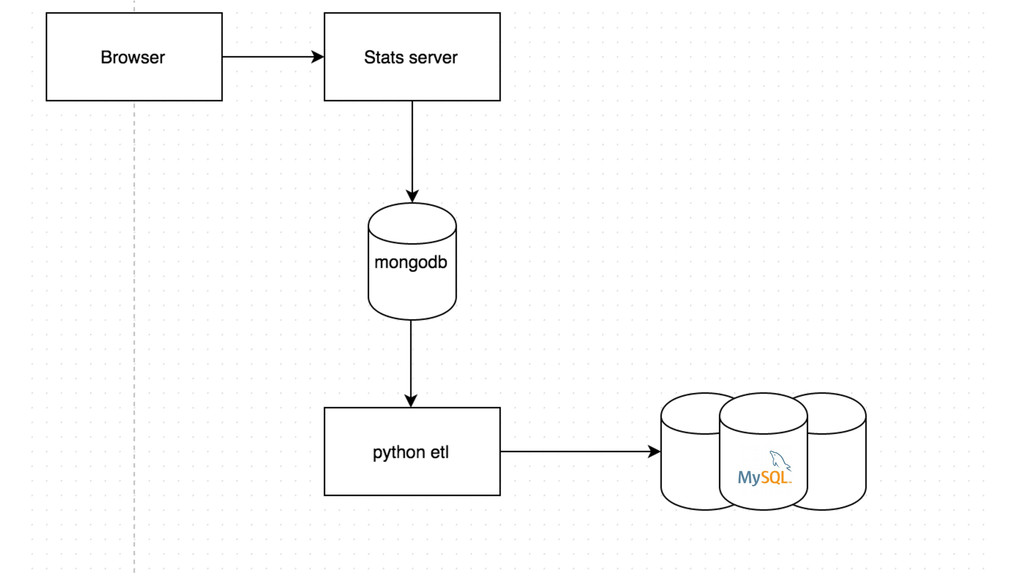
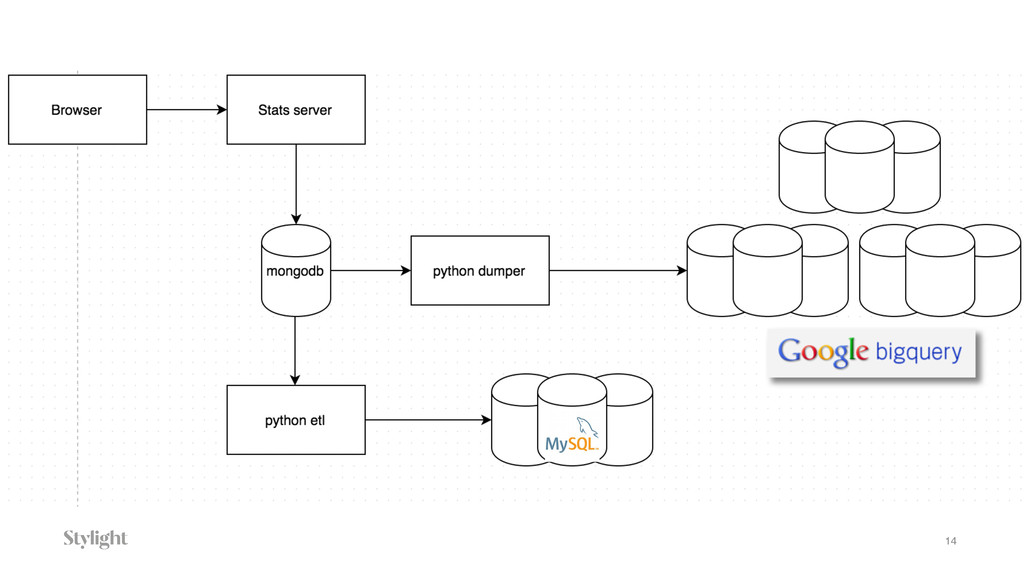
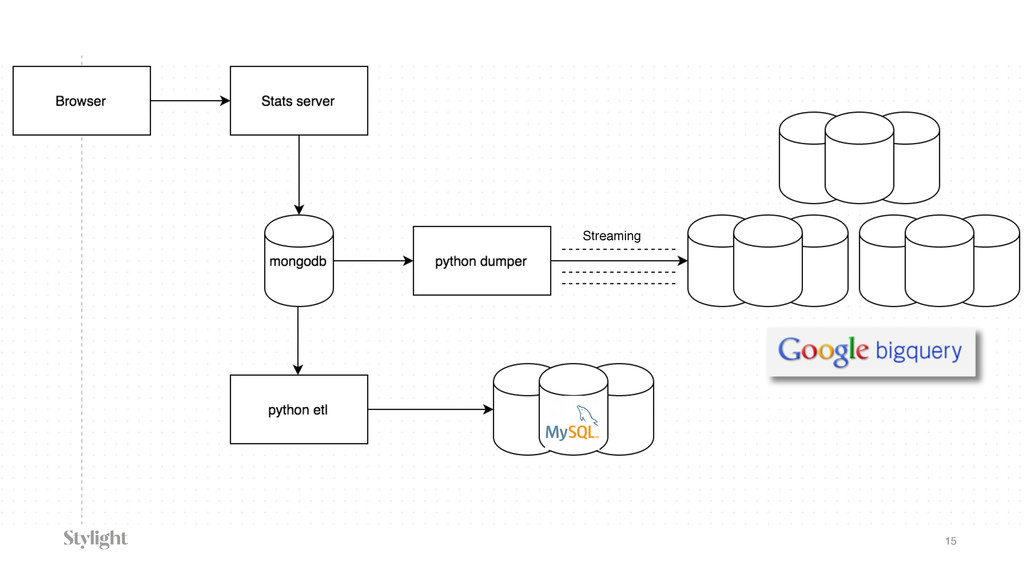
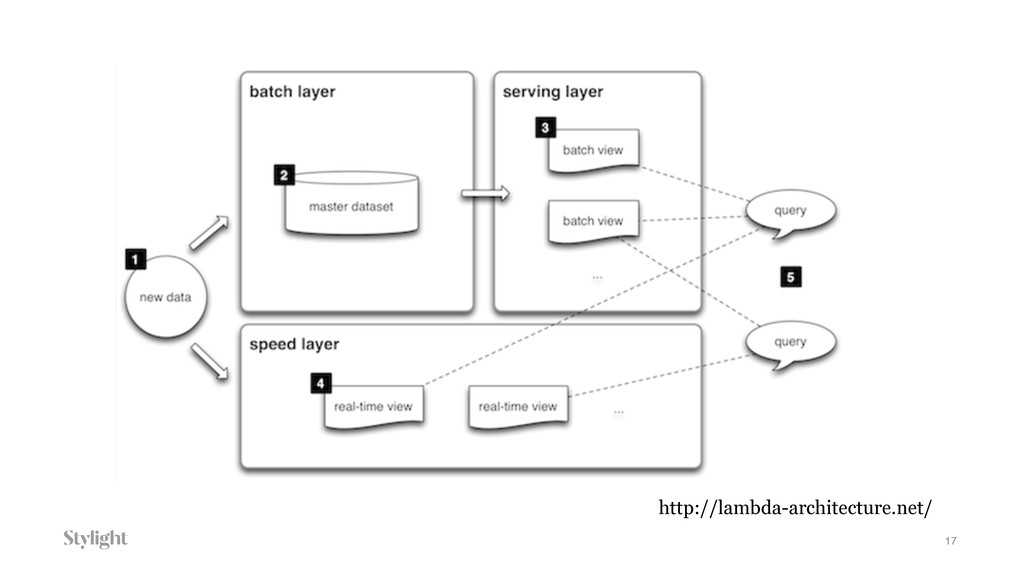
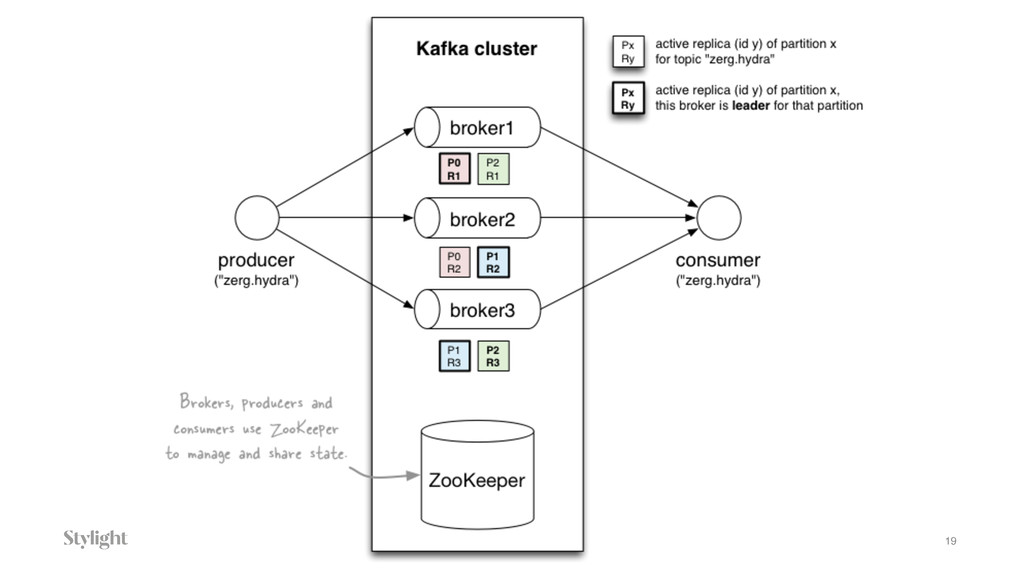
