Jung, Heechul, et al. "Joint fine-tuning in deep neural networks for facial expression recognition." Proceedings of the IEEE international conference on computer vision. 2015.
https://www.cv-foundation.org/openaccess/content_iccv_2015/html/Jung_Joint_Fine-Tuning_in_ICCV_2015_paper.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
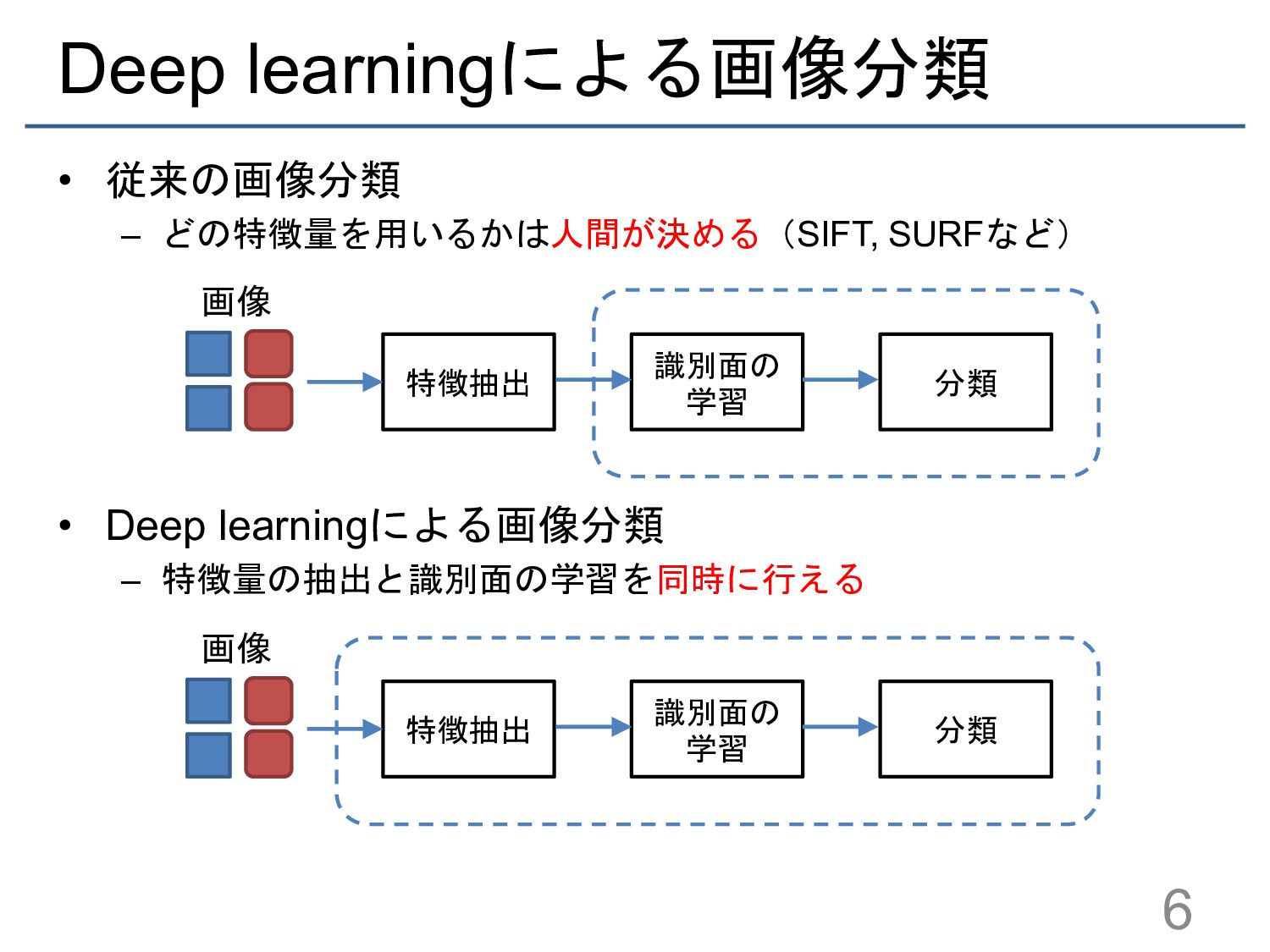{kind=link}
![表情認識におけるデータセットの課題 • 表情データベース – Cohn-Kanade (CK+)[1] – MMI[2] – Oulu-CASIA[3]](https://files.speakerdeck.com/presentations/56927fb35