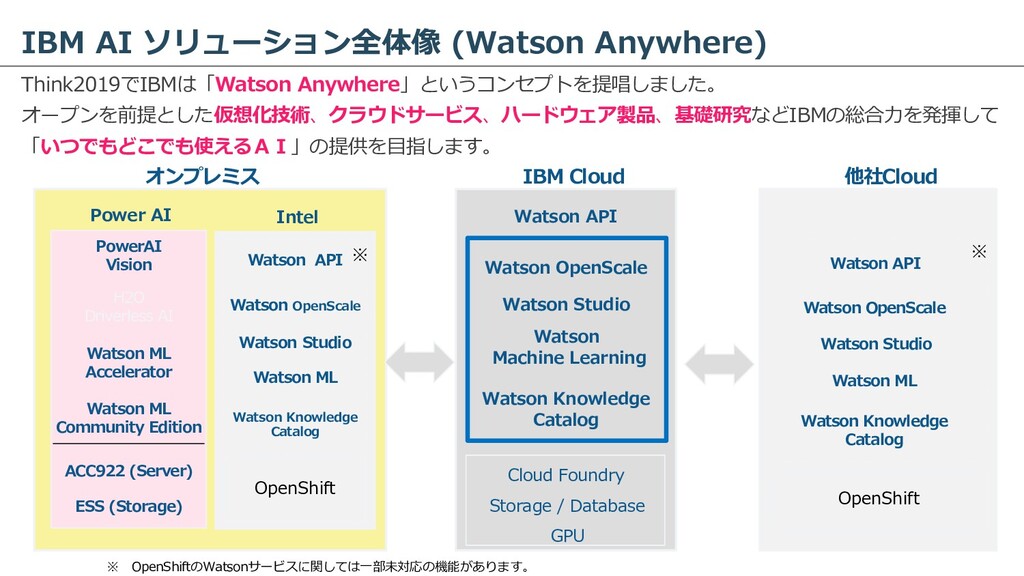
IBM Cloud 他社Cloud Power AI Intel ESS (Storage) ACC922 (Server) Watson ML Community Edition Watson ML Accelerator PowerAI Vision H2O Driverless AI OpenShift Watson Knowledge Catalog Watson ML Watson Studio Watson OpenScale Watson API OpenShift Watson Knowledge