Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra, "Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization." Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 618-626
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![従来研究 • Class activation mapping (CAM)[1] – CNNがどこを見たかを可視化 – 画像単位のラベルから物体の場所を特定する](https://files.speakerdeck.com/presentations/981d8189d4434835ab44bcca3a2191d1/slide_4.jpg){kind=link}
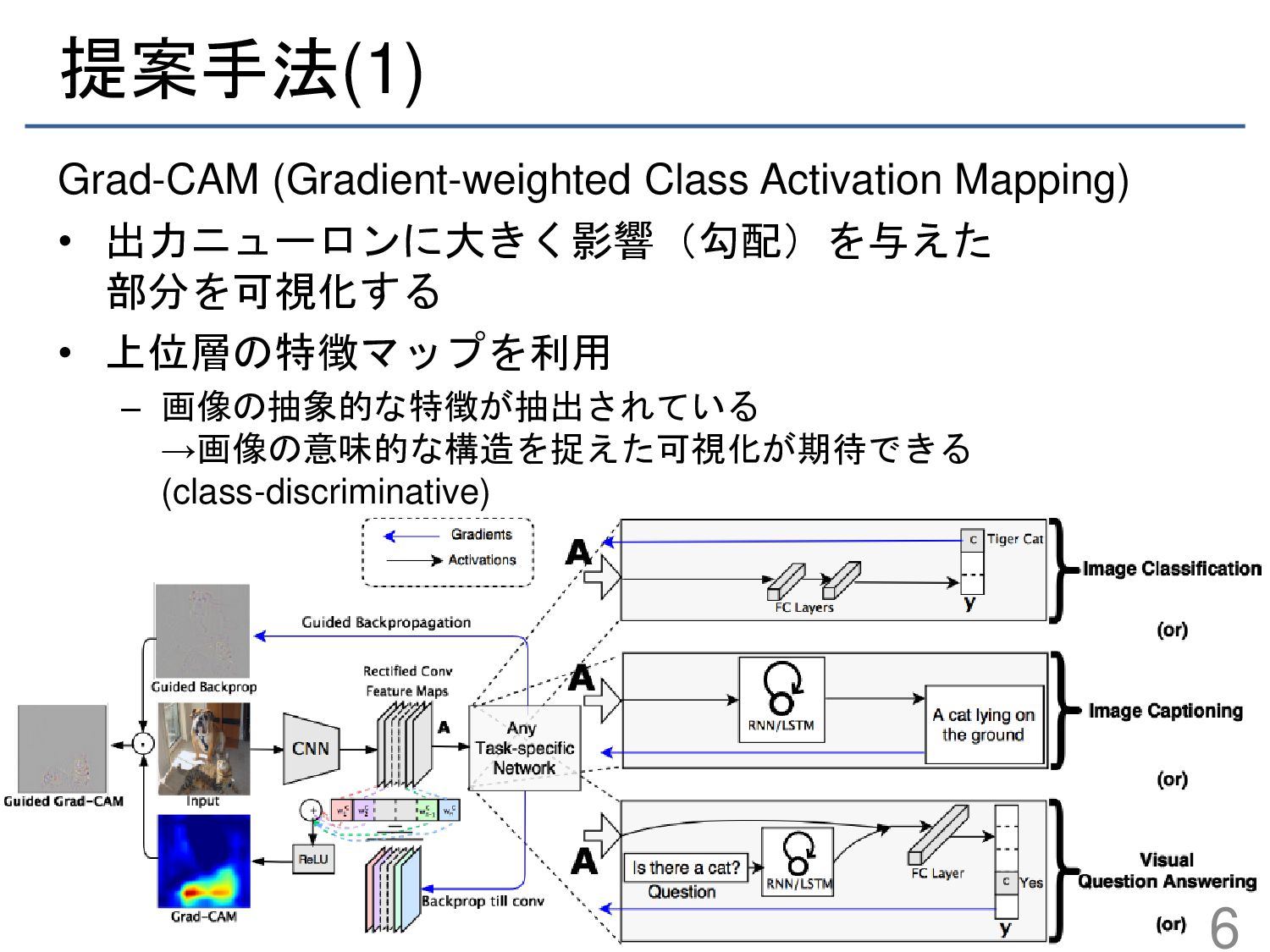{kind=link}
{kind=link}
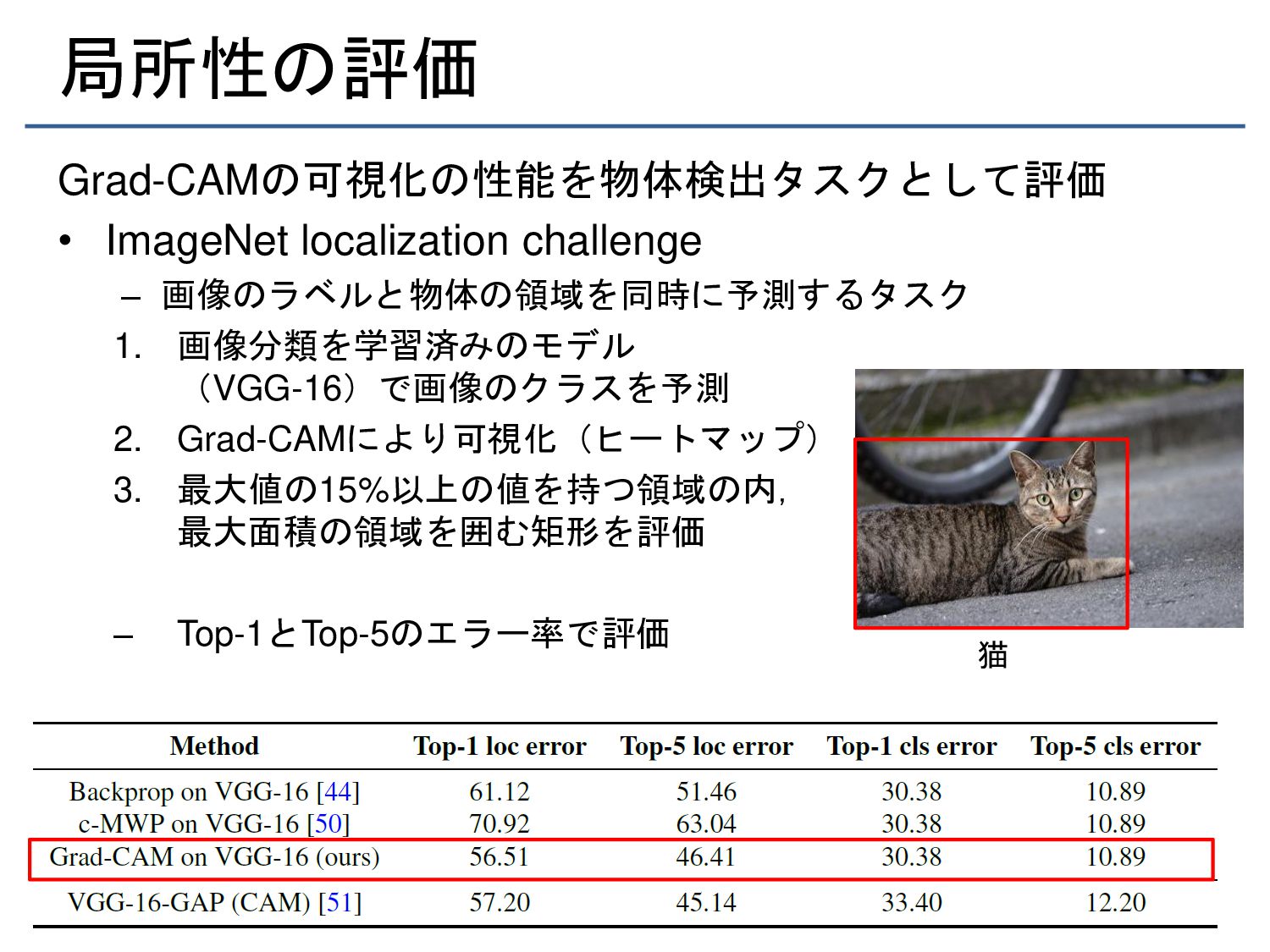{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