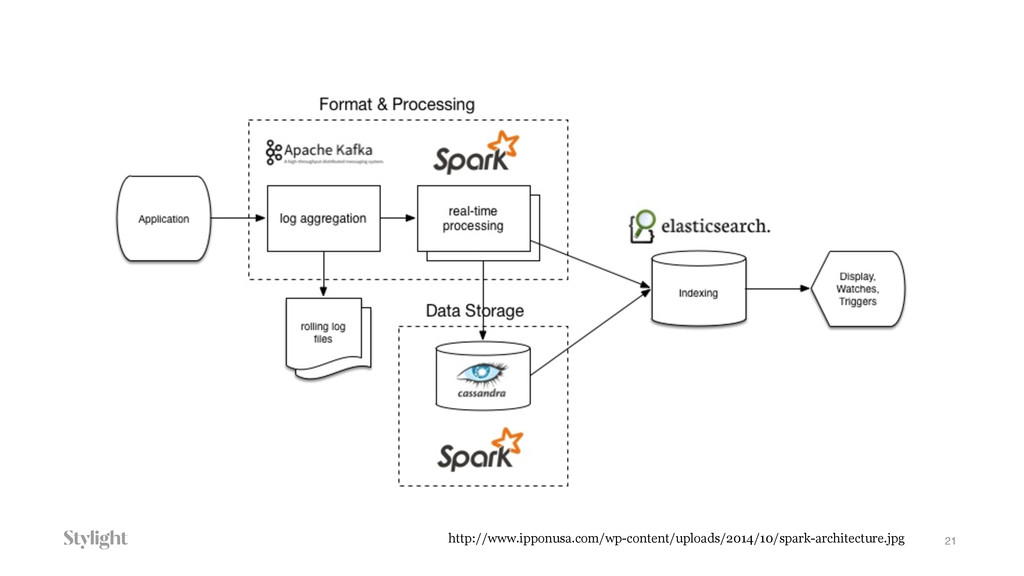
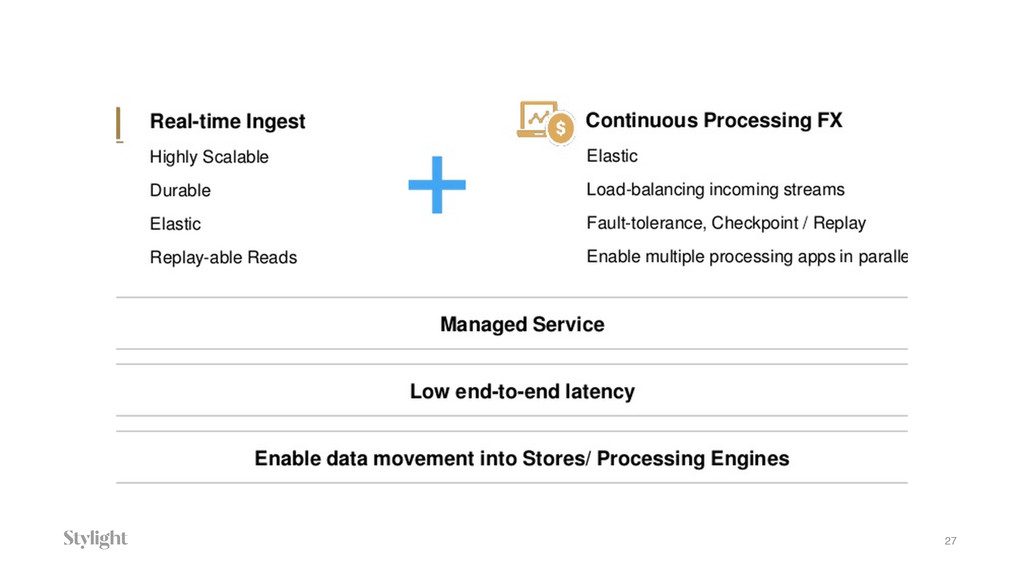
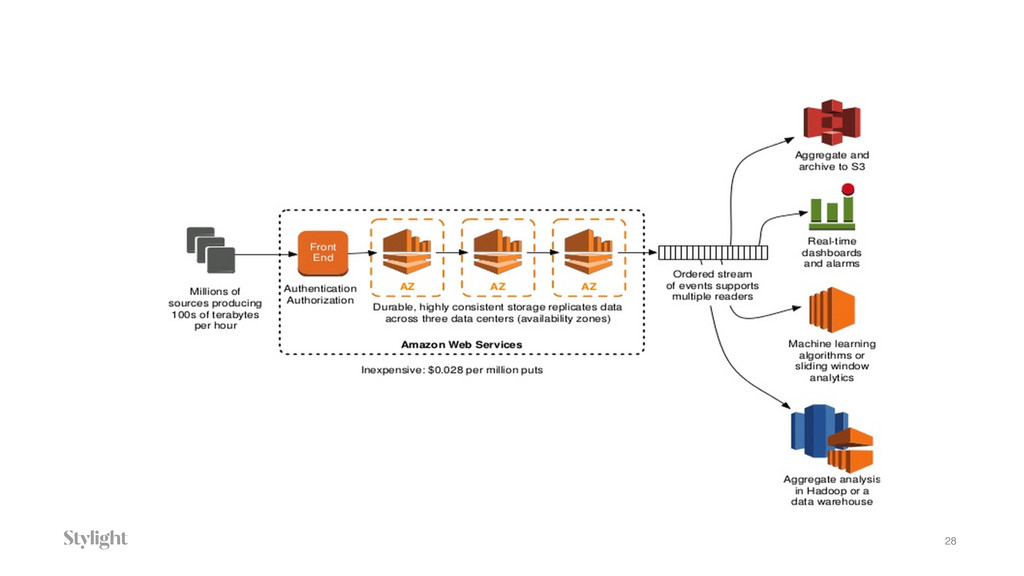
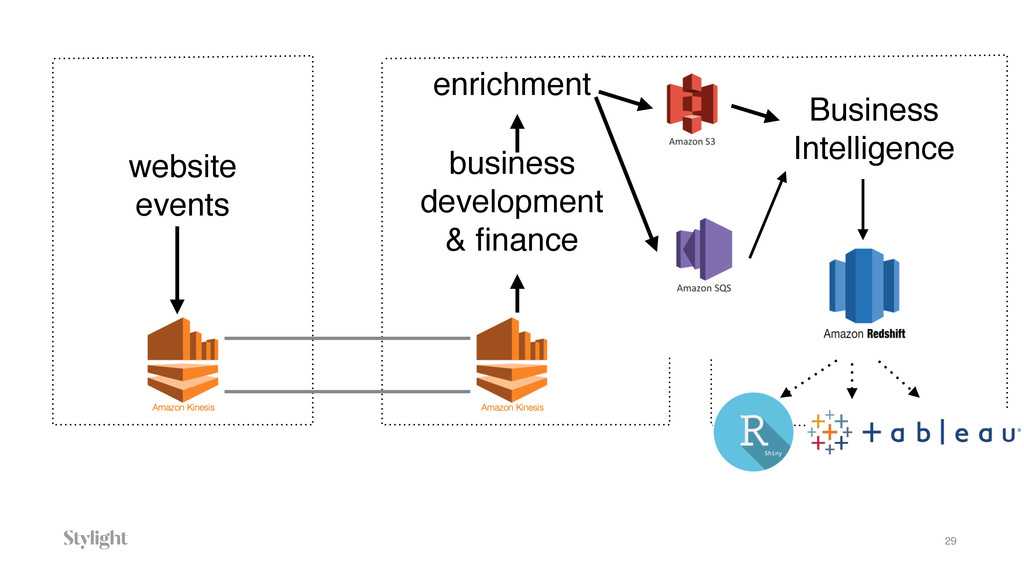
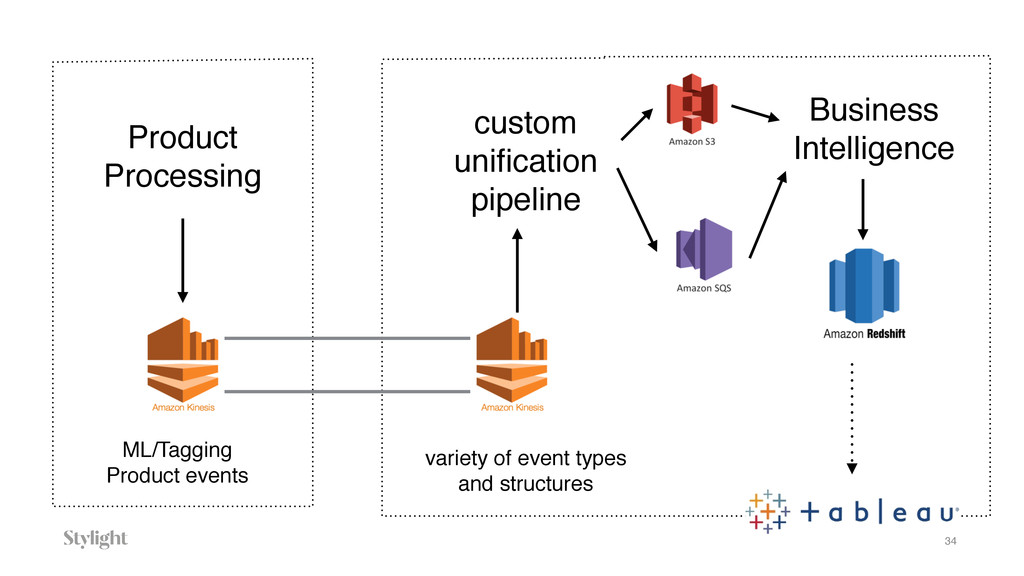
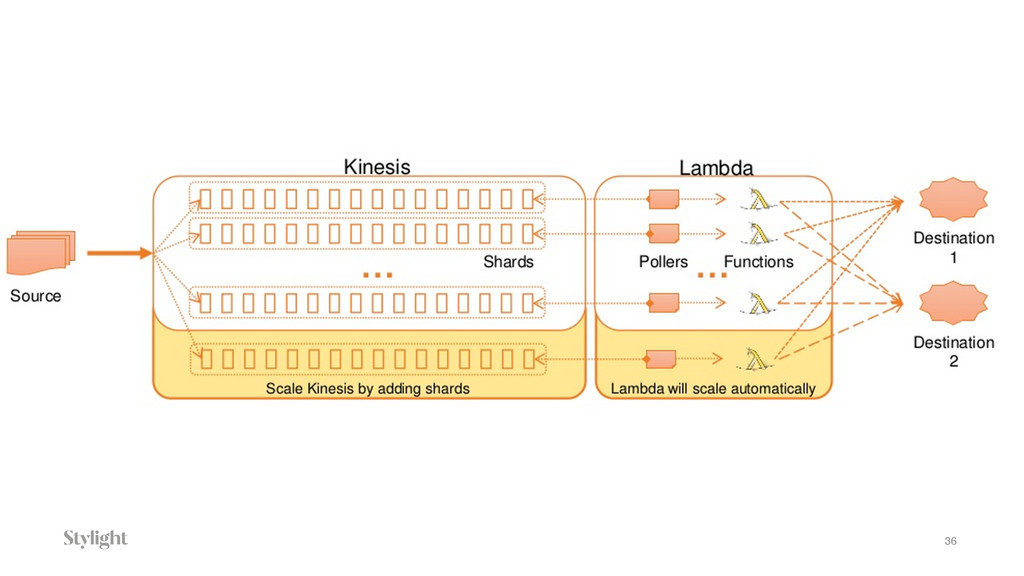
