team •Kafka contributor •KIP-764: Configurable backlog size for creating Acceptor •Author of tlaplus-intellij-plugin •https://github.com/ocadaruma/tlaplus-intellij-plugin
to make our cluster highly reliable •e.g. •“Reliability Engineering Behind The Most Trusted Kafka Platform” (LINE DEVELOPER DAY 2019) •"Investigating Request Delay in a Large-Scale Kafka Cluster Caused by TCP" (LINE DEVELOPER DAY 2021)
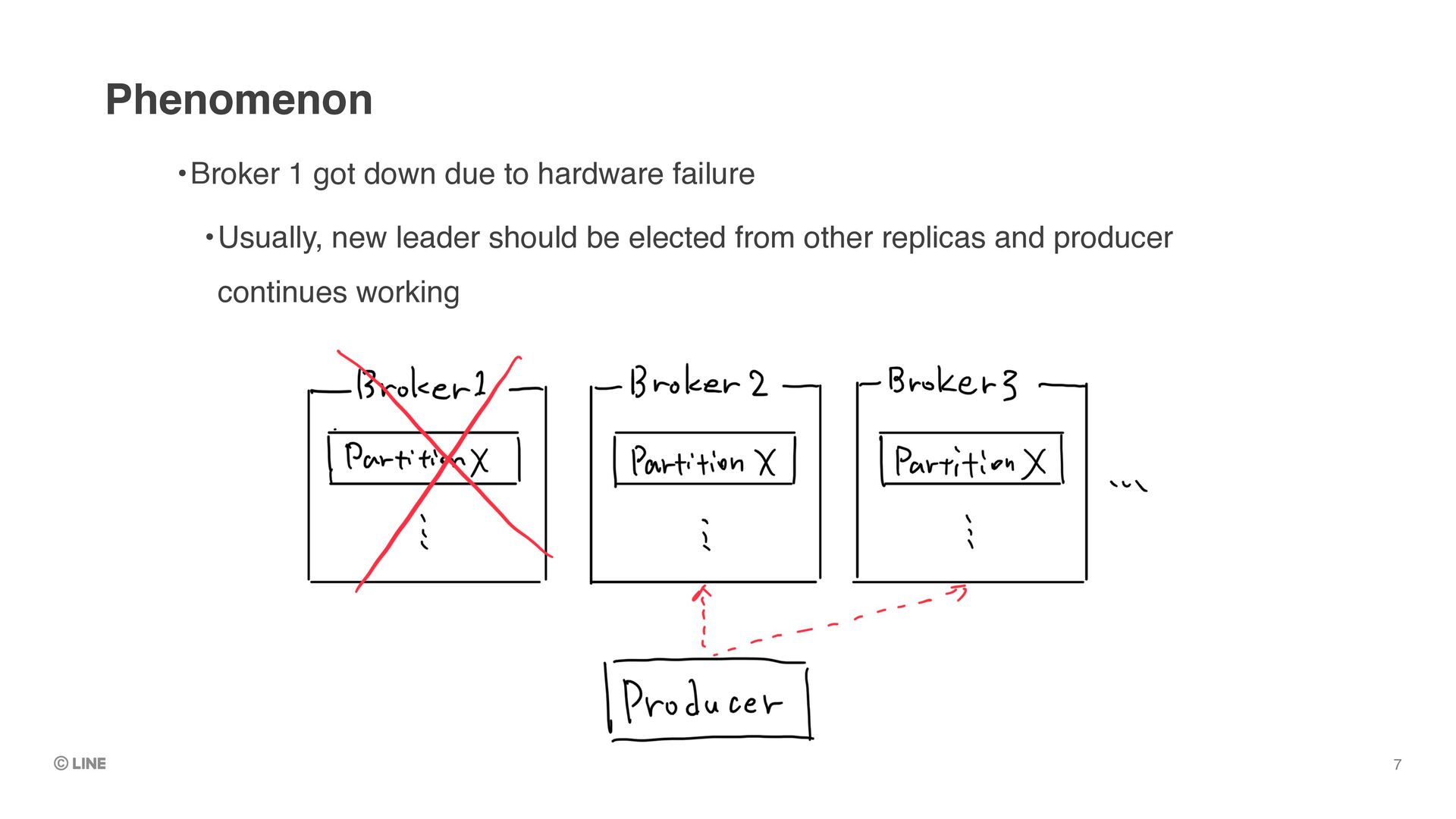
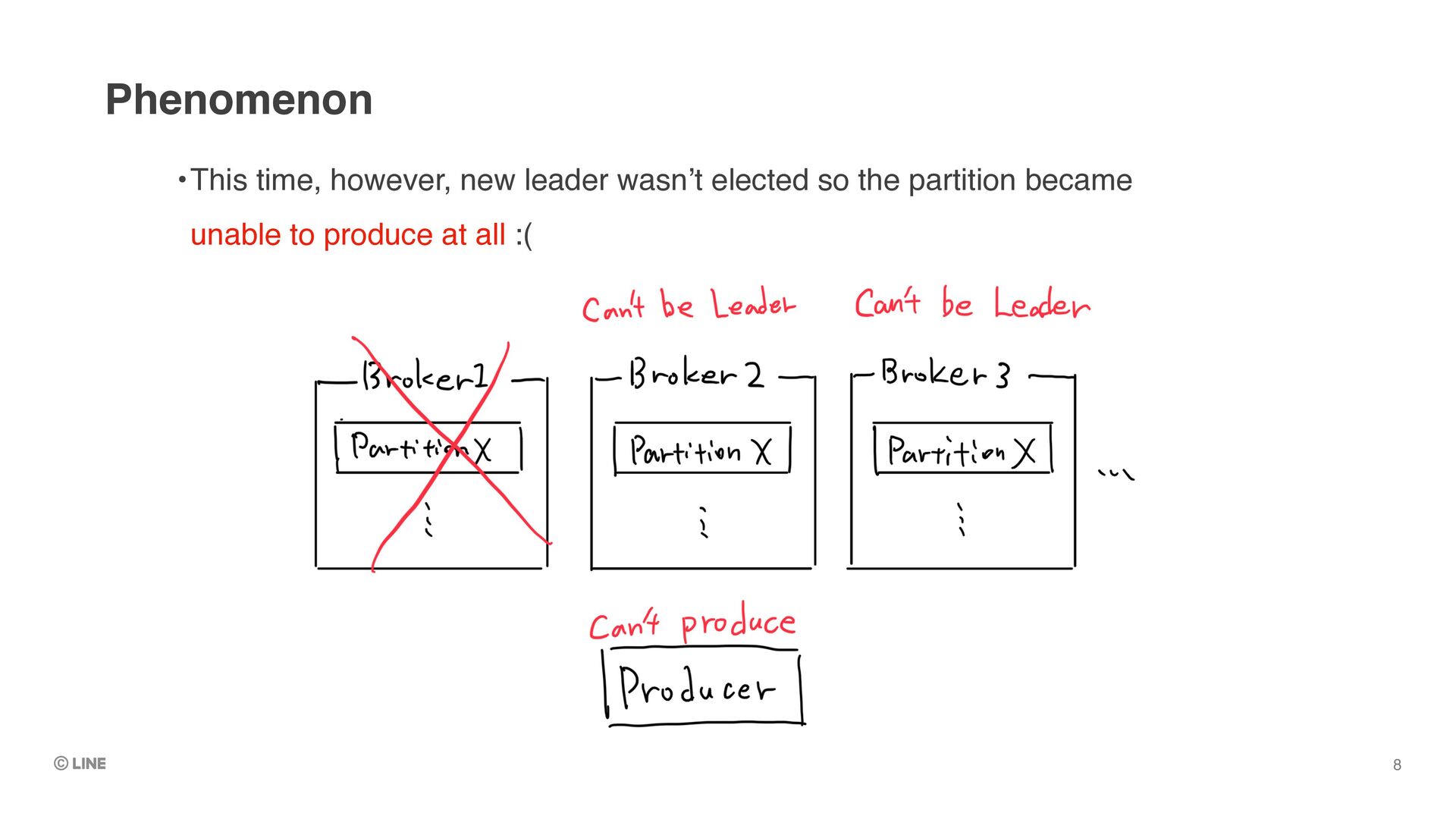
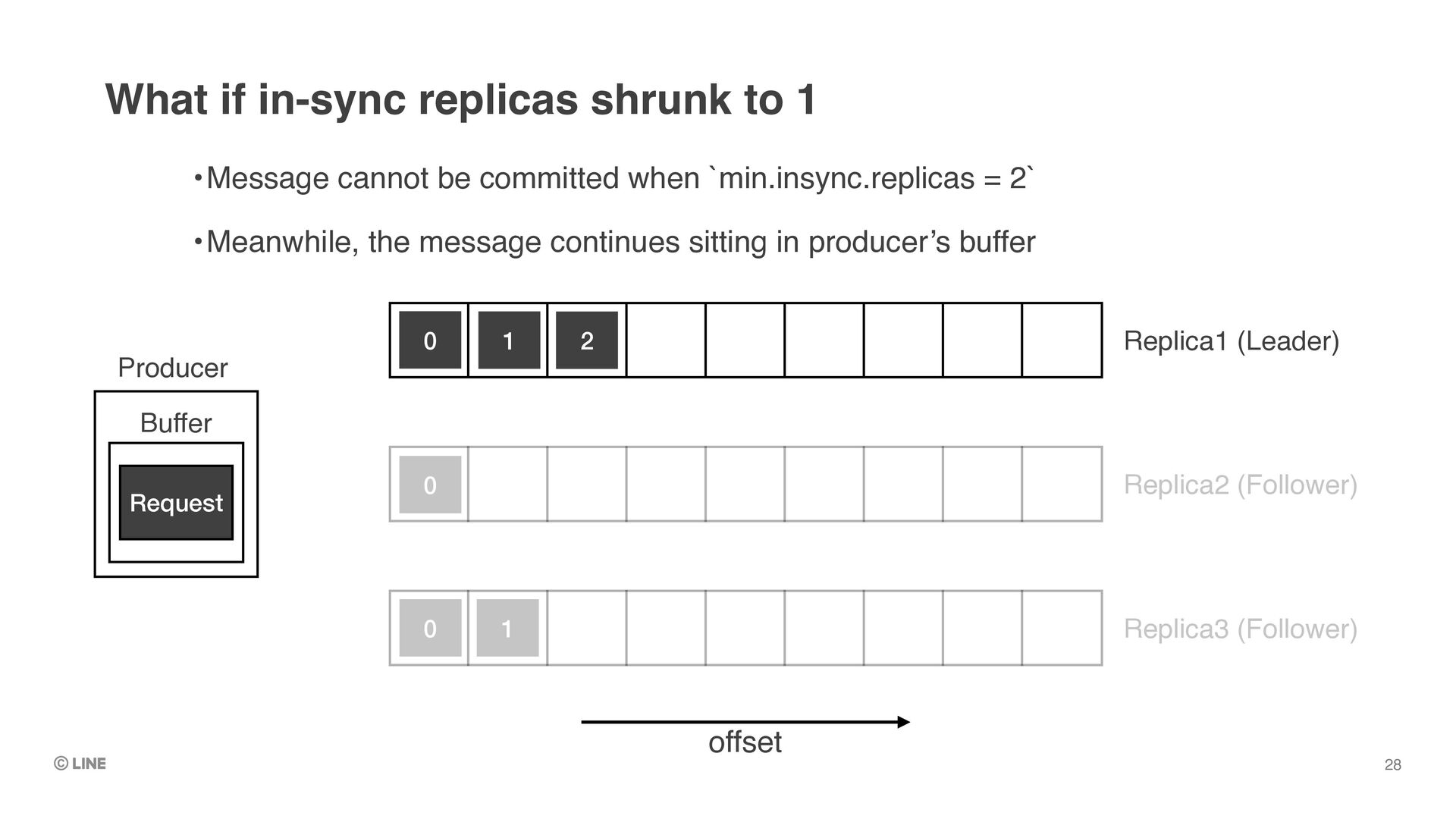
