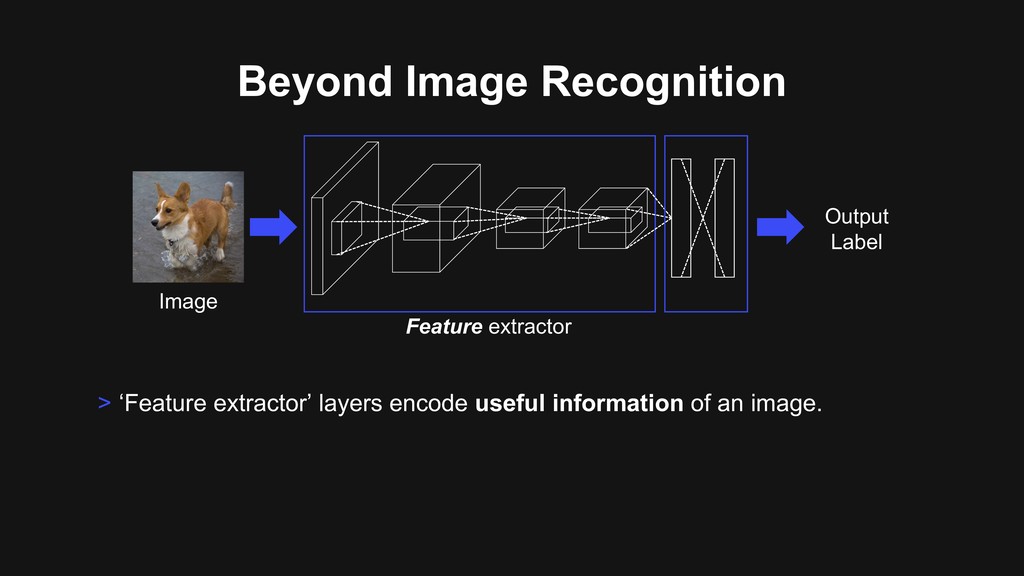
semantic segmentation Source [1] K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask r-cnn”, ICCV 2017. [2] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollár, “Panoptic segmentation”, CVPR 2019. [3] M. Najibi, P. Samangouei, R. Chellappa, and L. S. Davis, “Ssh: Single stage headless face detector”, CVPR 2017.
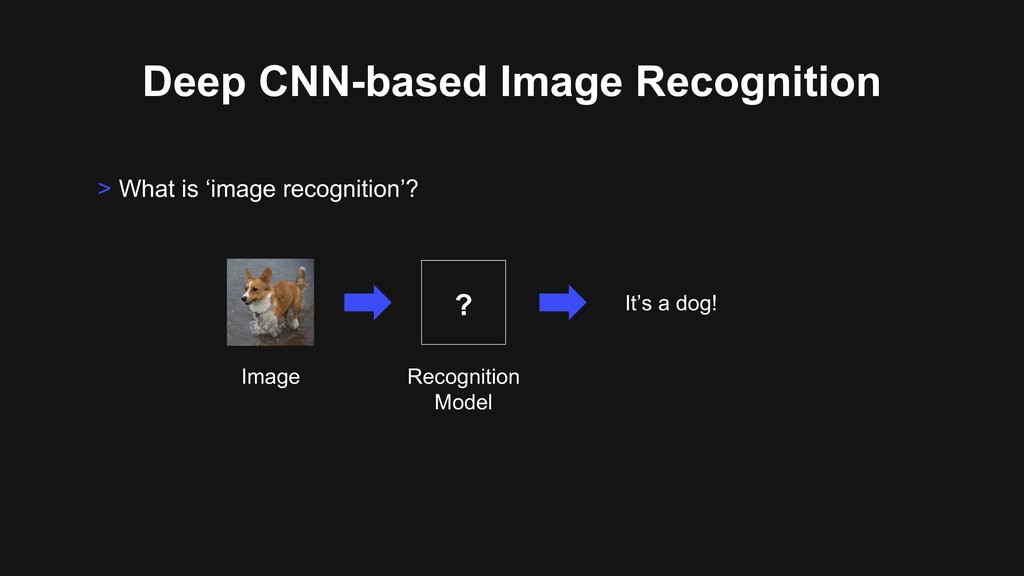
deep network? It’s a dog! Source Lee, Honglak, et al. "Unsupervised learning of hierarchical representations with convolutional deep belief networks." Communications of the ACM, 2011. Image
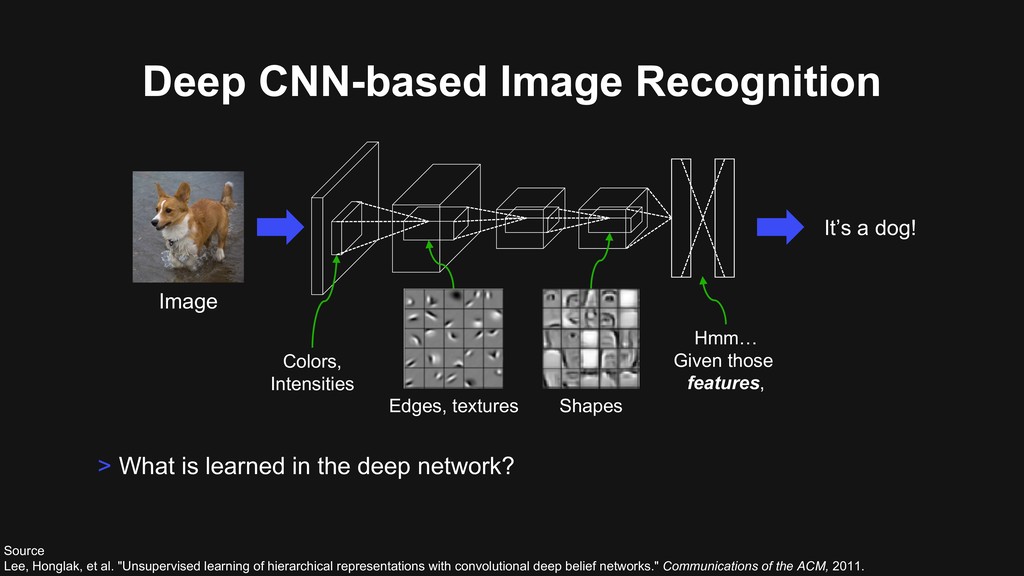
deep network? It’s a dog! Edges, textures Shapes Colors, Intensities Hmm… Given those features, Source Lee, Honglak, et al. "Unsupervised learning of hierarchical representations with convolutional deep belief networks." Communications of the ACM, 2011. Image
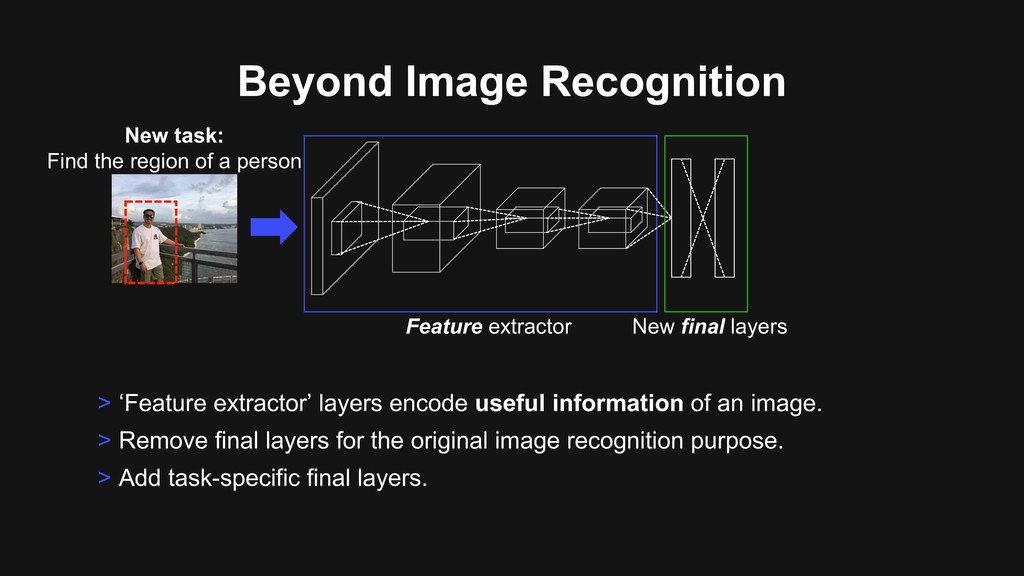
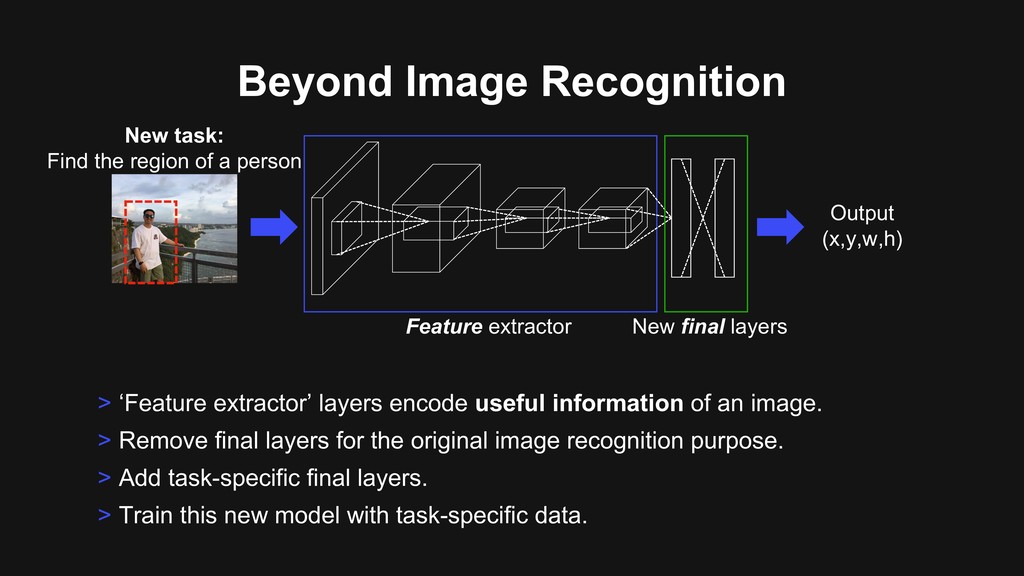
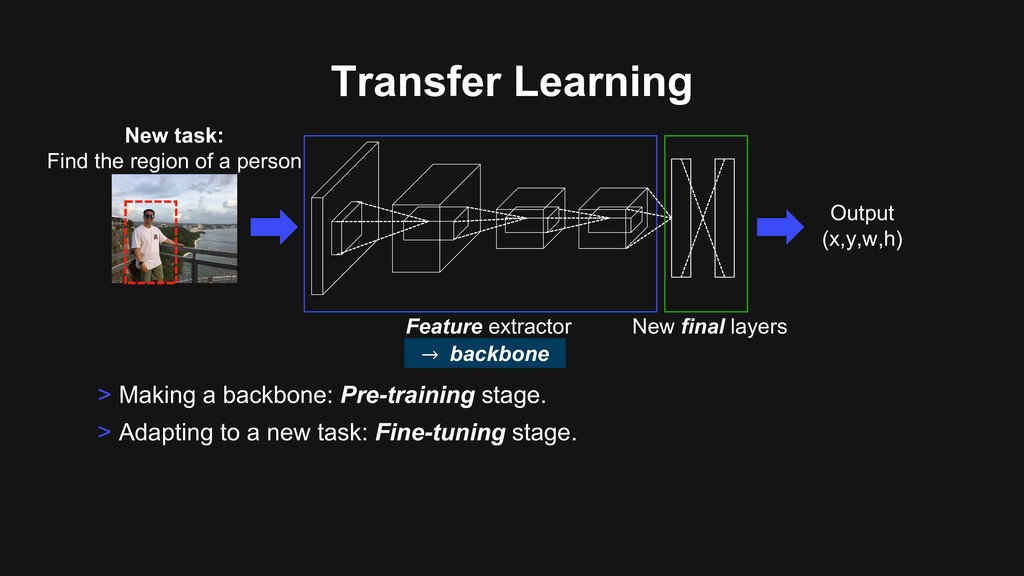
of an image. > Remove final layers for the original image recognition purpose. > Add task-specific final layers. Feature extractor New final layers New task: Find the region of a person
