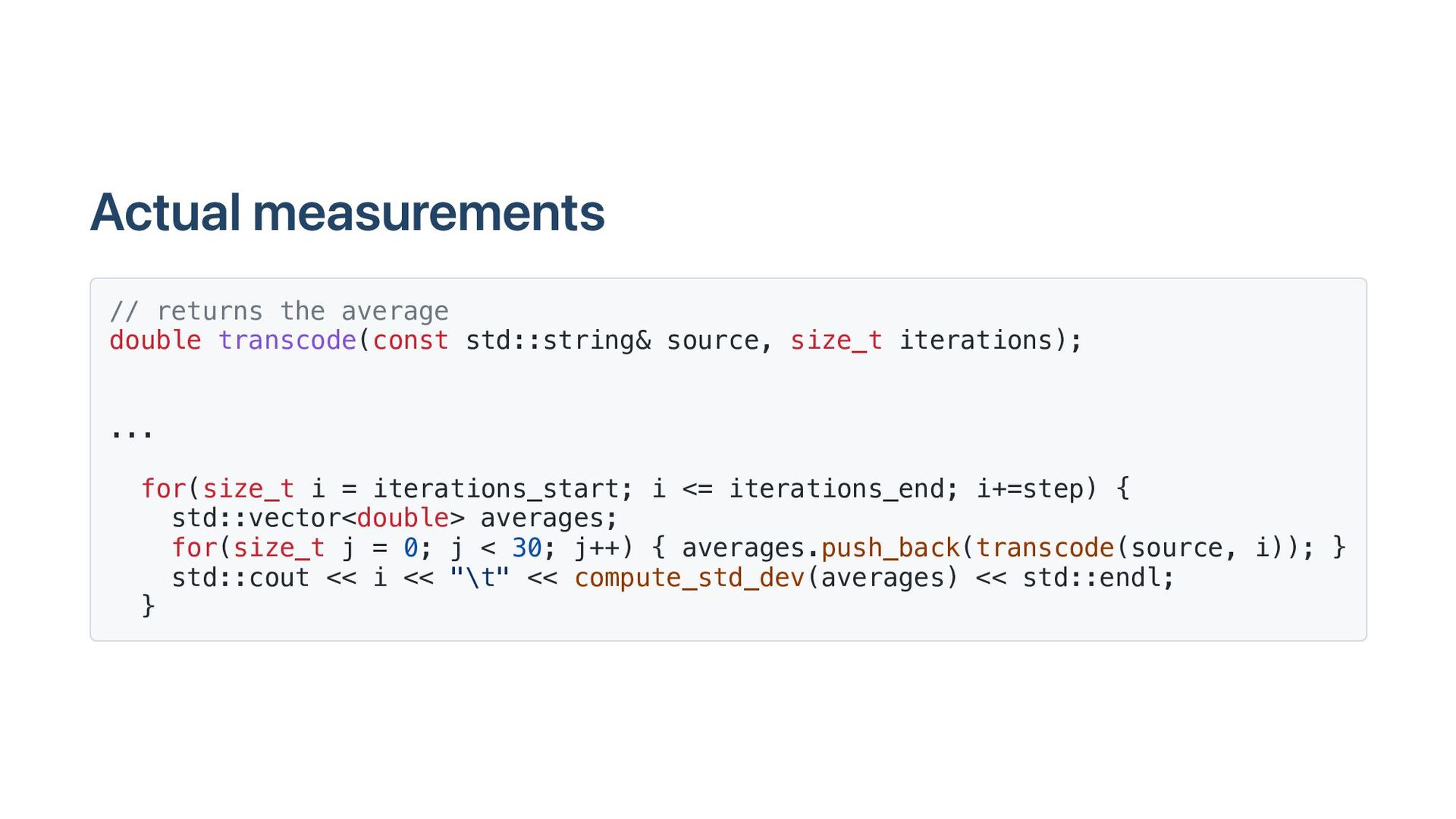
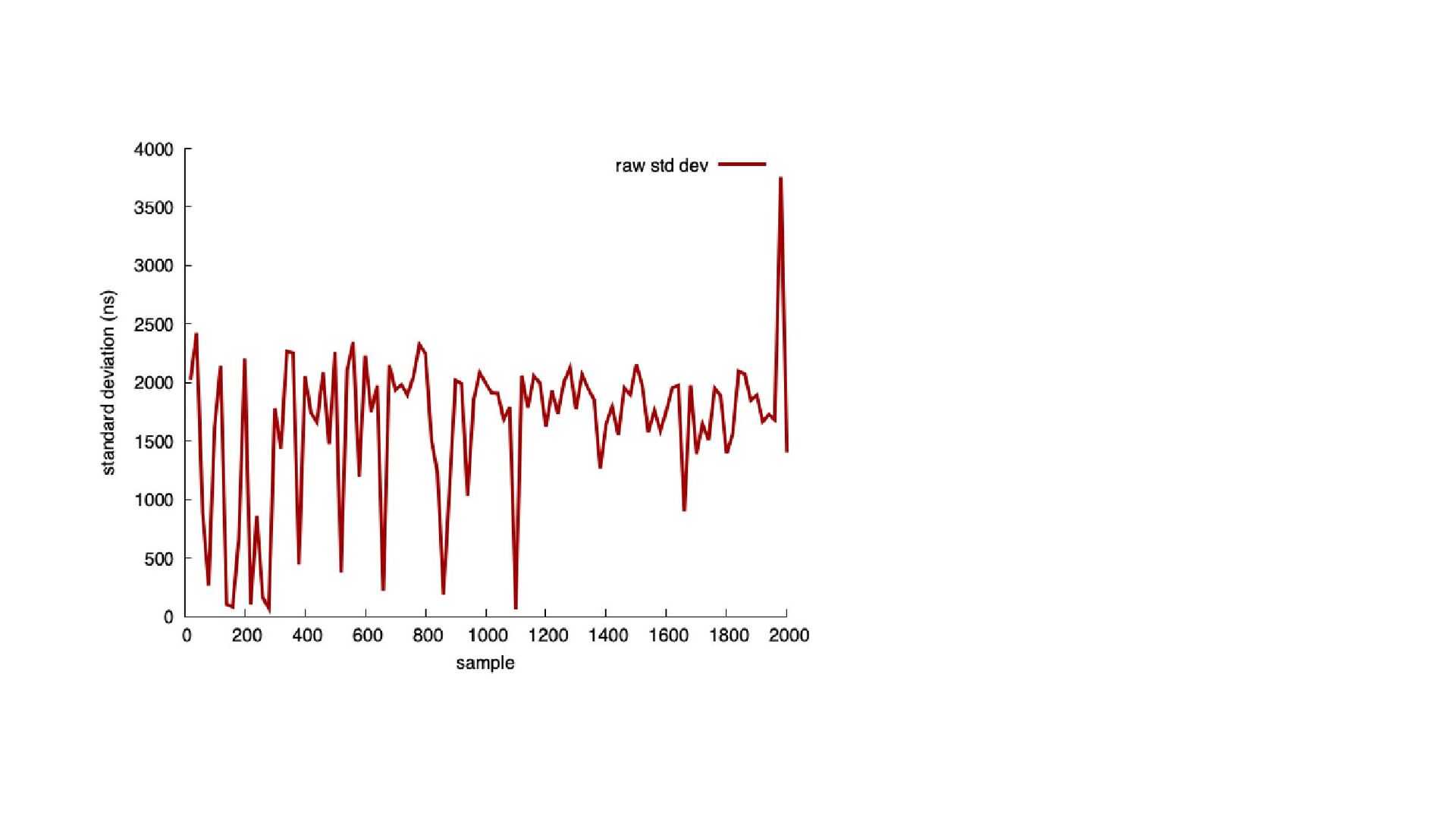
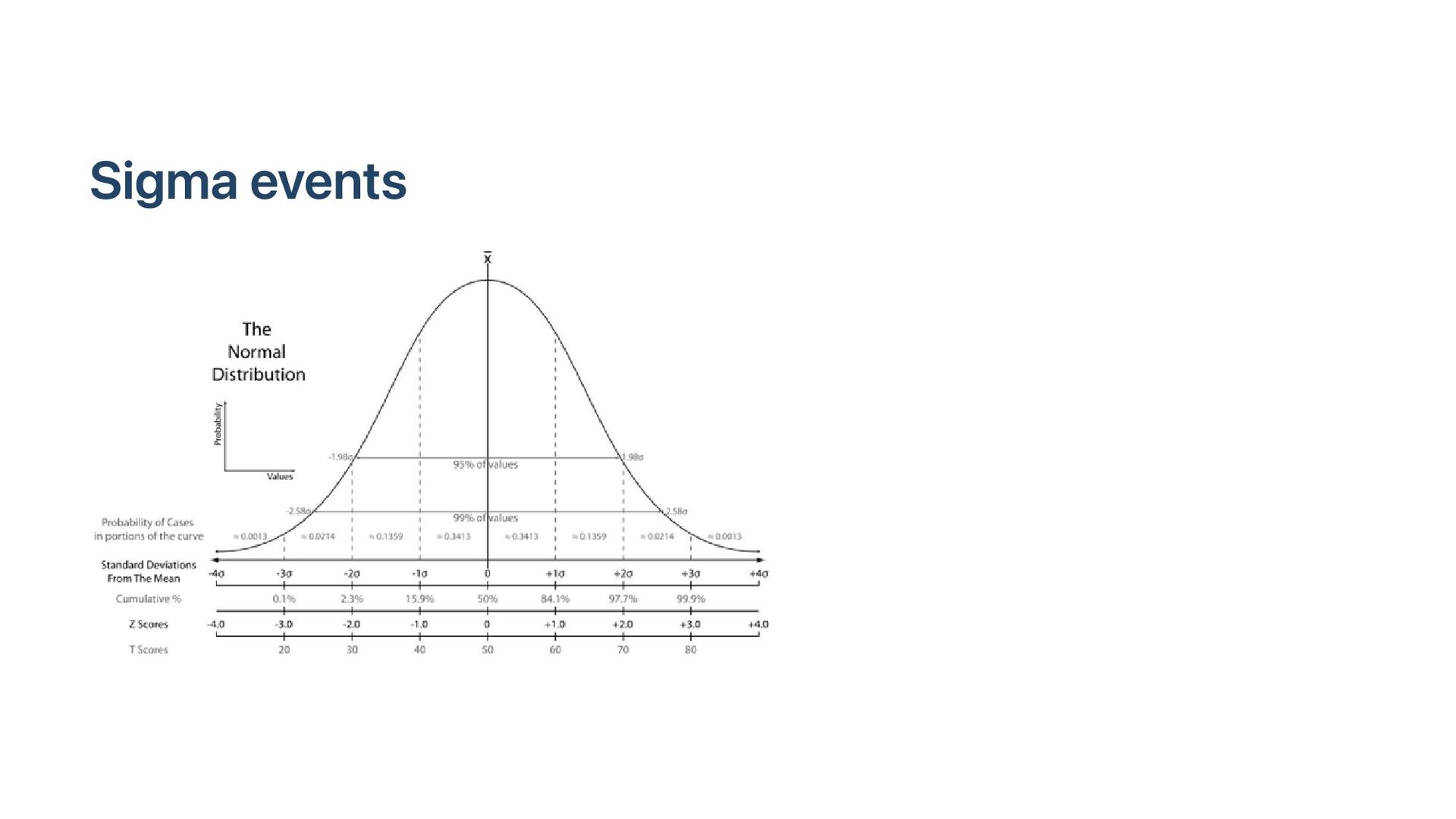
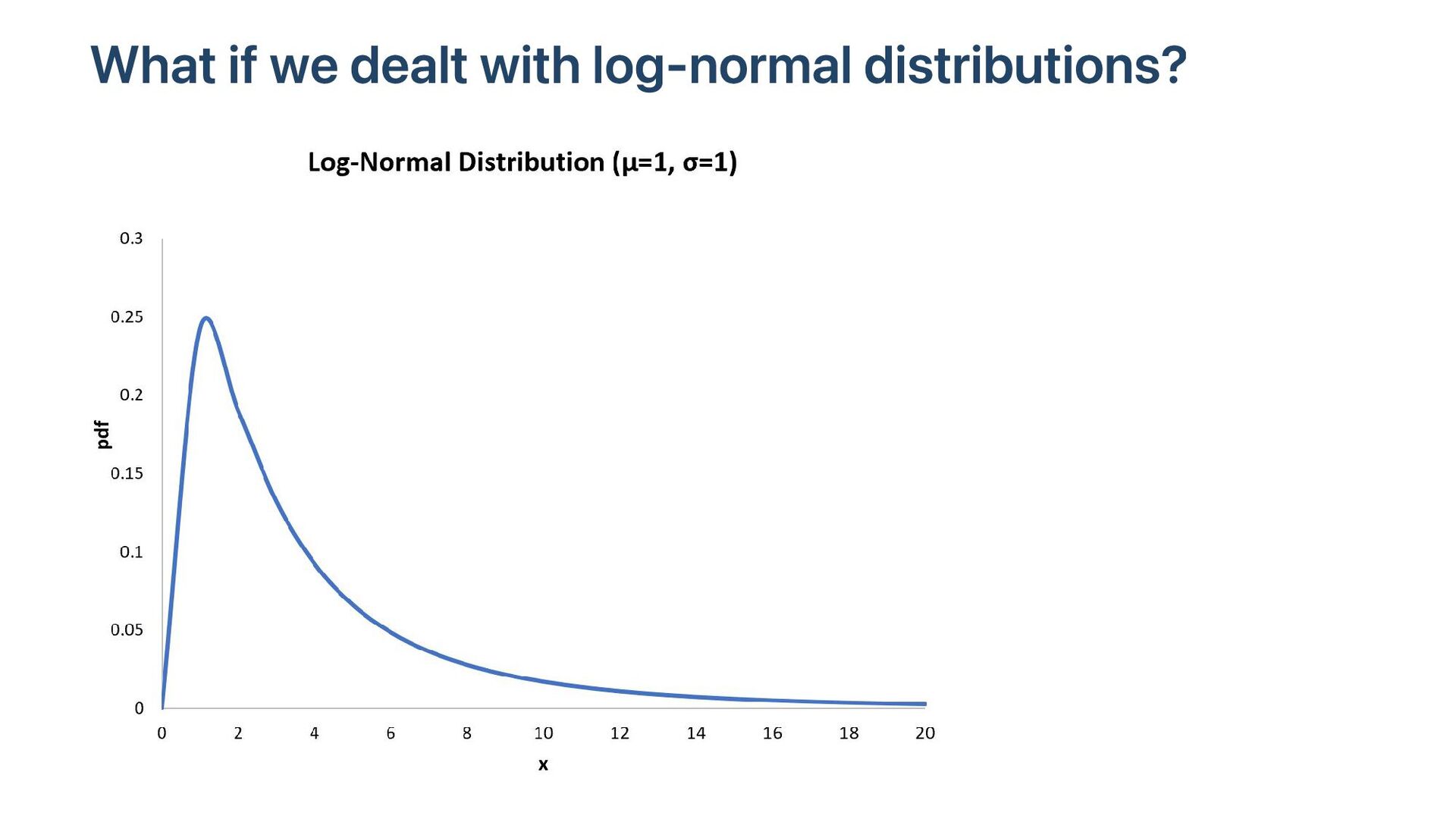
