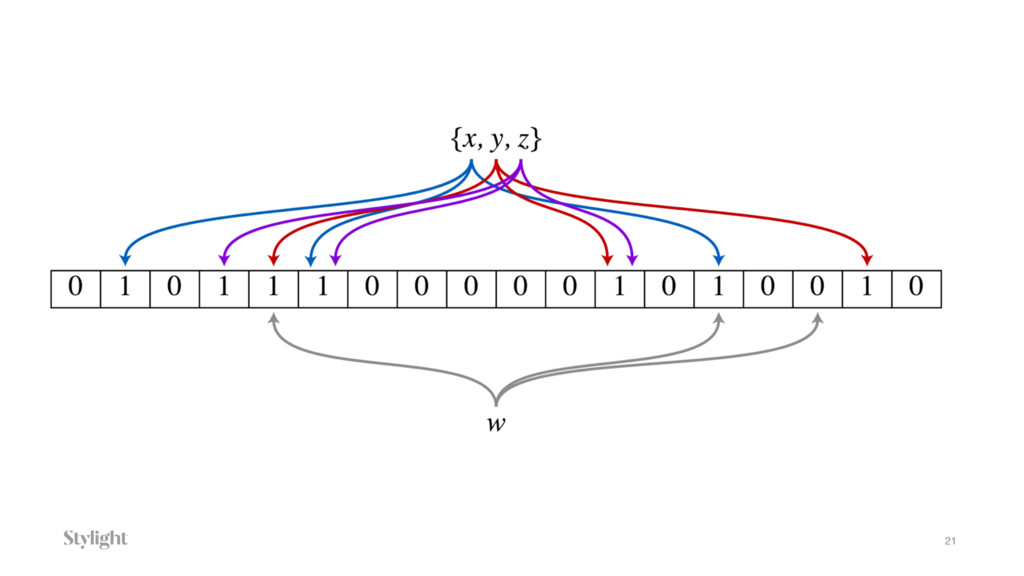
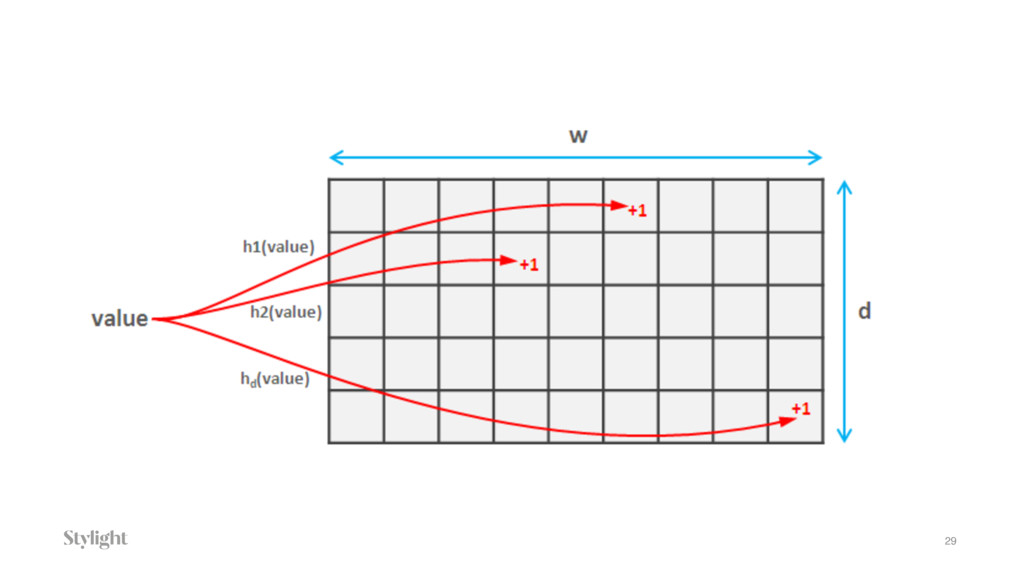
Many people use Go for different projects: WebDev, DevOps or other general-purpose tasks. On another hand, with all the beauty and performance of the language it could be a good challenger for Data applications. In the talk, we will go through the common problems of Data Engineering. Starting with high-performance caching and probabilistic data structures like Bloom filters, CountMin or Hyperloglog. We will cover all stages of Data Pipelining like writing data producers for open source Apache Kafka or proprietary Amazon Kinesis or Google Pub/Sub with further data consuming and processing.