a8a478a89cf8d38caae6f74/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
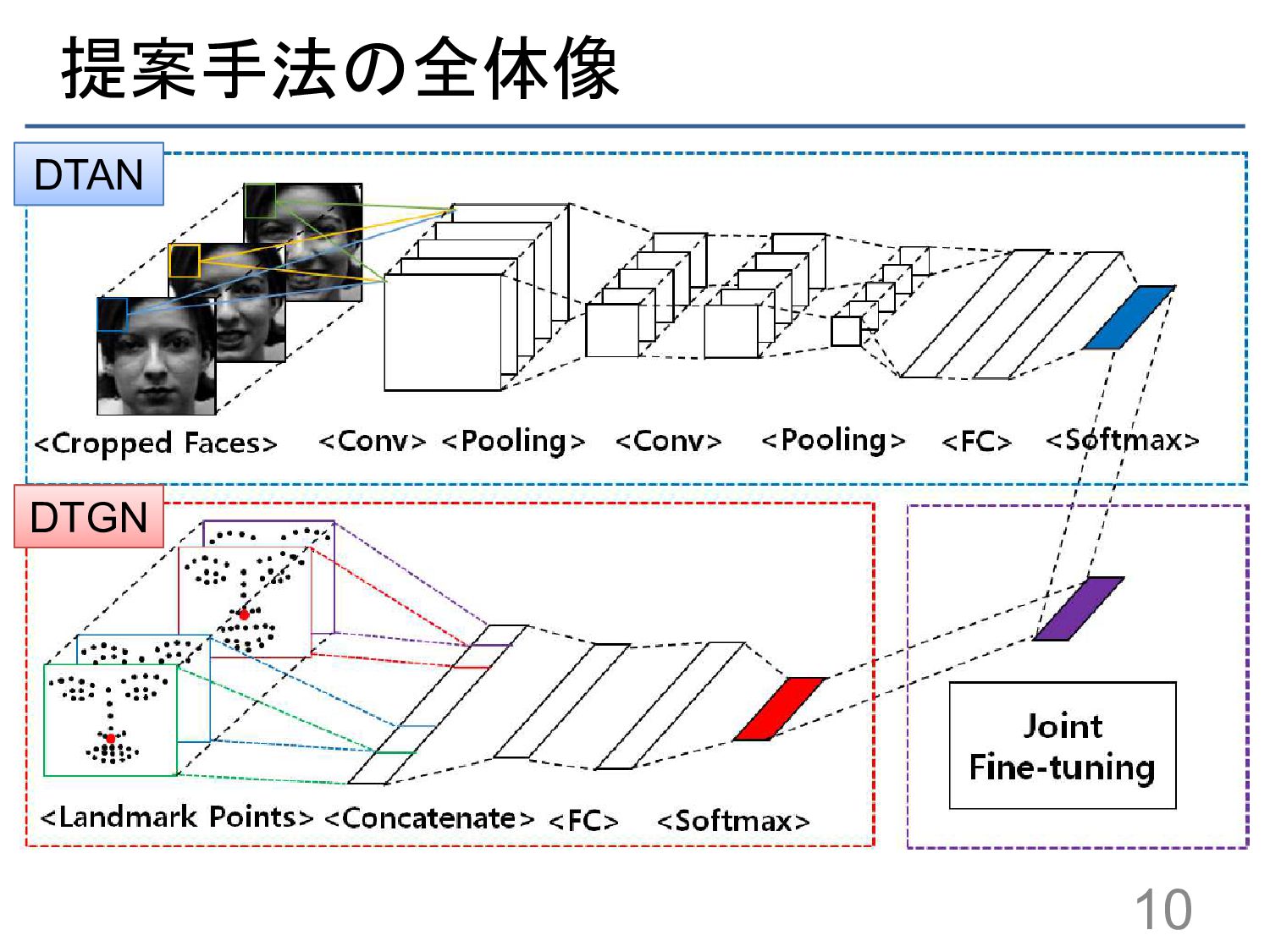{kind=link}
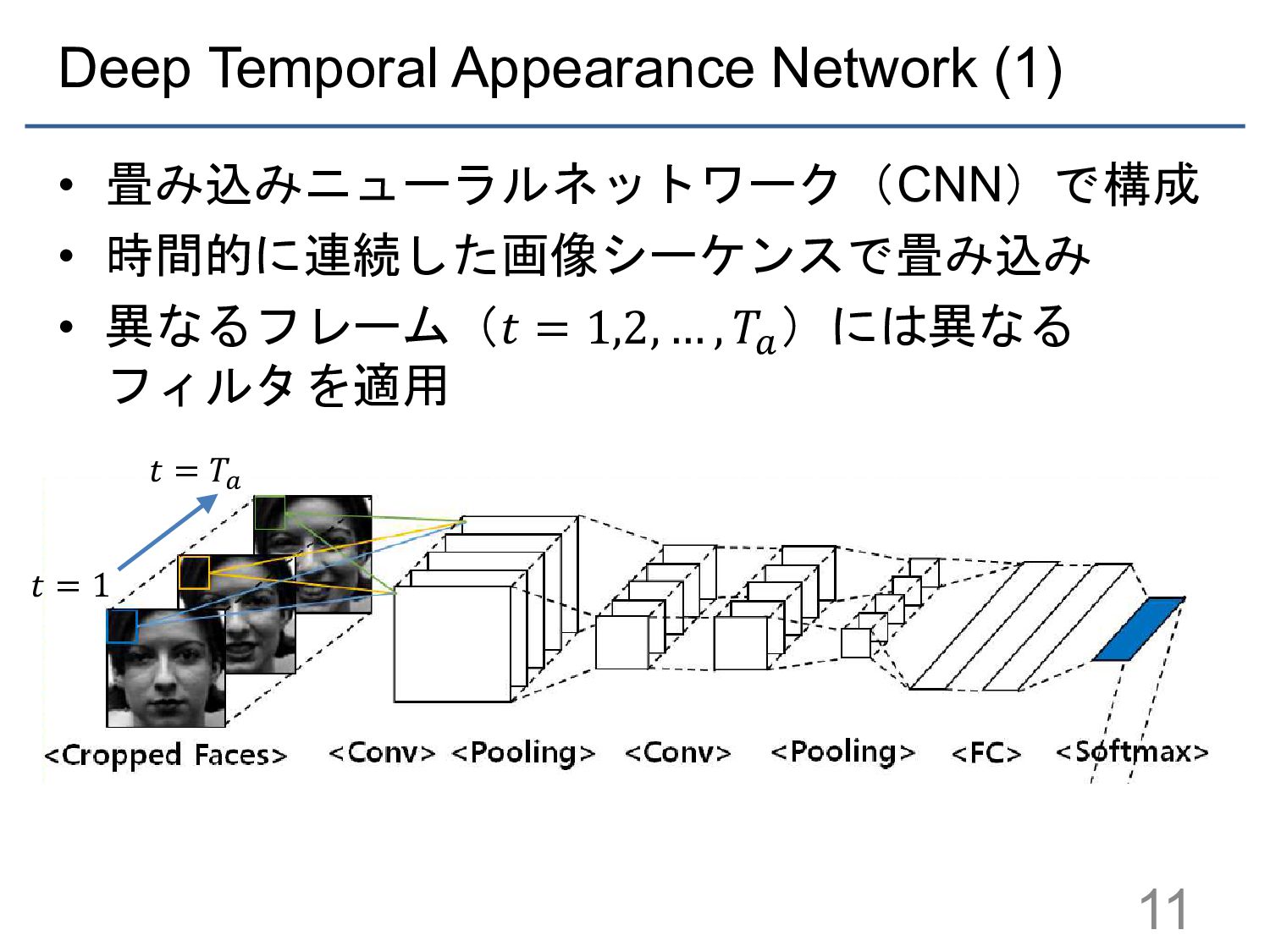{kind=link}
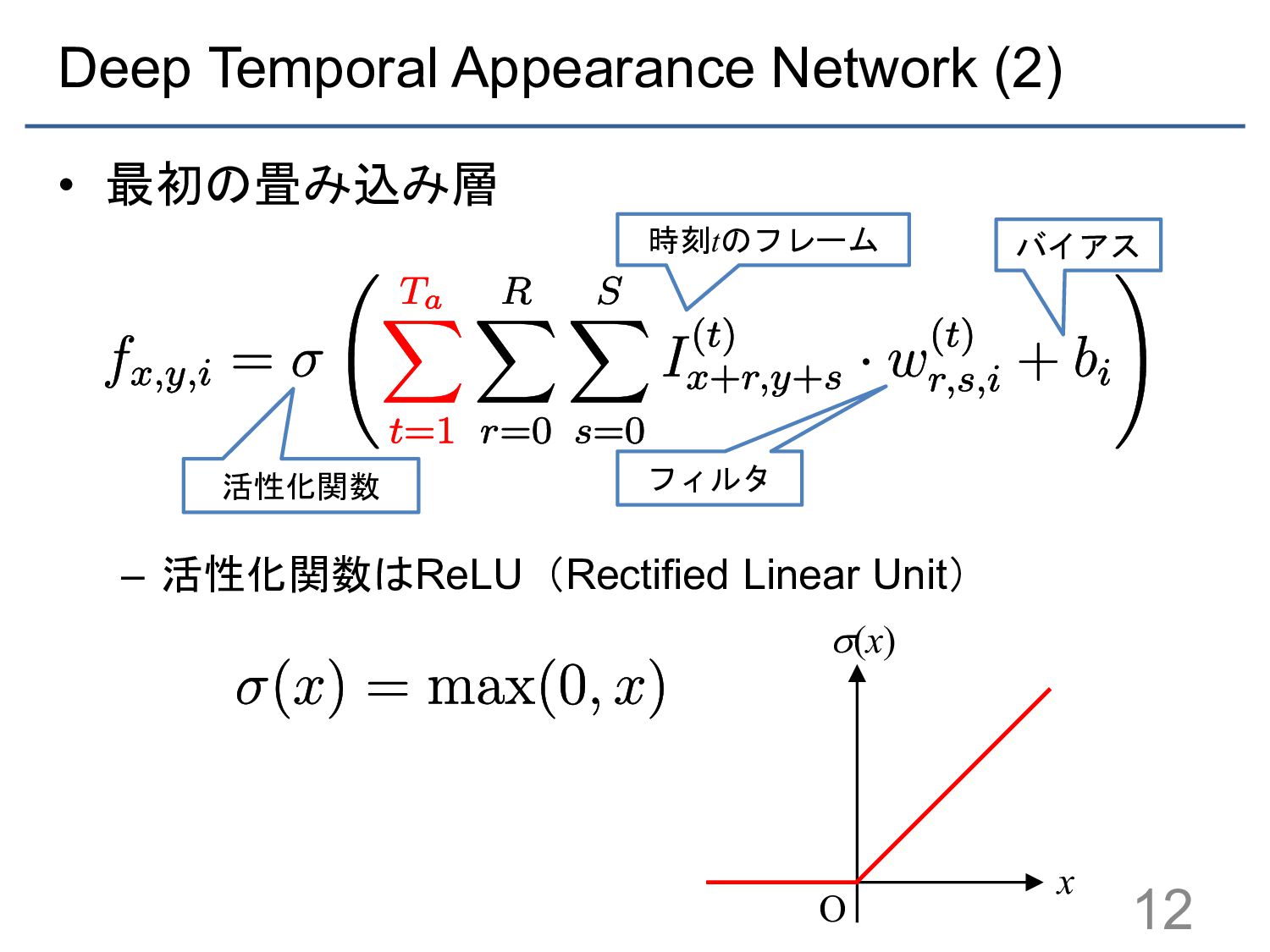{kind=link}
