IDF 算每一個「詞」對每一篇「文件」的分數 (score) LDA: 降維,提取文件與詞中的概念 A: 台北 現在 有 下雨 嗎 ? 明天 會 下雨 嗎 ? B: 明天 台北 會 很冷 嗎 ? 「下雨」的 TF = 2/9, IDF = log(2/1) = log2, TF-IDF = TF x IDF = 2/9 x log2 = 0.067 文件 台北 現在 有 下雨 嗎 明天 會 很冷 ? A 1 1 1 2 2 1 1 0 2 B 1 0 0 0 1 1 1 1 1 TF-IDF LDA A: [0, 0.033, 0.033, 0.067, 0, 0, 0, 0, 0] B: [0, 0, 0, 0, 0, 0, 0, 0.033, 0] A: [X,X,X,…..,X] dim: 100 B: [X,X,X,…..,X] dim: 100 {(現在), (明天), (下雨)} -> {(1.3452 * 現在 + 0.2828 * 明天), (下雨)}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
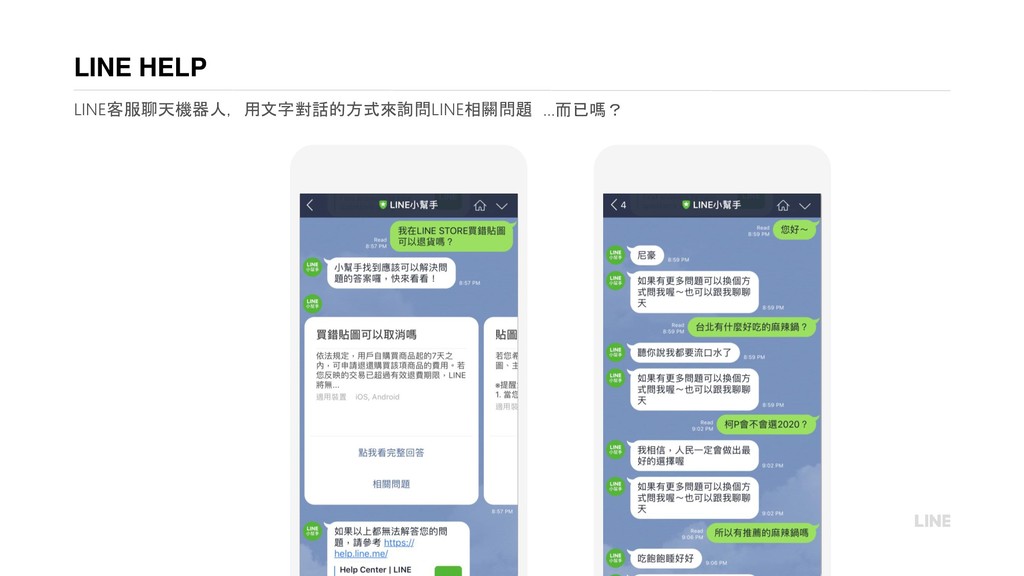{kind=link}
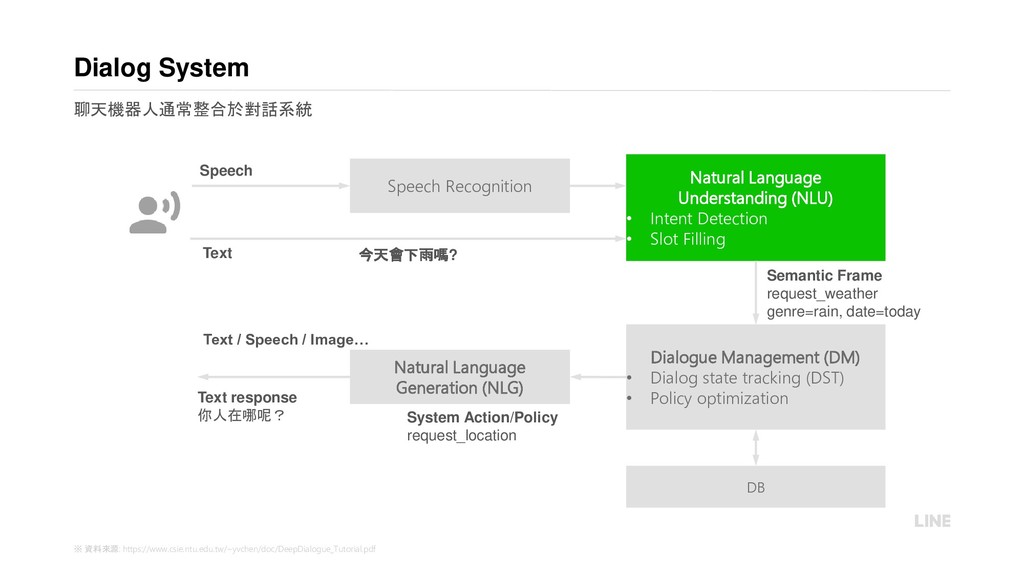{kind=link}
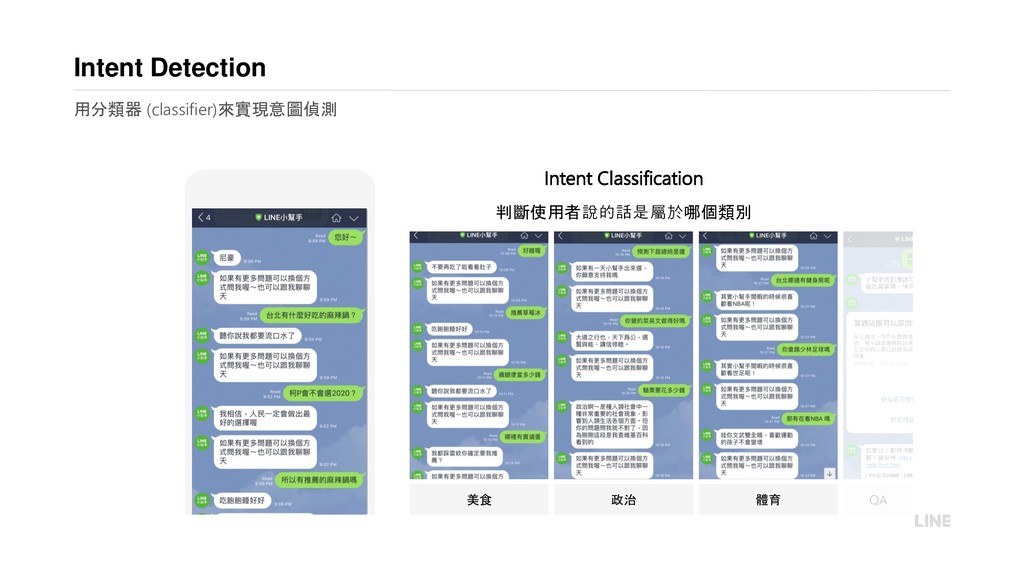{kind=link}
{kind=link}
{kind=link}
{kind=link}
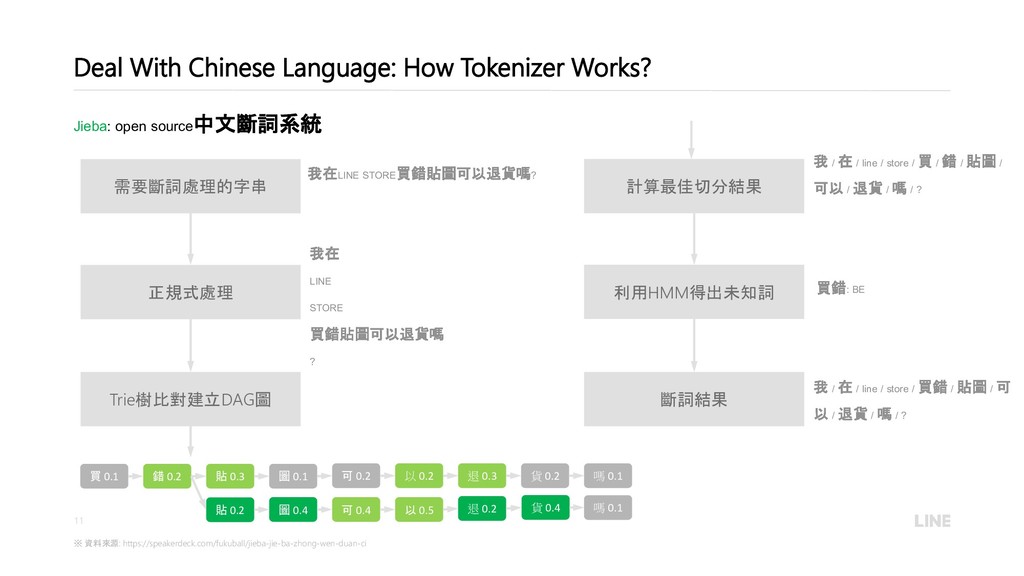{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}