Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「強化学習」輪読会#04資料_Chapter4前半
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
lazurite
December 17, 2019
Technology
0
630
「強化学習」輪読会#04資料_Chapter4前半
2019/12/17 MLPシリーズ「強化学習」輪読会 #04にて使用した資料です。
lazurite
December 17, 2019
Tweet
Share
Other Decks in Technology
See All in Technology
We Built for Predictability; The Workloads Didn’t Care
stahnma
0
150
SRE Enabling戦記 - 急成長する組織にSREを浸透させる戦いの歴史
markie1009
0
170
顧客との商談議事録をみんなで読んで顧客解像度を上げよう
shibayu36
0
340
10Xにおける品質保証活動の全体像と改善 #no_more_wait_for_test
nihonbuson
PRO
2
340
茨城の思い出を振り返る ~CDKのセキュリティを添えて~ / 20260201 Mitsutoshi Matsuo
shift_evolve
PRO
1
430
SREチームをどう作り、どう育てるか ― Findy横断SREのマネジメント
rvirus0817
0
360
AzureでのIaC - Bicep? Terraform? それ早く言ってよ会議
torumakabe
1
620
ECS障害を例に学ぶ、インシデント対応に備えた AIエージェントの育て方 / How to develop AI agents for incident response with ECS outage
iselegant
4
450
22nd ACRi Webinar - NTT Kawahara-san's slide
nao_sumikawa
0
120
顧客の言葉を、そのまま信じない勇気
yamatai1212
1
370
Claude_CodeでSEOを最適化する_AI_Ops_Community_Vol.2__マーケティングx_AIはここまで進化した.pdf
riku_423
2
610
猫でもわかるKiro CLI(セキュリティ編)
kentapapa
0
120
Featured
See All Featured
Navigating Team Friction
lara
192
16k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
1.9k
How to build a perfect <img>
jonoalderson
1
4.9k
Producing Creativity
orderedlist
PRO
348
40k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
310
Building Applications with DynamoDB
mza
96
6.9k
Balancing Empowerment & Direction
lara
5
900