to recover the situation •Meanwhile, produce / consume against the partition is unable Possible handlings for offline partition: Start up the failed leader (our choice) 15 => We decided doing this to avoid data-loss
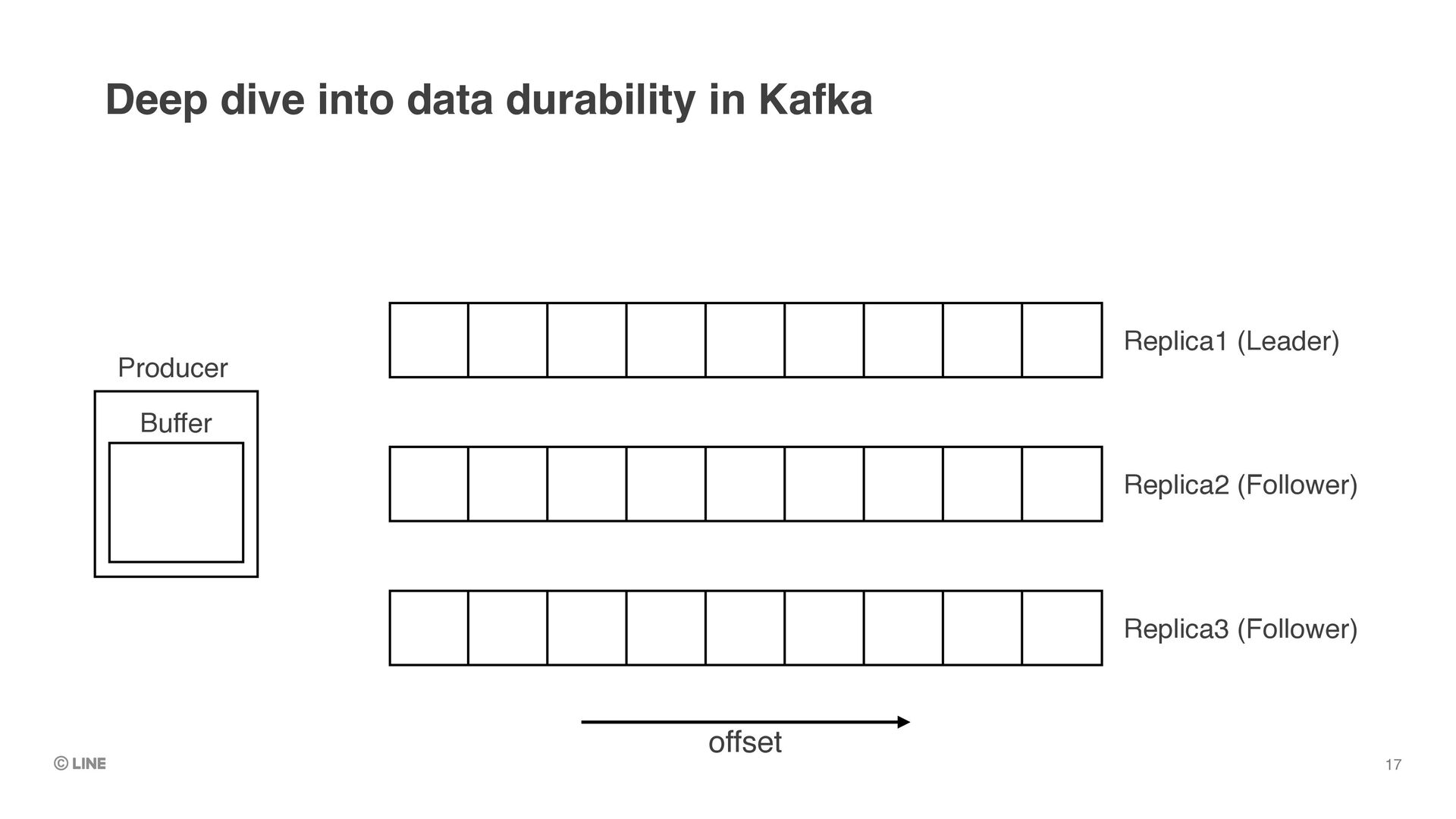
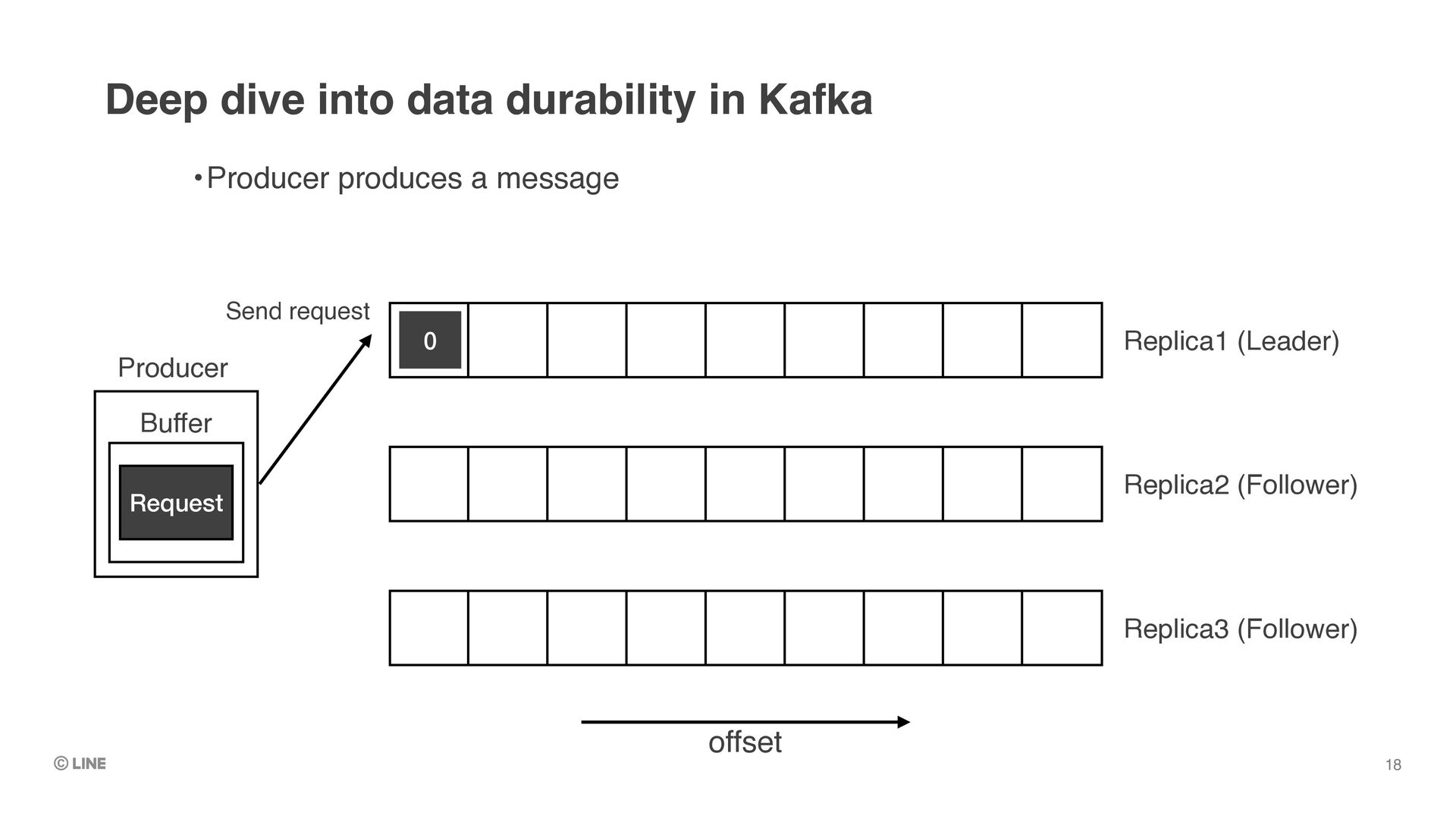
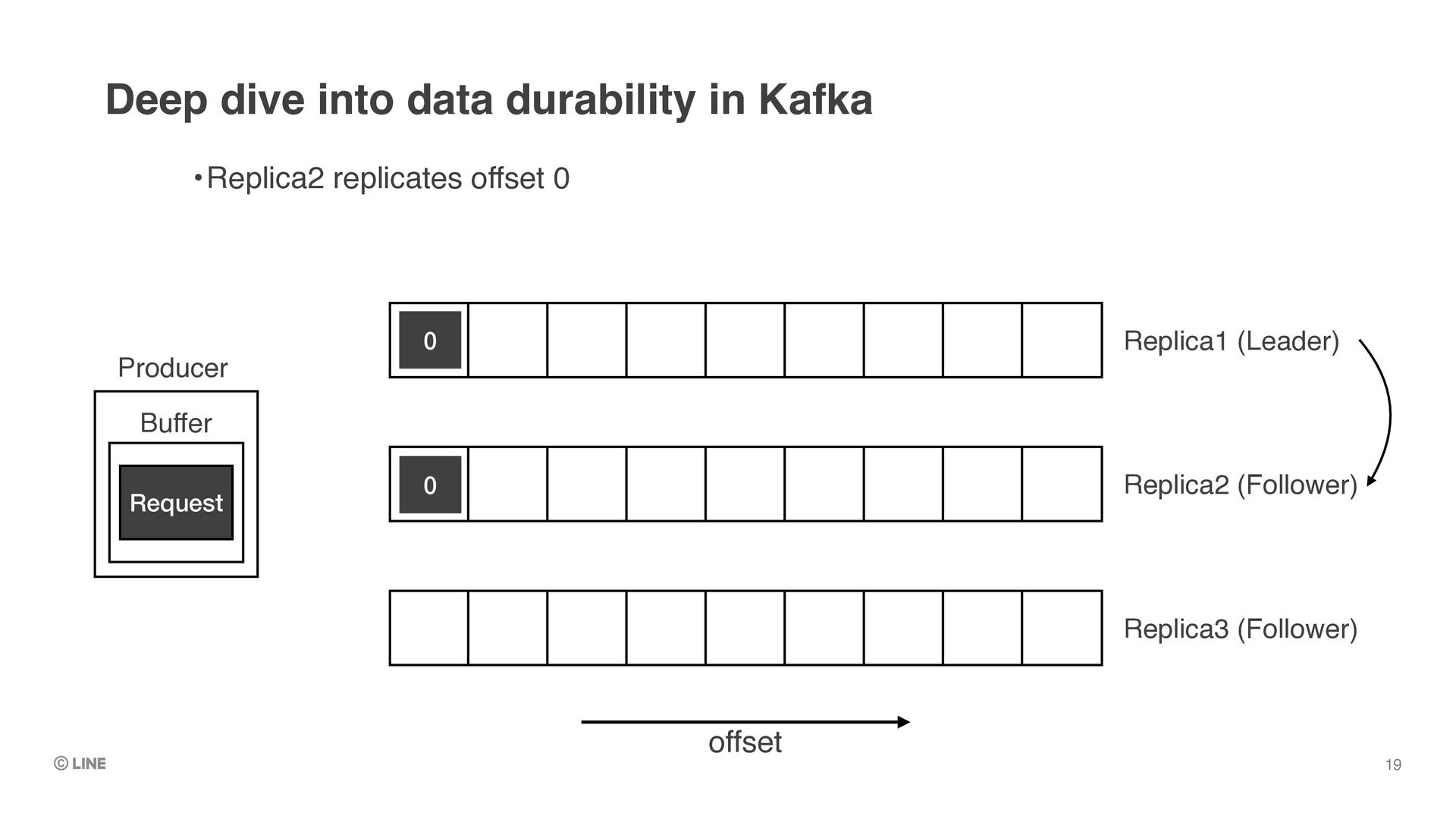
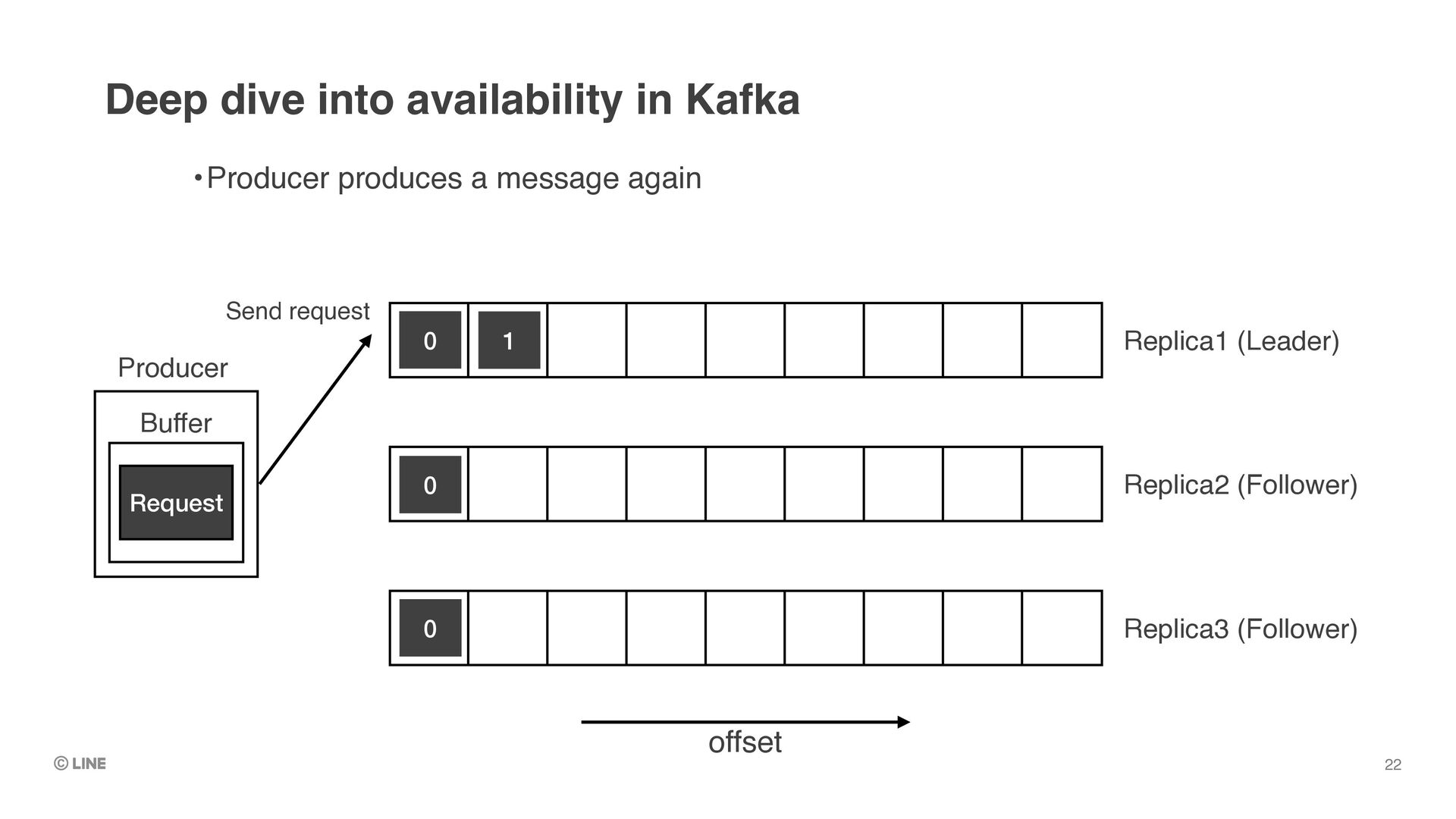
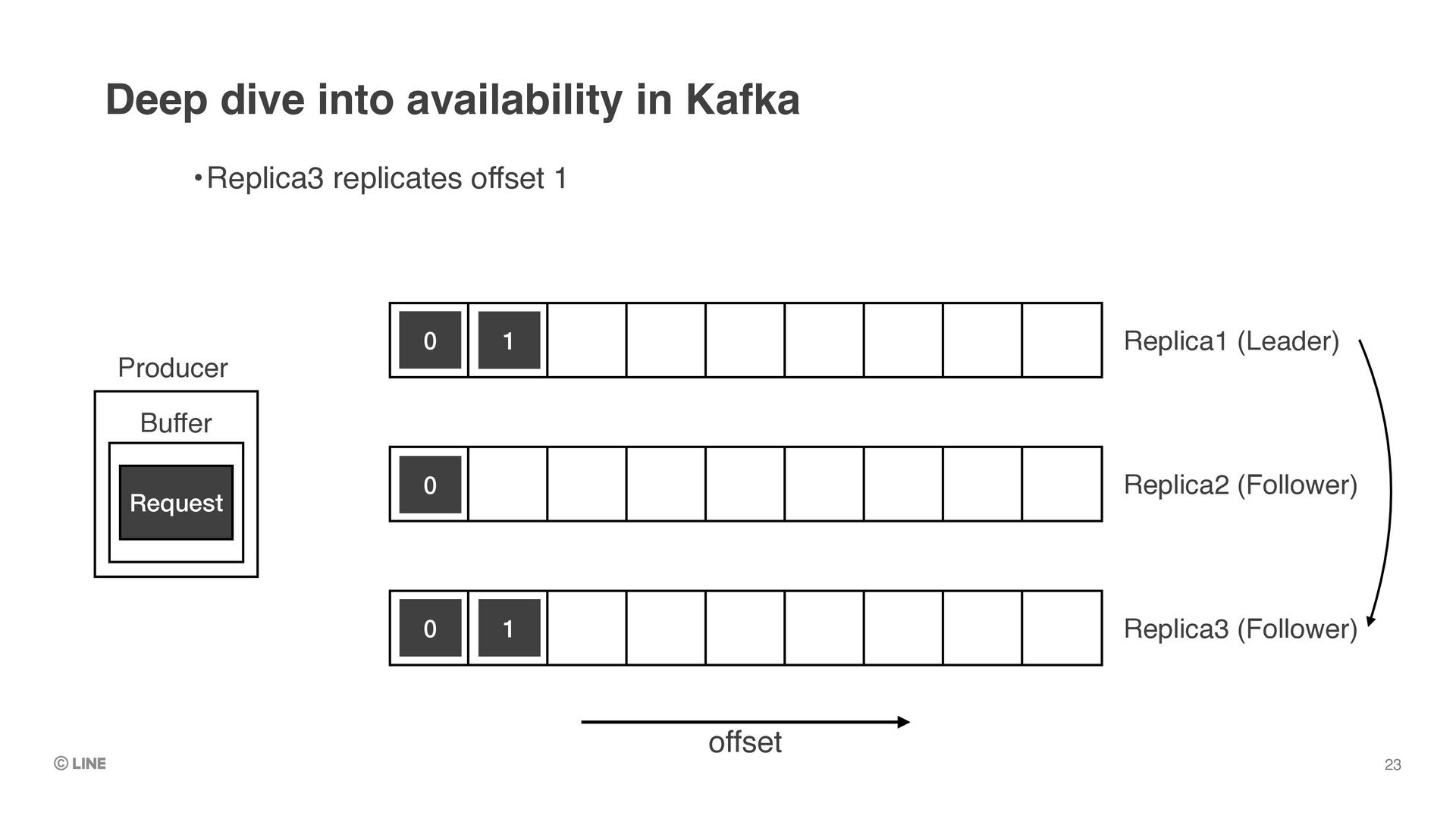
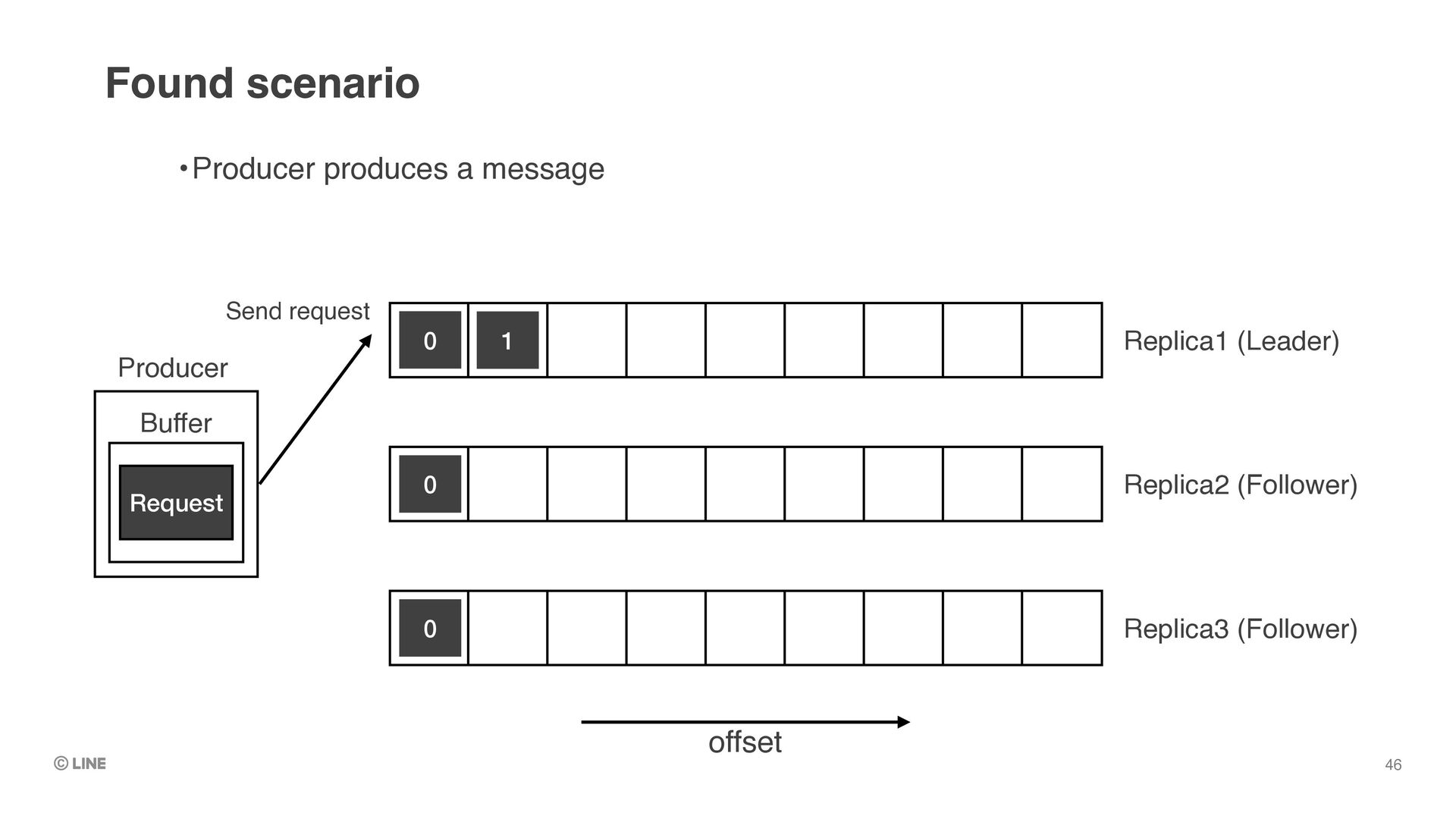