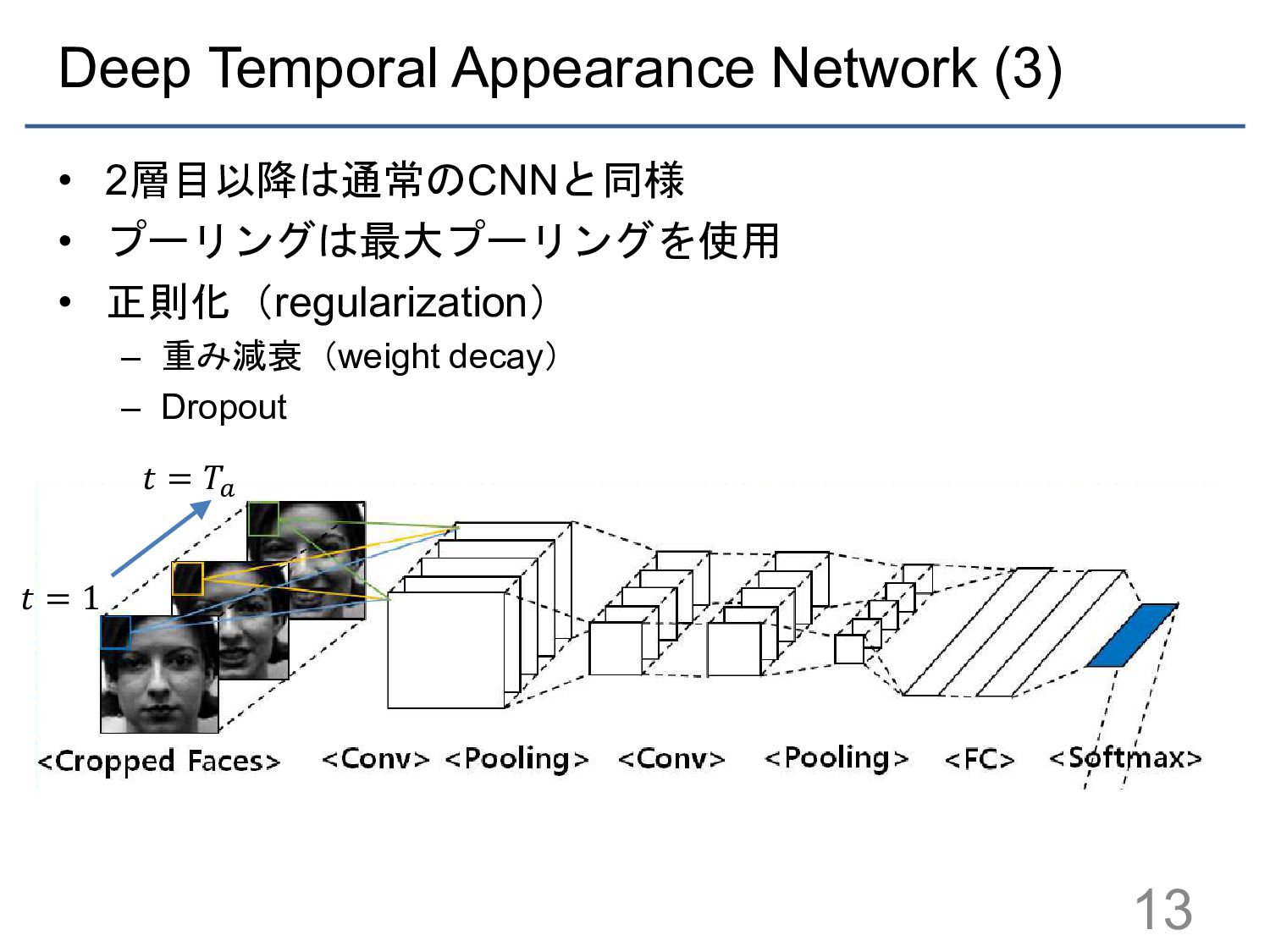{kind=link}
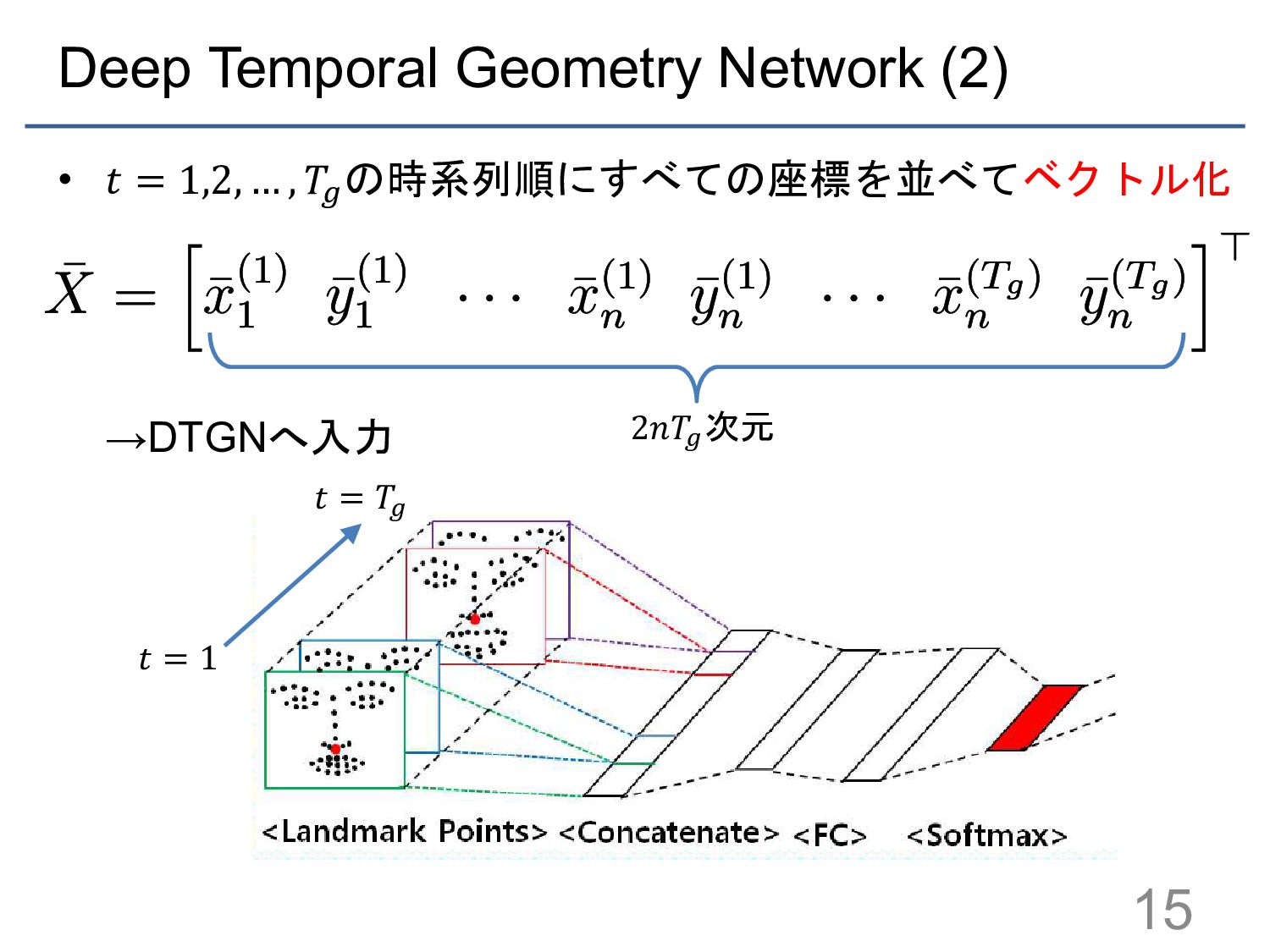
![Deep Temporal Geometry Network (1) • IntraFaceアルゴリズム[4]により,顔面上の n=49個のランドマーク点を検出 – ランドマーク点の座標:](https://files.speakerdeck.com/presentations/56927fb35a8a478a89cf8d38caae6f74/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