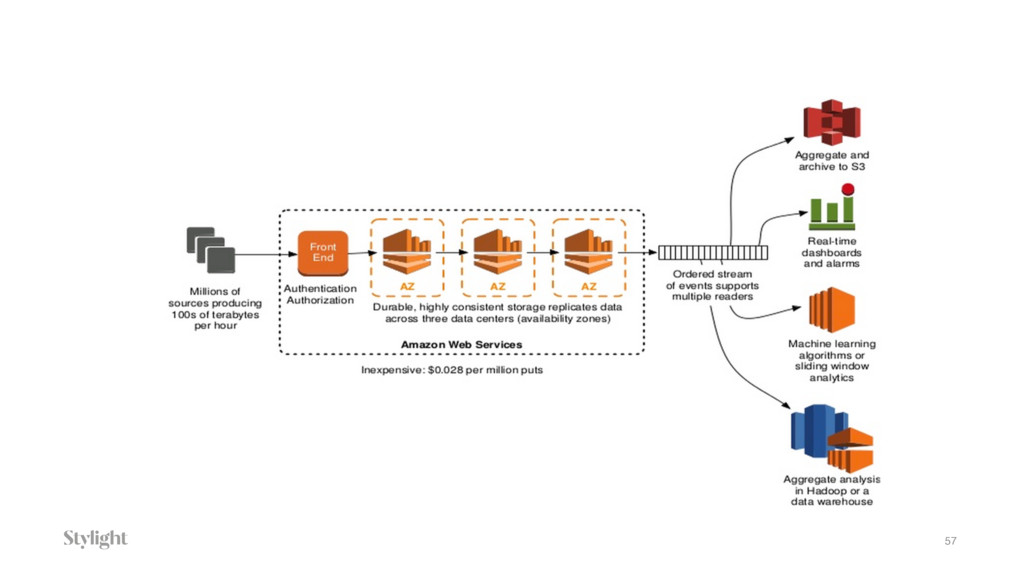
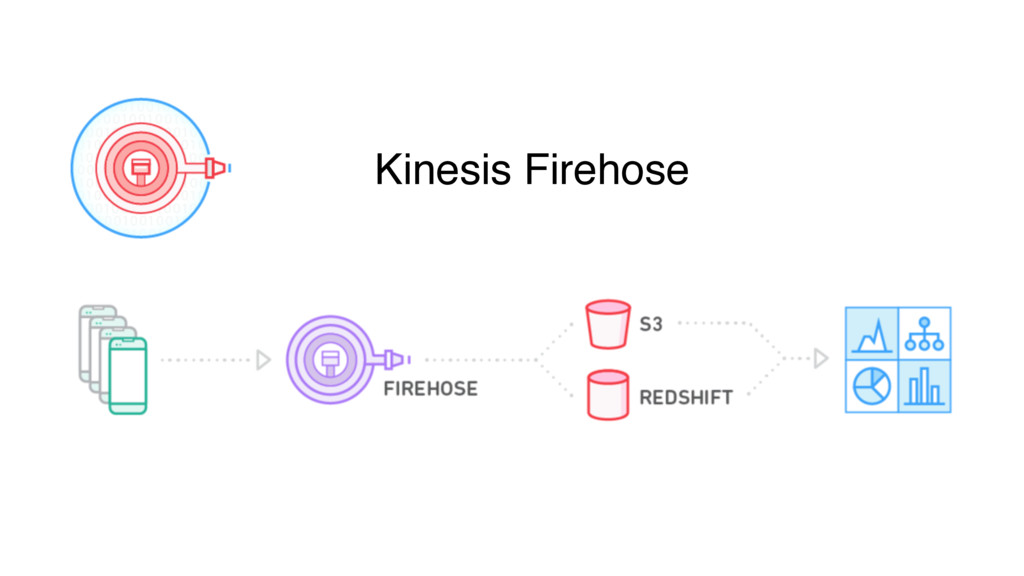
The talk covers real-life use-cases of Data Applications and will provide an overview of existing possibilities of Golang as a language for data engineering. In the talk, we