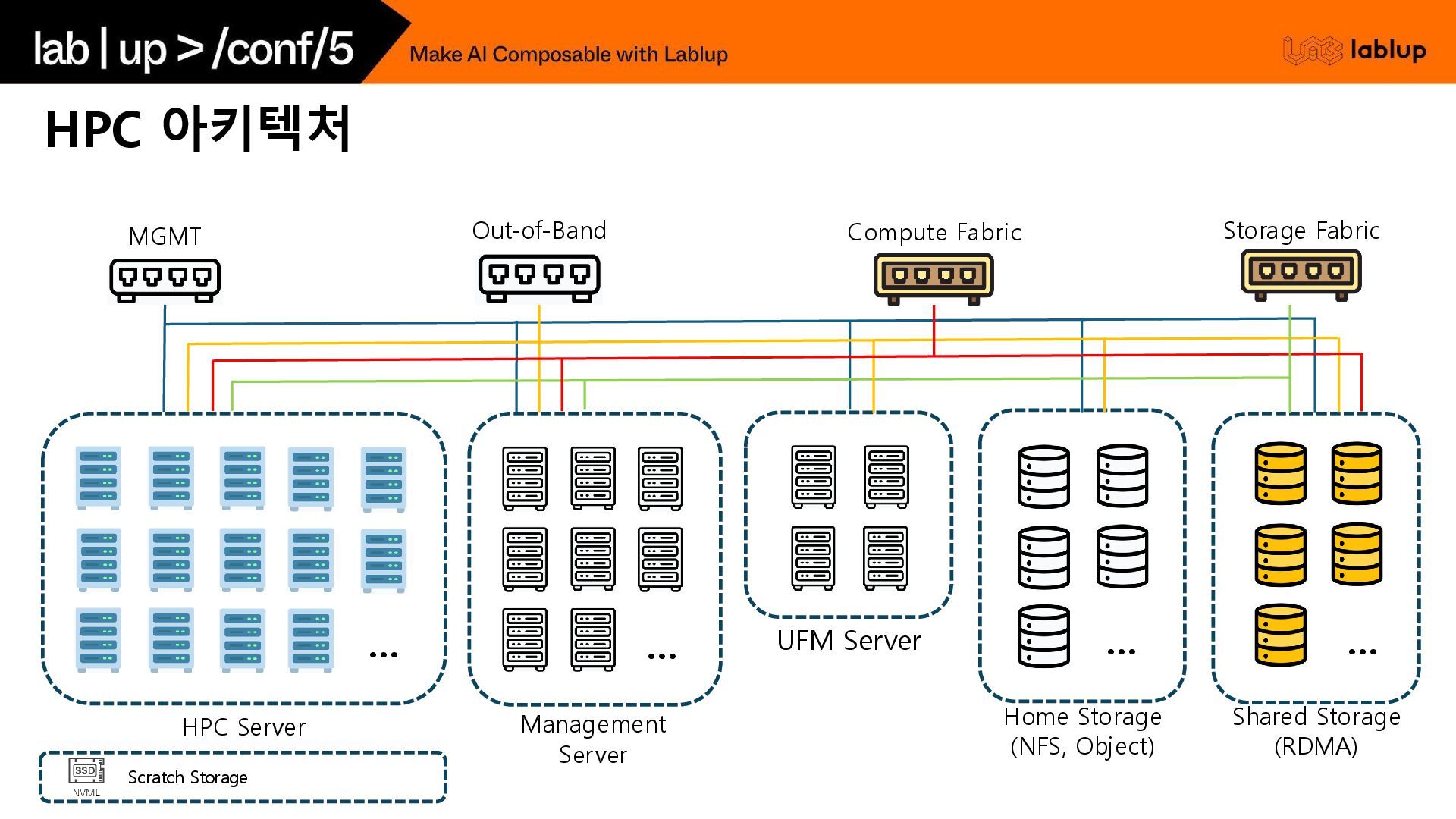
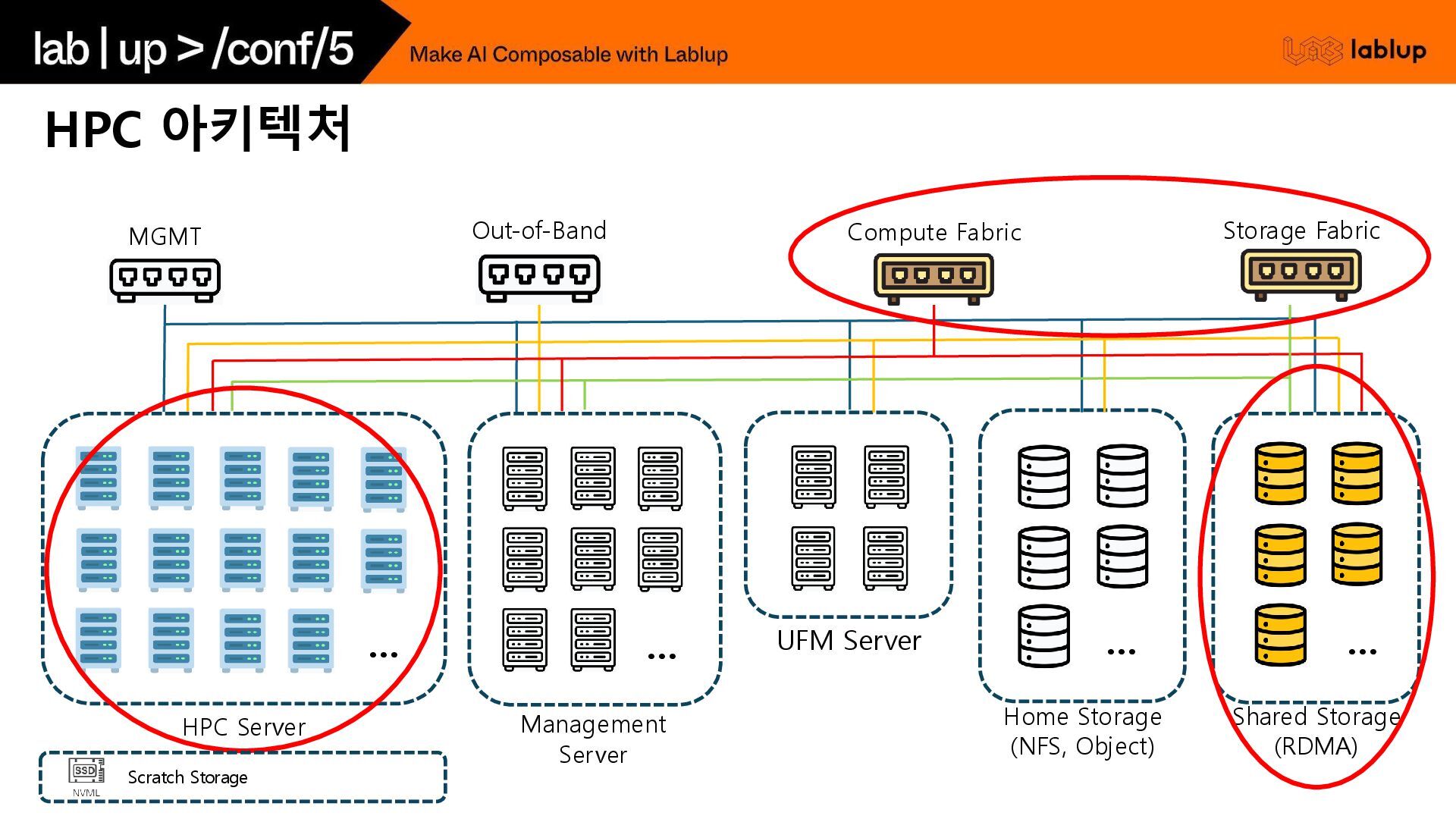
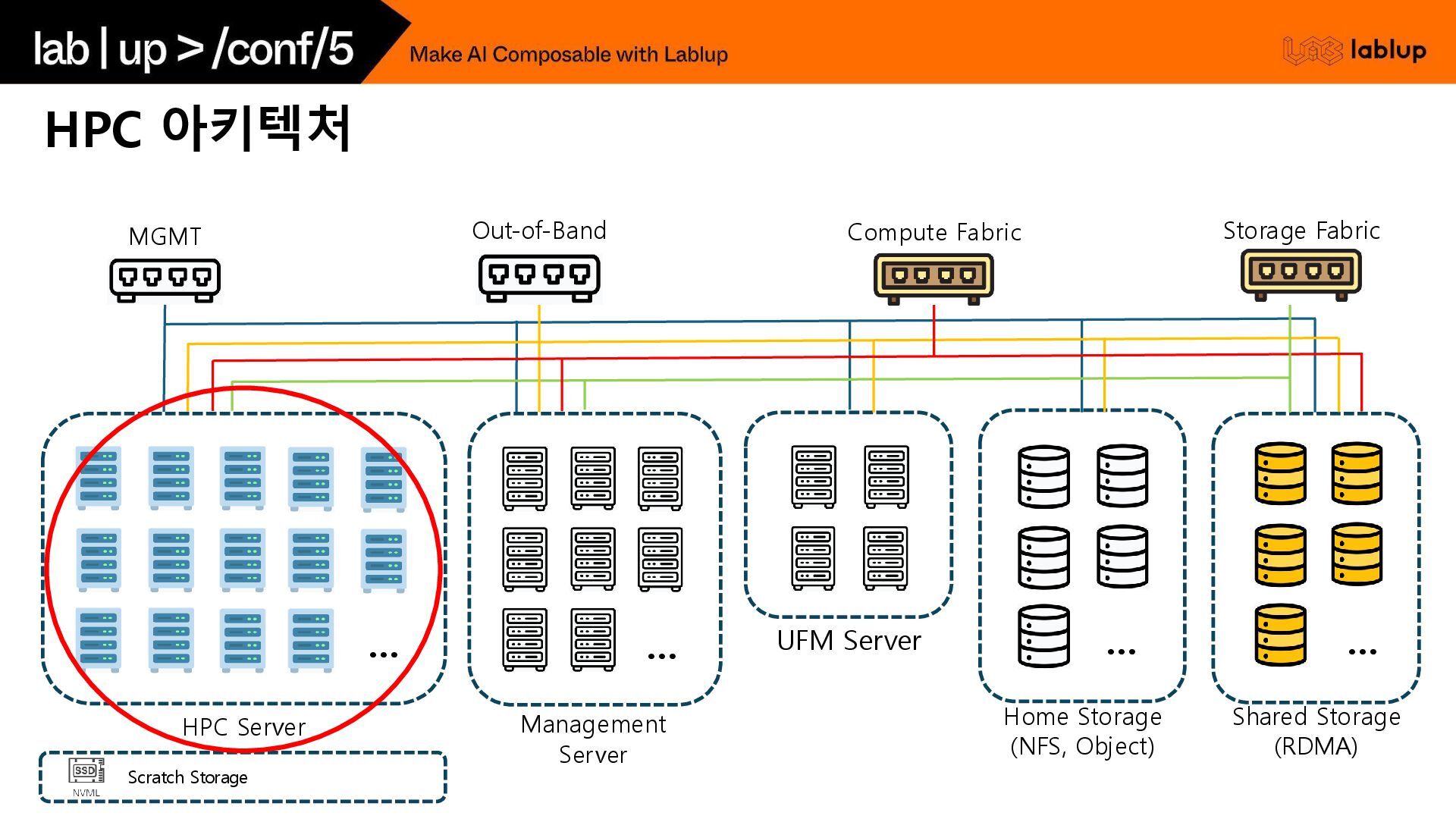
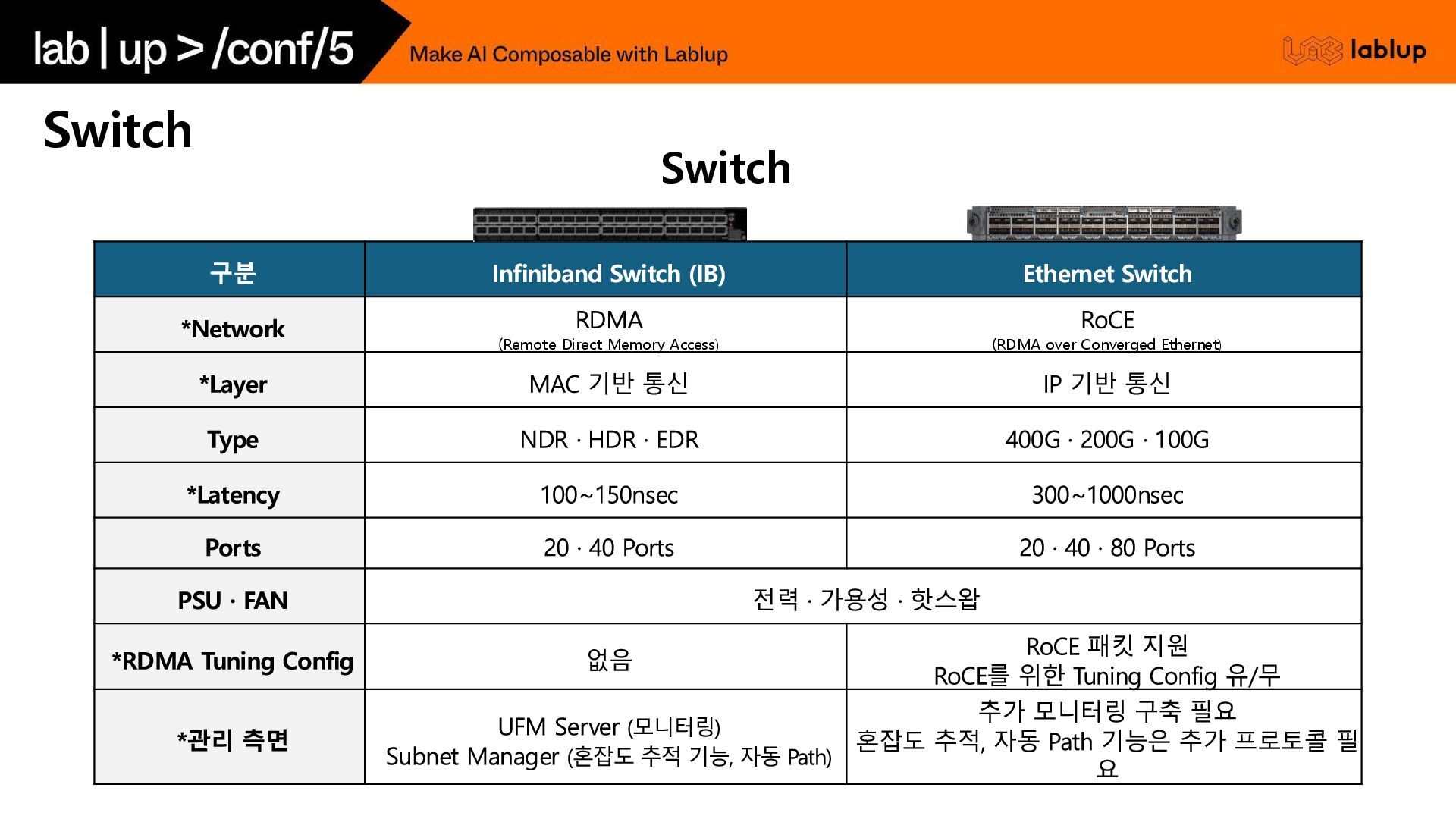
Direct Memory Access) RoCE (RDMA over Converged Ethernet) *Layer MAC 기반 통신 