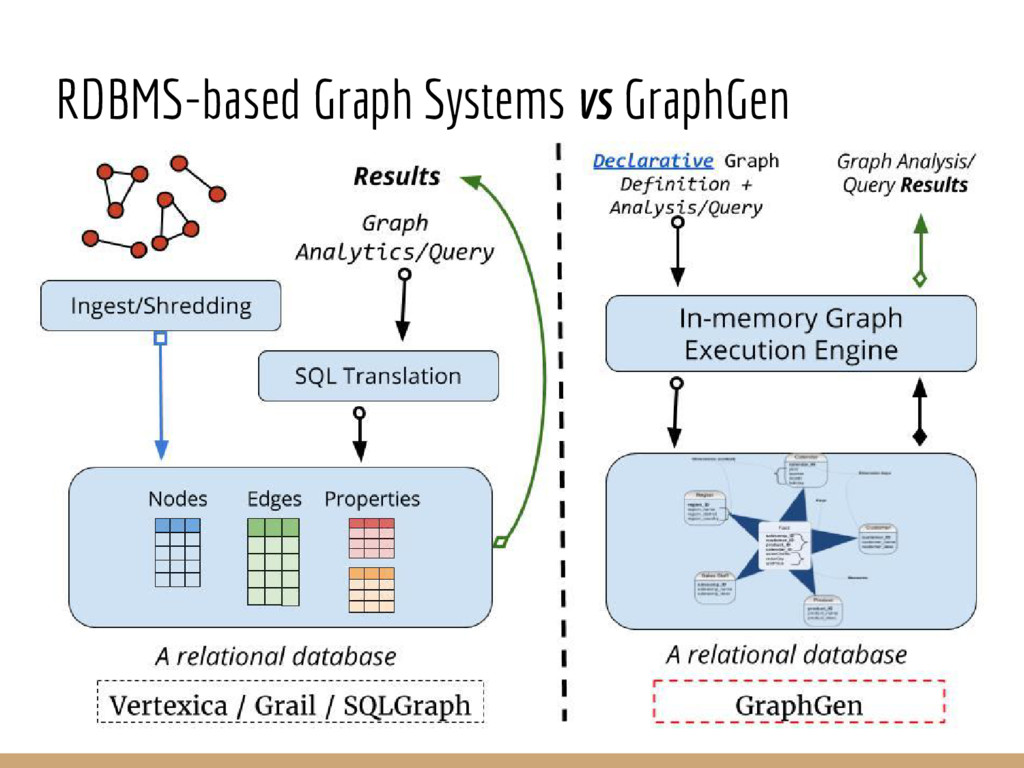
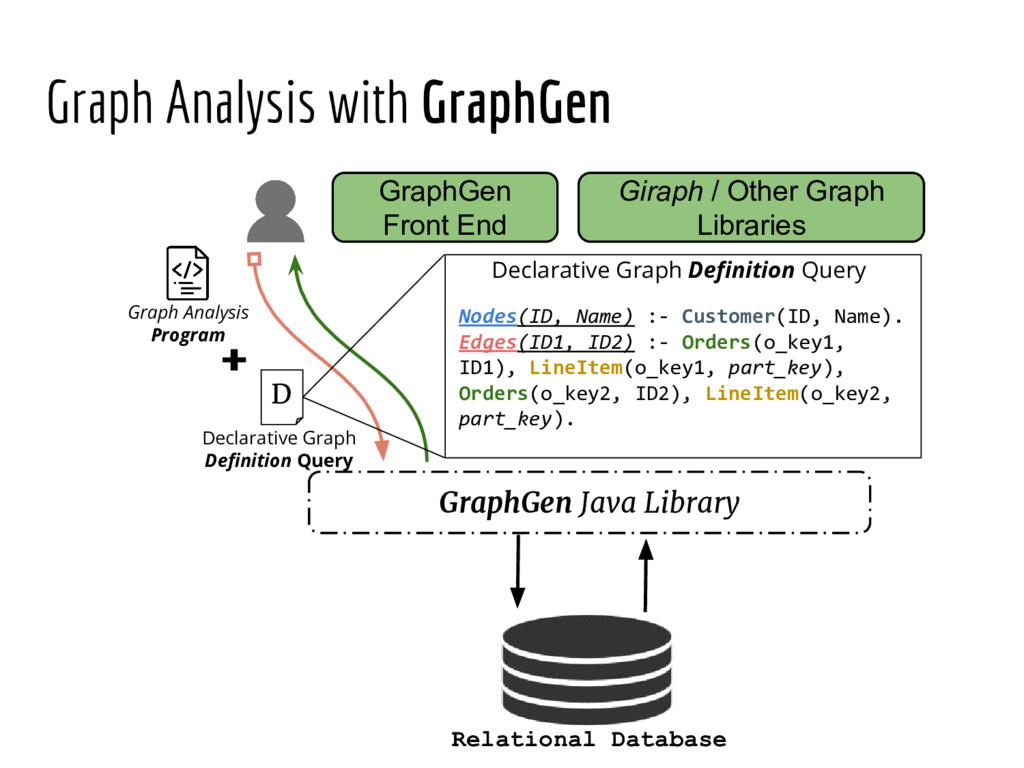
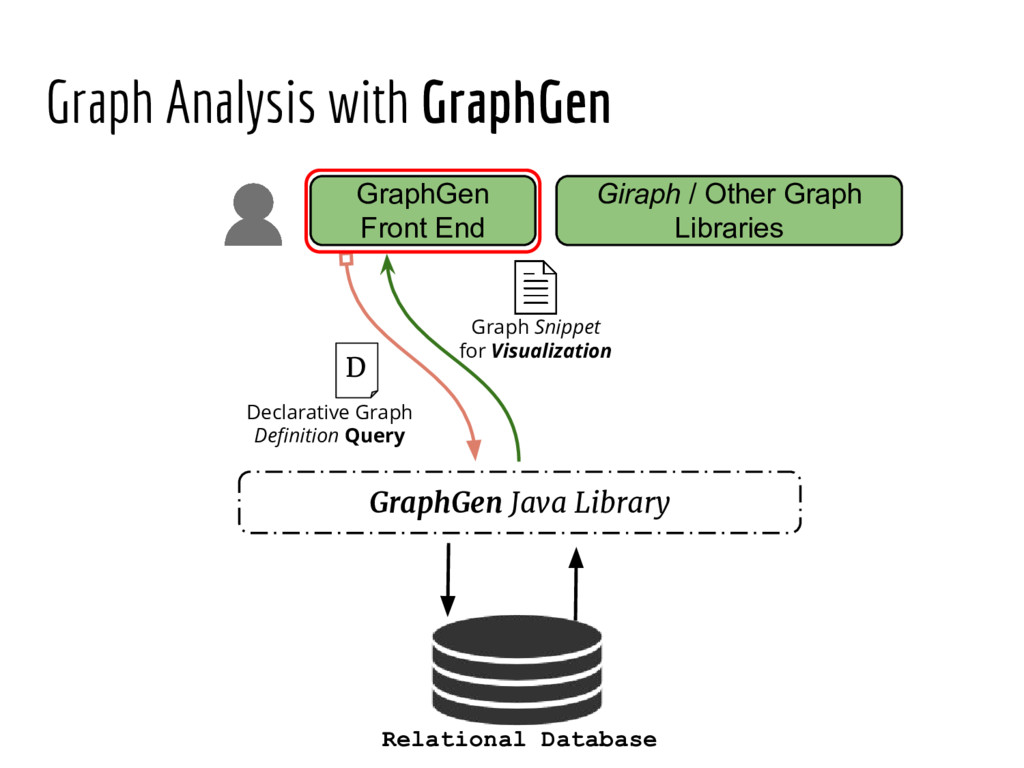
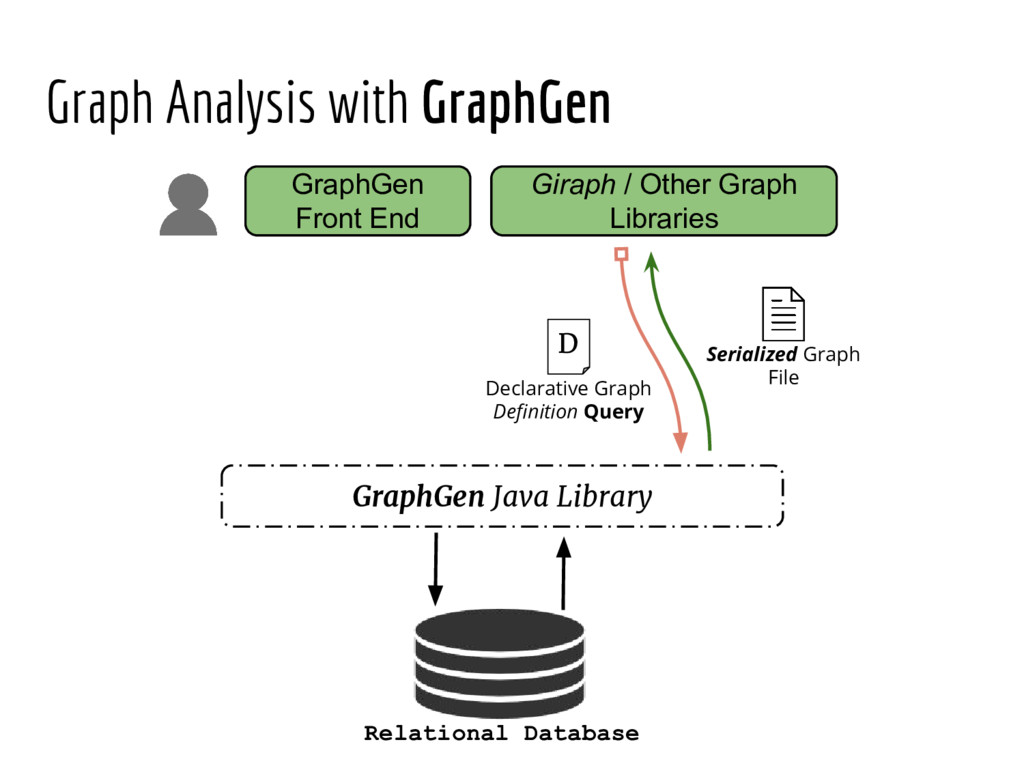
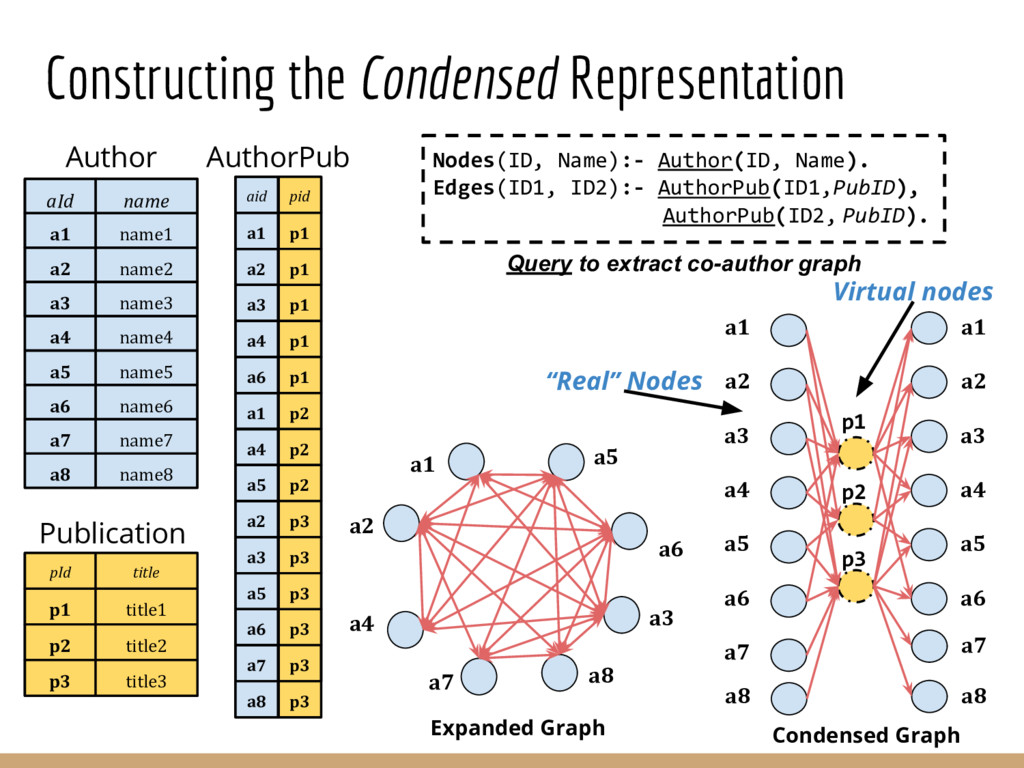
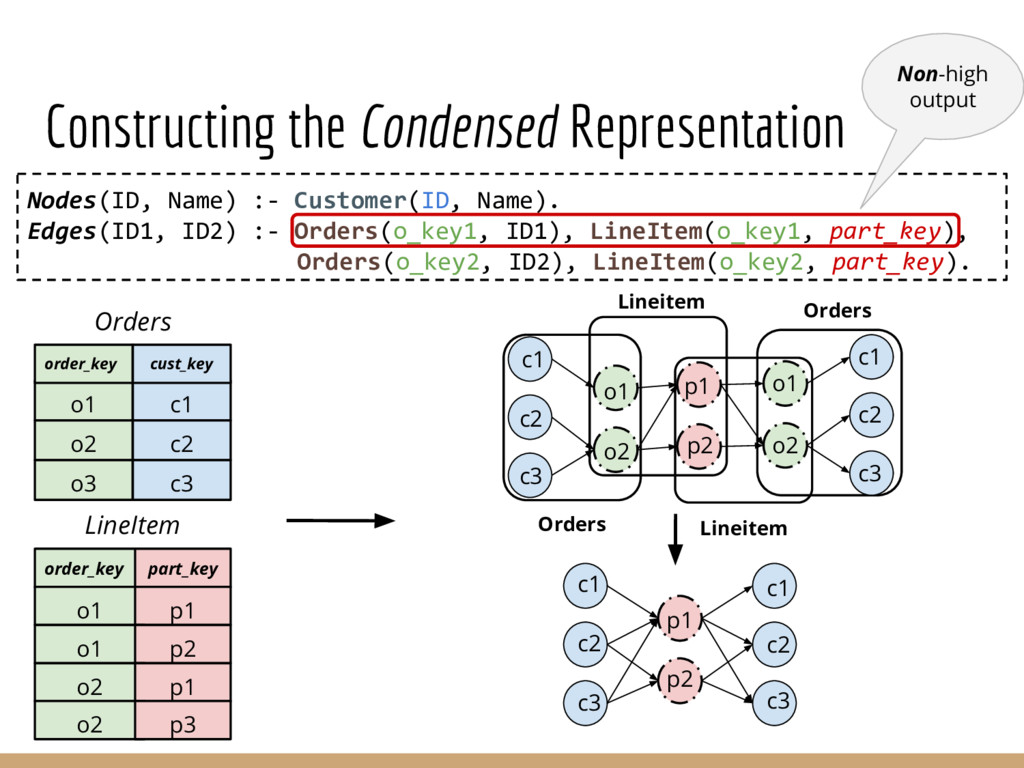
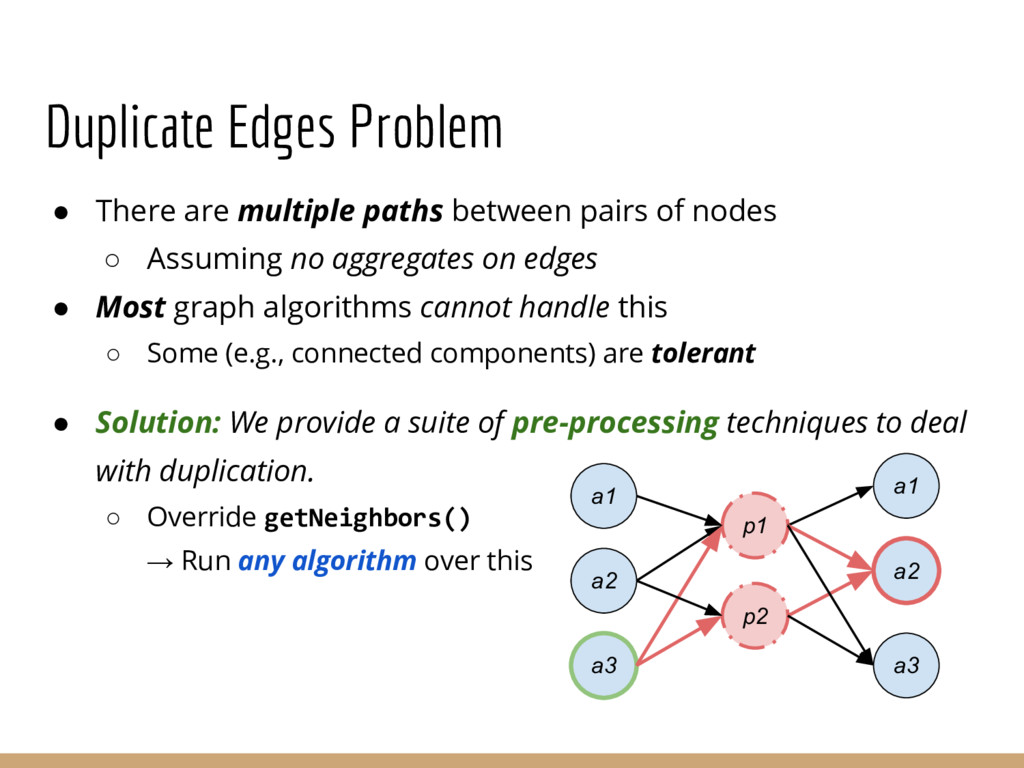
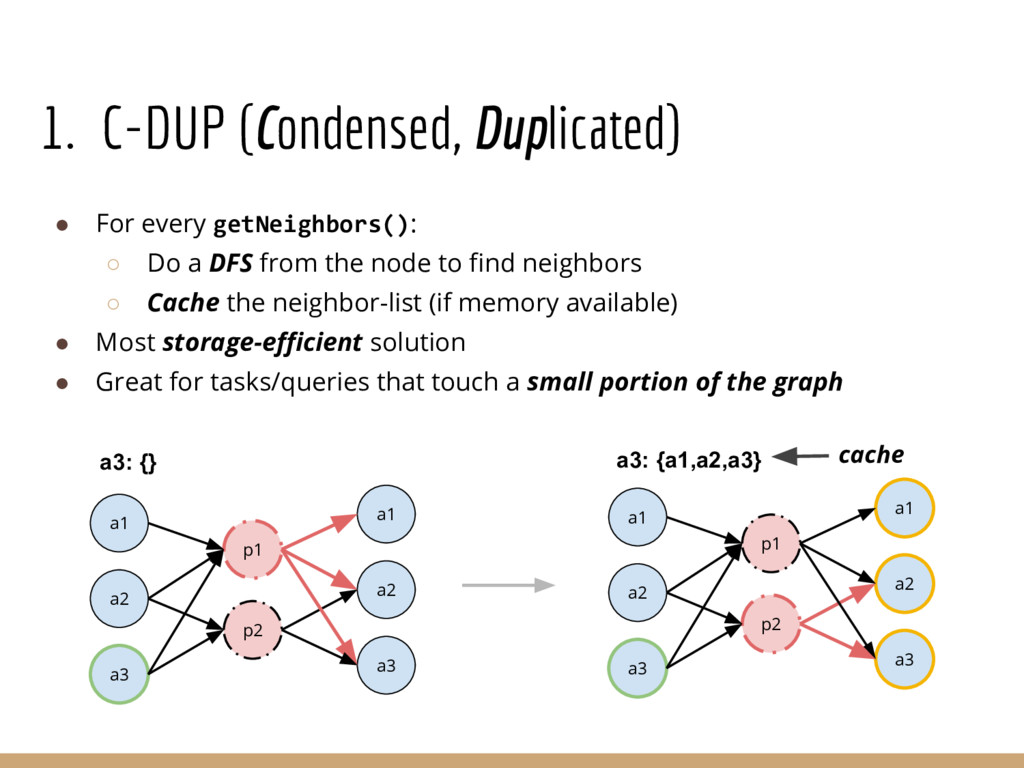
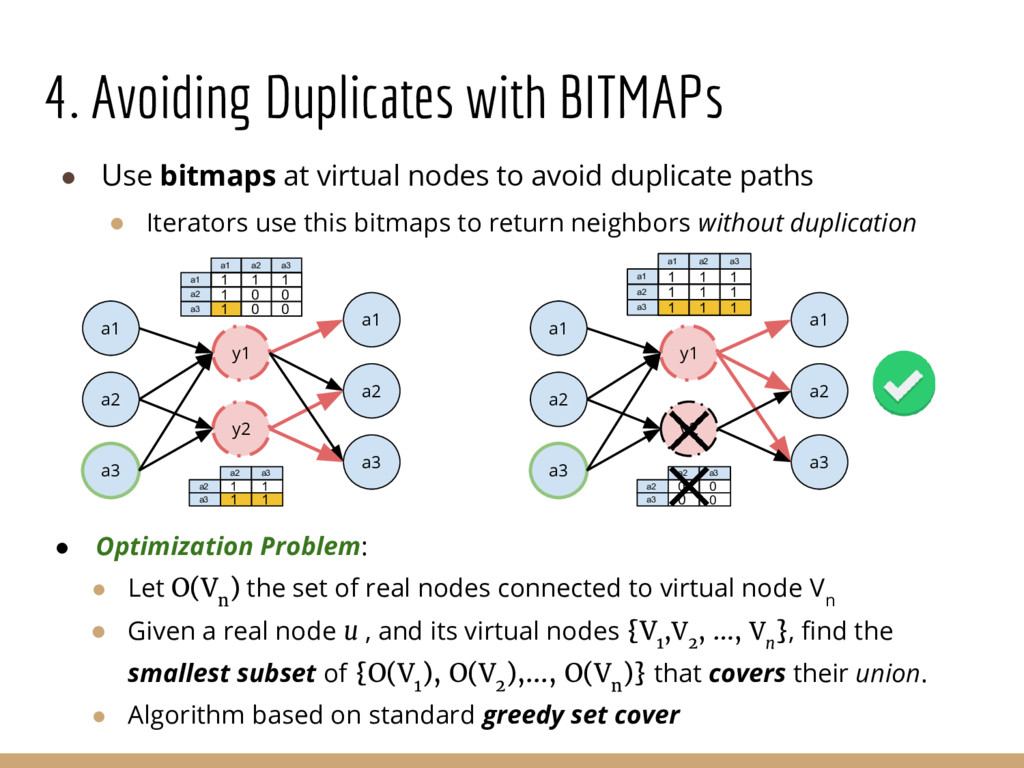
