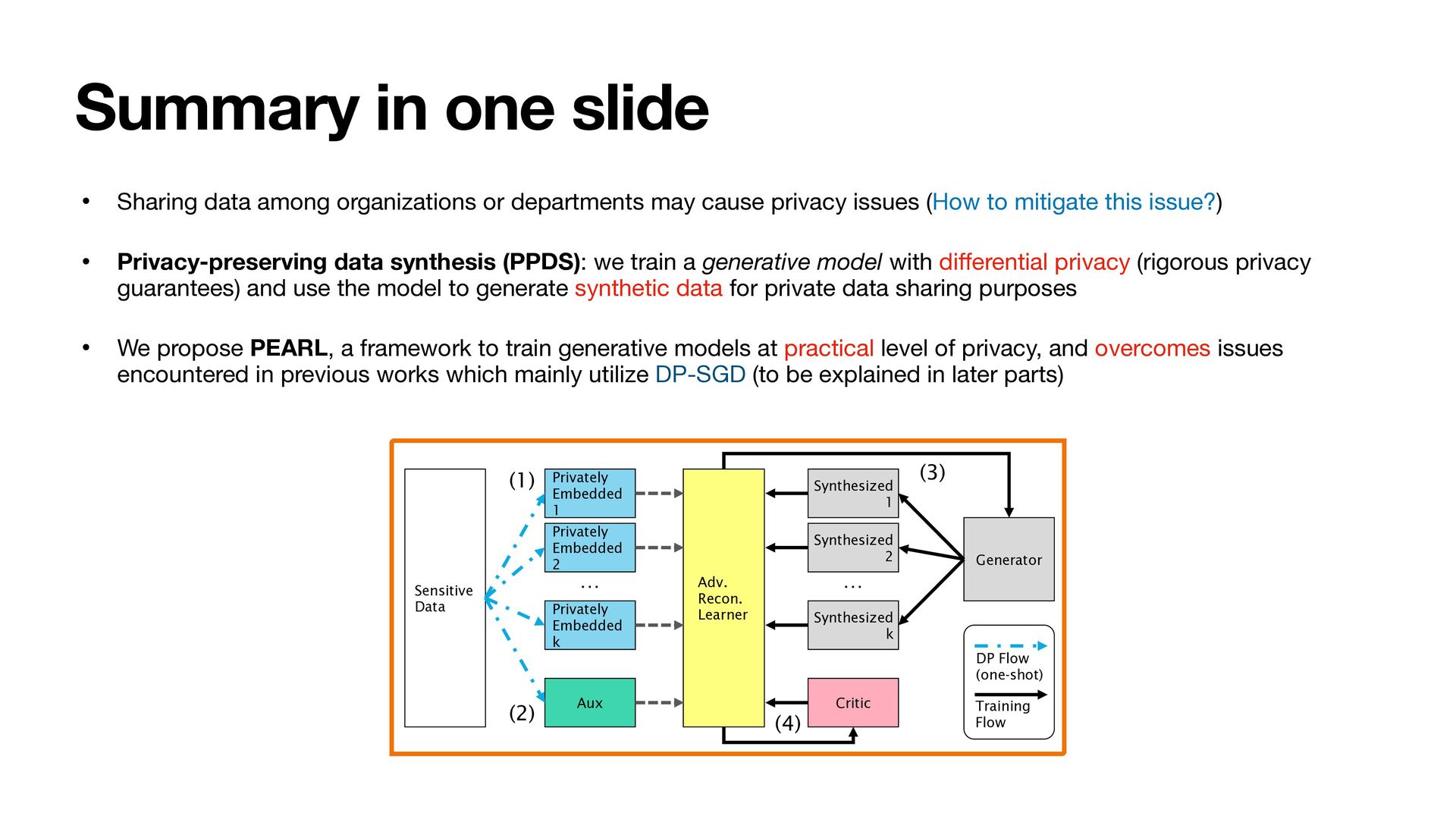
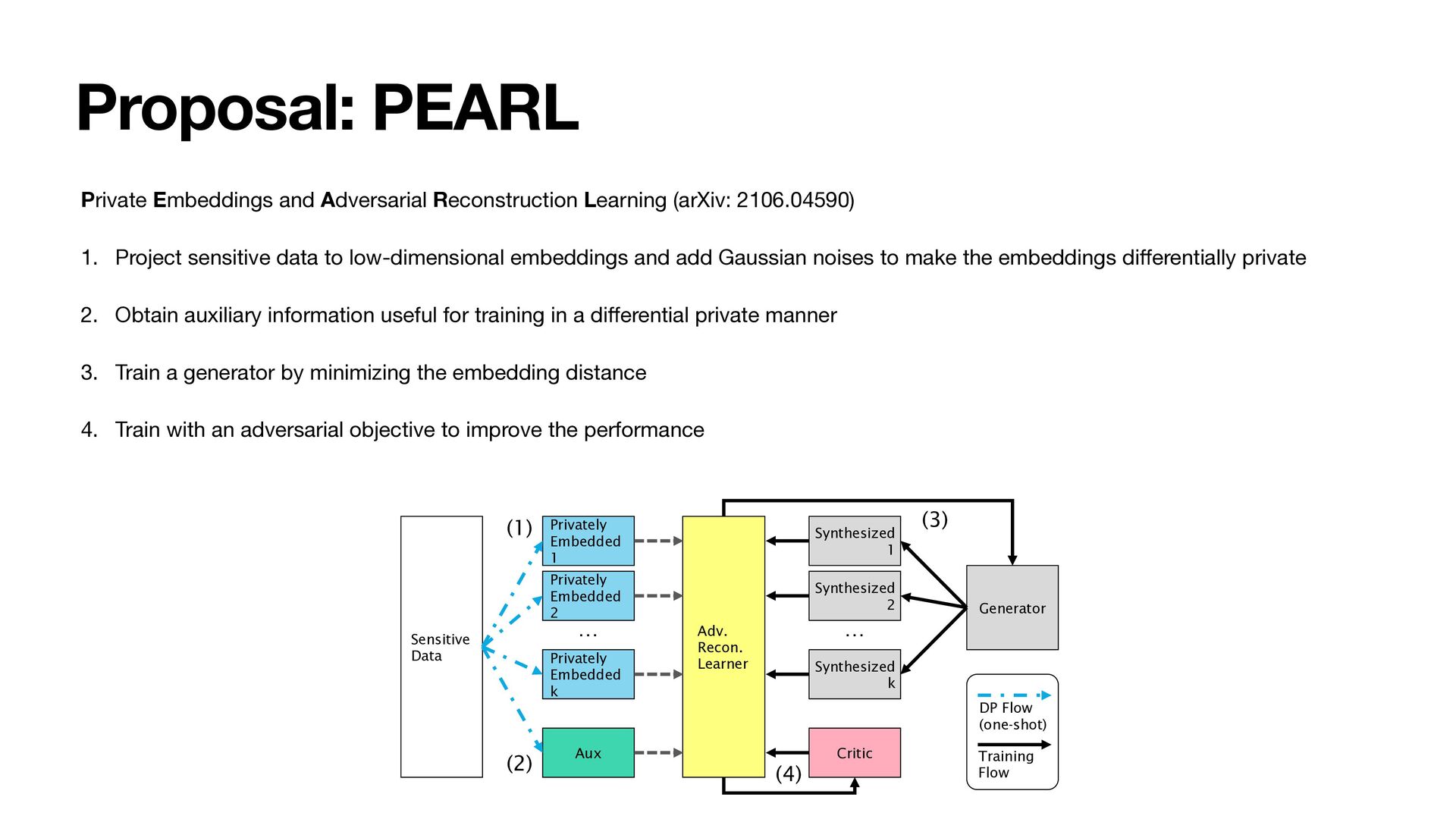
departments may cause privacy issues (How to mitigate this issue?) • Privacy-preserving data synthesis (PPDS): we train a generative model with di ff erential privacy (rigorous privacy guarantees) and use the model to generate synthetic data for private data sharing purposes • We propose PEARL, a framework to train generative models at practical level of privacy, and overcomes issues encountered in previous works which mainly utilize DP-SGD (to be explained in later parts) Sensitive Data Privately Embedded 1 Privately Embedded 2 Privately Embedded k Aux Synthesized 1 Synthesized 2 Synthesized k Critic Adv. Recon. Learner Generator (1) (2) (3) (4) DP Flow (one-shot) Training Flow … …