IP 기반 통신 Type NDR · HDR · EDR 400G · 200G · 100G *Latency 100~150nsec 300~1000nsec Ports 20 · 40 Ports 20 · 40 · 80 Ports PSU · FAN 전력 · 가용성 · 핫스왑 *RDMA Tuning Config 없음 RoCE 패킷 지원 RoCE를 위한 Tuning Config 유/무 *관리 측면 UFM Server (모니터링) Subnet Manager (혼잡도 추적 기능, 자동 Path) 추가 모니터링 구축 필요 혼잡도 추적, 자동 Path 기능은 추가 프로토콜 필 요 Switch
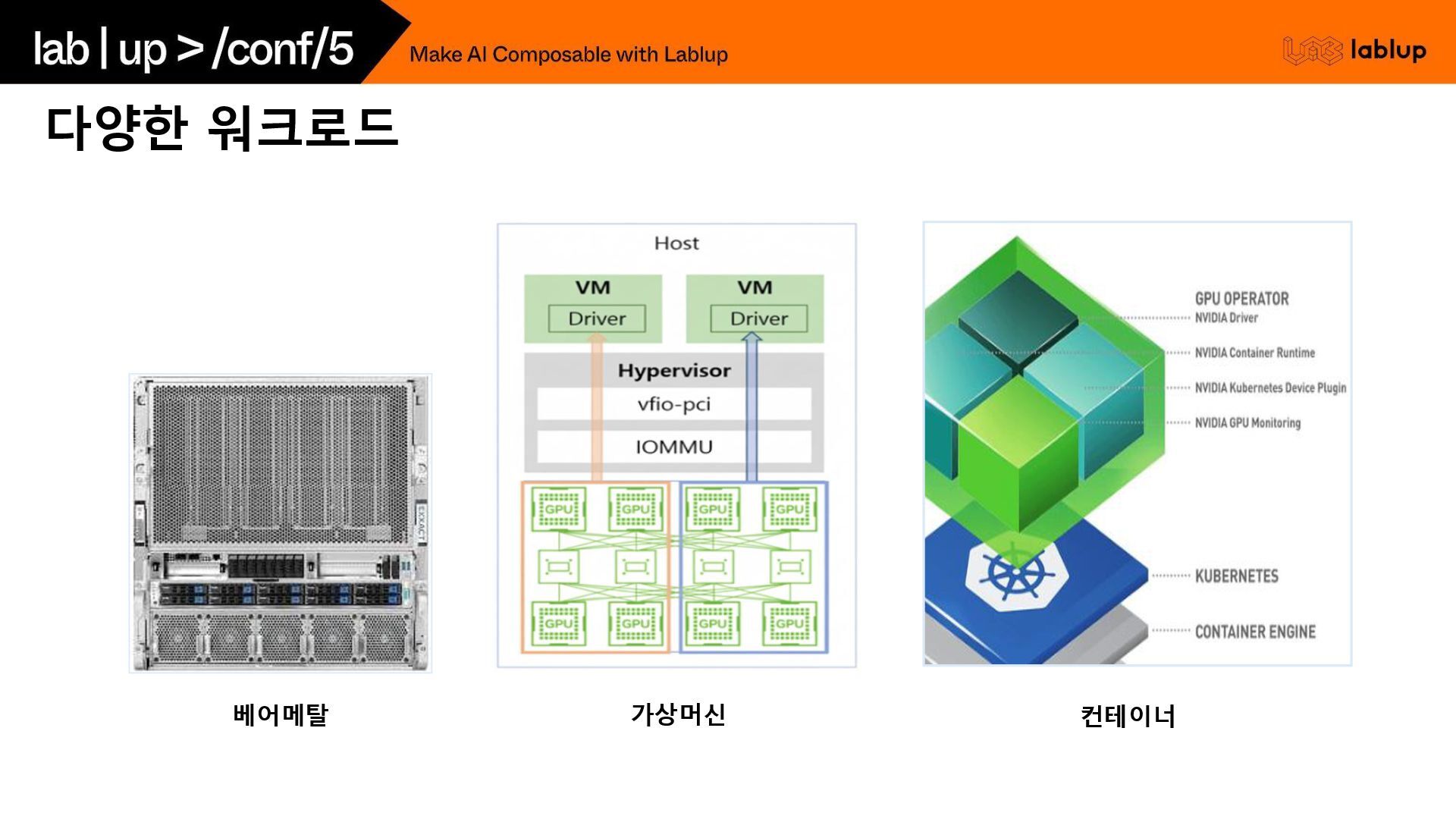
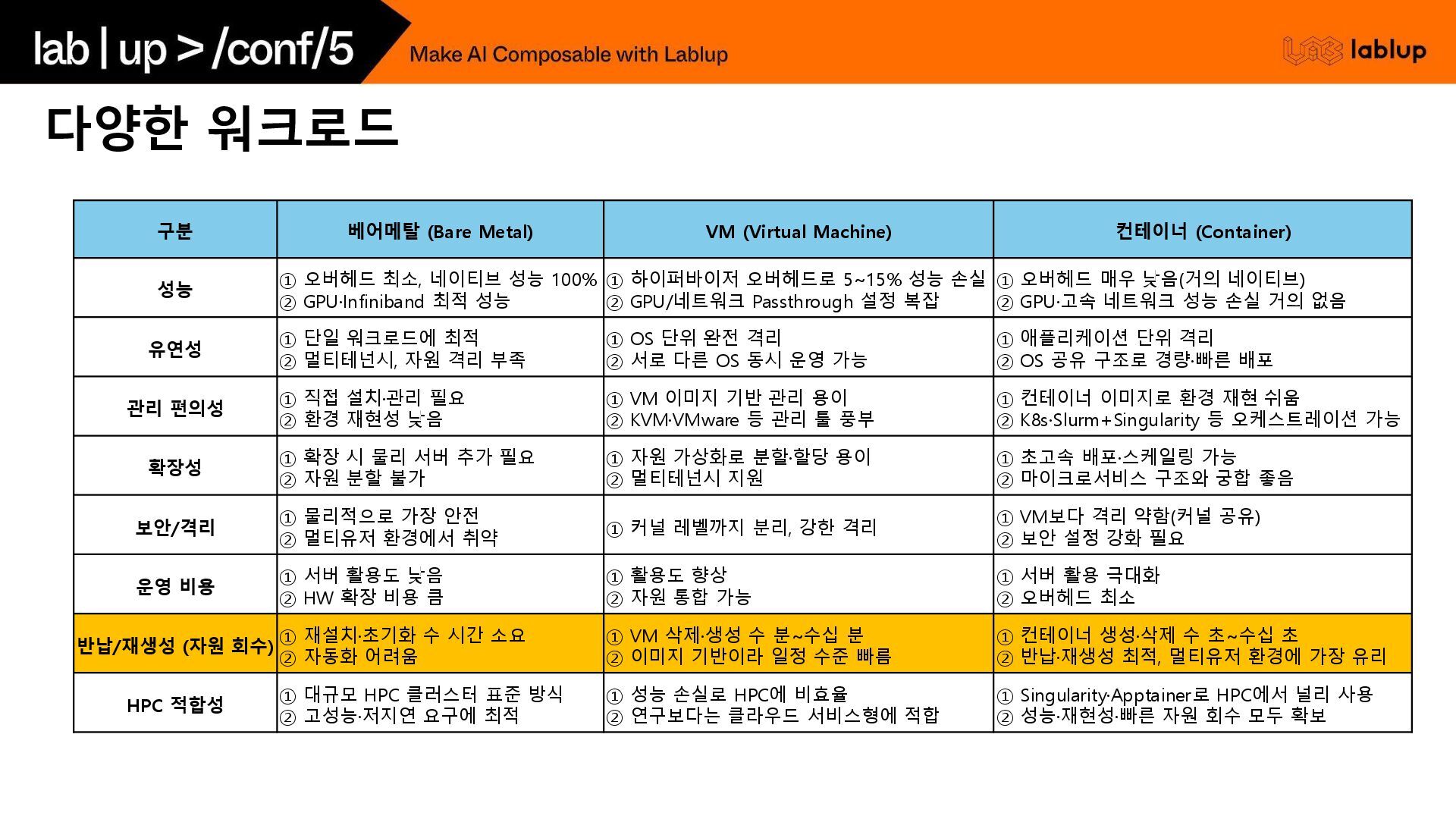
(Container) 성능 ① 오버헤드 최소, 네이티브 성능 100% ② GPU·Infiniband 최적 성능 ① 하이퍼바이저 