Hybrid GPU Orchestration for Enterprise AI at Scale
In this presentation, I dive into how to think about hybrid GPU-enabled workloads and why HashiCorp Nomad is the right foundation for an Enterprise AI platform.
This version of the talk was given at IBM's booth at NVIDIA GTC in March 2026.
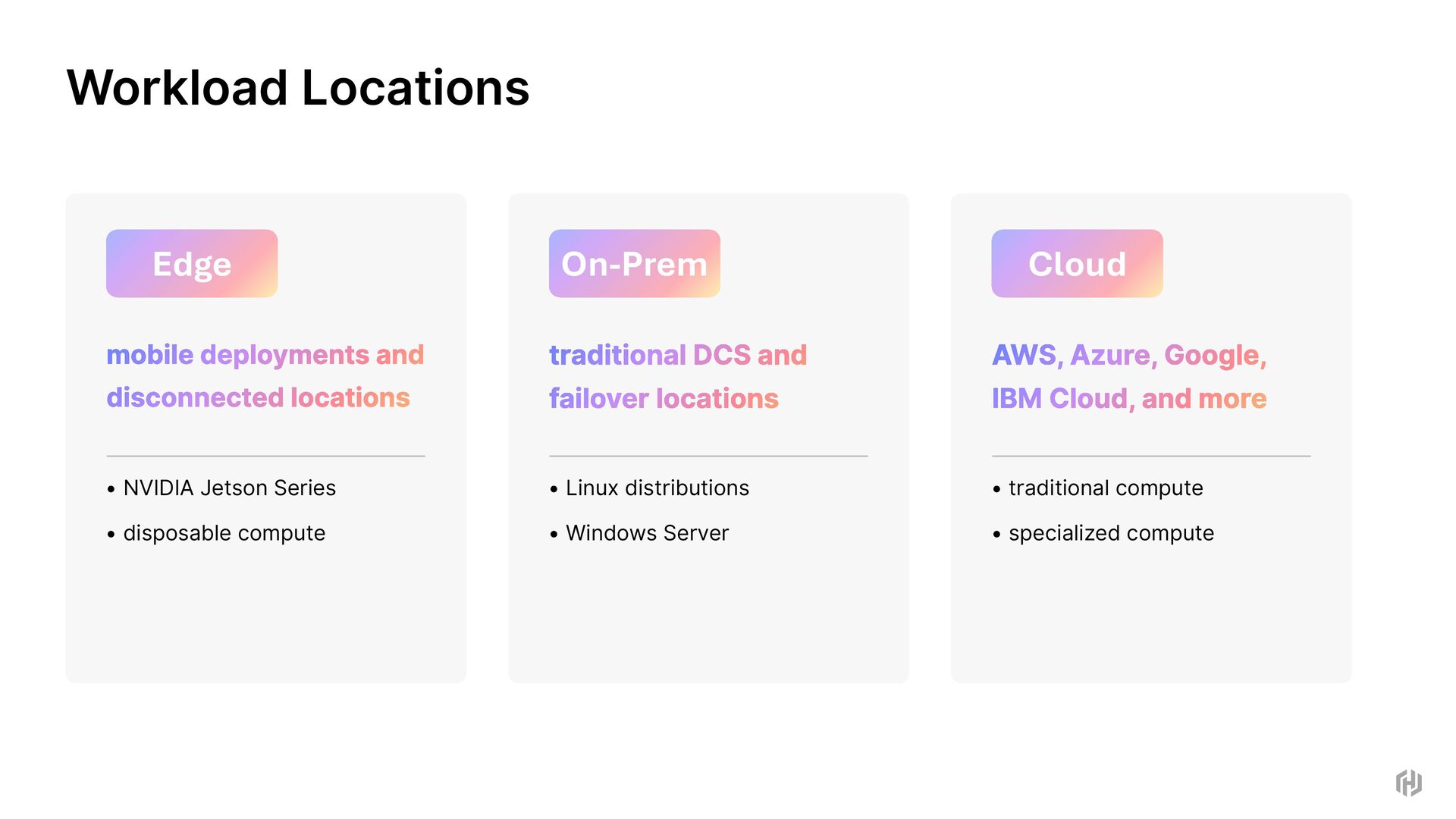
disposable compute Edge traditional DCS and failover locations • Linux distributions • Windows Server On-Prem AWS, Azure, Google, IBM Cloud, and more • traditional compute • specialized compute Cloud Workload Locations