of an image. > Remove final layers for the original image recognition purpose. > Add task-specific final layers. > Train this new model with task-specific data. Feature extractor New final layers New task: Find the region of a person Output (x,y,w,h)
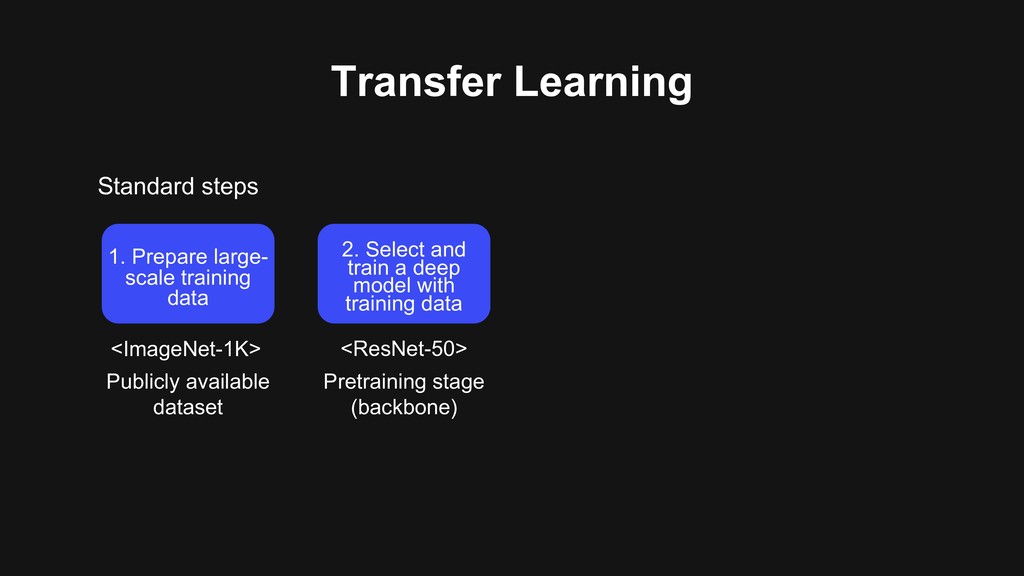
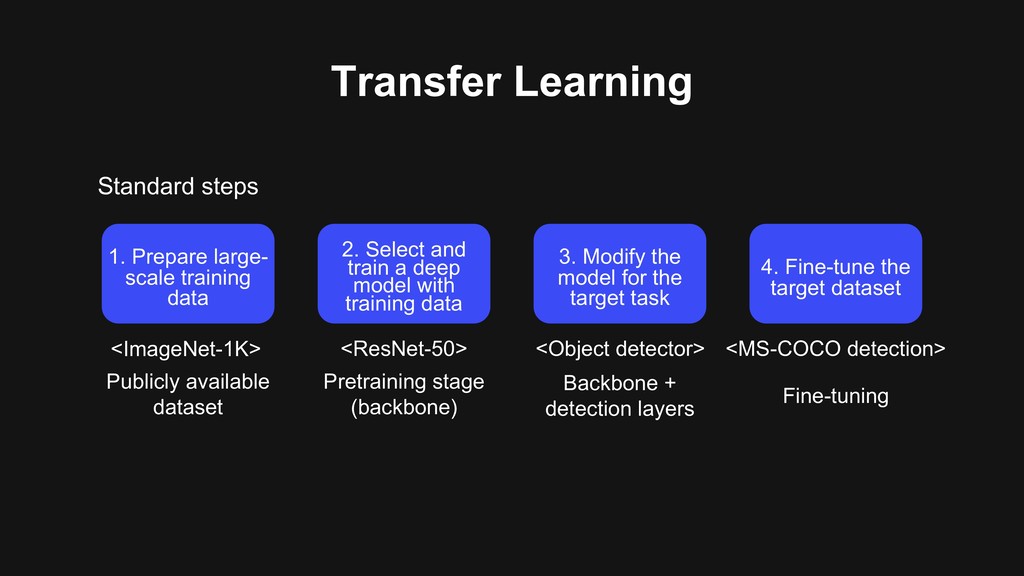
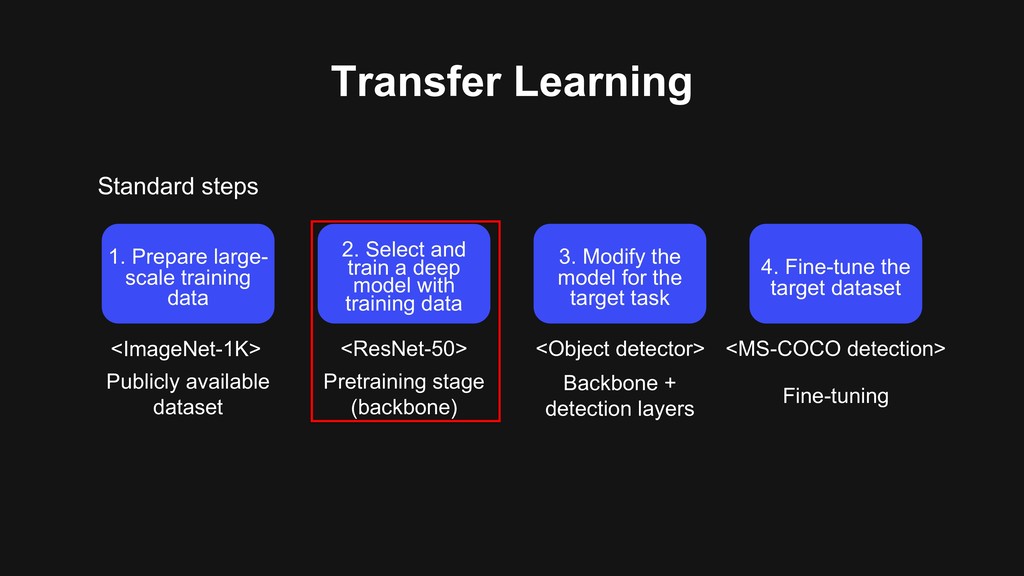
2. Select and train a deep model with training data 3. Modify the model for the target task 4. Fine-tune the target dataset <ImageNet-1K> <Object detector> <ResNet-50> <MS-COCO detection> Pretraining stage (backbone) Publicly available dataset Backbone + detection layers Fine-tuning
2. Select and train a deep model with training data 3. Modify the model for the target task 4. Fine-tune the target dataset <ImageNet-1K> <Object detector> <ResNet-50> <MS-COCO detection> Pretraining stage (backbone) Publicly available dataset Backbone + detection layers Fine-tuning