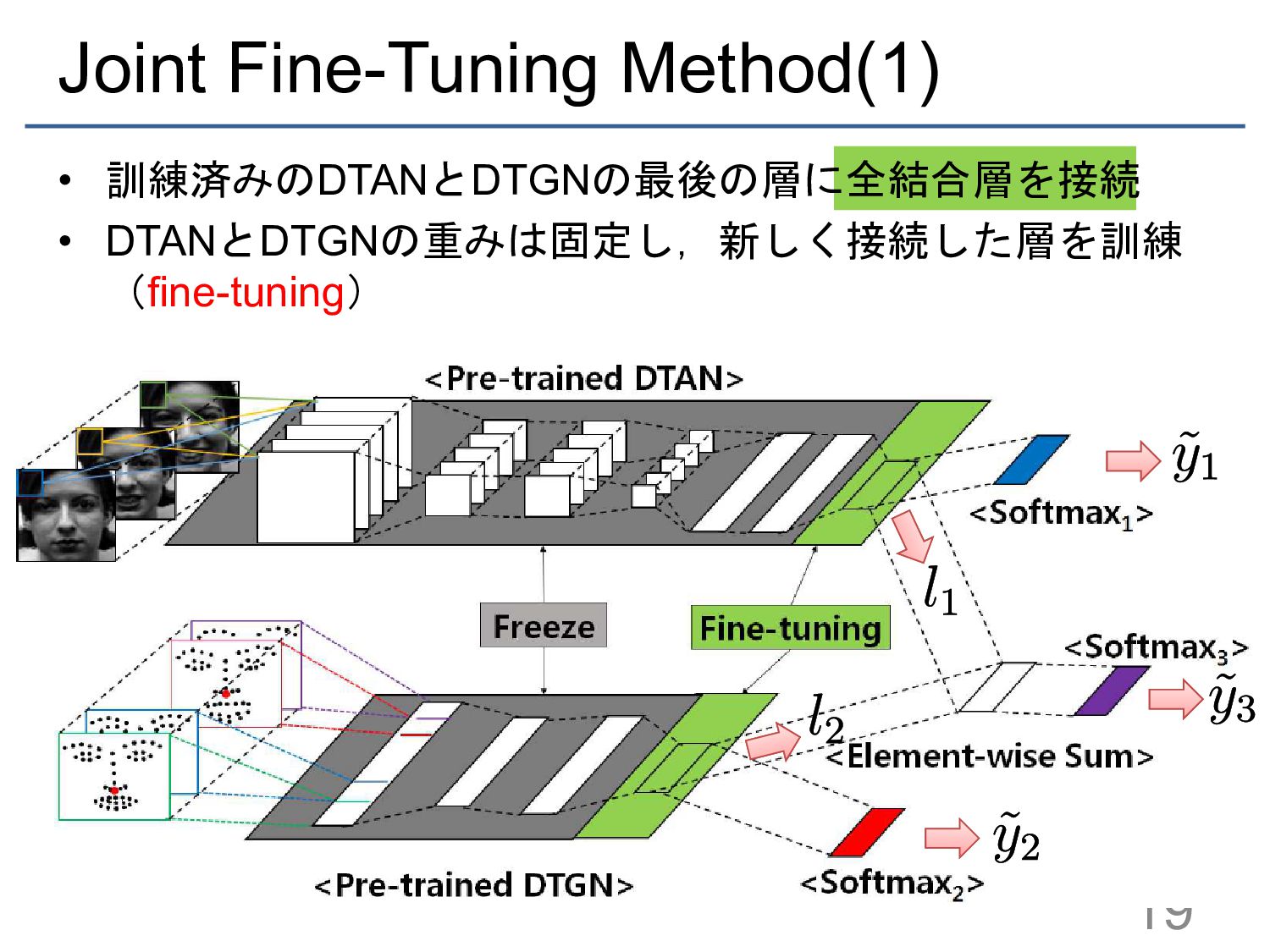{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
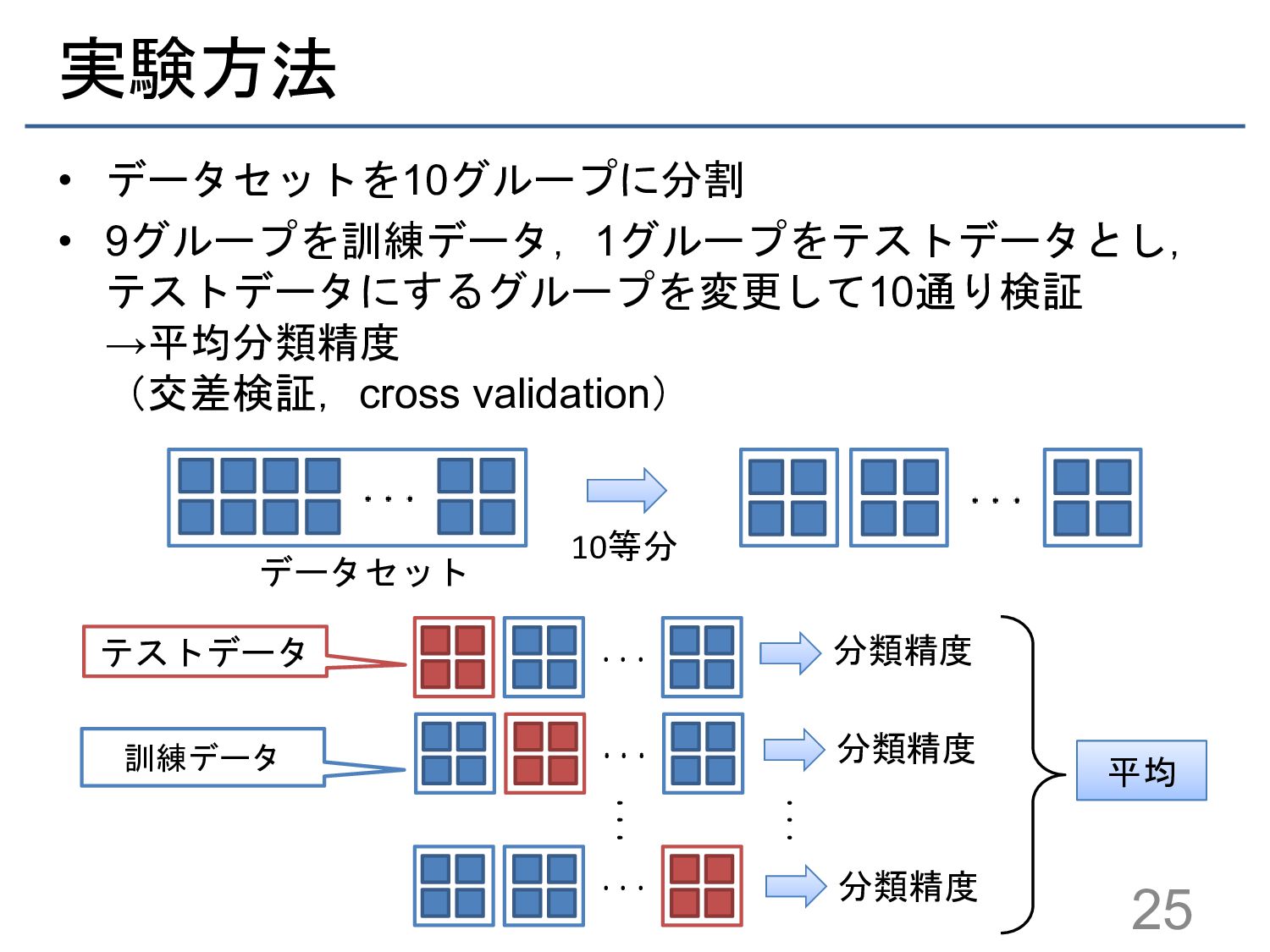{kind=link}
{kind=link}
![実験結果 – CK+(1) 手法 分類精度 [%] HOG 3D 91.44 