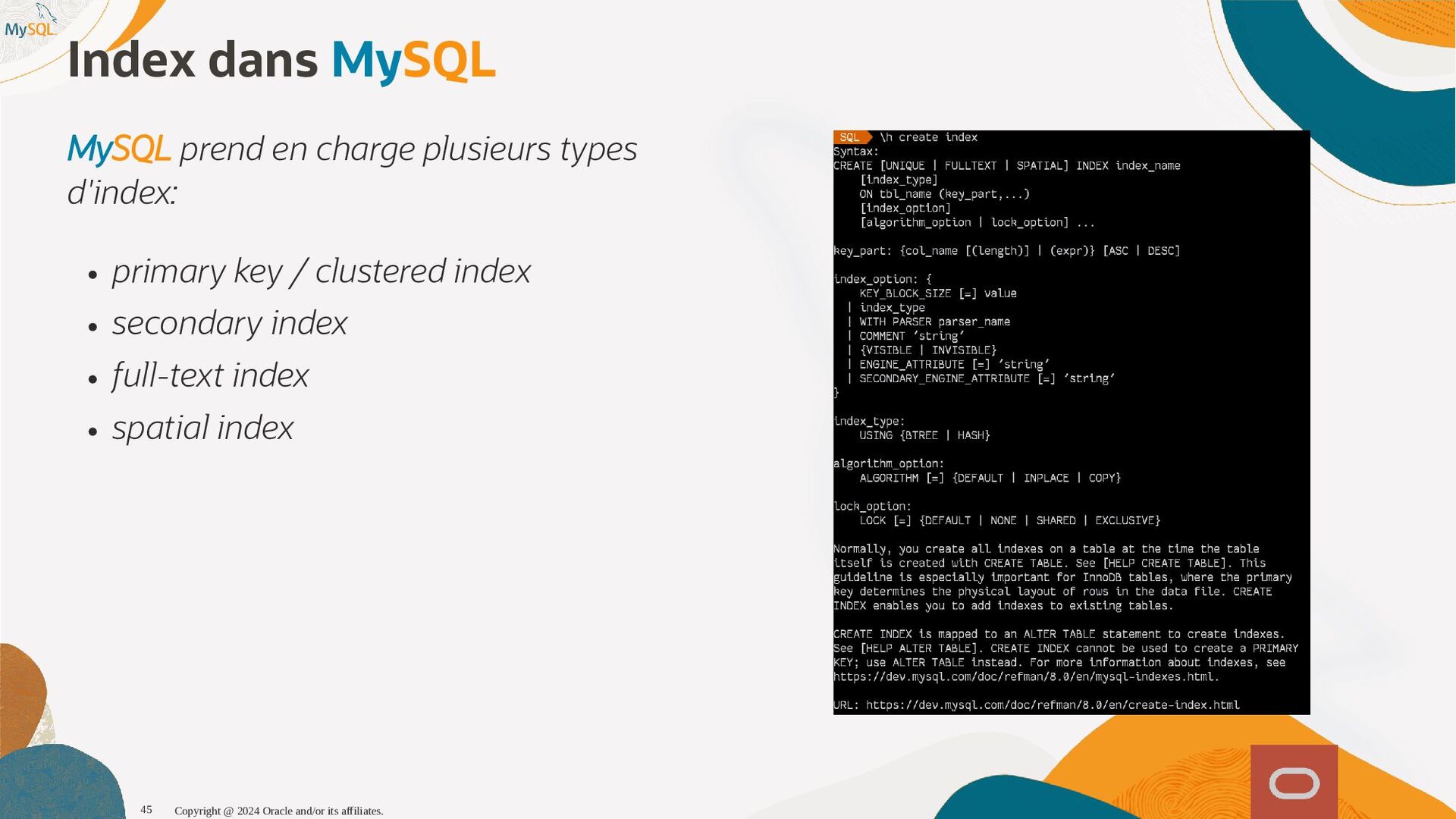
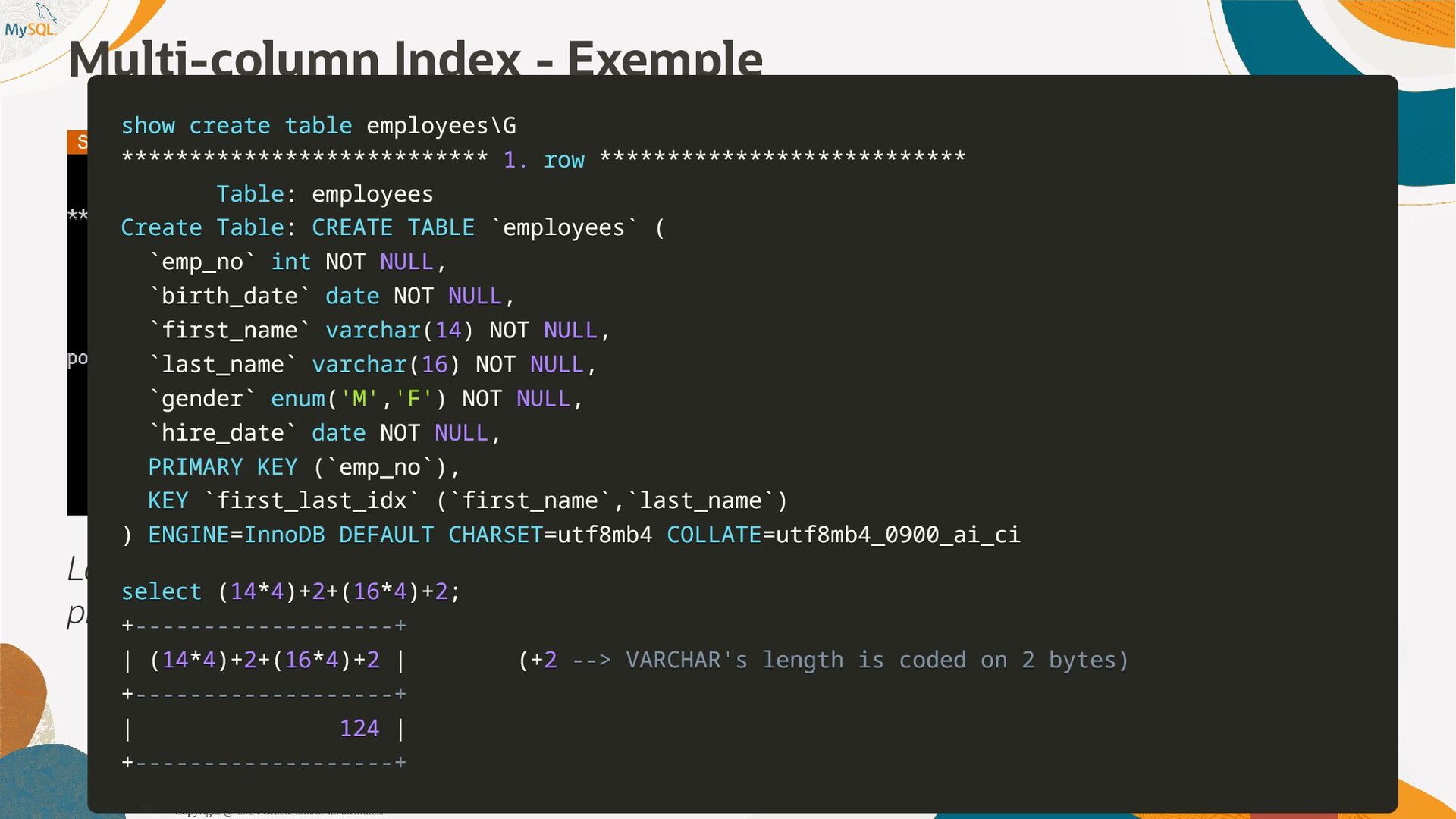
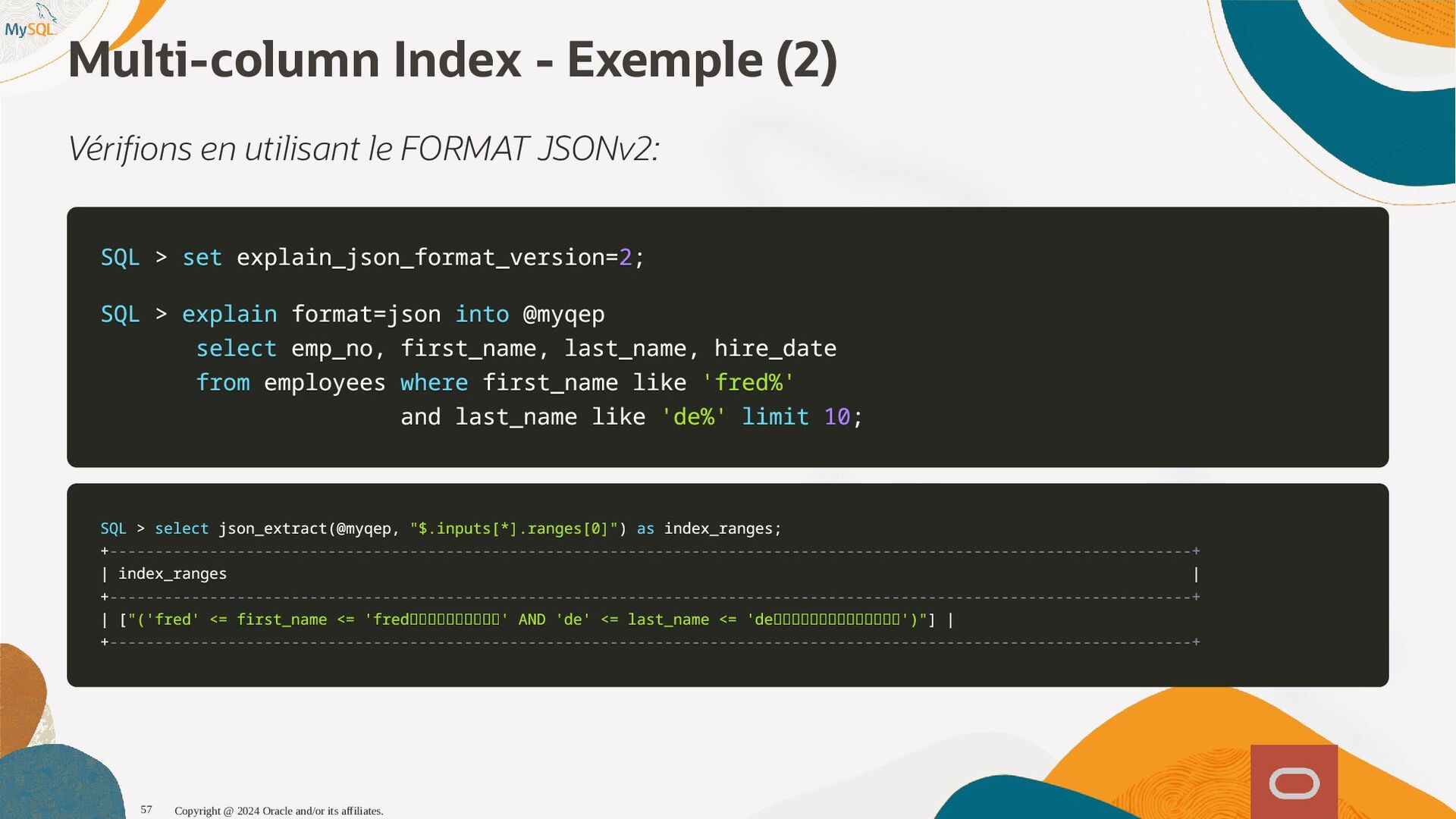
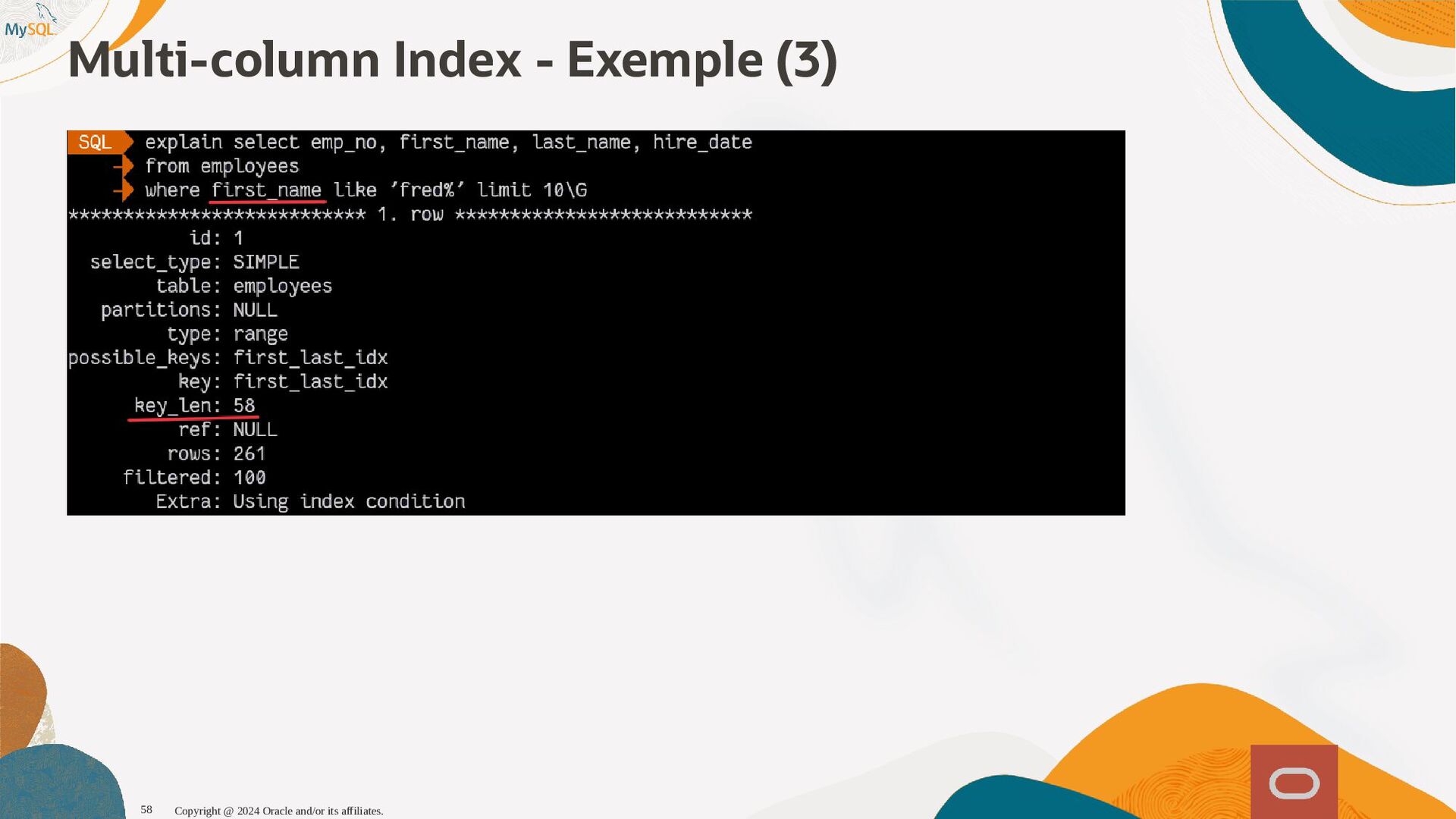
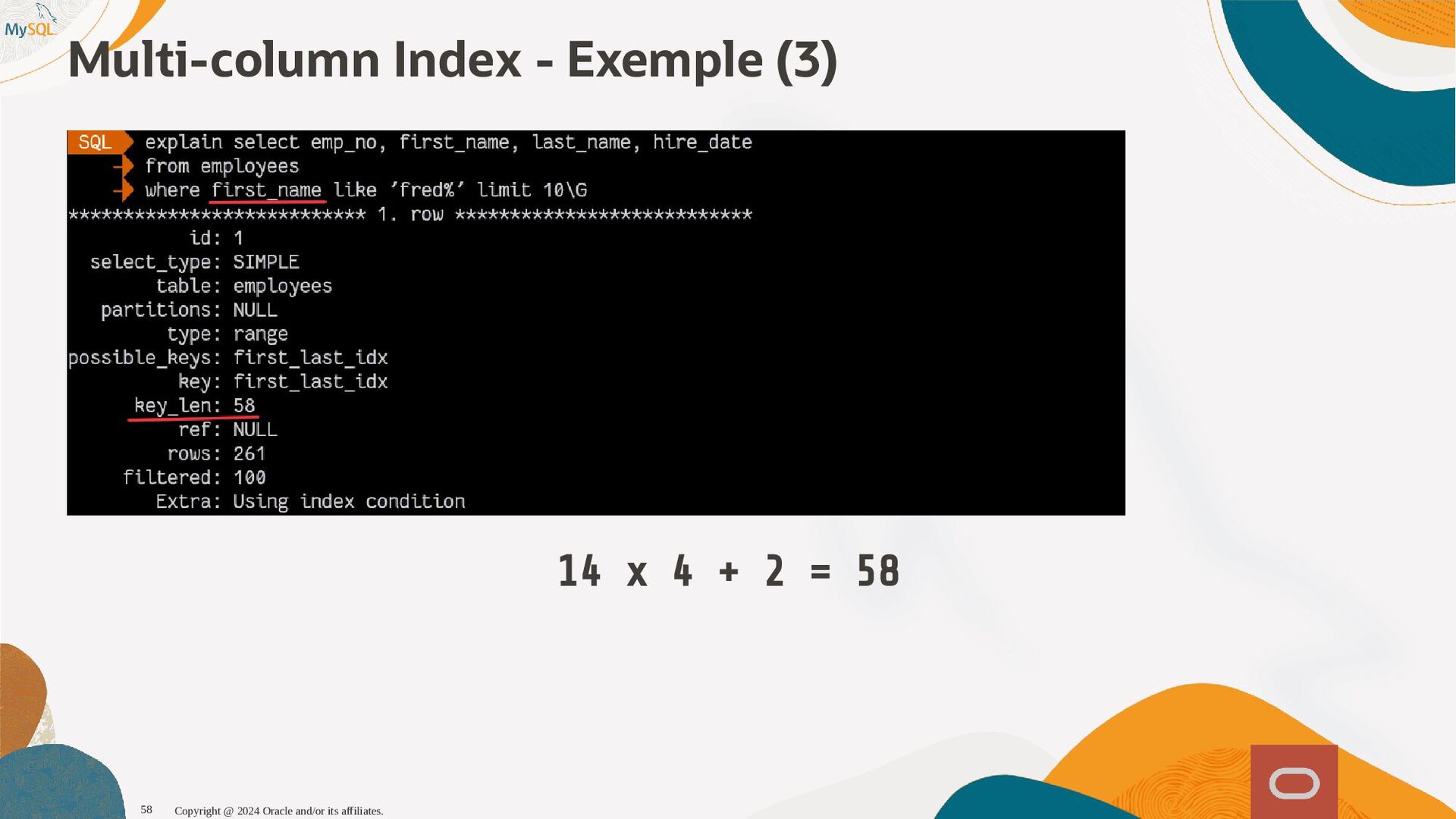
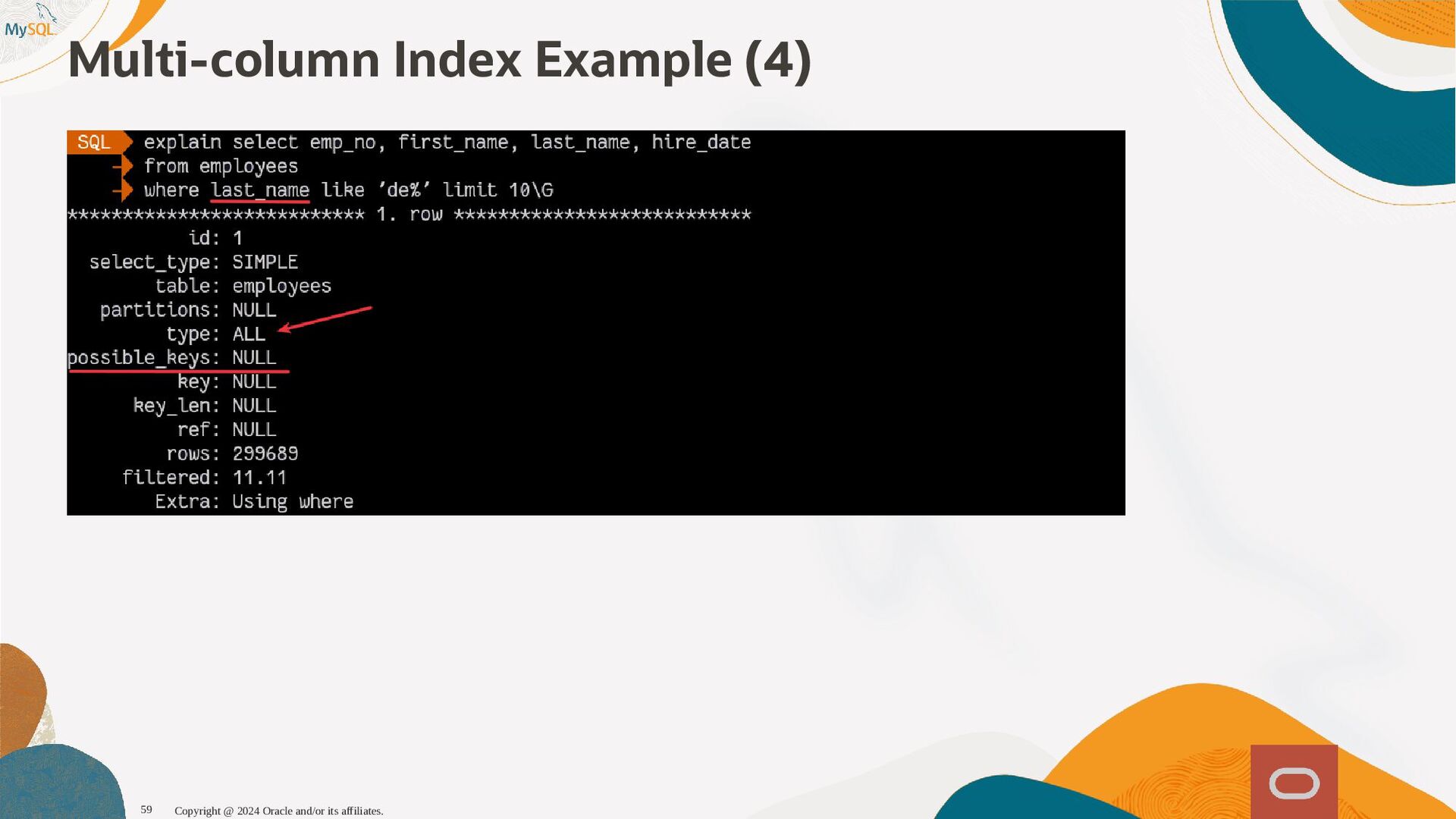
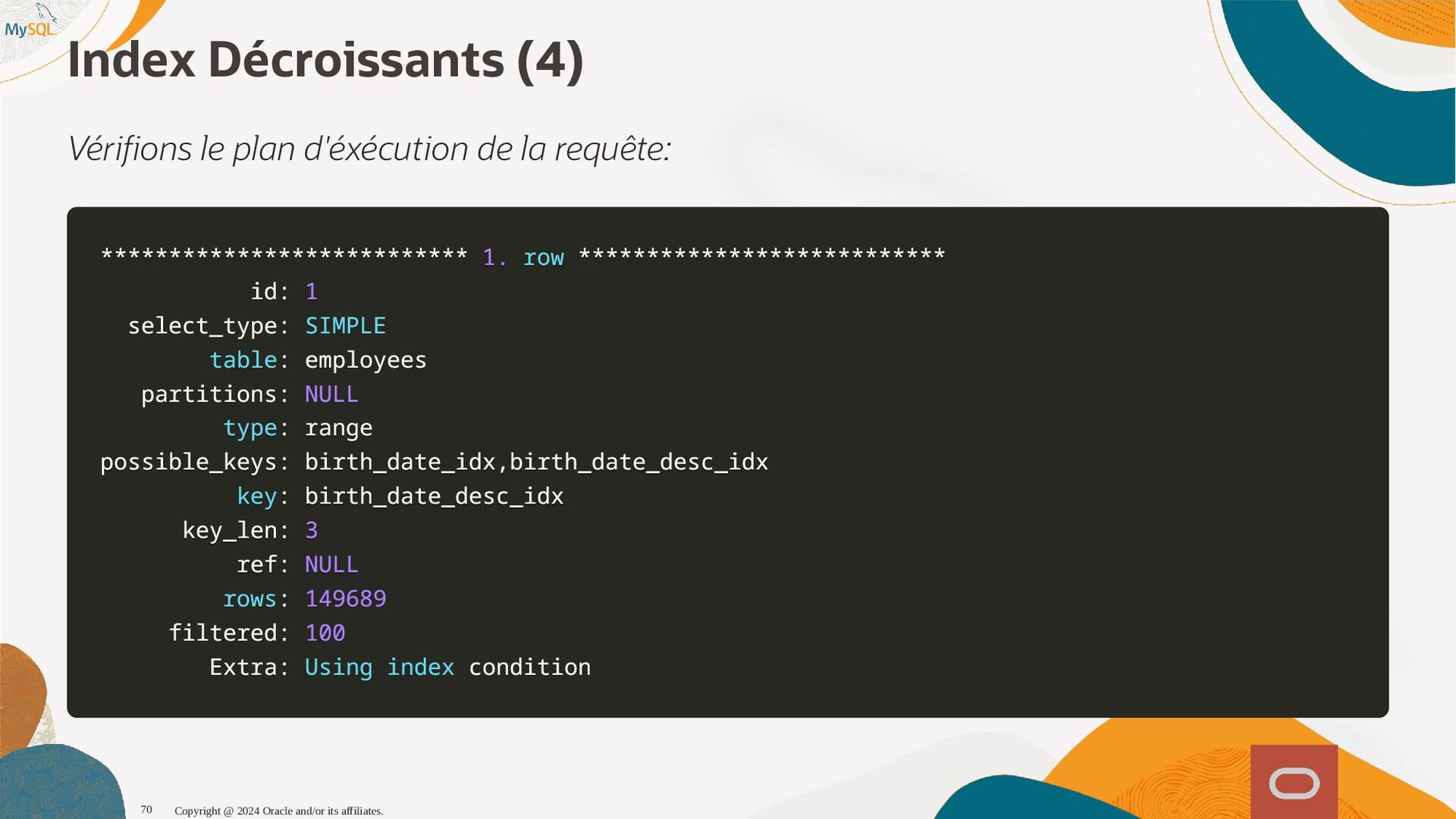
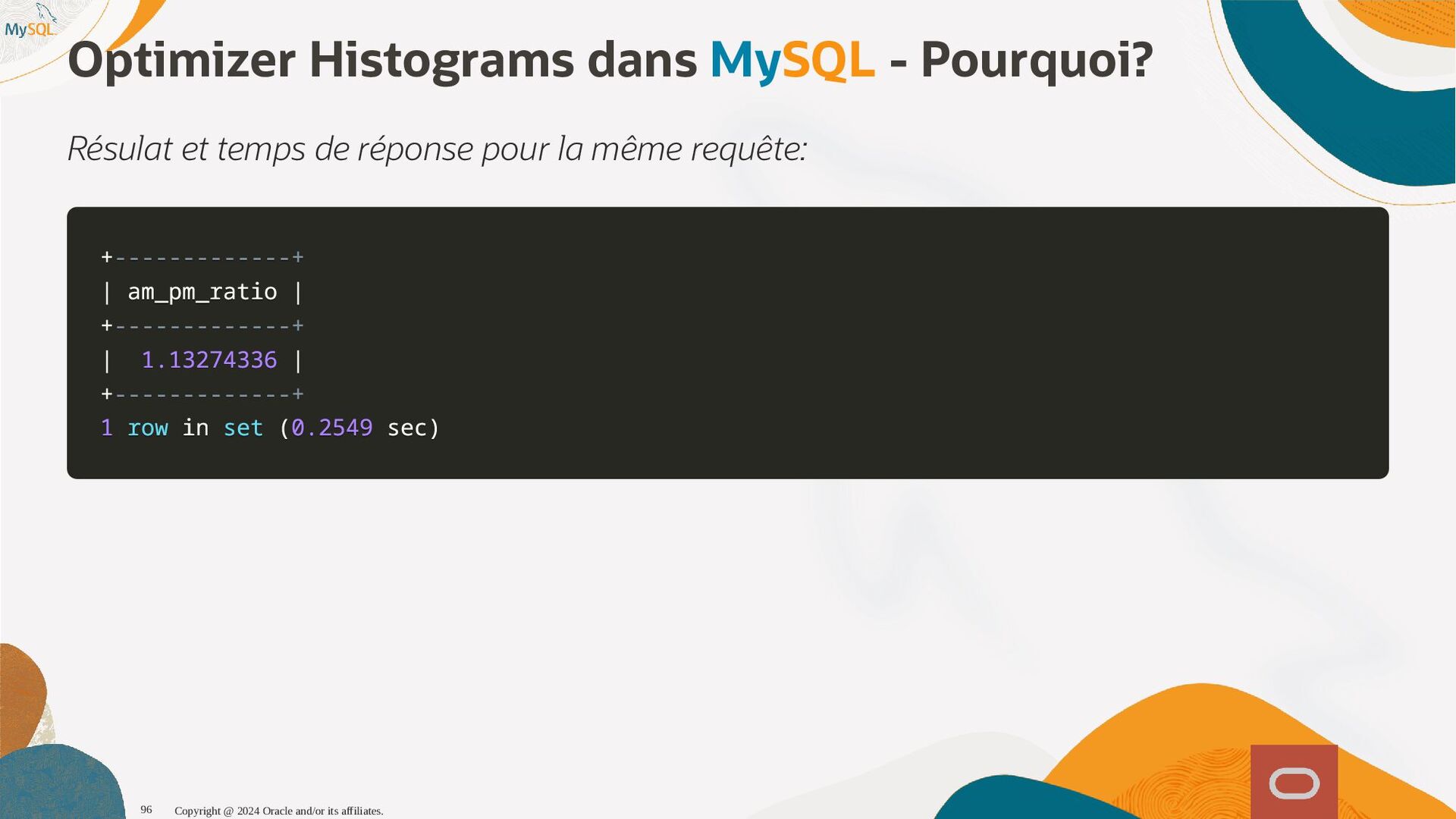