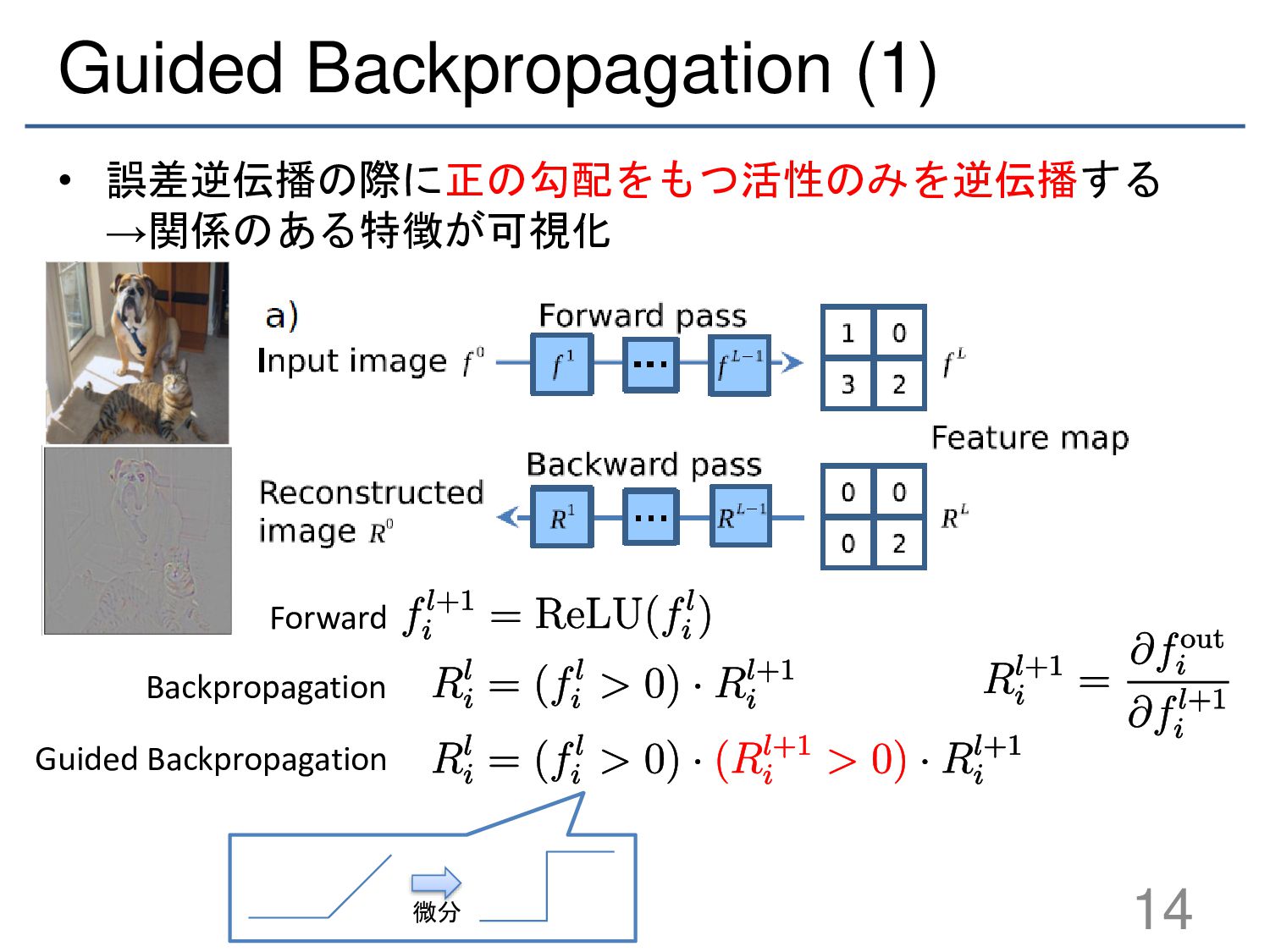{kind=link}
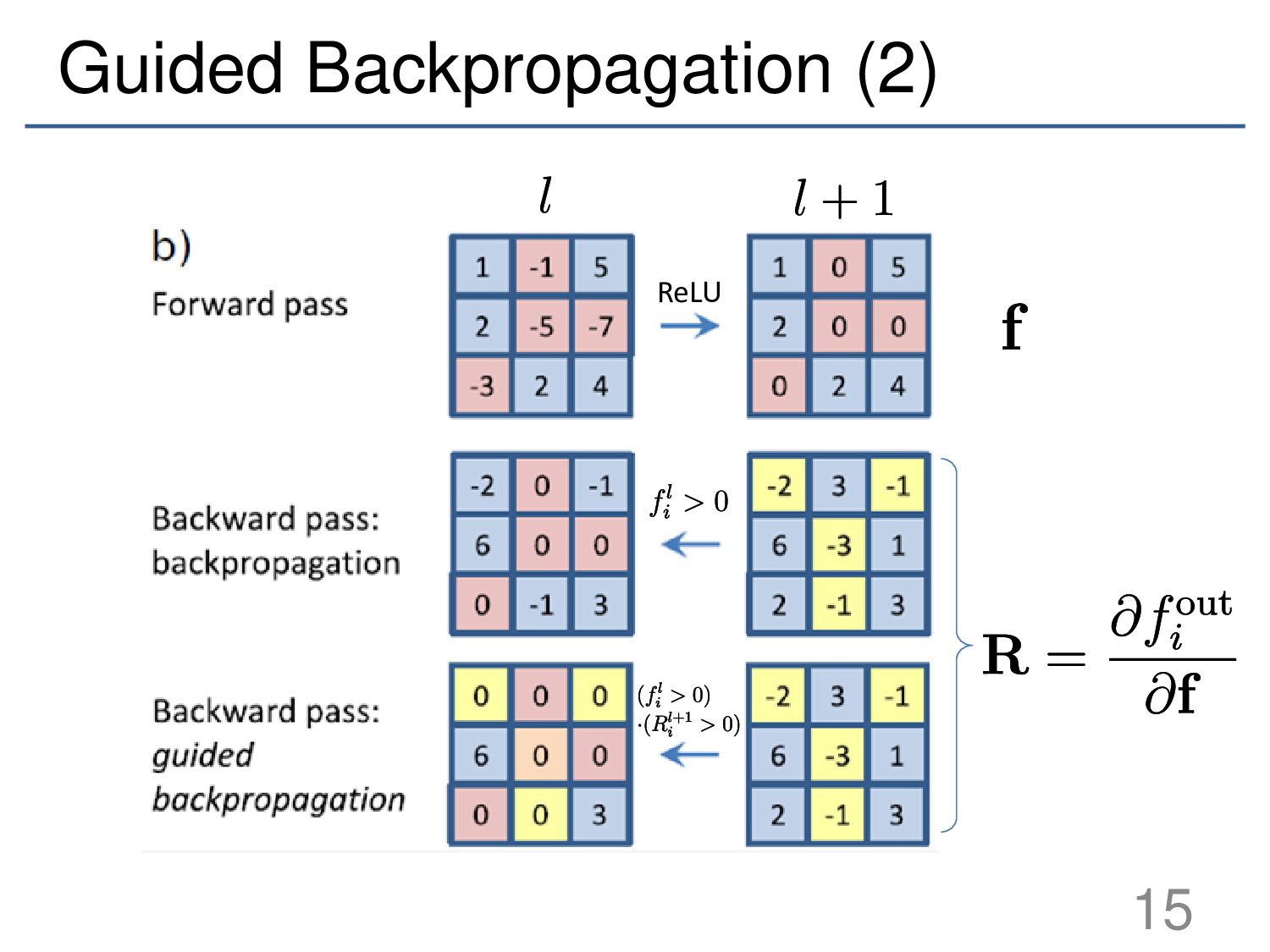{kind=link}
{kind=link}
{kind=link}
![可視化の妥当性の評価 18 • 可視化された画像から人間が正しいクラスを選択できた割合 手法 スコア [%] Deconvolution 53.33 