MSR](https://files.speakerdeck.com/presentations/56927fb35a8a478a89cf8d38caae6f74/slide_26.jpg){kind=link}
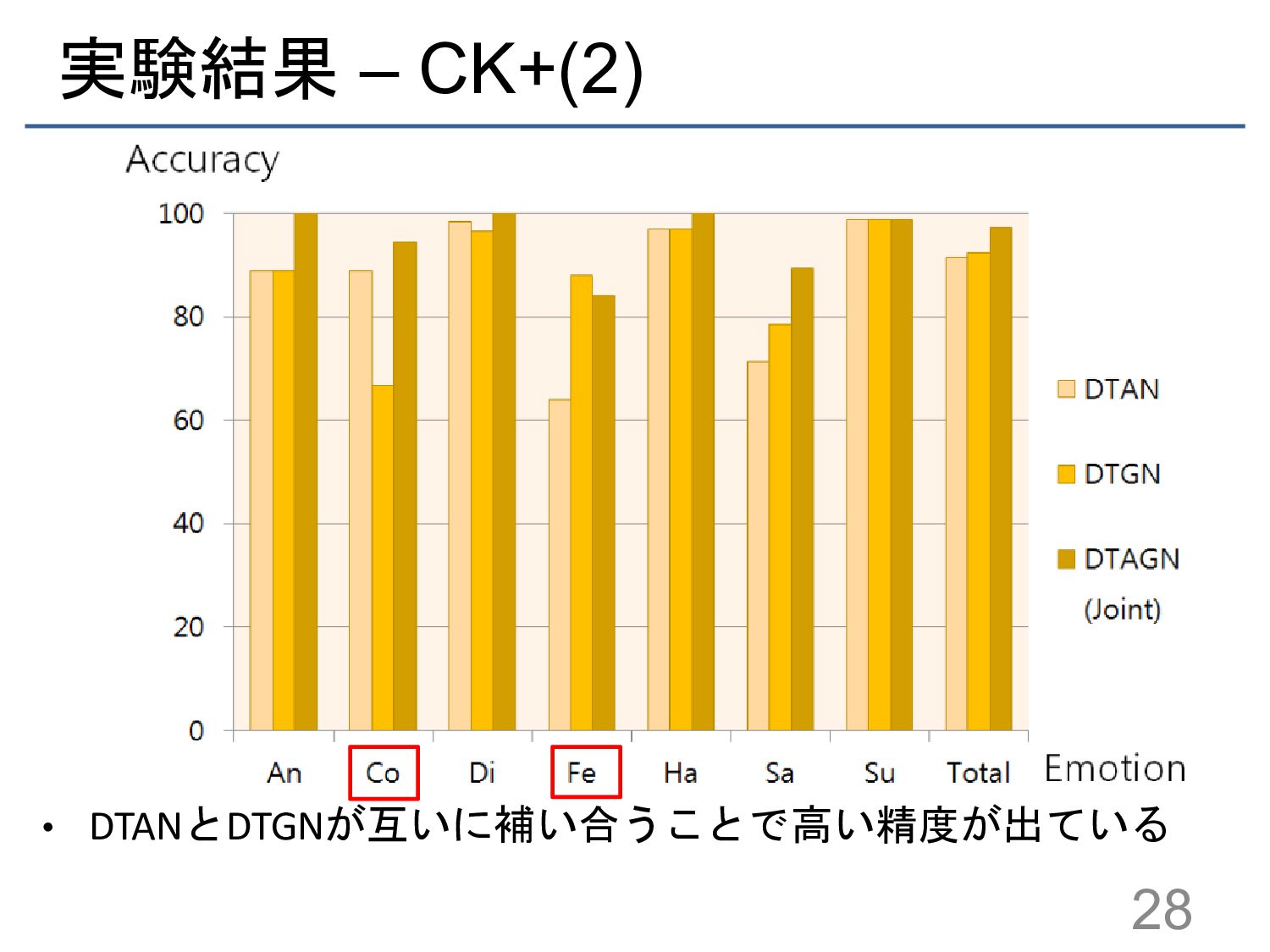{kind=link}
![実験結果 – Oulu-CASIA(1) 手法 分類精度 [%] 3D SIFT 55.83 LBP-TOP](https://files.speakerdeck.com/presentations/56927fb35a8a478a89cf8d38caae6f74/slide_28.jpg){kind=link}
