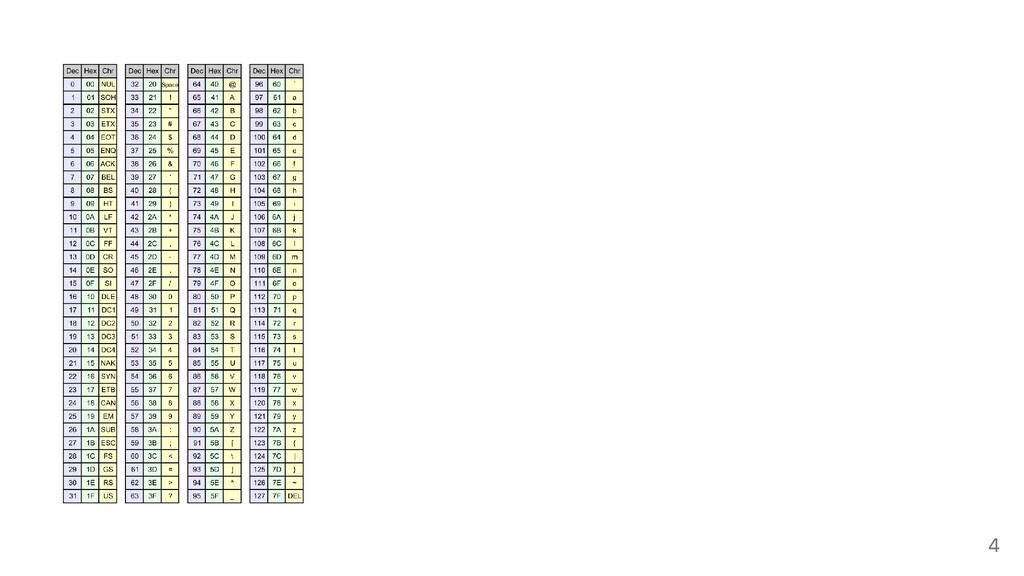
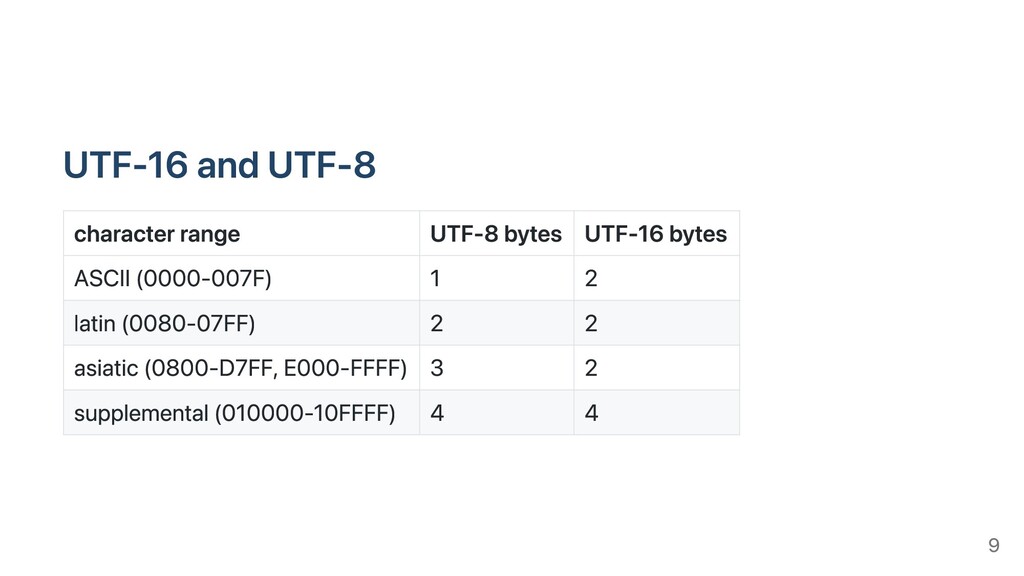
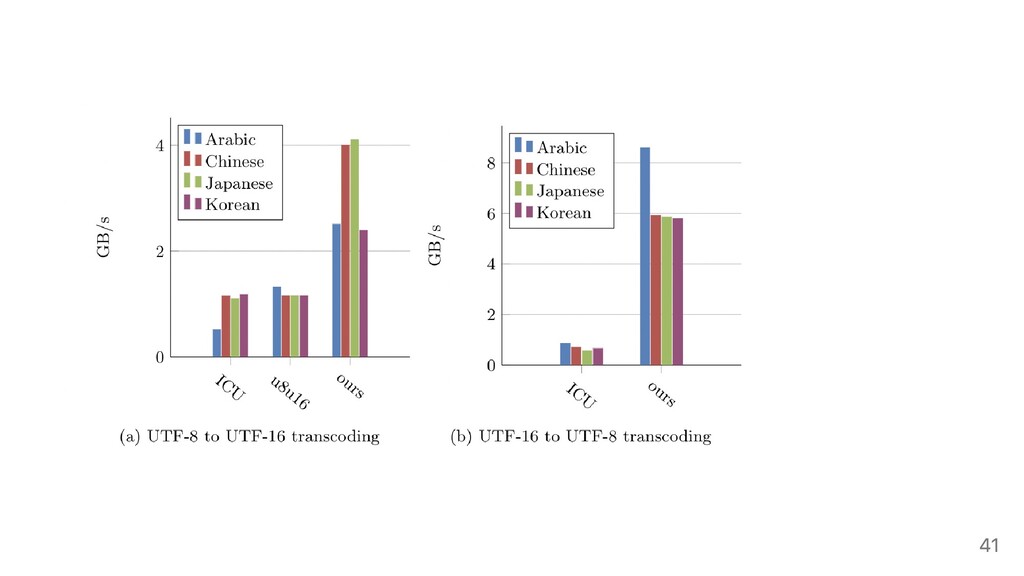
We often represent text using Unicode formats (UTF-8 and UTF-16). UTF-8 is increasingly popular (XML, HTML, JSON, Rust, Go, Swift, Ruby). UTF-16 is most common in Java, .NET, and inside operating systems such as Windows. Software systems frequently have to validate text or convert text from one encoding to the other. While recent disks have bandwidths of 5 GB/s or more, conventional approaches transcode non-ASCII text at a fraction of a gigabyte per second. We show that we can transcode (UTF-8, UTF-16) at gigabytes per second on current systems (x64 and ARM) without sacrificing safety. Our open-source library can be ten times faster than the popular ICU library on non-ASCII strings and even faster on ASCII strings.
Invited talk at SPIRE 2021, 28th International Symposium on String Processing and Information Retrieval (October 4-6th, 2021 - Lille, France)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![UTF-8 to UTF-16 transcoding (example) Start with... [01000001] ([11000100] [10000101])](https://files.speakerdeck.com/presentations/8316ef29566048f2b908afaf21748a93/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Array of nibbles: original: [a0 a1 a2 a3 a4 ...]](https://files.speakerdeck.com/presentations/8316ef29566048f2b908afaf21748a93/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}