LINE Pay LINE LIVE LINE MOBILE Hadoop Cluster (Data Lake) LINE Ads Platform LINE Creators Market LINE NEWS LINE Pay LINE LIVE LINE MOBILE ETL Analysis BI / Reporting
• Enables employees to analyze their service’s data as they like • Speeds up their data analysis process and decision making Multi-tenant Hadoop Cluster LINE Ads Platform LINE Creators Market LINE Ads Platform LINE Creators Market
single server • Does not support the “yarn-cluster” mode • Easy to freeze Apache Zeppelin Server Apache Zeppelin Driver Program 1 Driver Program 2 Driver Program 3 Driver Program 4 Driver Program 5
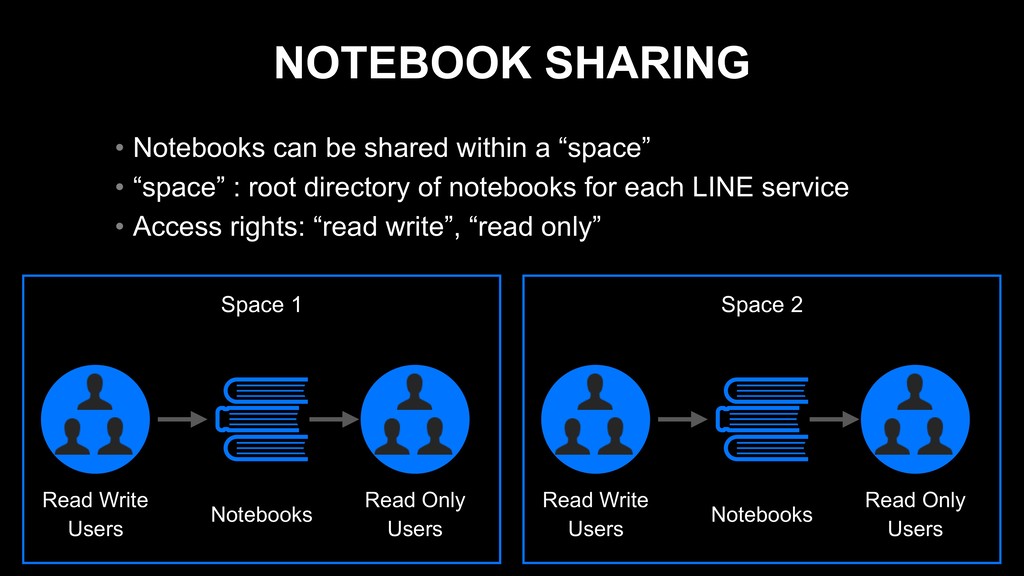
• “space” : root directory of notebooks for each LINE service • Access rights: “read write”, “read only” Space 1 Read Write Users Read Only Users Notebooks Space 2 Read Write Users Read Only Users Notebooks
{kind=link}
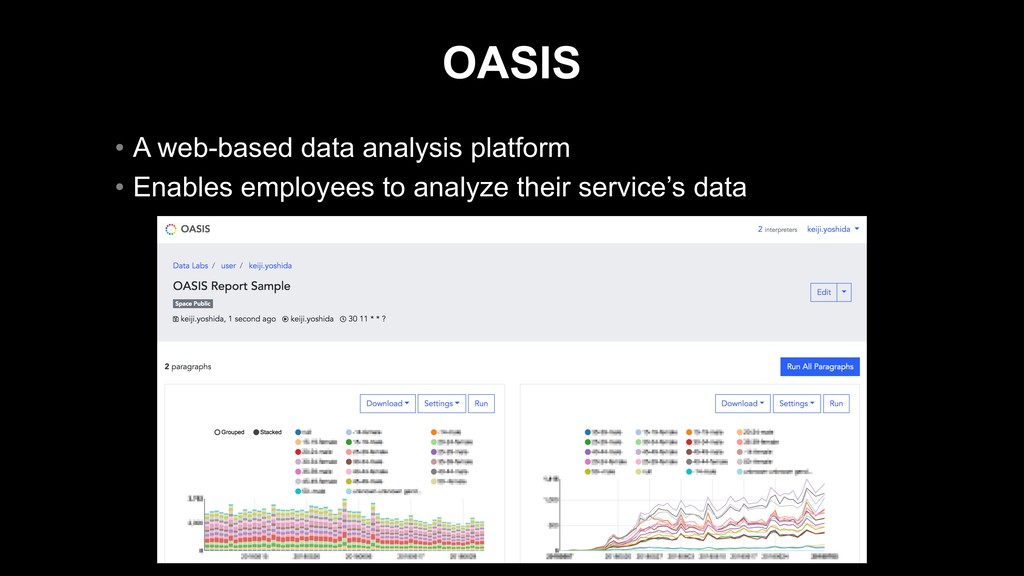{kind=link}
{kind=link}
{kind=link}
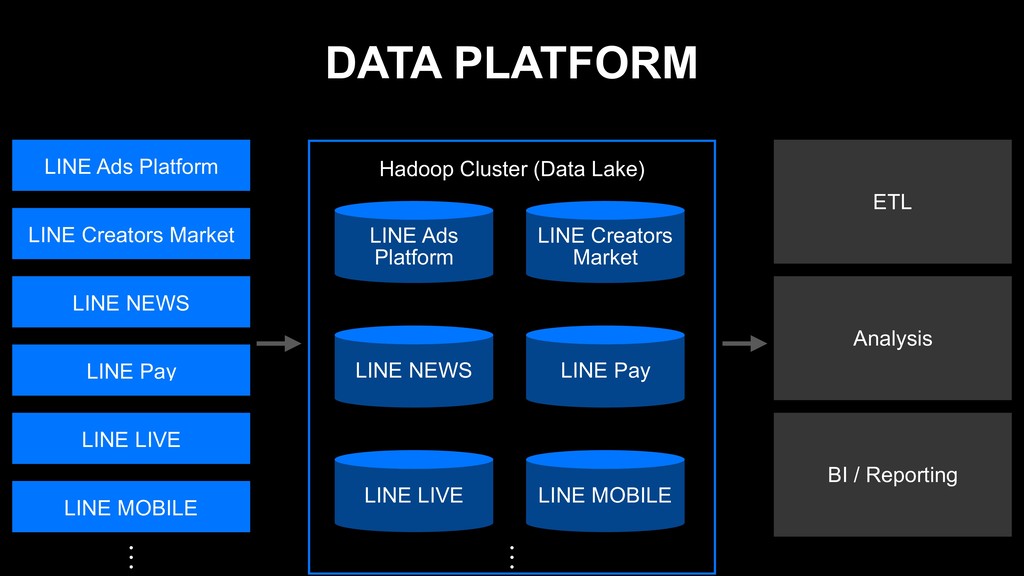{kind=link}
{kind=link}
{kind=link}
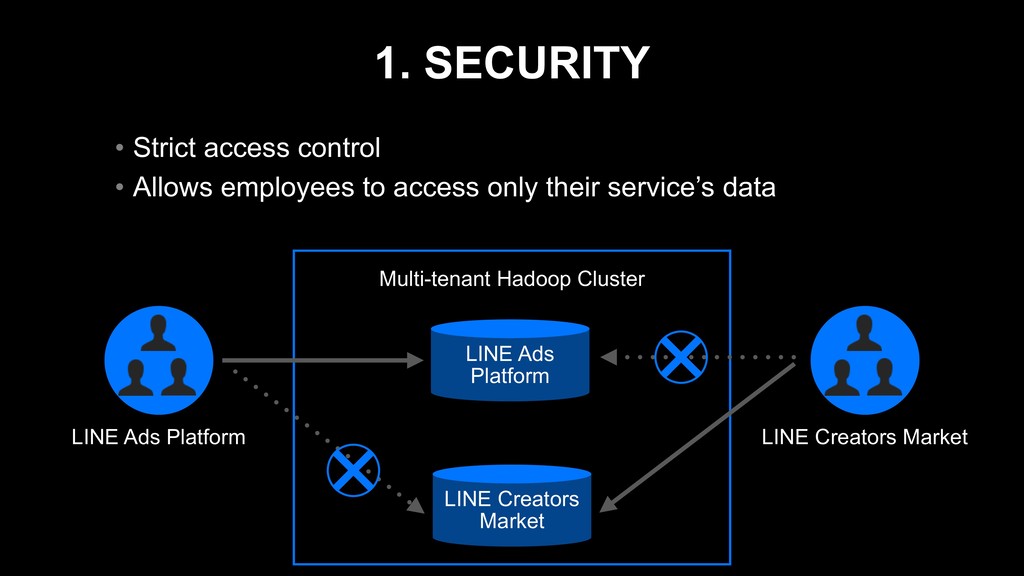{kind=link}
{kind=link}
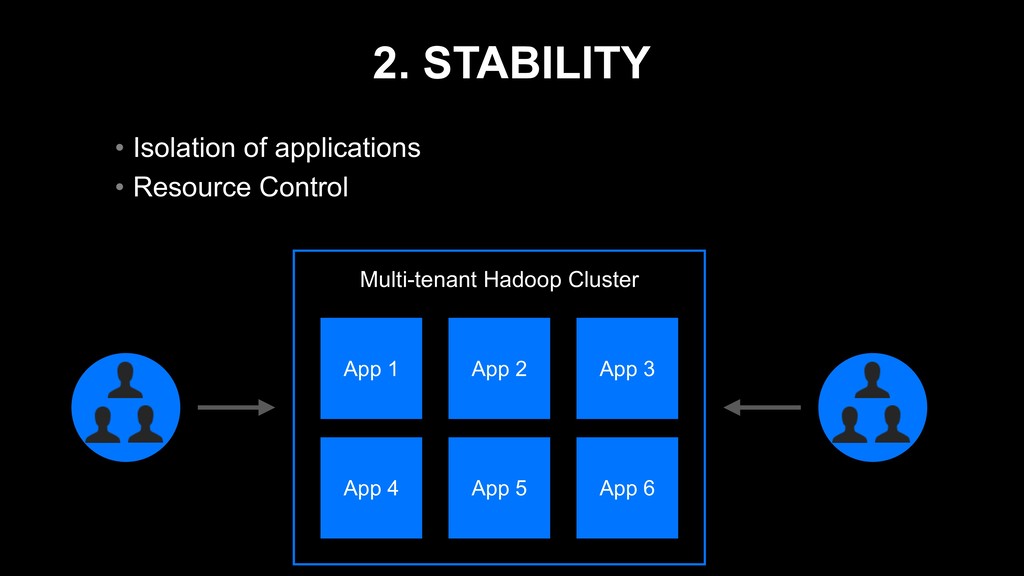{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}