오버헤드로 5~15% 성능 손실 ② GPU/네트워크 Passthrough 설정 복잡 ① 오버헤드 매우 낮음(거의 네이티브) ② GPU·고속 네트워크 성능 손실 거의 없음 유연성 ① 단일 워크로드에 최적 ② 멀티테넌시, 자원 격리 부족 ① OS 단위 완전 격리 ② 서로 다른 OS 동시 운영 가능 ① 애플리케이션 단위 격리 ② OS 공유 구조로 경량·빠른 배포 관리 편의성 ① 직접 설치·관리 필요 ② 환경 재현성 낮음 ① VM 이미지 기반 관리 용이 ② KVM·VMware 등 관리 툴 풍부 ① 컨테이너 이미지로 환경 재현 쉬움 ② K8s·Slurm+Singularity 등 오케스트레이션 가능 확장성 ① 확장 시 물리 서버 추가 필요 ② 자원 분할 불가 ① 자원 가상화로 분할·할당 용이 ② 멀티테넌시 지원 ① 초고속 배포·스케일링 가능 ② 마이크로서비스 구조와 궁합 좋음 보안/격리 ① 물리적으로 가장 안전 ② 멀티유저 환경에서 취약 ① 커널 레벨까지 분리, 강한 격리 ① VM보다 격리 약함(커널 공유) ② 보안 설정 강화 필요 운영 비용 ① 서버 활용도 낮음 ② HW 확장 비용 큼 ① 활용도 향상 ② 자원 통합 가능 ① 서버 활용 극대화 ② 오버헤드 최소 반납/재생성 (자원 회수) ① 재설치·초기화 수 시간 소요 ② 자동화 어려움 ① VM 삭제·생성 수 분~수십 분 ② 이미지 기반이라 일정 수준 빠름 ① 컨테이너 생성·삭제 수 초~수십 초 ② 반납·재생성 최적, 