performance on the new task! [1, 2] Citations [1] Kornblith et al., Do Better ImageNet Models Transfer Better?, CVPR 2019 [2] Pang et al, Libra R-CNN: Towards Balanced Learning for Object Detection, CVPR 2019. Weak backbone Strong backbone > ImageNet-1K accuracy gap: 1~2%. > Detection accuracy gap: 2~3%. > The gap is greater. Fu et al., DSSD: Deconvolutional Single Shot Detector, arxiv 2017.
performance on the new task! > Then, how to make a strong backbone? > Option 1) Bigger pre-training datasets (Expensive) > Option 2) Bigger deep models (Expensive)
performance on the new task! > Then, how to make a strong backbone? > Option 1) Bigger pre-training datasets (Expensive) > Option 2) Bigger deep models (Expensive) > Option 3) Better training strategy (Efficient)
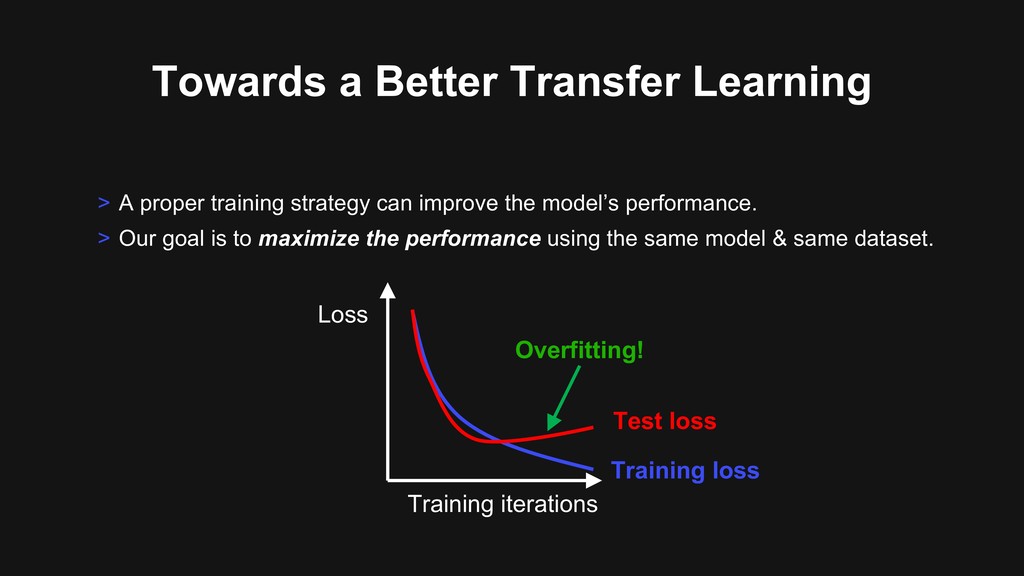
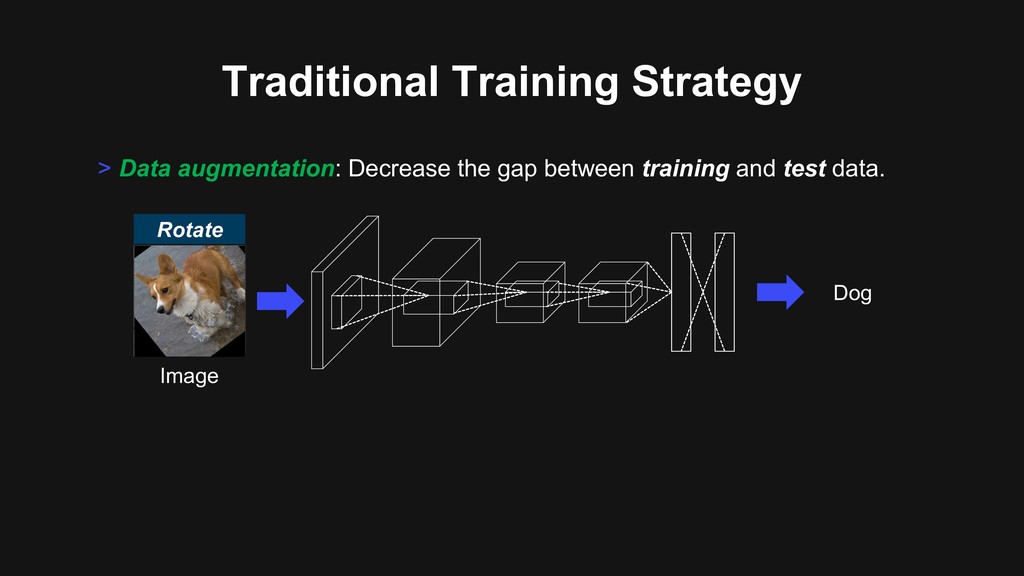
can improve the model’s performance. > Our goal is to maximize the performance using the same model & same dataset. Loss Training iterations Training loss Test loss Overfitting!
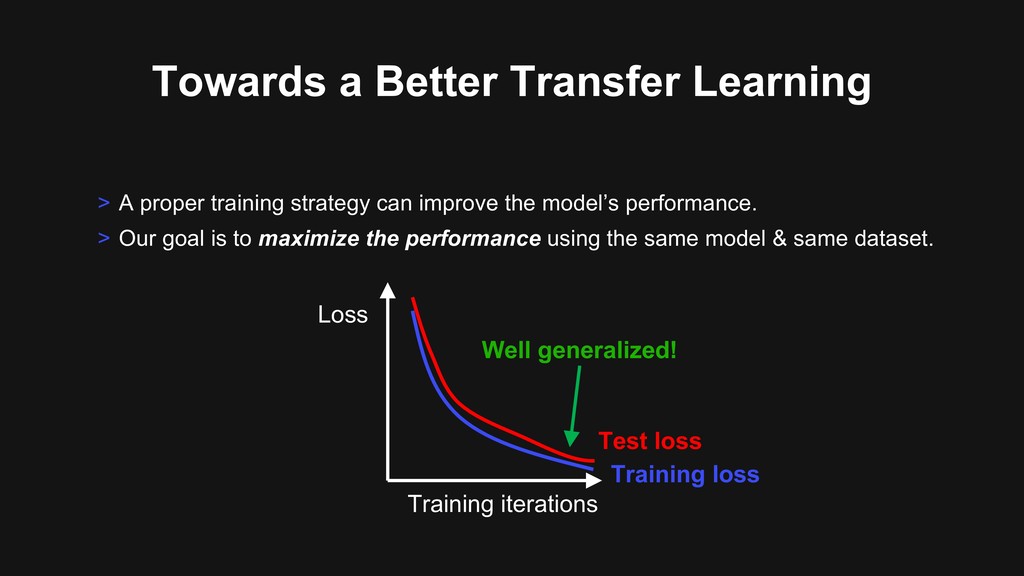
can improve the model’s performance. > Our goal is to maximize the performance using the same model & same dataset. Loss Training iterations Training loss Test loss Well generalized!