upon successful return of produce requests •(Assumes producer is configured with `acks = all`) •Messages replicated to all in-sync replicas are called “committed messages” •≠ “committed offset” (which means the checkpoint of consumer position) Deep dive into data durability in Kafka
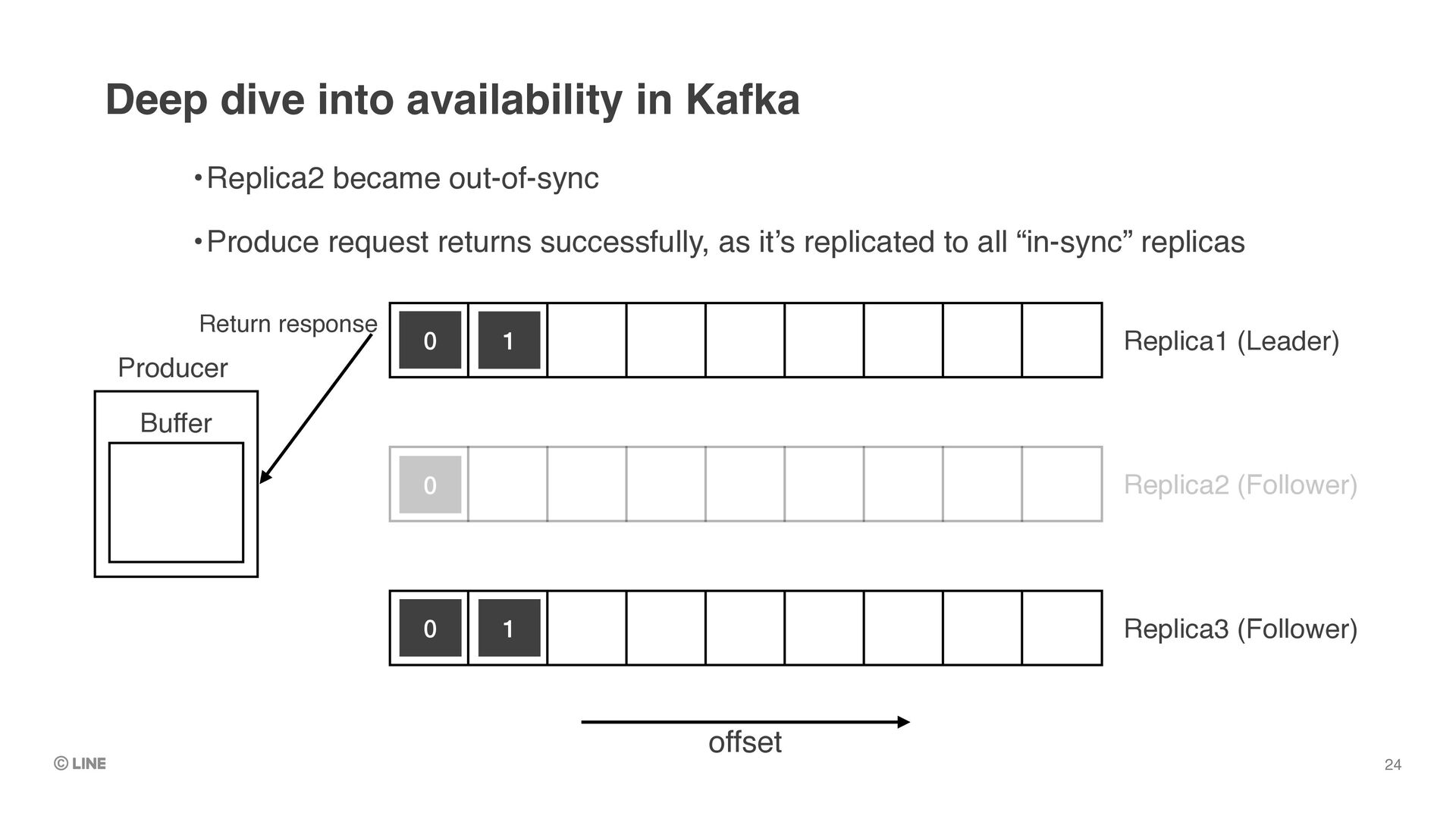
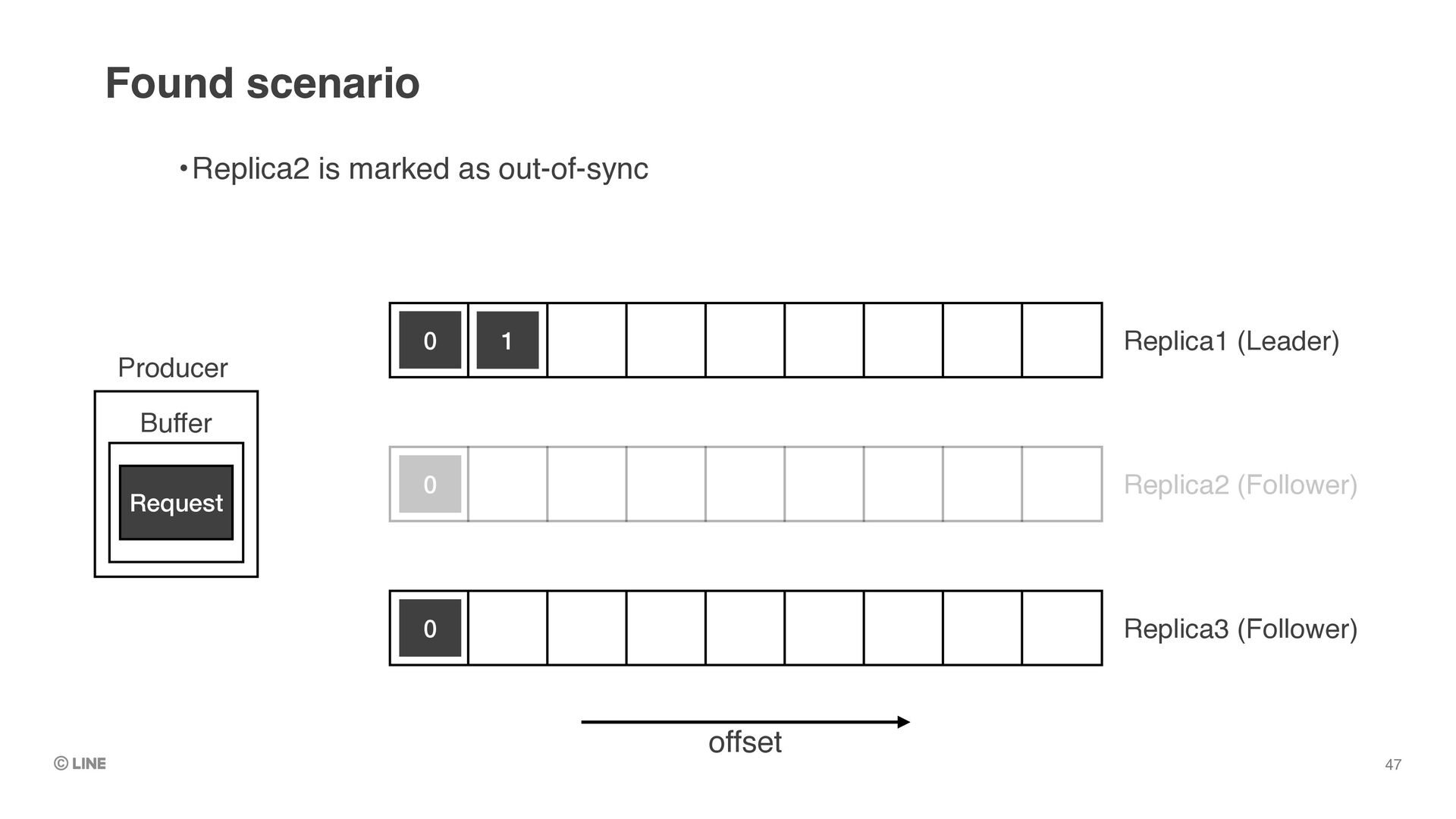
out-of-sync •Produce request returns successfully, as it’s replicated to all “in-sync” replicas 0 0 0 1 1 Return response Producer Buffer Deep dive into availability in Kafka
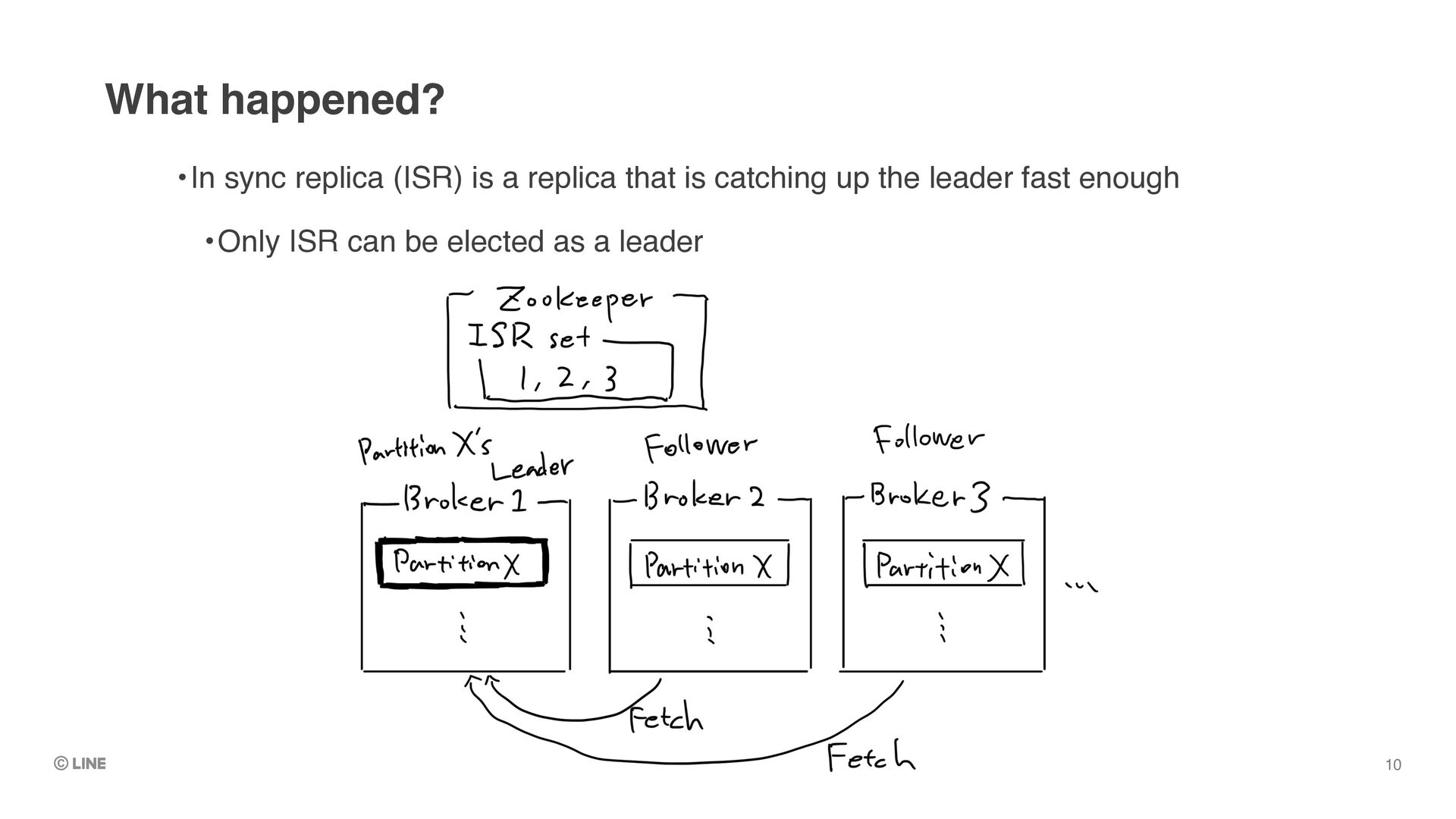