A designer walks into a library…
pauljervisheath
210
24k
エンジニアに許された特別な時間の終わり
watany
106
230k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
180
30 Presentation Tips
portentint
PRO
1
230
Transcript
強化学習 輪読会 #04 Chapter 4 モデルフリー型の強化学習 (前半) @lazurite_ml
自己紹介 @lazurite_ml • JTC勤務 • 興味:データ分析、機械学習、Python • 強化学習初心者
Chapter 4 モデルフリー型の強化学習 4.1 データにもとづく意思決定 4.2 価値関数の推定
4.3 方策と行動価値関数の学習 4.4*収束性 4.5 アクター・クリティック法
Chapter 4 モデルフリー型の強化学習 4.1 データにもとづく意思決定 4.2 価値関数の推定
4.3 方策と行動価値関数の学習 4.4*収束性 4.5 アクター・クリティック法
4.1 データにもとづく意思決定 #1 • 意思決定の問題設定 • バッチ学習 : すべてのデータから方策を学習 •
オンライン学習 : データを収集しながら逐次的に学習 • データとは、 エージェントと環境が相互作用した履歴を記録したもの 単一の意思決定系列(4.1式)の場合と、複数系列の場合 ℎ ≜ 0 , 0 , 0 , . . . , −1 , −1 , −1 , (4.1)
4.1 データにもとづく意思決定 #2 状態 で行動 を実行 →報酬 と次状態 ′
の組 , , , ′ が系列の最小構成 (=標本, 経験データ, 経験とも) 最小構成の系列が N 個ある場合は、 ℎ 1 (1), … , ℎ 1 () = 0 (1), 0 (1), 0 (1), 1 (1) , … , 0 (), 0 (), 0 (), 1 () となり、このような経験データの集合を履歴データと呼ぶ (再掲) ℎ ≜ 0 , 0 , 0 , . . . , −1 , −1 , −1 , (4.1)
Chapter 4 モデルフリー型の強化学習 4.1 データにもとづく意思決定 4.2 価値関数の推定
4.3 方策と行動価値関数の学習 4.4*収束性 4.5 アクター・クリティック法
4.2 価値関数の推定 4.2.1 ベルマン作用素の標本近似 4.2.2 バッチ学習の場合 4.2.3
オンライン学習の場合 4.2.3.1 TD法 4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法
4.2 価値関数の推定 #1 方策 に従い行動選択する場合の期待リターン(価値関数) p.29 をデータから推定する 未知:状態遷移確率、報酬関数の環境情報
既知:状態数、行動数 価値関数の推定器は、価値関数と同じ自由度を持つ関数 を用いることを想定
4.2 価値関数の推定 #2 履歴データ からのもっとも素朴な 価値関数の推定方法 →モンテカルロ推定: 実績リターン
ハイパーパラメータ ( に近い時間ステップ のリターン を除外するため) のリターンは (偏りのある推定)
4.2 価値関数の推定 #3 モンテカルロ推定(再掲): 実績リターン(再掲): 特に割引率 が1に近い場合:
リターンを正確に計算するには →・ を十分に大きくする → を十分に小さくする( から離したい) →標本数が少なくなる(一般に推定の効率はよくない) →ベルマン作用素にもとづくアプローチへ
4.2 価値関数の推定 4.2.1 ベルマン作用素の標本近似 4.2.2 バッチ学習の場合 4.2.3
オンライン学習の場合 4.2.3.1 TD法 4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法
に従い収集した履歴データ からベルマン期待作用素 を標本近似する は確率変数 の実現値に対応 、 、
など表記は様々 4.2.1 ベルマン作用素の標本近似 #1
p.43式(2.7) の方策のベルマン期待作用素 は関数 に対して と書けるので… 4.2.1 ベルマン作用素の標本近似 #2
の直接的な近似アプローチとして、以下のように 標本近似することが考えられる ここで を近似ベルマン期待作用素(近似ベルマン作用素)と 呼ぶ 4.2.1 ベルマン作用素の標本近似 #3
がモデルべ―ス型でのベルマン作用素と実質同じであること を確認する 行動 について周辺化した報酬関数 を 最小二乗法で推定 or 最尤推定すれば、任意の
について が求まり、(周辺化)状態遷移確率 を 多項分布を用いて最尤推定すれば、次の遷移確率を得る 4.2.1 ベルマン作用素の標本近似 #4
と を用いて式(4.4)の近似ベルマン作用素 は と書けるので、 はモデルベース型のアプローチで最尤推定したベルマン作用 素と同一であるとわかる また は縮小性などのベルマン期待作用素の性質をもつ
4.2.1 ベルマン作用素の標本近似 #5
4.2.1 ベルマン作用素の標本近似 #6 マルコフ決定過程 がエルゴード性(既約的かつ非周期的 である, p.32)を満たすとする 各状態への滞在確率の極限は初期状態に依存せず非ゼロ
よって近似ベルマン作用素 は極限 で初期状態 に依存せず、 となり、ベルマン期待作用素 に収束(式(4.3)) 4.2.1 ベルマン作用素の標本近似 #7
4.2.1 ベルマン作用素の標本近似 #8 また、Tが有限の場合でも の条件付き期待値は と一致
4.2 価値関数の推定 4.2.1 ベルマン作用素の標本近似 4.2.2 バッチ学習の場合 4.2.3
オンライン学習の場合 4.2.3.1 TD法 4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法
4.2.2 バッチ学習の場合 #1 ある方策 に従い行動し収集した履歴データ がすでにあり、 そのデータから の価値関数 を推定するバッチ学習の
場合を考える (2.30)の近似として ベルマン期待作用素 の代わりに式(4.4)の近似作用素 を用いて のように を更新すればよい ベルマン作用素の縮小性の補題2.5 b.(p.51)より、式(4.9)を繰り 返し実施することで、 は唯一の不動点 に単調に収束
4.2.2 バッチ学習の場合 #2 式(4.10)は式(2.10)のベルマン方程式の標本近似に対応 式(4.9)の操作を繰り返さなくても、 方策反復法(アルゴリズム2.2)での方策評価の場合のように 連立方程式を解くことで解析的に を求めることも可能
履歴データ の系列長 の極限 のとき 式(4.7)より は真の に収束するので 推定価値関数 は真の価値関数 に一致
4.2 価値関数の推定 4.2.1 ベルマン作用素の標本近似 4.2.2 バッチ学習の場合 4.2.3