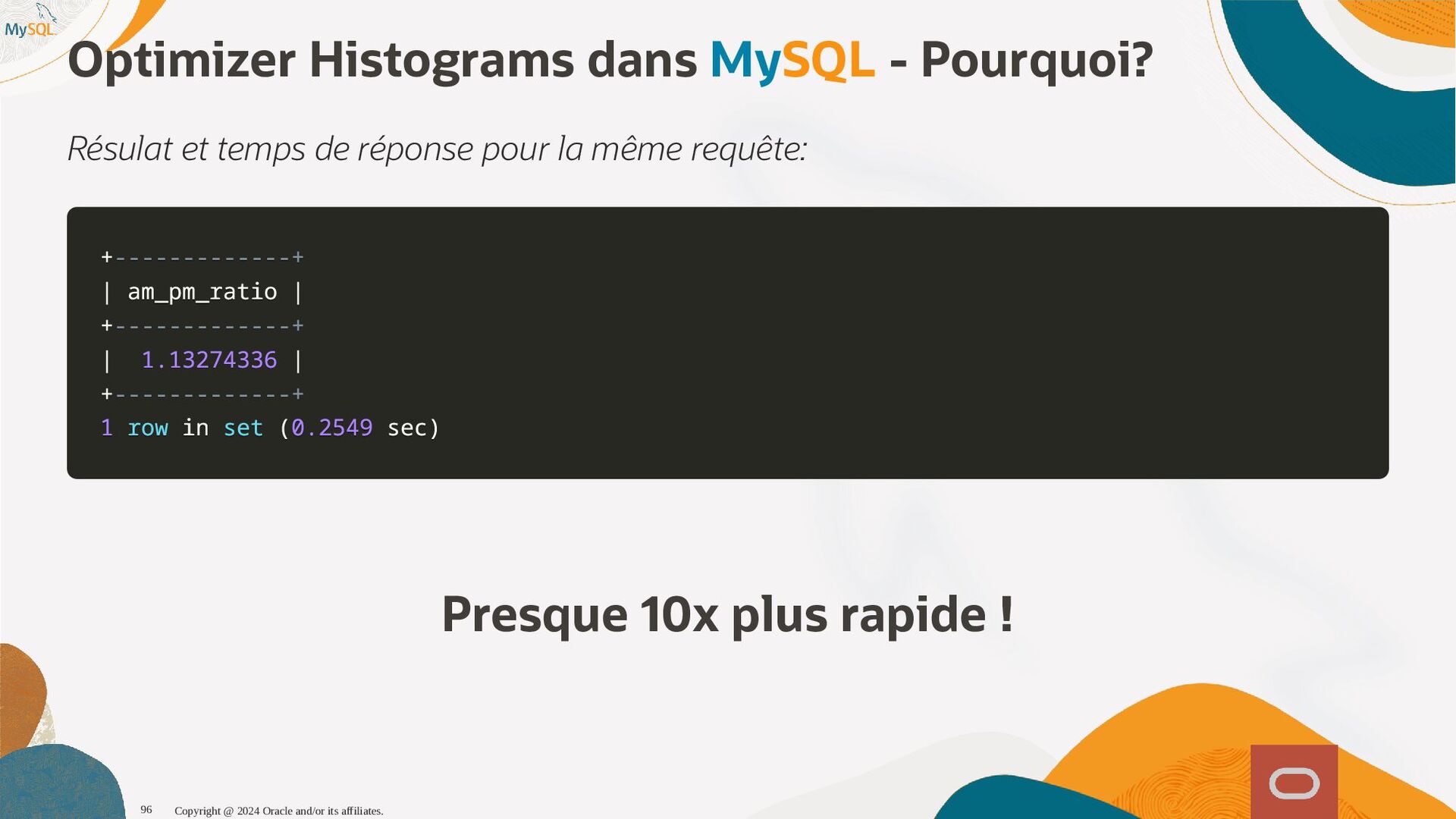
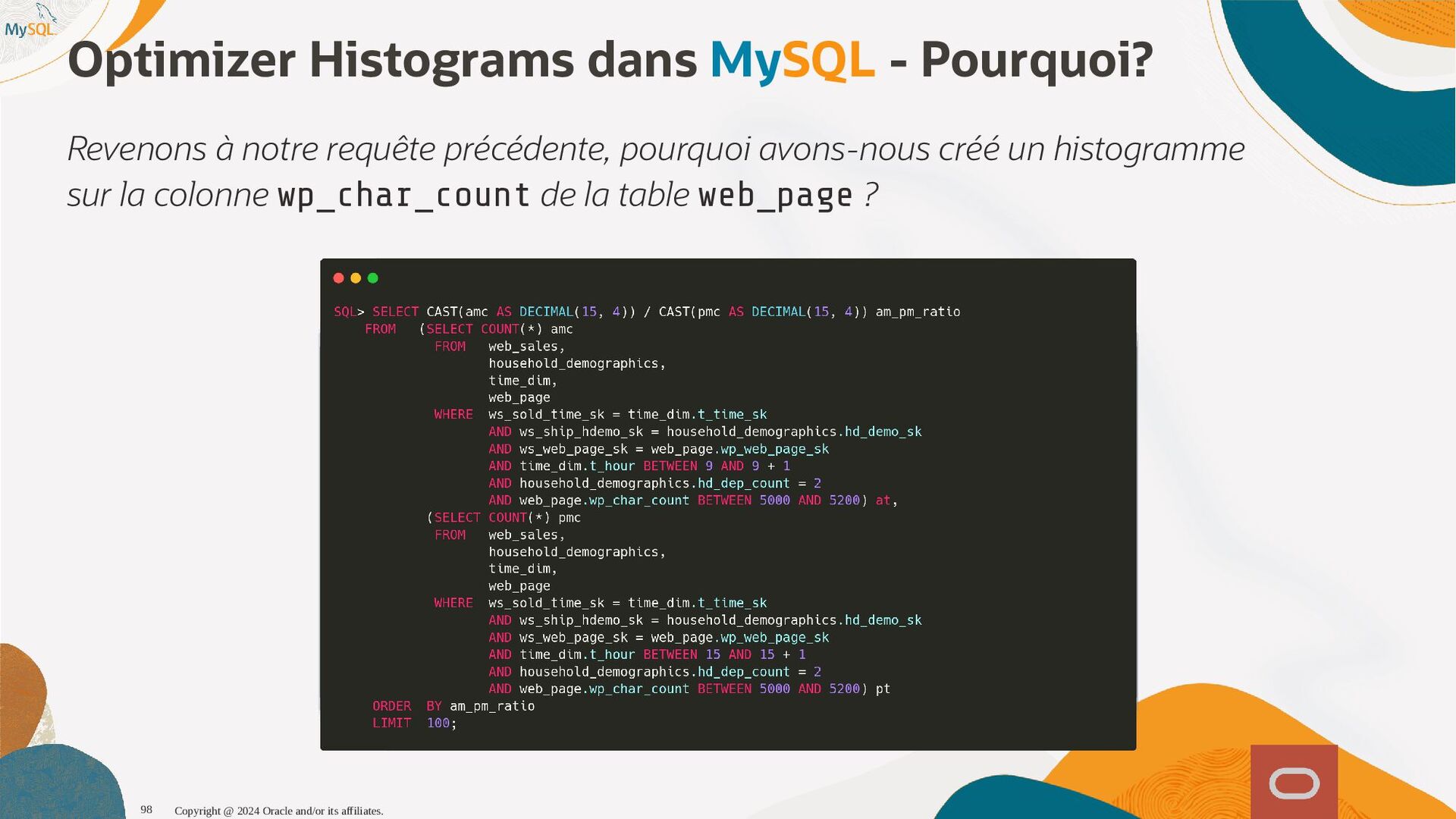
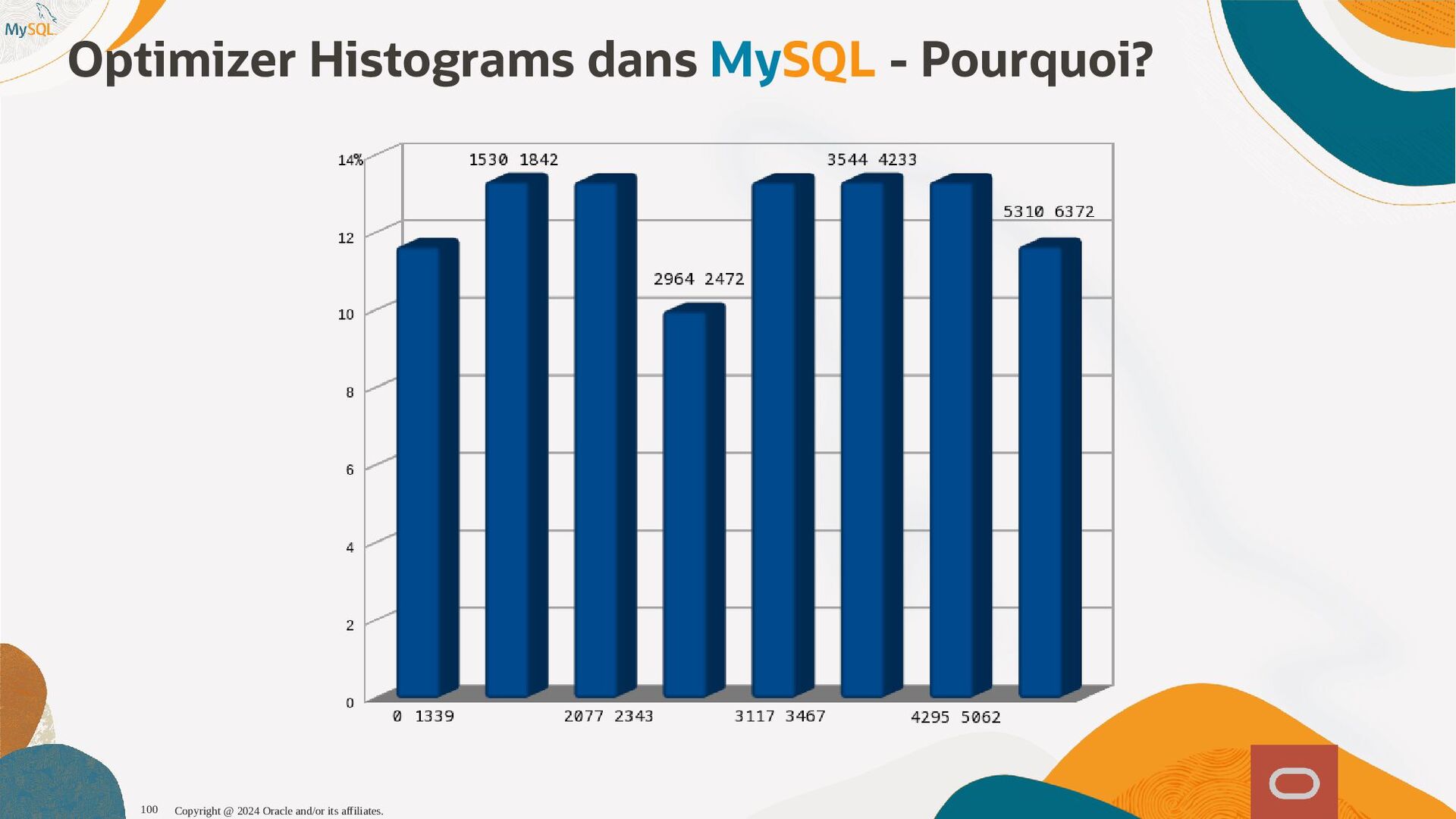
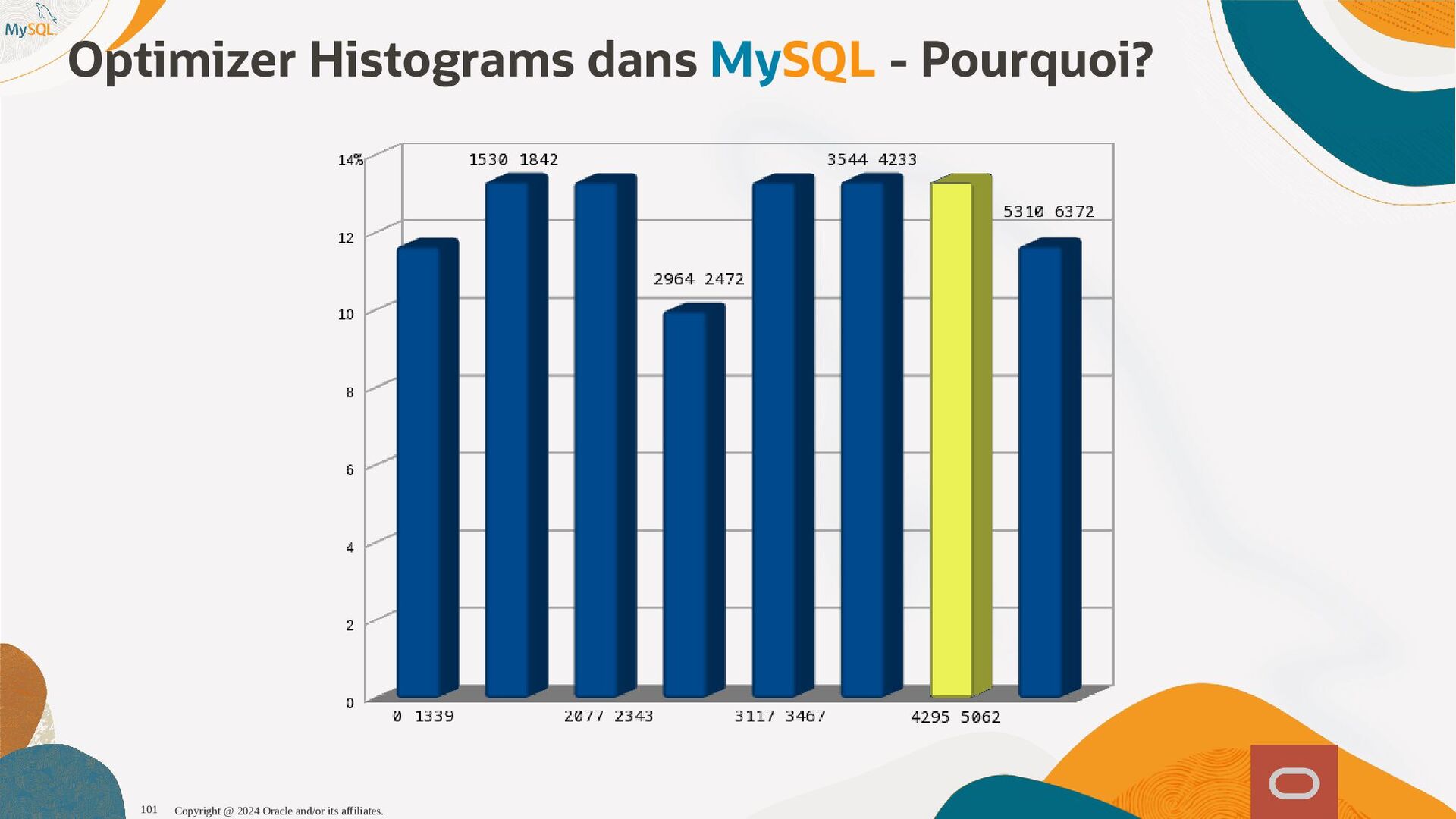
disponibles, l'optimiseur sait maintenant que seul 1,6% (1 enregistrement sur 60) et pousse la table plus tôt dans l'ordre de jointure, produisant ainsi un plan d'exécution qui s'exécute près de dix fois plus vite. SQL SQL> > select select histogram histogram from from information_schema information_schema. .column_statistics column_statistics where where table_name table_name= ='web_page' 'web_page'\G \G . .. .. . HISTOGRAM: { HISTOGRAM: {"buckets" "buckets": : [ [[ [0 0, , 1339 1339, , 0.11666666666666667 0.11666666666666667, , 5 5] ], , [ [1530 1530, , 1842 1842, , 0.25 0.25, , 6 6] ], , [ [2077 2077, , 2343 2343, , 0.38333333333333336 0.38333333333333336, , 6 6] ], , [ [2472 2472, , 2964 2964, , 0.48333333333333334 0.48333333333333334, , 6 6] ], , [ [3117 3117, , 3467 3467, , 0.6166666666666667 0.6166666666666667, , 5 5] ], , [ [3544 3544, , 4233 4233, , 0.75 0.75, , 7 7] ], , [ [4295 4295, , 5062 5062, , 0.8833333333333333 0.8833333333333333, , 6 6] ], , [ [5310 5310, , 6372 6372, , 1.0 1.0, , 6 6] ]] ], , (0.8833333333333333-0.75)*(5062-5000)/(5062-4295) = 0.010777923 Copyright @ 2024 Oracle and/or its affiliates. 102