Catalog Watson ML Watson Studio Watson OpenScale Watson API Watson Knowledge Catalog Watson Machine Learning Watson Studio Watson OpenScale Watson API Cloud Foundry Storage / Database GPU ※ ※ ※ OpenShiftのWatsonサービスに関しては⼀部未対応の機能があります。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
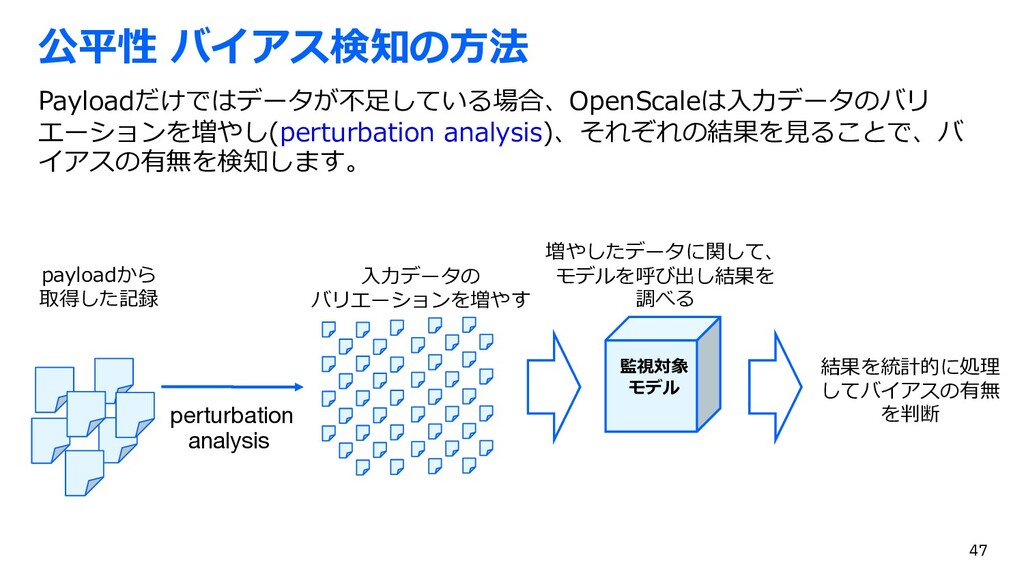{kind=link}
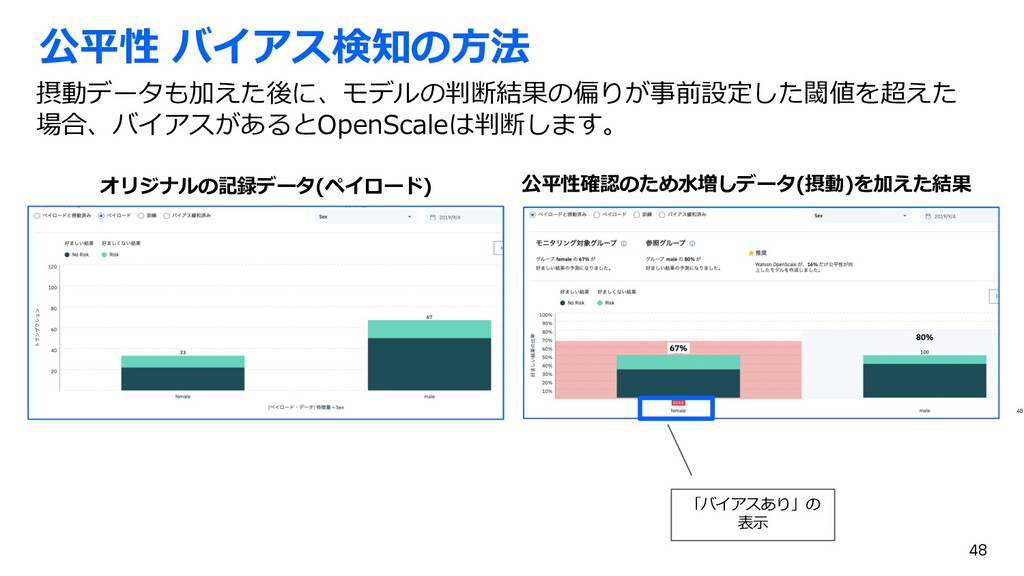{kind=link}
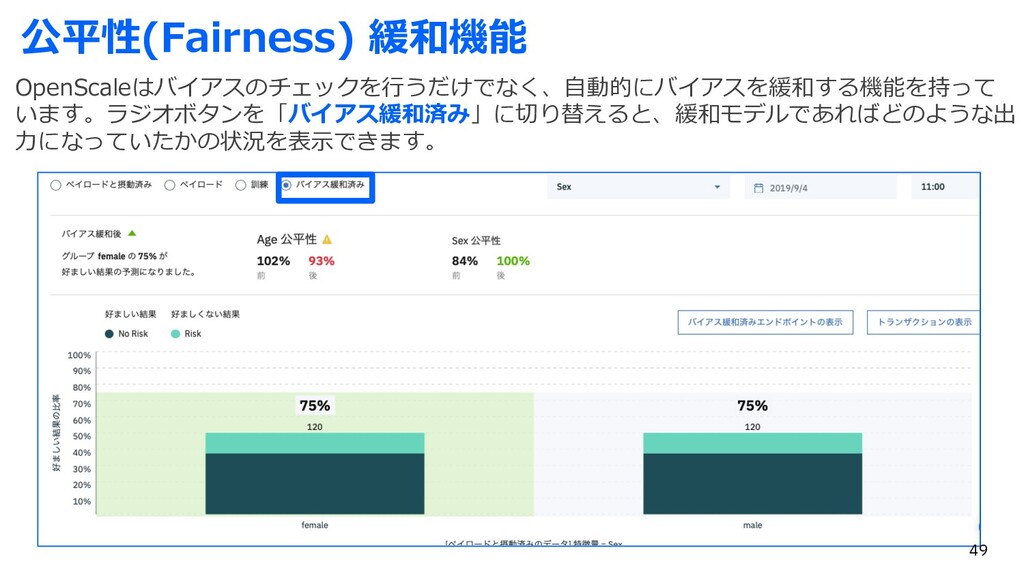{kind=link}
{kind=link}
{kind=link}
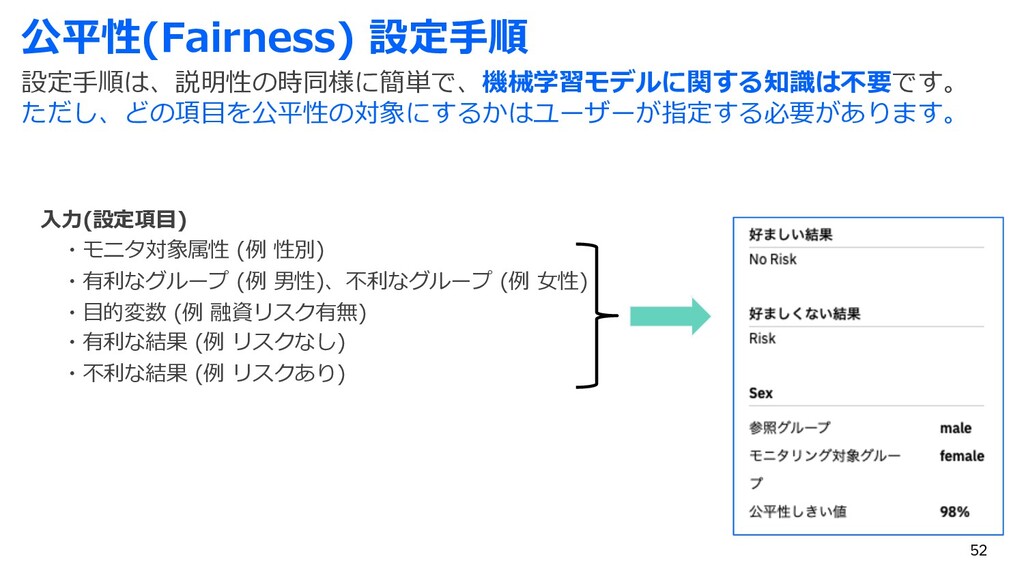{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
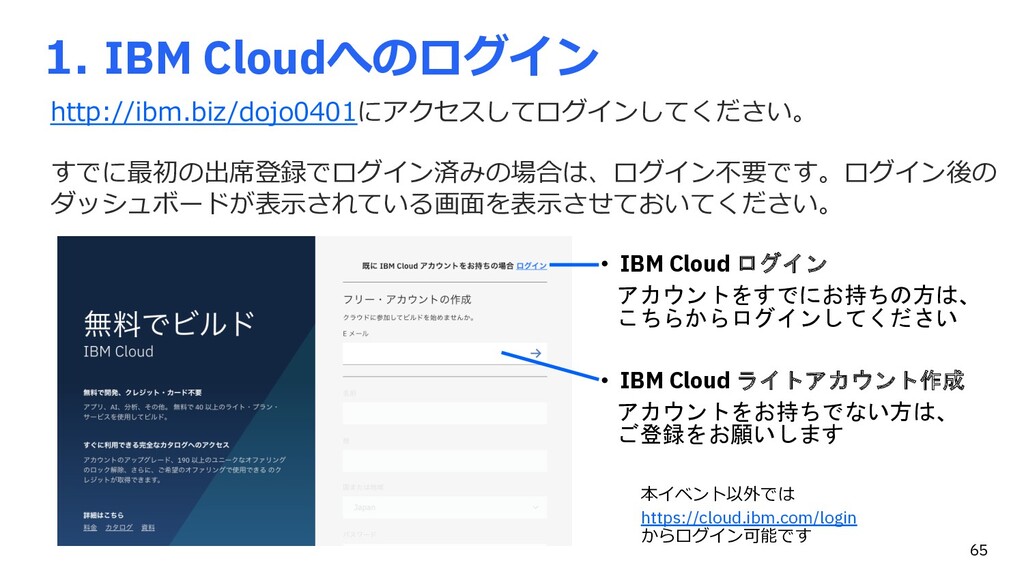{kind=link}
