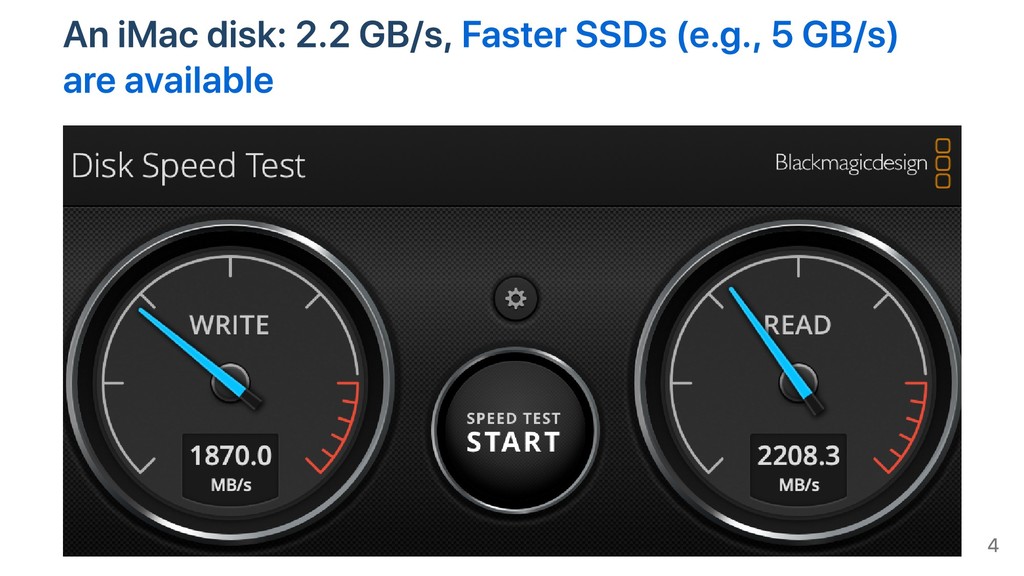
Our disks and networks can load gigabytes of data per second; we feel strongly that our software should follow suit. Thus we wrote what might be the fastest JSON parser in the world, simdjson. It can parse typical JSON files at speeds of over 2 GB/s on single commodity Intel core with full validation; it is several times faster than conventional parsers.
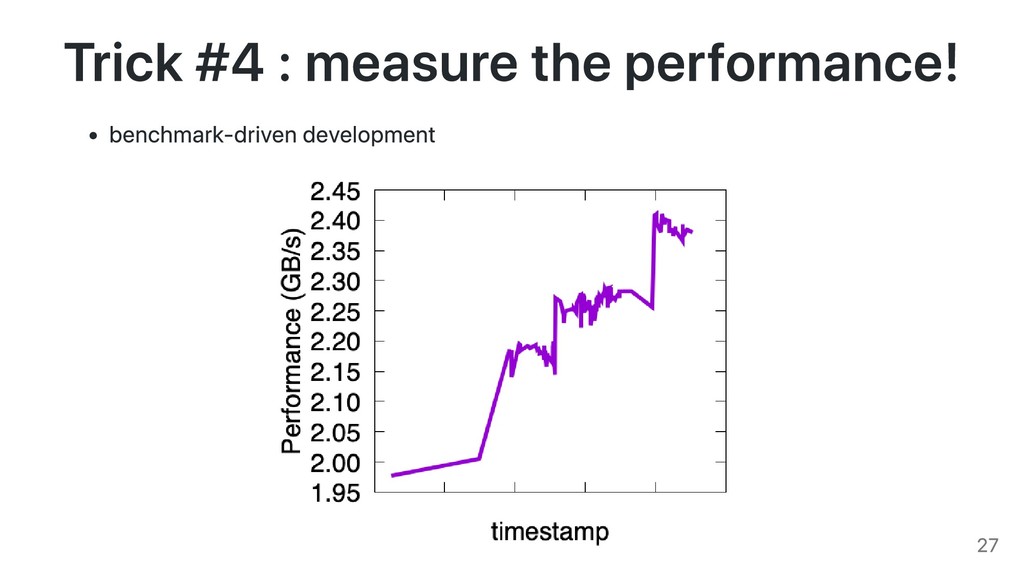
How did we go so fast? We started with the insight that we should make full use of the SIMD instructions available on commodity processors. These instructions are everywhere, from the ARM chip in your smartphone all to way to server processors. SIMD instructions work on wide registers (e.g., spanning 32 bytes): they are faster because they process more data using fewer instructions. To our knowledge, nobody had ever attempted to produce a full parser for something as complex as JSON by relying primarily on SIMD instructions. And many people were skeptical that a full parser could be done fruitfully with SIMD instructions. We had to develop interesting new strategies that are generally applicable. In the end, we learned several lessons. Maybe one of the most important lesson is the importance of a nearly obsessive focus on performance metrics. We constantly measure the impact of the choices we make.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
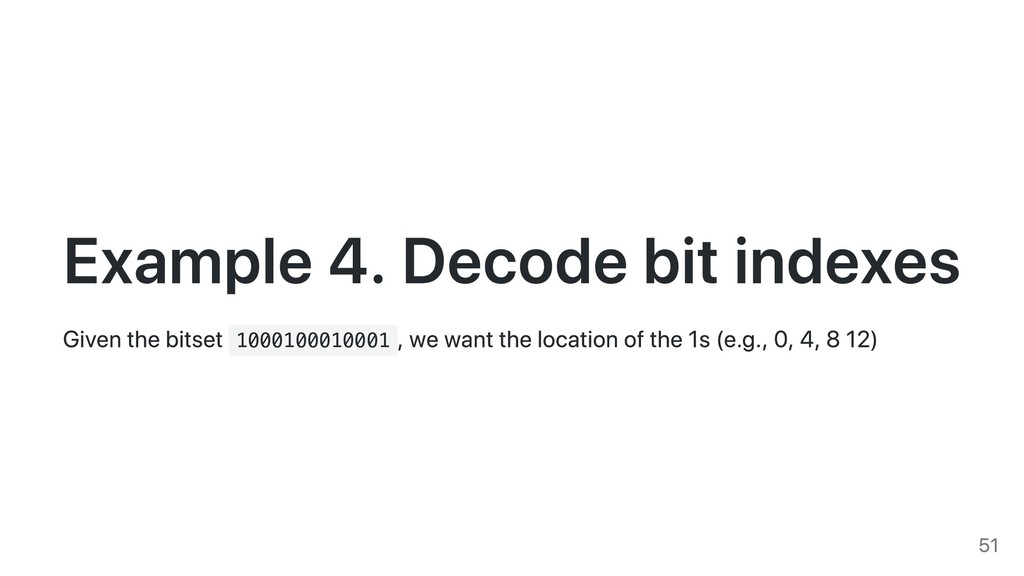
![while (word != 0) { result[i] = trailingzeroes(word); word =](https://files.speakerdeck.com/presentations/7ec58c7e06d141209db0e079ce5ca4f4/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}