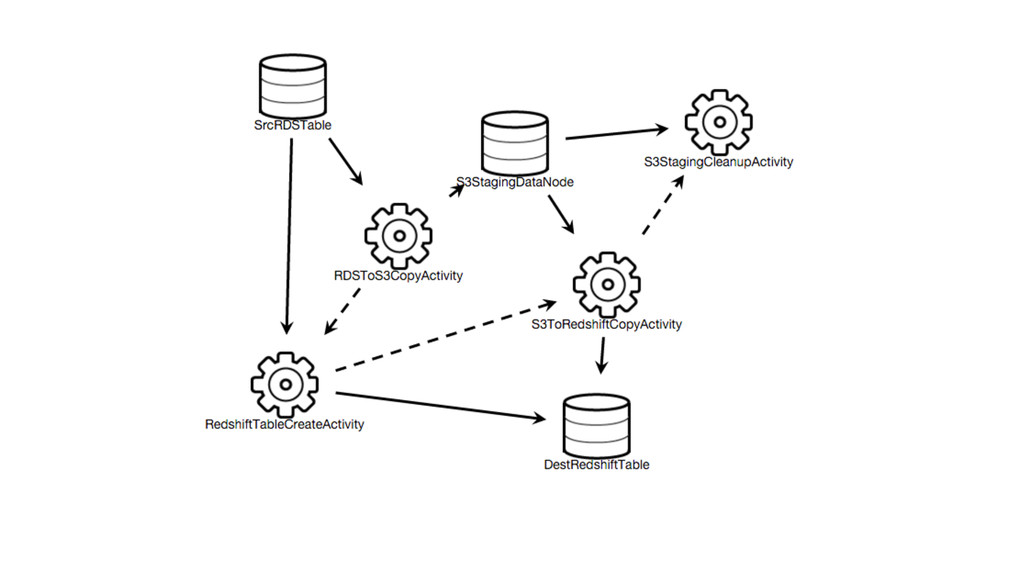
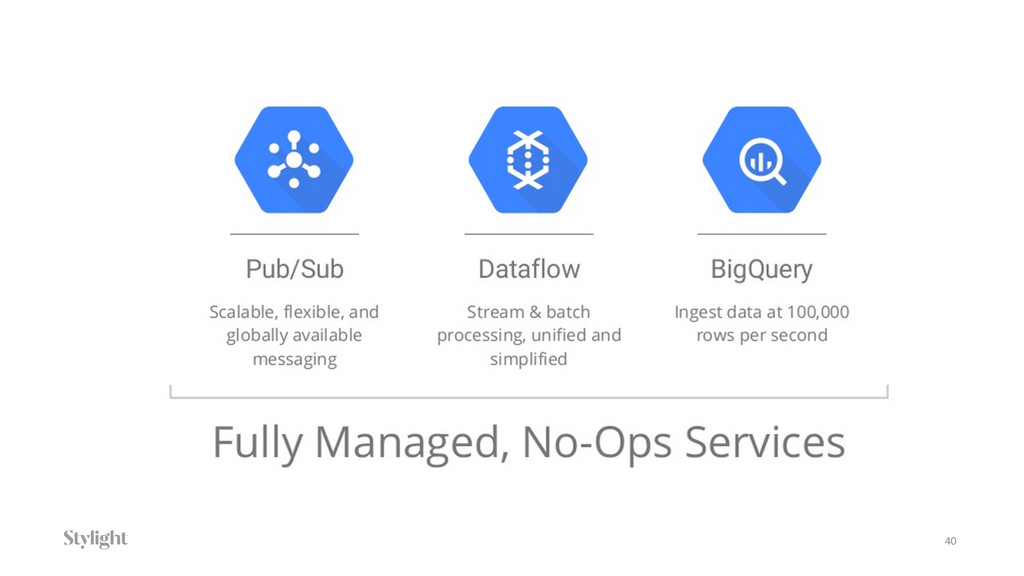
Data is becoming one of the main decision-makers in an organisation. The more data we have the more challenges we face every