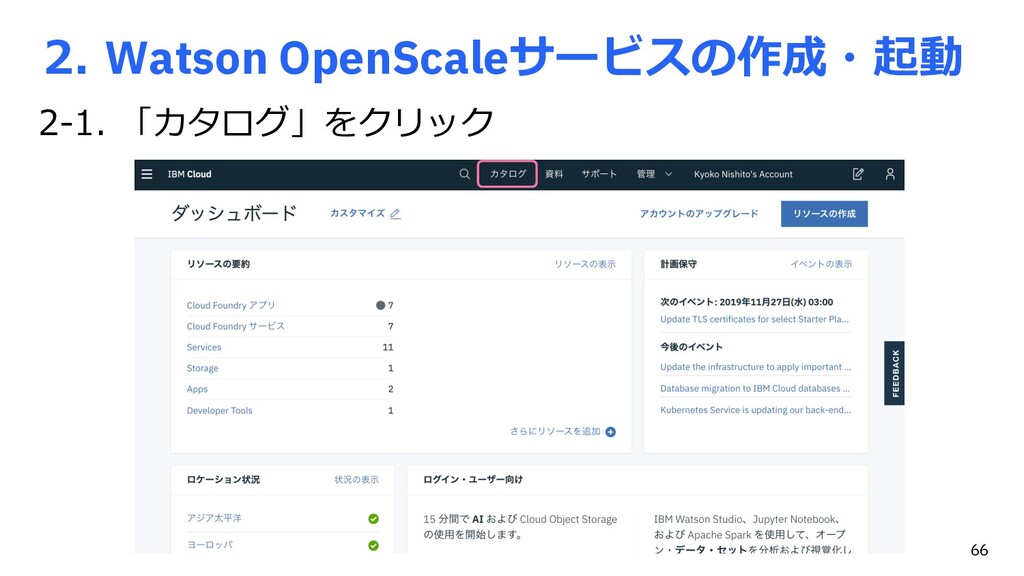{kind=link}
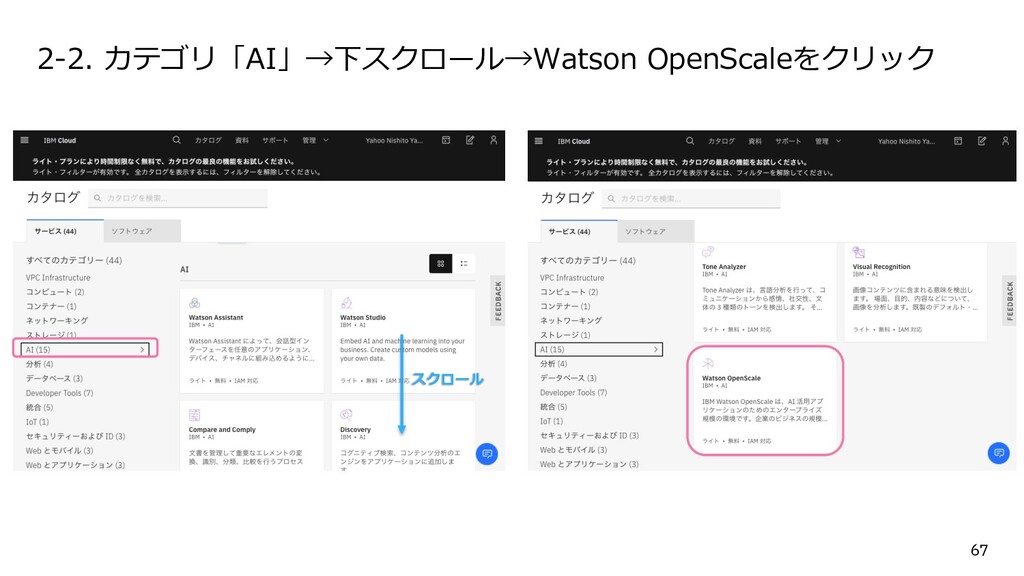{kind=link}
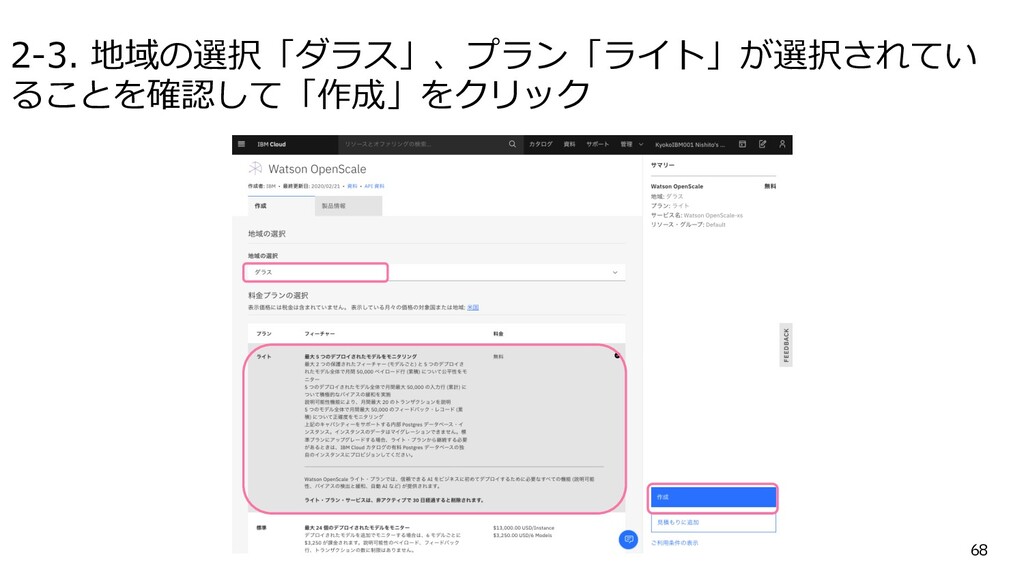{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![4. .Watson OpenScaleを体験 4-1. Watson OpenScale ダッシュボードのツアーが開始され ますので、[次へ]をクリックしながら解説読み進めます。 