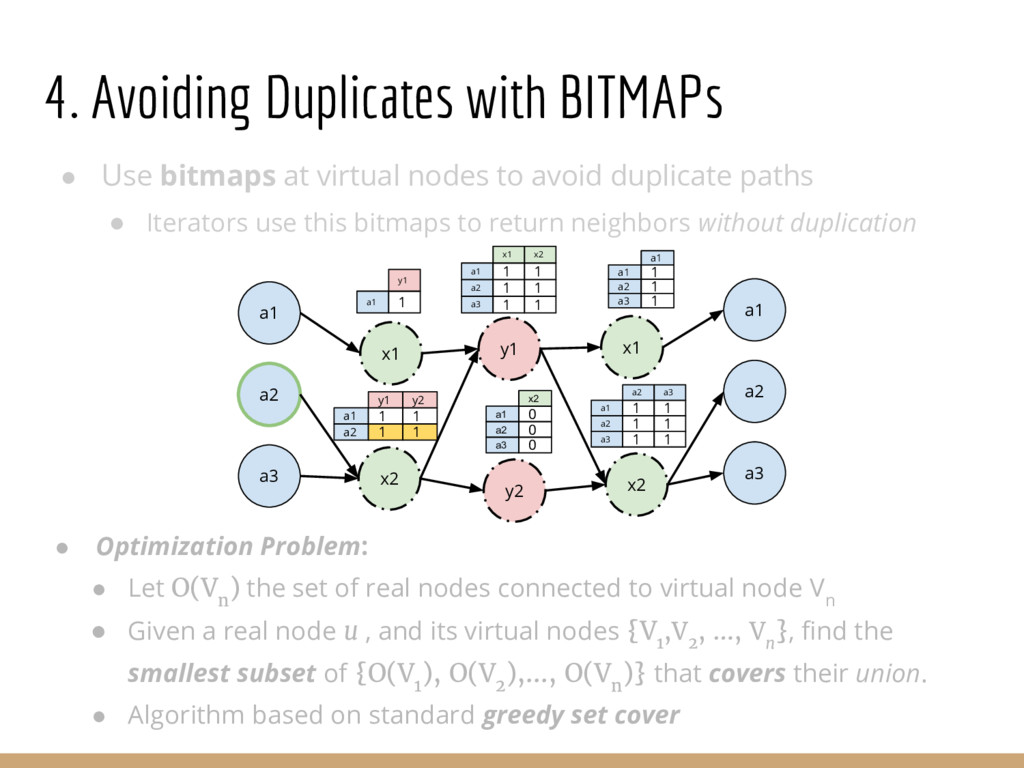
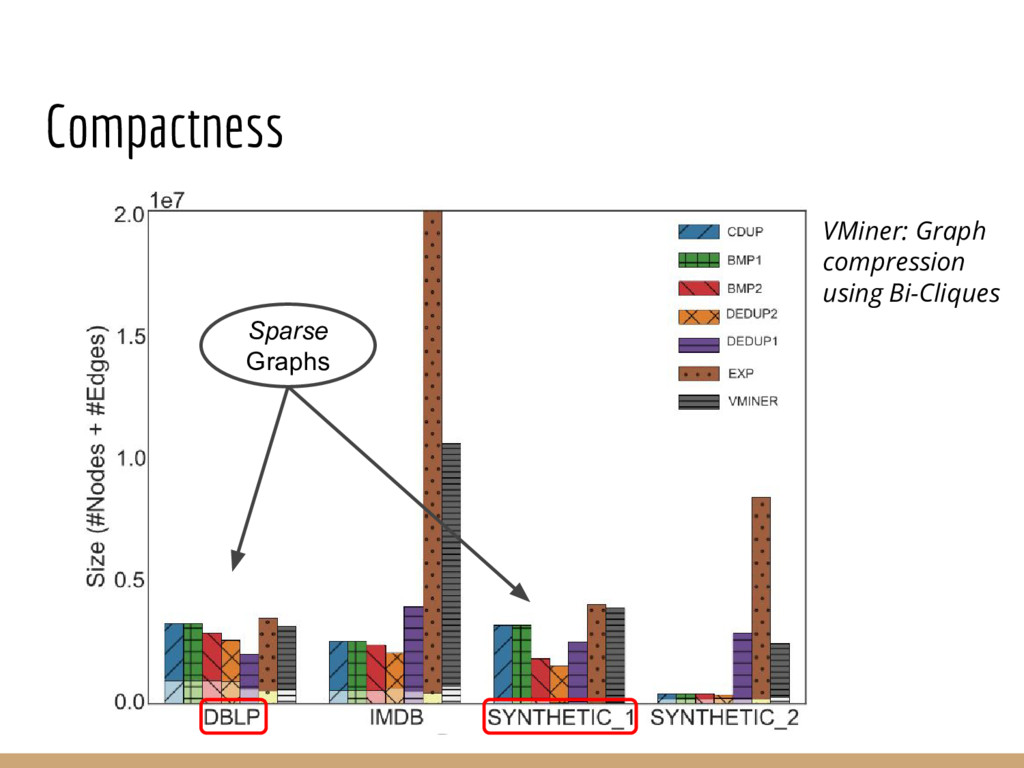
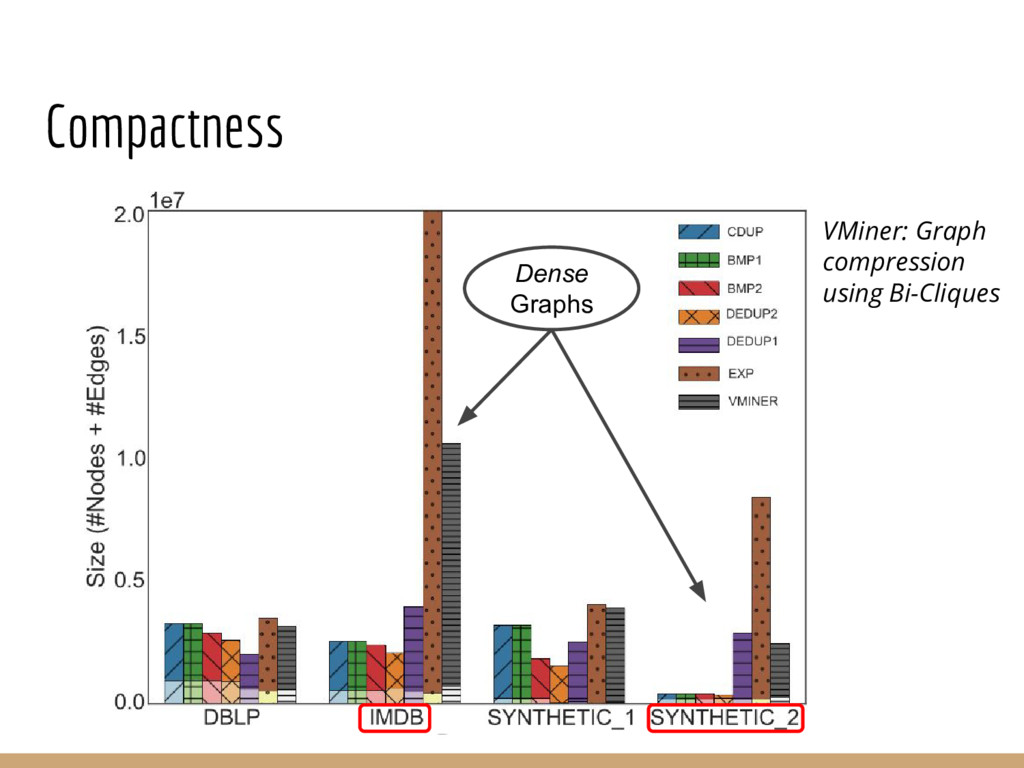
Analyzing interconnection structures among underlying entities or objects in a dataset through the use of graph analytics can provide tremendous value in many application domains. However, graphs are not the primary representation choice for storing most data to- day, and in order to