day. Every decision we make will have long-term implications. In the talk we will go through different approaches to the data pipelines: from a simple in-house built, with comparison to open source solutions based on Apache stack(Apache Kafka, Apache Samza, Spark) and finally hosted auto-scaling solutions based Amazon(S3, Kinesis, Lambda, EMR) or Google(Pub/Sub, Dataflow, BigQuery). The talk covers the main aspects of data collecting processes altogether with further implications for data processing, highlighting appropriate solutions and architectures for the particular use-cases.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
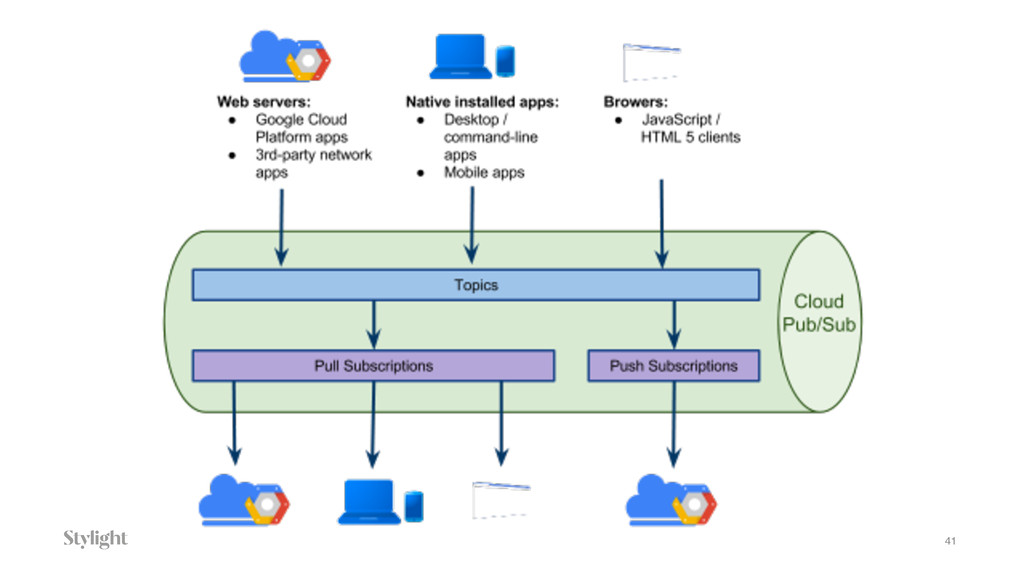{kind=link}
{kind=link}
{kind=link}
{kind=link}
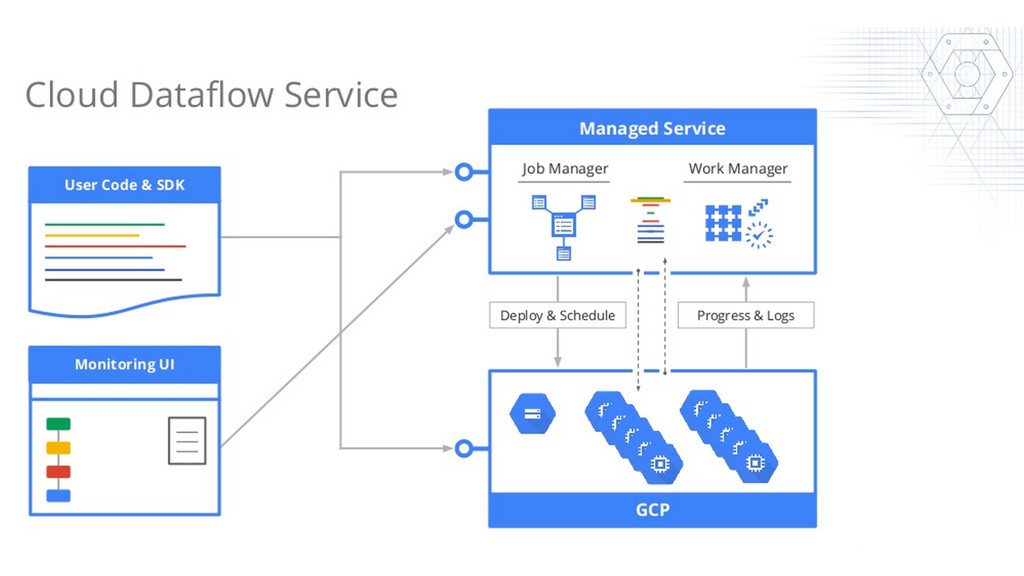{kind=link}
{kind=link}
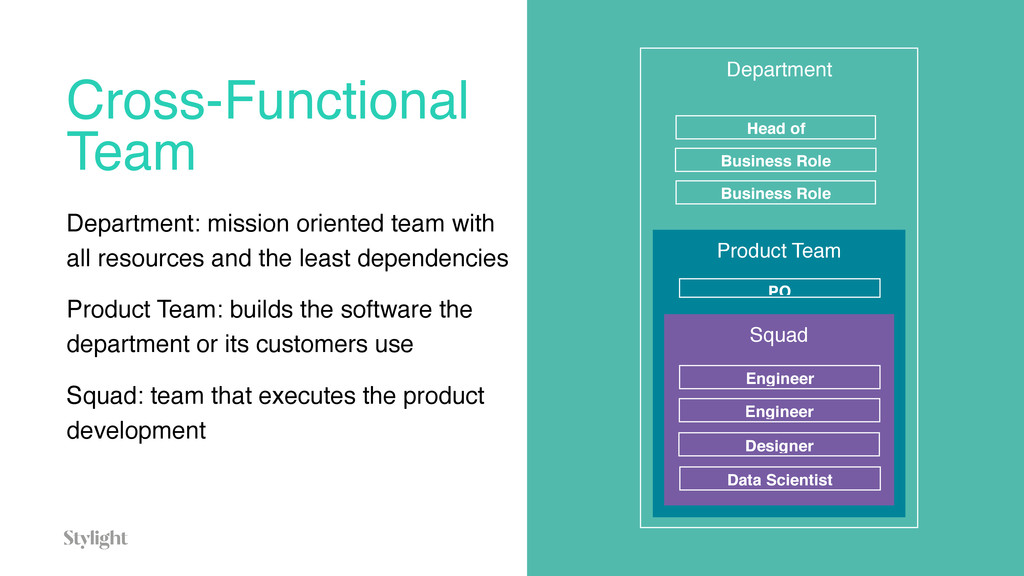{kind=link}