74](https://files.speakerdeck.com/presentations/5816126a1cb740b5b09bc36557c43c3b/slide_73.jpg){kind=link}
{kind=link}
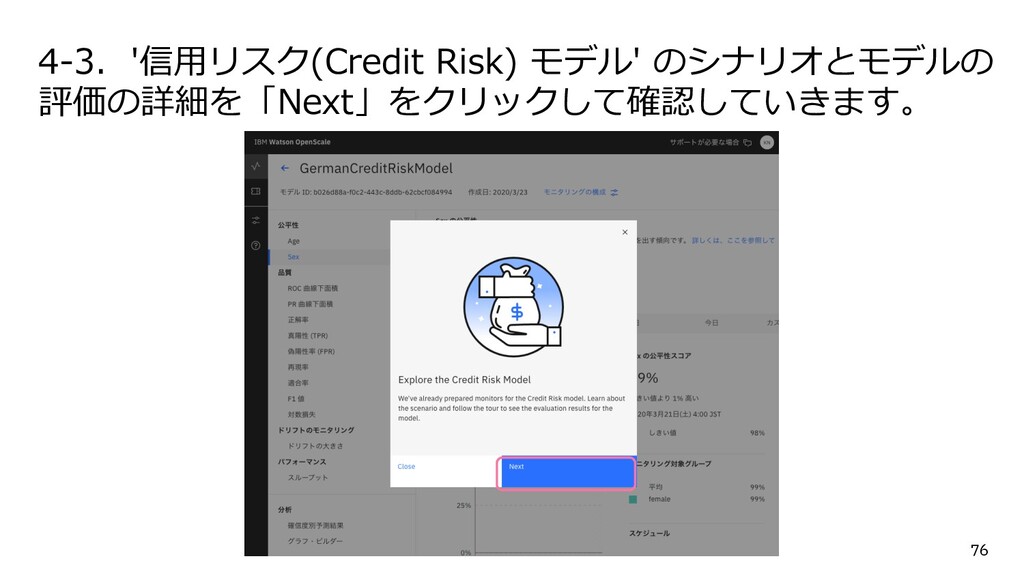{kind=link}
{kind=link}
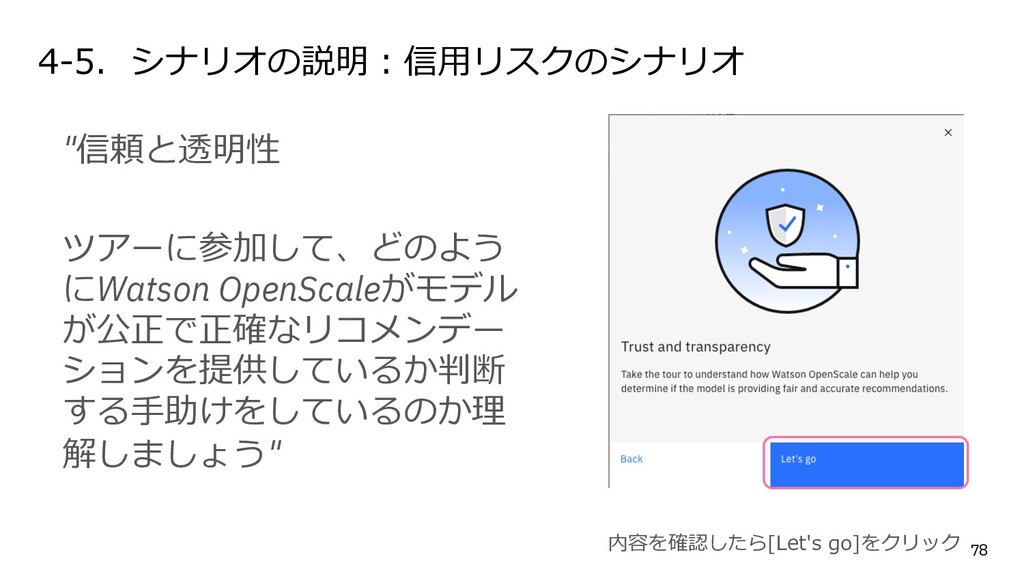{kind=link}
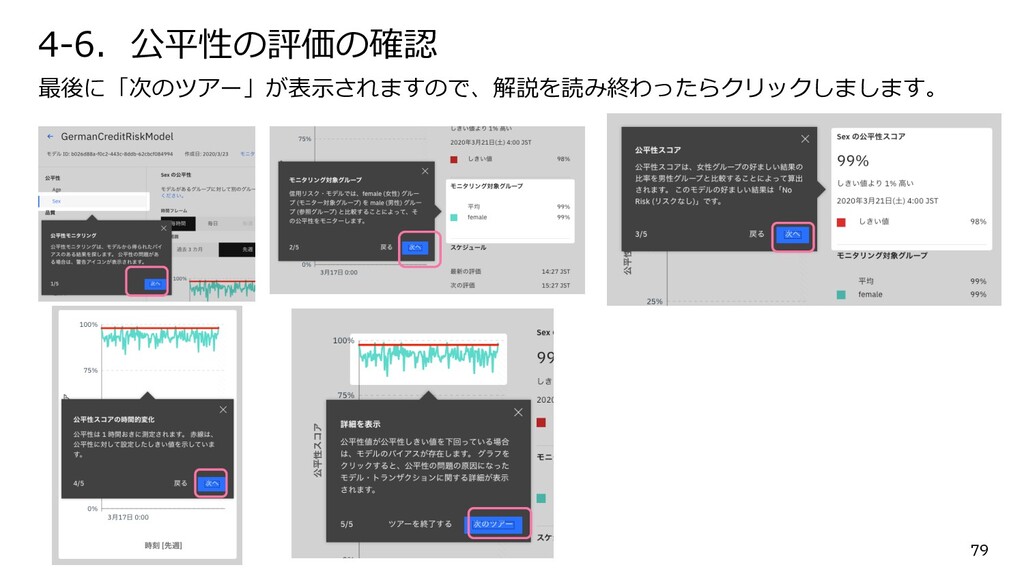{kind=link}
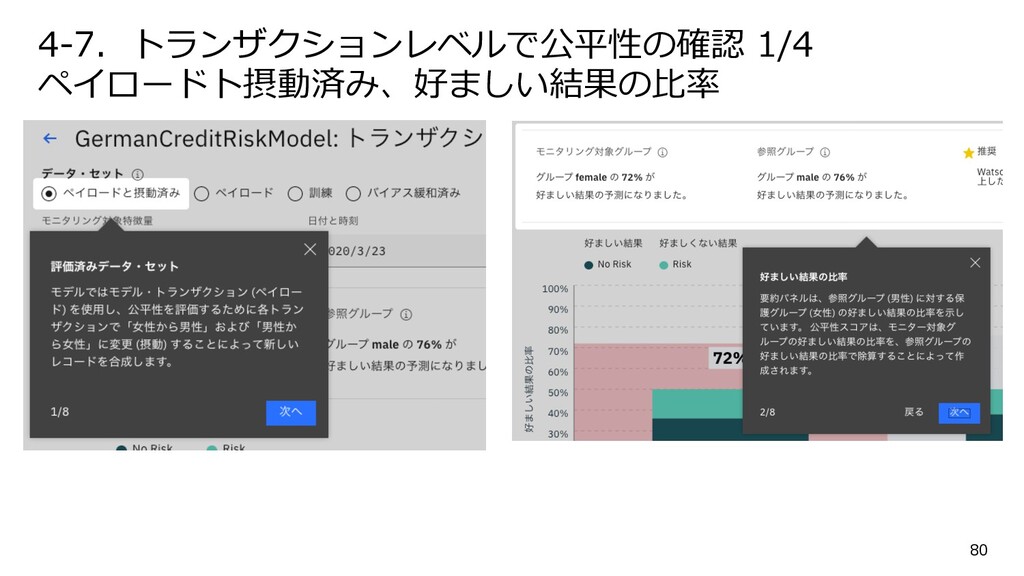{kind=link}