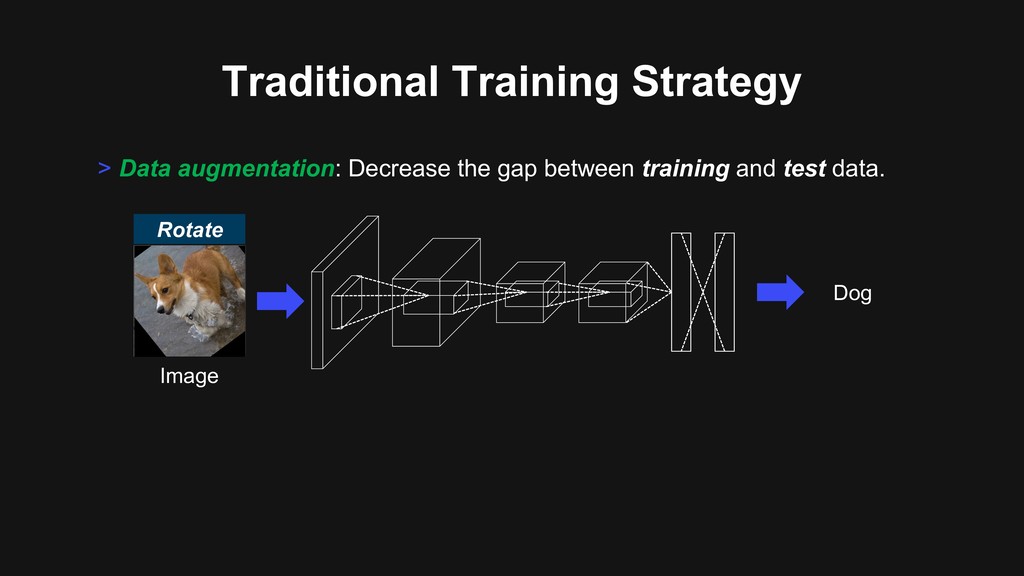
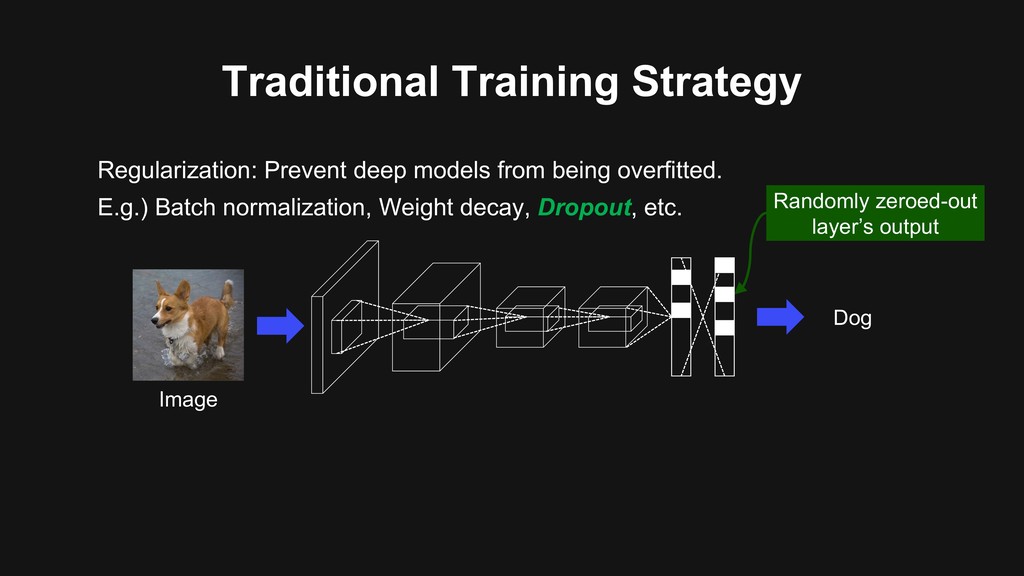
regions Recent works [1] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017. [2] Zhong et al., “Random erasing data augmentation”, arXiv 2017. Dog
regions Recent works [1] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017. [2] Zhong et al., “Random erasing data augmentation”, arXiv 2017. Dog → make “occlusion-robust” backbone ✓ Good generalization ability ✘ Cannot utilize full image regions
→ make backbone robust to uncertain samples ✓ Good generalization ability ✓ Use full image region ✘ Locally unrealistic image [1] Zhang et al., “mixup: Beyond empirical risk minimization.”, ICLR 2018.
Sangdoo Yun Clova AI Naver Dongyoon Han Clova AI Naver Seong Joon Oh Clova AI LINE+ Sanghyuk Chun Clova AI Naver Junsuk Choe* Yonsei University Youngjoon Yoo Clova AI Naver * Intern at Clova. Presented at ICCV 2019, Korea
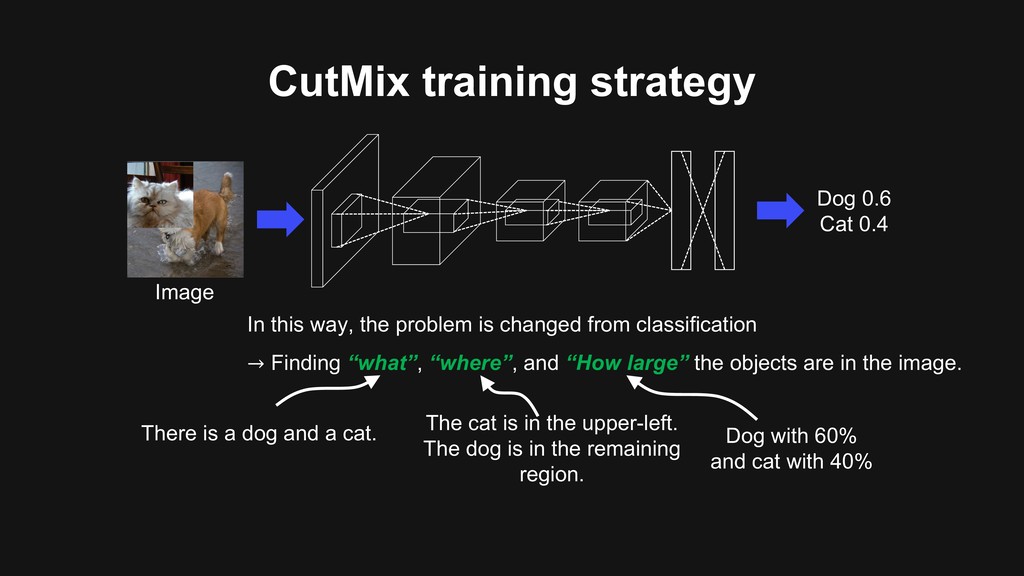
Label Dog 1.0 Dog 1.0 Dog 0.5 Cat 0.5 CutMix Dog 0.6 Cat 0.4 ✓ Unlike Cutout, CutMix uses full image region ✓ Unlike Mixup, CutMix makes realistic local image patches ✓ CutMix is simple: only 20 lines of PyTorch code