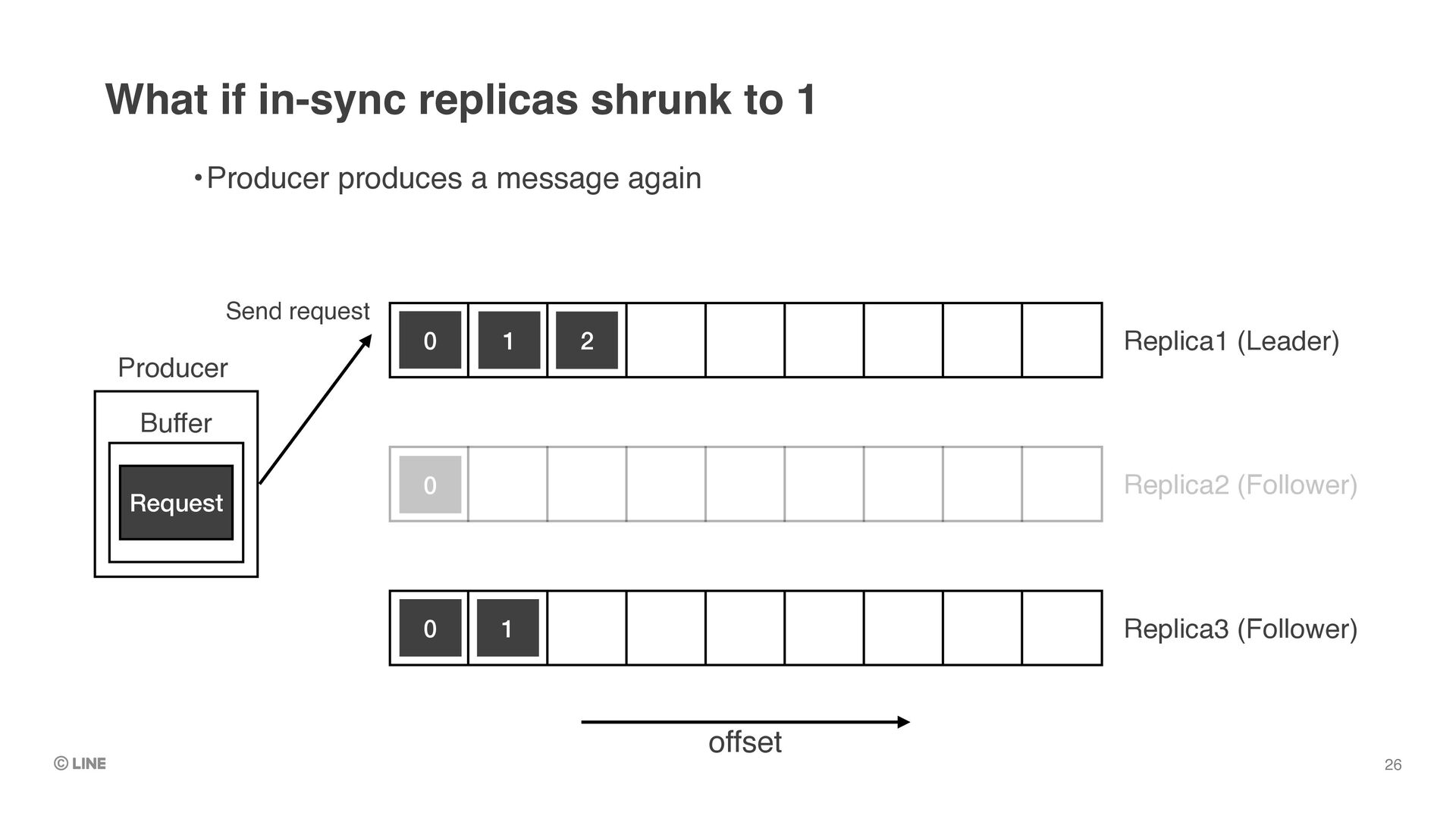
to “commit” the messages •`min.insync.replicas` config •e.g. (Assumes there are 3 replicas) •`min.insync.replicas = 2` •=> Can tolerate 1 replica to fail to continue working, with ensuring at least 2 replicas have full set of committed messages Deep dive into availability in Kafka
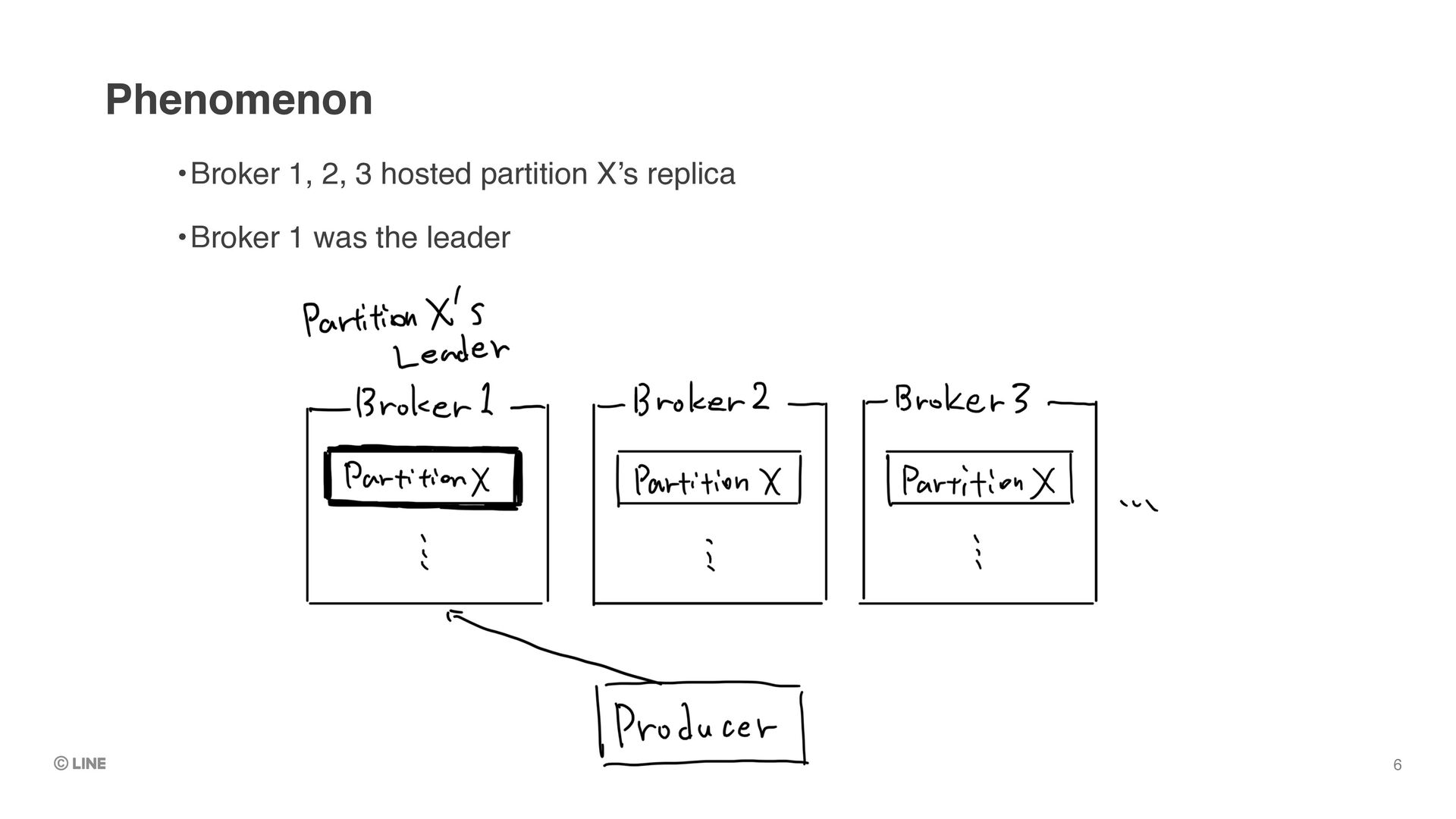
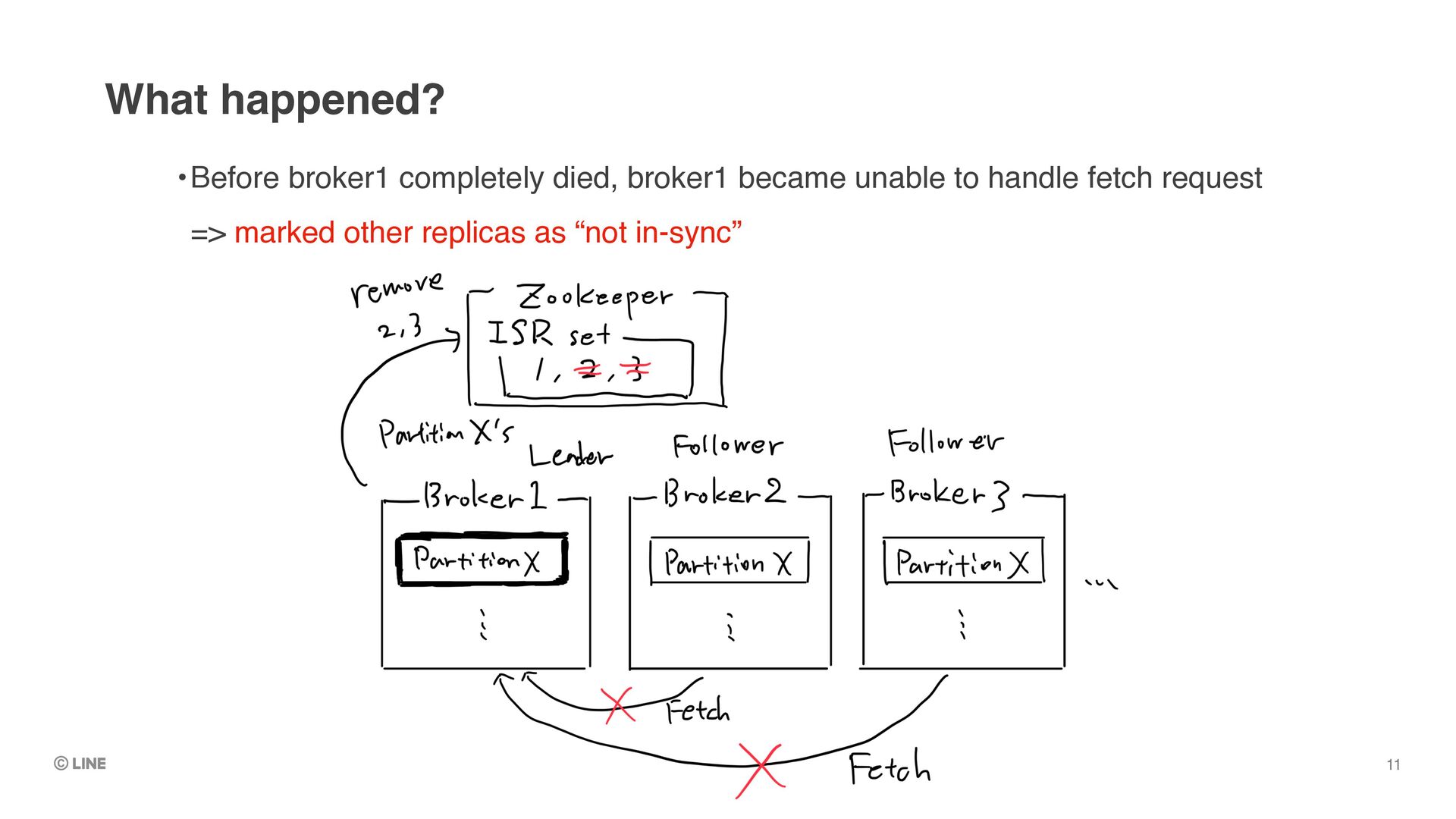
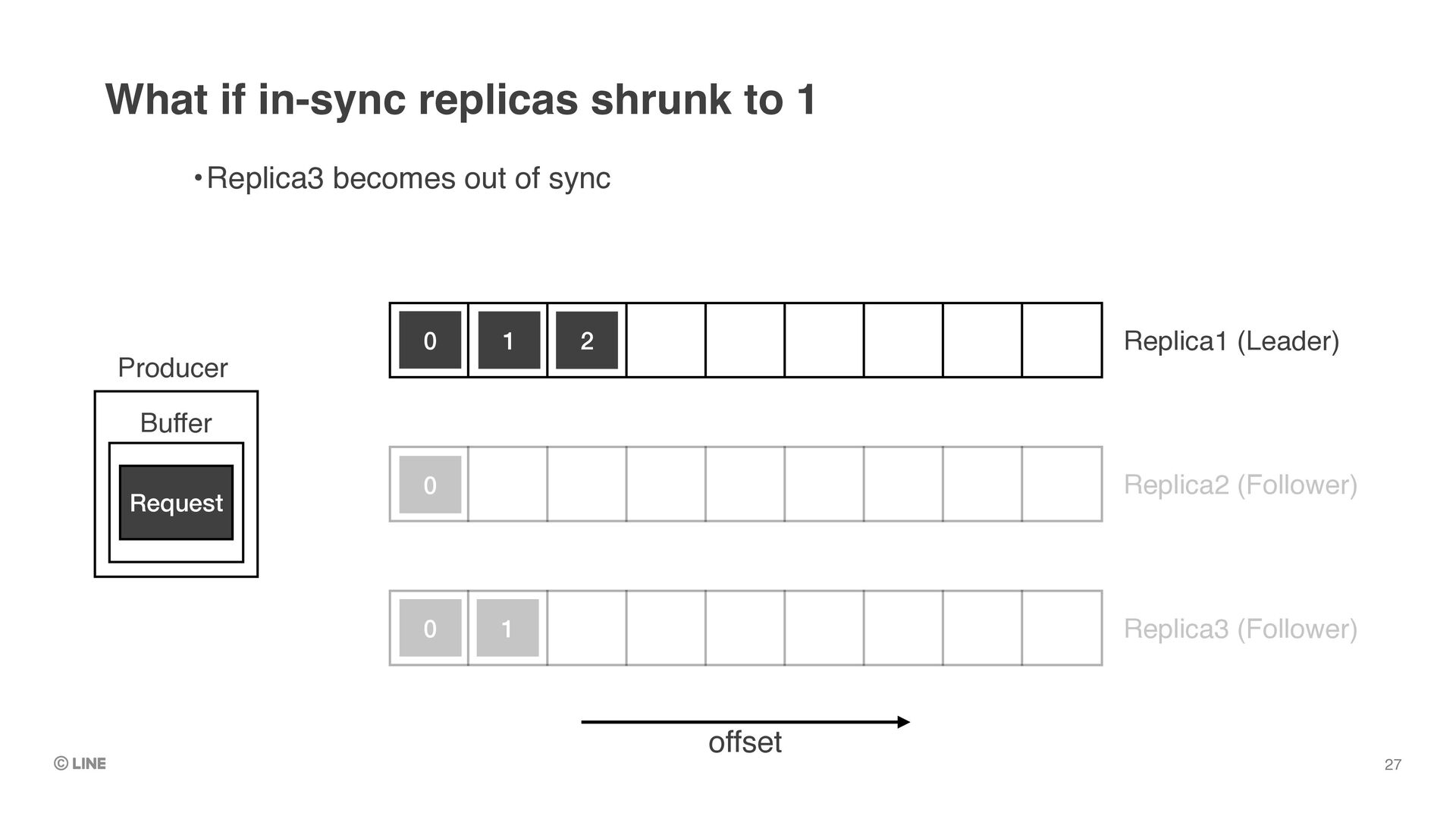
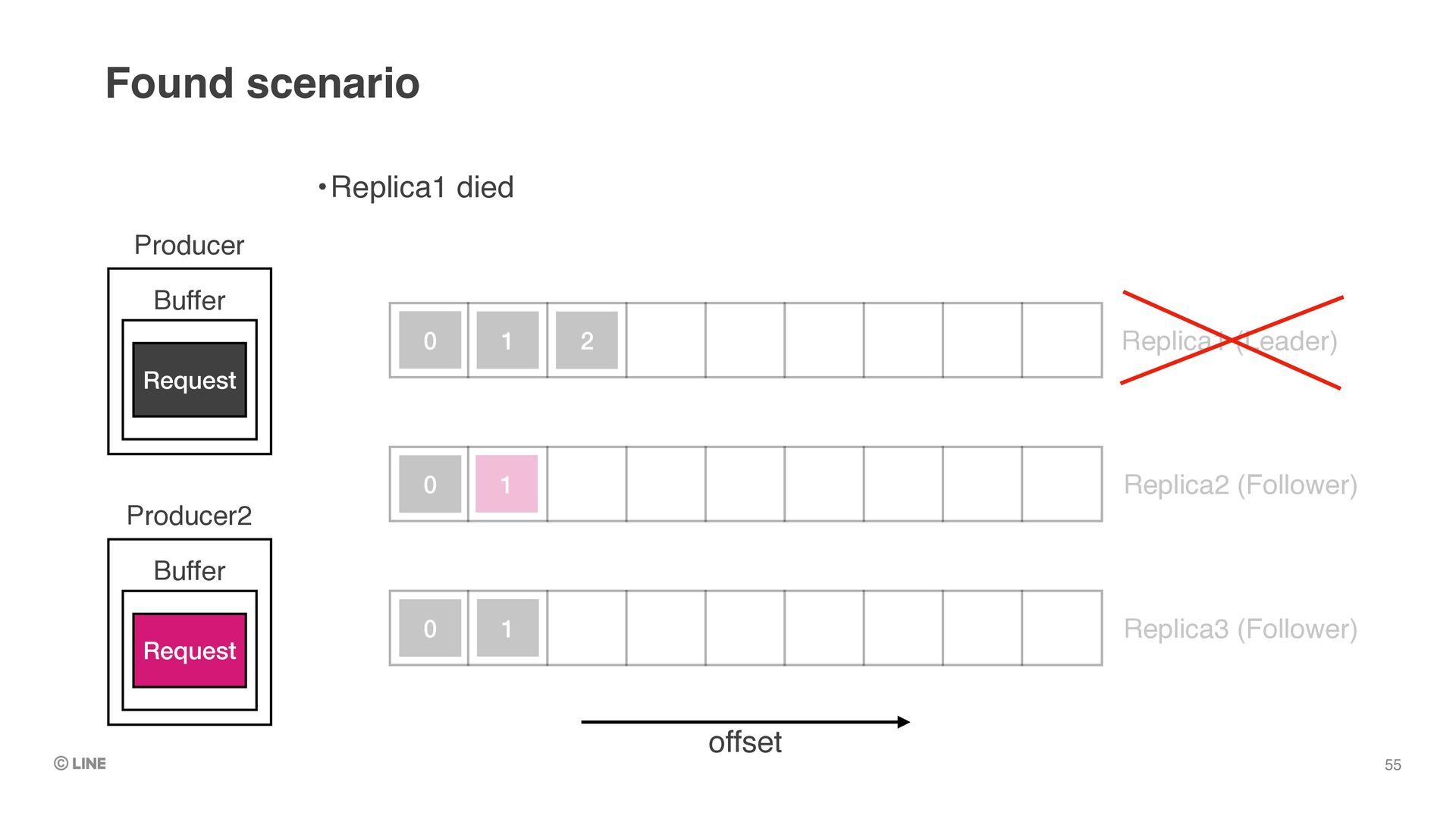