{kind=link}
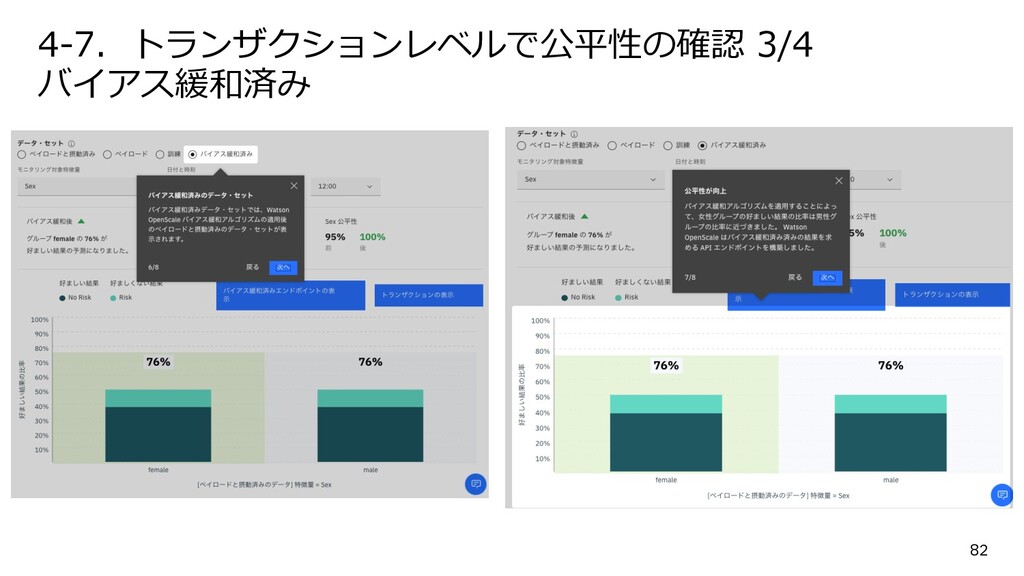{kind=link}
![4-7. トランザクションレベルで公平性の確認 1/4 [次のツアー]でトランザクションの表⽰ 83](https://files.speakerdeck.com/presentations/5816126a1cb740b5b09bc36557c43c3b/slide_82.jpg){kind=link}
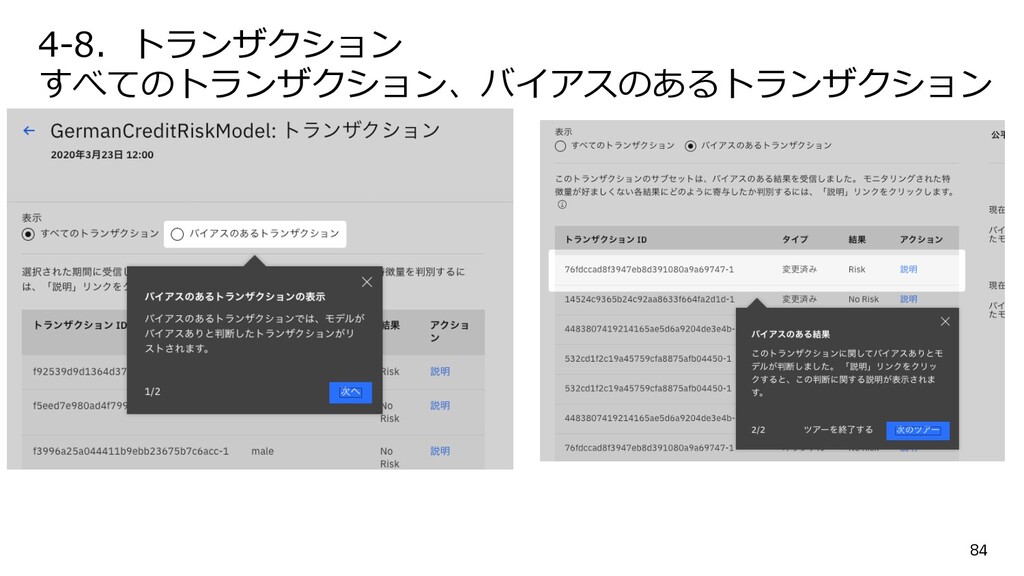{kind=link}
