論文紹介:Facial Action Unit Detection Using Active Learning and an Efficient Non-linear Kernel Approximation
Senechal, Thibaud, Daniel McDuff, and Rana Kaliouby. "Facial action unit detection using active learning and an efficient non-linear kernel approximation." Proceedings of the IEEE International Conference on Computer Vision Workshops. 2015.
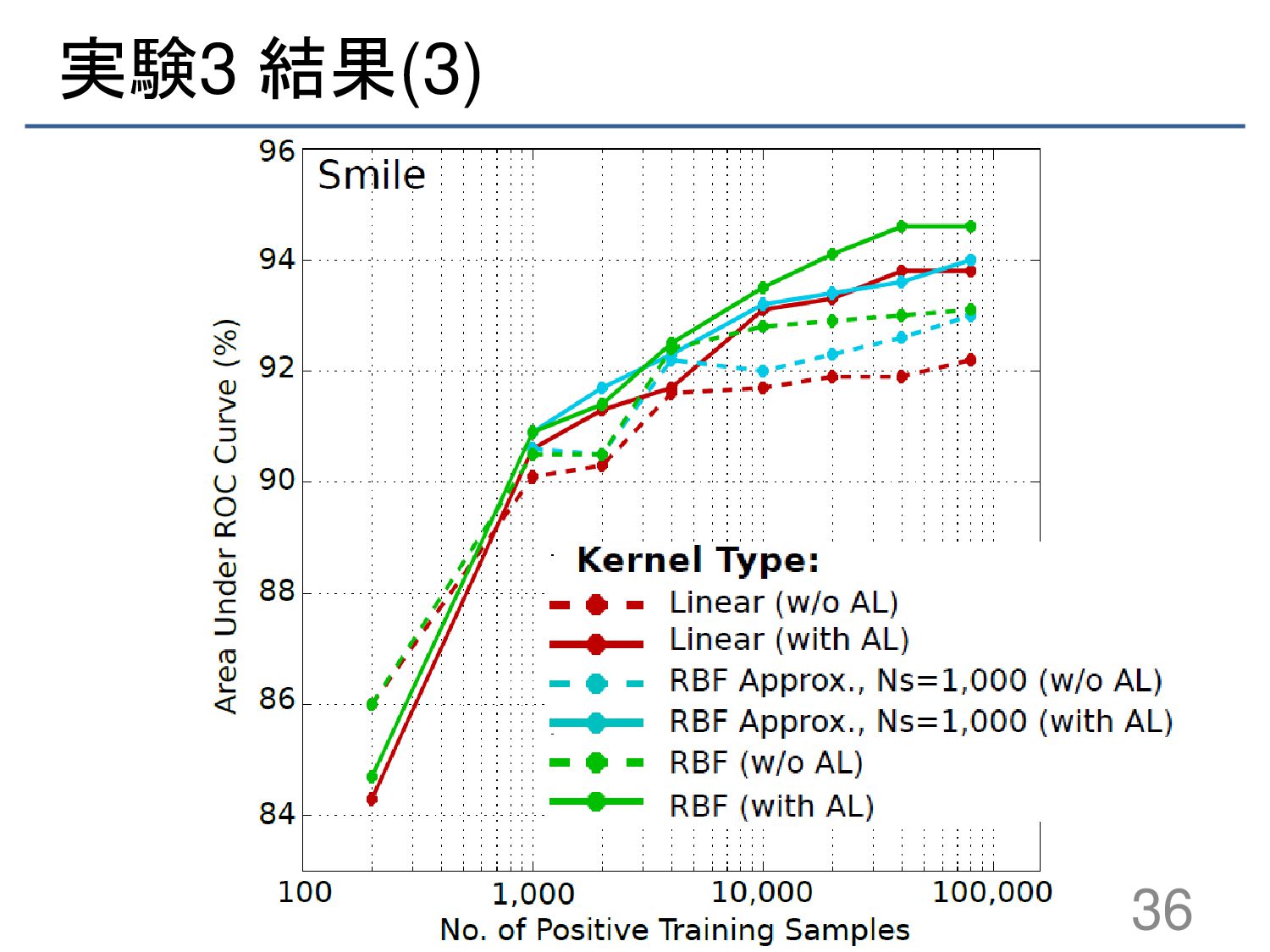
Unit Detection using Active Learning and an Efficient Non-Linear Kernel Approximation”, Proceedings of the IEEE International Conference on Computer Vision Workshops, 2015 3