Replica1 (Leader) •Let’s say the leader dies as like the phenomenon we encountered 0 1 2 Producer Buffer Request Replica2 (Follower) Replica3 (Follower) 0 0 1
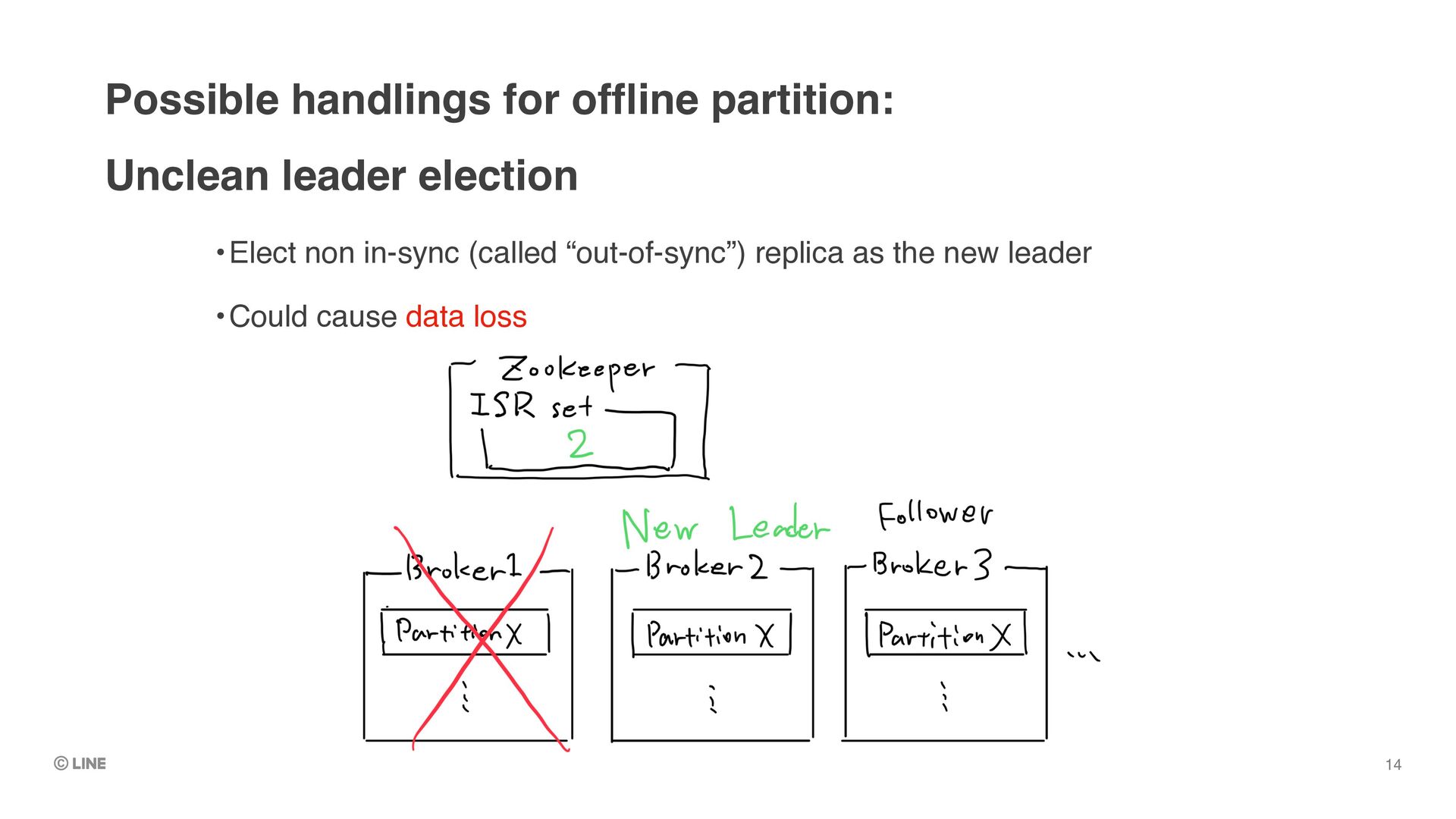
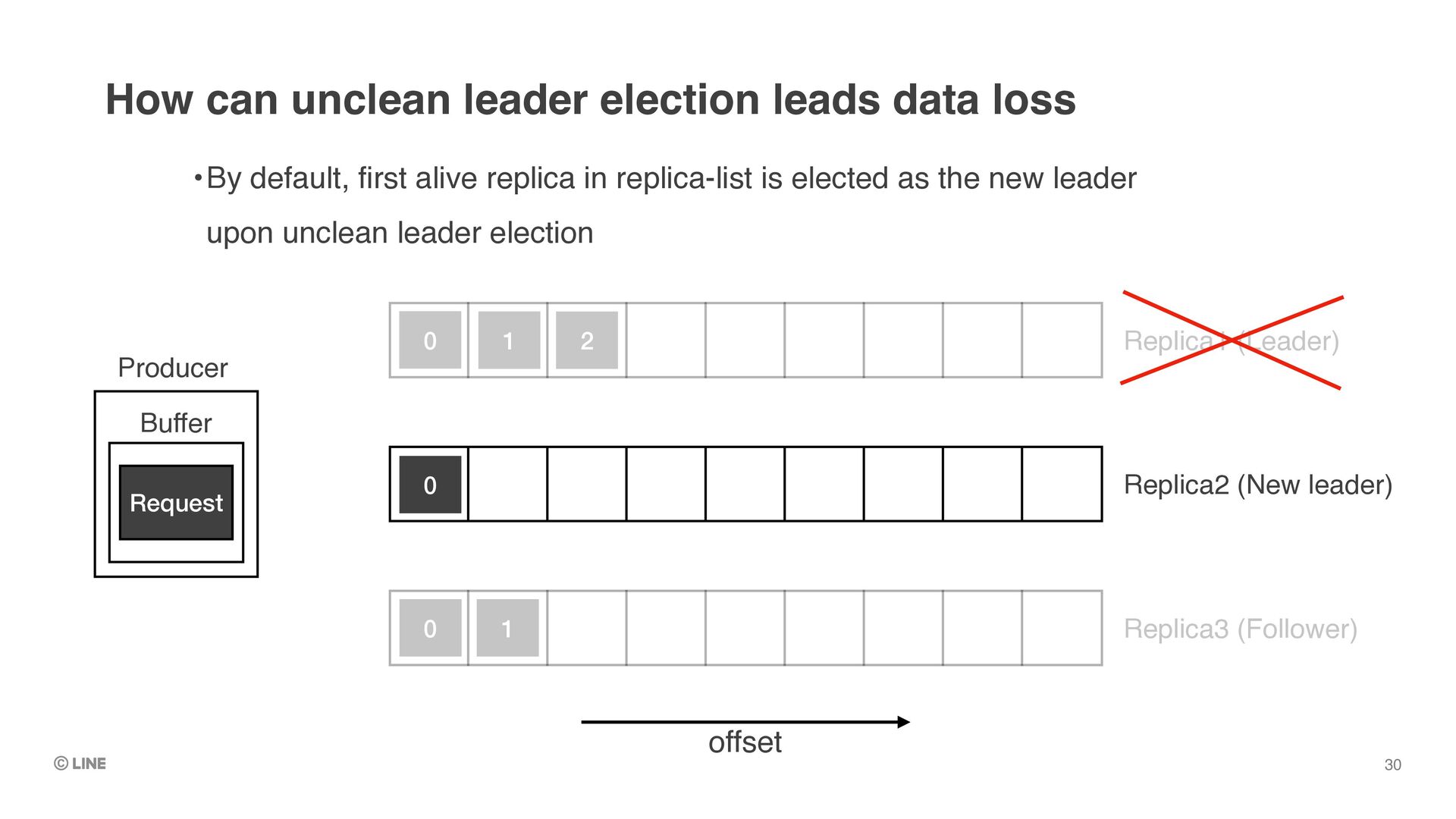
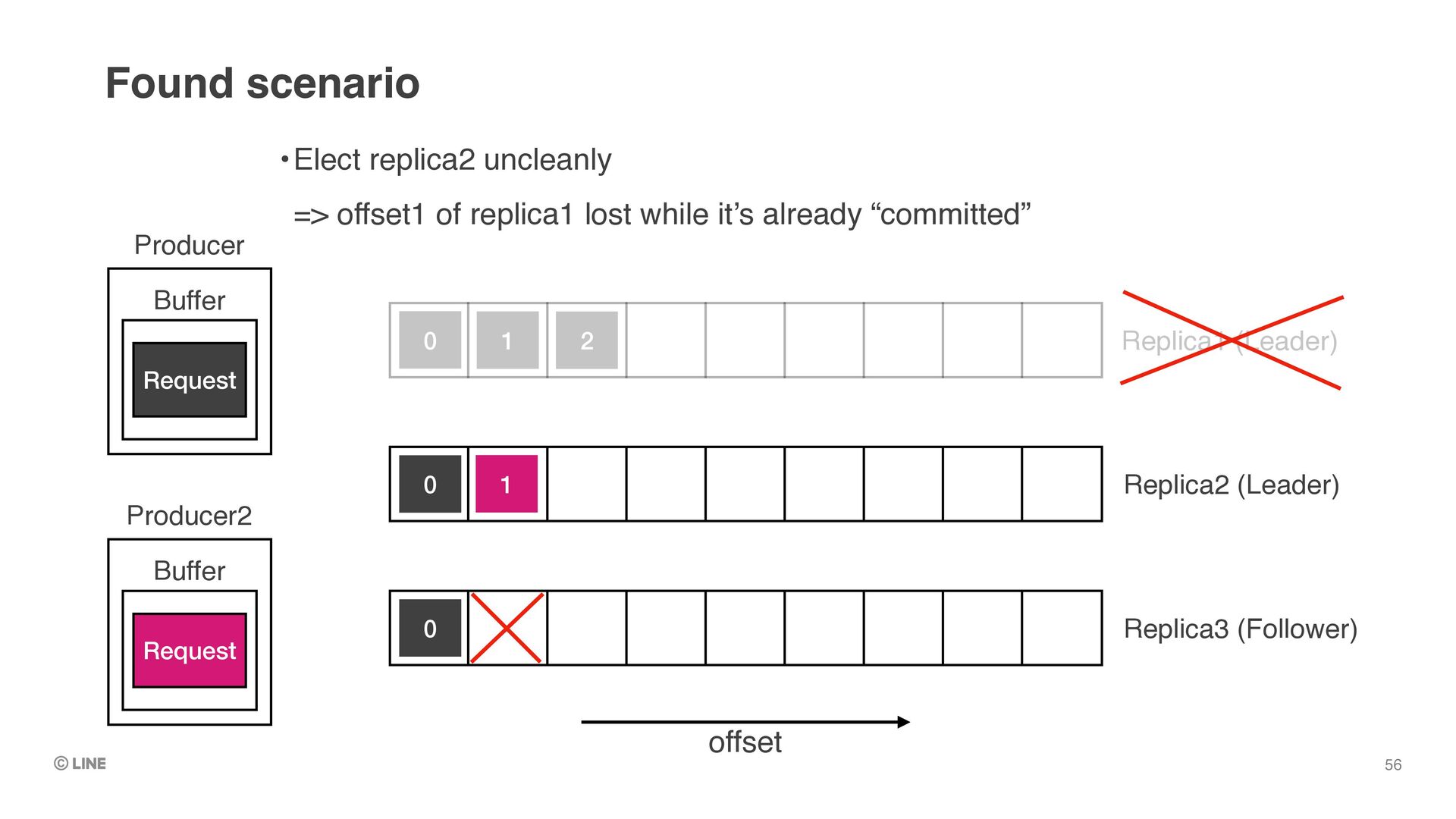
Replica1 (Leader) •By default, first alive replica in replica-list is elected as the new leader upon unclean leader election 0 1 2 Producer Buffer Request Replica2 (New leader) Replica3 (Follower) 0 0 1
Replica1 (Leader) •Replica3 will truncate offset 1 because new leader doesn’t have it •=> offset 1 lost 0 1 2 Producer Buffer Request Replica2 (New leader) Replica3 (Follower) 0 0