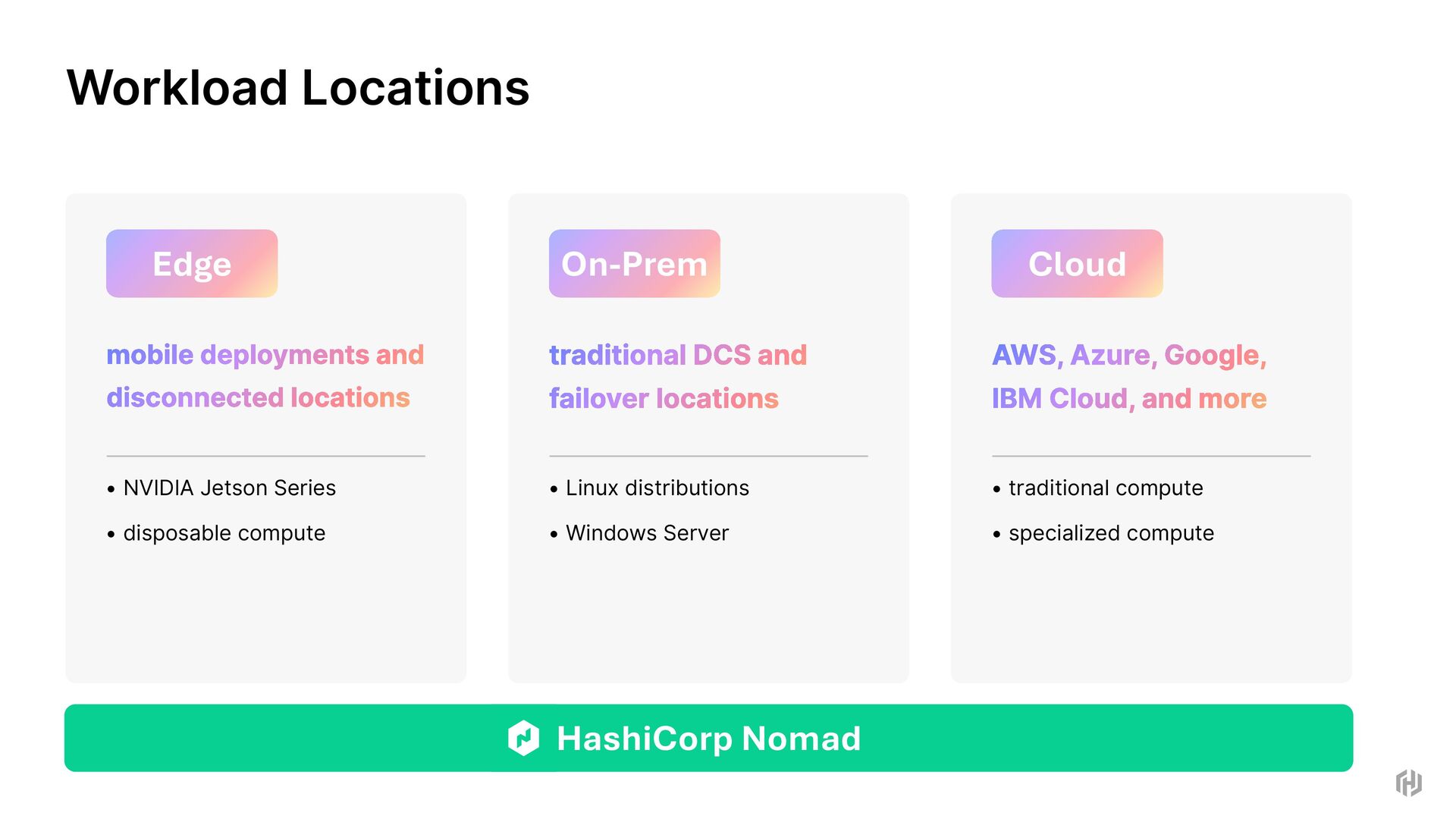
disposable compute Edge traditional DCS and failover locations • Linux distributions • Windows Server On-Prem AWS, Azure, Google, IBM Cloud, and more • traditional compute • specialized compute Cloud Workload Locations HashiCorp Nomad
of job • update strategy defines atomic units of work • driver selection • task environment • resource requirements defines how to co-locate tasks • network config • volume config • service discovery Task Job Group Workload Specification
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