– MMI[2] – DISFA[3] 6 自然な表情を大量の人数から集める必要がある • 特定の環境 • 作られた表情 • 収集した人数が少ない 多様性に 乏しい [1] Lucey, P., Cohn, J. F., Kanade, T., Saragih, J., Ambadar, Z., & Matthews, I. (2010). The Extended Cohn-Kanade Dataset (CK+): A complete expression dataset for action unit and emotion-specified expression. Proceedings of the Third International Workshop on CVPR for Human Communicative Behavior Analysis (CVPR4HB 2010), San Francisco, USA, 94-101. [2] Pantic, Maja, et al. "Web-based database for facial expression analysis." Multimedia and Expo, 2005. ICME 2005. IEEE International Conference on. IEEE, 2005. [3] Mavadati, S. Mohammad, et al. "Disfa: A spontaneous facial action intensity database." IEEE Transactions on Affective Computing 4.2 (2013): 151-160.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![訓練データの収集 • 認識したい表情の正例と負例を大量に集める必要性 • 大量のデータすべてに人手でラベル付けするのは困難 • 表情データベース – Cohn-Kanade (CK+)[1]](https://files.speakerdeck.com/presentations/494294be329b4d13b28a8d4aeab7958b/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
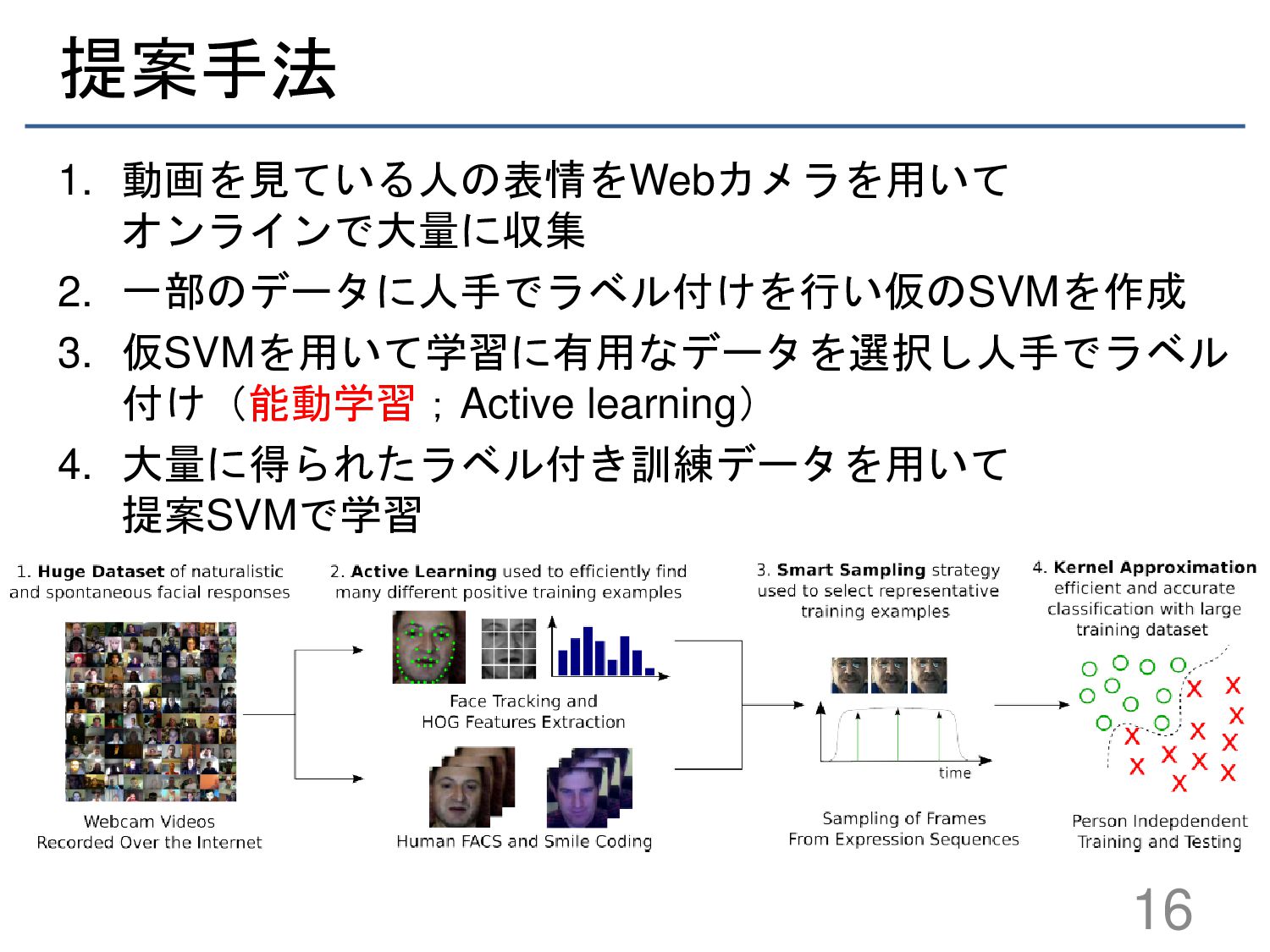{kind=link}
{kind=link}
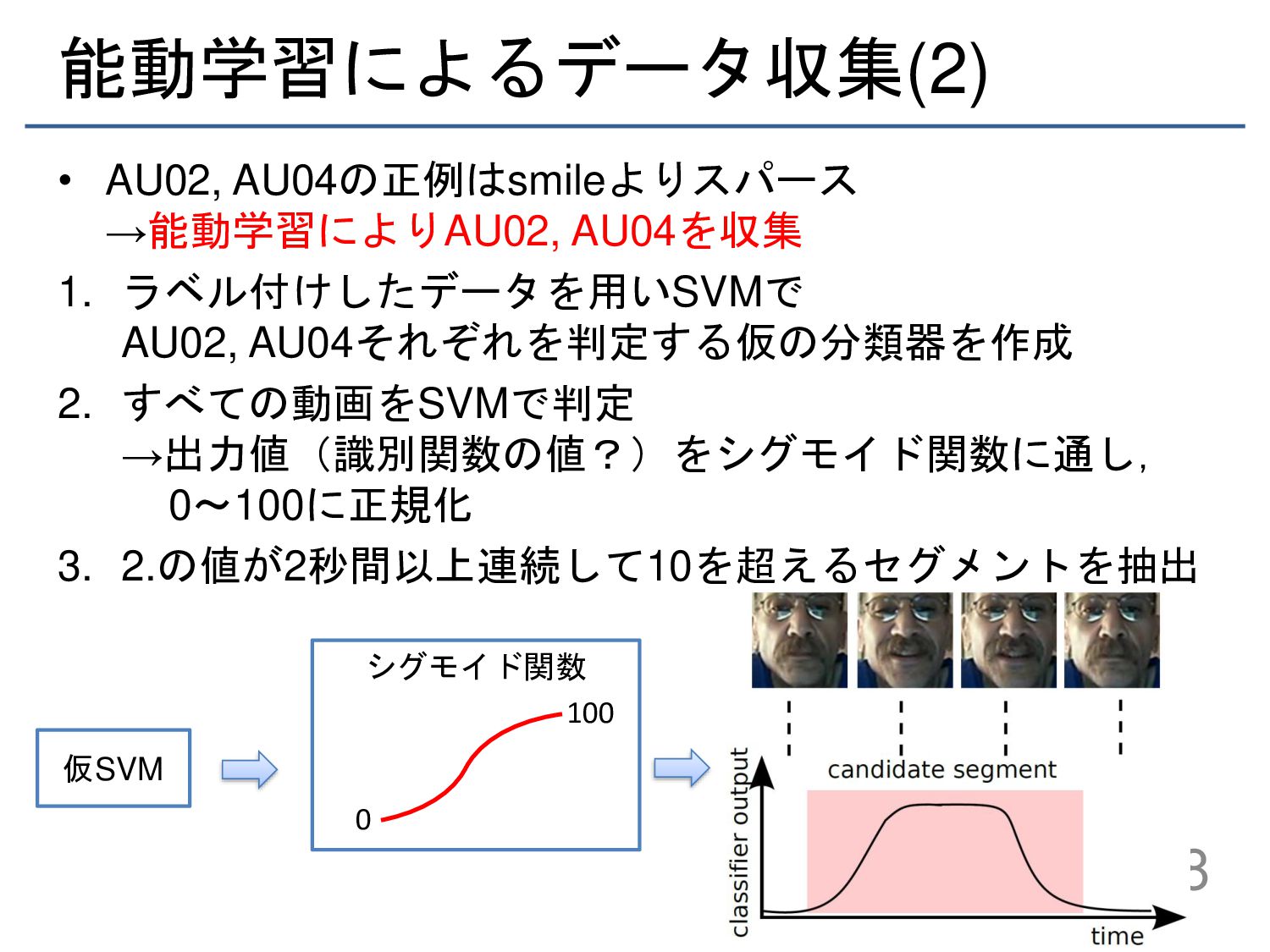{kind=link}
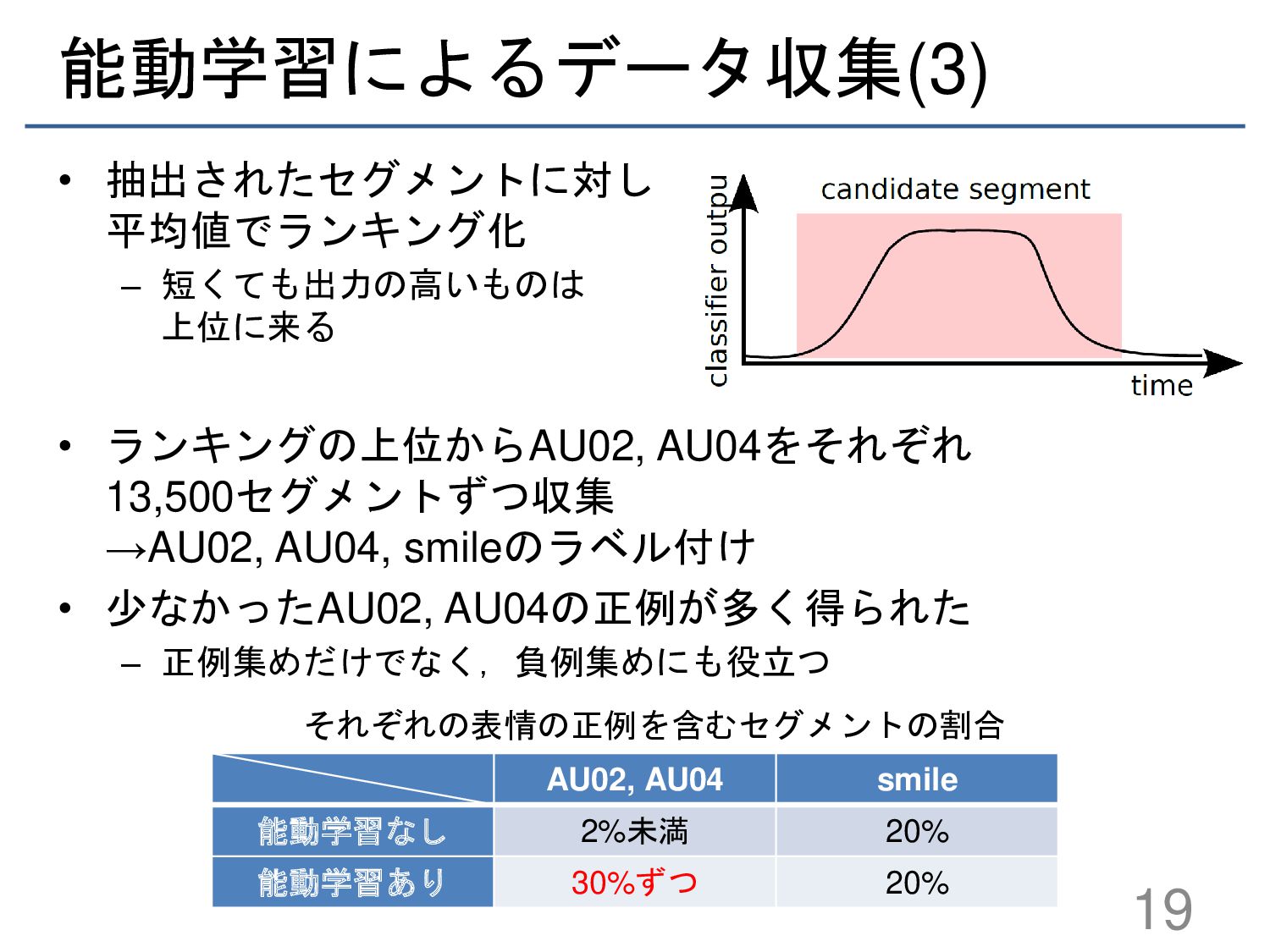{kind=link}