full set of committed messages •i.e. Replica3 in previous example •At LINE, all topics are configured with `min.insync.replicas = 2` •=> If we can choose such replica as the new “unclean” leader, we can expect no data-loss even on unclean leader election Idea: Avoid data loss even on unclean leader election 32
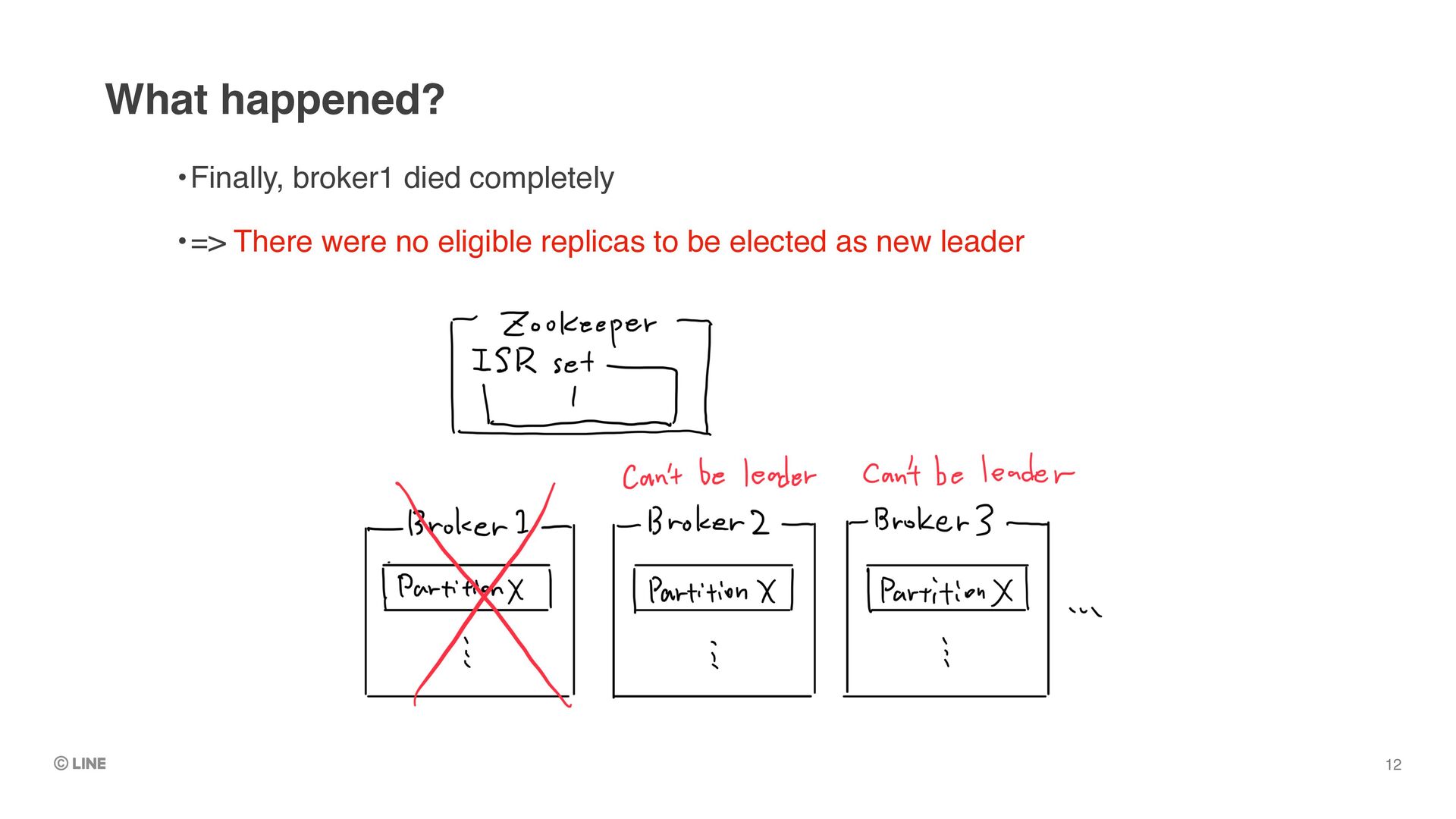
of committed messages without inspecting failed leader’s log •Because we likely cannot login to failed leader’s machine How can we identify such “eligible” replica? 33