way, the problem is changed from classification → Finding “what”, “where”, and “How large” the objects are in the image. There is a dog and a cat. The cat is in the upper-left. The dog is in the remaining region. Dog with 60% and cat with 40%
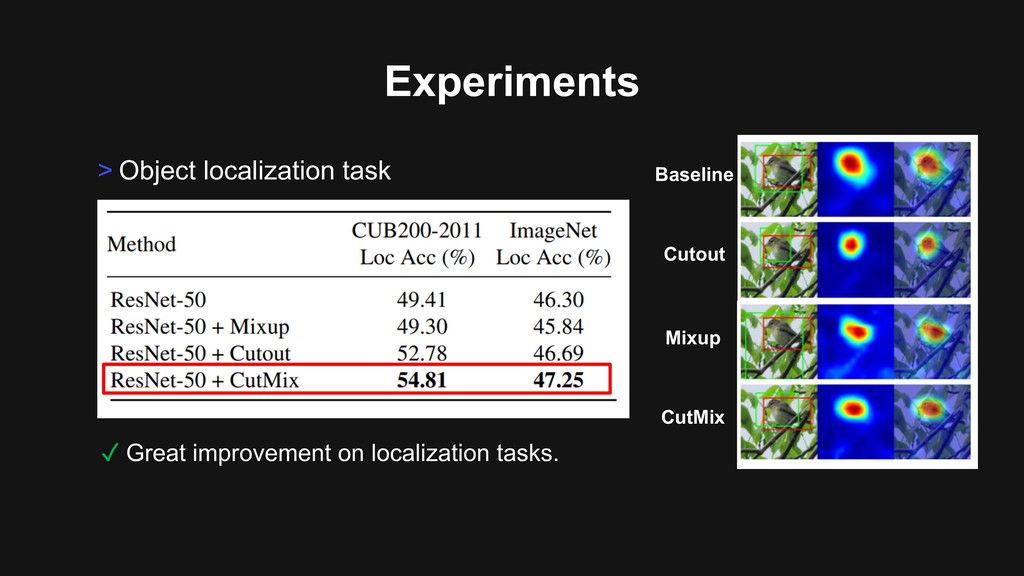
al., Learning Deep Features for Discriminative Localization, CVPR 2016. Heatmap visualization[1]: Where does the model recognize the object? Heatmap of St. Bernard Heatmap of Poodle
of St. Bernard [1] Zhang et al., “mixup: Beyond empirical risk minimization.”, ICLR 2018. [2] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017.
of St. Bernard Heatmap of Poodle [1] Zhang et al., “mixup: Beyond empirical risk minimization.”, ICLR 2018. [2] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017.
of St. Bernard [1] Zhang et al., “mixup: Beyond empirical risk minimization.”, ICLR 2018. [2] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017.
