Obtenir de bonnes performances en ingénierie des données est un défi de taille. Notre objectif est de traiter des milliards d'enregistrement par seconde par coeur. Nous présenterons nos travaux sur la conception d'index plus rapides et utilisant peu de mémoire. Certains de nos travaux incluent les index Roaring faisant partie de systèmes tels que Spark, Hive, Druid, Netflix Atlas, LinkedIn Pinot, Kylin (eBay), Microsoft Visual Studio Team Services, et les index EWAH faisant partie de Git (GitHub). Nous discuterons l'utilisation des algorithmes conçus pour les instructions single-instruction-multiple-data (SIMD) disponibles sur tous nos processeurs courants.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
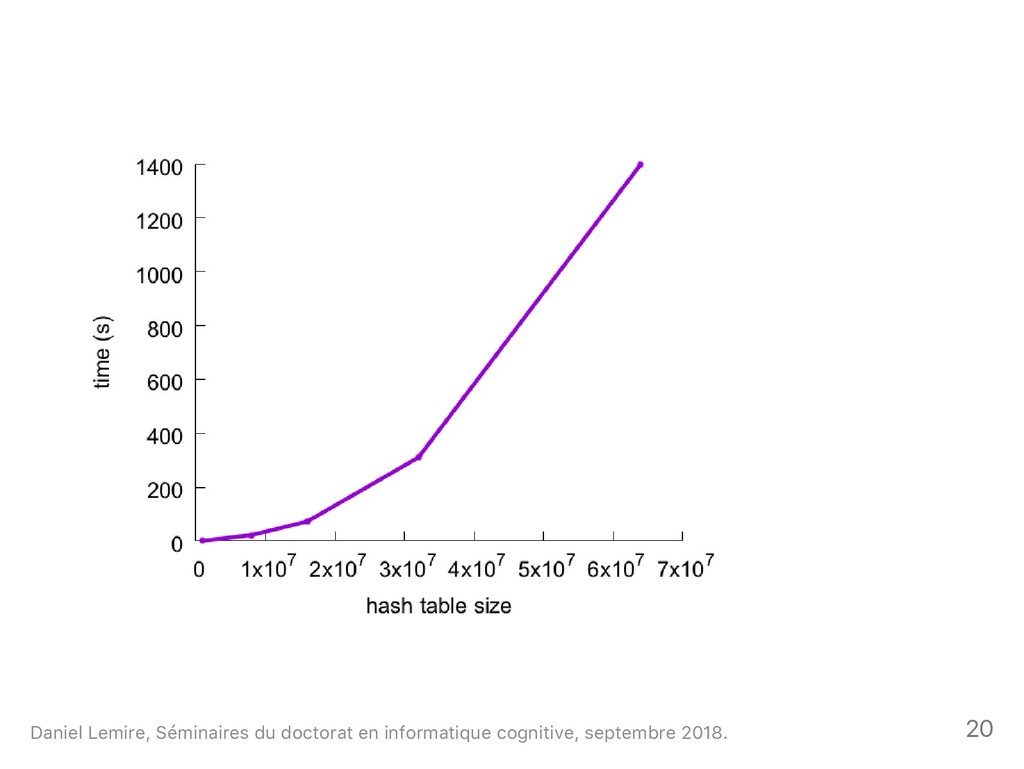{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
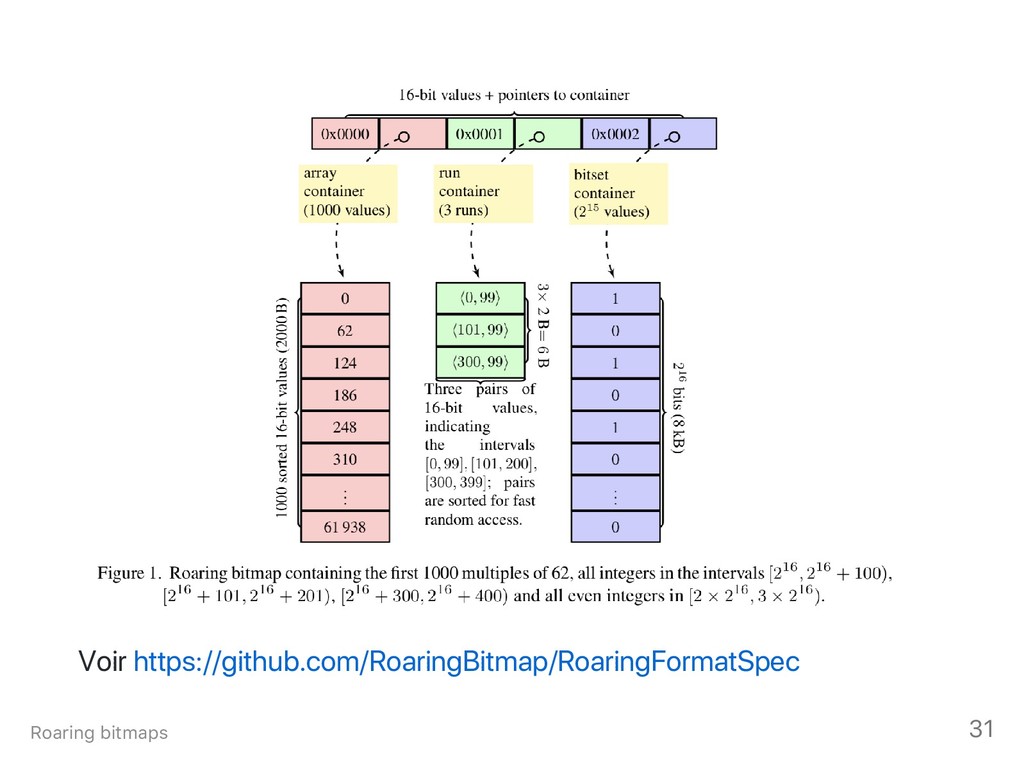{kind=link}
{kind=link}
{kind=link}
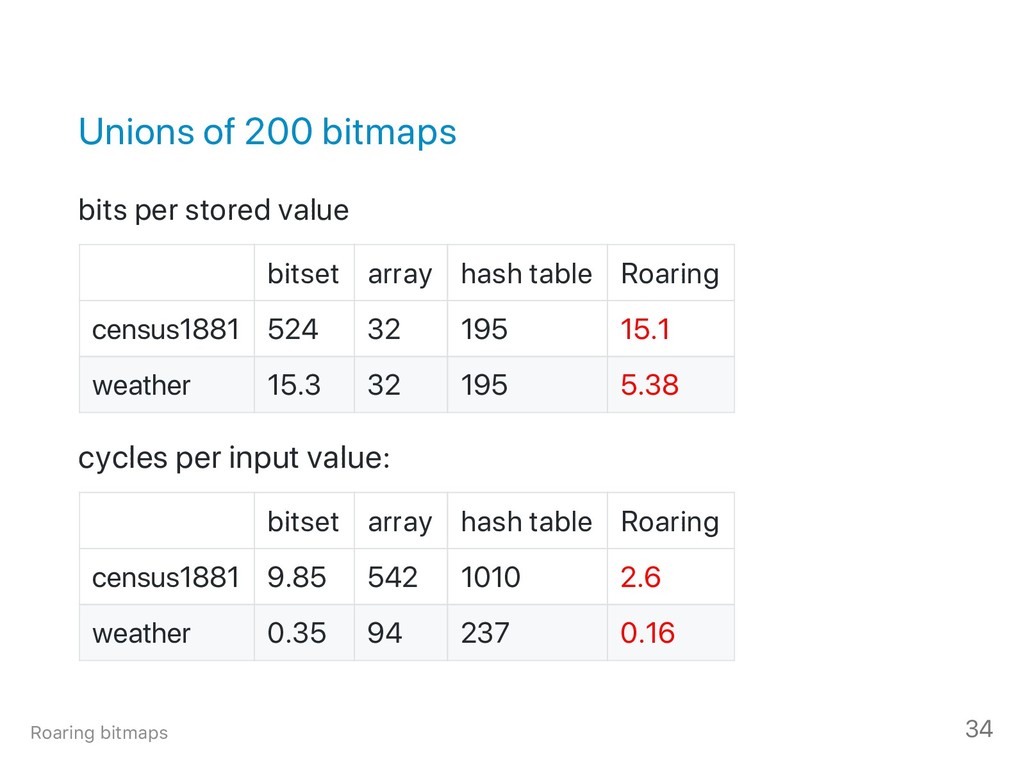{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}