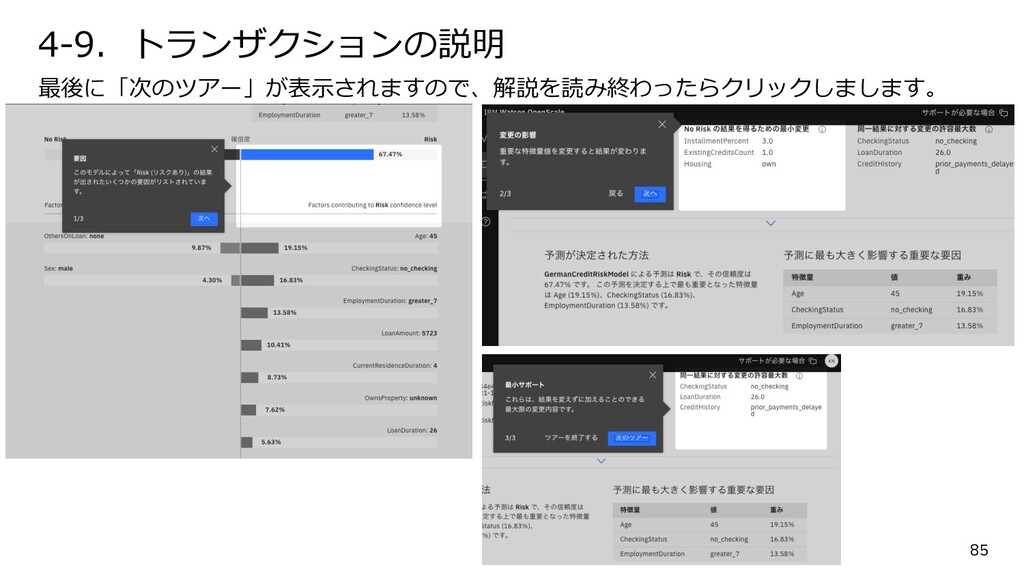{kind=link}
{kind=link}
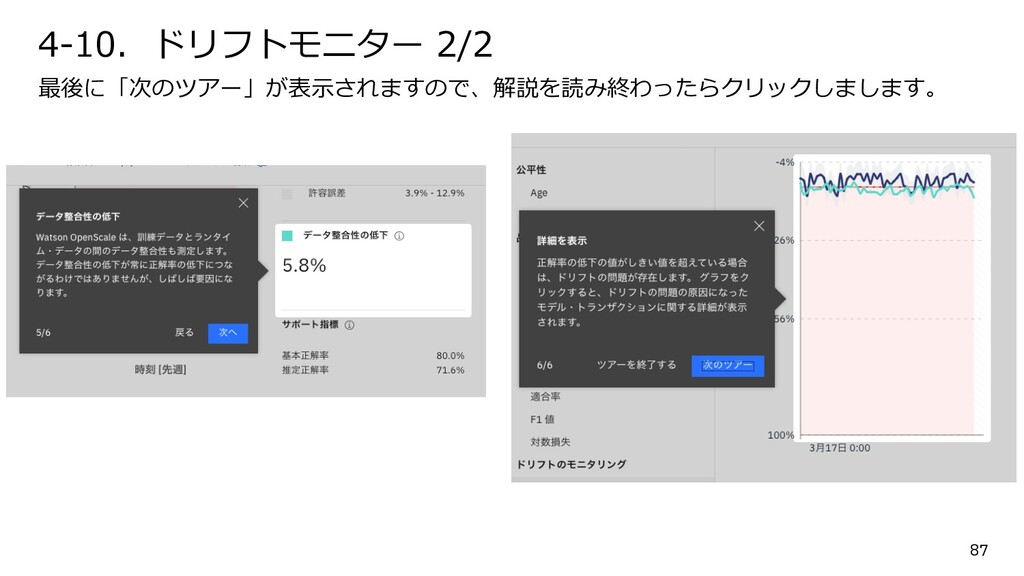{kind=link}
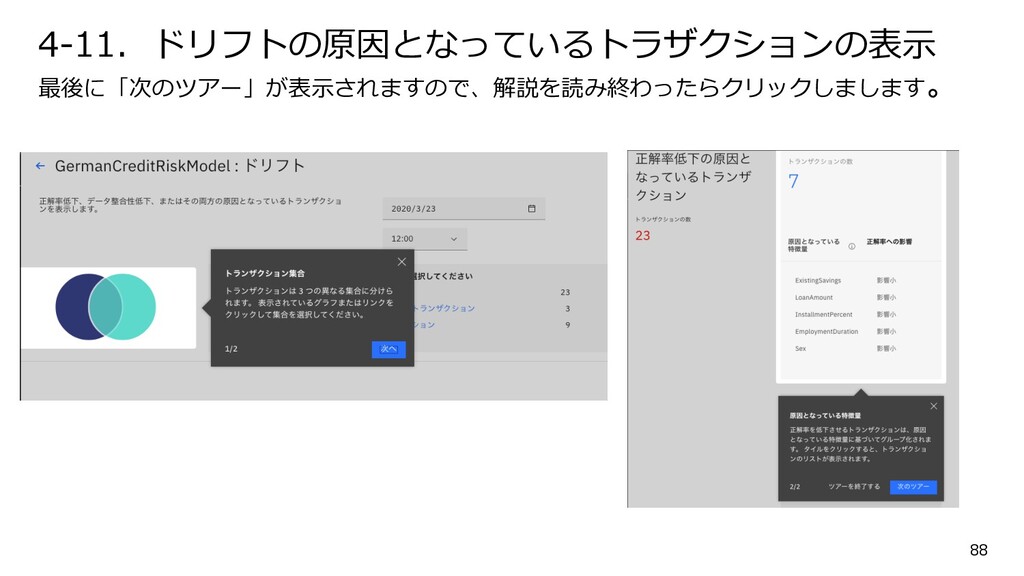{kind=link}
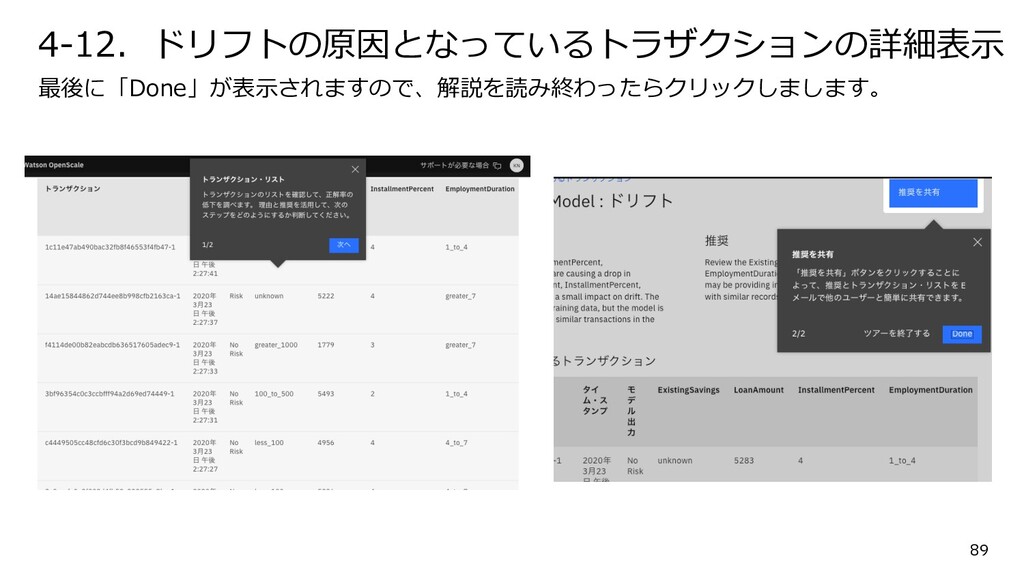{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
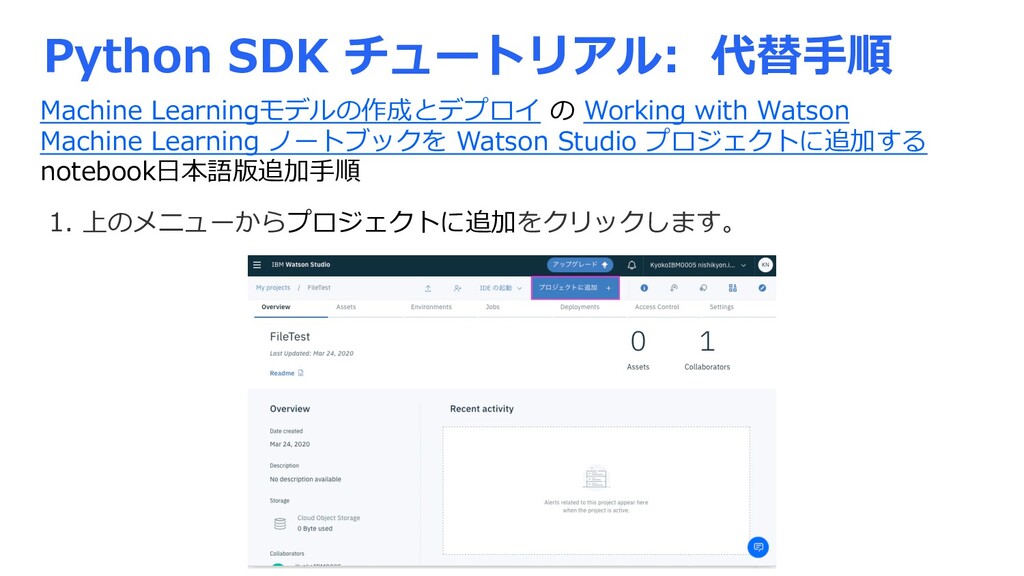{kind=link}
