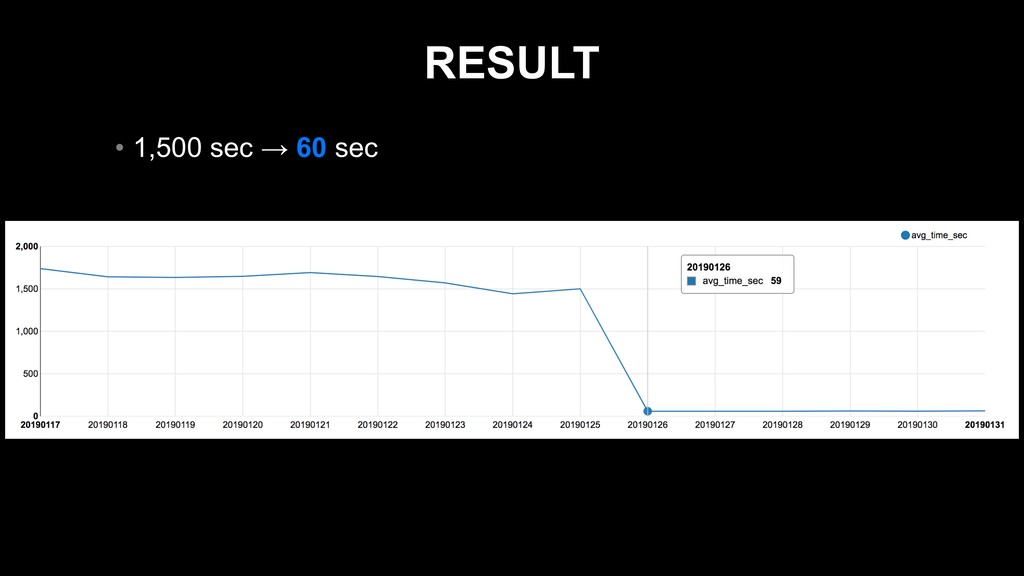
from db.transaction where dt between '20190211' and '20190217' ) t inner join db.master m on m.key = t.key group by t.dt, m.name 1,800,000,000 records 200 records
from db.transaction where dt between '20190211' and '20190217' ) t inner join db.master m on m.key = t.key group by t.dt, m.name 1,800,000,000 records 200 records
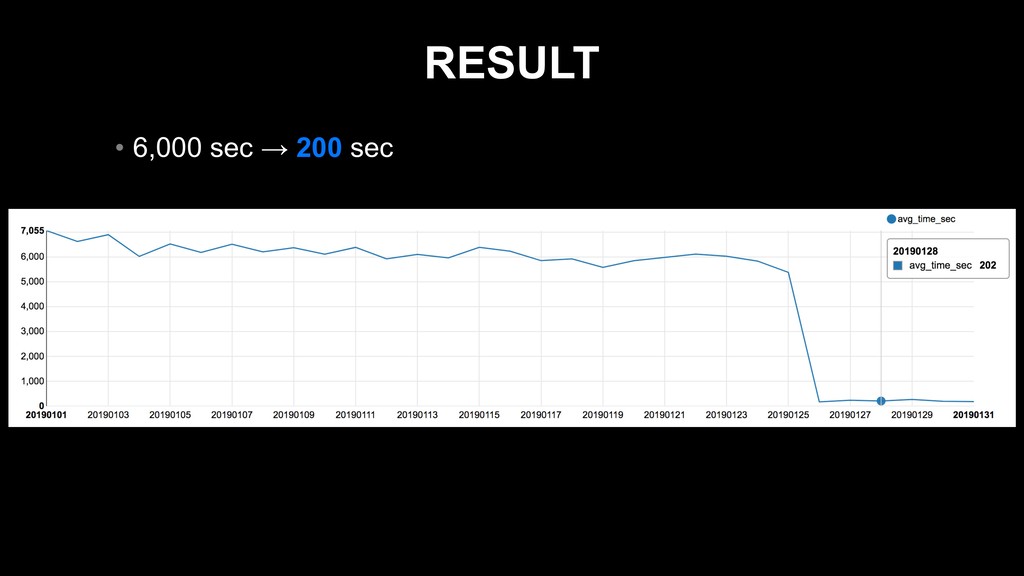
area_code, uid from db.transaction where dt between '20180818' and '20190217' ) t inner join (select * from db.area where dt = ‘20190217’) a on a.area_code = t.area_code group by t.dt, a.area_name
area_code, uid from db.transaction where dt between '20180818' and '20190217' ) t inner join (select * from db.area where dt = ‘20190217’) a on a.area_code = t.area_code group by t.dt, a.area_name 4,500,000,000 records 90 records