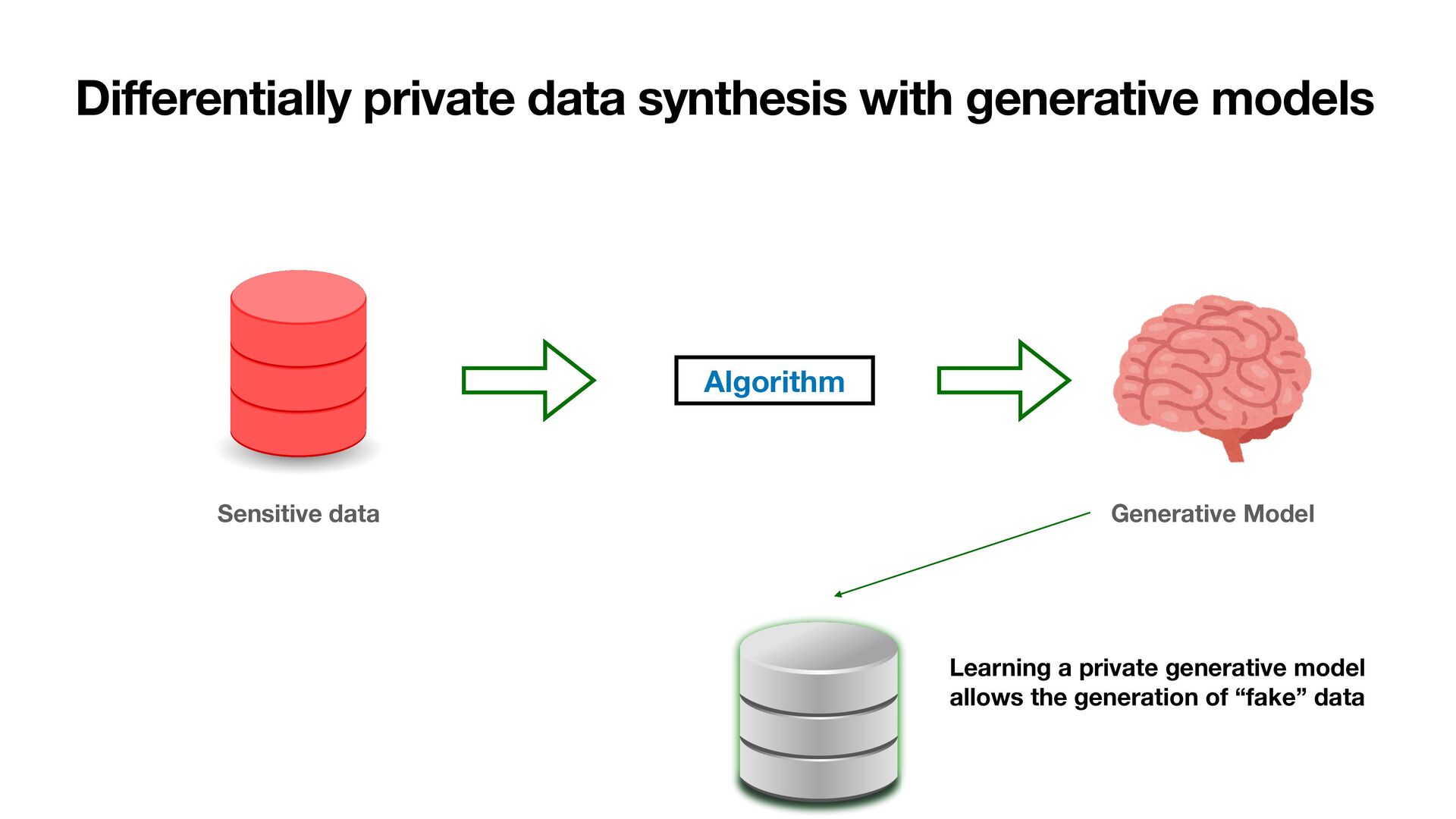
Private Data Synthesis (with generative model) • Training generative models with di ff erential privacy (and general shortcomings) • Proposal: PEARL • Realization of PEARL (embedding, generative model, critic) • Results
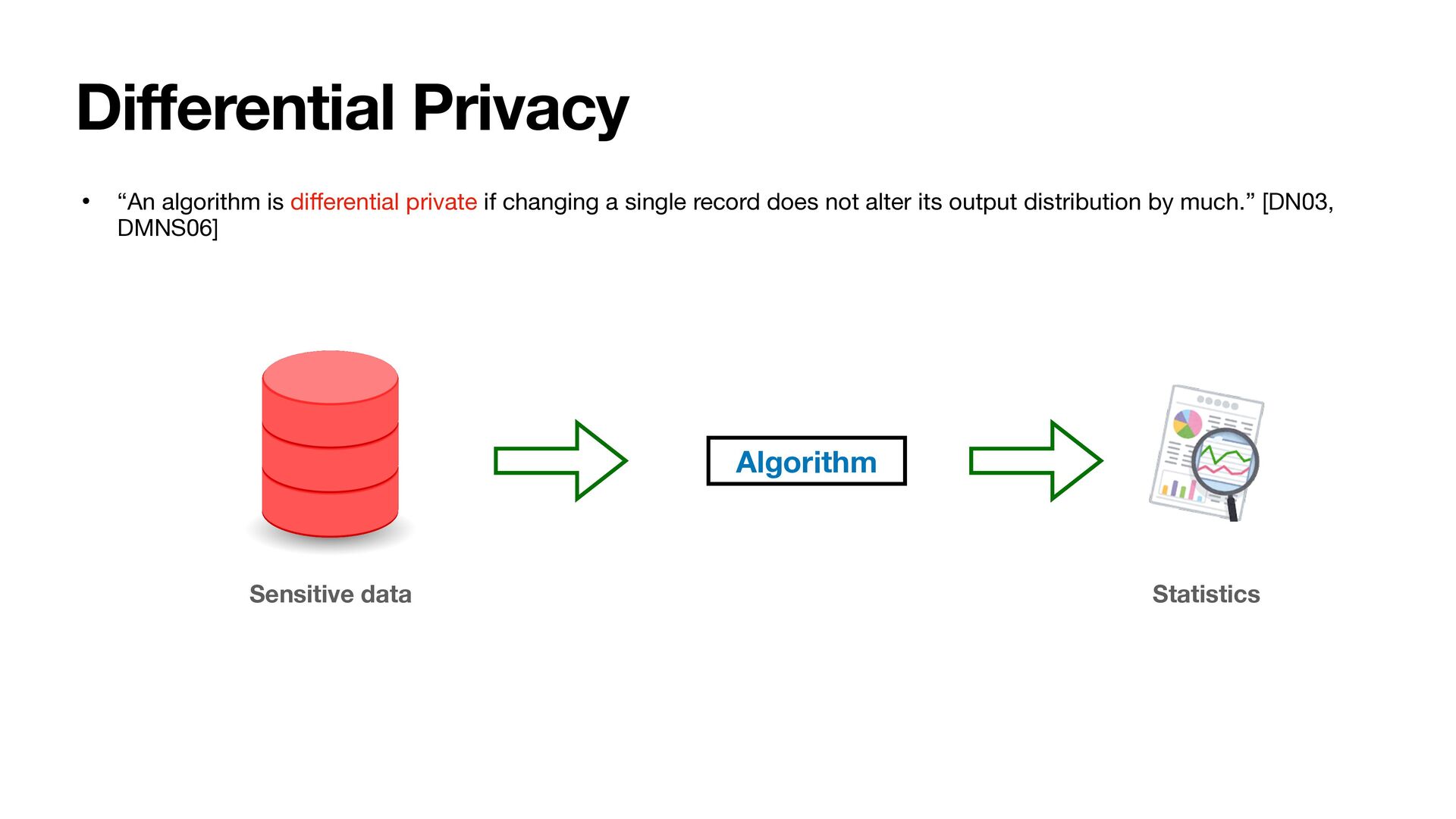
ff er in the data of a single record. • An algorithm is -di ff erentially private if for all neighboring datasets, , and all outputs, : D, D′  M ϵ D, D′  x • The parameter controls the degree of privacy, often called privacy budget. ϵ Pr[M(D) = x] ≤ eϵPr[M(D′  ) = x] Pr[M(D) = x] ≤ (1 + ϵ)Pr[M(D′  ) = x] Note: at small , we can instead write ϵ