オンライン学習の場合 4.2.3.1 TD法 4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法
4.2.3.1 TD法 #1 データが逐次的に追加され、それに従い推定価値関数 を 逐次的に更新するオンライン学習問題を考える (4.9)をそのままオンライン学習に適用 すると、推定価値関数を
のように更新することが考えられる しかし、 履歴データをすべて記憶しておく必要 すべての状態 それぞれに対して を計算する必要 があるため計算量が大きく、効率的ではない
4.2.3.1 TD法 #2 簡略化して現時間ステップ の観測 , , +1 のみを用いて
を微小に更新すれば となり、履歴データを記憶する必要がなくなる は学習率(ステップサイズ)というハイパーパラメータ や十分小さい定数などを用いる ※収束性を保証するにはロビンス・モンローの条件 を満たす必要がある(詳細は4.4節*)
4.2.3.1 TD法 #3 更新式(4.12)の収束性について 時間ステップ: 状態: 報酬: ≔ ,
次状態:+1 ~ ∙ | , の状況にいるとして、(4.12)の は確率変数 その期待値は、 となって真のベルマン期待作用素 による演算と一致 (式(4.8)p.90参照)
4.2.3.1 TD法 #4 真のベルマン期待作用素との誤差を と定義すれば、 その期待値 はゼロ 報酬が有界 なので明らかに
誤差 を用いて更新式(4.12)を書き直せば となり、真の を用いた更新則 にノイズ が乗っているものと解釈できる 確率的近似、特にロビンス・モンローのアルゴリズムとして有名
4.2.3.1 TD法 #5 更新式(4.12)は による動的計画法(式(2.30))の確率的近似 に対応 学習率 がロビンス・モンローの条件を満たしていれば、
極限 で は を満たす不動点に収束 ベルマン方程式の一意性(命題2.4, p.50)より、上式を満たす は唯一 なので、 が真の価値関数 に収束
4.2.3.1 TD法 #6 更新式(4.12)を書き換えると、 ここで は の更新量であり、 は
+ 1と の異なる時間ステップでの の予測価値の差異 と解釈できる → :時間的差分誤差もしくはTD誤差 式(4.15)による価値関数の学習法:TD法 TD誤差を利用する学習法の総称:TD学習
4.2.3.1 TD法 #7 (4.16) (4.15)
4.2 価値関数の推定 4.2.1 ベルマン作用素の標本近似 4.2.2 バッチ学習の場合 4.2.3
オンライン学習の場合 4.2.3.1 TD法 4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法
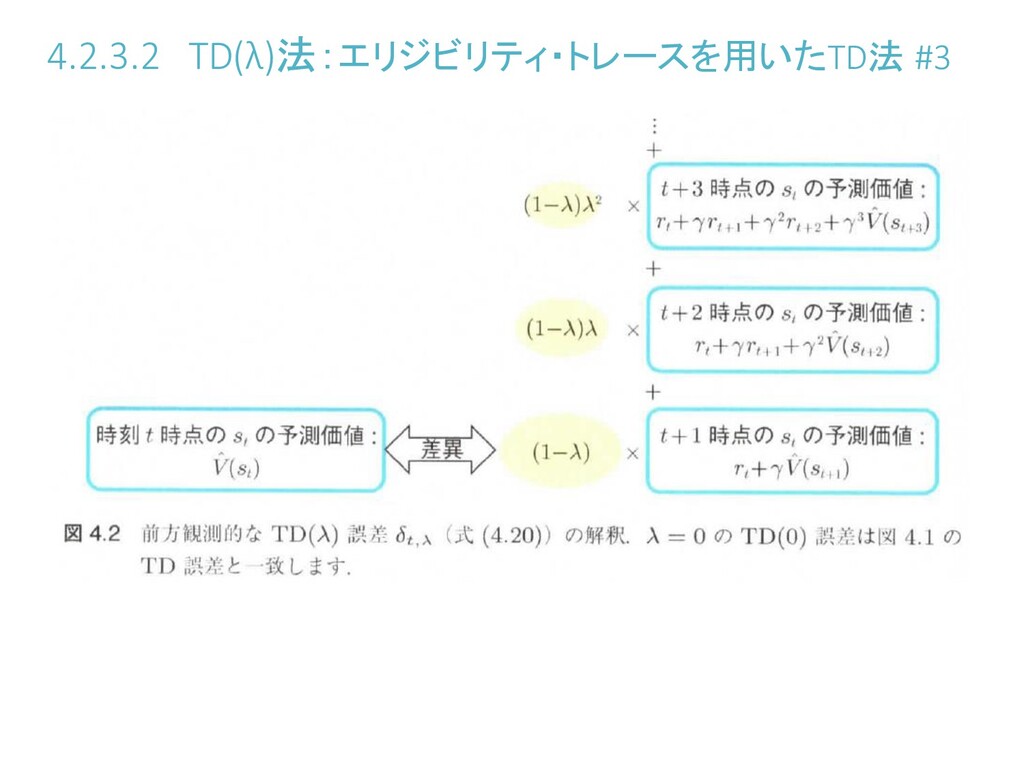
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #1 TD法を一般化したものがTD()法 = 0のときはTD法と同一とみなせる(TD(0)法) のTD誤差
は、 + 1時点での の予測価値 を 目的変数とした場合の の予測誤差と解釈できる 一般化して、 を からのステップ切断リターンと呼ぶ このときのTD誤差は