will cover basic ideas of building high-performance data application, creating your own data pipelines based on open source solutions and also hosted proprietary like Amazon Kinesis or Google Pub/Sub. The idea is to provide an overview how good is Golang for data engineering and what are Pros and Cons.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
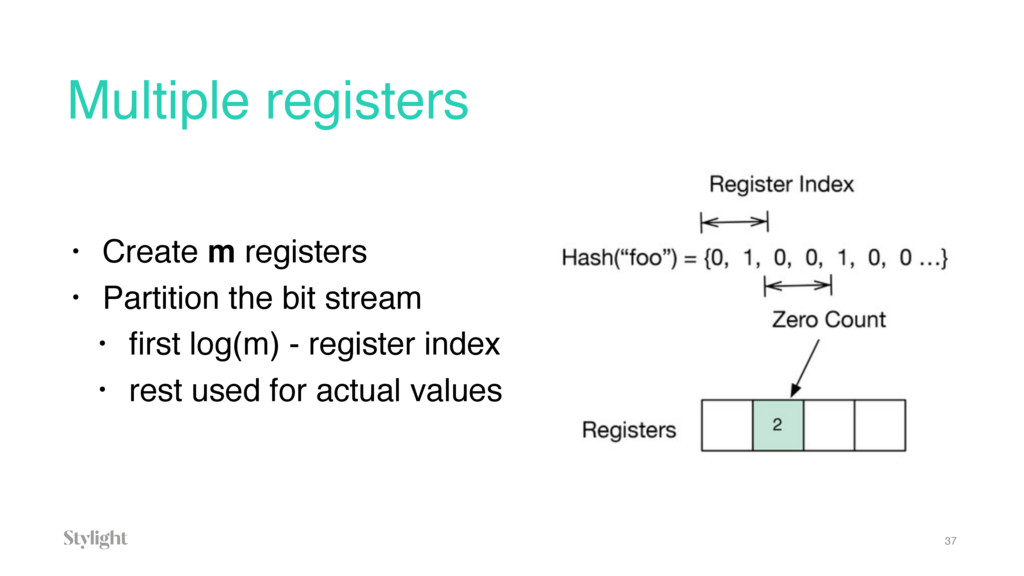{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
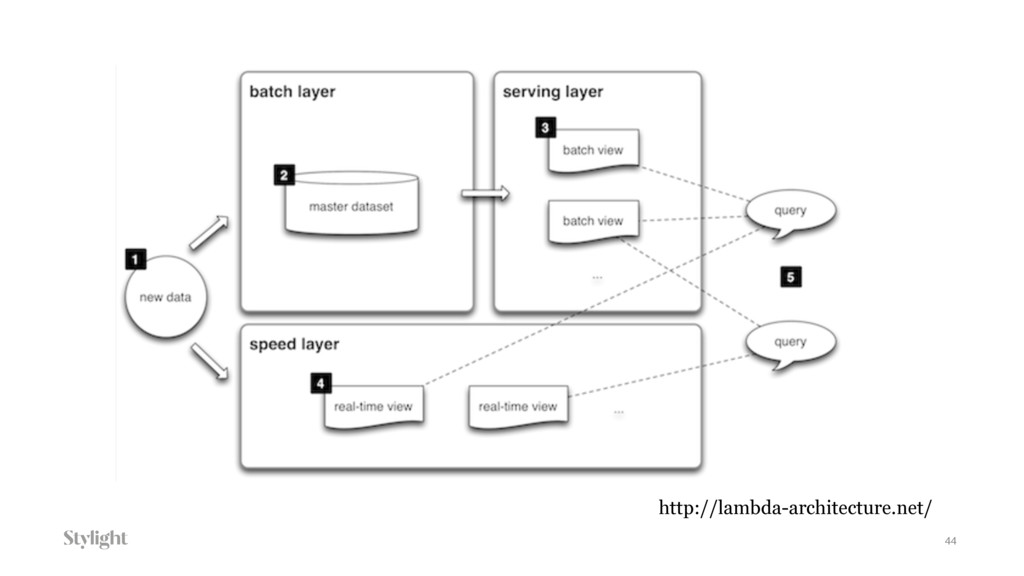{kind=link}
{kind=link}