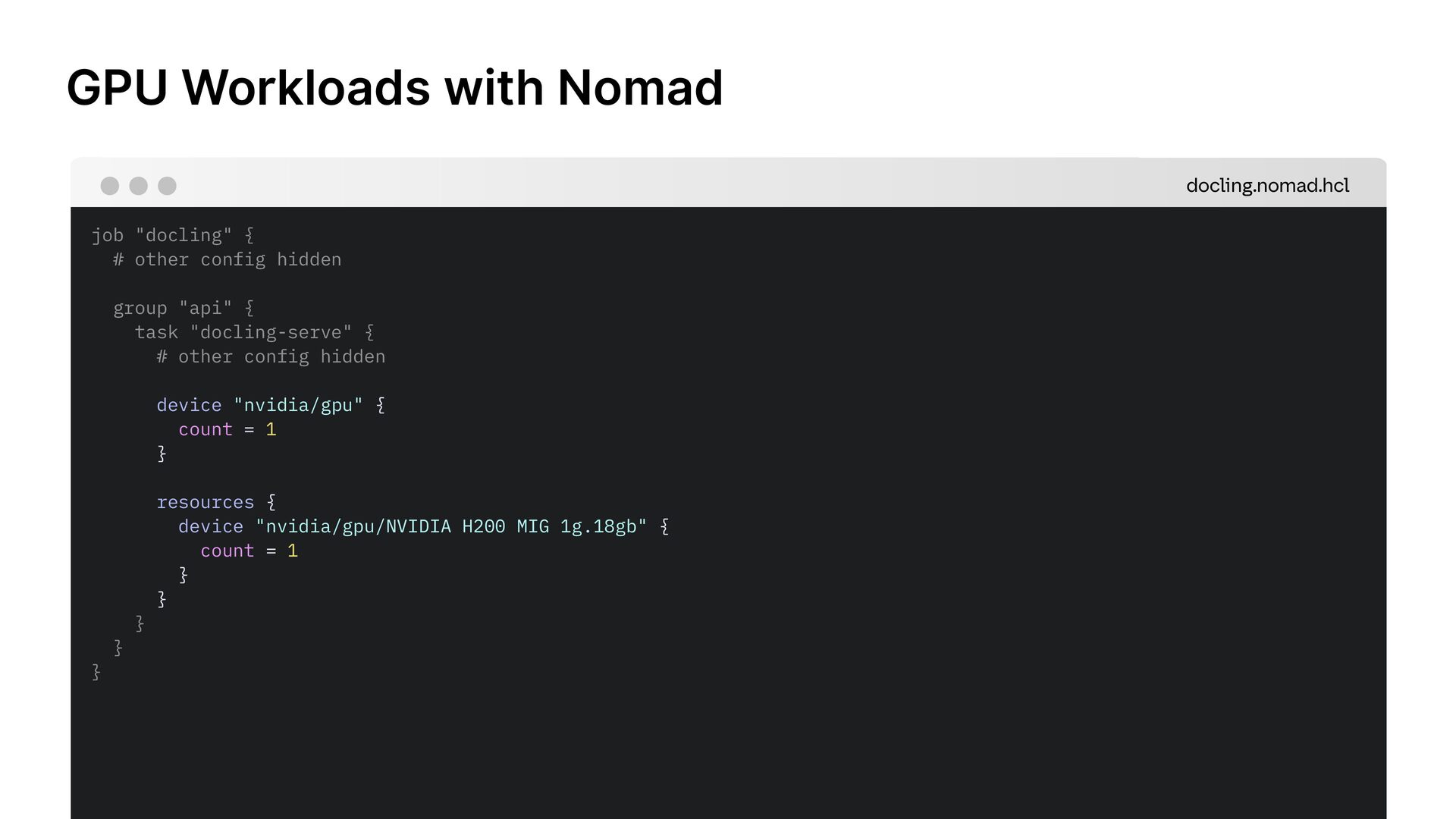
![GPU Workloads with Nomad job "docling" { datacenters = ["dc1"]](https://files.speakerdeck.com/presentations/a716eccd0ed047a498cdf71de95fa936/slide_20.jpg){kind=link}
![GPU Workloads with Nomad job "docling" { datacenters = ["dc1"]](https://files.speakerdeck.com/presentations/a716eccd0ed047a498cdf71de95fa936/slide_21.jpg){kind=link}
![GPU Workloads with Nomad job "docling" { datacenters = ["dc1"]](https://files.speakerdeck.com/presentations/a716eccd0ed047a498cdf71de95fa936/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}