have access to these analyses, users are forced to manually extract data from their data stores, construct the requisite graphs, and then load them into some graph engine in order to execute their graph analysis task. Moreover, in many cases (especially when the graphs are dense), these graphs can be significantly larger than the initial input stored in the database, making it infeasible to construct or analyze such graphs in memory. In this pa- per we address both of these challenges by building a system that enables users to declaratively specify graph extraction tasks over a relational database schema and then execute graph algorithms on the extracted graphs. We propose a declarative domain specific language for this purpose, and pair it up with a novel condensed, in- memory representation that significantly reduces the memory foot- print of these graphs, permitting analysis of larger-than-memory graphs. We present a general algorithm for creating such a condensed representation for a large class of graph extraction queries against arbitrary schemas. We observe that the condensed representation suffers from a duplication issue, that results in inaccuracies for most graph algorithms. We then present a suite of in-memory representations that handle this duplication in different ways and allow trading off the memory required and the computational cost for executing different graph algorithms. We also introduce several novel deduplication algorithms for removing this duplication in the graph, which are of independent interest for graph compression, and provide a comprehensive experimental evaluation over several real-world and synthetic datasets illustrating these trade-offs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GraphGen Visual Front End [VLDB 2015 Demo] User can visually](https://files.speakerdeck.com/presentations/c4e69f0ef6ed4376b48abbf19891b2b4/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
