repl with vector clocks based on Client Ids • Riak 1.x: Quorum-based repl with vector clocks based on Vnode Ids • Riak 2.0: CRDTs and DVVs • Riak 2.x: MultiPaxos • Machi: Chain Replication
database can keep consistency (of atomic objects) and availability under network partition • One of FLP impossibility indications: • No consensus; Atomic objects (nodes) cannot be maintained consistent under failure of majority and delay • Network is not reliable[7] and no database has tried to tolerate these failures before Dynamo and Riak
the same order, while concurrent writes may be seen in different order in different observers • Alternative guarantee in available system that tolerates any kind of network partition • Works under network partition, failures, delay, whatever, because it does not need coordination (vs Strong Consistency) • Allow multiple values but tracking causality of those values matters
kept as siblings • Caused by hot key, slow clients, network partition, failure, bugs, retry, etc • Even just by two clients! • Better than losing data, but screws up VM, GC, backend, etc C2
30 40 50 60 70 80 Number of Siblings Duration [sec] Number of siblings in DVV=false, 4 nodes concurrency=8 concurrency=16 concurrency=32 0 20 40 60 80 100 0 50 100 150 200 250 Number of Siblings Duration [sec] Number of siblings in DVV=true, 4 nodes concurrency=8 concurrency=16 concurrency=32 With sibling_benchmark.erl: http://bit.ly/1TPcwwc
Amazon S3 API • Breaks large object to 1MB chunks and stores as write-once registers of Riak keys • Chunks are write once registers, and each manifest points to single version described by UUID • ~10^3 TB or more
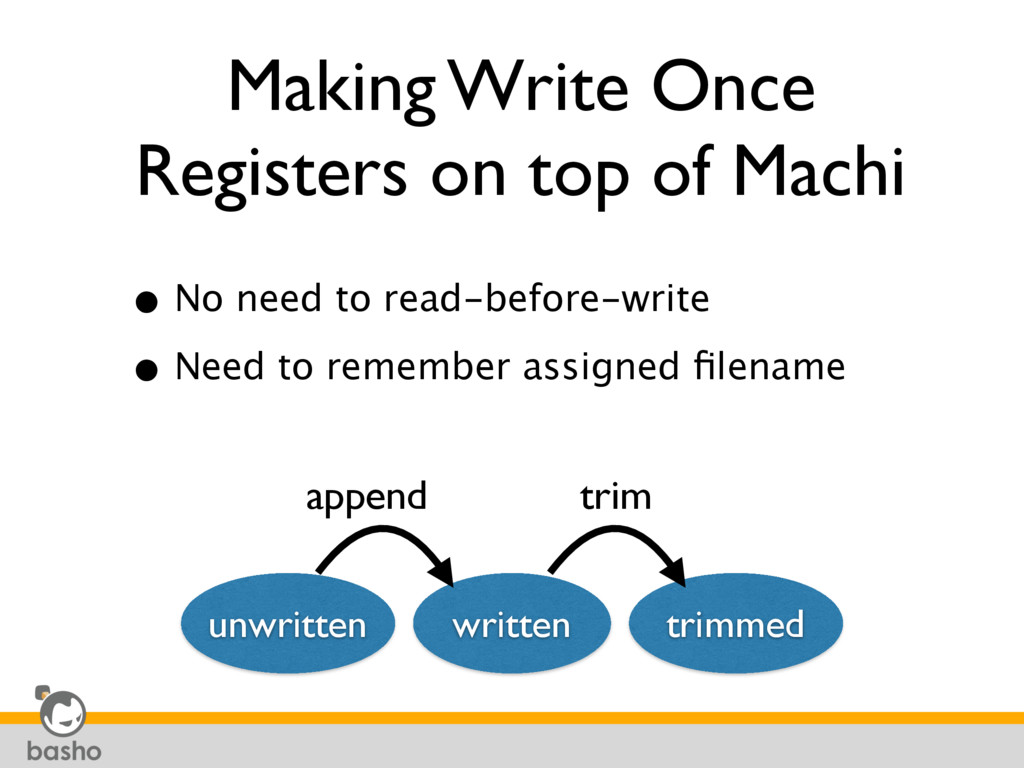
the system • No implicit overwrite happens • No need to track causality • Every byte has simple state transition: • unwritten => written => trimmed • Choose AP (eventual consistency) and CP (strong consistency) mode with single replication protocol
• AP mode • Split the chain and manipulate heads • Assign different names from same prefix • CP mode • Replicate until live nodes in chain is still majority [H, M1, M2, T] [H, M1, T], [M2] [H, M1] [M2, T]
Machi source code: https://github.com/basho/machi • [3] CORFU: A Distributed Shared Log for Flash Clusters • http://research.microsoft.com/apps/pubs/default.aspx?id=157204 • [4] A Brief History of Time in Riak • https://speakerdeck.com/seancribbs/a-brief-history-of-time-in-riak • https://www.youtube.com/watch?v=3SWSw3mKApM • [5] Managing Chain Replication with Humming Consensus • http://ricon.io/speakers/slides/Scott_Fritchie_Ricon_2015.pdf • https://www.youtube.com/watch?v=yR5kHL1bu1Q • [6] Version Vectors are not Vector Clocks, [7] The Network is Reliable
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Causality graph with vanilla VV B [B,C] C [B,C,D] D](https://files.speakerdeck.com/presentations/a16537d77cbc476b88a0d30ccc86b5a1/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
![Causality graph with DVV B [B,C] C [C,D] D [D,E]](https://files.speakerdeck.com/presentations/a16537d77cbc476b88a0d30ccc86b5a1/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Important Resources • [1] Riak source code: https://github.com/basho/riak • [2]](https://files.speakerdeck.com/presentations/a16537d77cbc476b88a0d30ccc86b5a1/slide_25.jpg){kind=link}