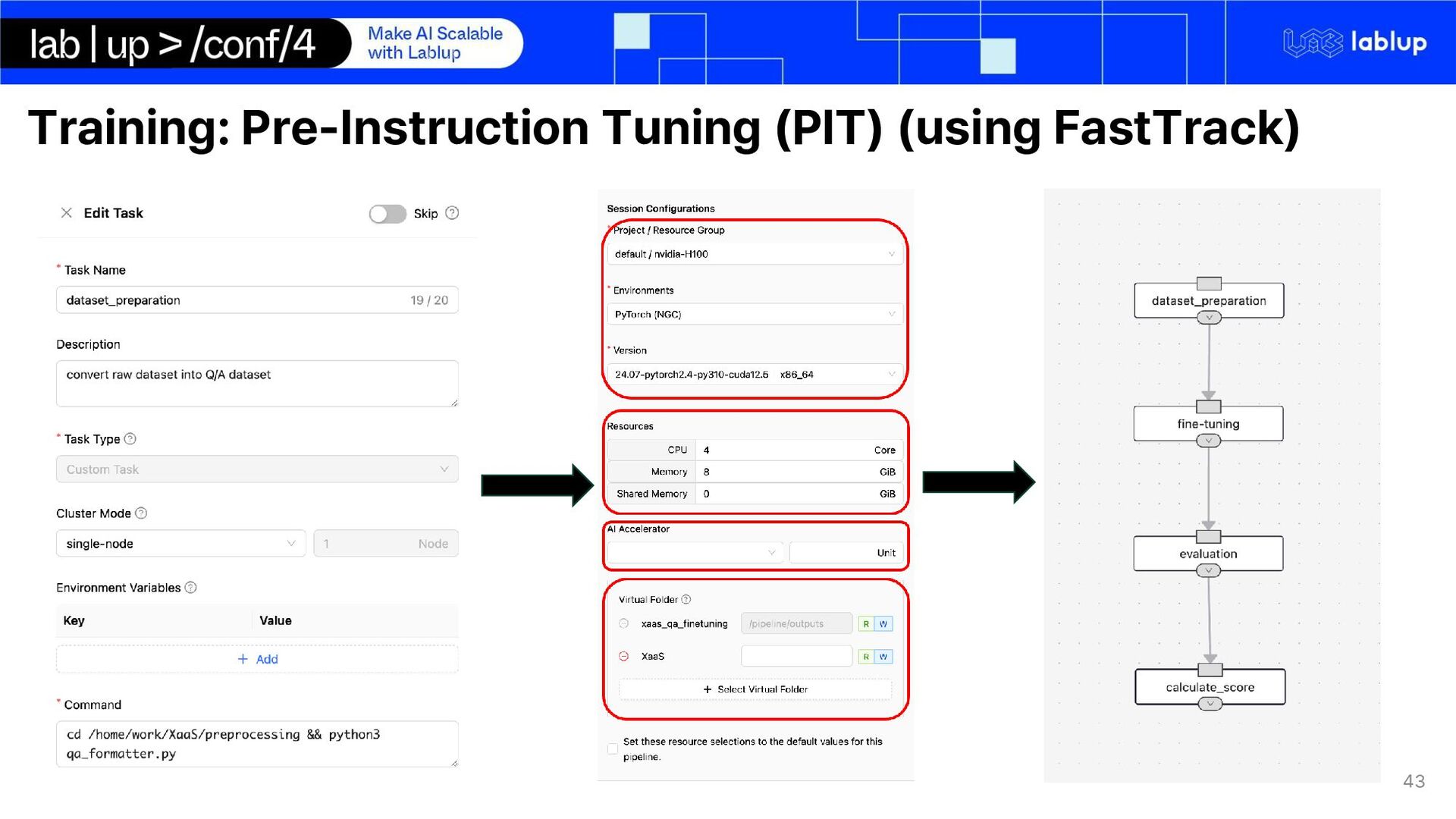
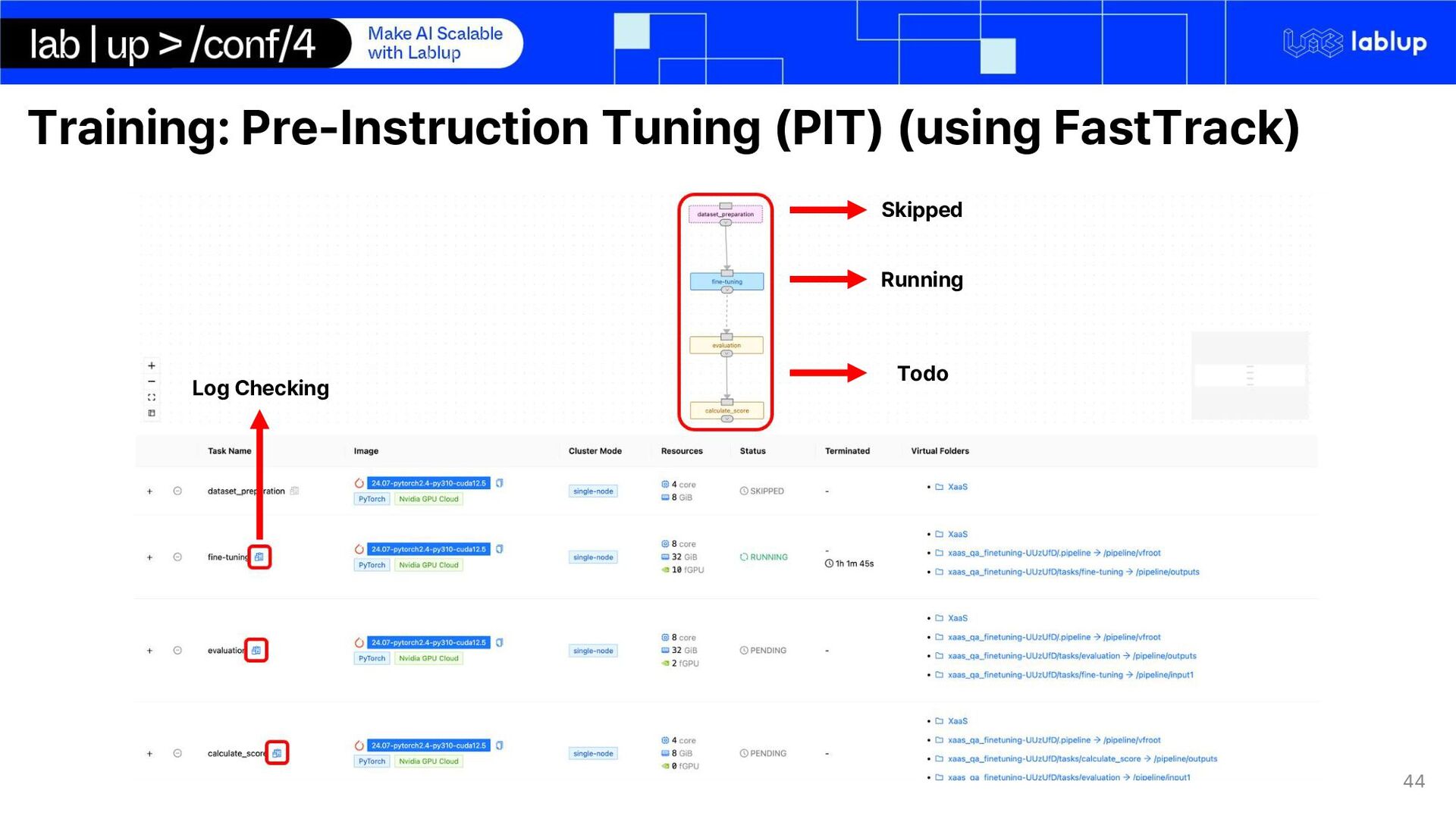
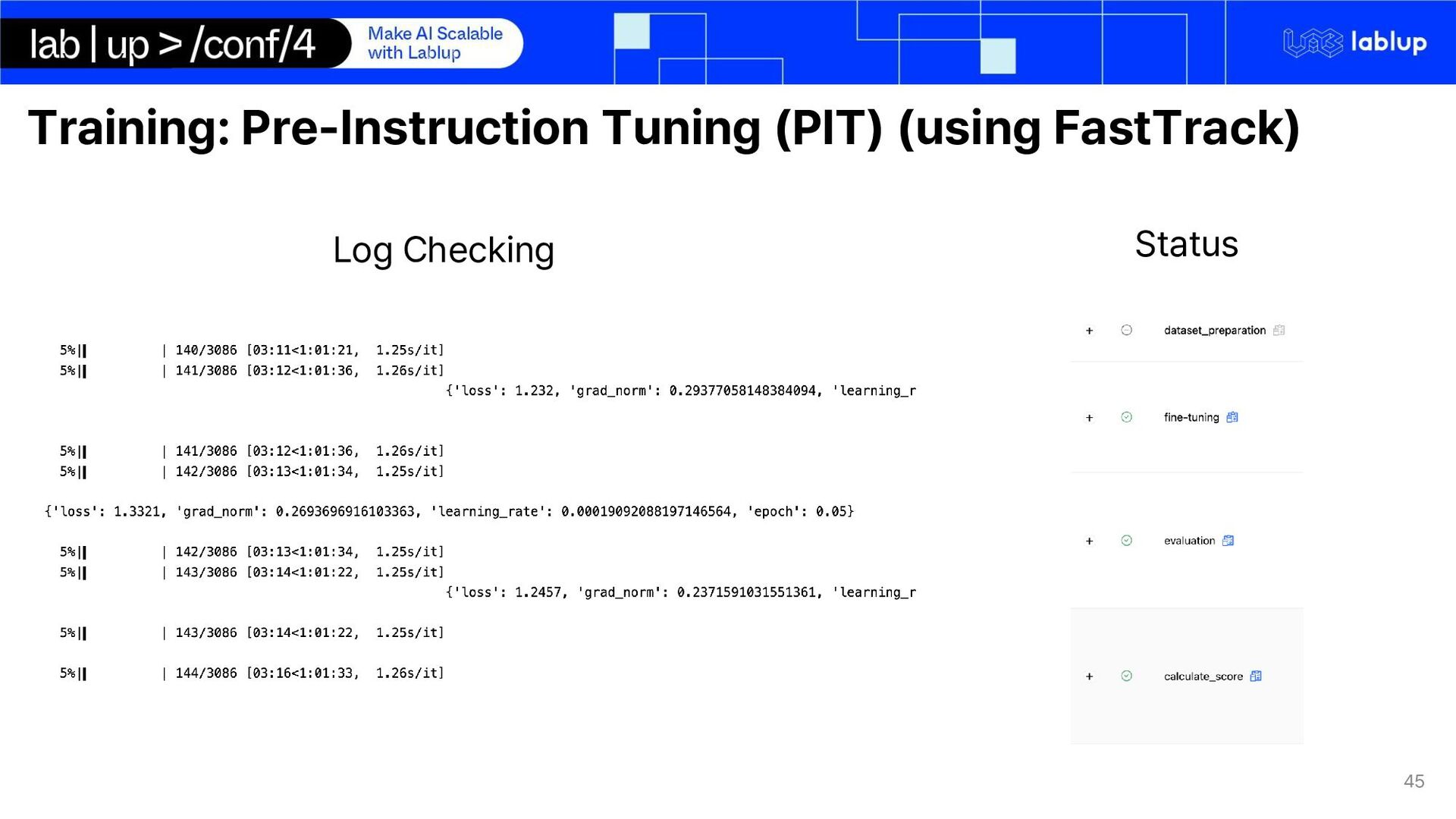
2. Background 3. Objective 4. Demo 2. Part 2 - Data Preparation and Processing pipeline 1. Data acquisition for Domain Adaptation 2. Synthetic Data Generation Pipeline 3. Part 3 - Model Development and Evaluation 1. Domain Adaptation 2. Pre-Instruction Tuning (PIT) (using FastTrack) 3. Key-Fact Fine-tuning 4. Fine-tuning & Evaluation
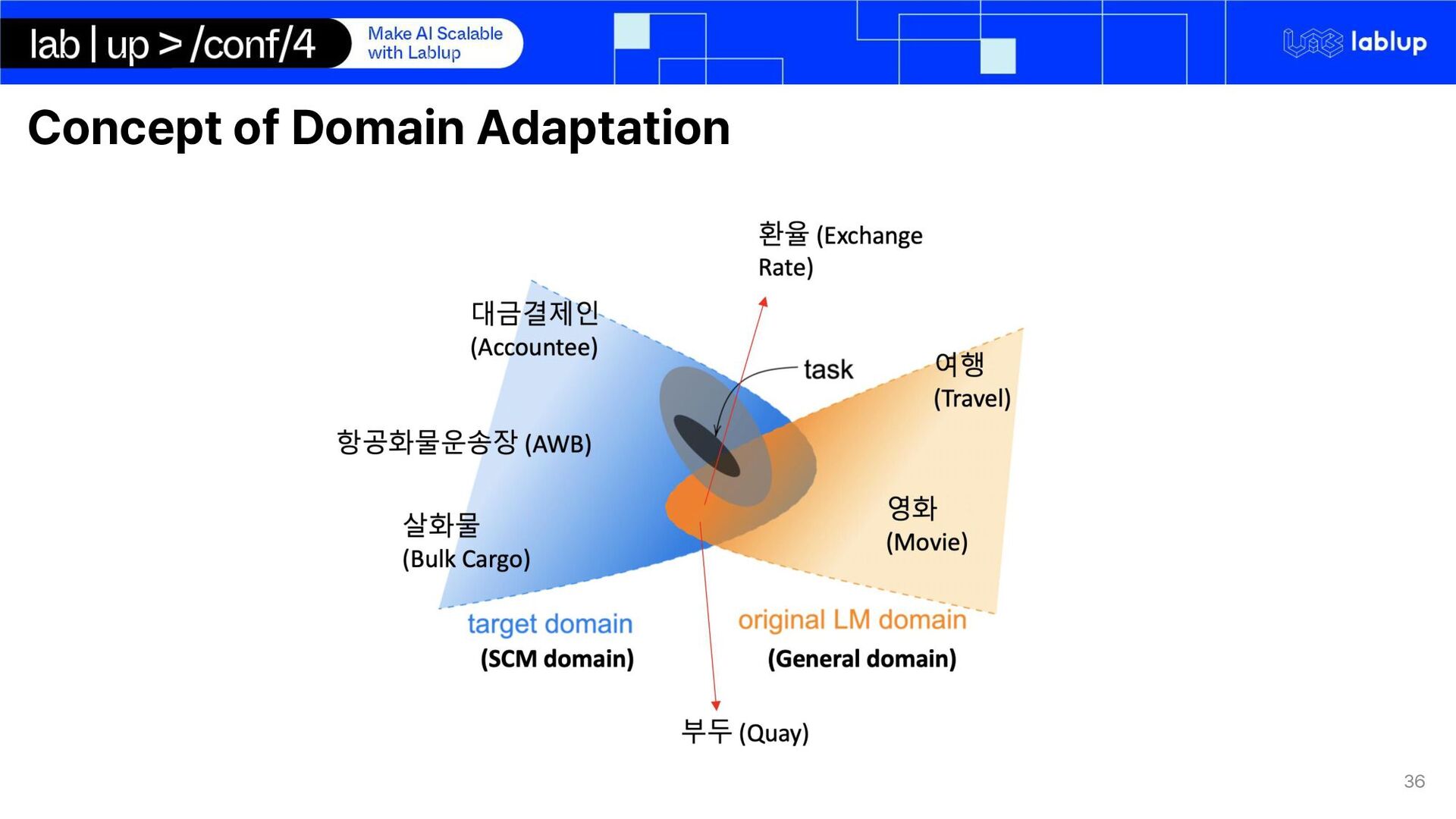