Software is often improved incrementally. Each software optimization should be assessed with microbenchmarks. In a microbenchmark, we record performance measures such as elapsed time or instruction counts during specific tasks, often in idealized conditions. In principle, the process is easy: if the new code is faster, we adopt it. Unfortunately, there are many pitfalls, such as unrealistic statistical assumptions and poorly designed benchmarks. Abstractions like cloud computing add further challenges. We illustrate effective benchmarking practices with examples.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
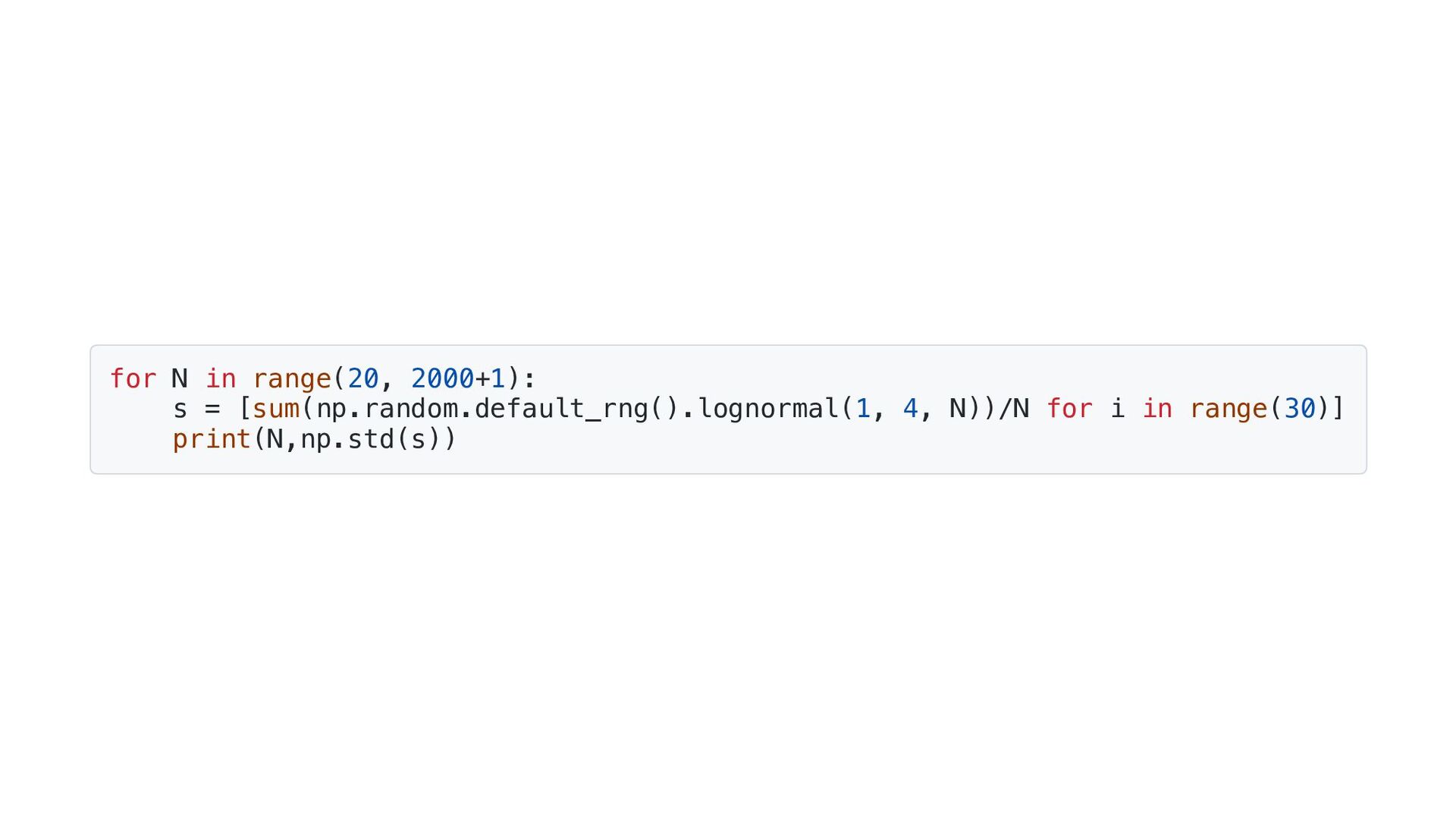{kind=link}
{kind=link}
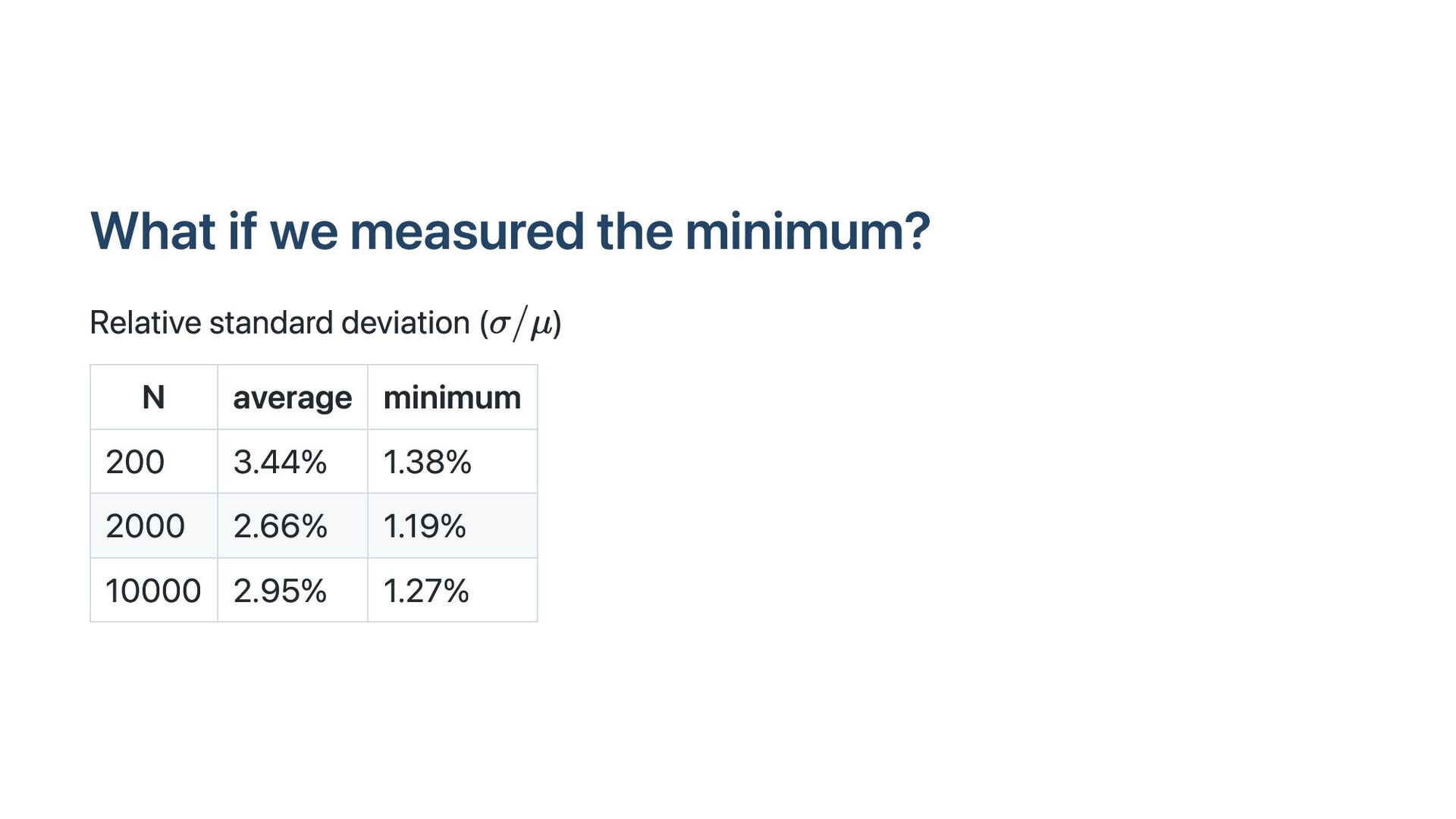{