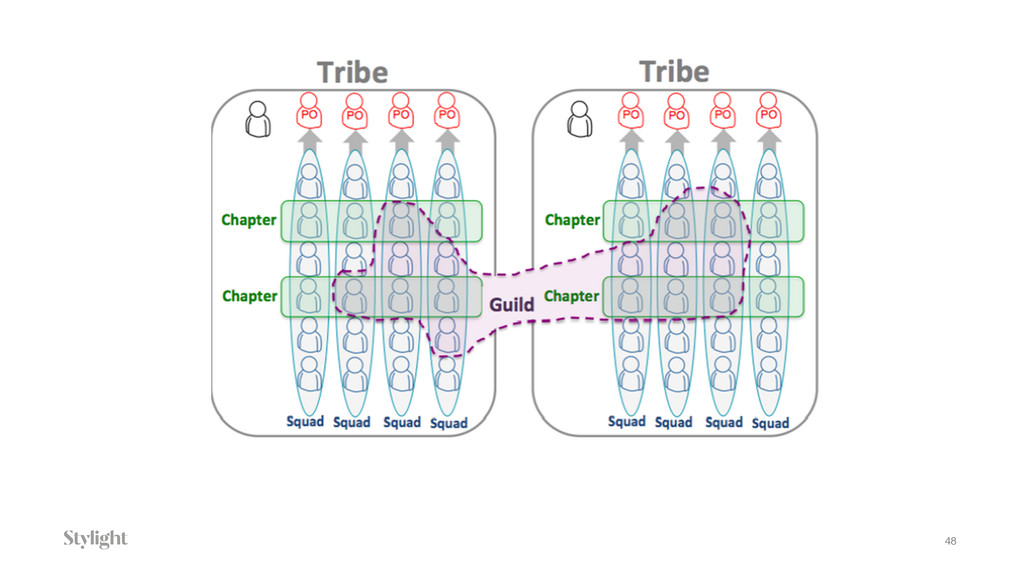{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.stylight.com [email protected] @lc0d3r](https://files.speakerdeck.com/presentations/4fffff1df213452f9d8abadc26791f07/slide_54.jpg){kind=link}
{kind=link}