Data – hdp://ceph.com/papers/weil-‐crush-‐sc06.pdf • Replicaeon under scalable hashing: A family of algorithms for scalable decentralized data distribueon – hdp://www.ssrc.ucsc.edu/Papers/honicky-‐ ipdps04.pdf • A fast algorithm for online placement and reorganizaeon of replicated data – hdp://users.soe.ucsc.edu/~elm/Papers/ipdps03.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
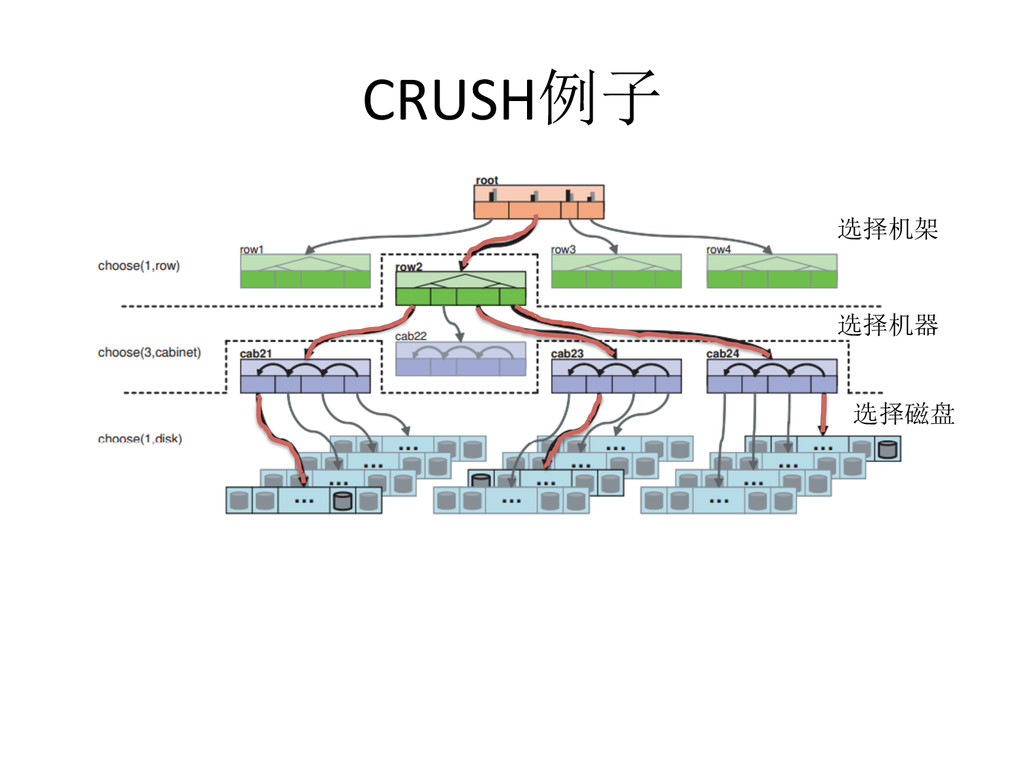{kind=link}
{kind=link}
{kind=link}
{kind=link}
![List Buckets • 从表头开始计算hash(x, r, item)得到一个 [0~1]的v,如果v在[0~Wh/Ws)之间,则副本 在表头中,否则继续遍历剩余链表 – x](https://files.speakerdeck.com/presentations/6de8b710db320131fd3c768f64fa20bc/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}