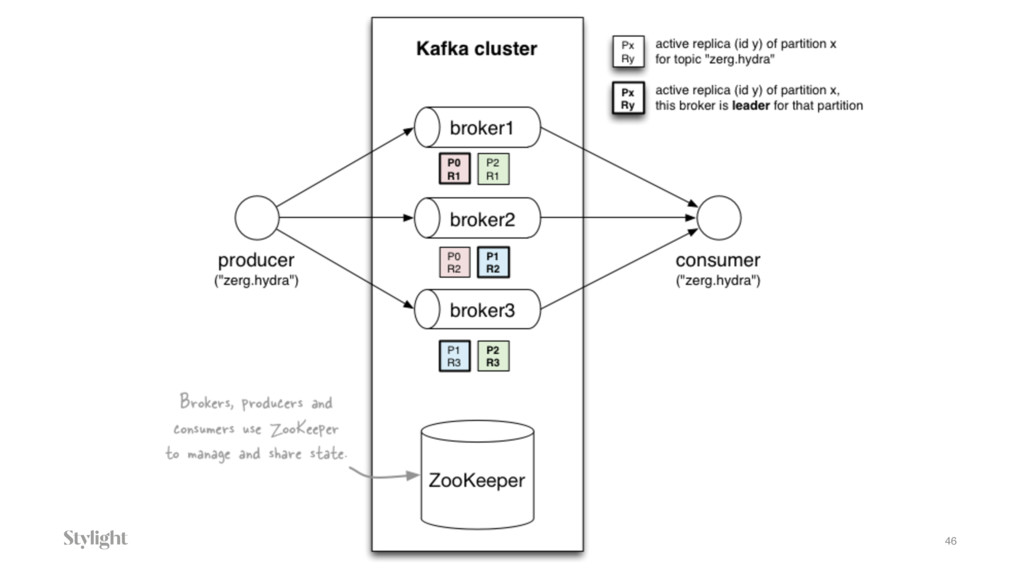{kind=link}
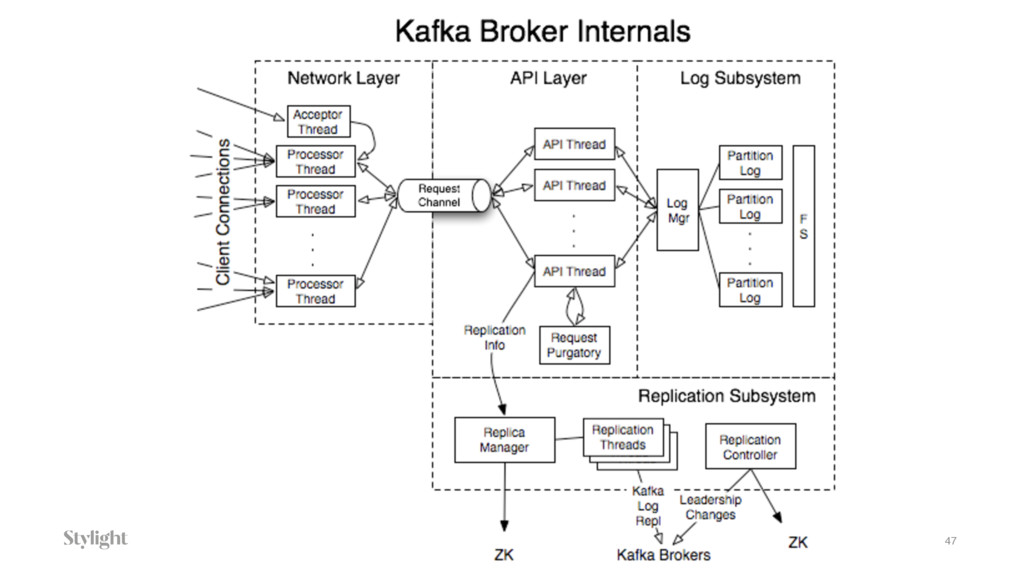{kind=link}
{kind=link}
![49 producer, err := NewAsyncProducer([]string{"localhost:9092"}, nil) if err != nil](https://files.speakerdeck.com/presentations/6017d