replica that has the latest offset” be the criteria of “the replica that has full set of committed messages” ? Replica1 (Leader) 0 1 2 Producer Buffer Request Replica2 (Follower) Replica3 (New leader) 0 0 1 offset
scenario like previous example, it should work •However, there are infinite number of possible scenarios •Checking all of them is beyond human capability
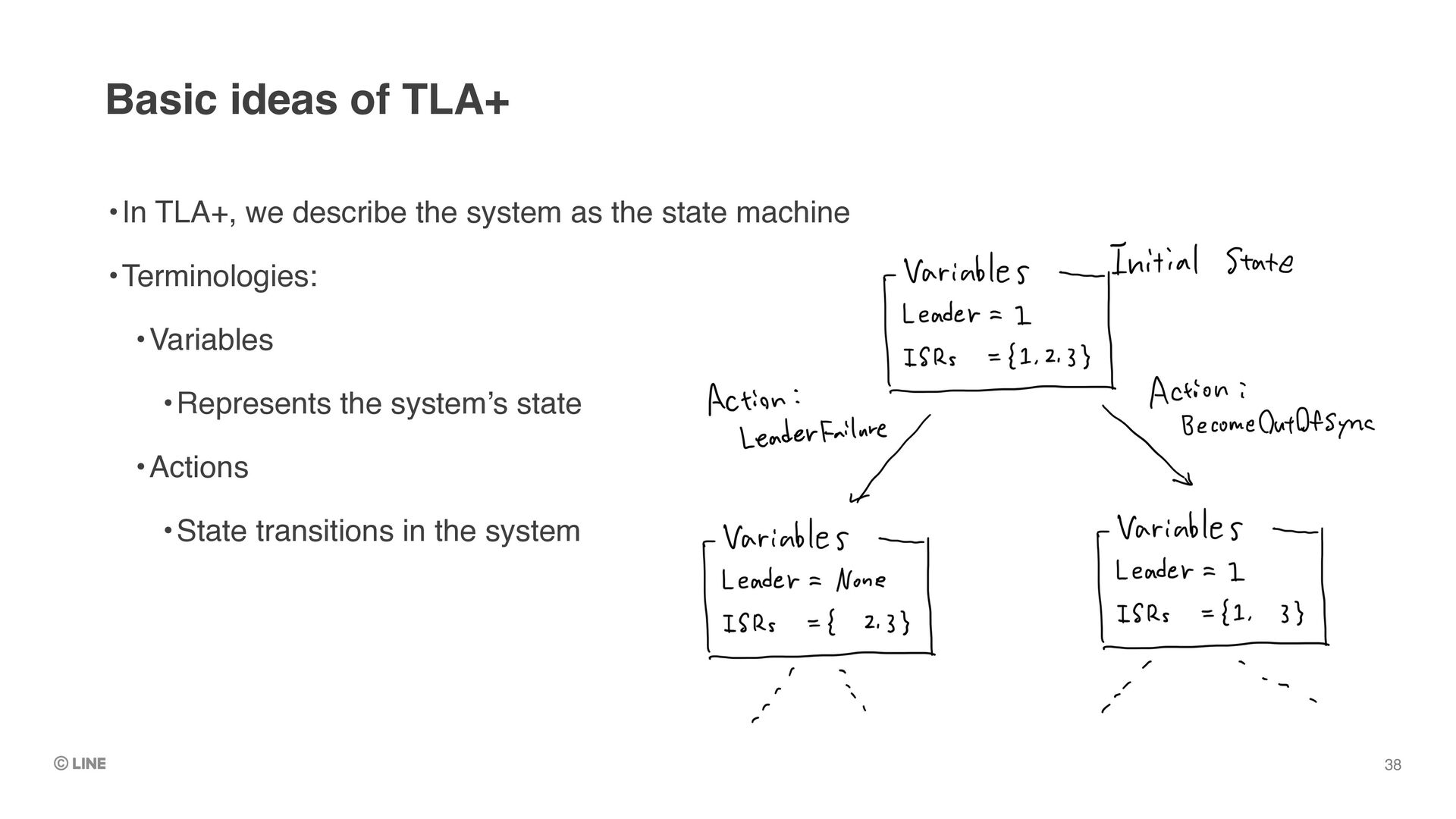