goods or services across borders, connecting supplier and buyers globally o Key in enabling access to broader markets, reducing costs o Supply Chain Management (SCM) ensures smooth operations by managing Logistics Customs Tarrifs Deliveries
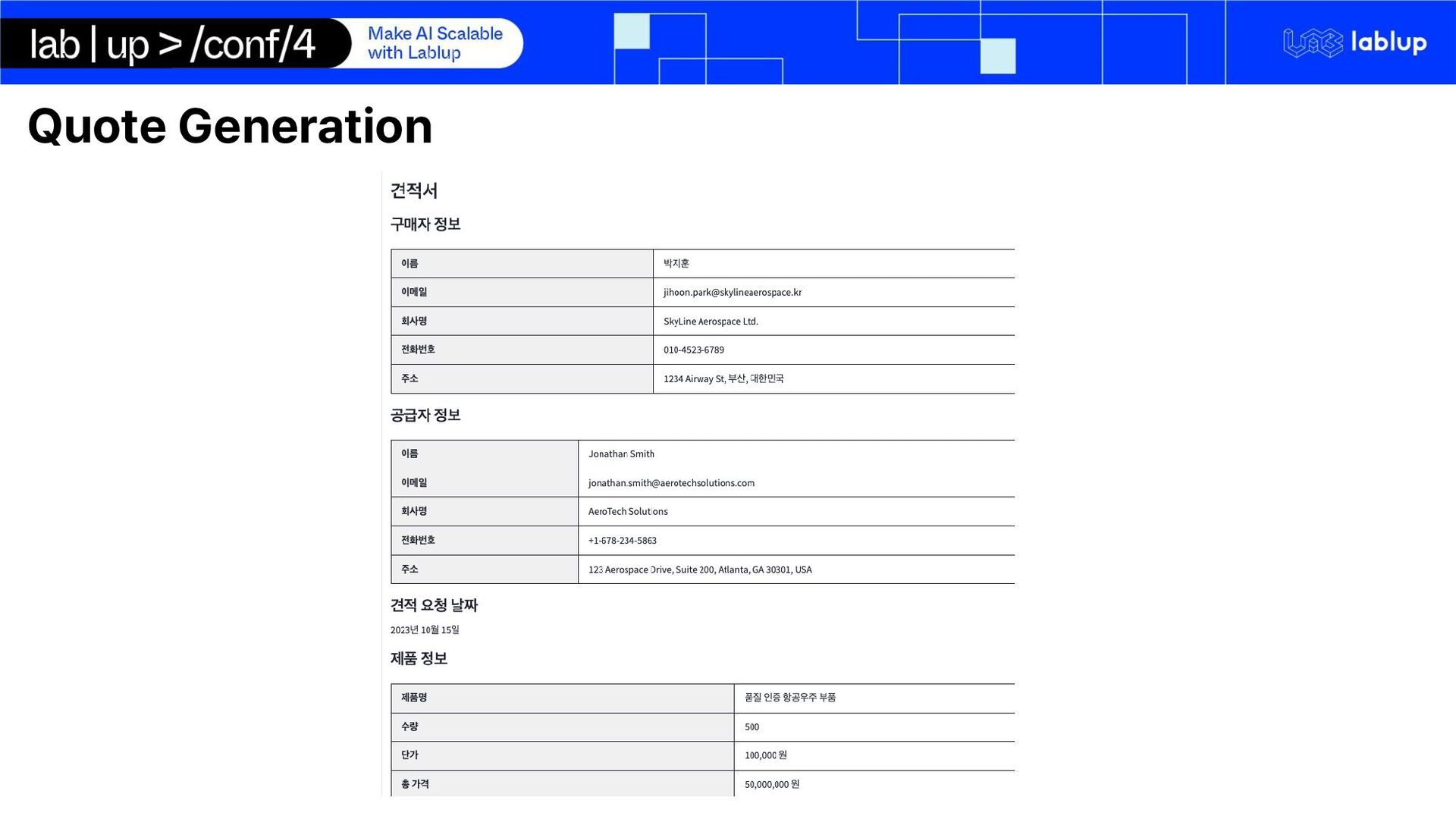
제품에 대해 더 많은 정보를 알고 싶습니다. 특히 X 제품의 가격과 배송 기간에 대해 알려주시면 감사하겠습니다." – Supplier (Response): "안녕하세요. X 제품의 가격은 개당 10,000원이며, 최소 주문 수량은 50개입니다. 배송 기간은 주문 후 약 7일 정도 소요됩니다." – Buyer (Negotiation): "가격을 조금 조정할 수 있을까요? 100개를 주문하면 할인이 가능한지 알고 싶습니다." – Supplier (Response to Negotiation): "100개 주문 시 5% 할인을 제공해드릴 수 있습니다. 