6510d3c46f6b6631d2096d5436b/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
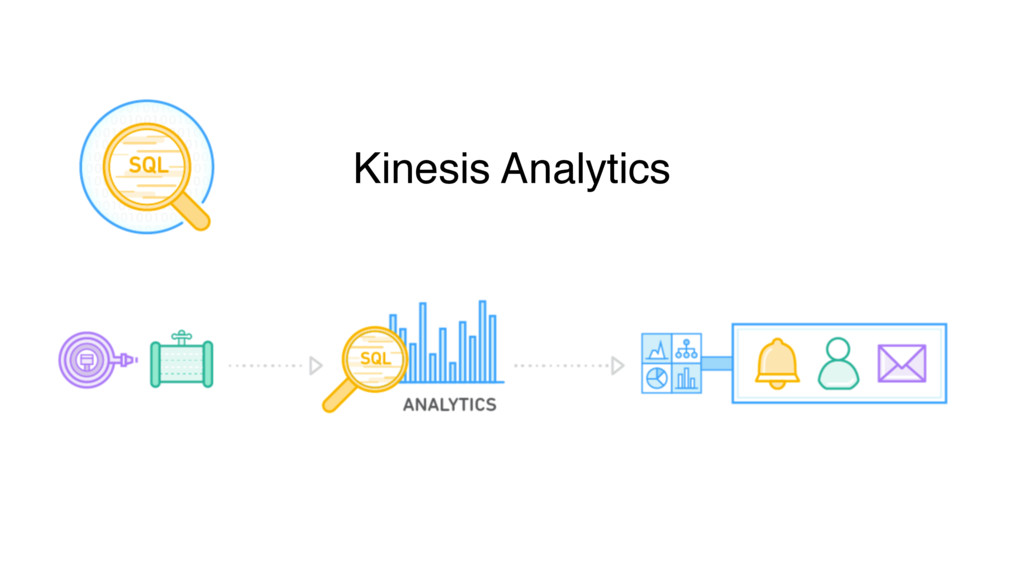{kind=link}
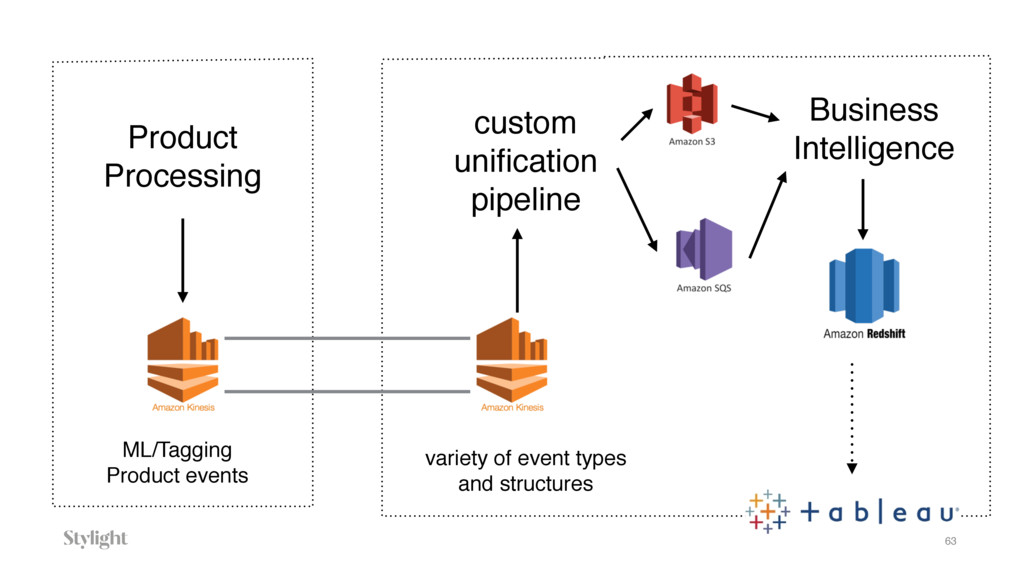{kind=link}
{kind=link}
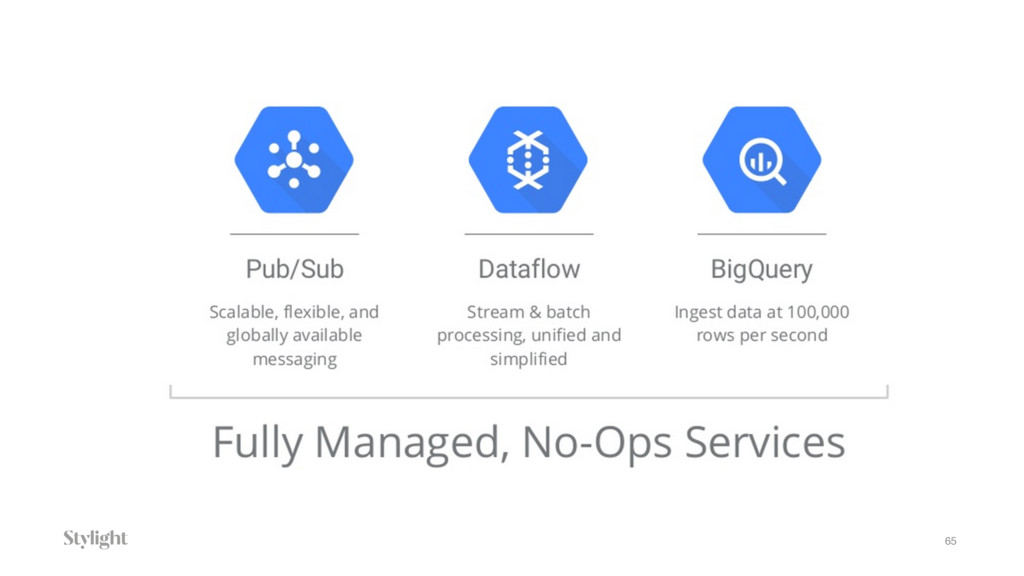{kind=link}