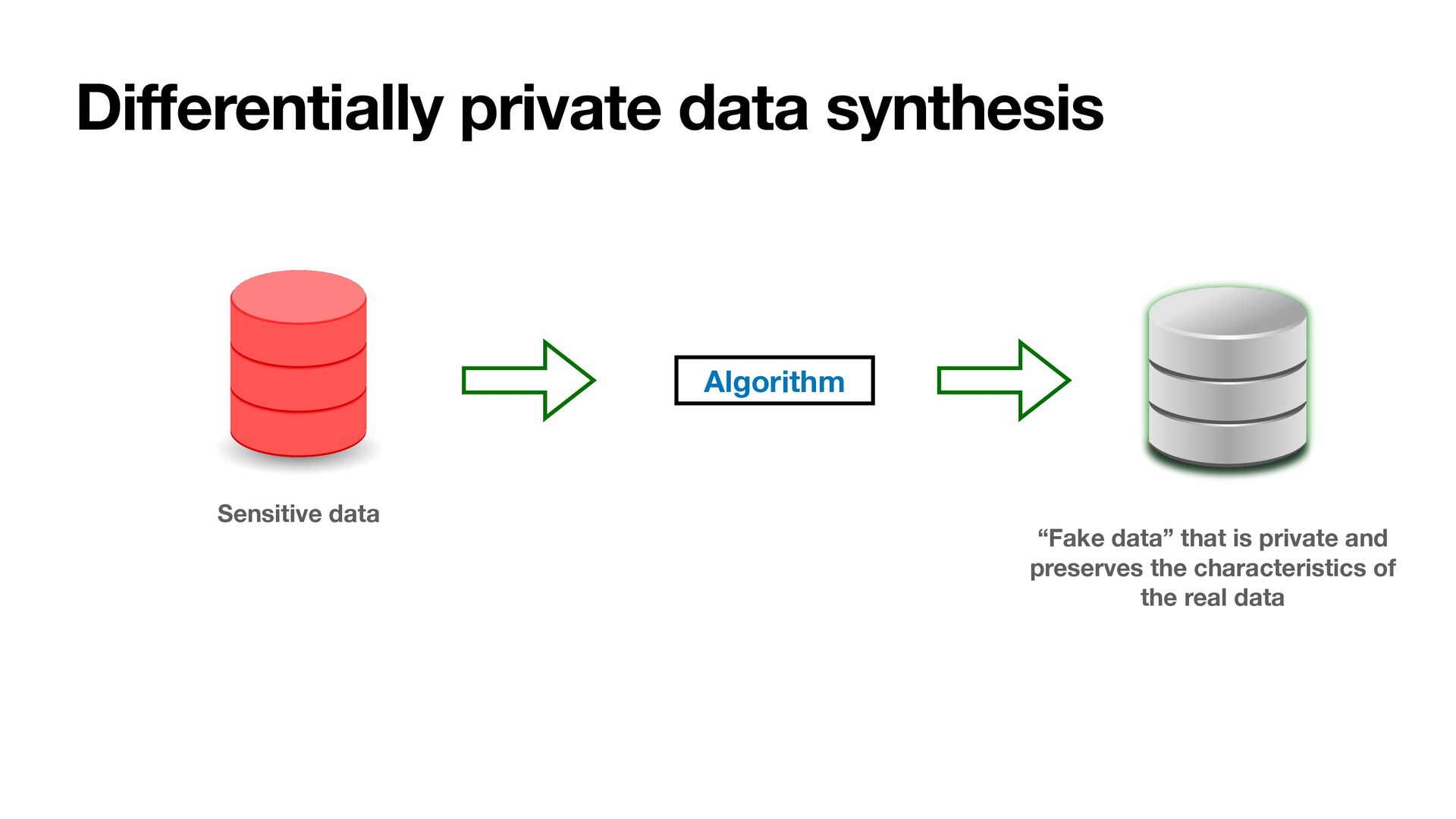
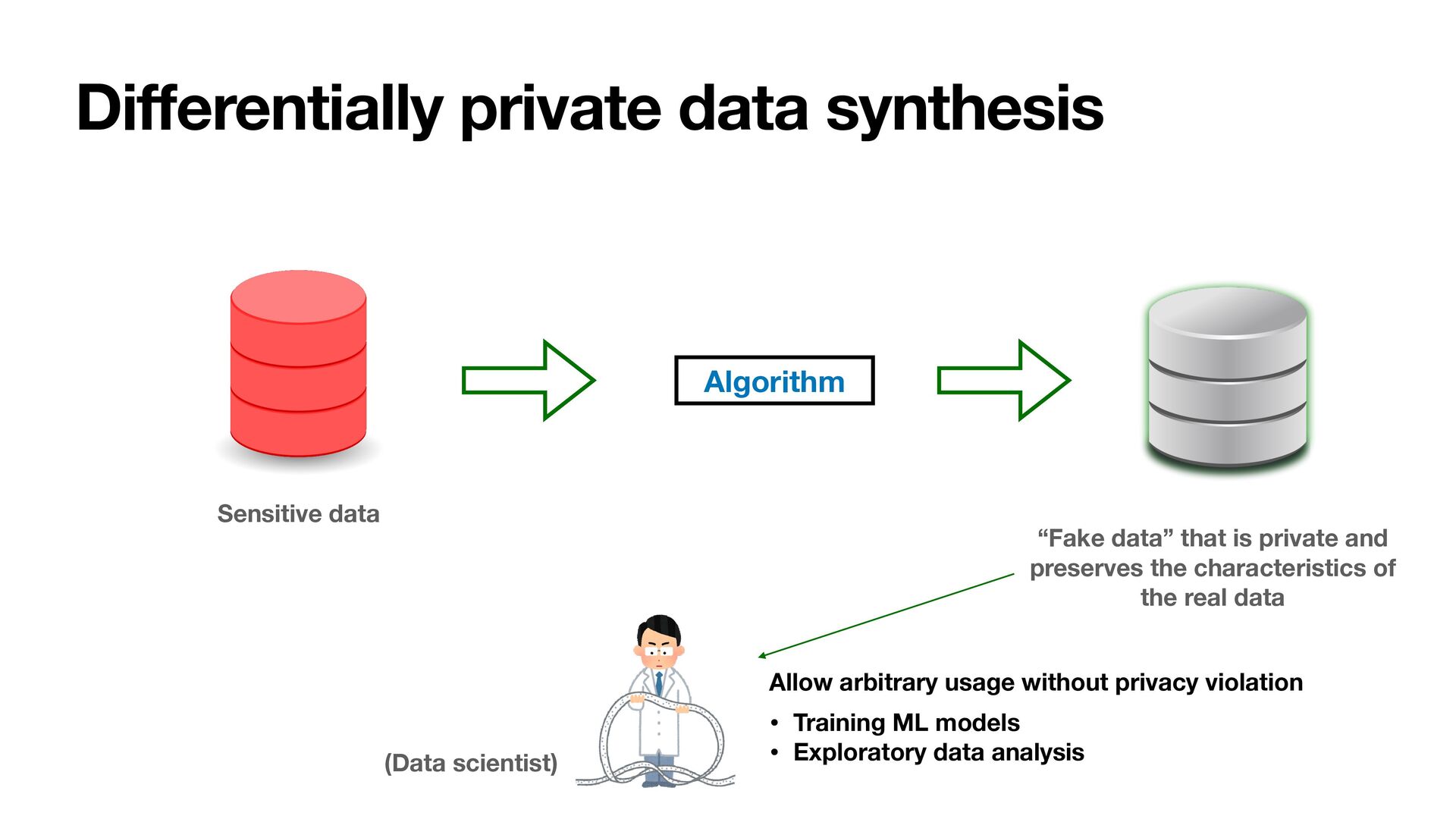
is private and preserves the characteristics of the real data Allow arbitrary usage without privacy violation (Data scientist) • Training ML models • Exploratory data analysis
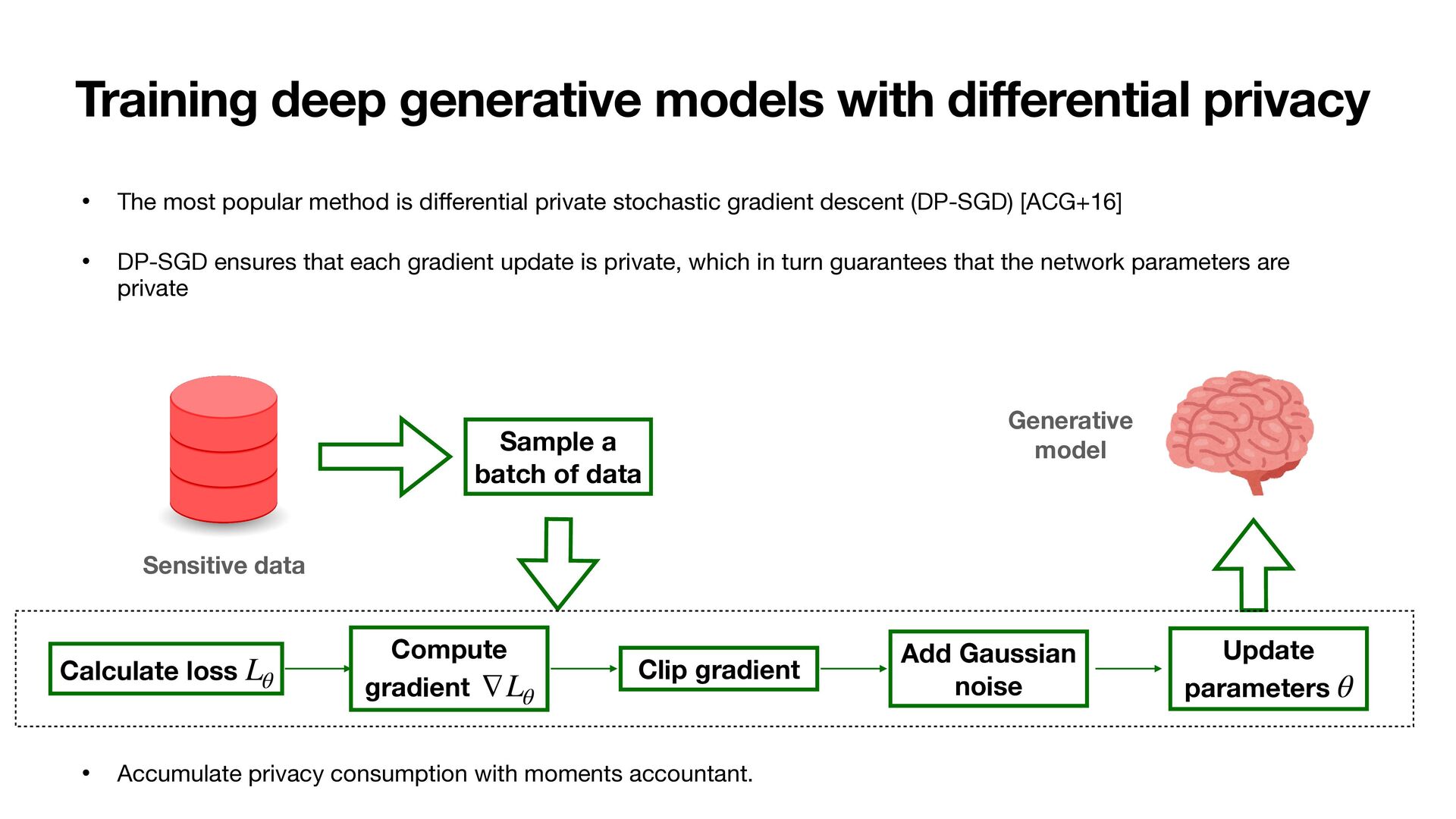
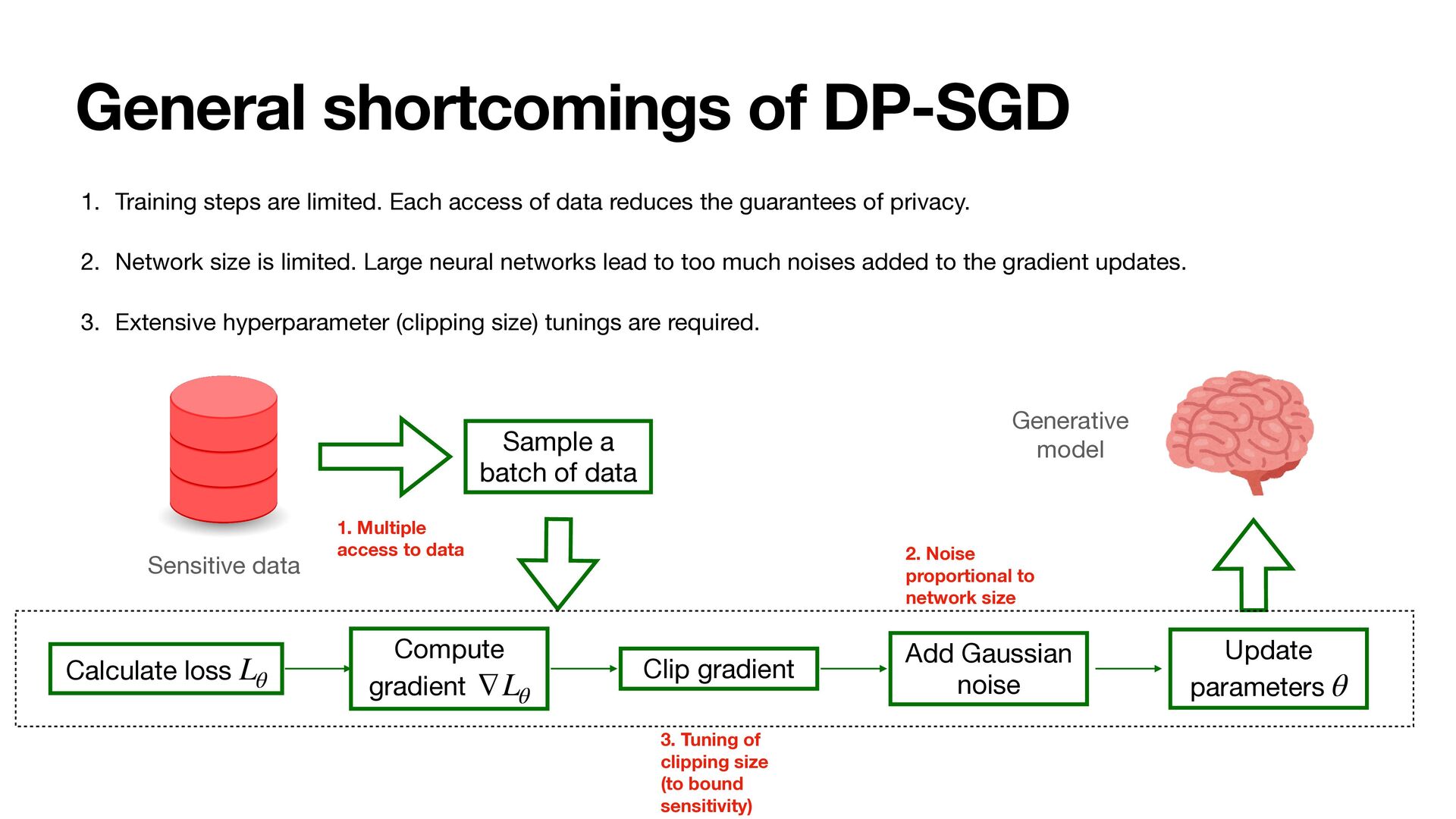
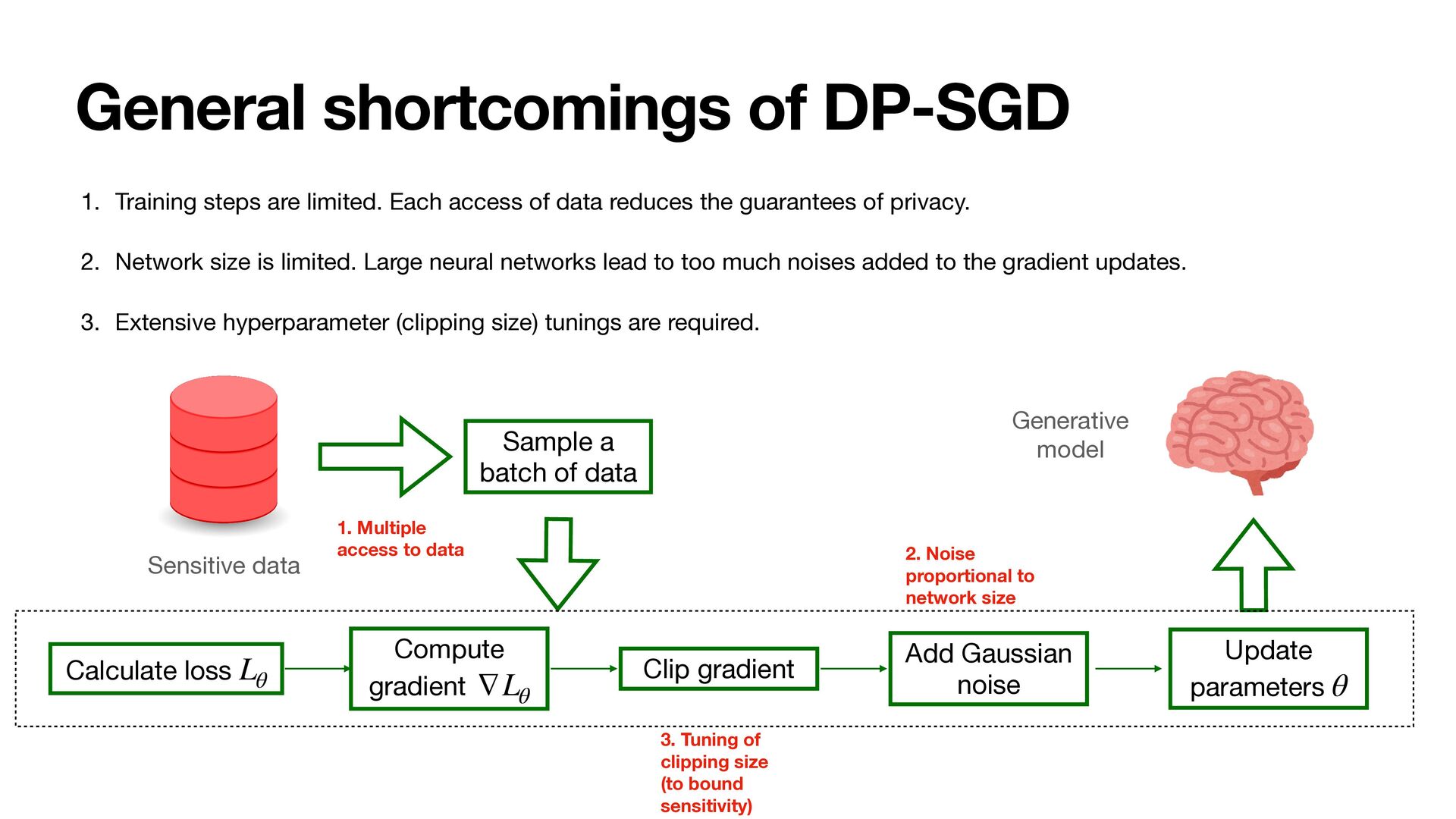
popular method is di ff erential private stochastic gradient descent (DP-SGD) [ACG+16] • DP-SGD ensures that each gradient update is private, which in turn guarantees that the network parameters are private Sensitive data Calculate loss Lθ Compute gradient ∇Lθ Add Gaussian noise Update parameters θ • Accumulate privacy consumption with moments accountant. Clip gradient Generative model Sample a batch of data
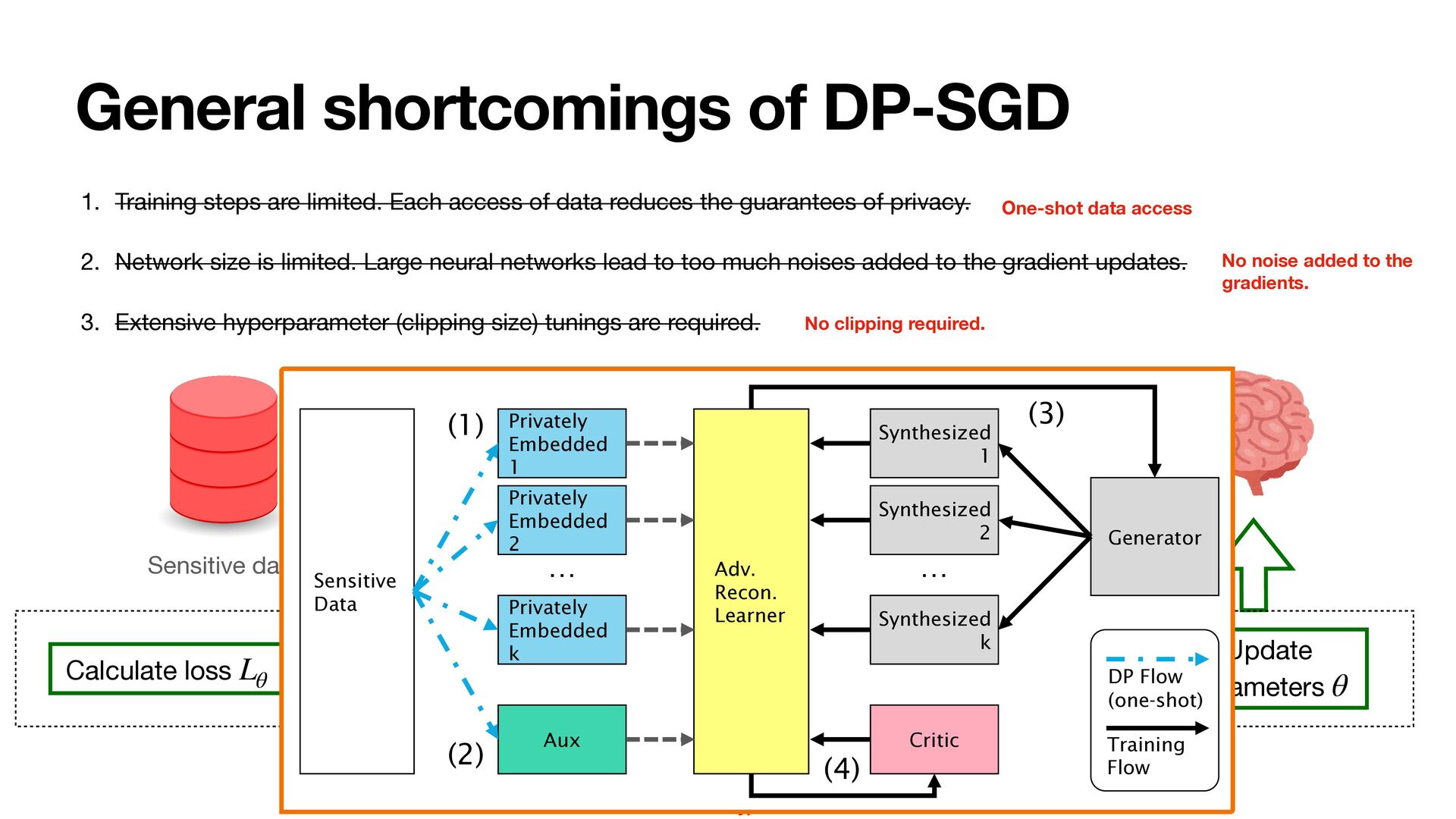
access of data reduces the guarantees of privacy. 2. Network size is limited. Large neural networks lead to too much noises added to the gradient updates. 3. Extensive hyperparameter (clipping size) tunings are required. Sensitive data Calculate loss Lθ Compute gradient ∇Lθ Add Gaussian noise Update parameters θ Clip gradient Generative model Sample a batch of data 1. Multiple access to data 3. Tuning of clipping size (to bound sensitivity) 2. Noise proportional to network size