이 경우 개당 9,500원이 되며, 배송 기간은 동일하게 유지됩니다." – Buyer (Request for Quote): "최종 조건으로 견적서를 보내주시면 감사하겠습니다. 확인 후 바로 주문하겠습니다." – Supplier (Final Quote): "첨부된 견적서를 확인해주시기 바랍니다. 기타 문의 사항이 있으시면 언제든지 연락 주십시오."
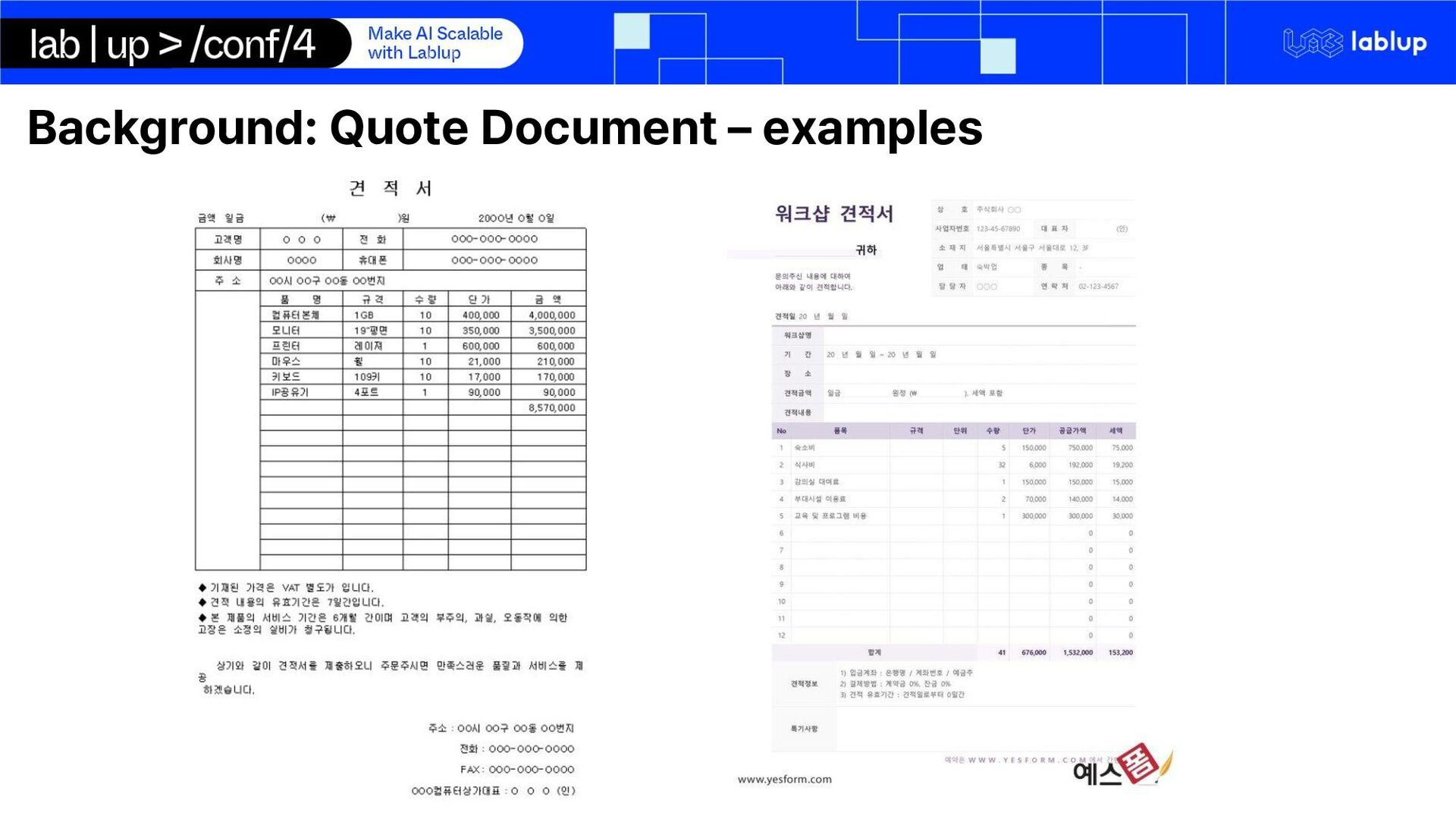
Long email communications Scattered Information Across Multiple Emails Manual information extraction o Errors can occur o Missing details o Takes long time Time-Consuming Quote Generation Privacy and confidentiality o Can not use OpenAI ChatGPT and other API services to help