of St. Bernard Heatmap of Poodle [1] Zhang et al., “mixup: Beyond empirical risk minimization.”, ICLR 2018. [2] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017.
of St. Bernard Heatmap of Poodle [1] Zhang et al., “mixup: Beyond empirical risk minimization.”, ICLR 2018. [2] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017.
Heatmap of St. Bernard Heatmap of Poodle [1] Zhang et al., “mixup: Beyond empirical risk minimization.”, ICLR 2018. [2] Devries et al., “Improved regularization of convolutional neural networks with cutout”, arXiv 2017.
Ren et al., Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, NIPS 2015. Karpathy et el., Deep Visual-Semantic Alignments for Generating Image Descriptions, CVPR 2015.
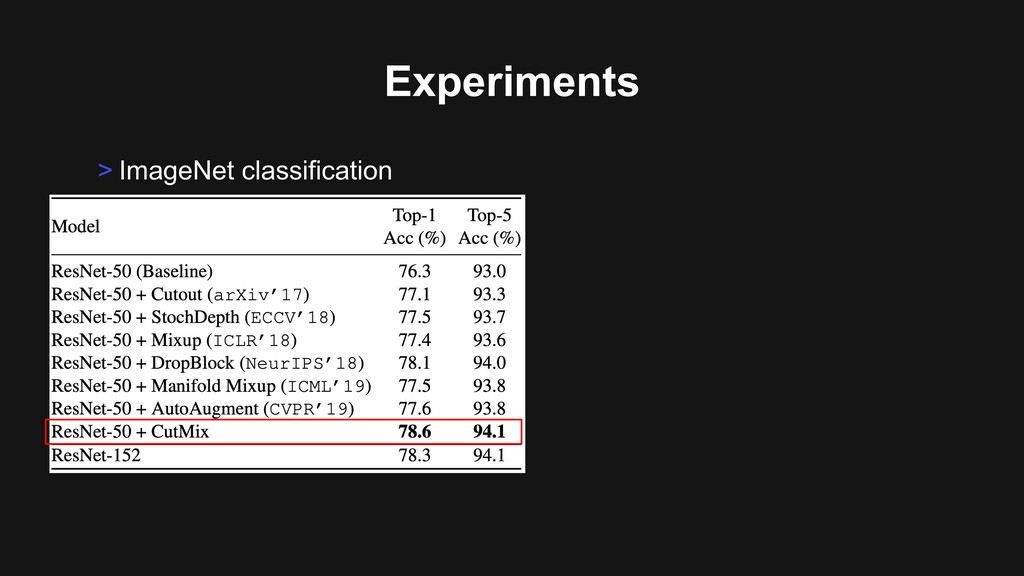
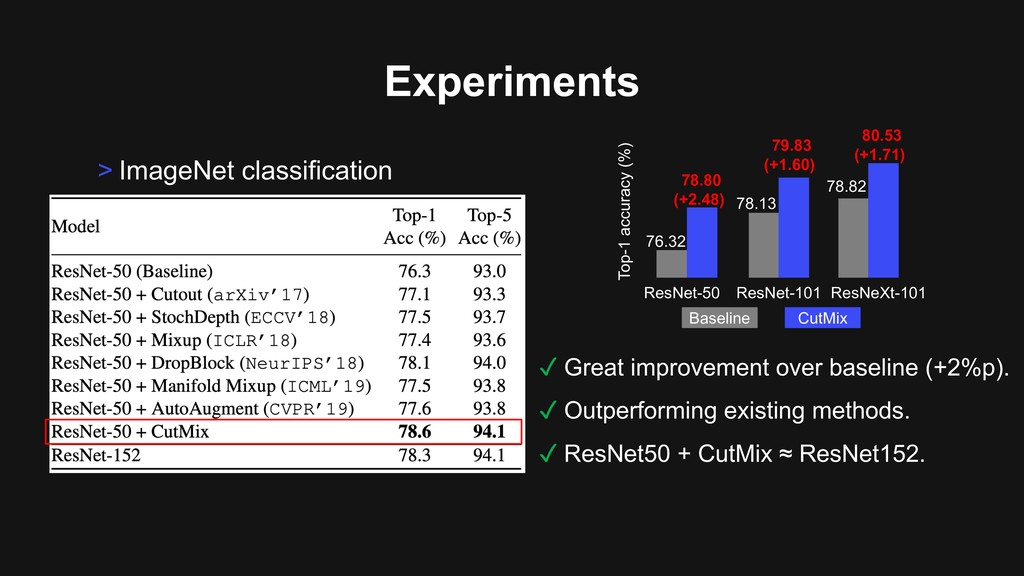
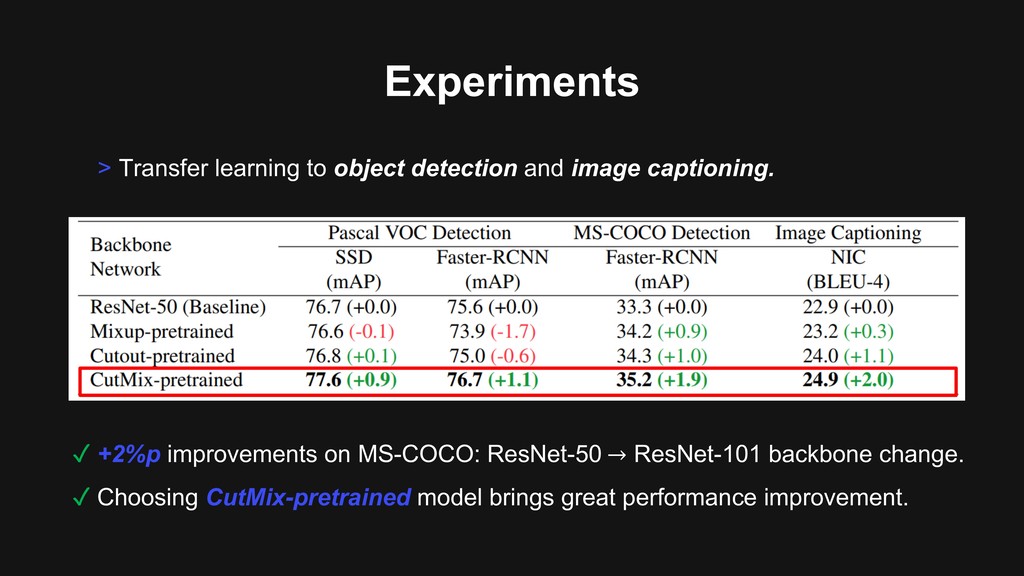
Training protocols Experiments • First, backbone is pre-trained on ImageNet dataset. • Then, fine-tuned on the specific target task. • See the performance improvement. • *Our experiment only changes backbone of the model.