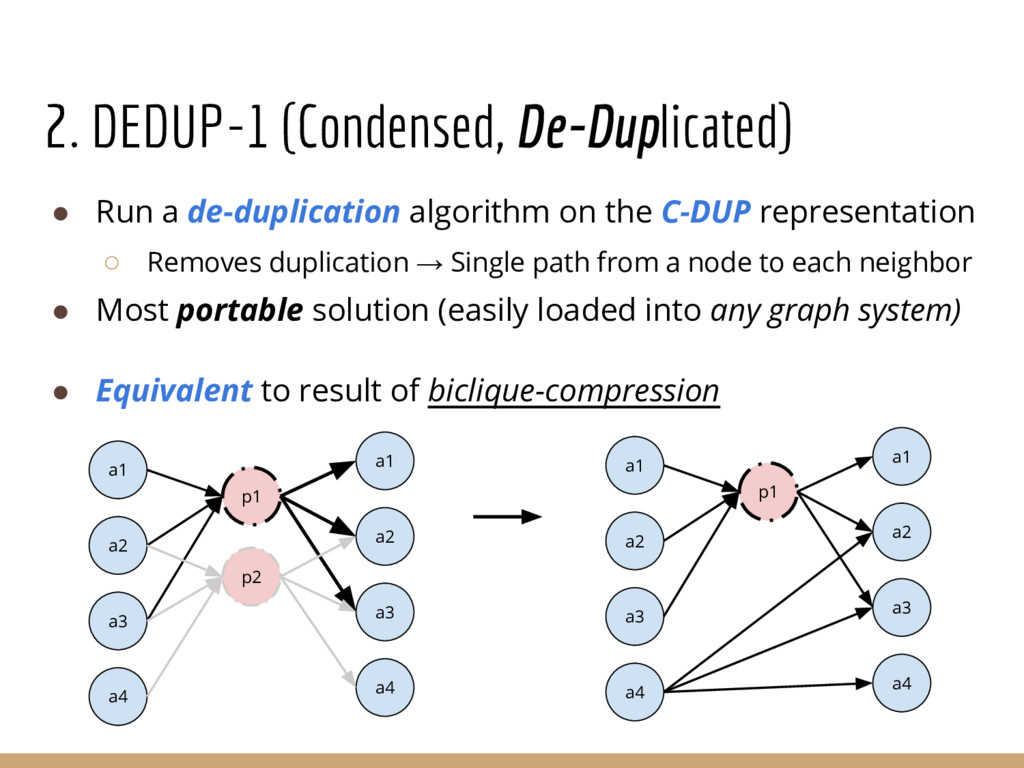{kind=link}
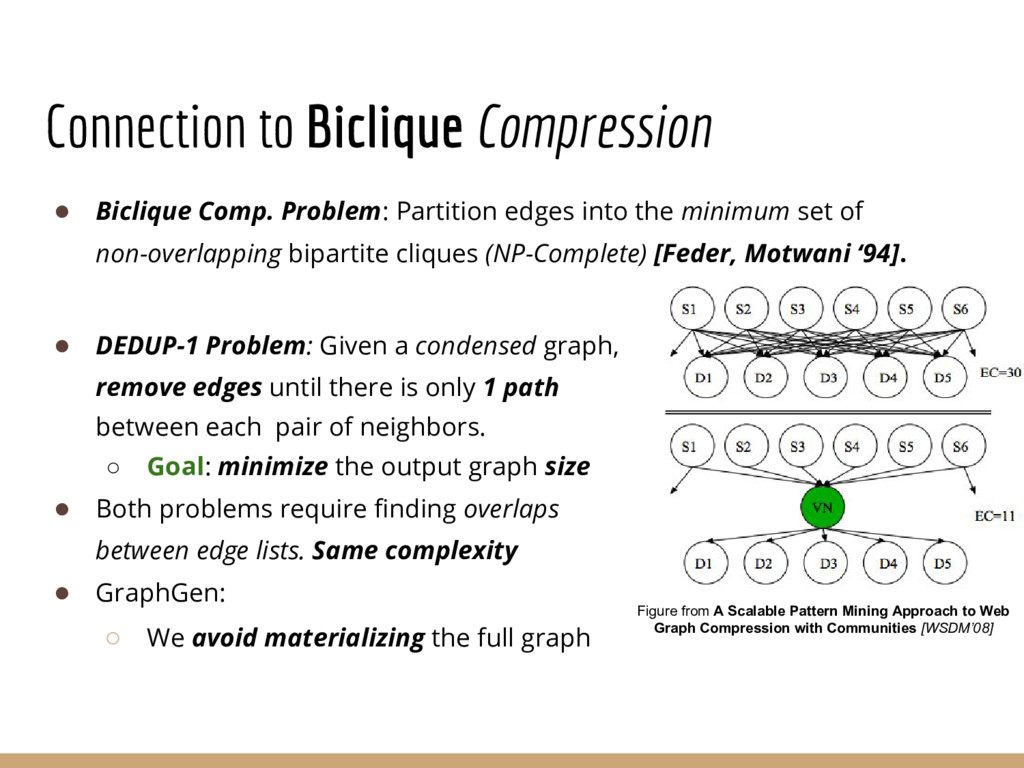{kind=link}
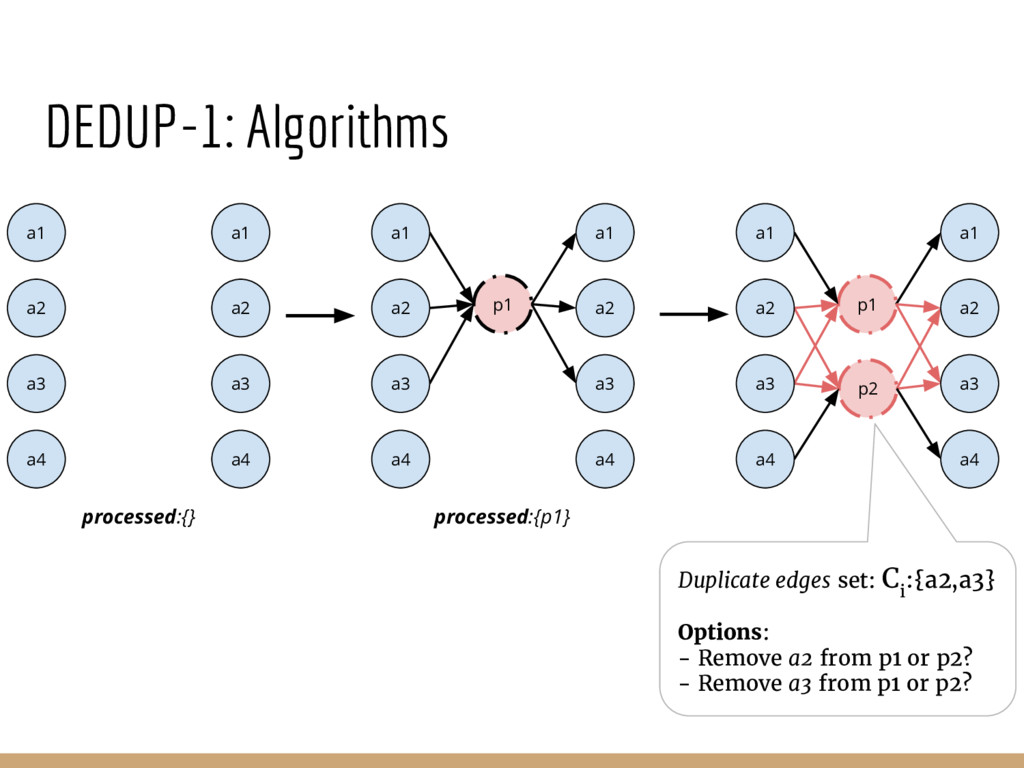{kind=link}
{kind=link}
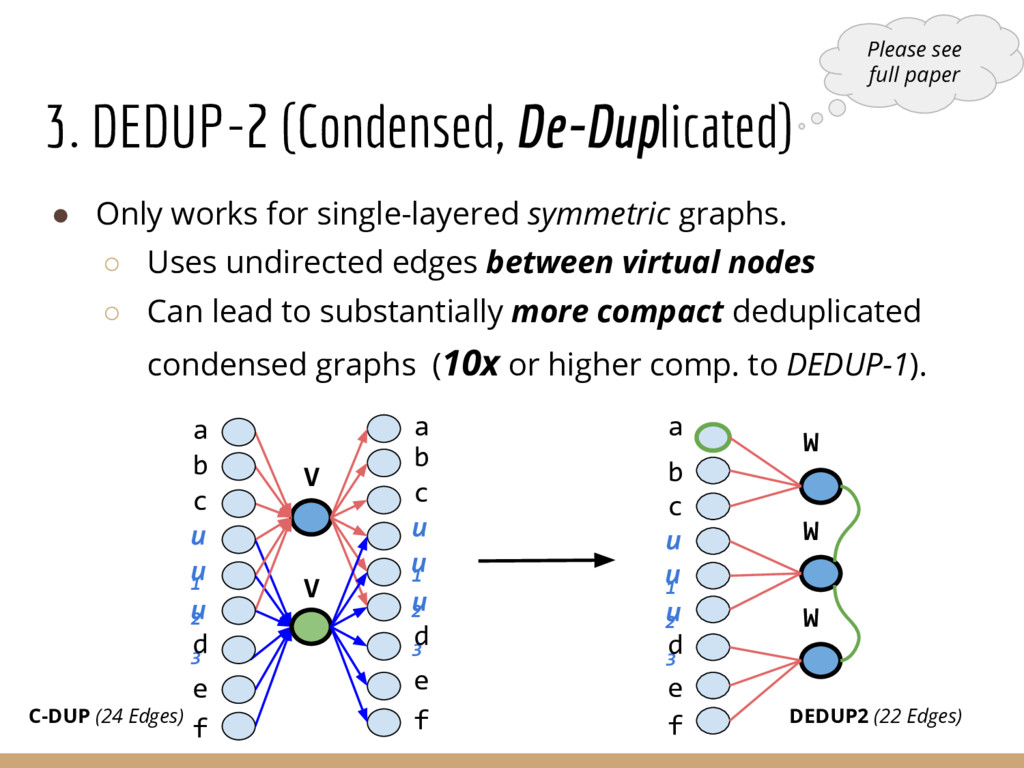{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
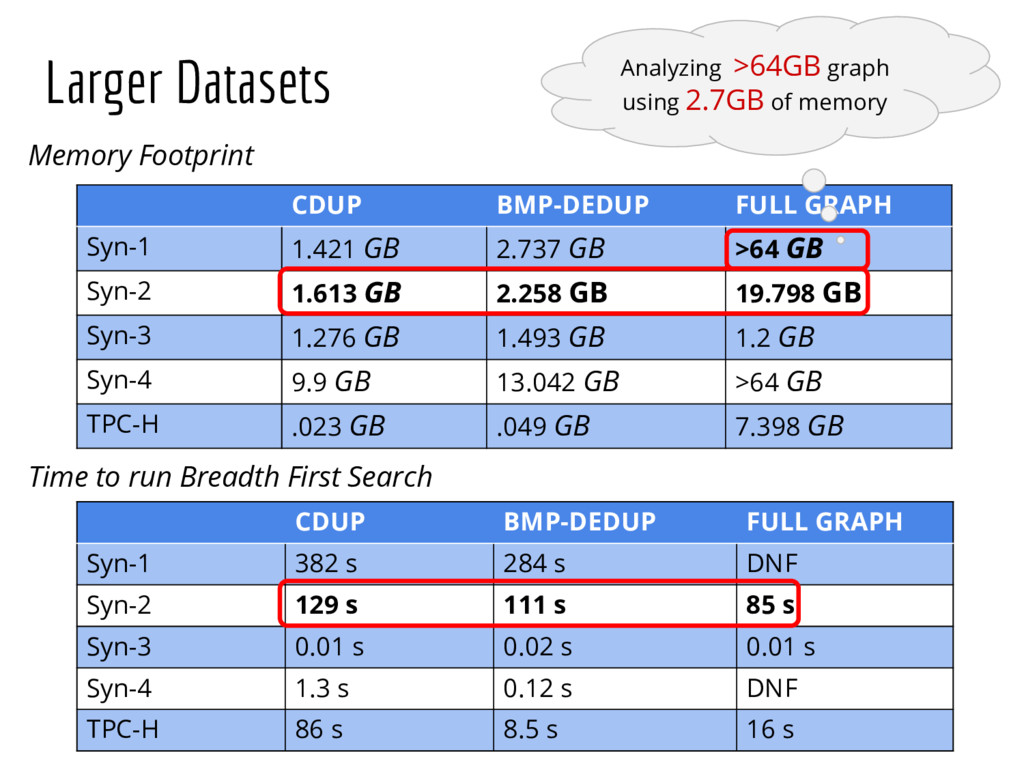{kind=link}
{kind=link}
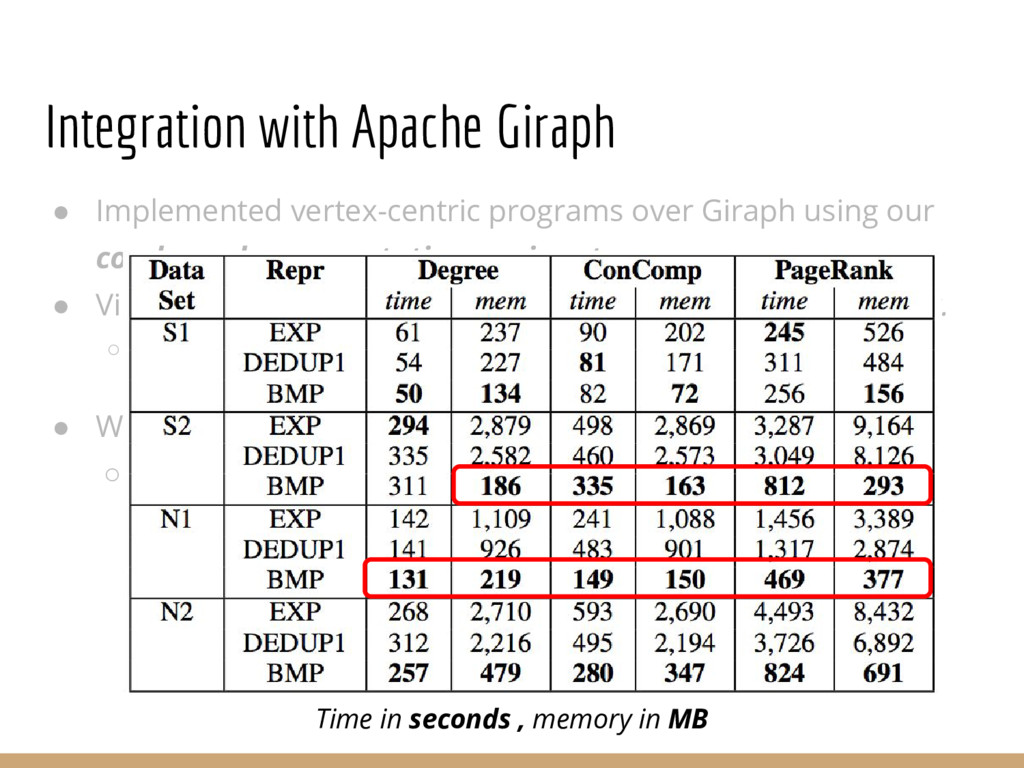{kind=link}
{kind=link}