멀티유저 환경에 가장 유리 HPC 적합성 ① 대규모 HPC 클러스터 표준 방식 ② 고성능·저지연 요구에 최적 ① 성능 손실로 HPC에 비효율 ② 연구보다는 클라우드 서비스형에 적합 ① Singularity·Apptainer로 HPC에서 널리 사용 ② 성능·재현성·빠른 자원 회수 모두 확보
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
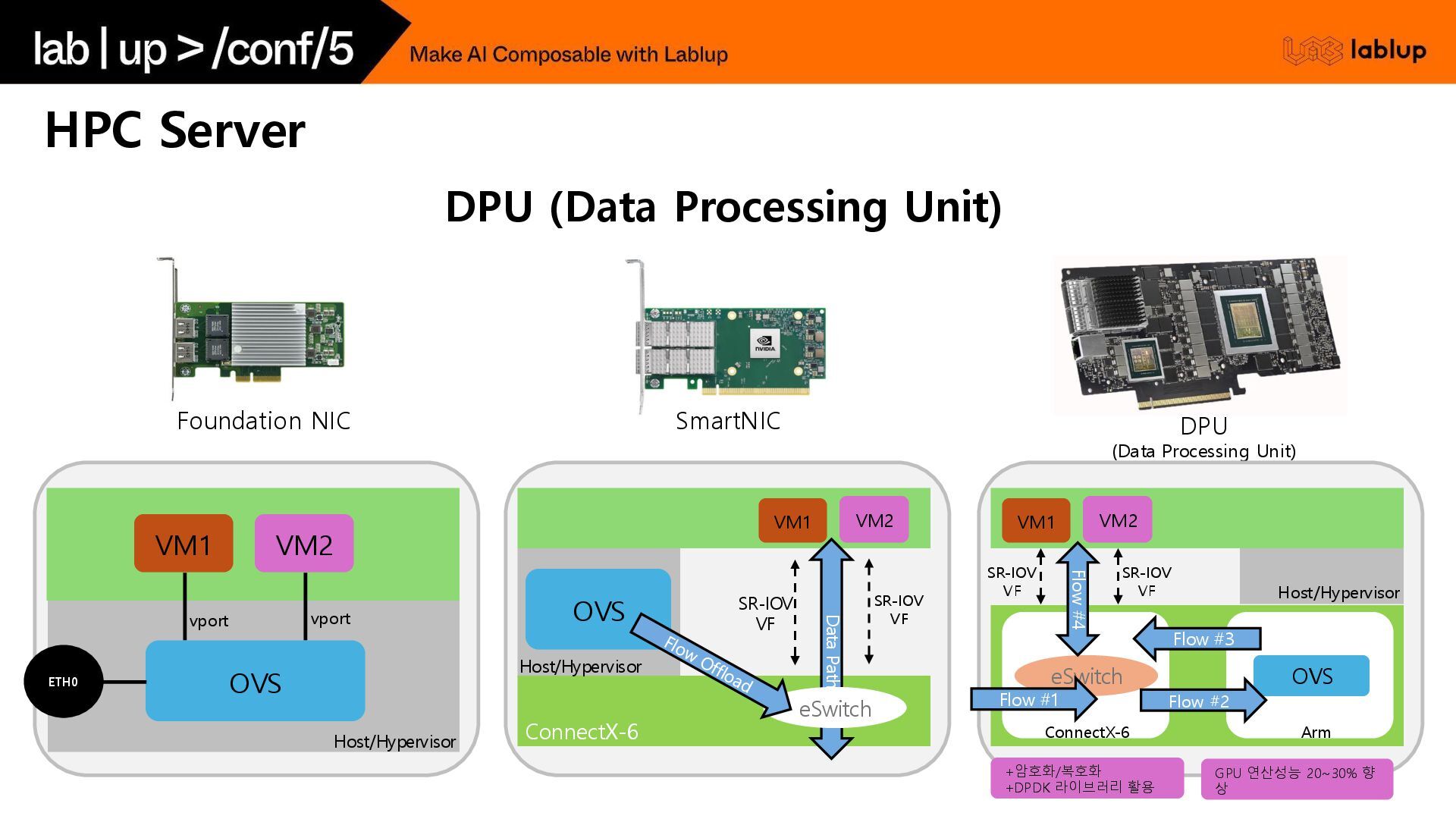{kind=link}
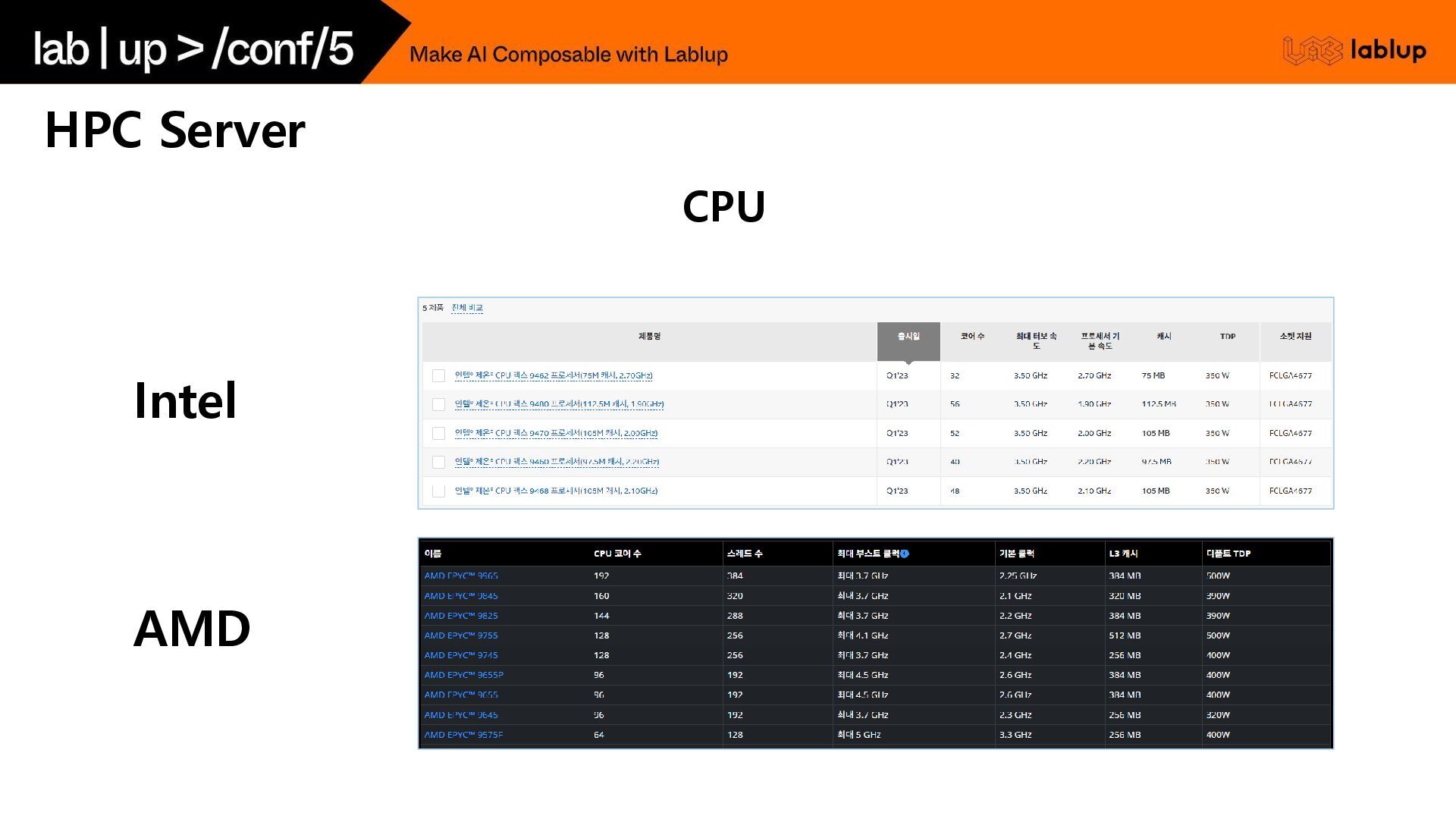{kind=link}
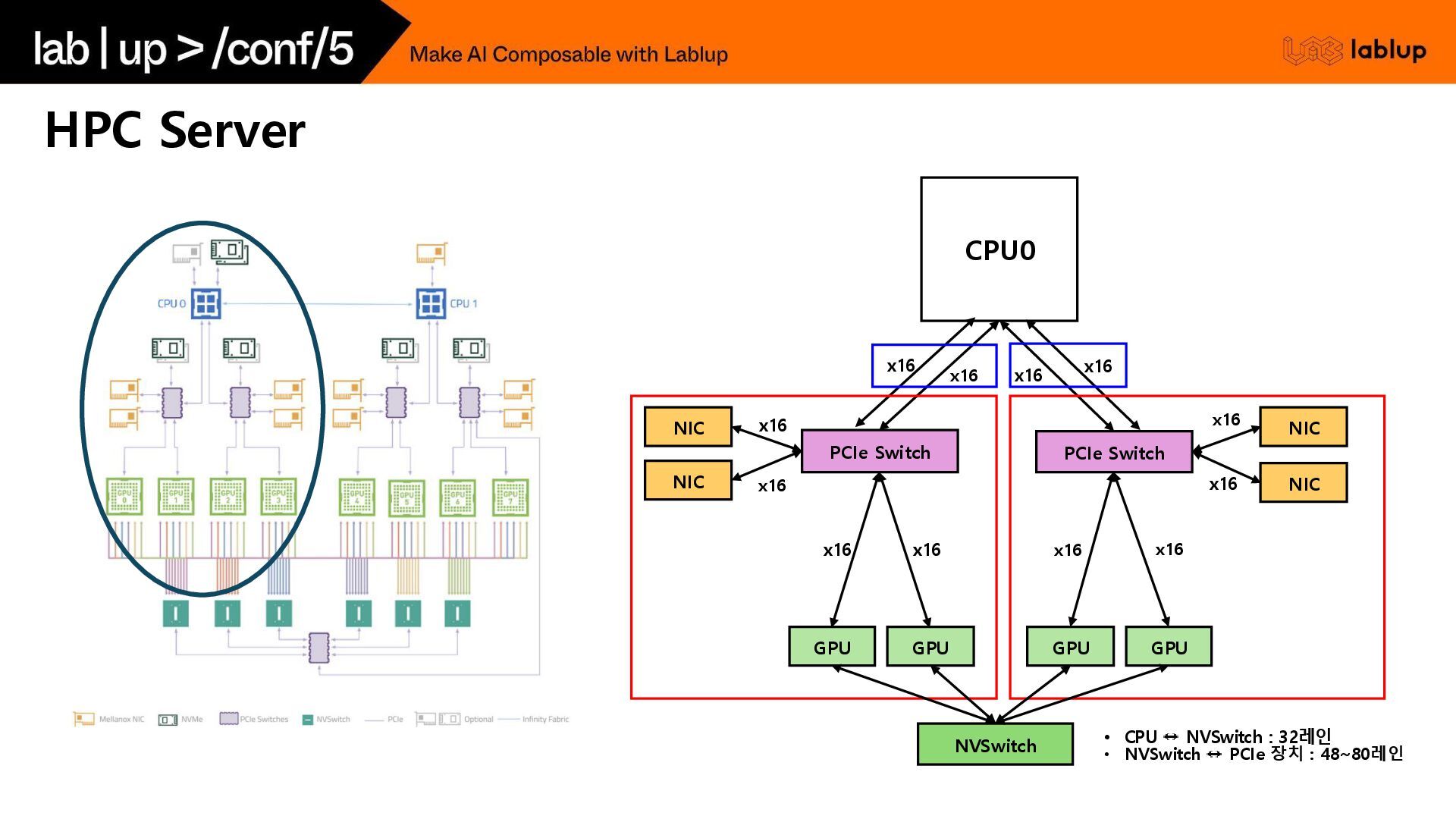{kind=link}
{kind=link}
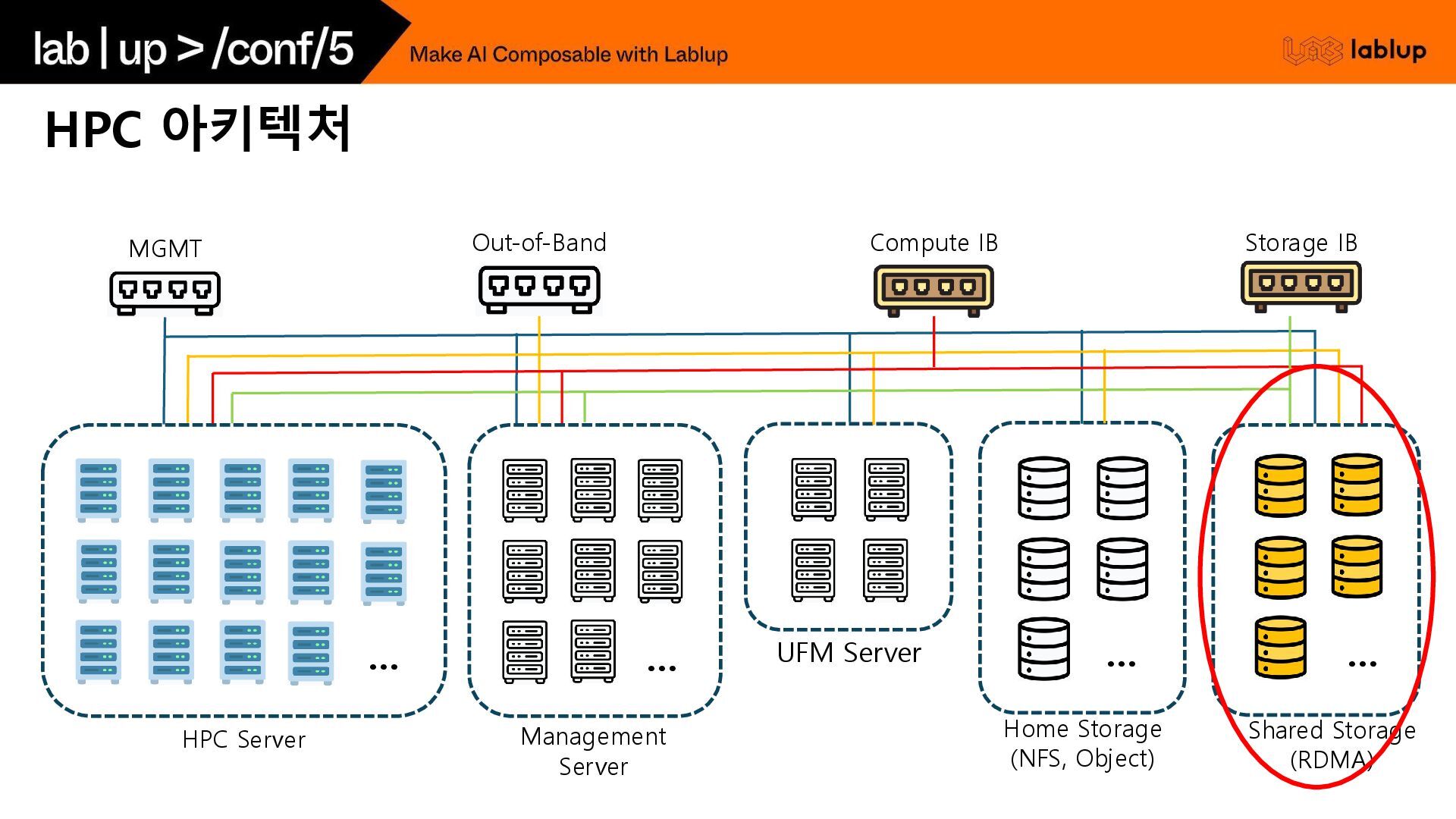{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}