Share
最尤法について演習ベースで取り扱った内容として、下記の第5章の内容の公開を行います。 https://lib-arts.booth.pm/items/1725936 対数尤度の最大化にあたっての数式変形の練習は慣れておくと良いので、演習を通して慣れることで理解度を高めていただけたらと思います。
また、最尤法を含めた確率モデリングの話は詳しくは下記などを参照いただけたらと思います。 https://www.amazon.co.jp/dp/B08FYMTYBW
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
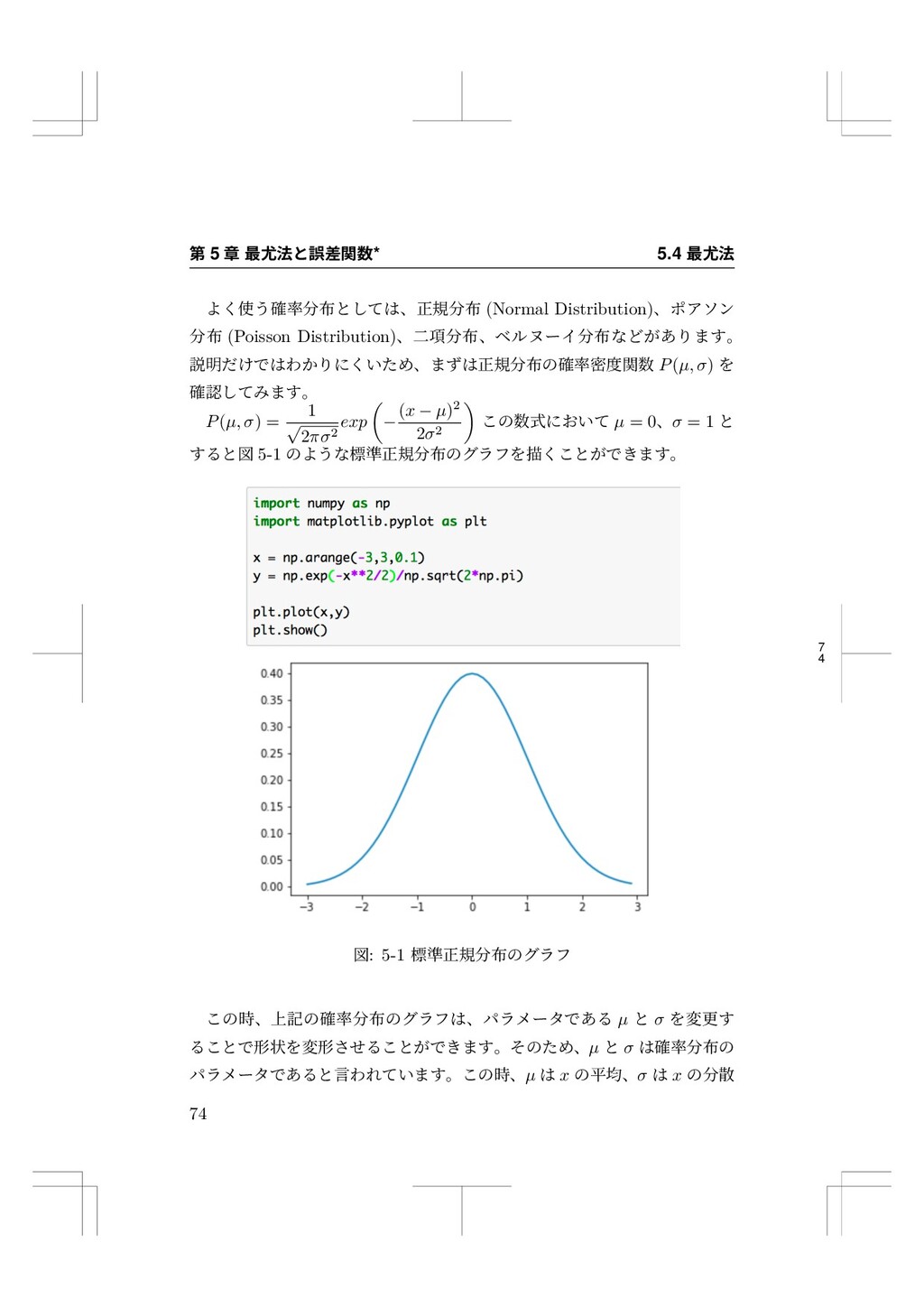{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}