{kind=link}
{kind=link}
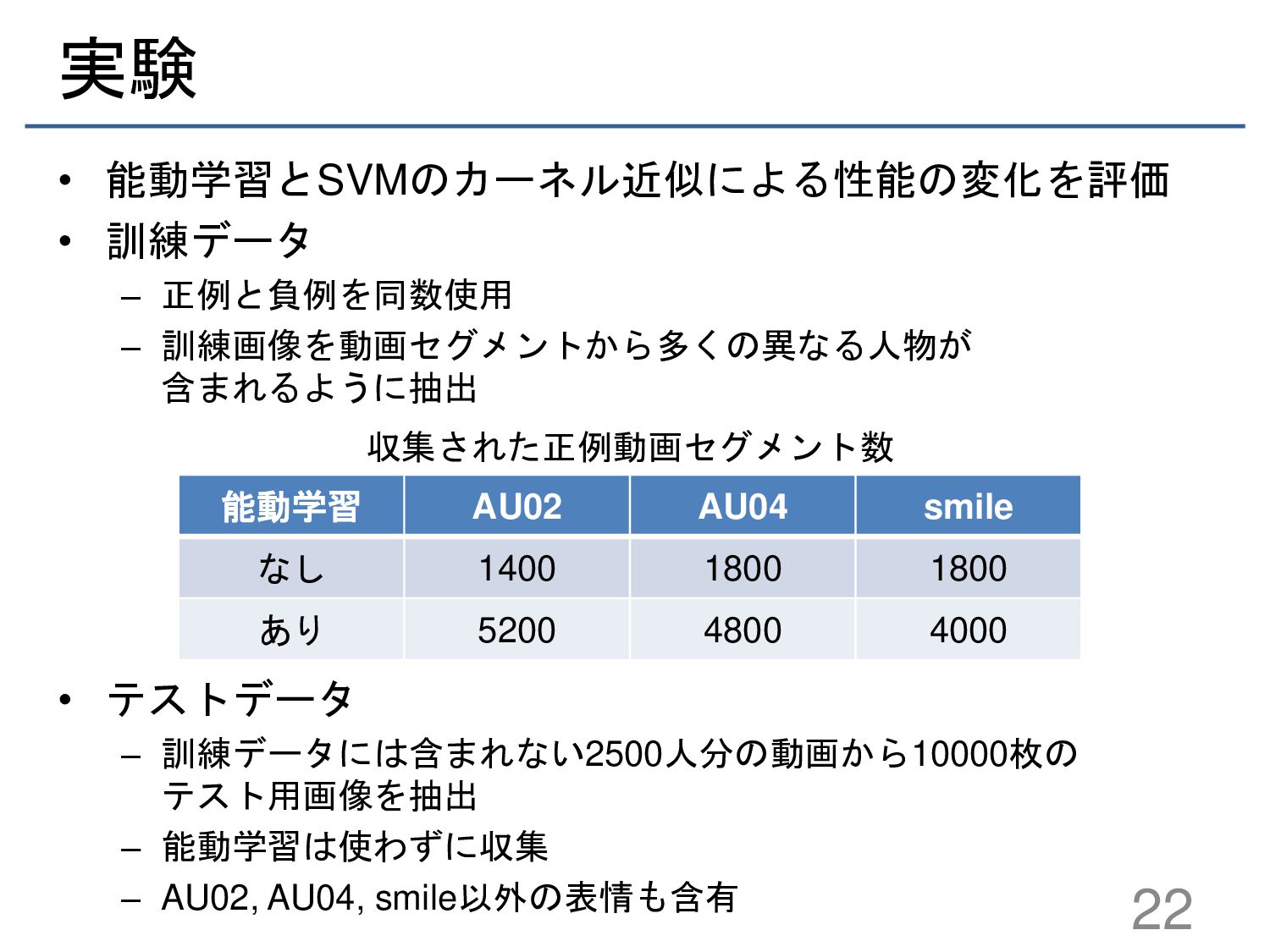{kind=link}
{kind=link}
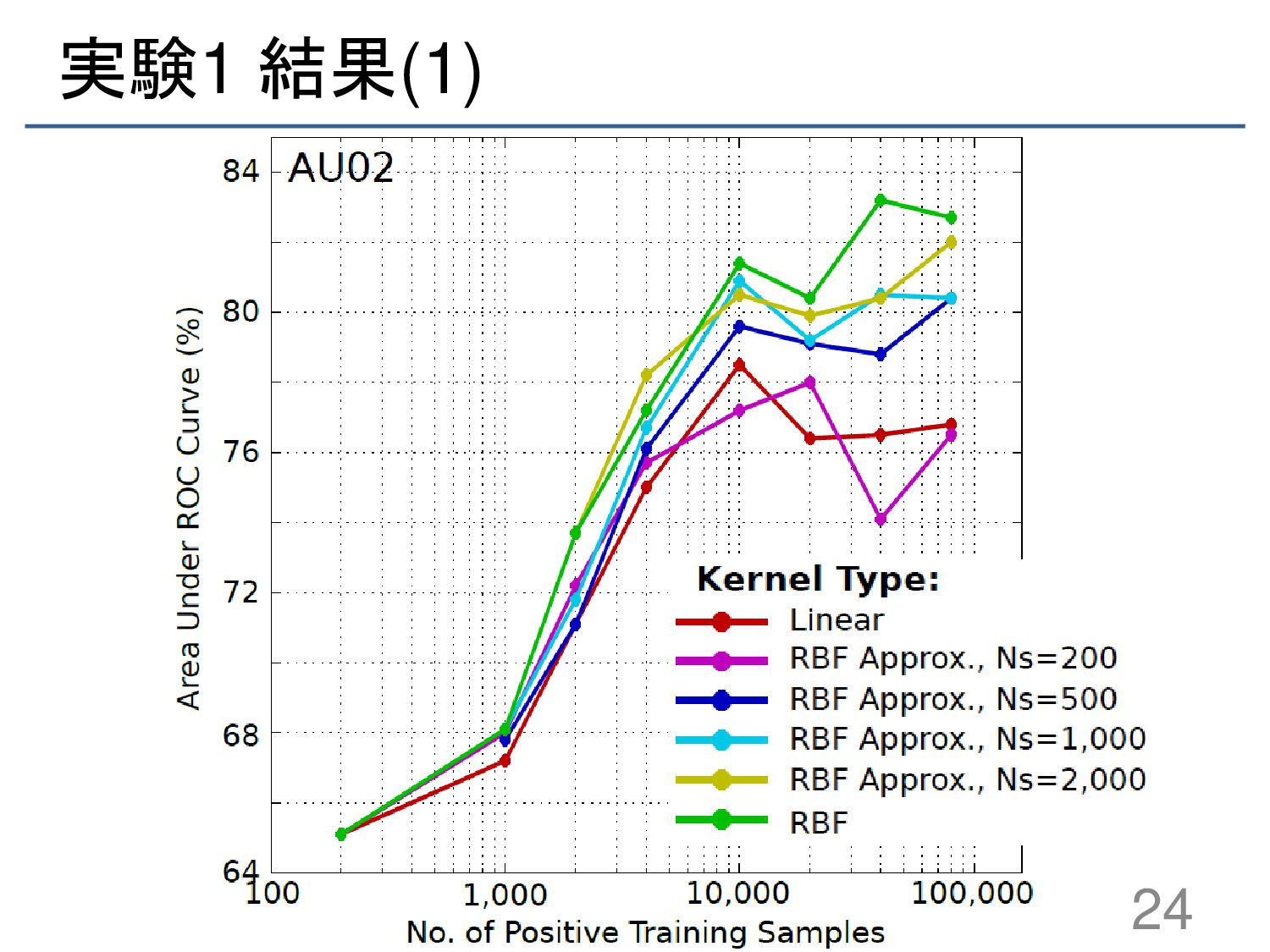{kind=link}
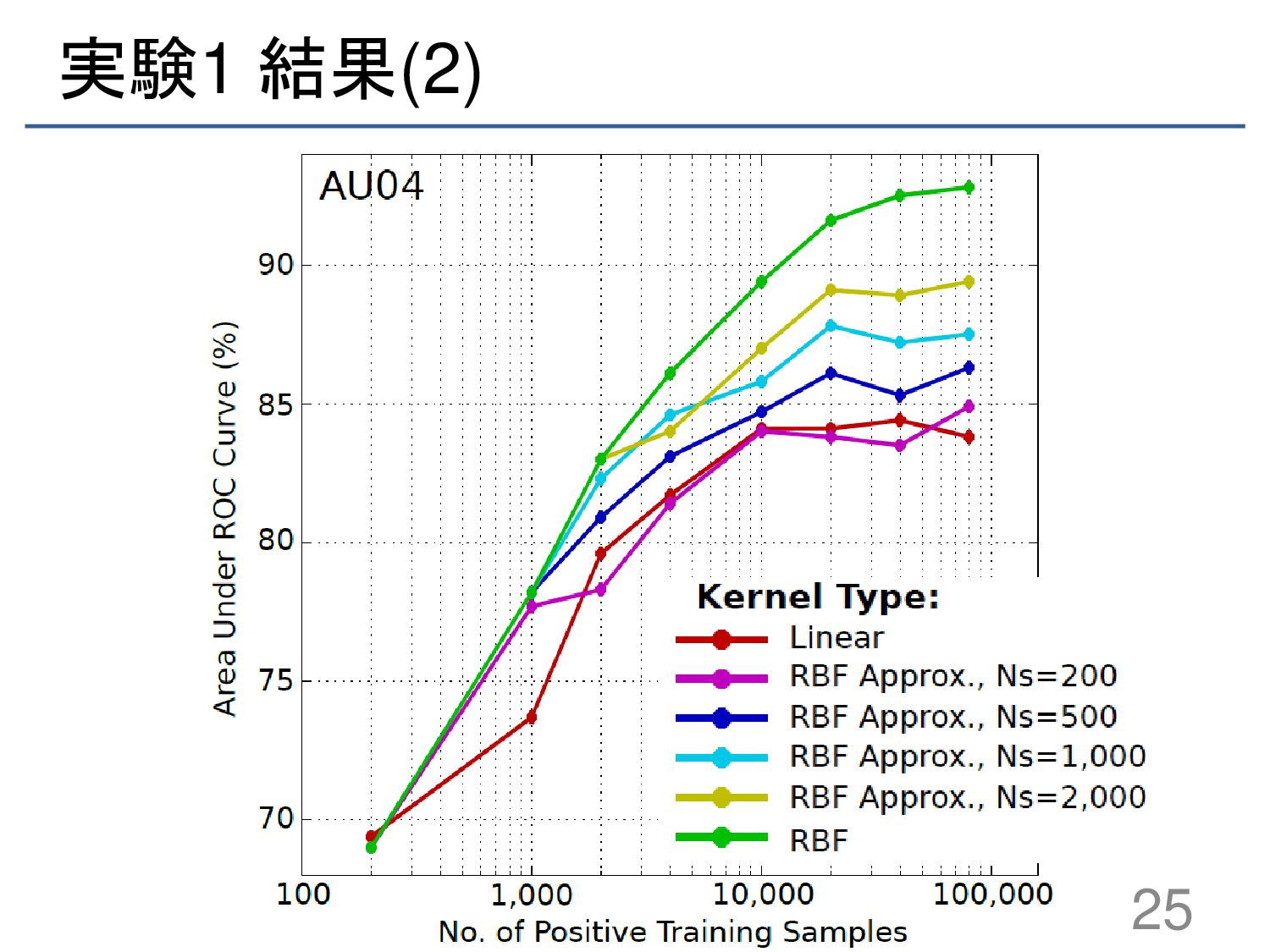{kind=link}
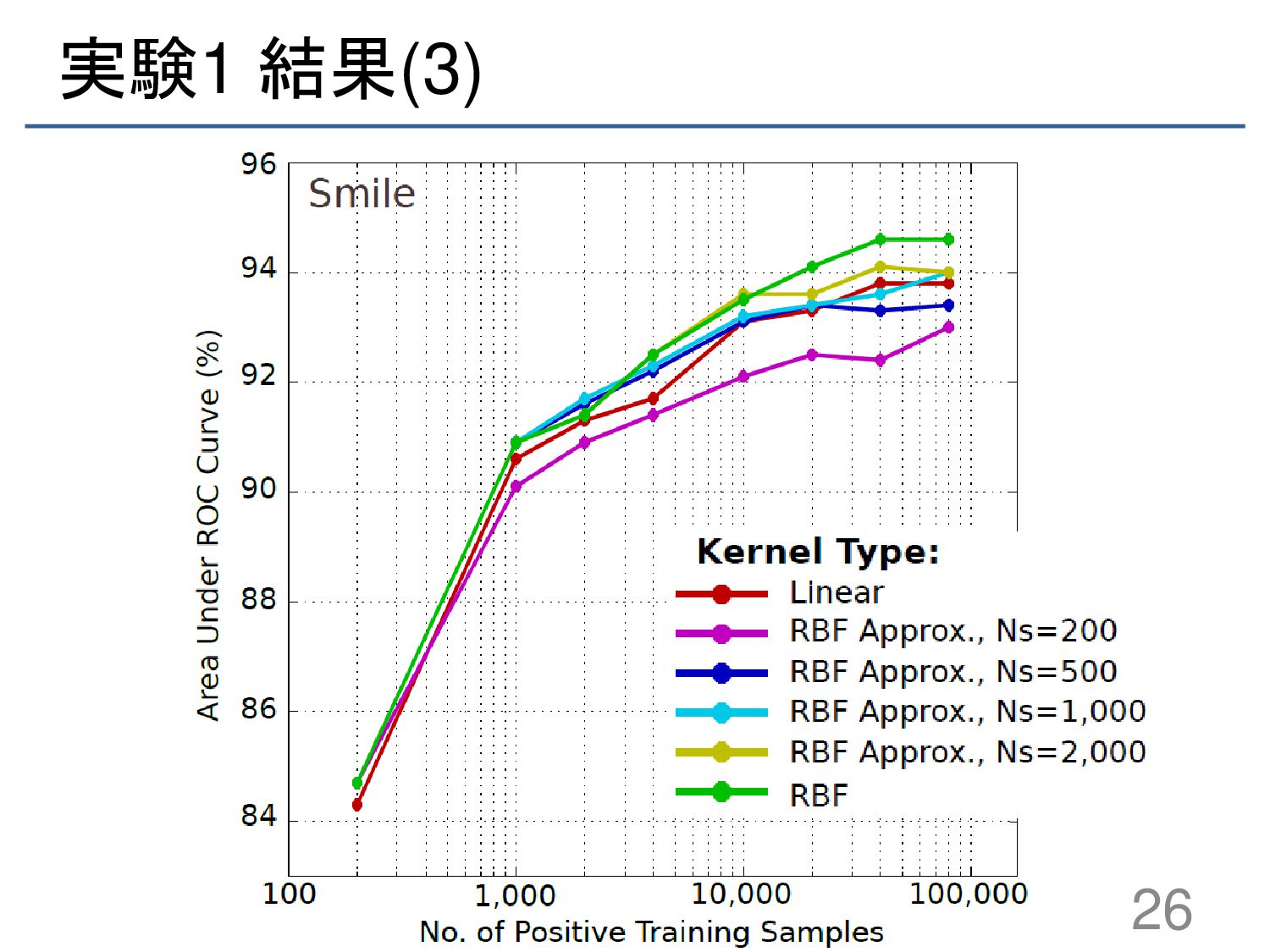{kind=link}
{kind=link}
{kind=link}