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
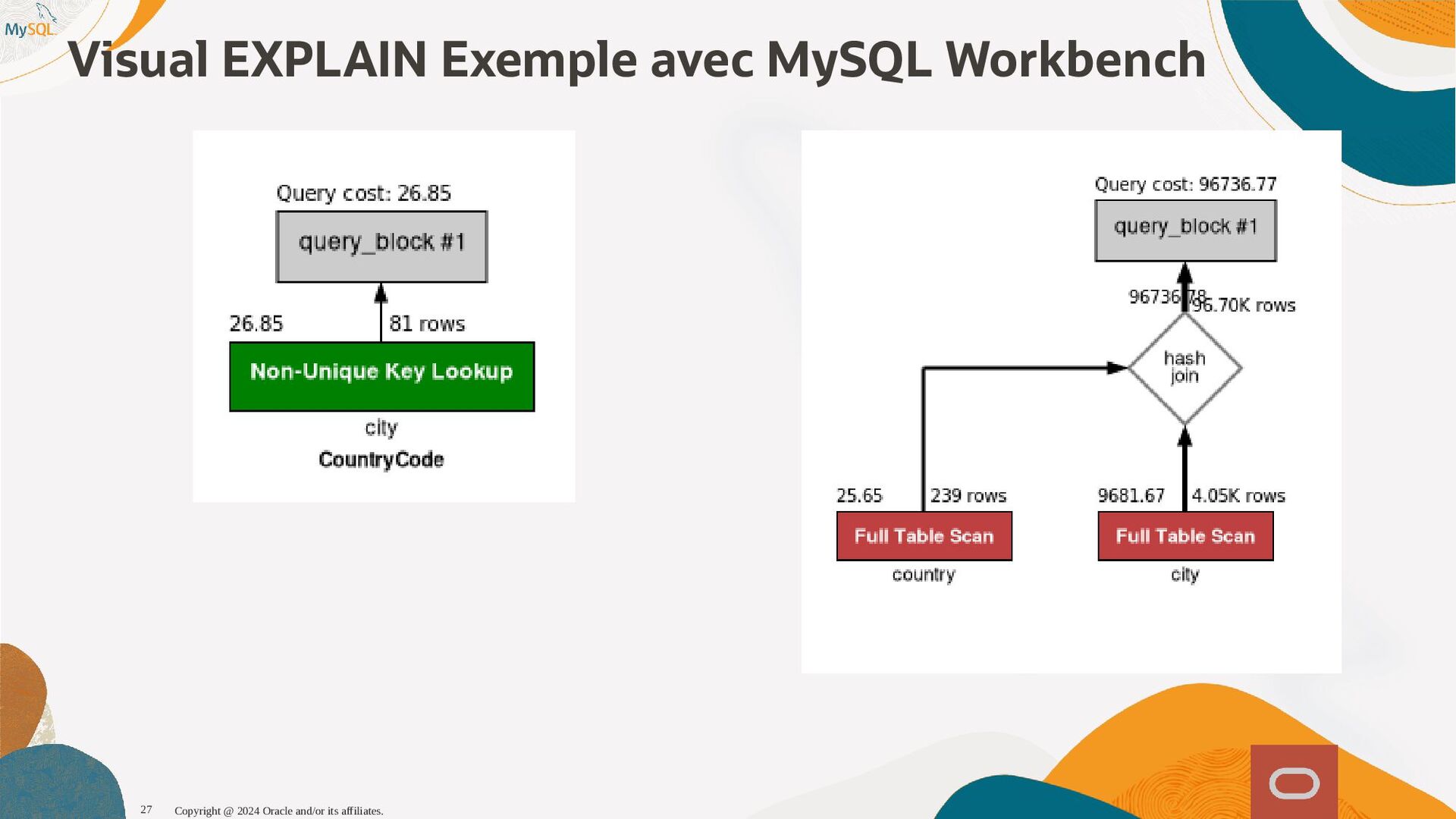{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
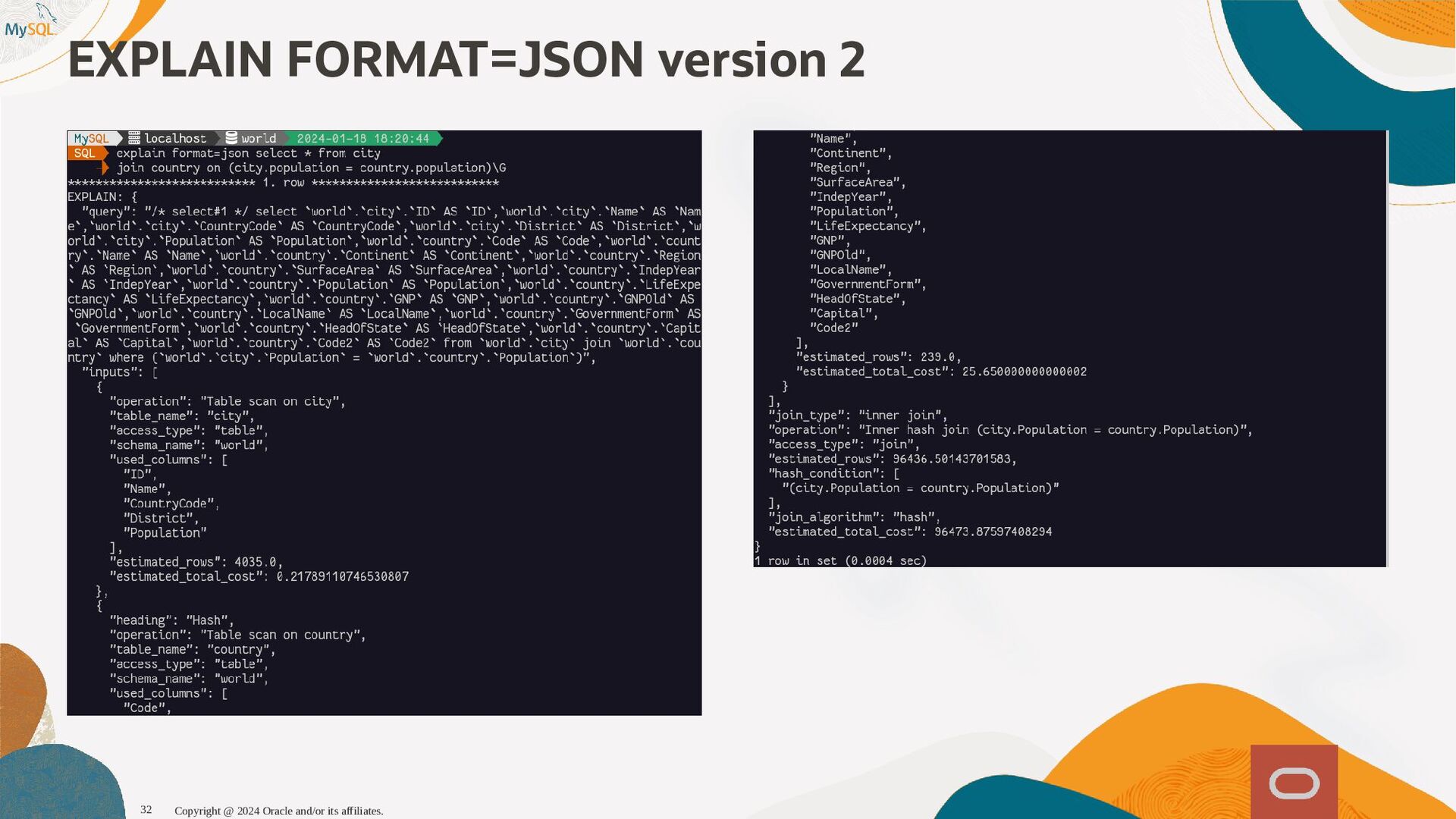{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
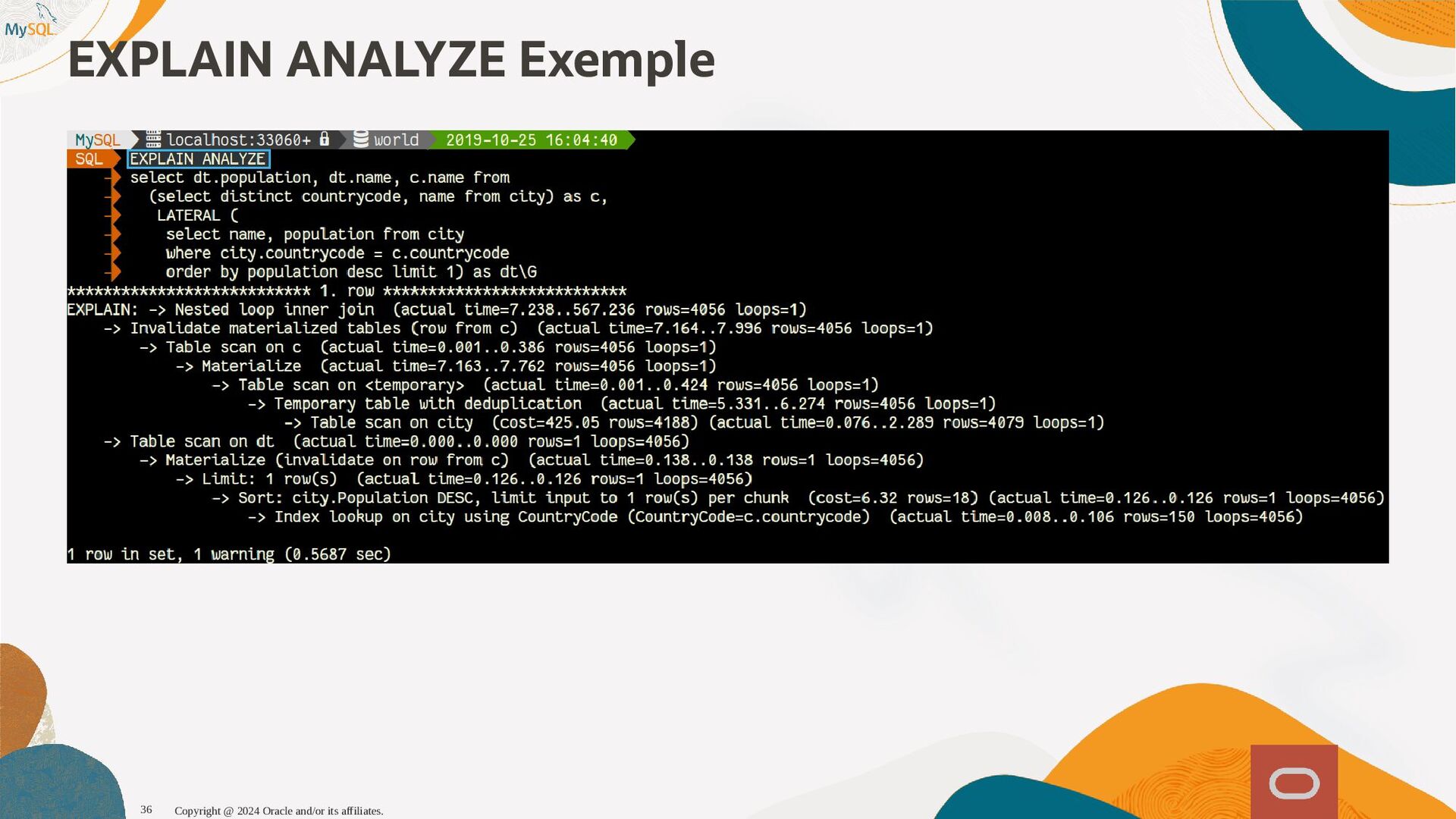{kind=link}