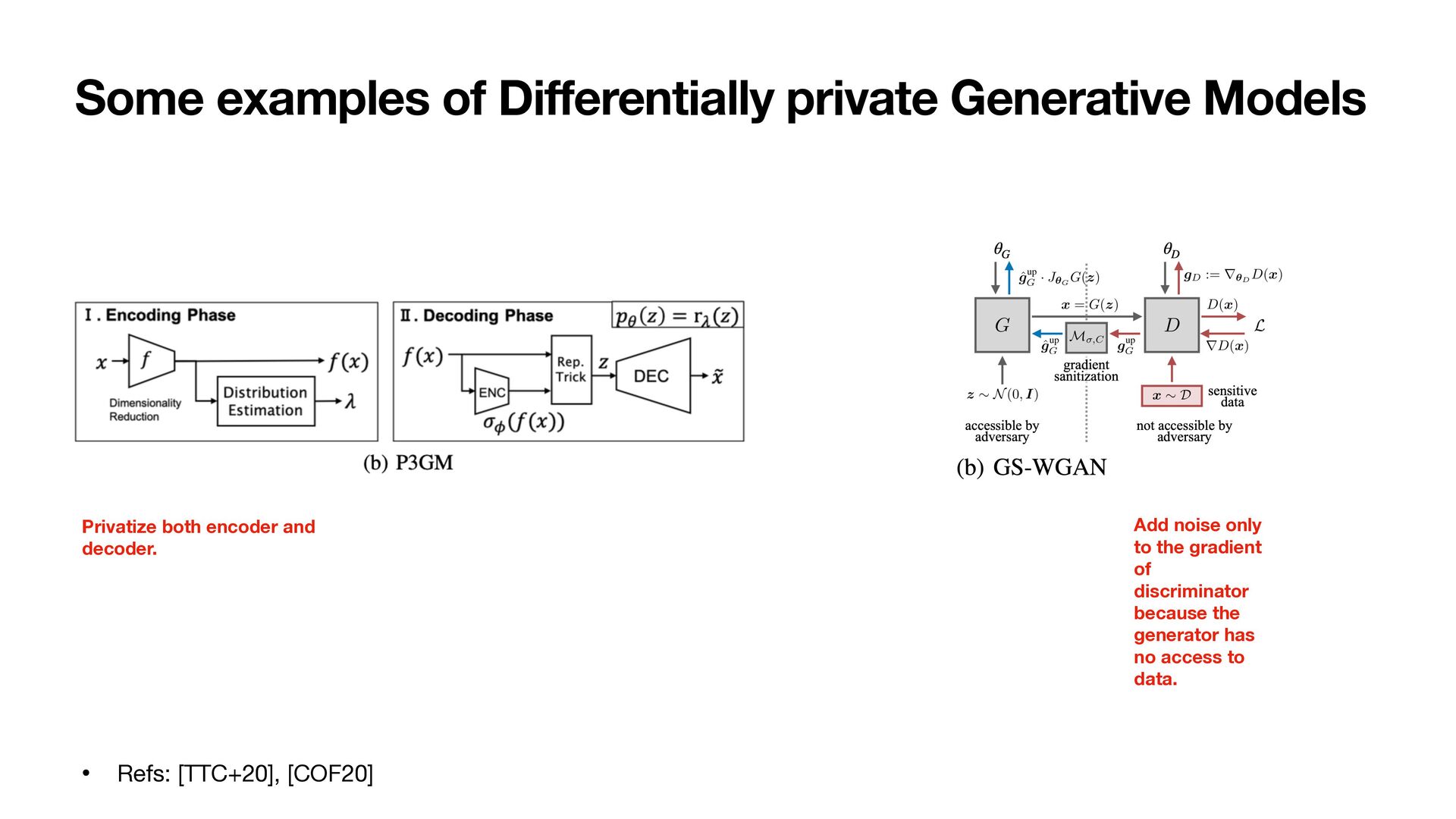
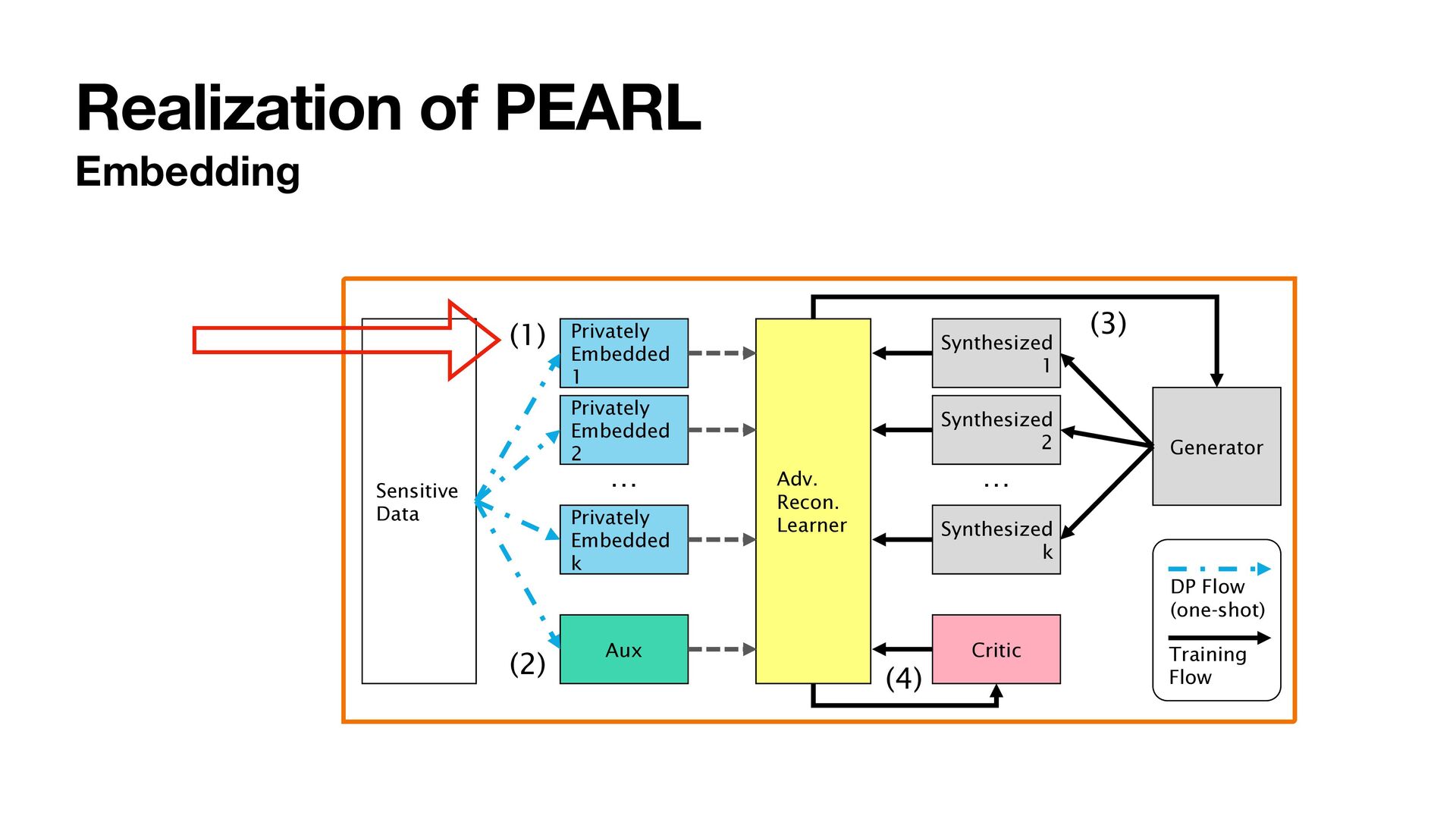
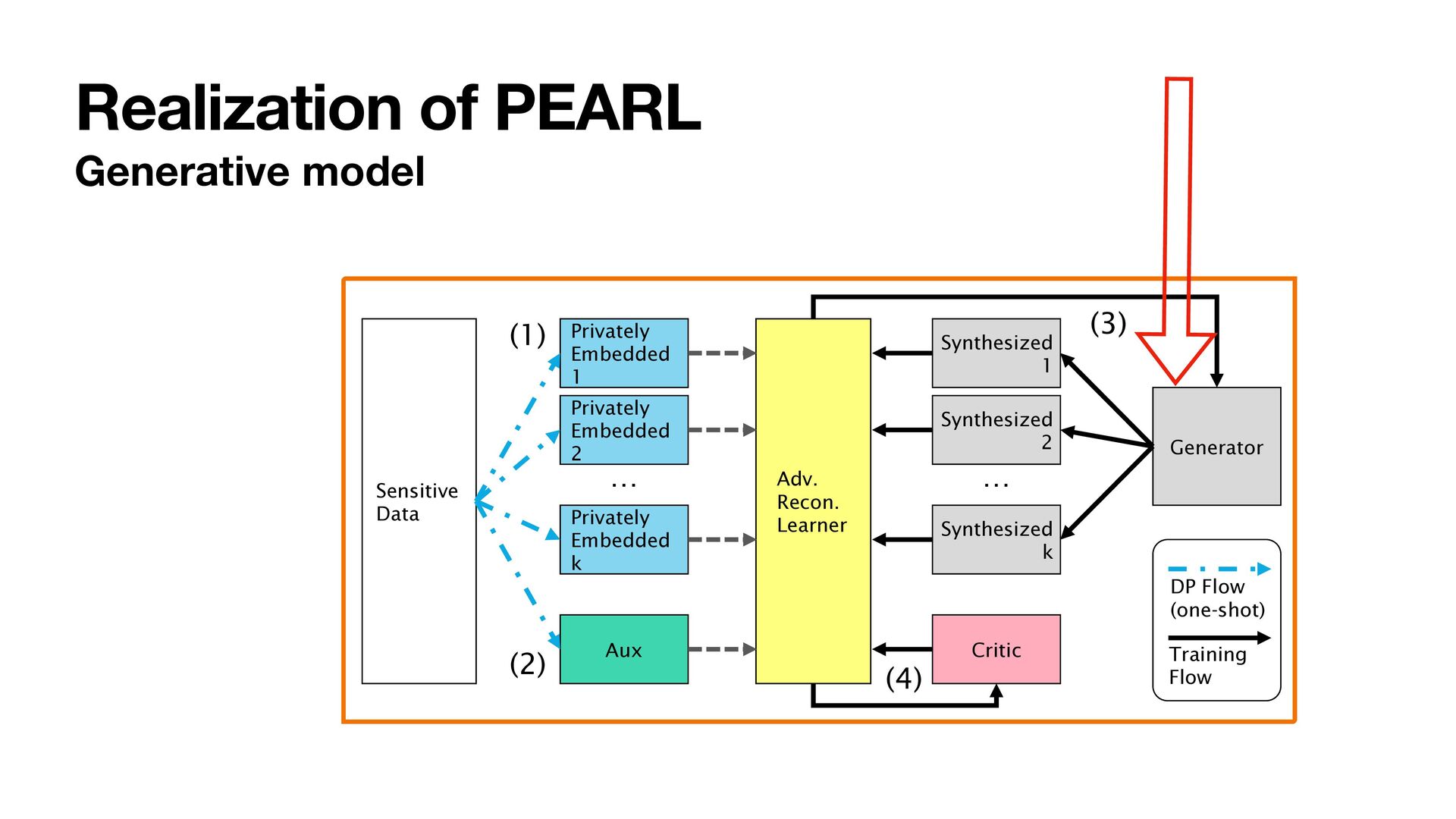
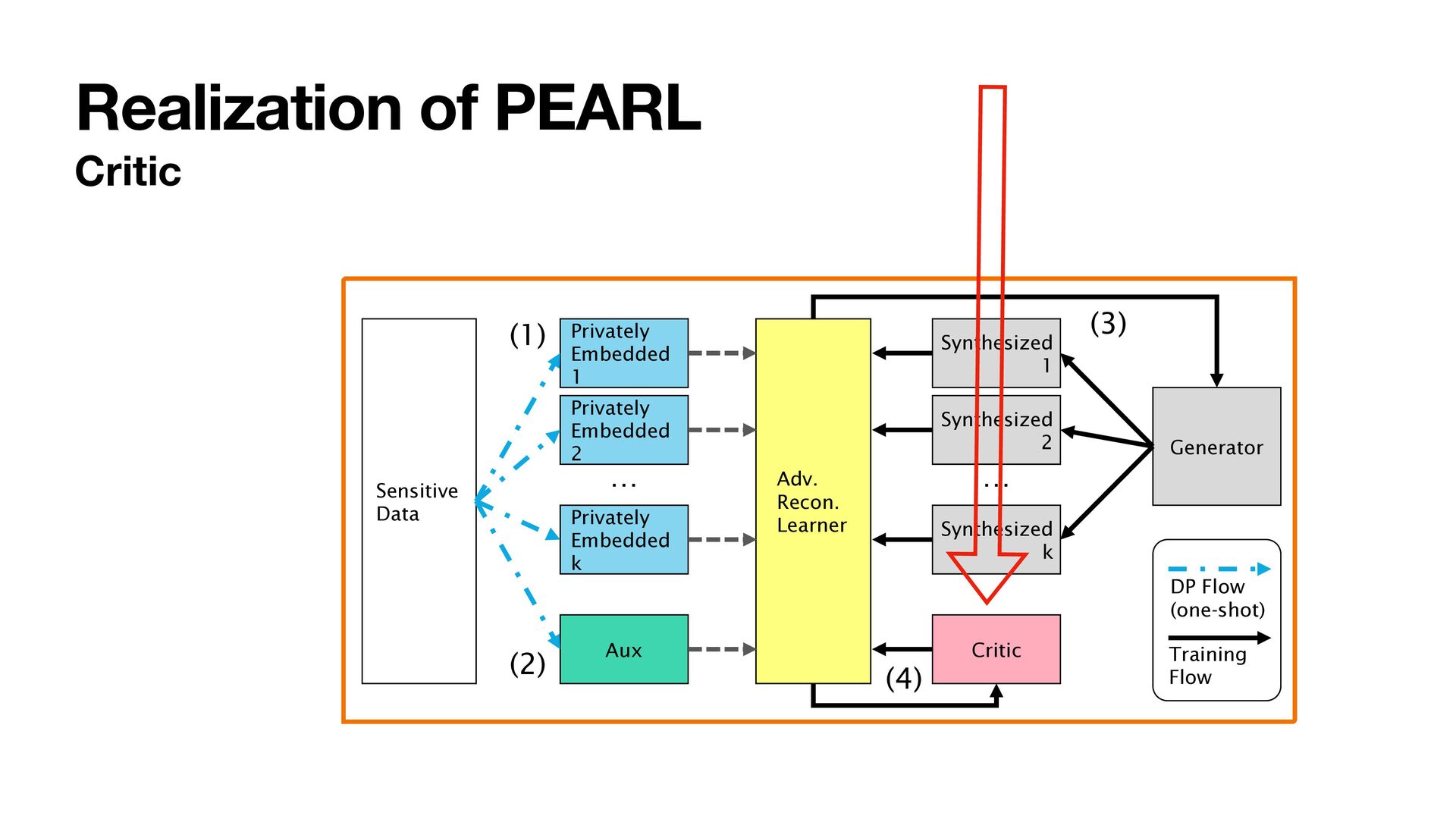
1. Project sensitive data to low-dimensional embeddings and add Gaussian noises to make the embeddings di ff erentially private 2. Obtain auxiliary information useful for training in a di ff erential private manner 3. Train a generator by minimizing the embedding distance 4. Train with an adversarial objective to improve the performance Sensitive Data Privately Embedded 1 Privately Embedded 2 Privately Embedded k Aux Synthesized 1 Synthesized 2 Synthesized k Critic Adv. Recon. Learner Generator (1) (2) (3) (4) DP Flow (one-shot) Training Flow … …