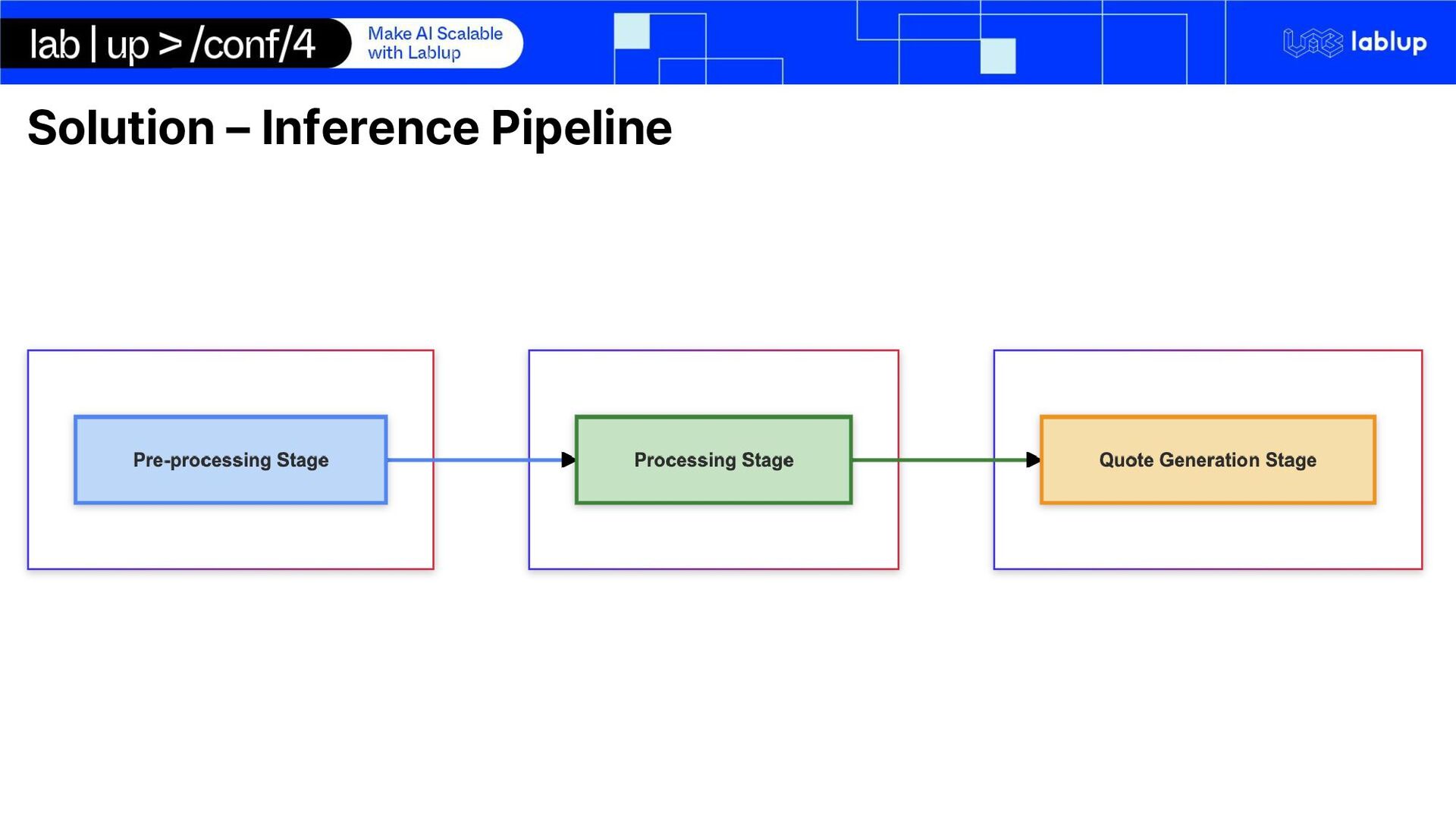
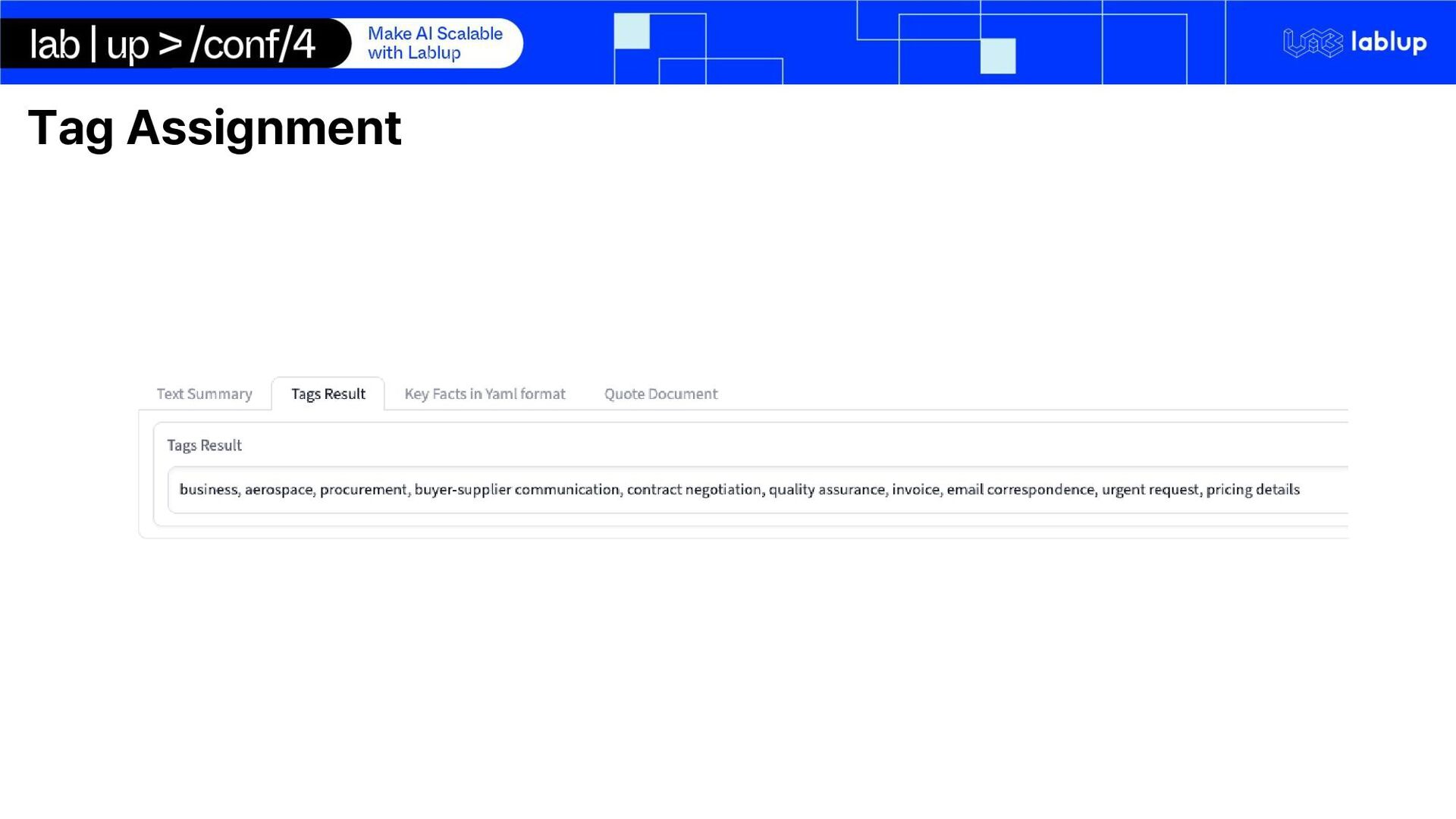
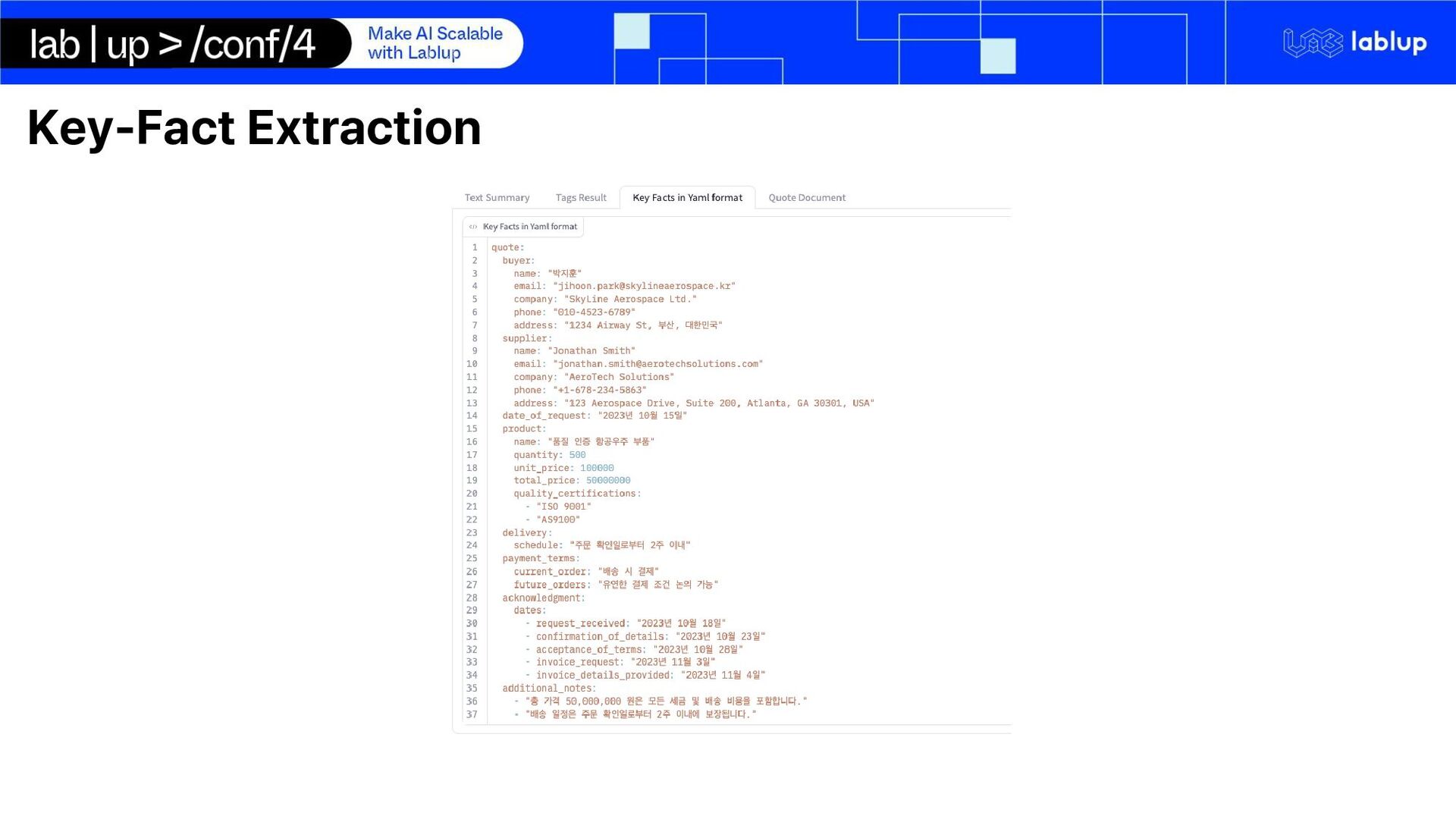
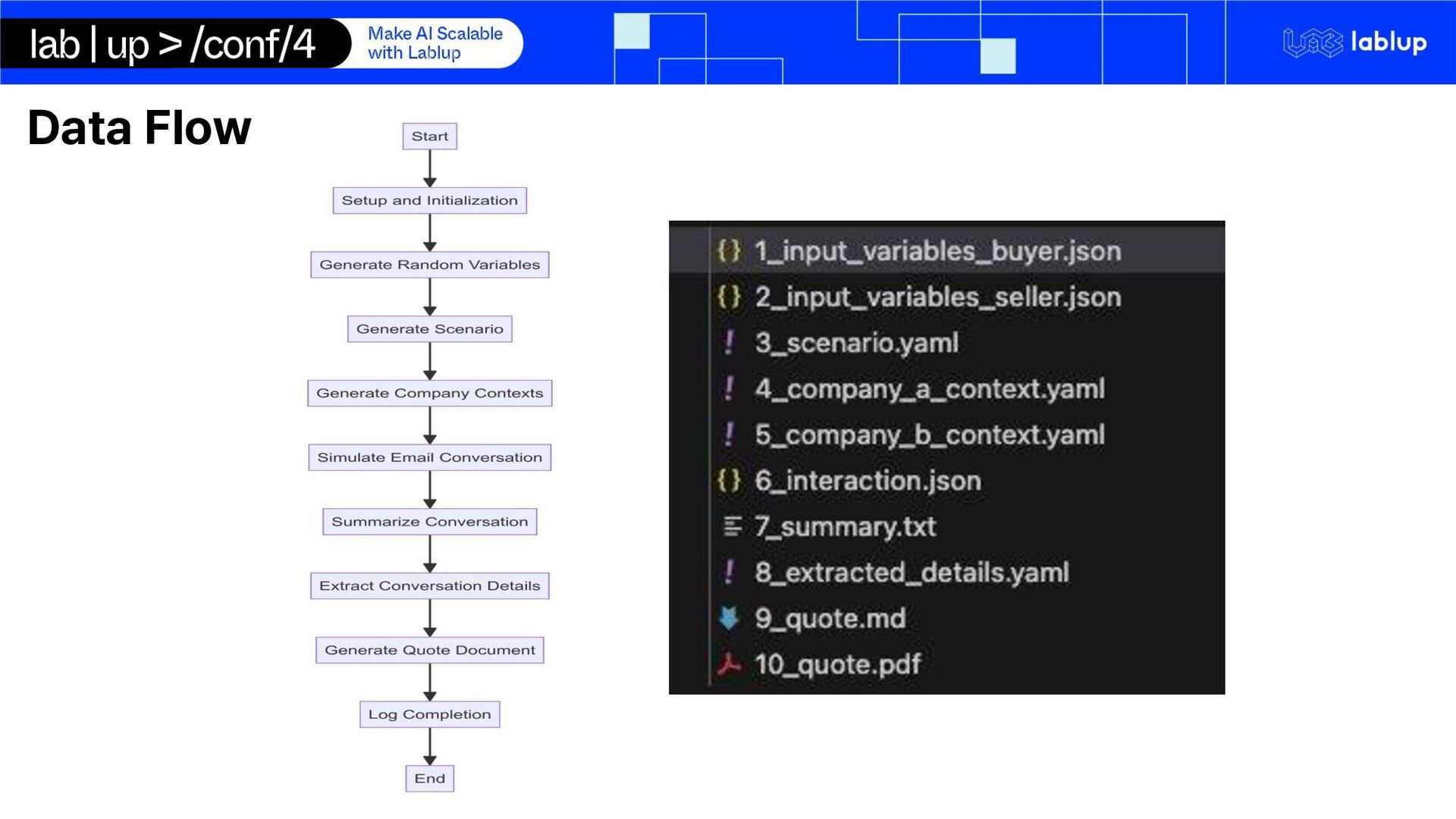
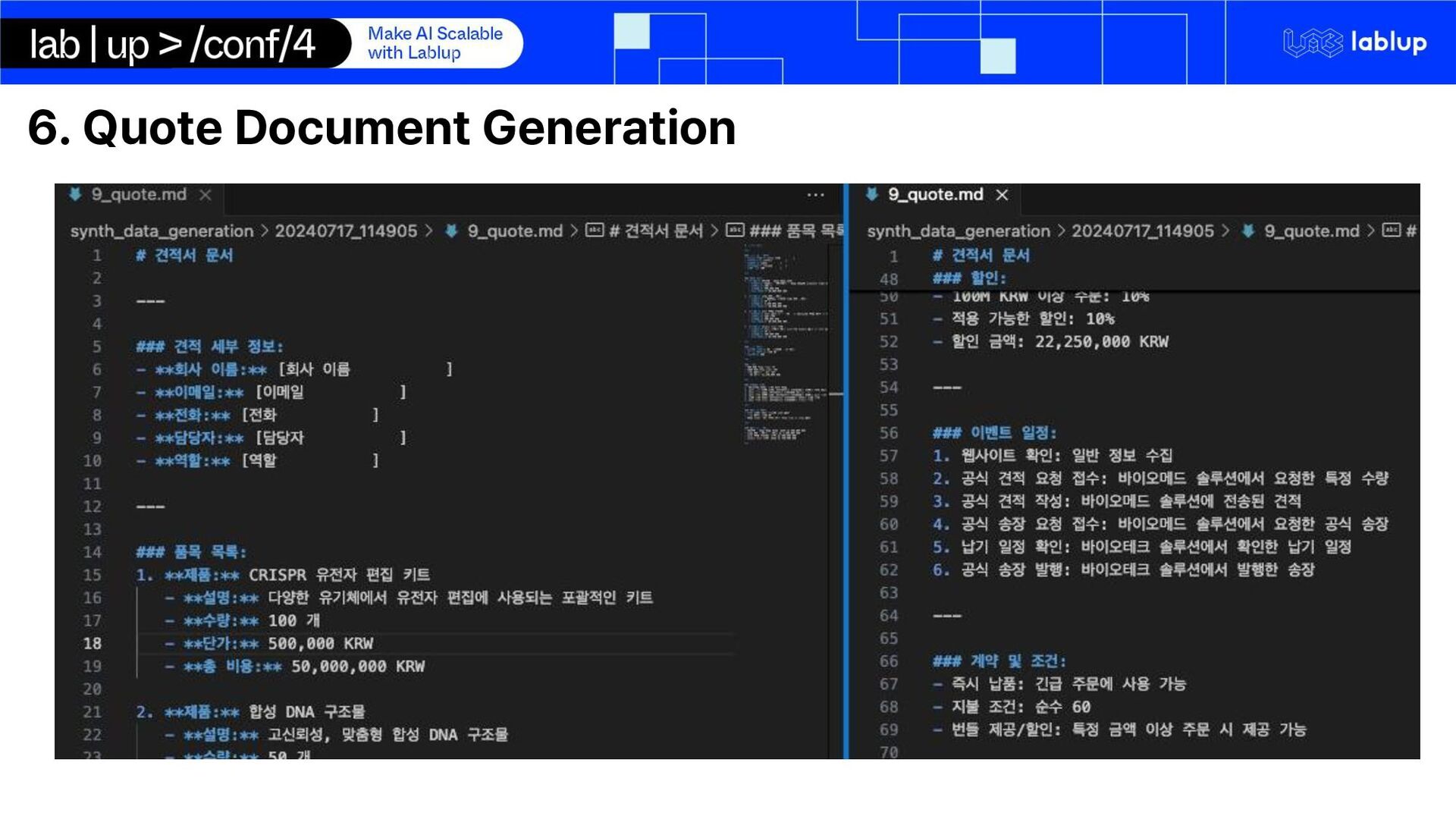
processing and quote generation pipeline using open-source self-hosted LLM run on Backend.AI Summarization Key-Fact Extraction Tag Assignment Quote Document Generation
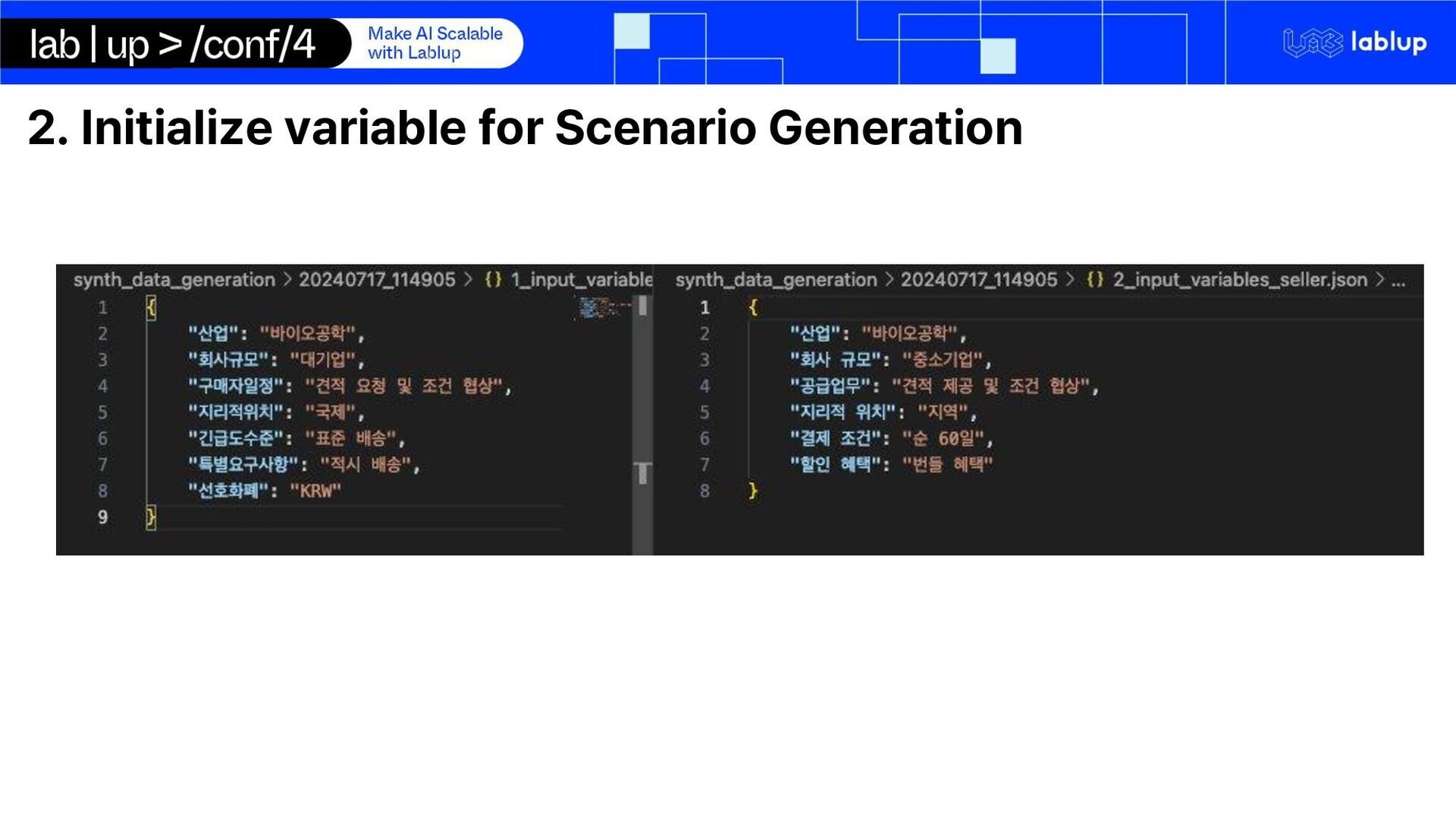
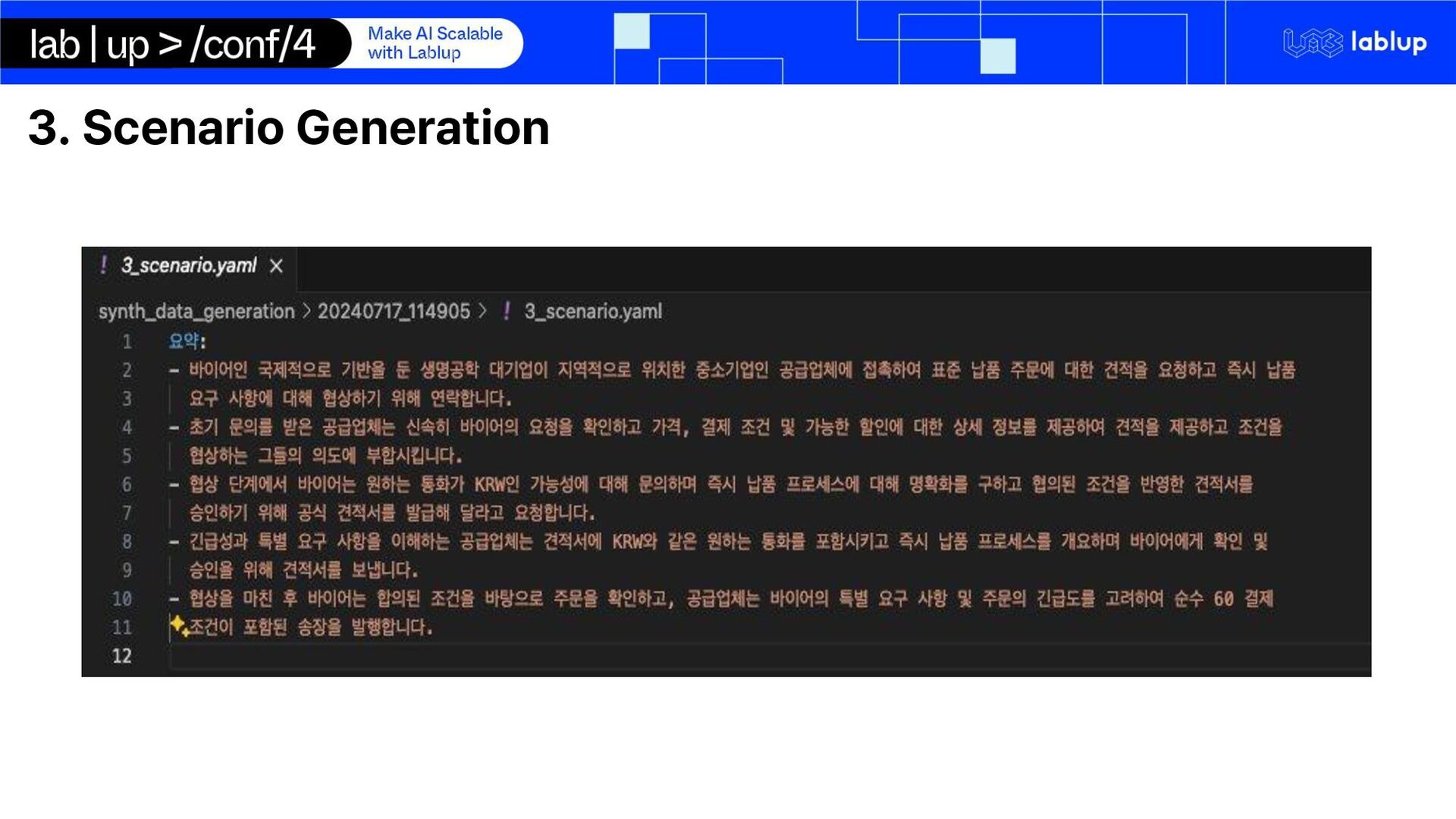