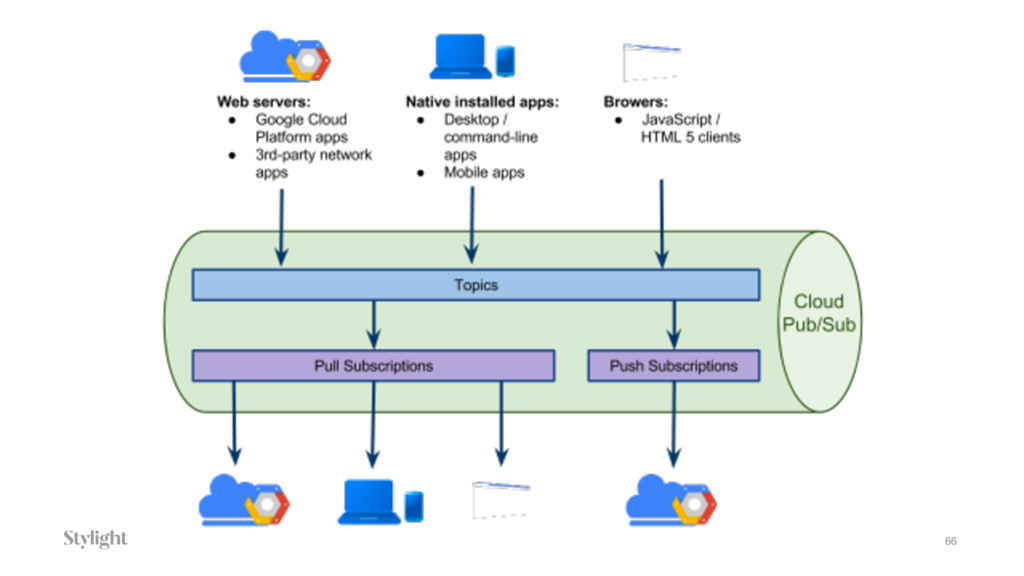{kind=link}
{kind=link}
{kind=link}
{kind=link}
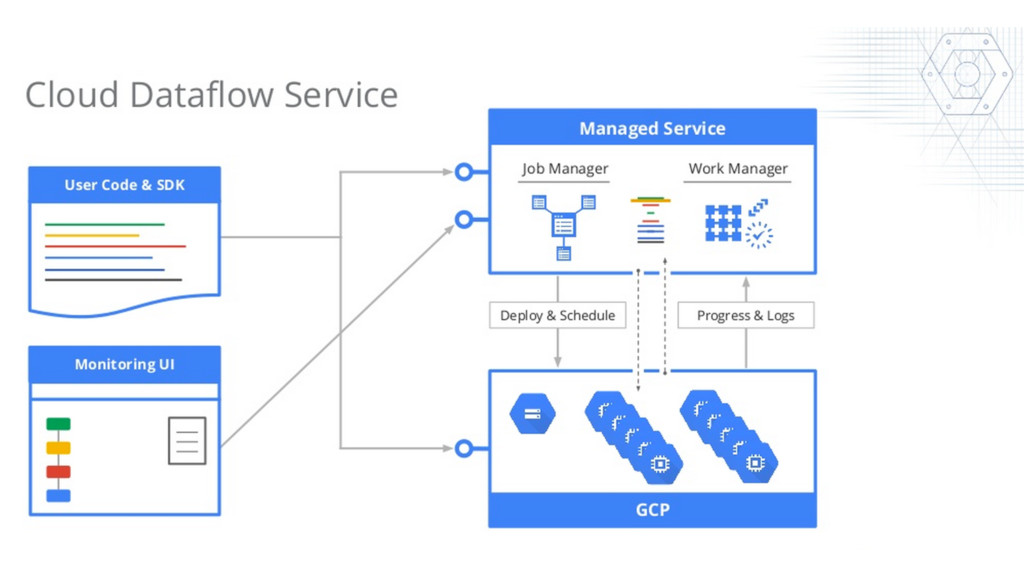{kind=link}
{kind=link}
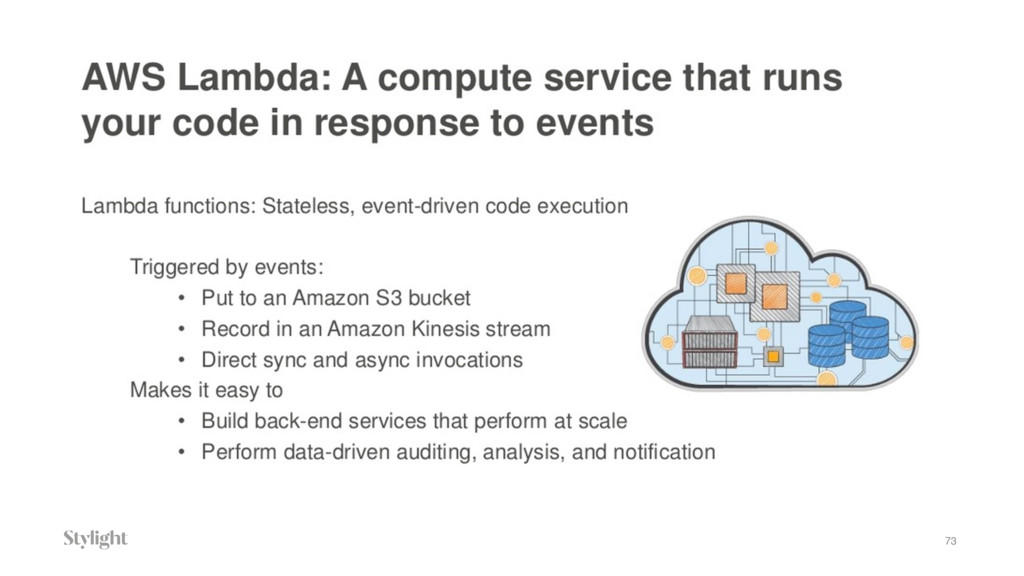
{kind=link}
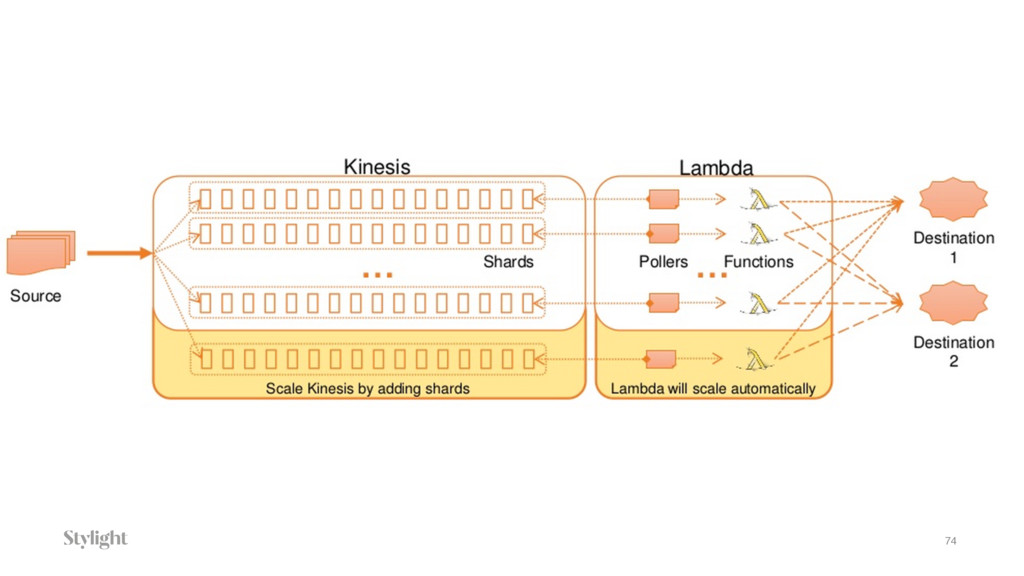
{kind=link}