![3. FromURLタブをクリックして、以下を⼊⼒し、[Create]をクリック: Name: 適当な名前。下の例は「Watson OpenScale and Watson ML Engine」 Select](https://files.speakerdeck.com/presentations/5816126a1cb740b5b09bc36557c43c3b/slide_95.jpg){kind=link}
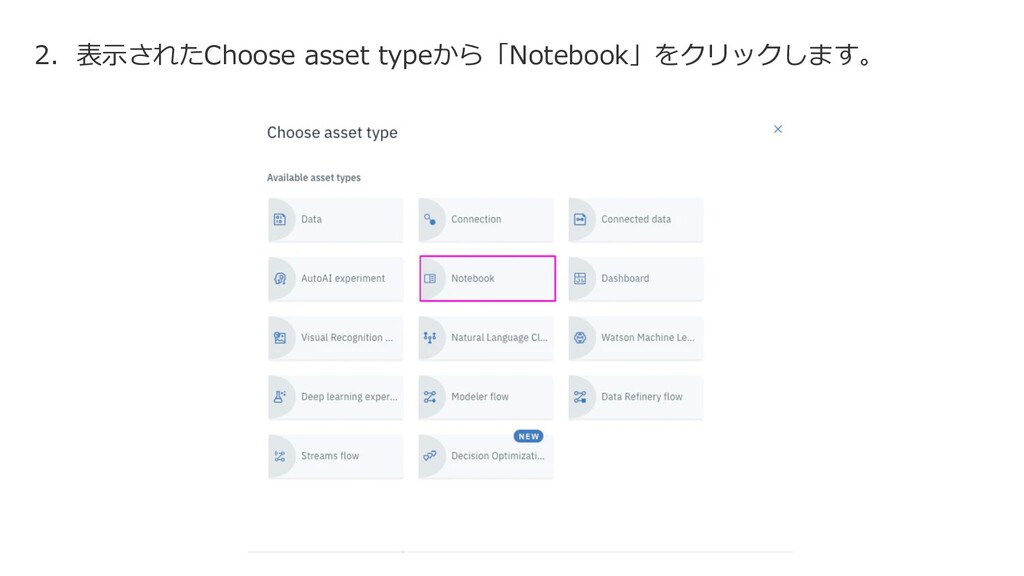{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}