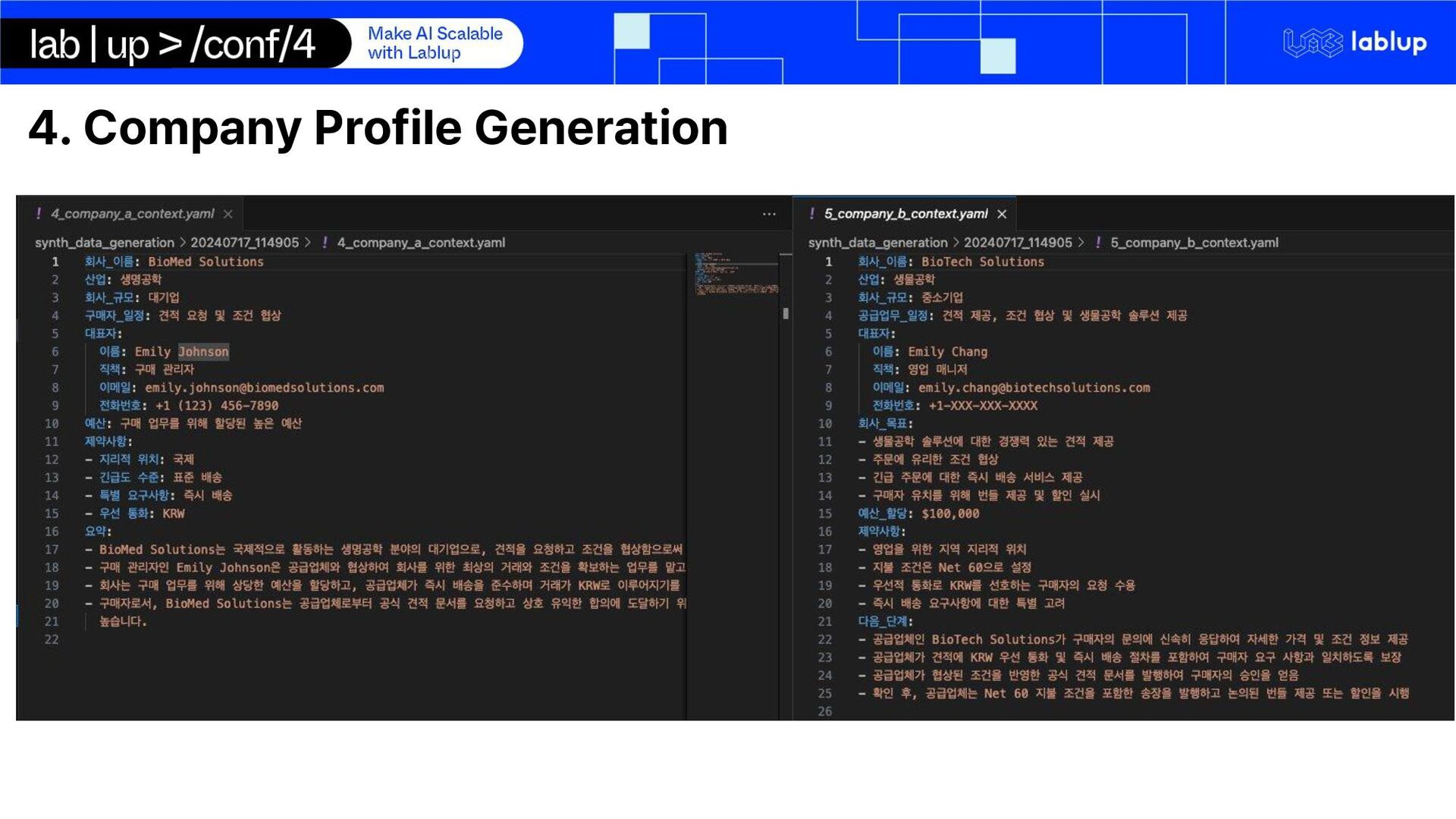
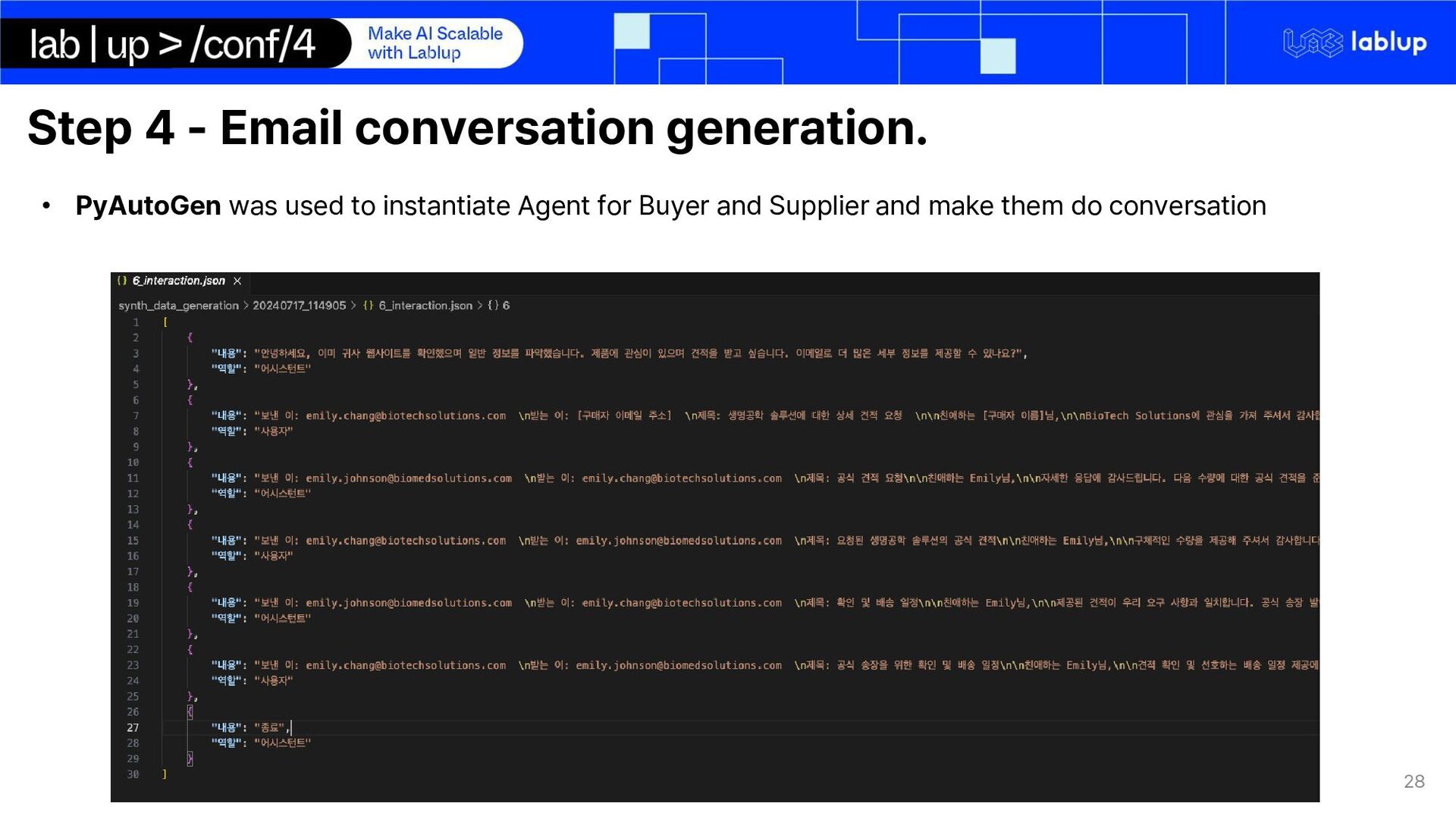
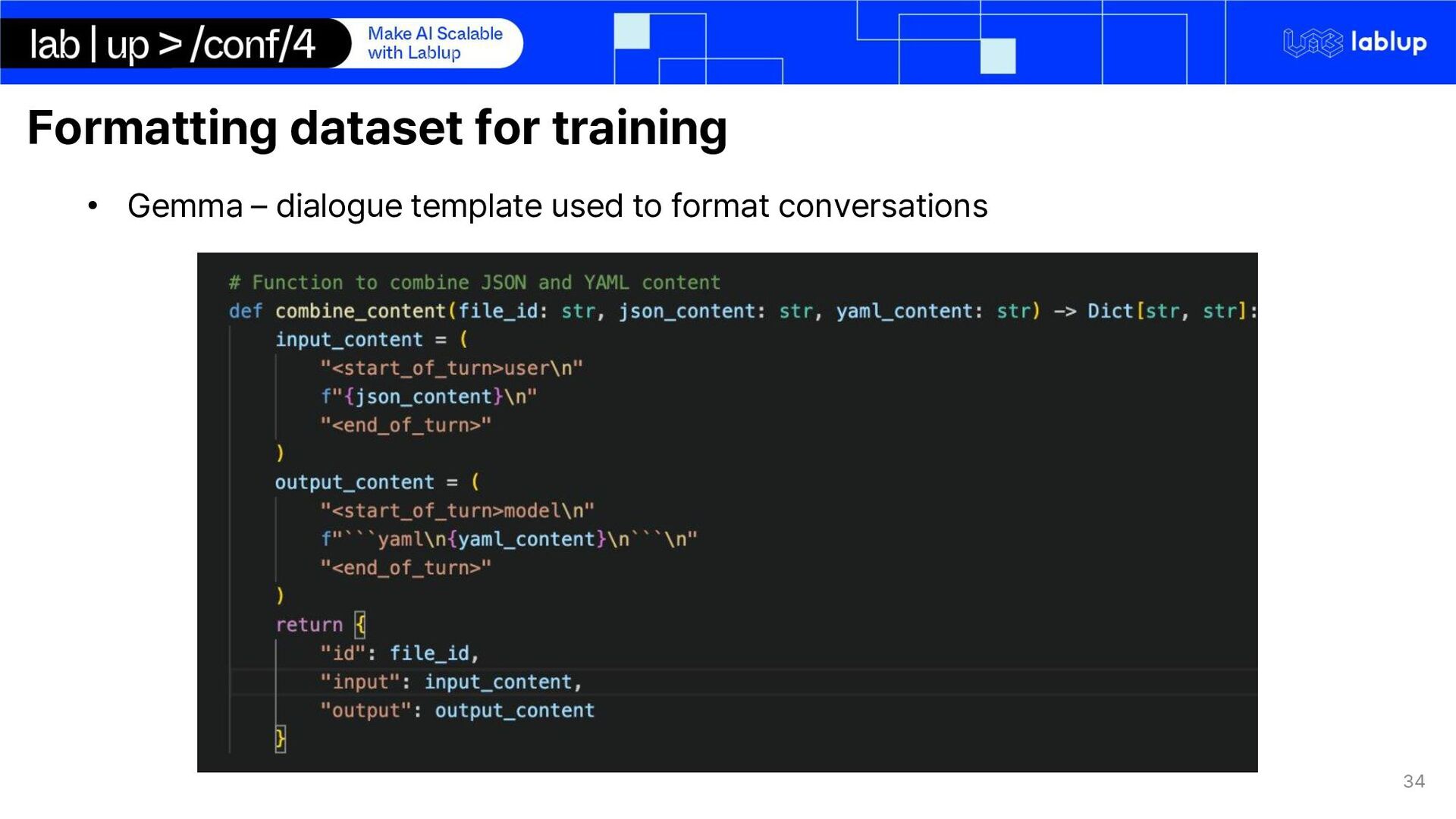
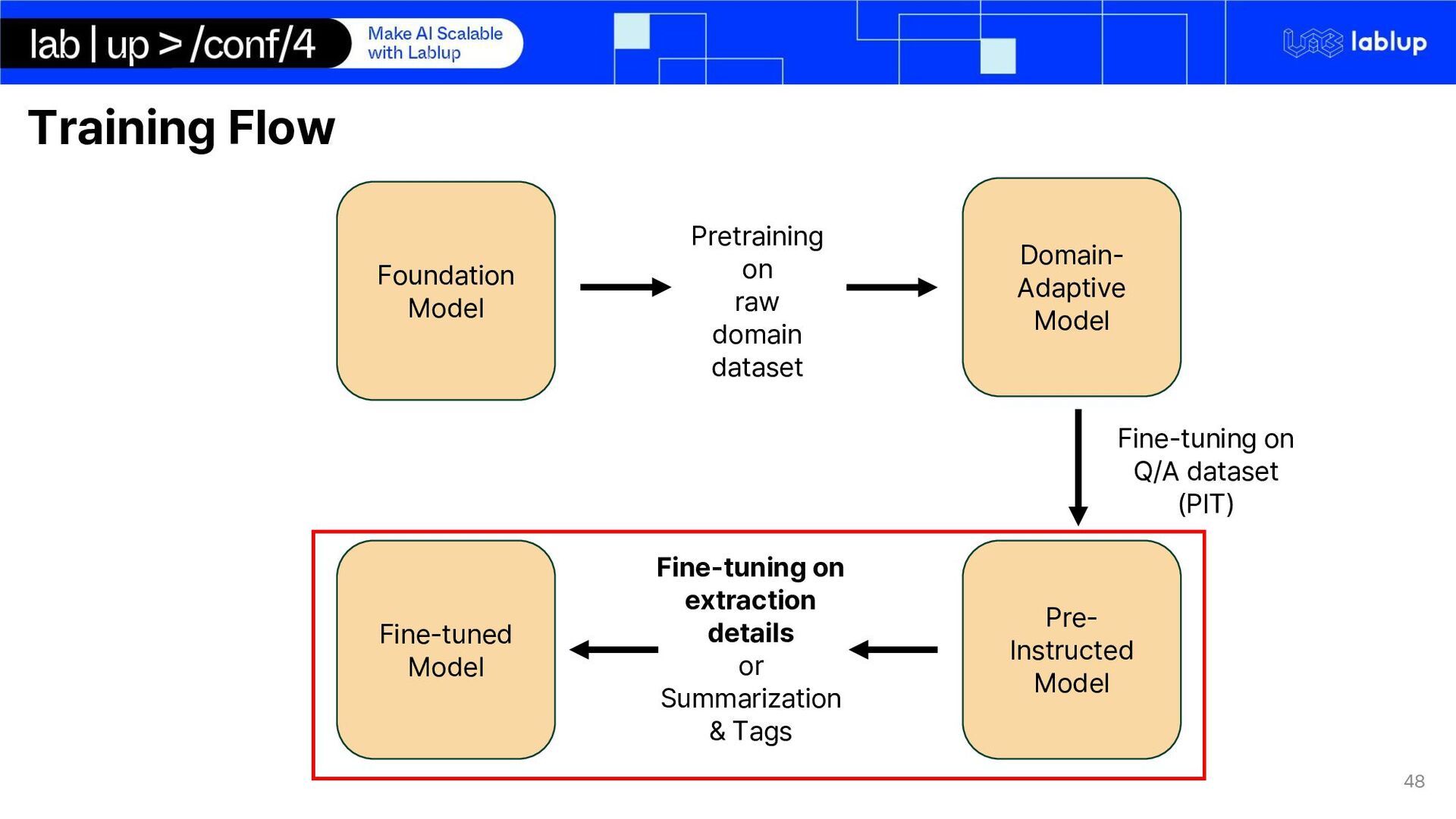
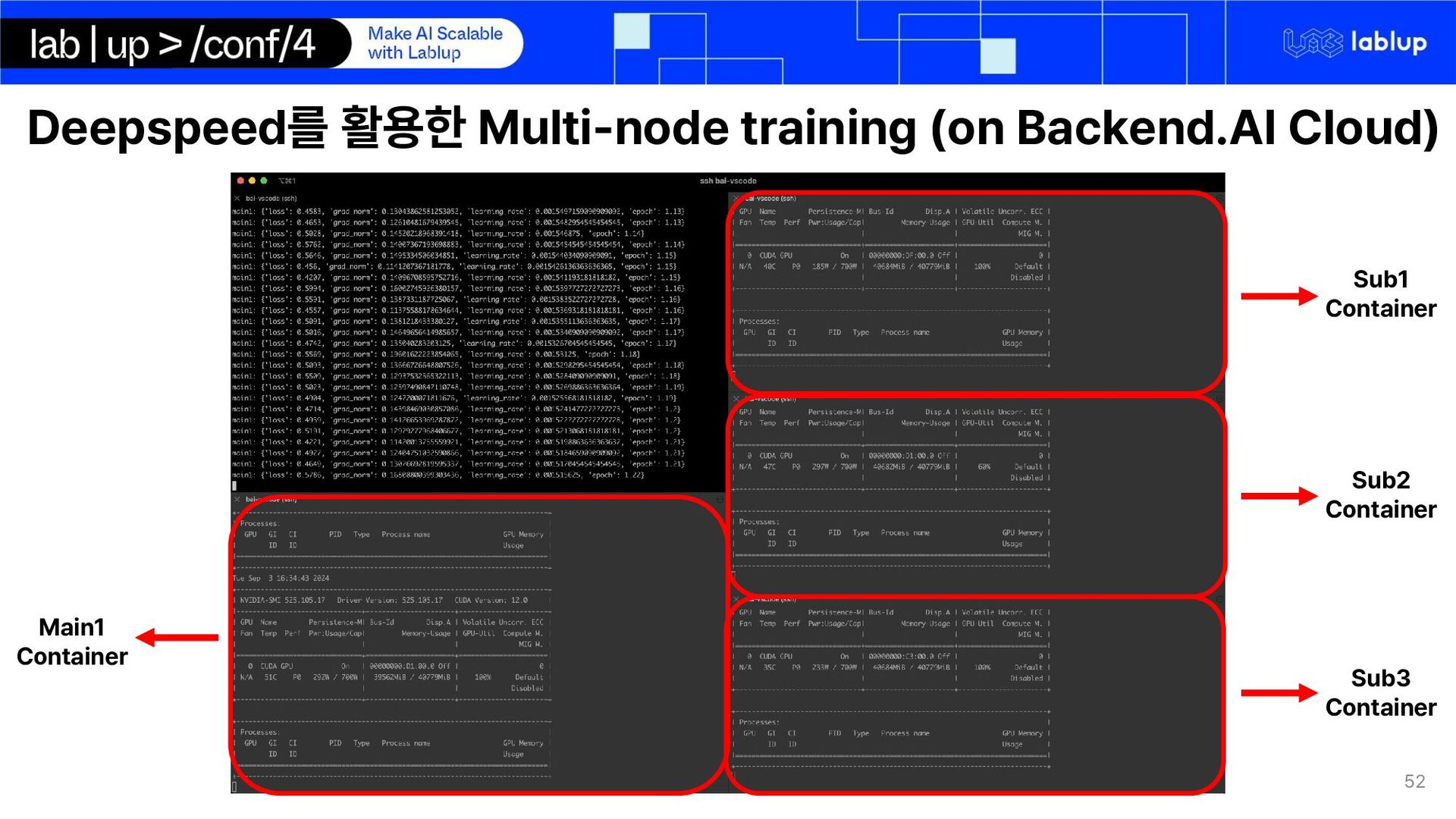
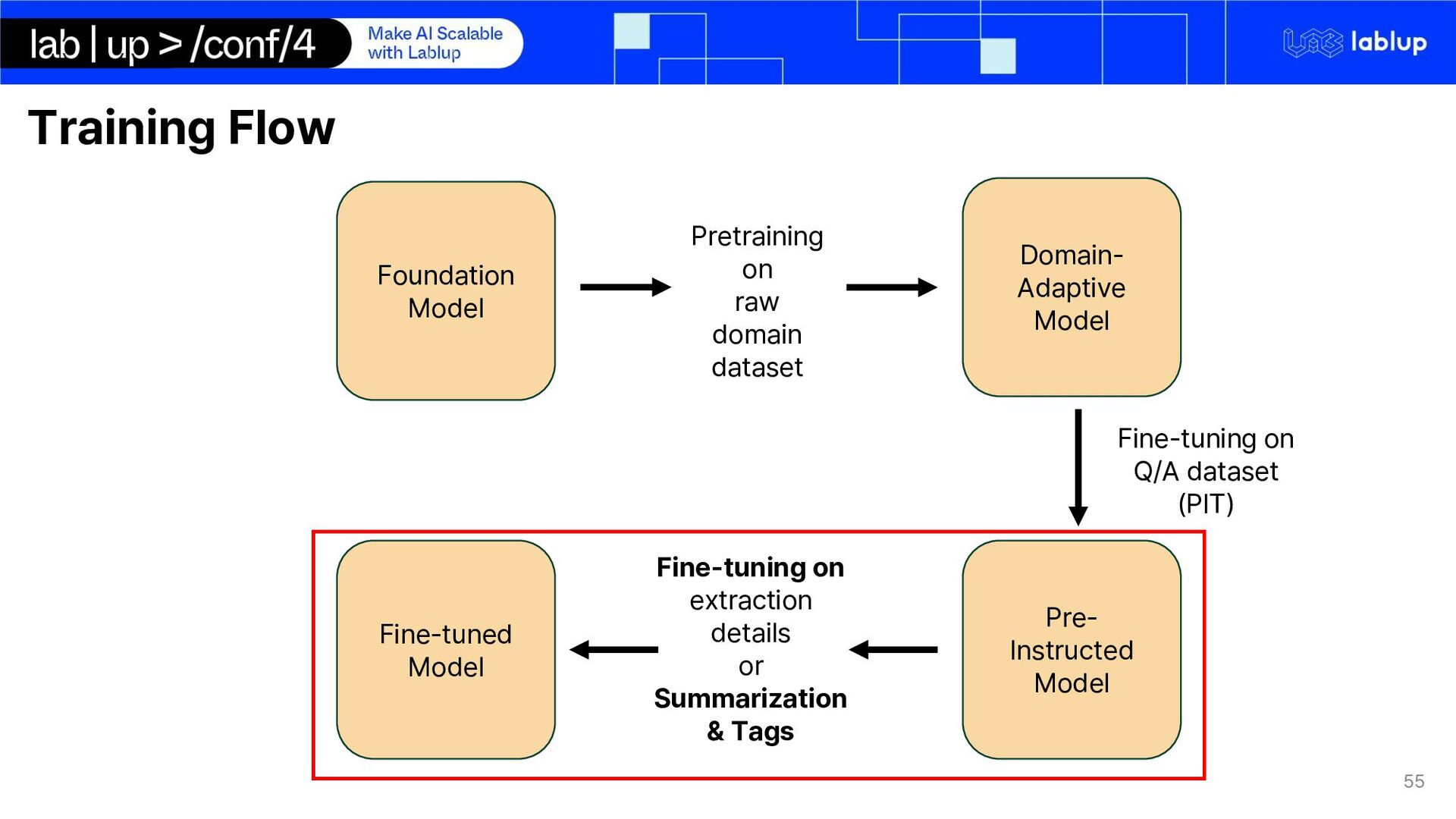
on domain adaptation of international trade domain Synthetic data generation for email conversation using LLM inference o Email conversations are private data and cannot be obtained LoRA Fine-tuning LLM on extraction key-facts Using LLM for quote generation using markdown syntax We use Gemma 2 – 2b Instruct o Multilingual o Small