Guided](https://files.speakerdeck.com/presentations/981d8189d4434835ab44bcca3a2191d1/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
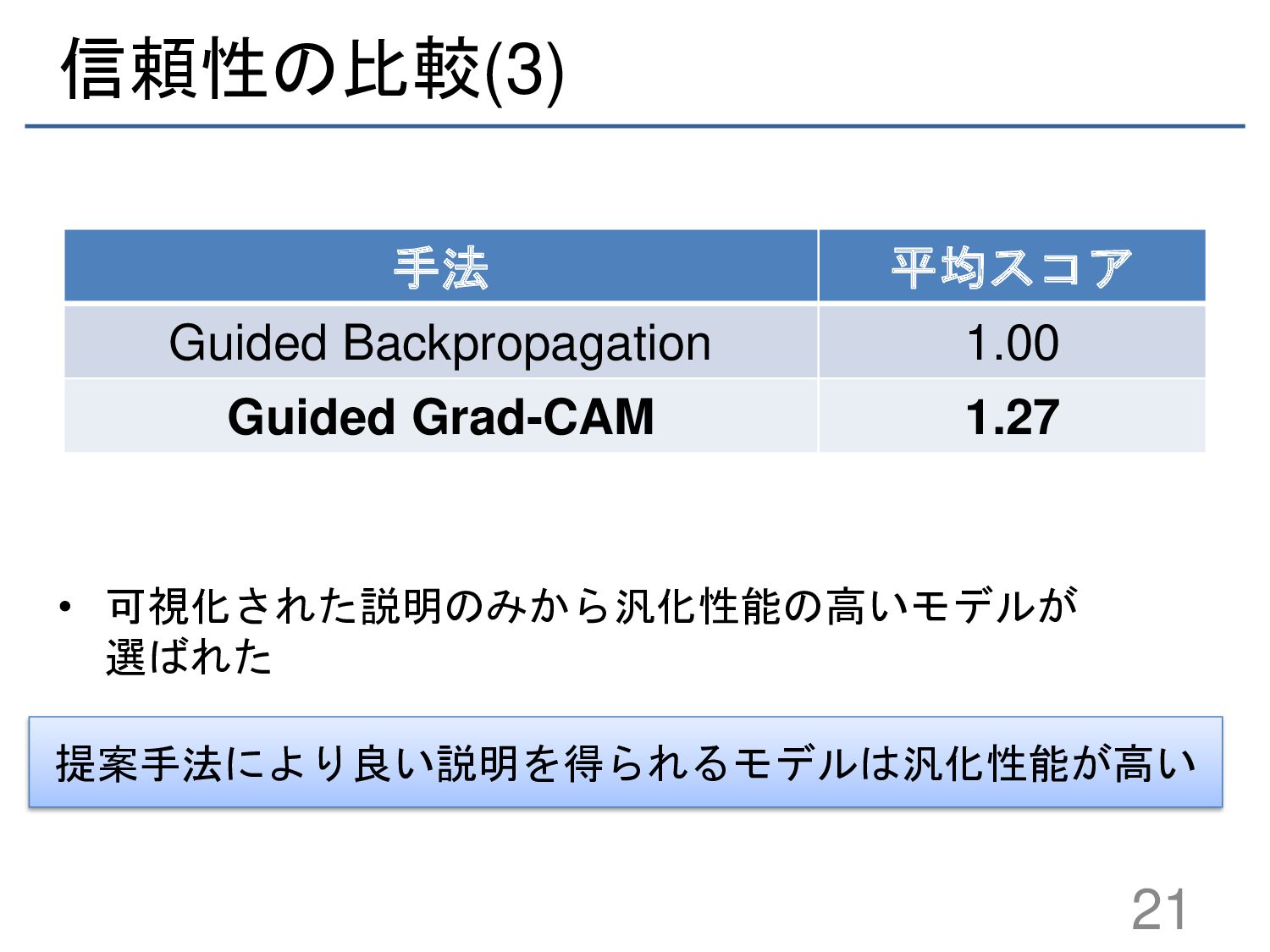{kind=link}
{kind=link}
{kind=link}