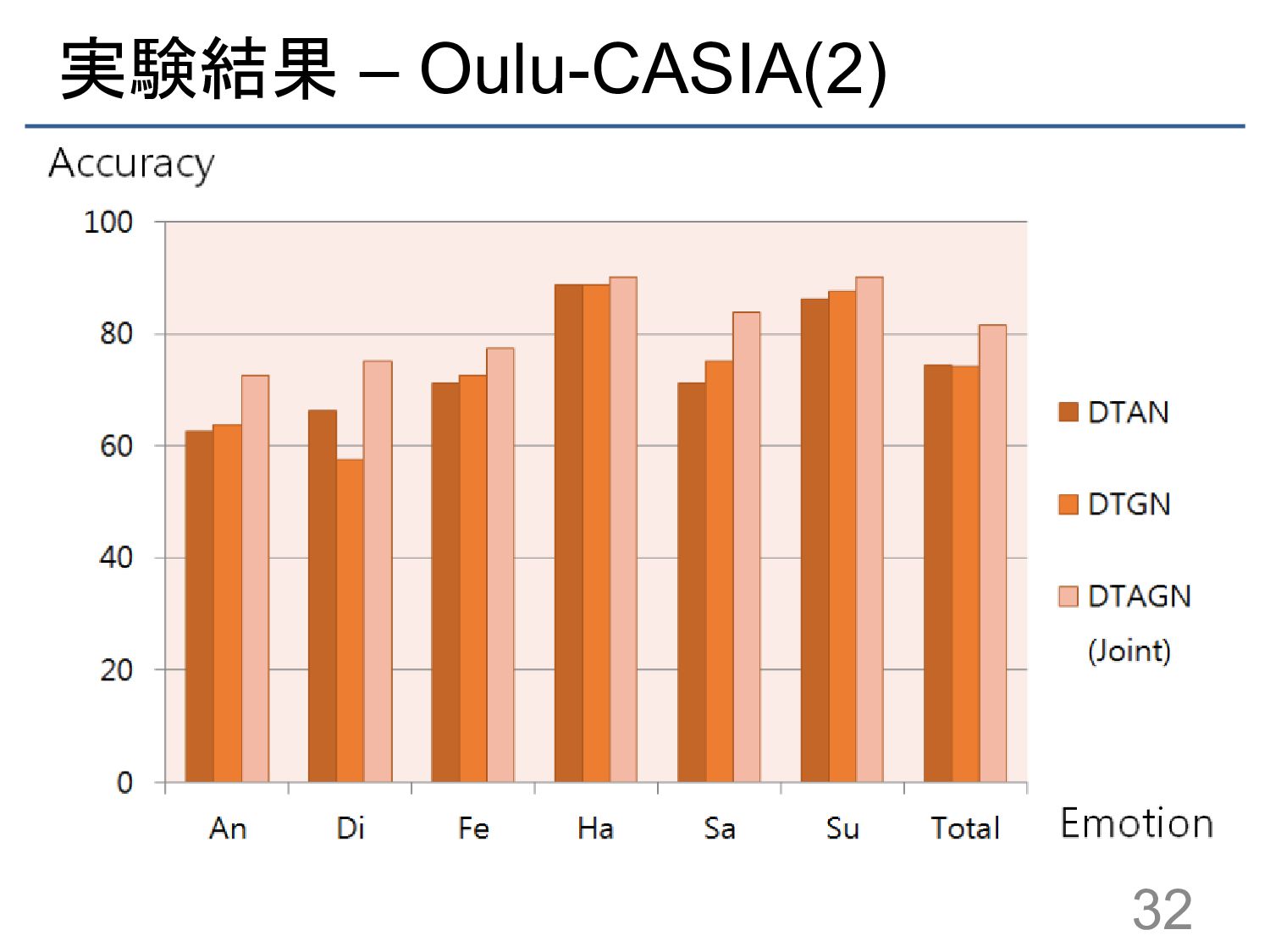{kind=link}
![実験結果 – MMI(1) 手法 分類精度 [%] HOG 3D 60.89 3D](https://files.speakerdeck.com/presentations/56927fb35a8a478a89cf8d38caae6f74/slide_30.jpg){kind=link}