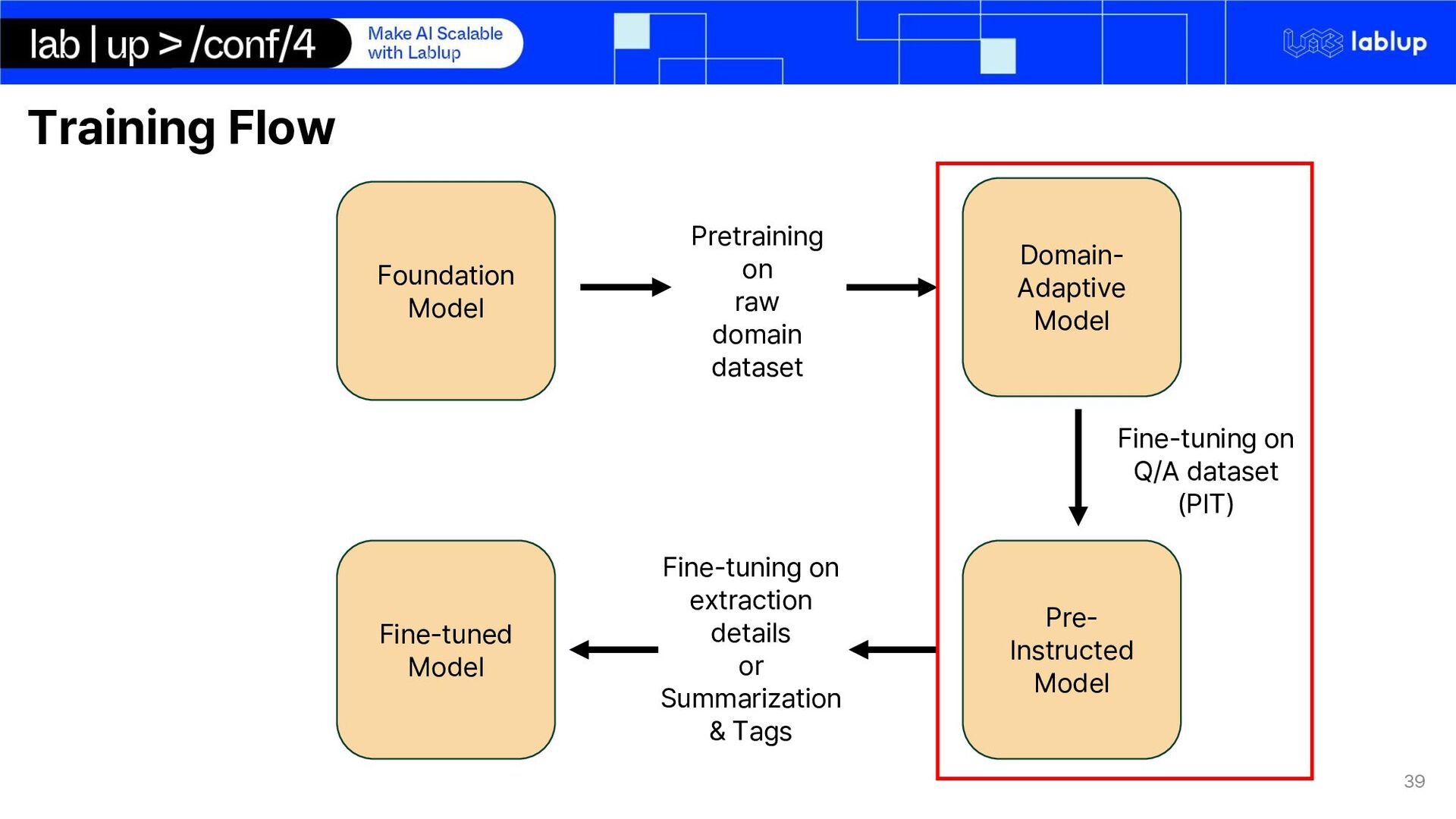
model, may not know some concepts and definition from International Trade LoRAcontinual pre-training Gemma 2 on vocabulary definition and domain can better help understand email conversation Lectures were pre-processed by turning them into detailed summaries Lecture transcript
Key-Facts Total synthetic conversations generated and used for finetuning: 1155 The conversations represented as a json format with 'role', 'content' keys.