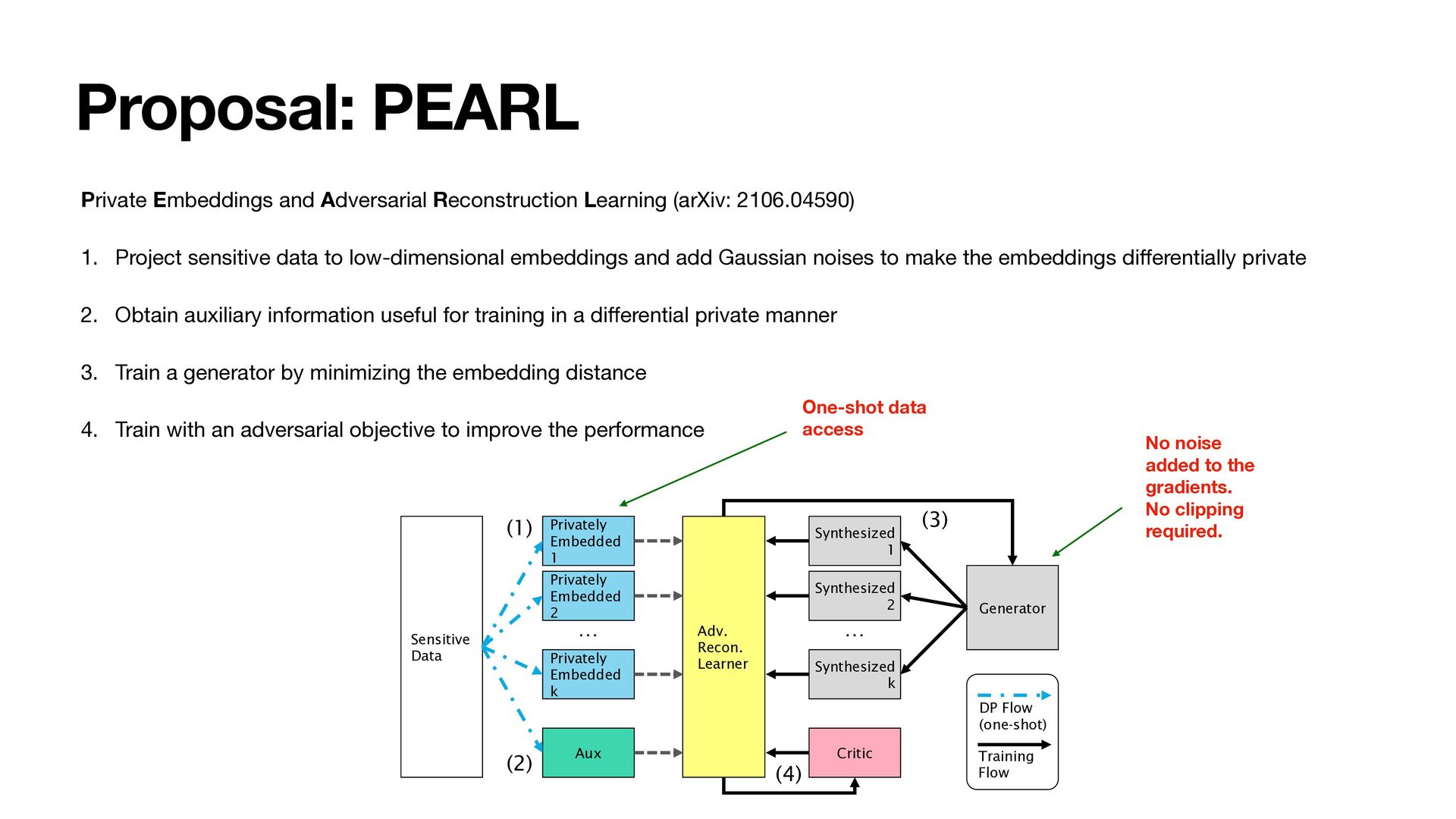
1. Project sensitive data to low-dimensional embeddings and add Gaussian noises to make the embeddings di ff erentially private 2. Obtain auxiliary information useful for training in a di ff erential private manner 3. Train a generator by minimizing the embedding distance 4. Train with an adversarial objective to improve the performance Sensitive Data Privately Embedded 1 Privately Embedded 2 Privately Embedded k Aux Synthesized 1 Synthesized 2 Synthesized k Critic Adv. Recon. Learner Generator (1) (2) (3) (4) DP Flow (one-shot) Training Flow … … One-shot data access No noise added to the gradients. No clipping required.