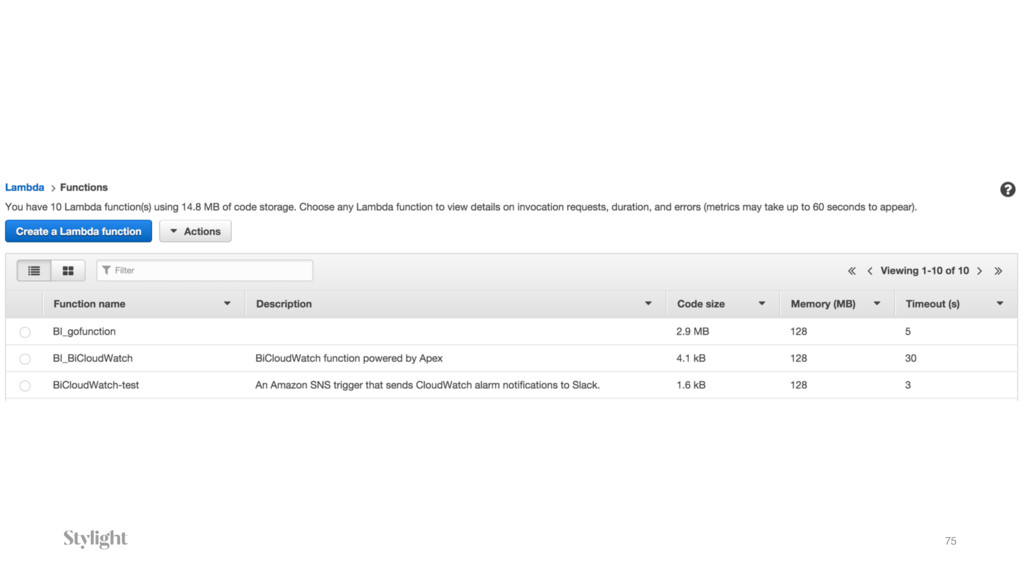
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.stylight.com [email protected] @lc0d3r](https://files.speakerdeck.com/presentations/6017d6510d3c46f6b6631d2096d5436b/slide_81.jpg){kind=link}
{kind=link}
{kind=link}