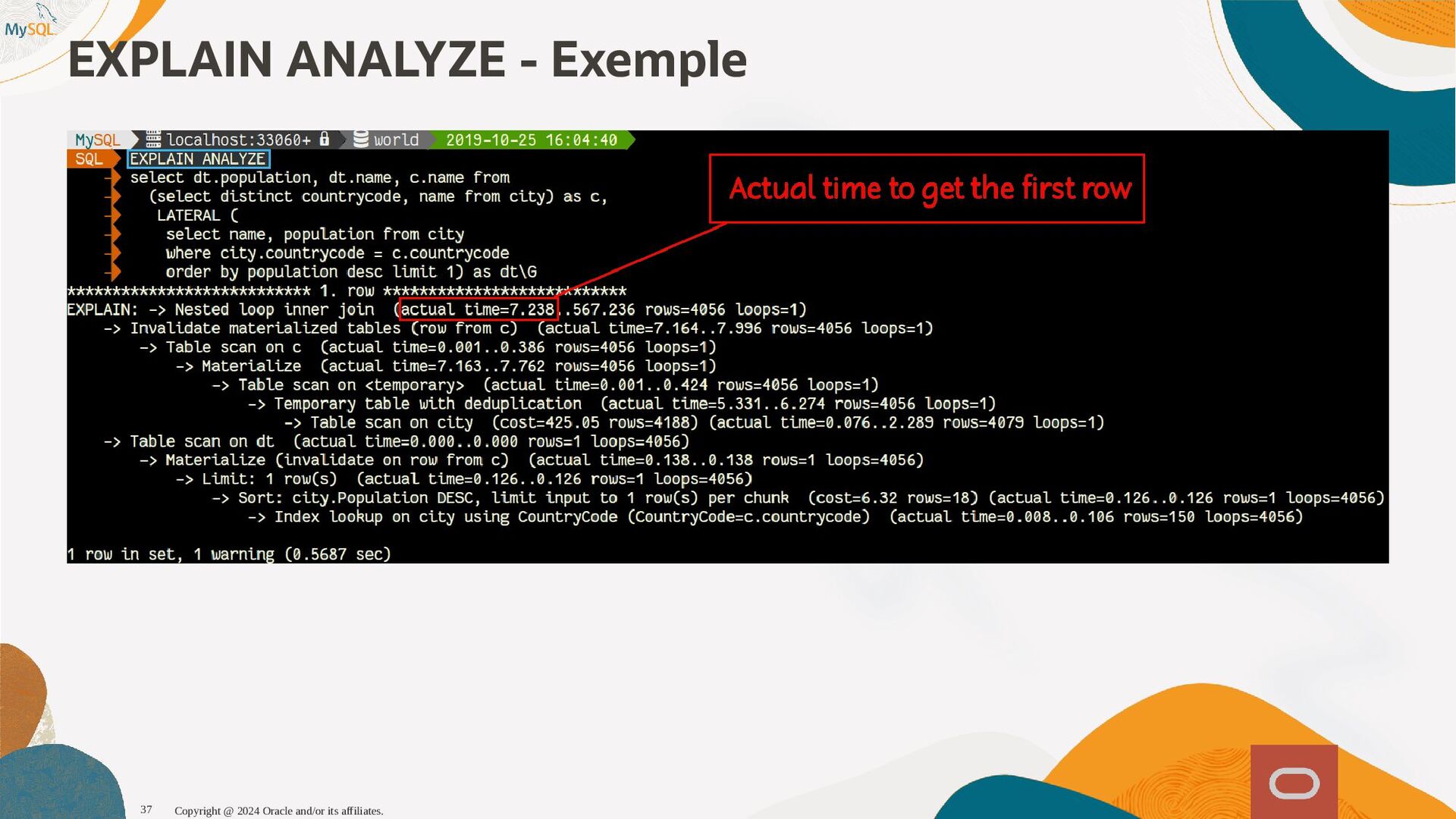{kind=link}
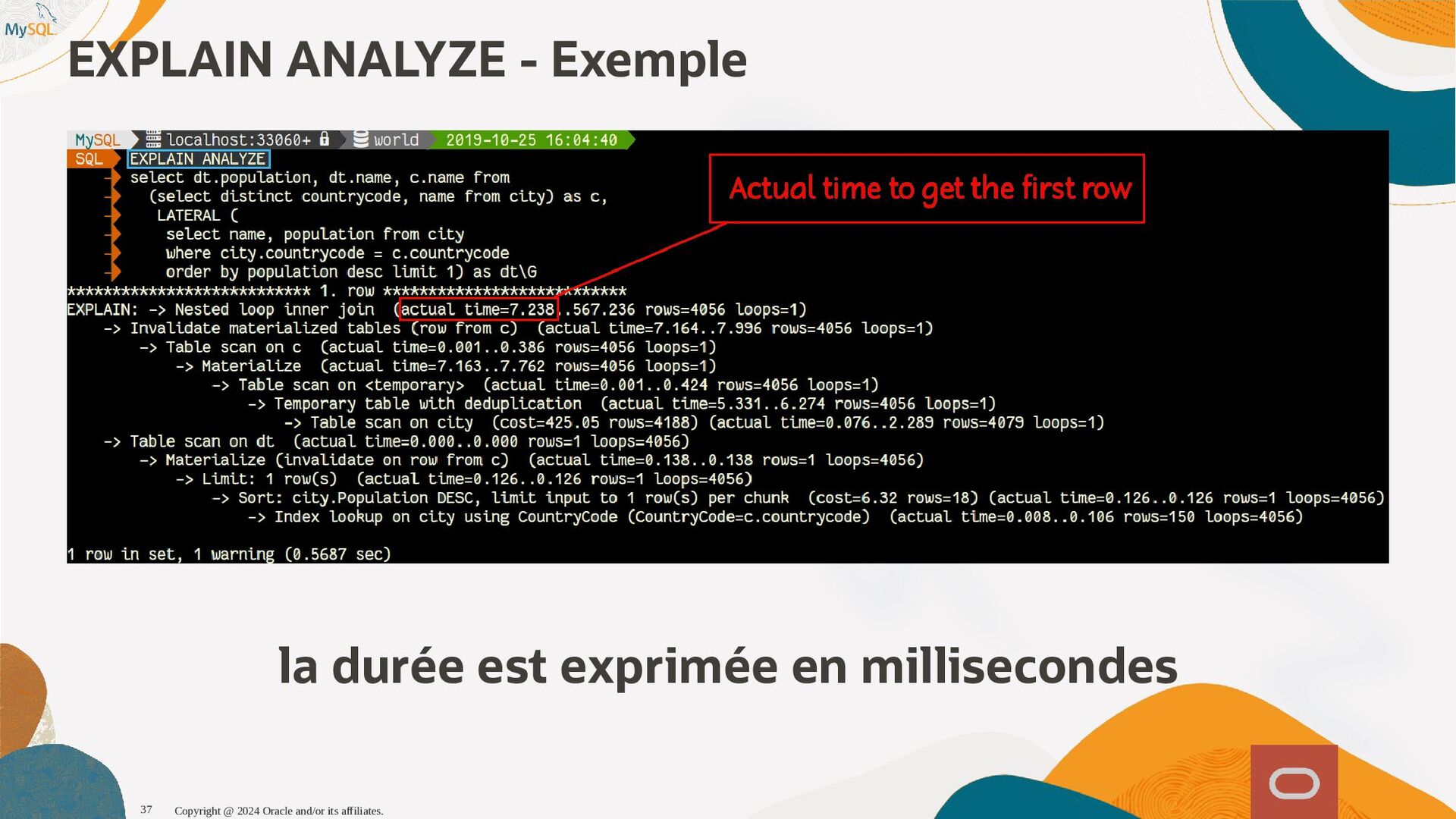{kind=link}
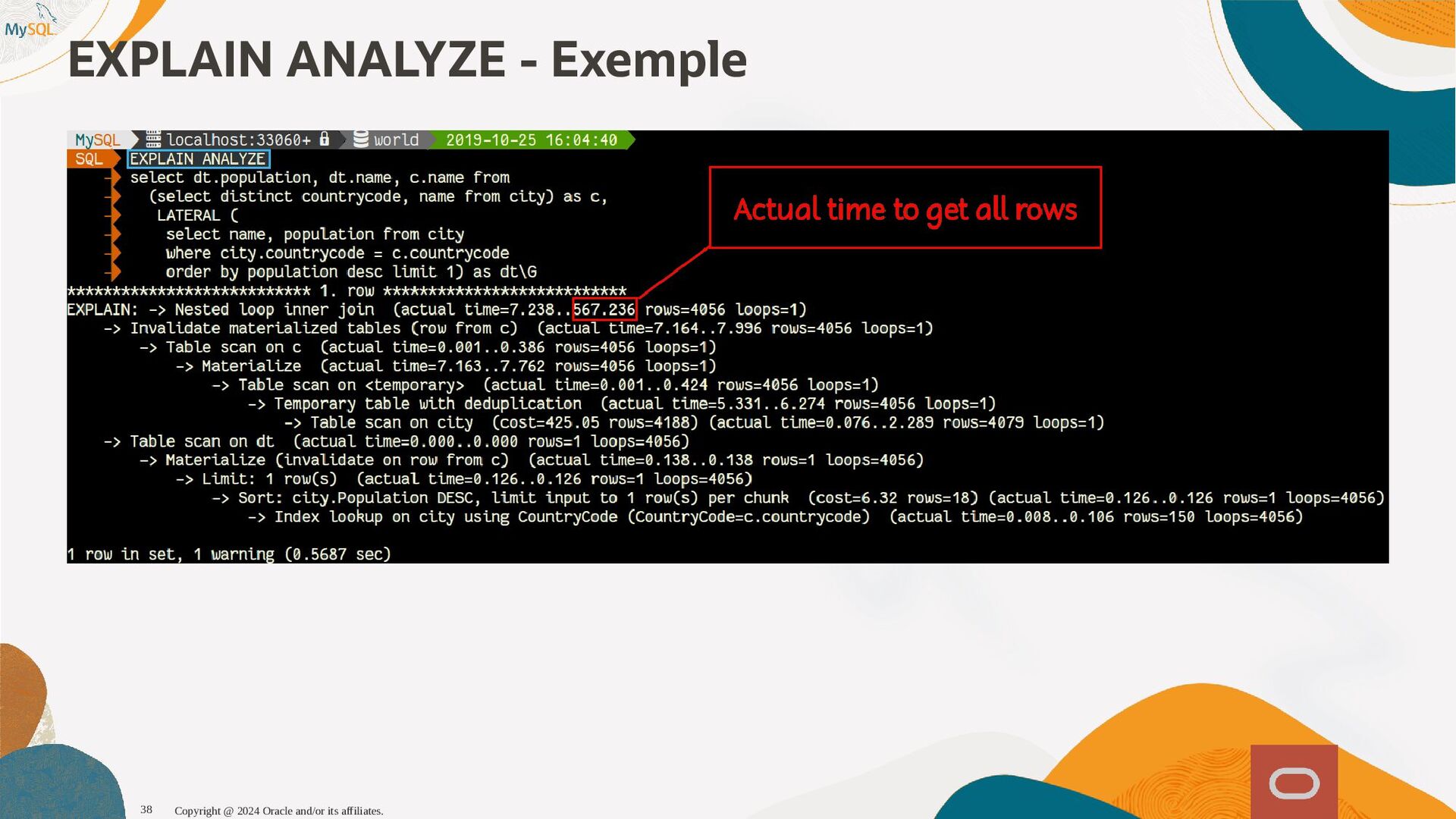{kind=link}
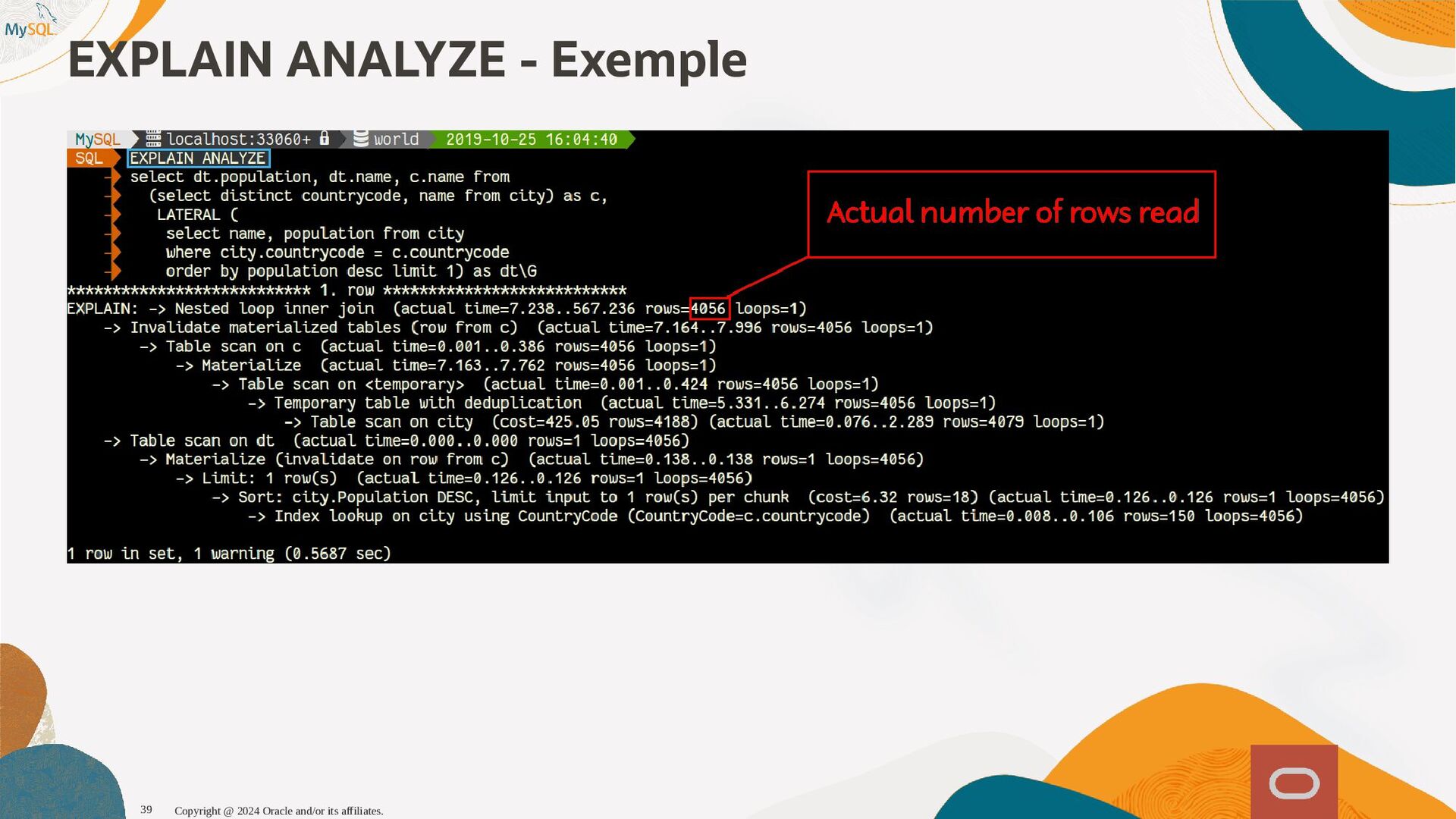{kind=link}
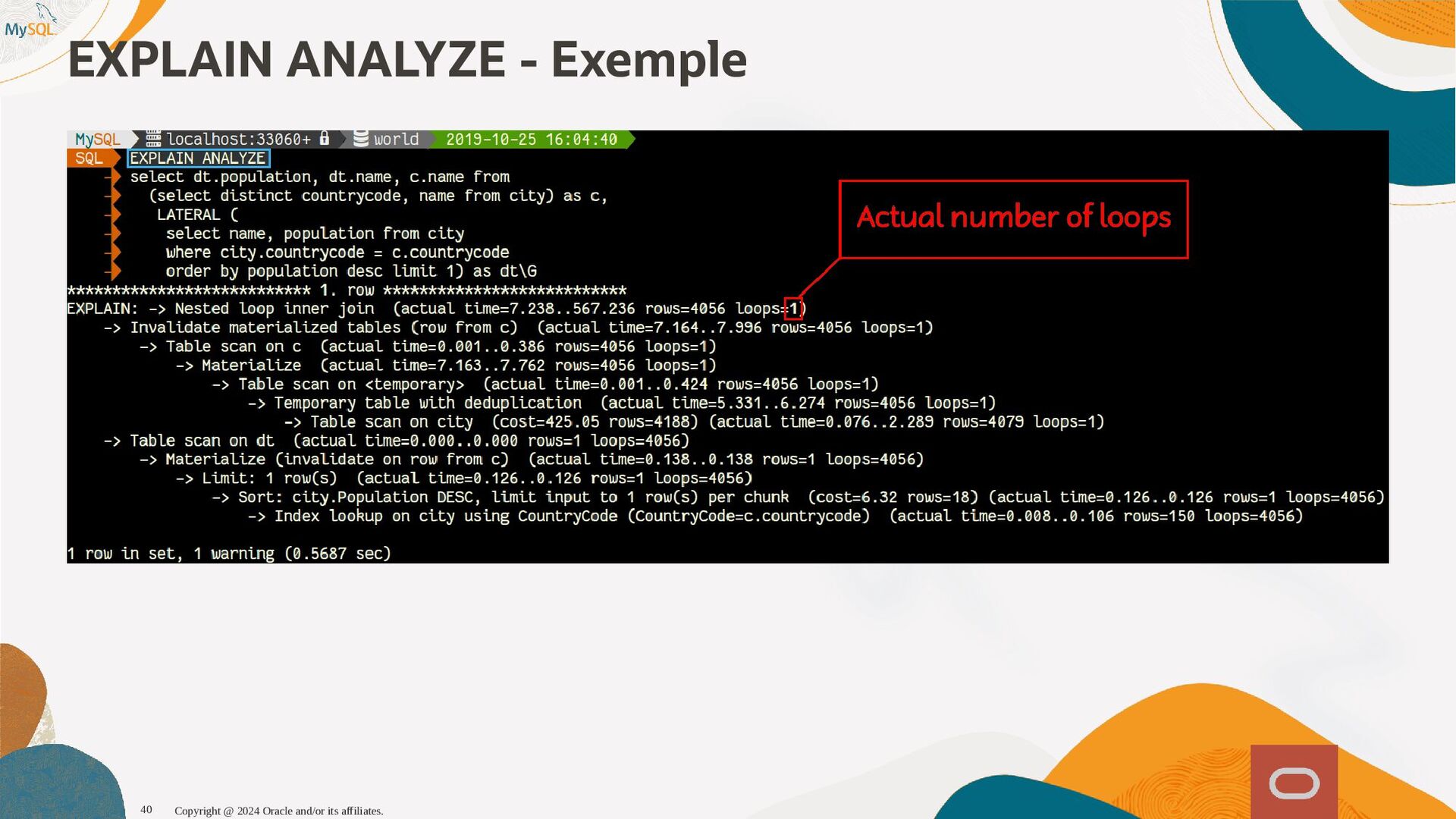{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