- We assume the non-discriminative patches also have useful information to determine the class. > What if more than two images are mixed? - We tried three and four images for CutMix, the improvements were almost the same. > Additional training cost? - CutMix processing costs are negligible FAQ + →
computer vision tasks. > Need to train a strong and robust classifier → Apply CutMix regularizer to your classifier. > Need a better pre-trained model for transfer learning → Download our CutMix-pretrained model. > Visit our website (codes & models): https://github.com/clovaai/CutMix-PyTorch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Image Regional Dropout strategy “Cutout” [1, 2]: randomly remove image](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_38.jpg){kind=link}
![Image Regional Dropout strategy “Cutout” [1, 2]: randomly remove image](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_39.jpg){kind=link}
![Recent works Image Dog > Mixup[1] regularization Cat Dog 0.5](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_40.jpg){kind=link}
![Dog 0.5 Cat 0.5 Recent works Image > Mixup[1] regularization](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![What does the model learn with CutMix? [1] Zhou et](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_48.jpg){kind=link}
![What does the model learn with CutMix? [1] Zhou et](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_49.jpg){kind=link}
{kind=link}
![What does the model learn with CutMix? Cutout[2] CutMix Heatmap](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_51.jpg){kind=link}
![What does the model learn with CutMix? Cutout[2] CutMix Heatmap](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_52.jpg){kind=link}
![What does the model learn with CutMix? Mixup[1] CutMix Heatmap](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_53.jpg){kind=link}
![What does the model learn with CutMix? Mixup[1] CutMix Heatmap](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_54.jpg){kind=link}
![What does the model learn with CutMix? Mixup[1] CutMix Heatmap](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_55.jpg){kind=link}
![What does the model learn with CutMix? Mixup[1] Cutout[2] CutMix](https://files.speakerdeck.com/presentations/71f8cc88bfb94c88a14a226df29953c2/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}