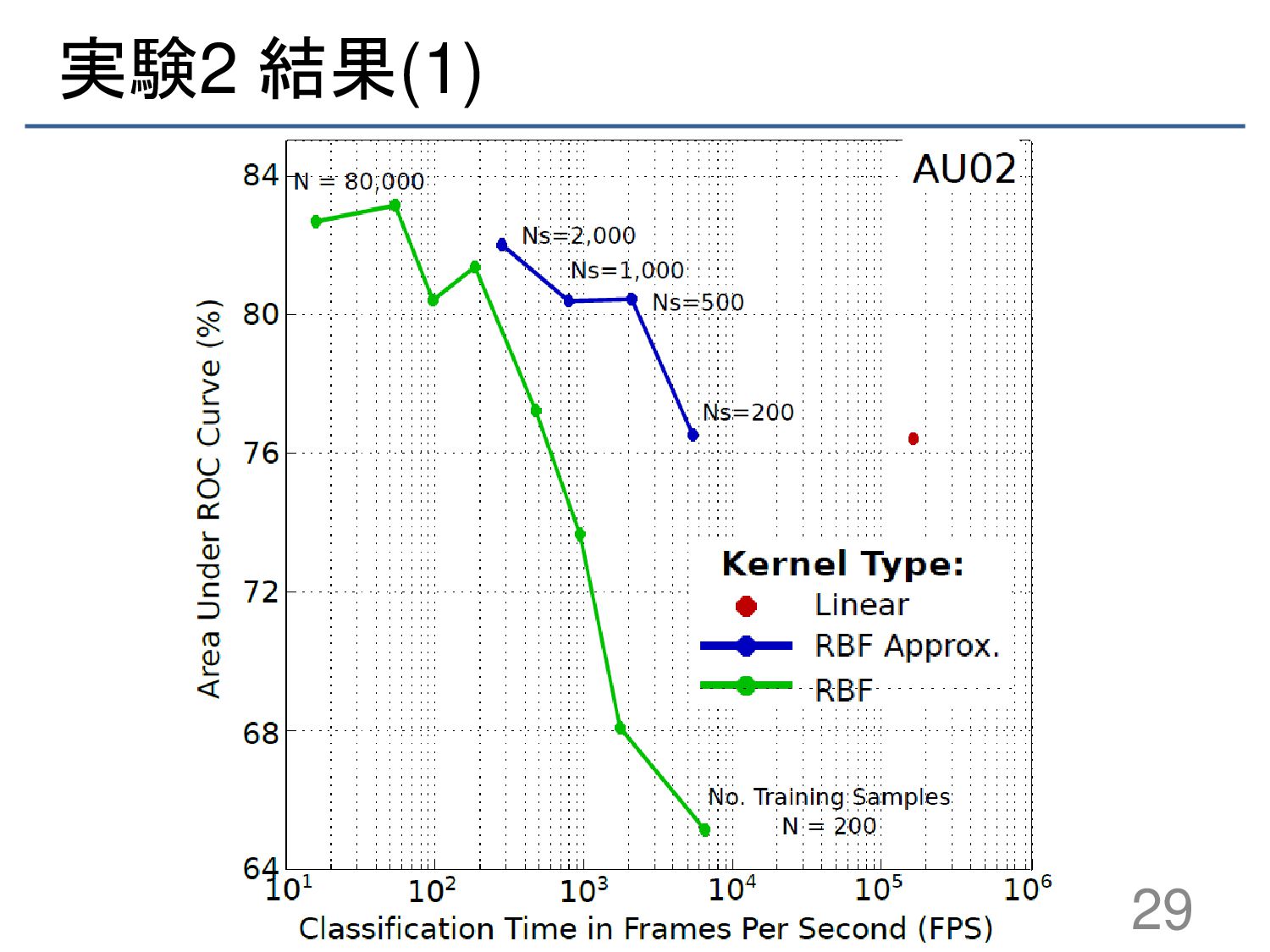{kind=link}
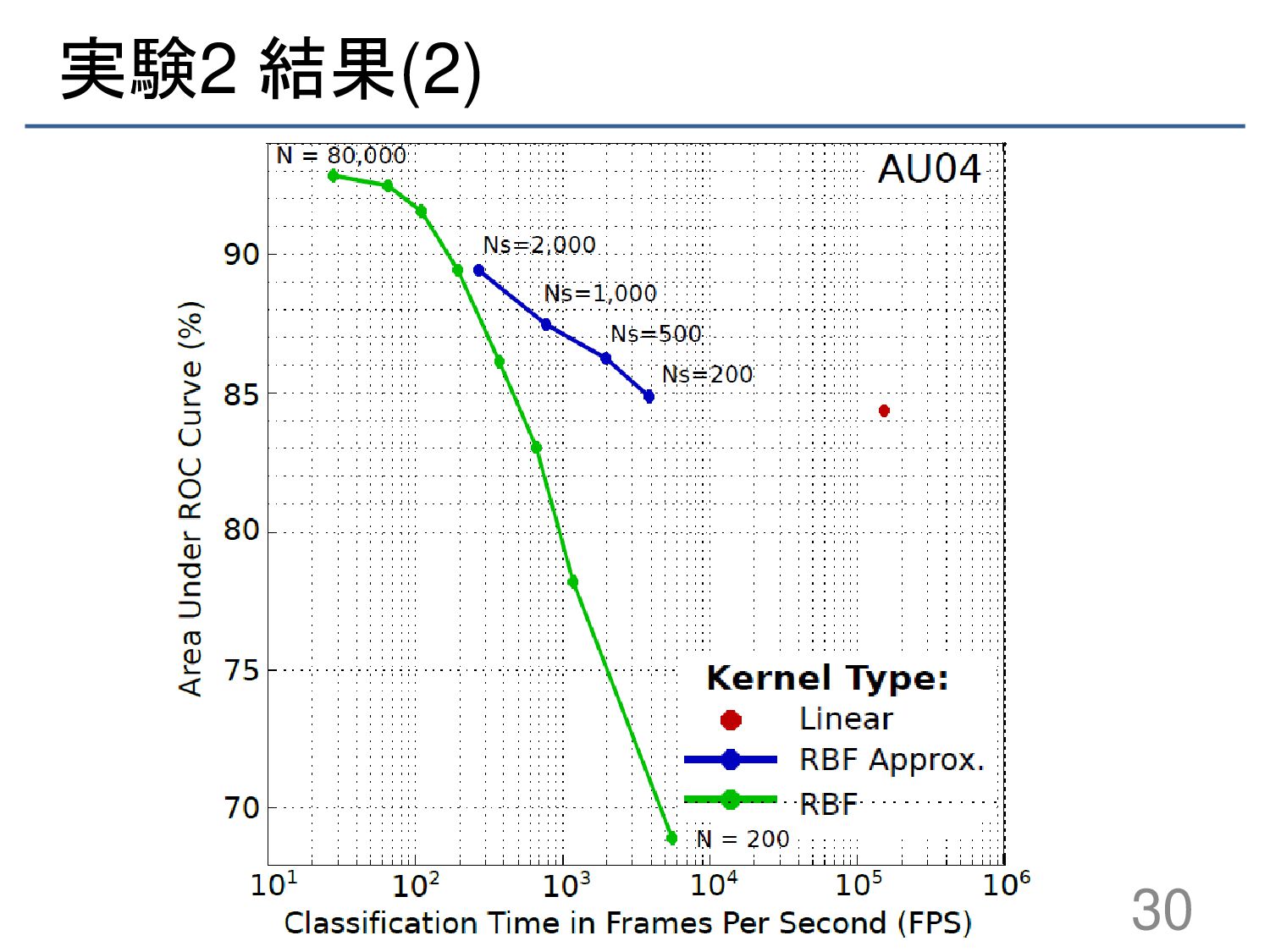{kind=link}
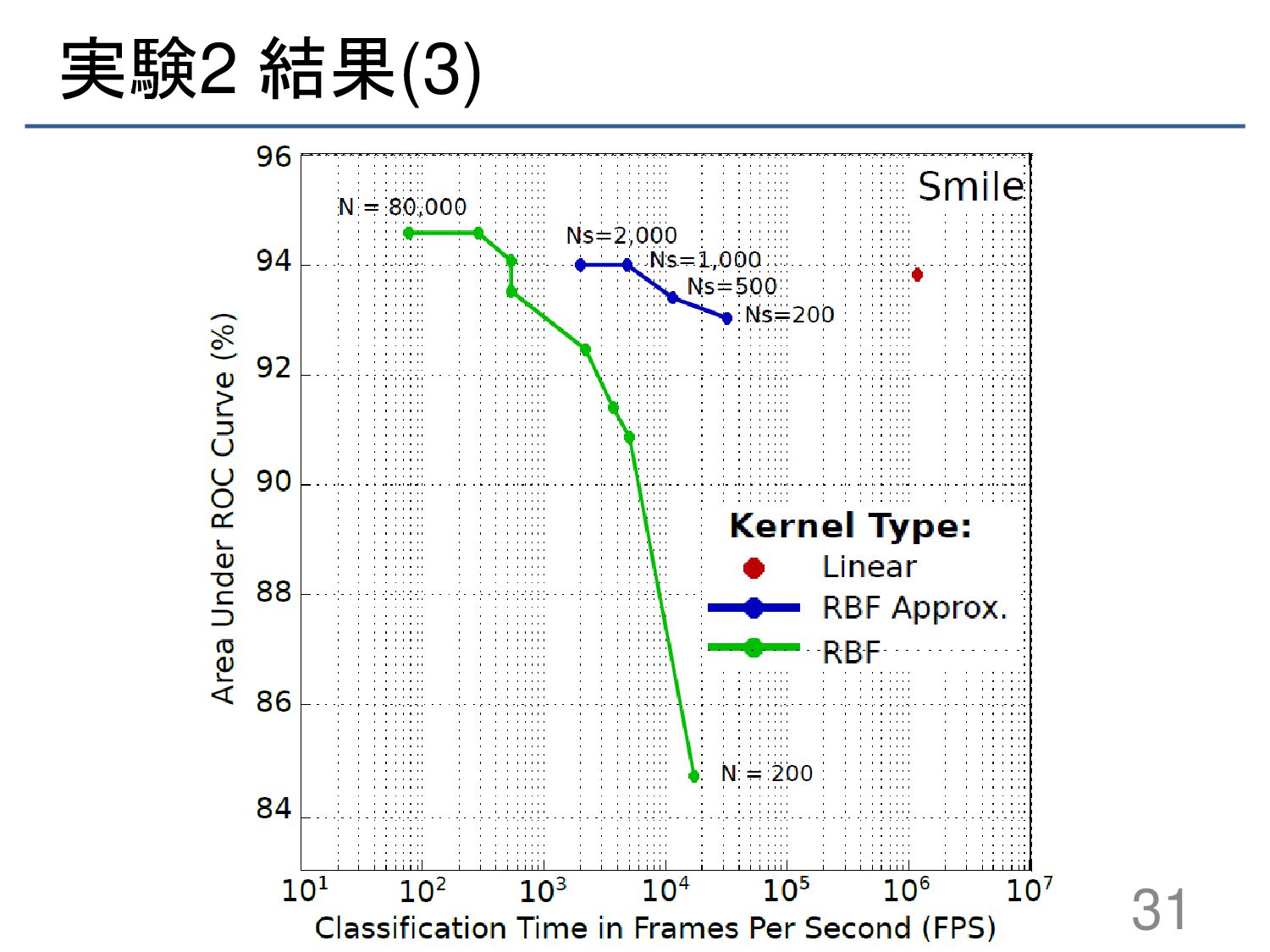{kind=link}
{kind=link}
{kind=link}
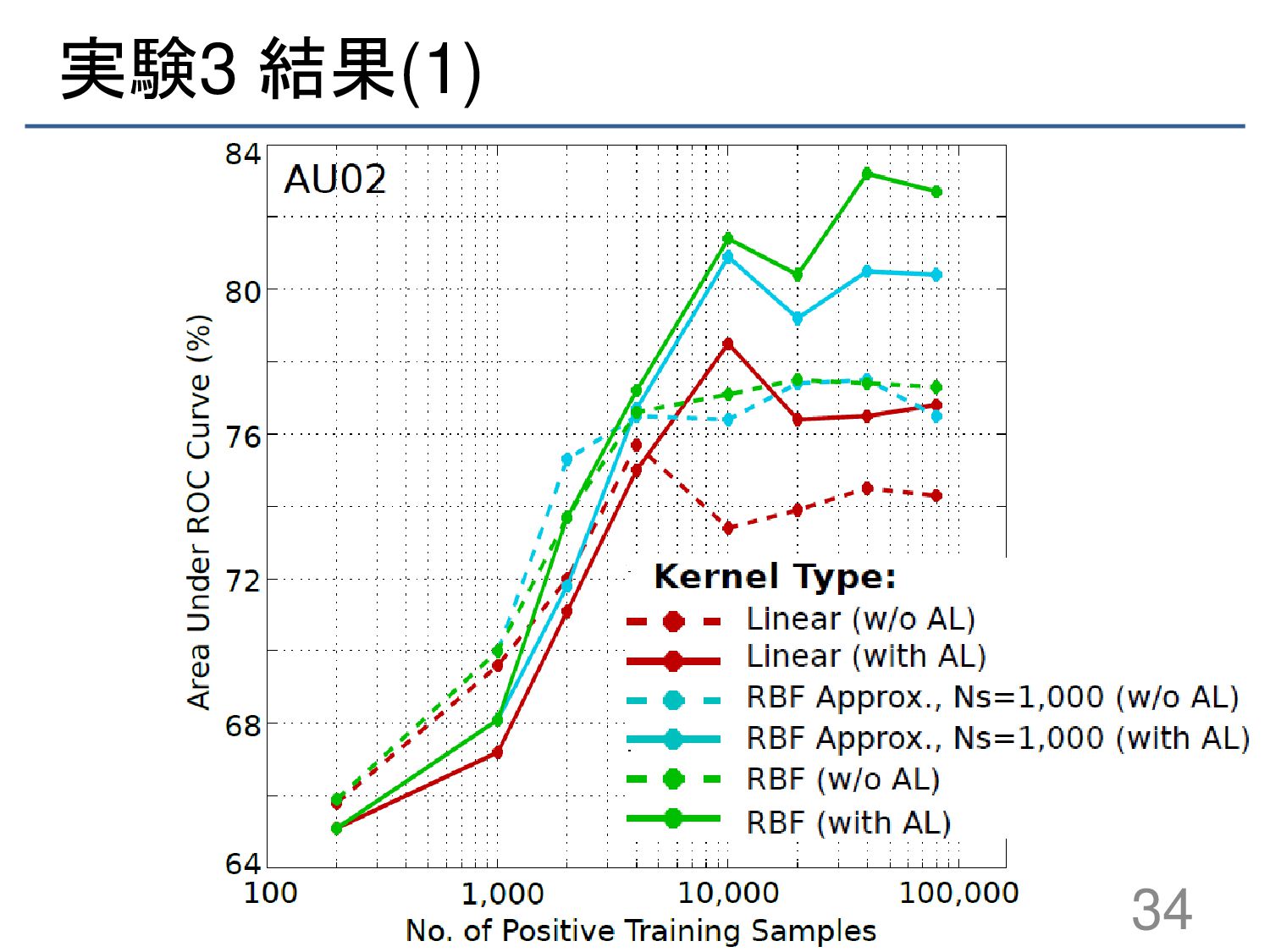{kind=link}
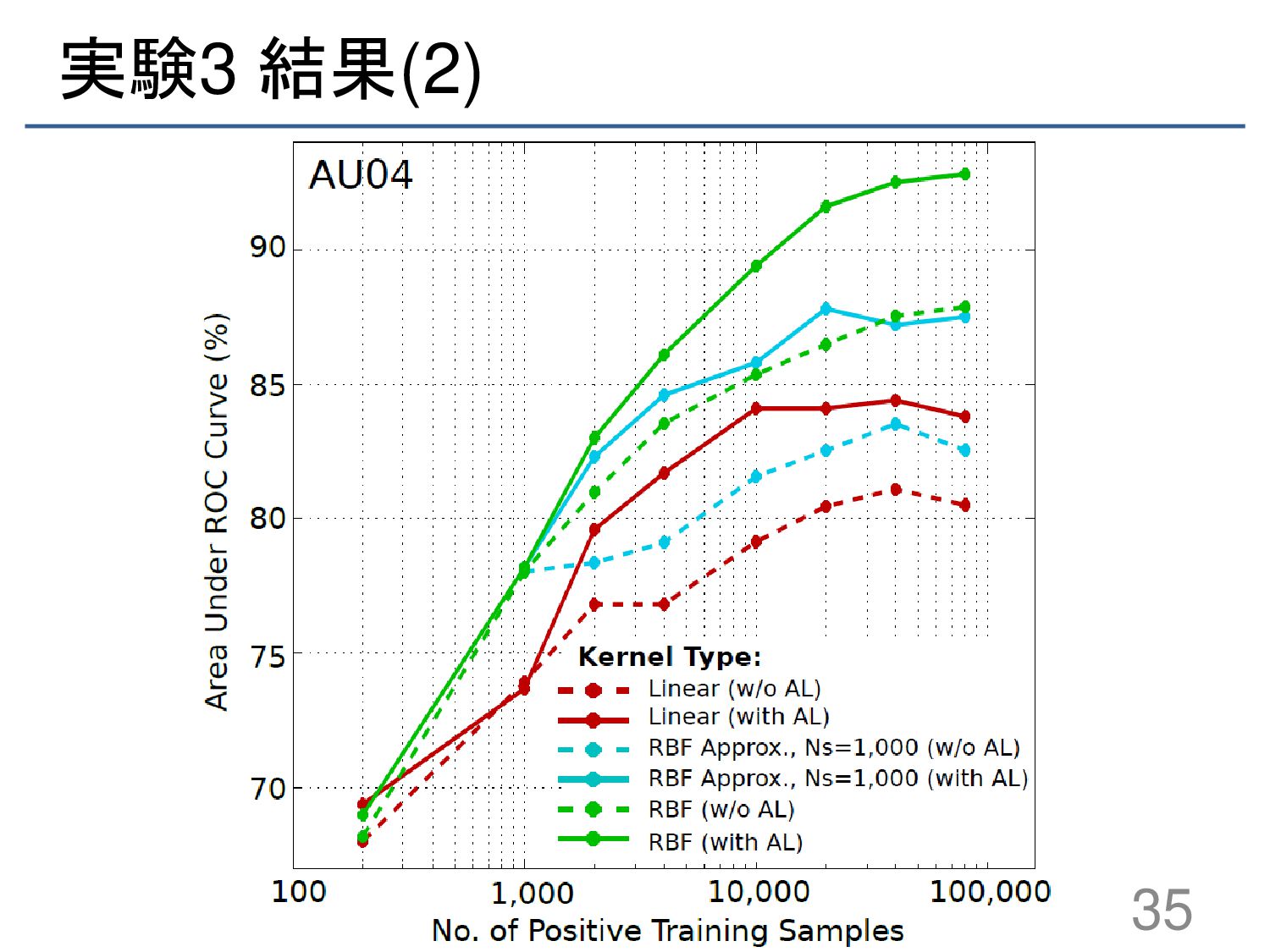{kind=link}
{kind=link}
{kind=link}
{kind=link}