access of data reduces the guarantees of privacy. 2. Network size is limited. Large neural networks lead to too much noises added to the gradient updates. 3. Extensive hyperparameter (clipping size) tunings are required. Sensitive data Calculate loss Lθ Compute gradient ∇Lθ Add Gaussian noise Update parameters θ Clip gradient Generative model Sample a batch of data 1. Multiple access to data 3. Tuning of clipping size (to bound sensitivity) 2. Noise proportional to network size
access of data reduces the guarantees of privacy. 2. Network size is limited. Large neural networks lead to too much noises added to the gradient updates. 3. Extensive hyperparameter (clipping size) tunings are required. Sensitive data Calculate loss Lθ Compute gradient ∇Lθ Add Gaussian noise Update parameters θ Clip gradient Generative model Sample a batch of data 1. Multiple access to data 3. Tuning of clipping size (to bound sensitivity) 2. Noise proportional to network size Sensitive Data Privately Embedded 1 Privately Embedded 2 Privately Embedded k Aux Synthesized 1 Synthesized 2 Synthesized k Critic Adv. Recon. Learner Generator (1) (2) (3) (4) DP Flow (one-shot) Training Flow … … One-shot data access No noise added to the gradients. No clipping required.
[eit⋅x] = ∫ ℝd eit⋅xdℙ ≃ ∑ x eit⋅x • Let be a random variable with probability distribution , the corresponding characteristic function is x ℙ • This mathematical operation is equivalent to Fourier transformation from the signal processing point of view. is frequency. • Also de fi ne Characteristic function distance between two distributions: t C2(ℙ, ℚ) = ∫ |Φℙ (t) − Φℚ (t)|2 ω(t)dt • It can be shown that with appropriately de fi ned density , ω(t) C(ℙ, ℚ) = 0 ⟺ ℙ = ℚ (empirical CF)
Let be the sensitive data. We sample a fi nite number of from , and add noise to the empirical CF to make it DP. x t ω(t) • De fi ne a generator that takes a latent vector (noise) as input and outputs “fake” Gθ z x inf θ∈Θ k ∑ i=1 ˜ Φℙ (ti ) − ̂ Φ ℚ (ti ) 2 • We can then train the generator with the following objective minimizing CF distance: Add noise to for sampled frequencies , t ̂ Φ ℚ (t) = ∑ y eit⋅y with y = Gθ (z) where is no. of sampled frequencies k ˜ Φℙ (t) No noise required because this term has no access to data