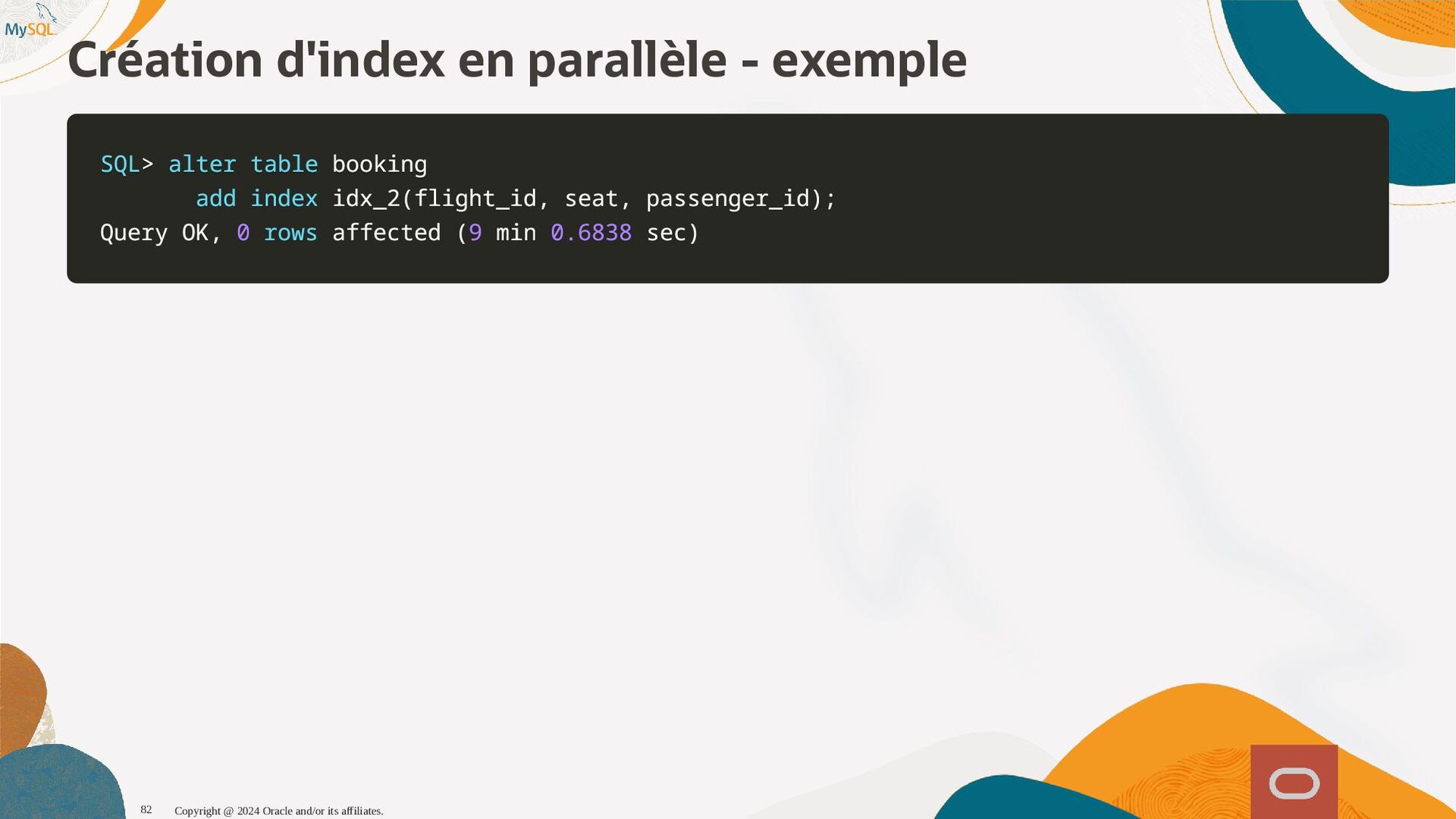
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
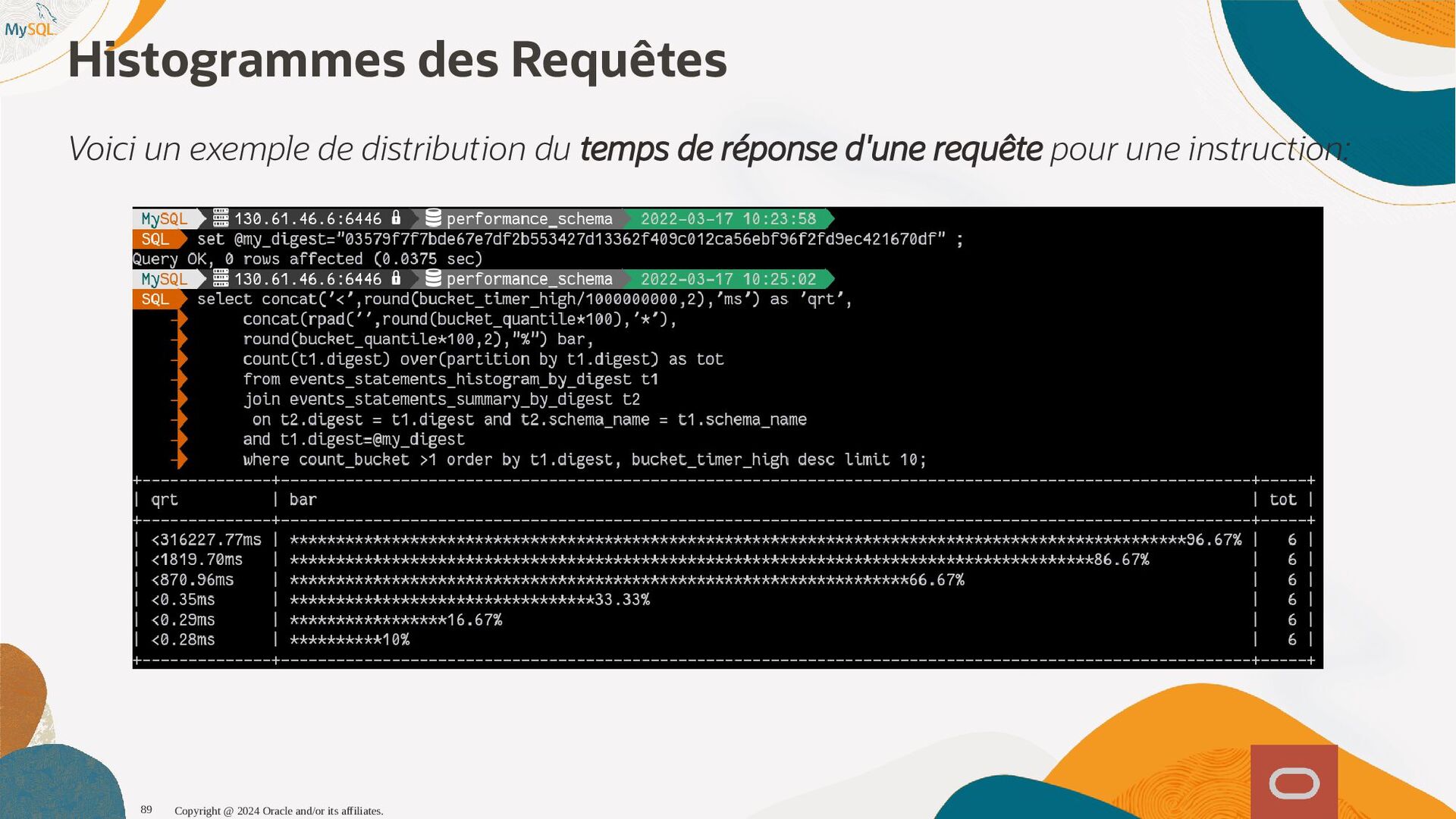
{kind=link}
{kind=link}
{kind=link}
{kind=link}
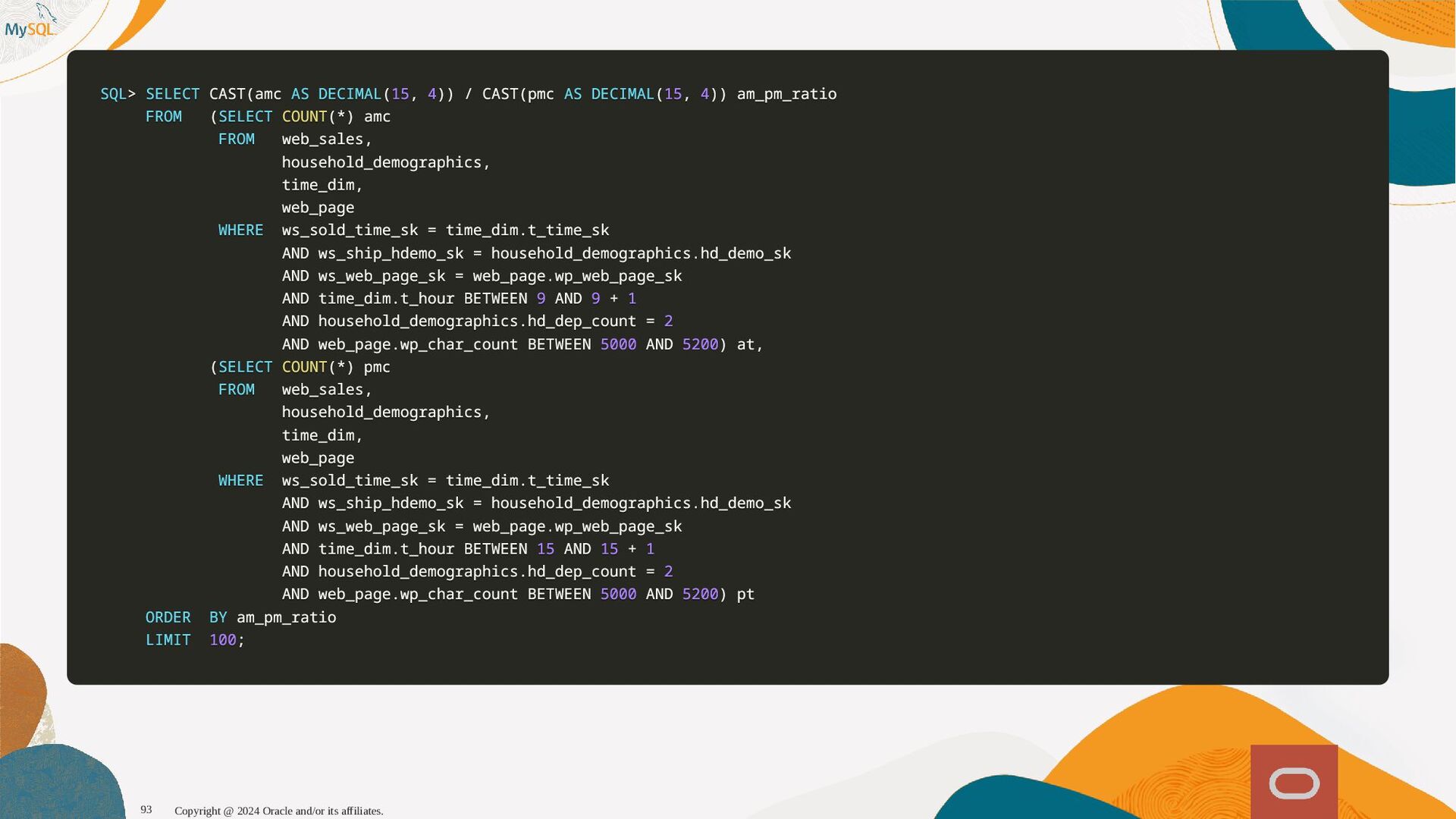
{kind=link}
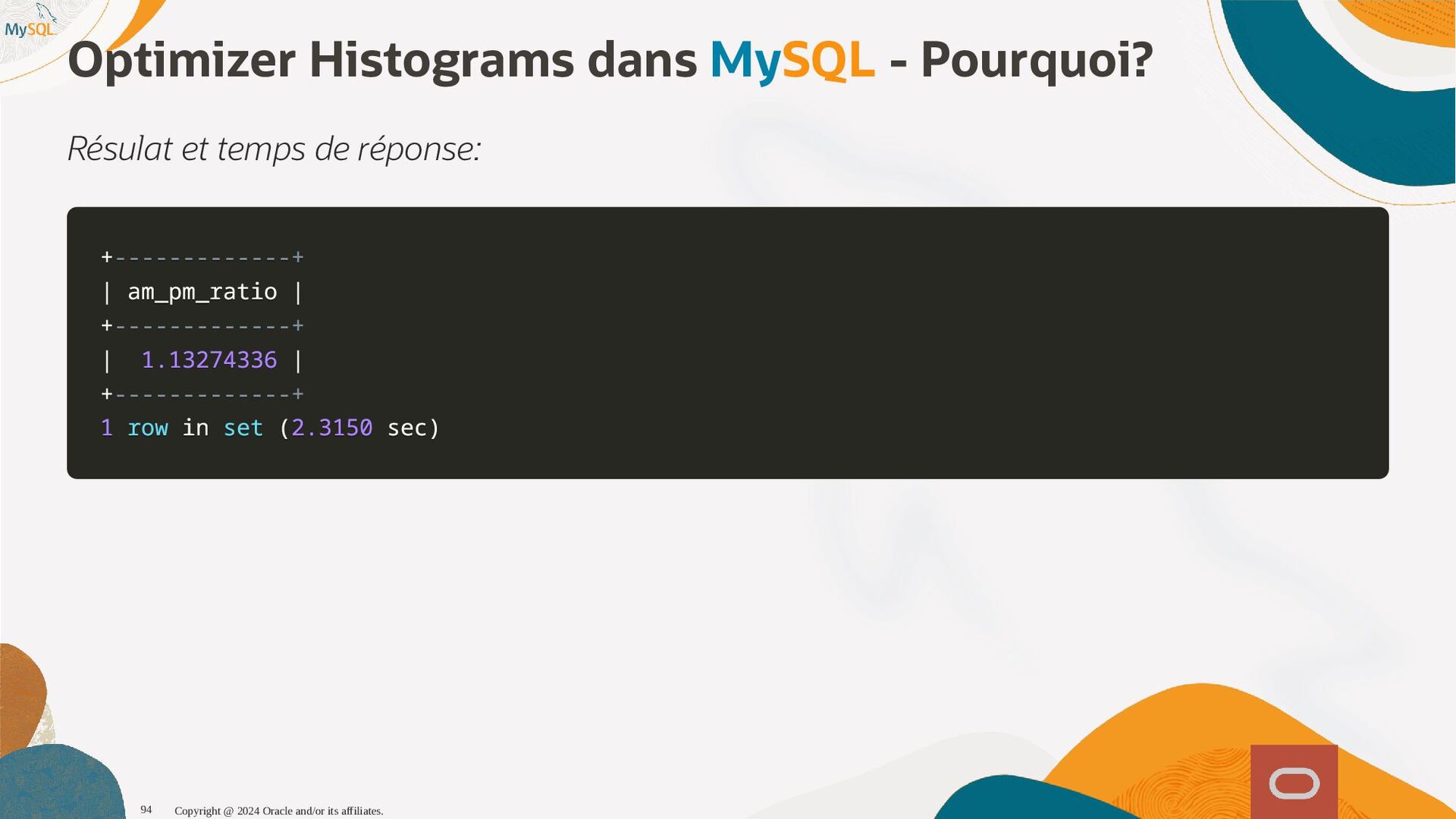
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}