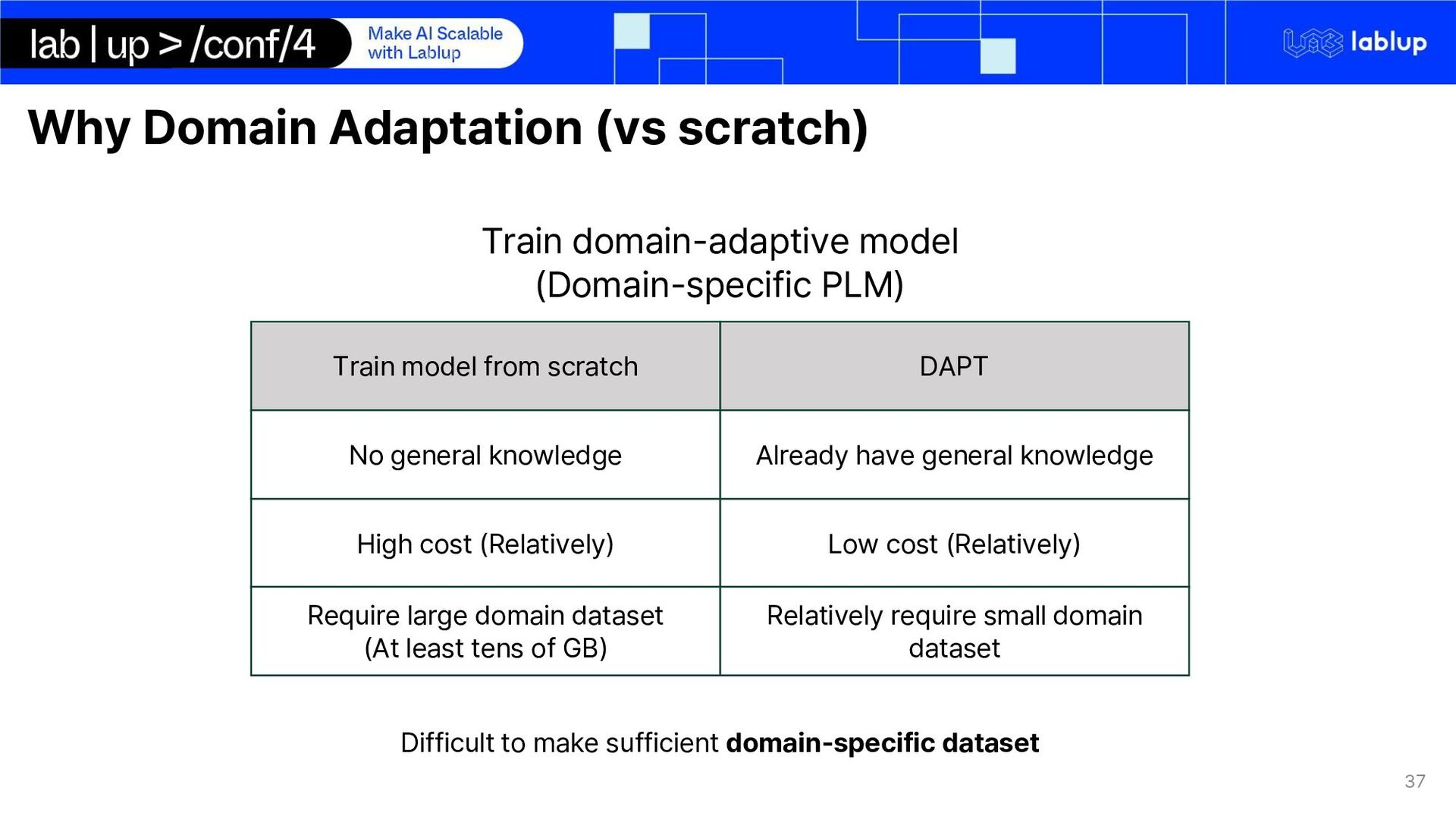
DAPT No general knowledge Already have general knowledge High cost (Relatively) Low cost (Relatively) Require large domain dataset (At least tens of GB) Relatively require small domain dataset Train domain-adaptive model (Domain-specific PLM) Difficult to make sufficient domain-specific dataset
0.77 1. SemScore • Target response와 Model response간의 의미적 유사도. 1.00 is the best Q: 송장과 포장 명세서의 차이점은 무엇인가요? • Target response: 송장은 수량, 단가, 총 금액을 포함하며, 포장 명세서는 순중량, 총중량, 포장단위, 포장수량을 포함합니다. 송장과 포장 명세서는 대부분 동일한 내용을 가지지만, 포장 명세서는 금액 정보가 없고 포장 관련 정보가 추가됩니다. • Model response: 송장과 포장 명세서는 내용이 유사하지만, 포장 명세서는 물픔의 포장 상태를 구체적으로 기재하여 실제 포장의 확인을 위한 기준으로 사용됩니다. Similarity: 0.723 => Trained model 이 Base model에 비해 의미적 유사도를 더 잘 반영하고 있음
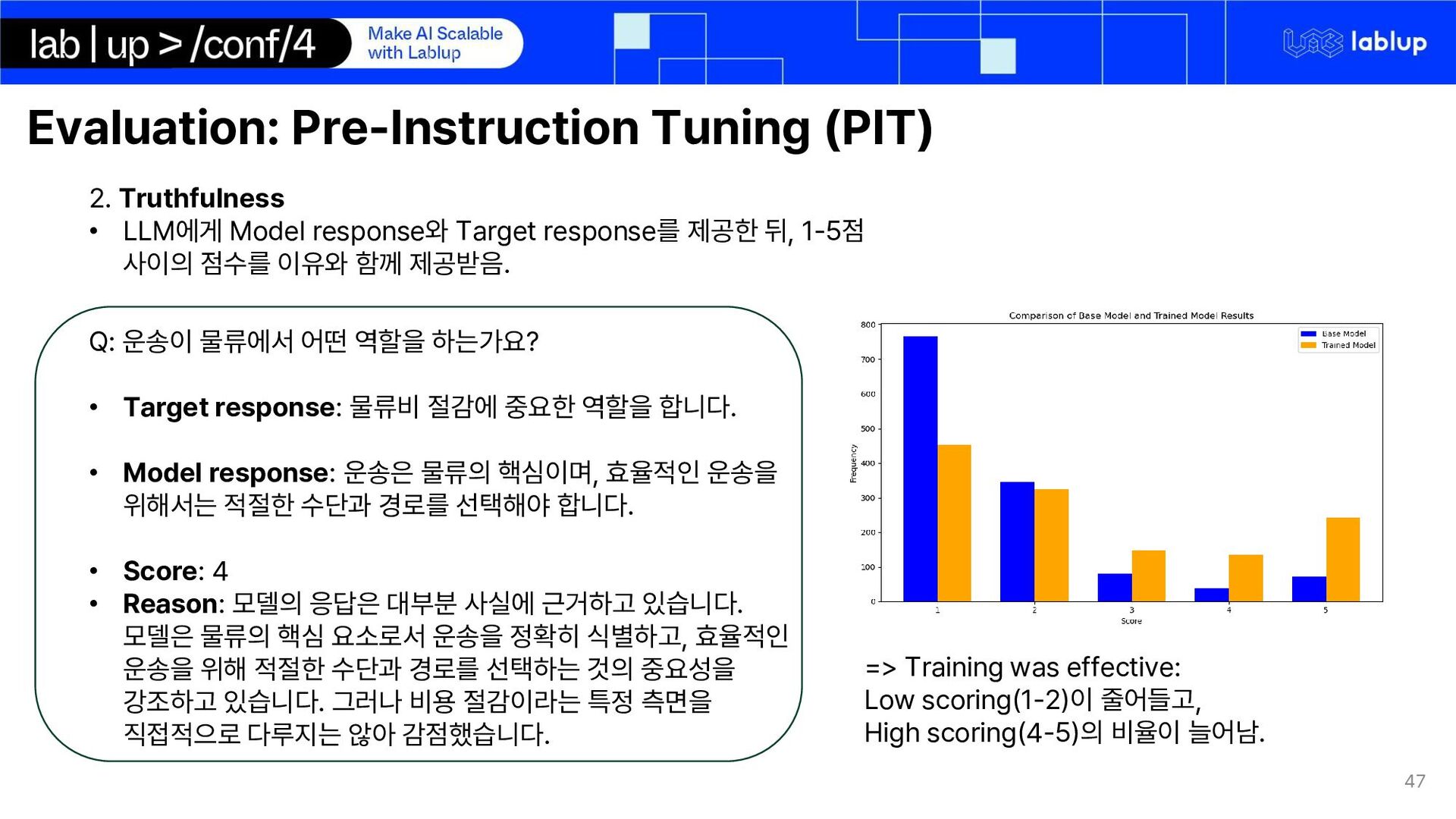
response와 Target response를 제공한 뒤, 1-5점 사이의 점수를 이유와 함께 제공받음. Q: 운송이 물류에서 어떤 역할을 하는가요? • Target response: 물류비 절감에 중요한 역할을 합니다. • Model response: 운송은 물류의 핵심이며, 효율적인 운송을 위해서는 적절한 수단과 경로를 선택해야 합니다. • Score: 4 • Reason: 모델의 응답은 대부분 사실에 근거하고 있습니다. 모델은 물류의 핵심 요소로서 운송을 정확히 식별하고, 효율적인 운송을 위해 적절한 수단과 경로를 선택하는 것의 중요성을 강조하고 있습니다. 그러나 비용 절감이라는 특정 측면을 직접적으로 다루지는 않아 감점했습니다. => Training was effective: Low scoring(1-2)이 줄어들고, High scoring(4-5)의 비율이 늘어남.