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #2 さらに一般化 →目的変数:複数ステップ の の平均値 ステップ数の増加に従って重み係数を指数減衰させるハイパー パラメータ
を導入すると、重み付き平均は このときのTD誤差 は前方観測的なTD()誤差と呼ばれる (λは0.4~0.8くらいが実験的によいと示されている)
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #3
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #4 を書き換えて として推定価値関数 を更新する方法 =前方観測的なTD()アプローチ ...ただし の計算に大きな時間遅れが発生し
オンライン学習に不適 → を時間的に分解、確定している部分のみを用いて 価値関数を更新するアプローチが提案されている (後方観測的アプローチ) p.93
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #5 推定価値関数 が固定(学習率 がゼロor非常に小さい)とき から、
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #5 これを時間分解すると となり、時間ステップ時点で第1項は計算可能
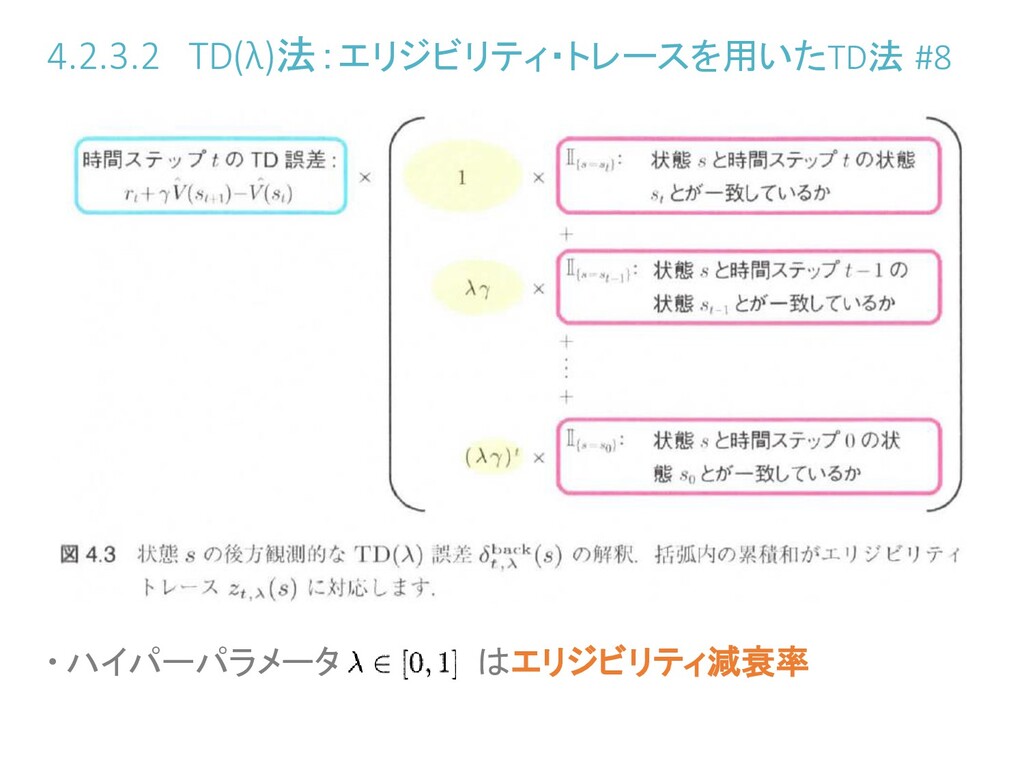
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #6 各状態についてのトータルの更新量を考える 時間ステップまでに状態に訪問した時間ステップの 集合: 状態の時間ステップまでのTD()誤差の和
を に分解して
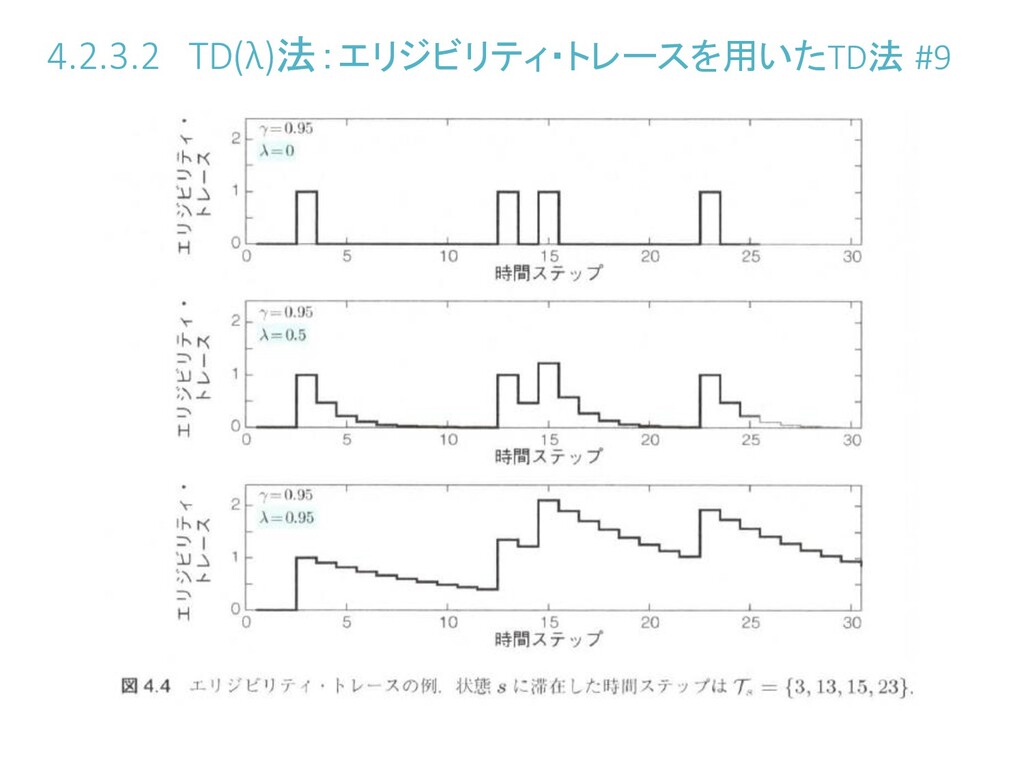
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #7 なので、 を導入すれば、 :後方観測的なTD()誤差( をどの程度過去まで伝播させるか) :エリジビリティ・トレース(状態に直近にどれほど滞在したか)
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #8 ハイパーパラメータ はエリジビリティ減衰率
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #9
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #10 より、前方観測的なTD()アプローチ の近似として、 これが後方観測的なTD()アプローチ
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #11 前方観測的なTD()誤差 と 後方観測的なTD()誤差 の時間平均は一致( 固定)
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #12 TD()法の実装 エリジビリティ・トレースは の定義から と初期化して、各時間ステップで と
を更新すれば、 は と一致
4.2.3.2 TD(λ)法:エリジビリティ・トレースを用いたTD法 #13
Chapter 4 前半終了 お疲れさまでした!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}