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PHYSICAL PLAN *(6) HashAggregate(keys=[dt#958, name#970], functions=[count(1)]) +- Exchange hashpartitioning(dt#958, name#970,](https://files.speakerdeck.com/presentations/5960dac2434b4cad9294838ed555d572/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PHYSICAL PLAN *(6) HashAggregate(keys=[dt#958, name#970], functions=[count(1)]) +- Exchange hashpartitioning(dt#958, name#970,](https://files.speakerdeck.com/presentations/5960dac2434b4cad9294838ed555d572/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PHYSICAL PLAN *(3) HashAggregate(keys=[dt#149, name#161], functions=[count(1)]) +- Exchange hashpartitioning(dt#149, name#161,](https://files.speakerdeck.com/presentations/5960dac2434b4cad9294838ed555d572/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CUSTOMIZE OPTIMIZATION object InsertBroadcastHints extends Rule[LogicalPlan] { val targets =](https://files.speakerdeck.com/presentations/5960dac2434b4cad9294838ed555d572/slide_35.jpg){kind=link}
![OPTIMIZED LOGICAL PLAN Aggregate [...] +- Project [...] +- Join](https://files.speakerdeck.com/presentations/5960dac2434b4cad9294838ed555d572/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
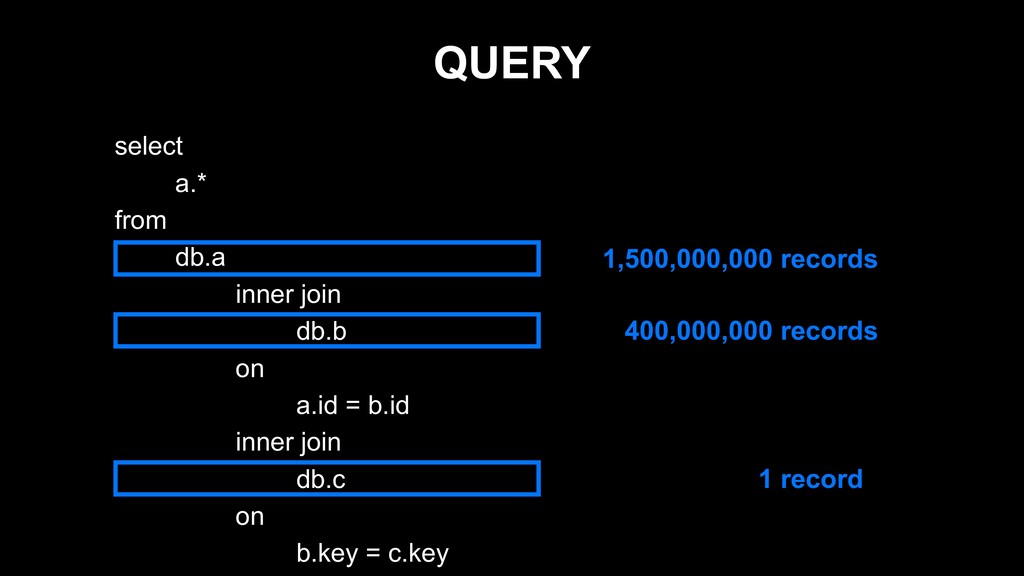{kind=link}
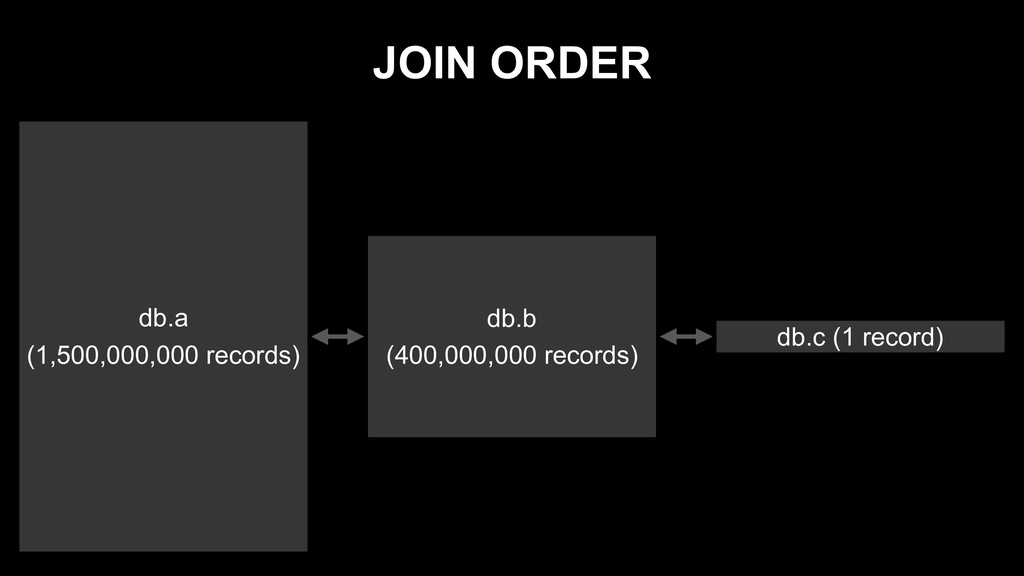{kind=link}
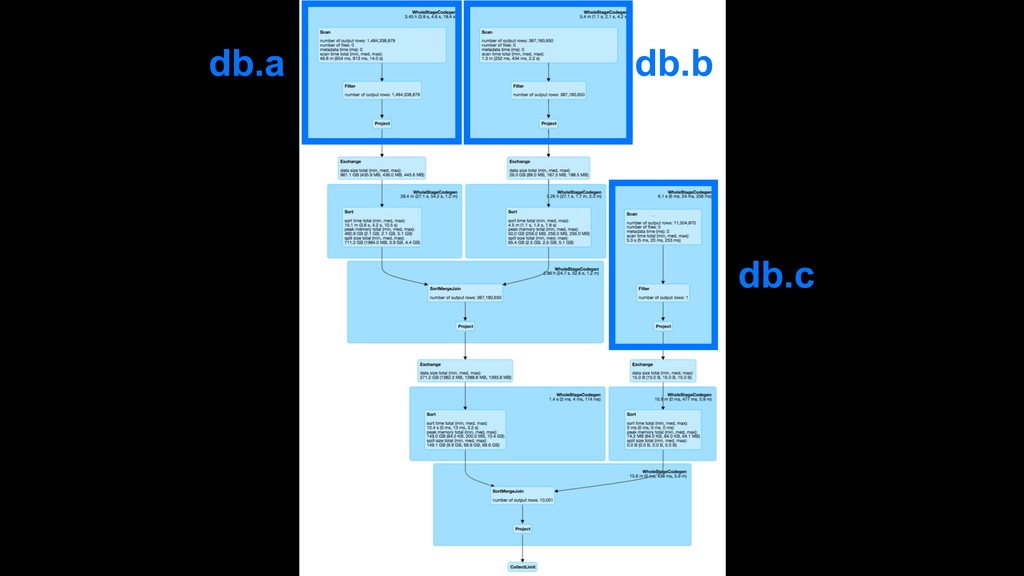{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}