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
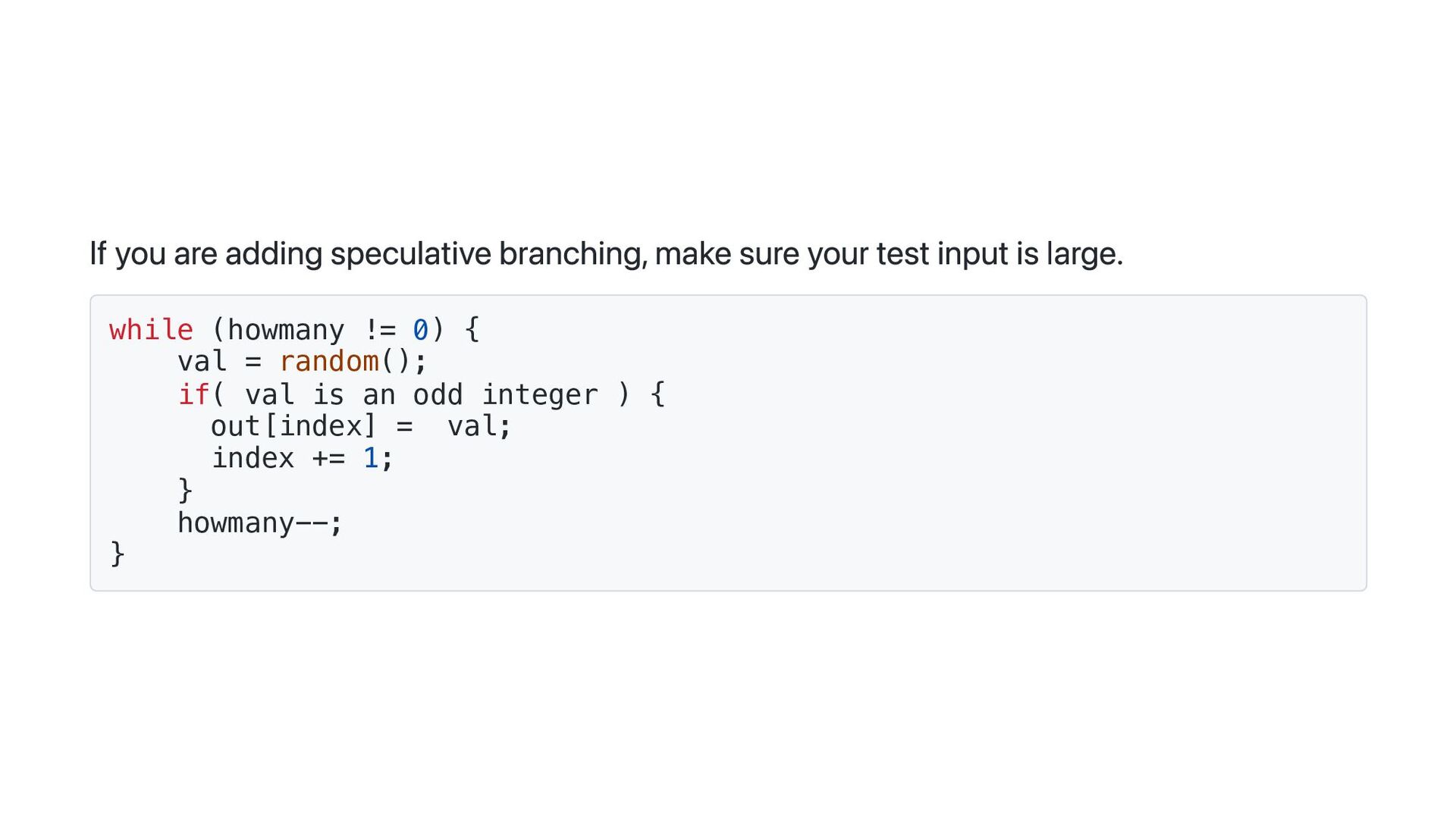{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}