about so far. • The idea is to treat as an adversarial critic to provide more discriminative features for training , like in GANs • cannot be optimized directly. Known methods, e.g., reparametrization tricks require access to data, violating privacy. ω(t) ω(t) Gθ ω(t) • We propose to re-weight the CFs to choose the “best” weight for training while preserving privacy by performing minimax optimization: Gθ inf θ∈Θ sup ω∈Ω Cω (ℙ, ℚθ ) C2(ℙ, ℚ) = ∫ |Φℙ (t) − Φℚ (t)|2 ω(t)dt
optimization is proposed: • Additionally, we are able to show that the above optimization has the following theoretical properties: 1. Continuity and di ff erentiability (allows generator to be trained via gradient descent) 2. Weak convergence (good for training GAN-like models [ACB’17]) 3. Consistency at in fi nite sampling limit (ensures the maximization procedure is consistent asymptotically) inf θ∈Θ sup ω∈Ω k ∑ i=1 ω(ti ) ω0 (ti ) ˜ Φℙ (ti ) − ̂ Φ ℚ (ti ) 2
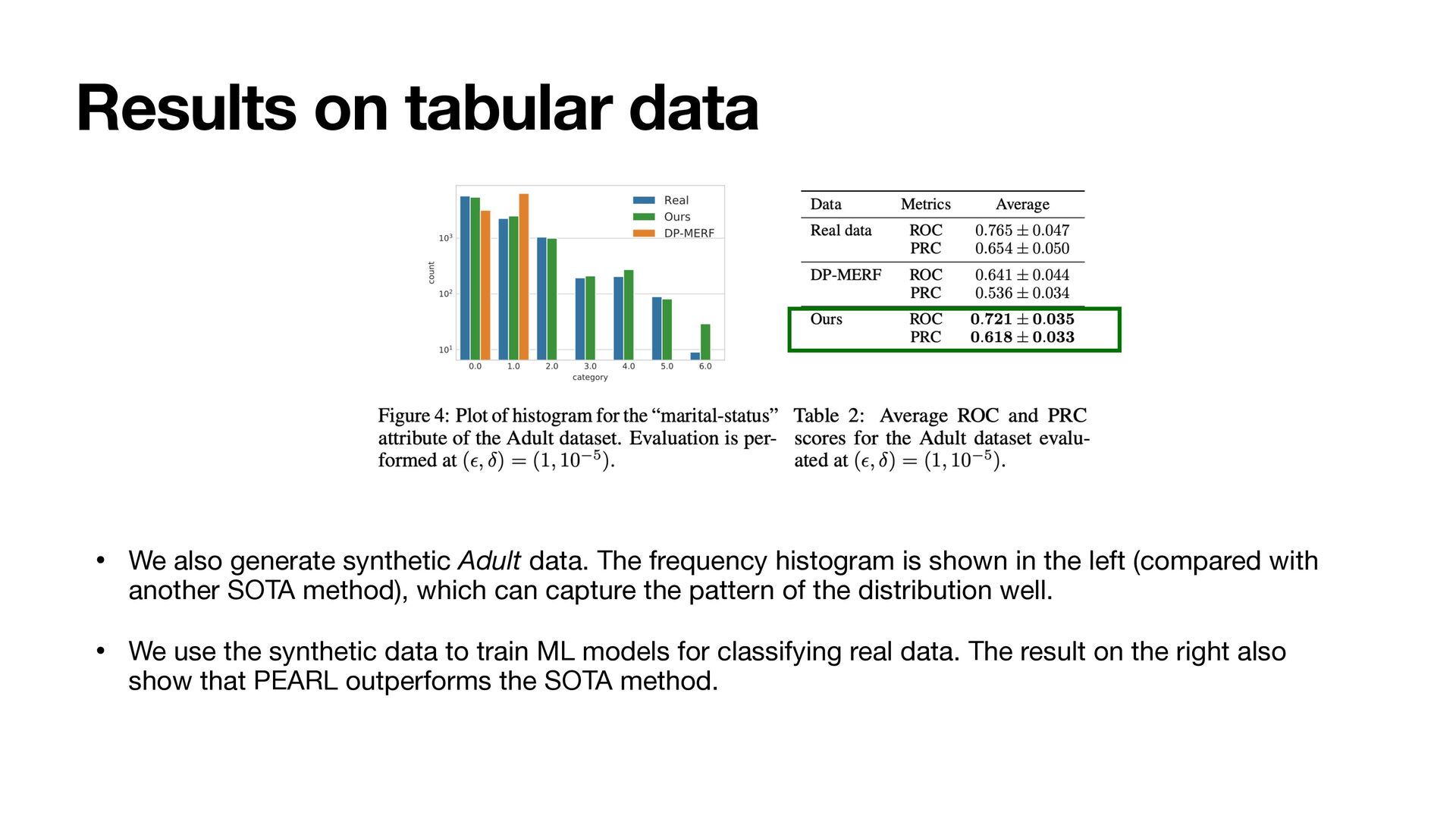
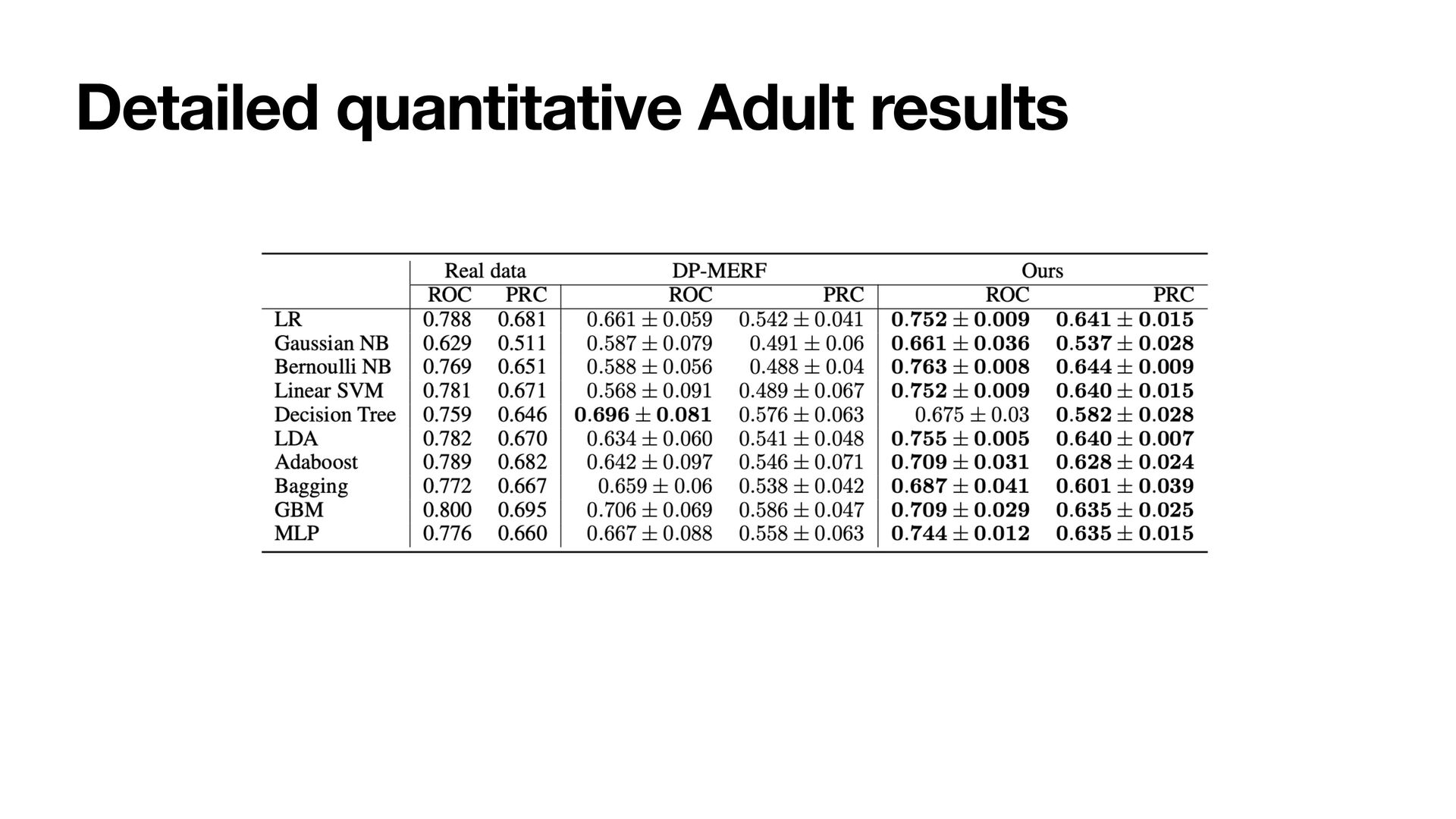
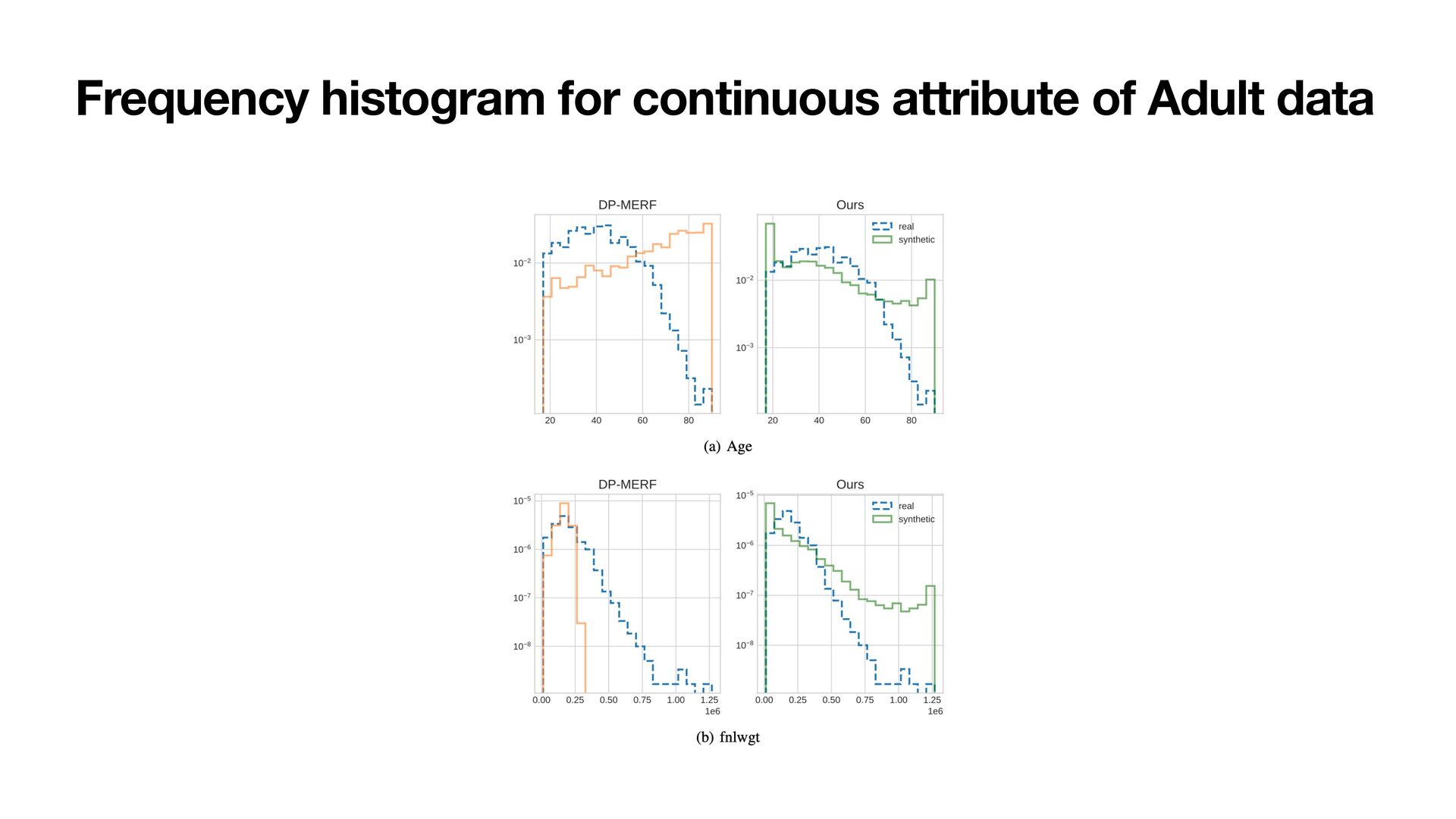
data. The frequency histogram is shown in the left (compared with another SOTA method), which can capture the pattern of the distribution well. • We use the synthetic data to train ML models for classifying real data. The result on the right also show that PEARL outperforms the SOTA method.
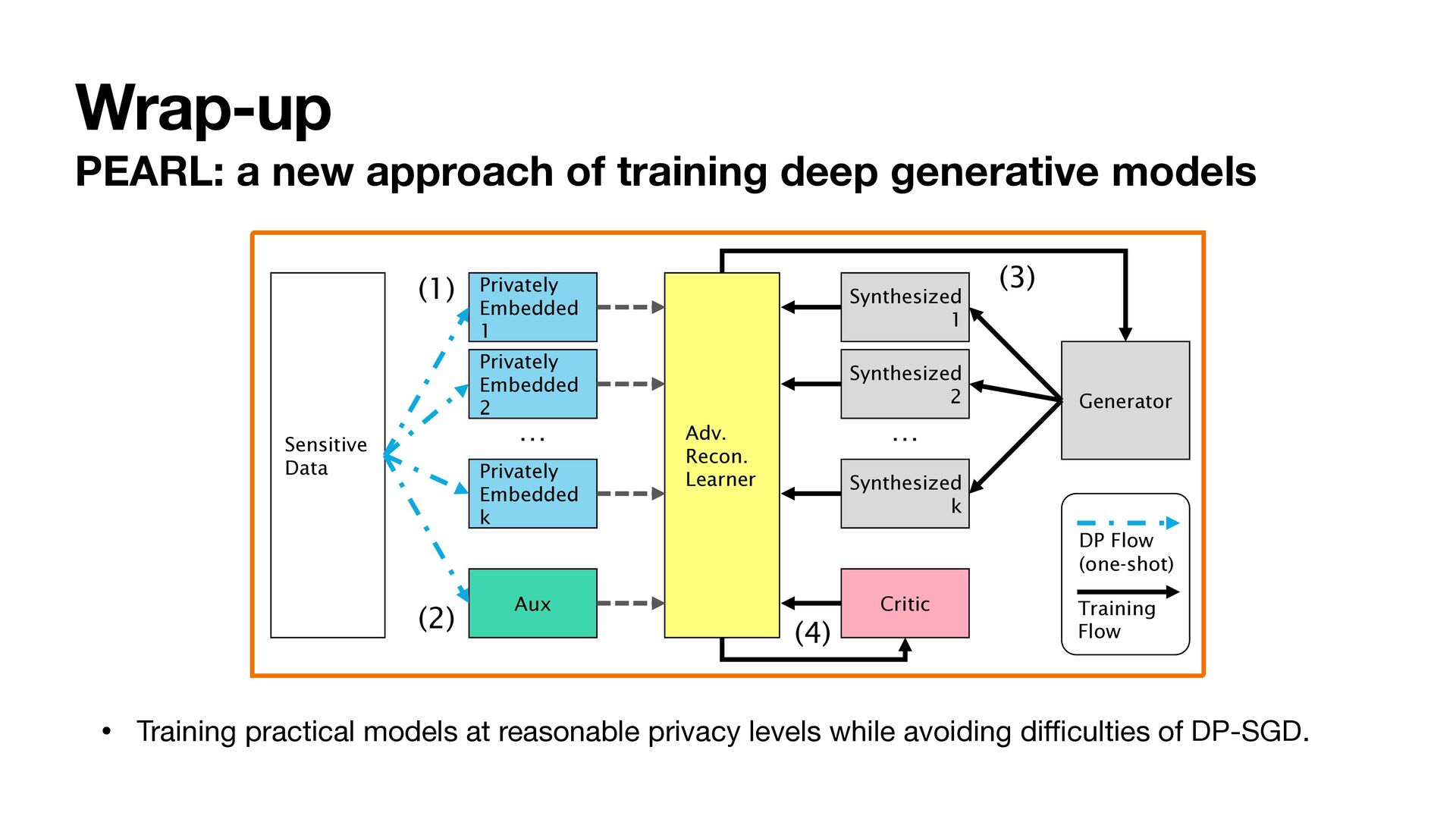
1 Sensitive Data Privately Embedded 1 Privately Embedded 2 Privately Embedded k Aux Synthesized 1 Synthesized 2 Synthesized k Critic Adv. Recon. Learner Generator (1) (2) (3) (4) DP Flow (one-shot) Training Flow … … • Training practical models at reasonable privacy levels while avoiding di ffi culties of DP-SGD.
generative model. • Tabular table: use DP-mean to train Gaussian Mixture Model to better model continuous attributes. • Class imbalance: get the number of samples in each class to perform re-weighting to train more balanced model.
of data points). • We estimate the mean privately instead because it is more tractable. • The privacy budget for this calculation is accounted for appropriately ω0 (t)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}