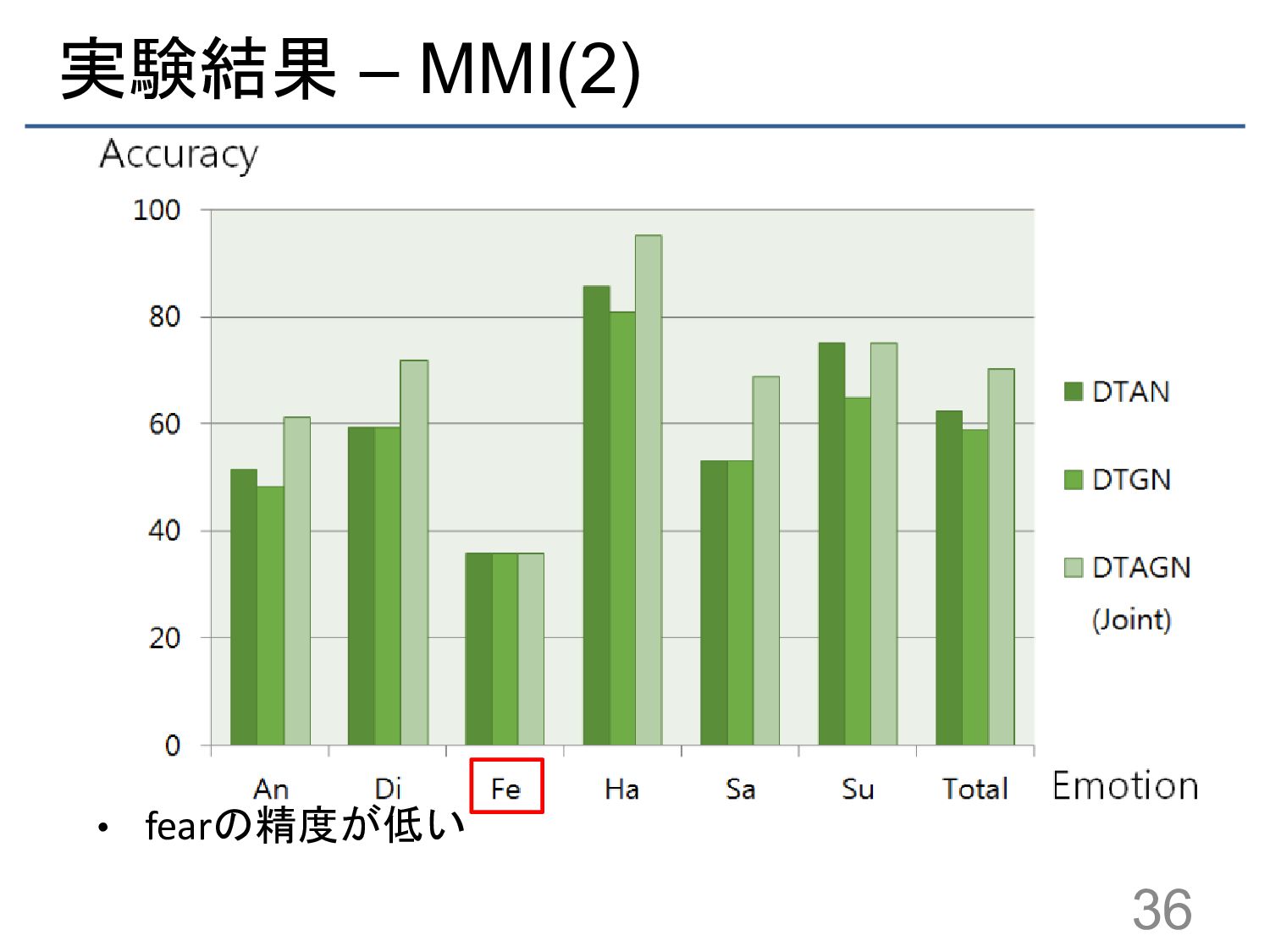{kind=link}
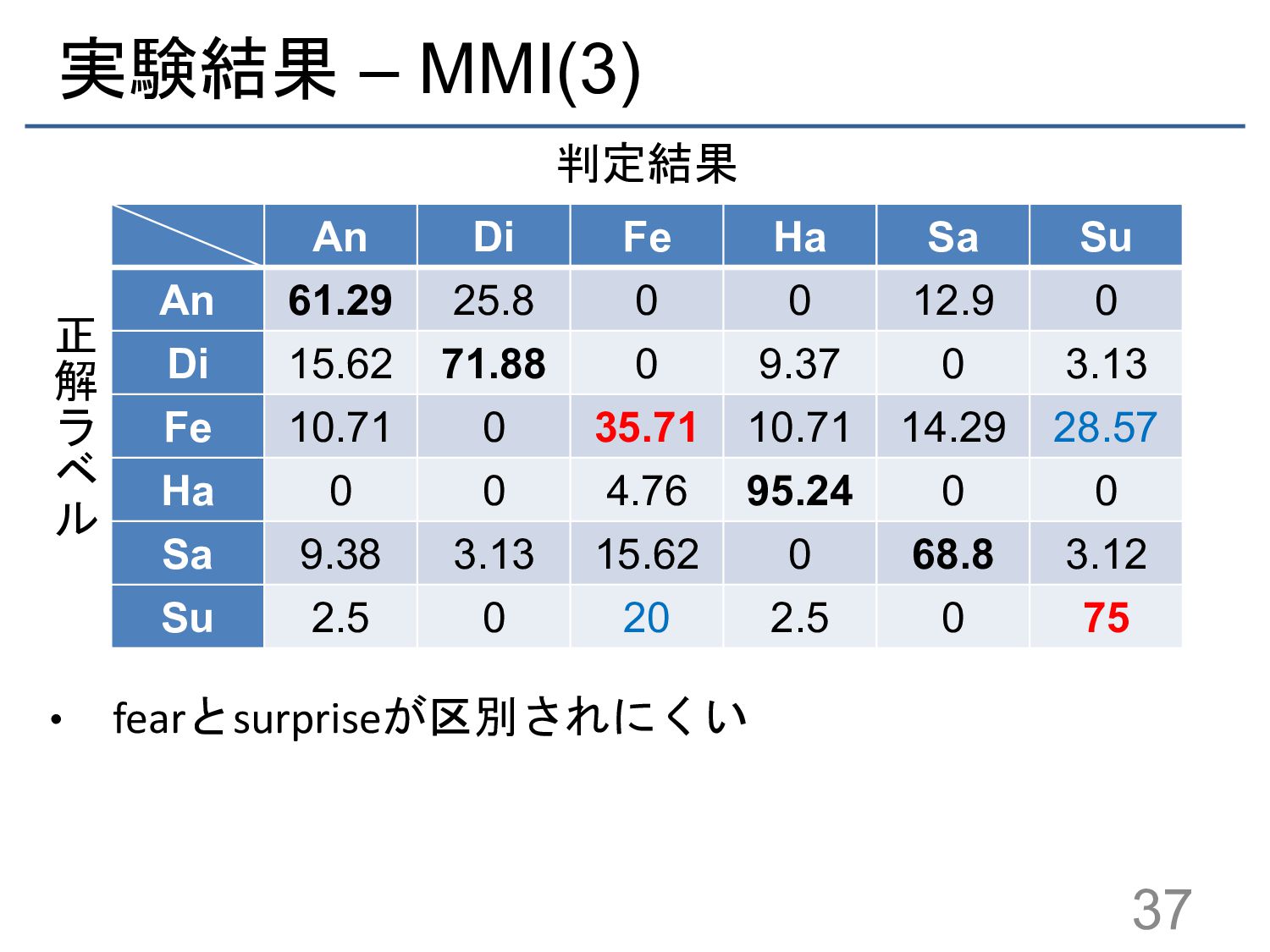{kind=link}
{kind=link}
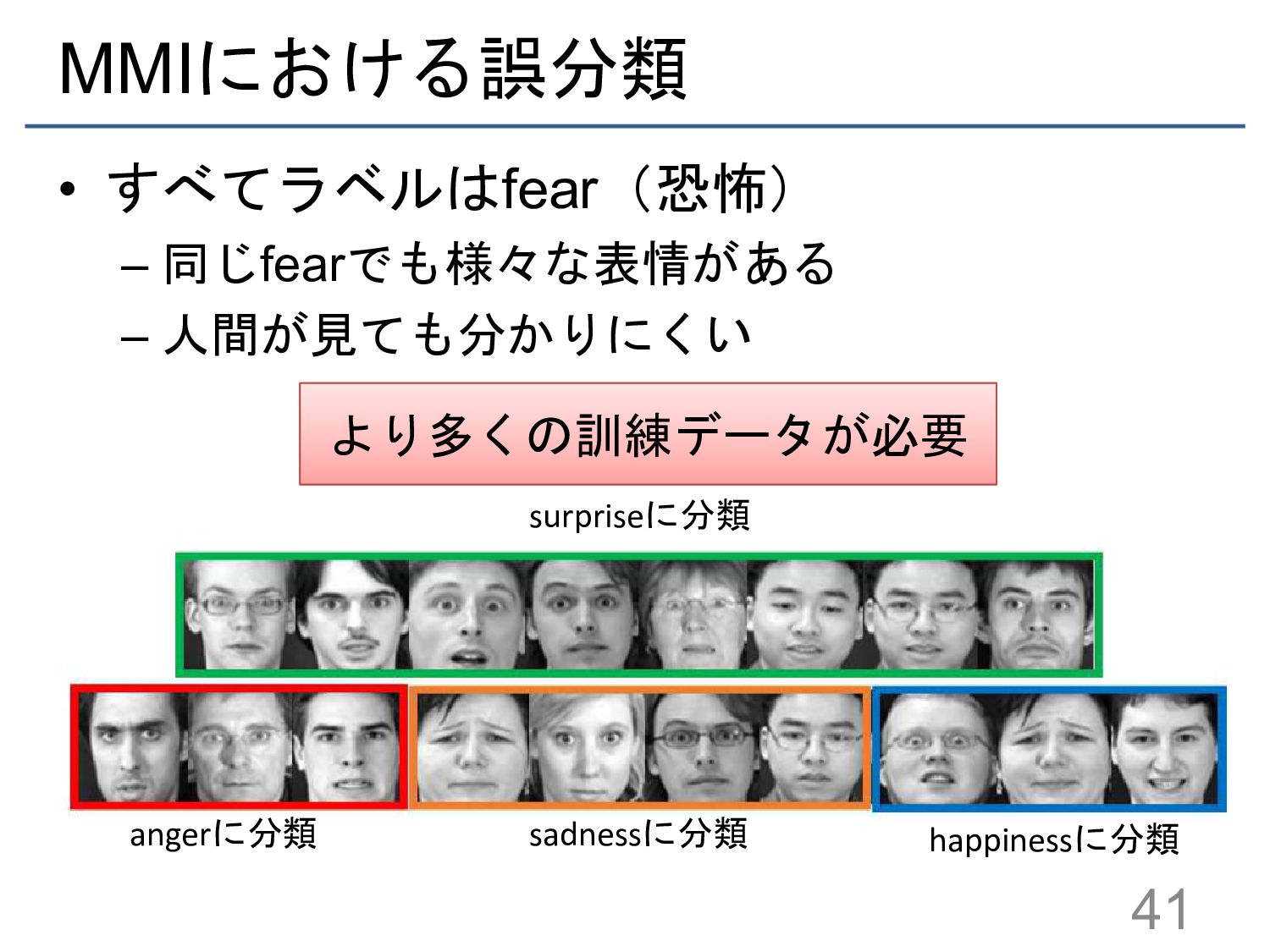{kind=link}
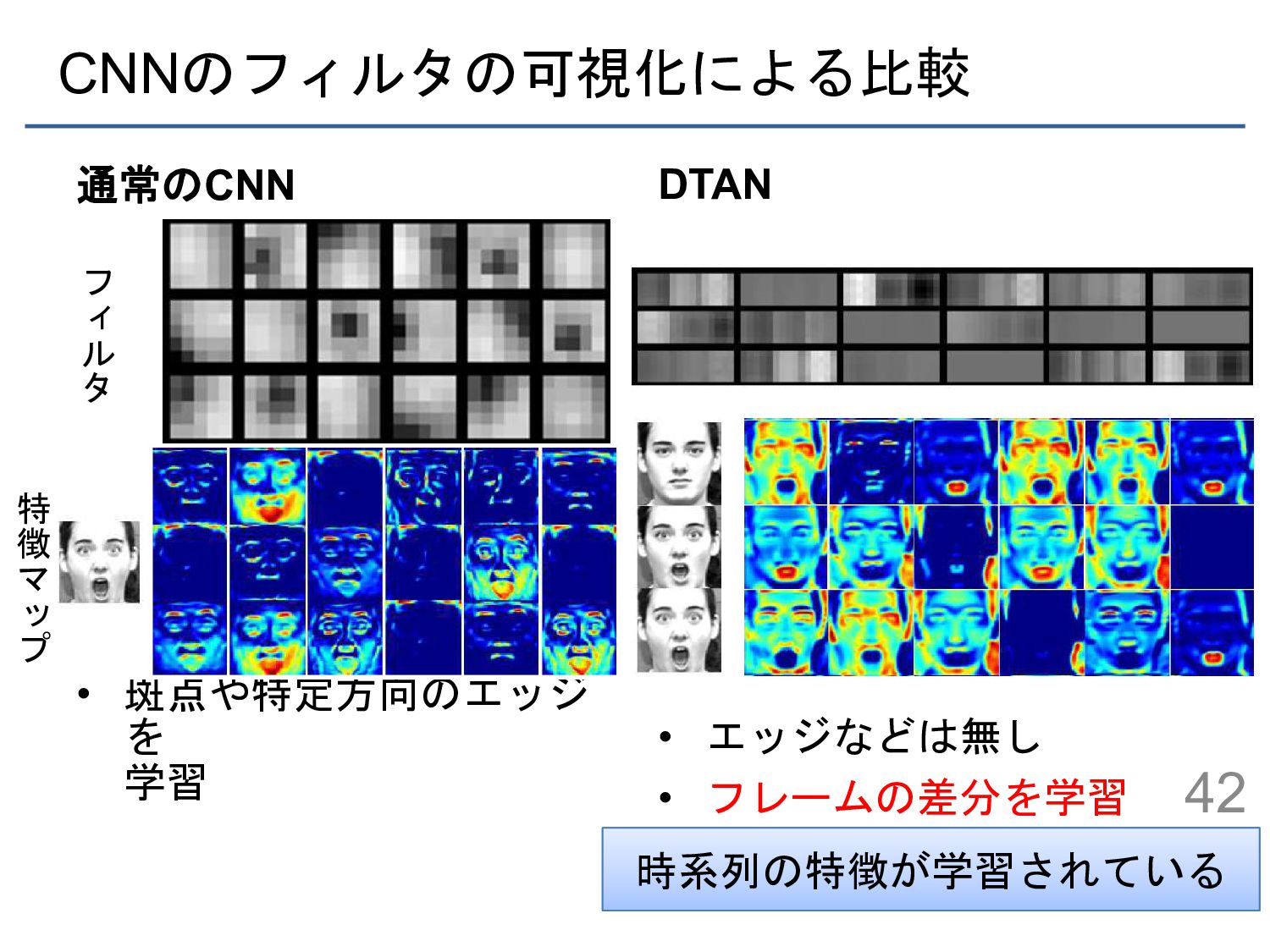{kind=link}
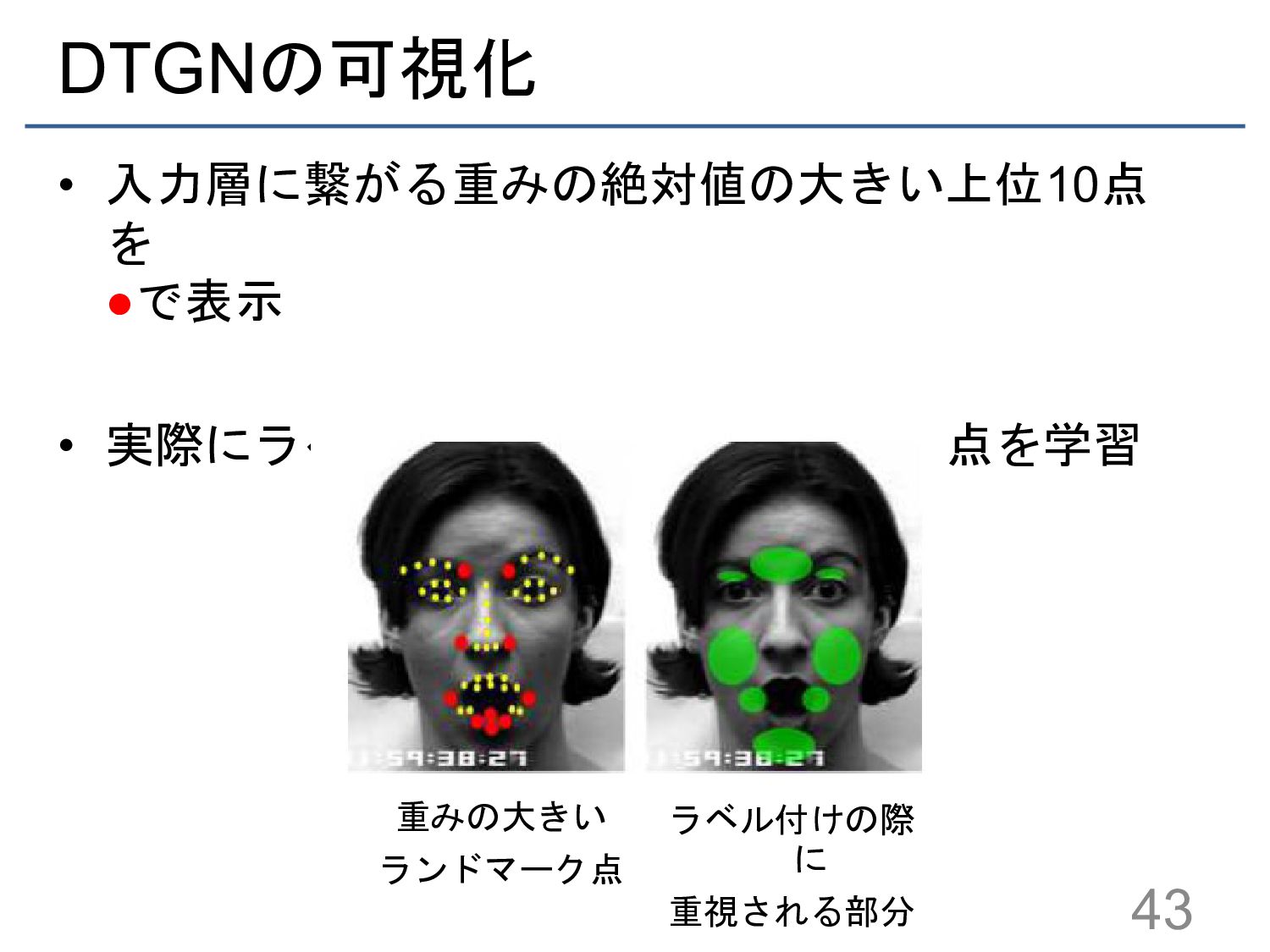{kind=link}
{kind=link}