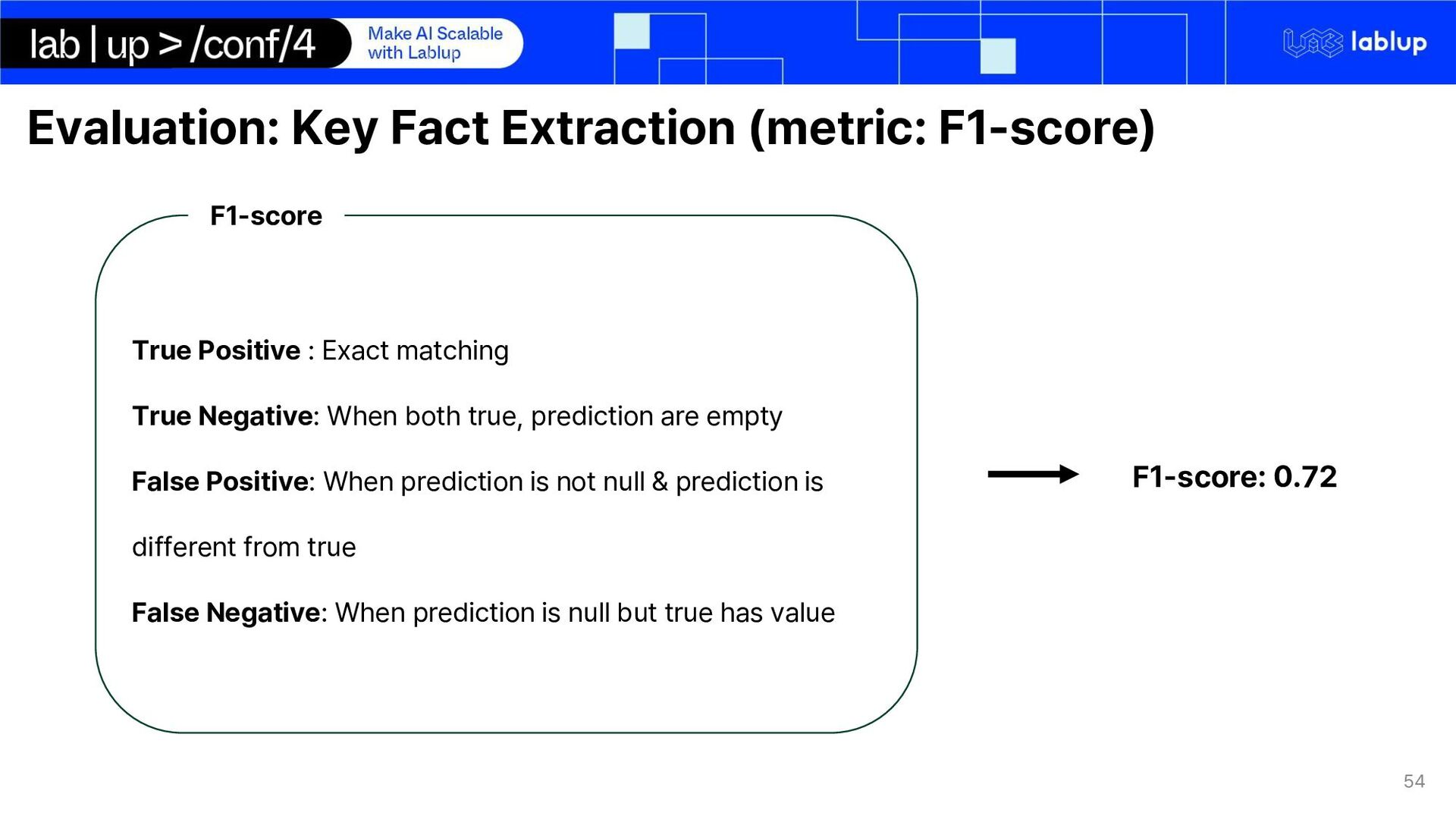
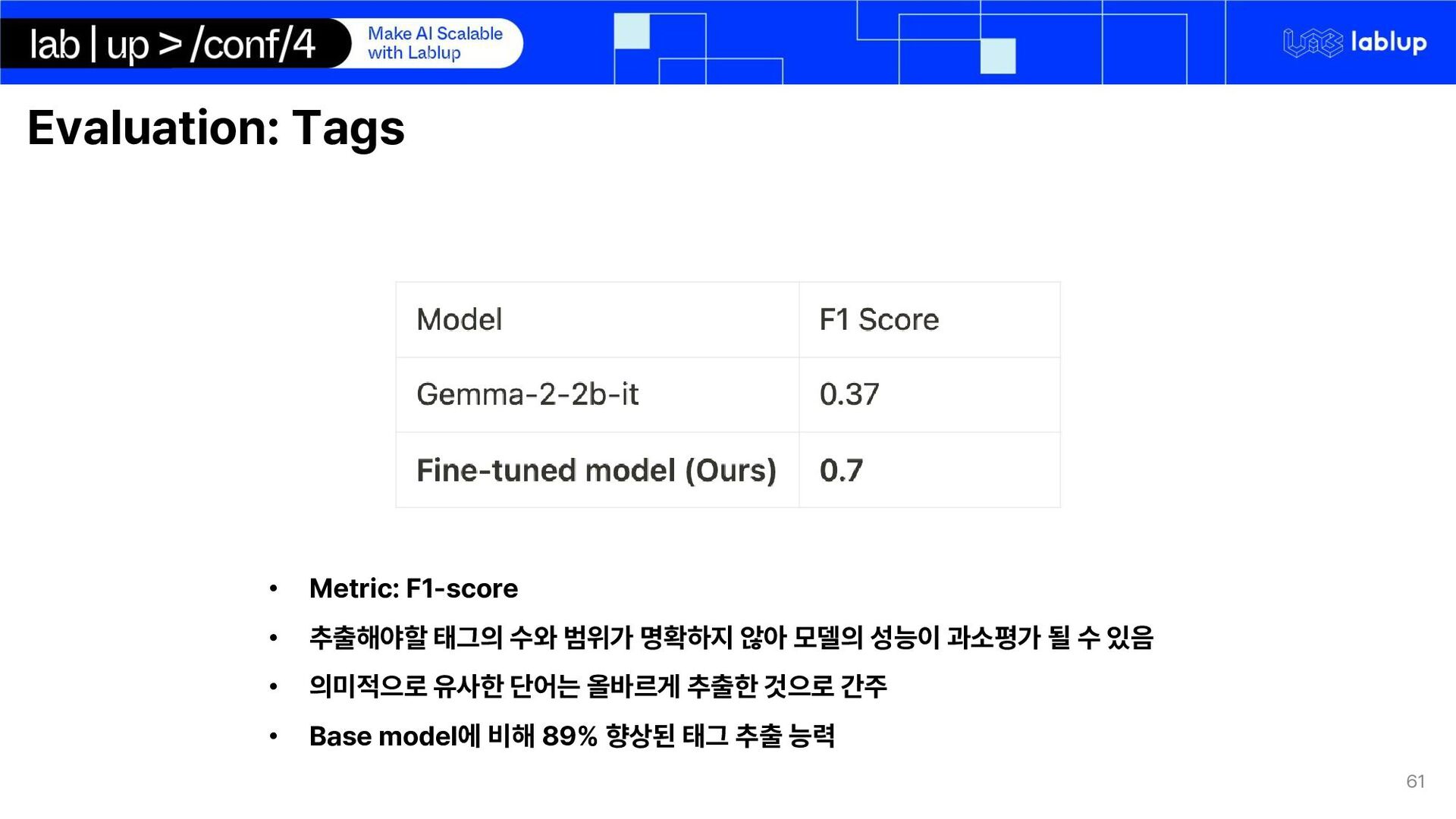
Exact matching True Negative: When both true, prediction are empty False Positive: When prediction is not null & prediction is different from true False Negative: When prediction is null but true has value F1-score F1-score: 0.72
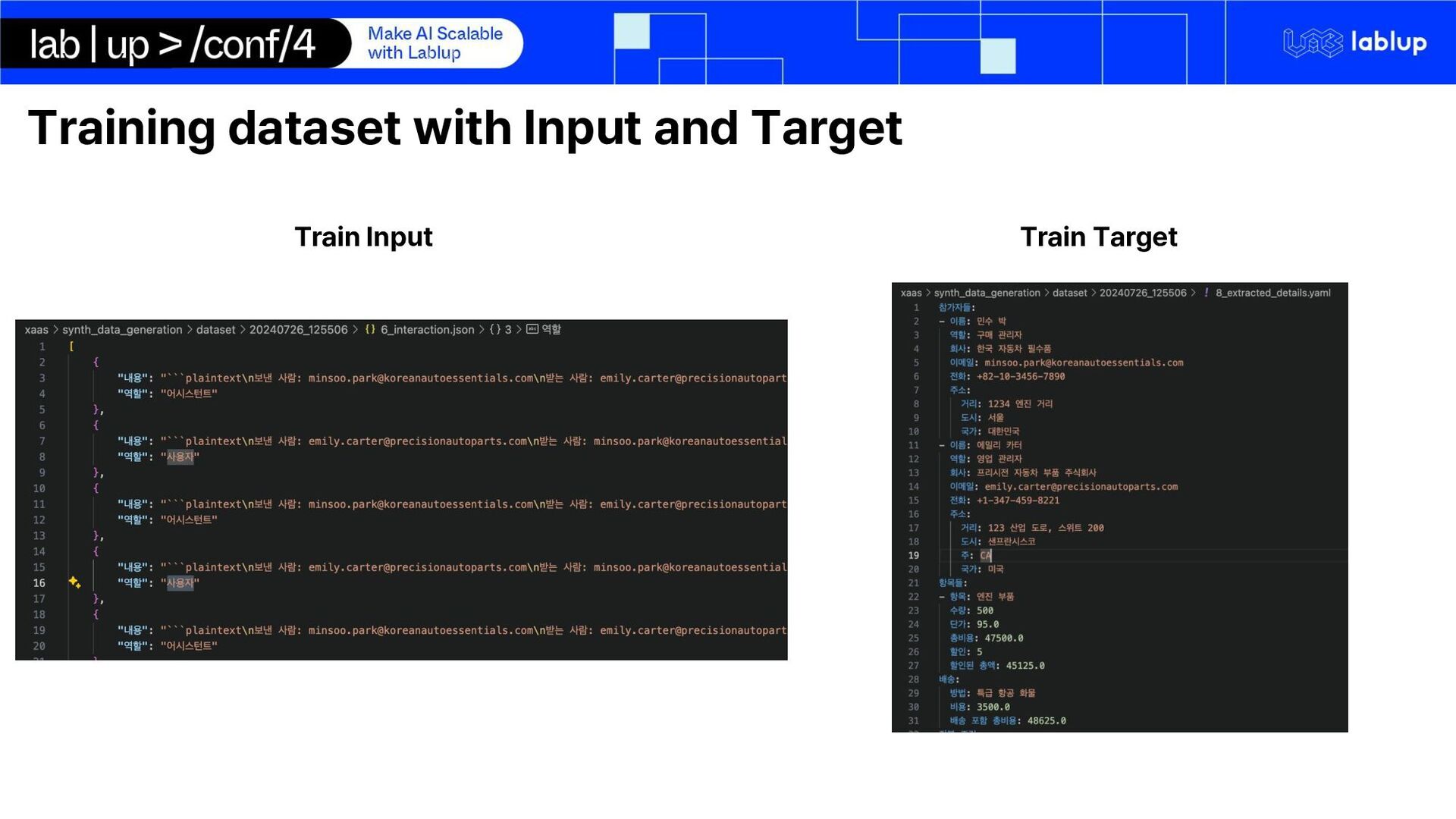
from email conversation 1. 초기 문의 및 견적 요청: • 발신자: 이민재 한국에너텍 구매담당 과장. • 긴급성과 규정 준수를 강조하면서 에너지 솔루션에 대한 자세한 견적 요청을 보냈습니다. 예산은 5억 원으로 명시됐습니다. 2. 답변: • 발신자: EnerTech Solutions 수석 영업 관리자 David Park. • 태양광 패널, 풍력 터빈, 에너지 저장 시스템, 설치/유지보수 서비스가 포함된 세부 견적을 제공하며 총 5억 원입니다. • 배송 시 결제, 표준 배송과 빠른 배송 옵션, 규정 준수, 5년 보증 등의 서비스 약관이 포함되어 있습니다. Summary ['거래', '협상', '공급망', '에너지', '기술', '계약', '한국'] Tags
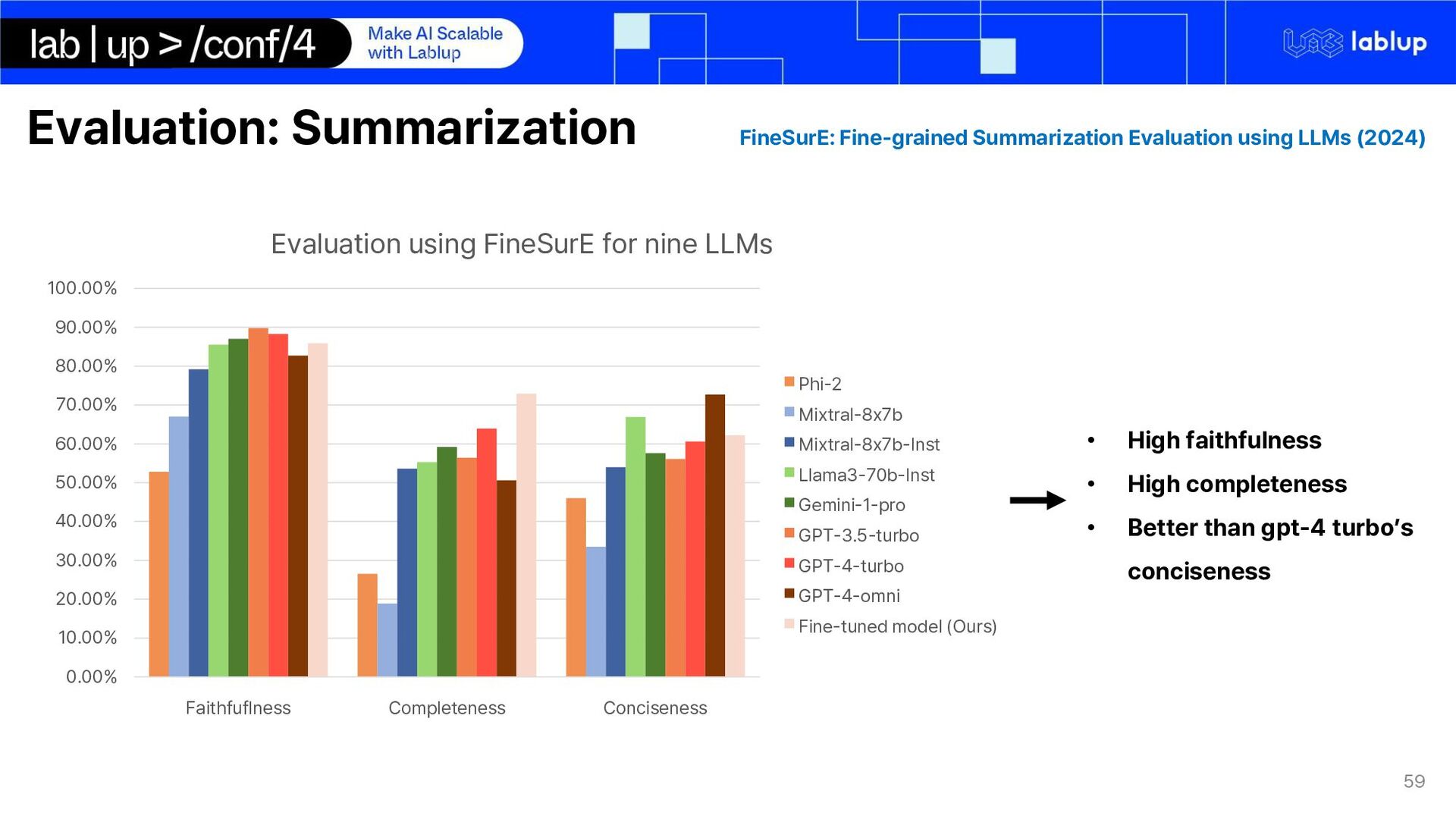
Faithfulness: 문서에 없는 정보를 포함하거나, 문서의 내용과 다른 잘못된 정보를 포함하고 있는가? (Hallucination) Completeness: 모든 핵심 사실을 포함하고 있는가? Conciseness: 모델의 요약에 불필요한 세부 정보가 포함되지 않았는가?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}