a rigorous way •In dedicated specification languages •We can run exhaustive check against the system and find any path that leads undesired situation •Specification languages: •VDM++, Z, Alloy,…, TLA+ (our choice) Formal methods to the rescue! 36
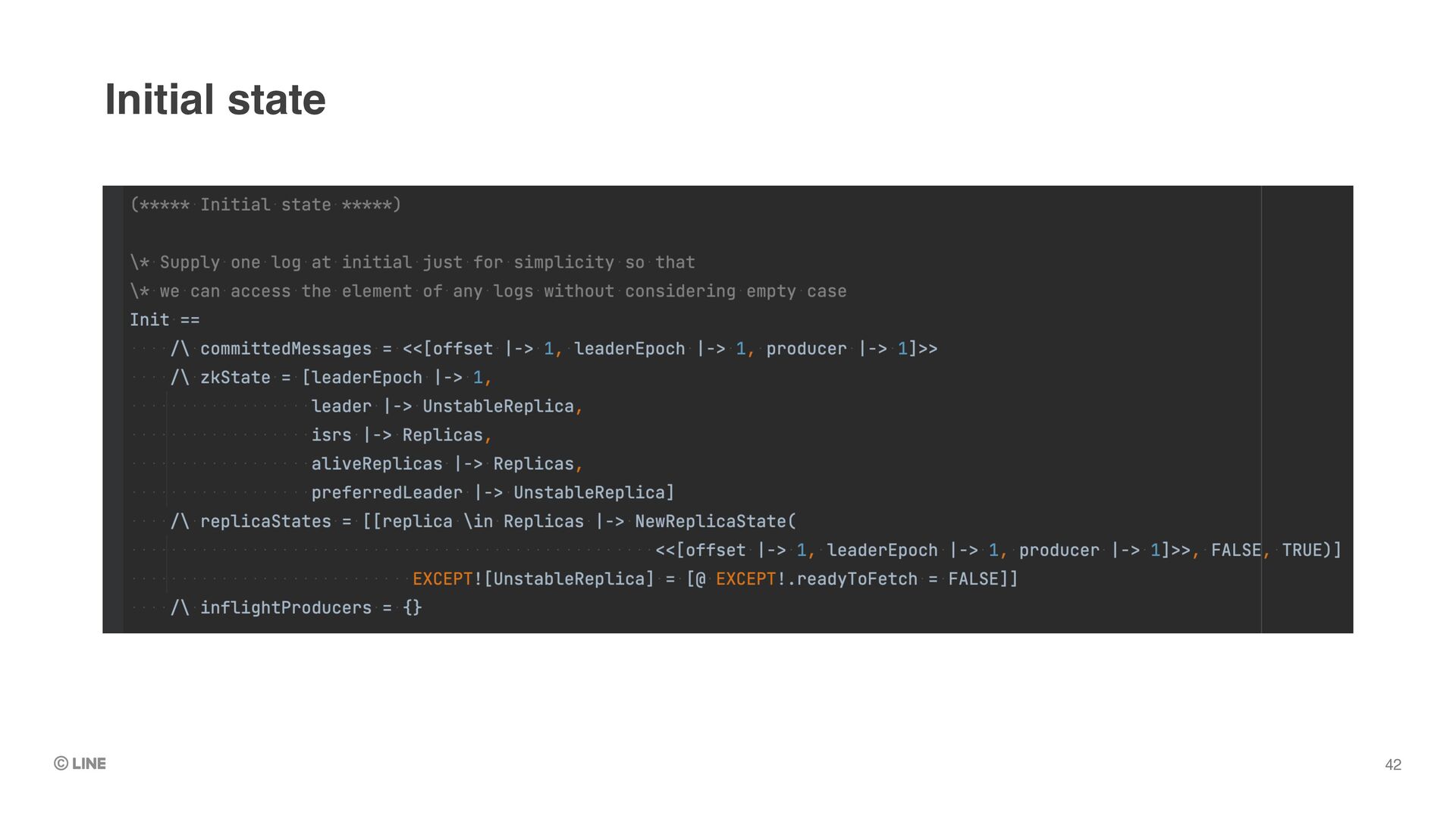
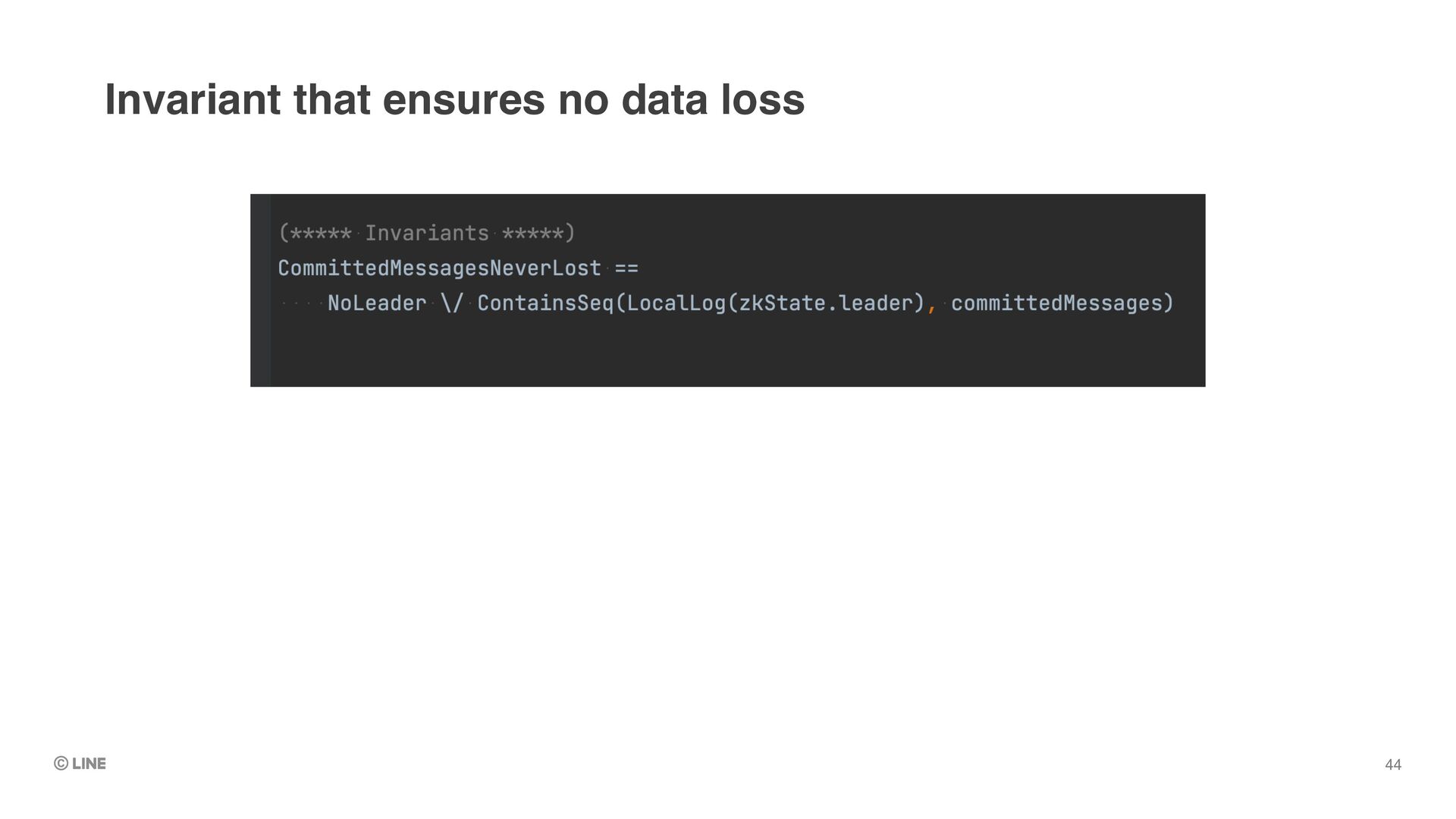
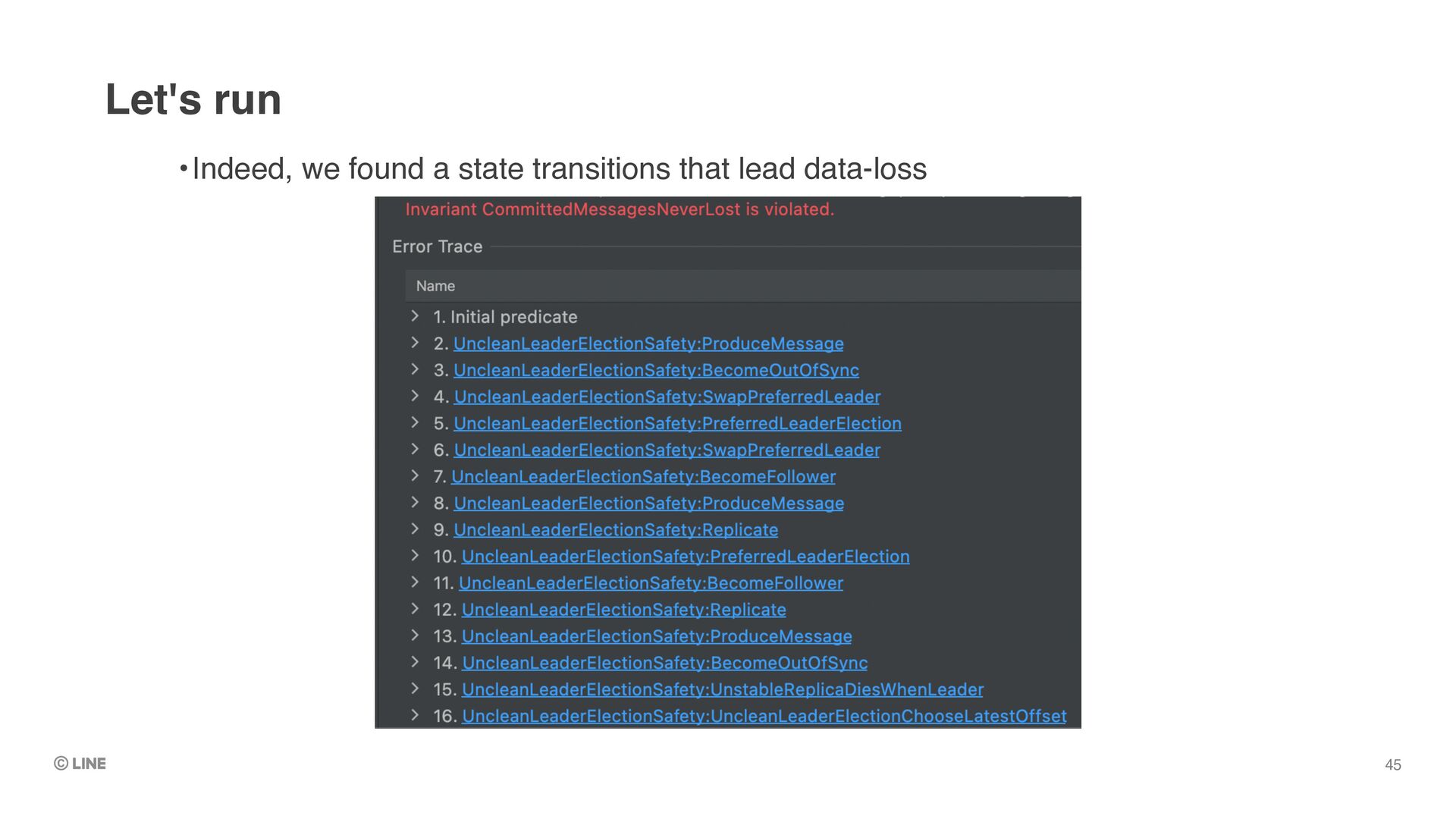
specify “invariant” of the system when running TLC •e.g. “Committed messages never lost” •As soon as TLC found a state that doesn’t satisfy the invariant, it stops and dumps the state transitions TLC model checker 39
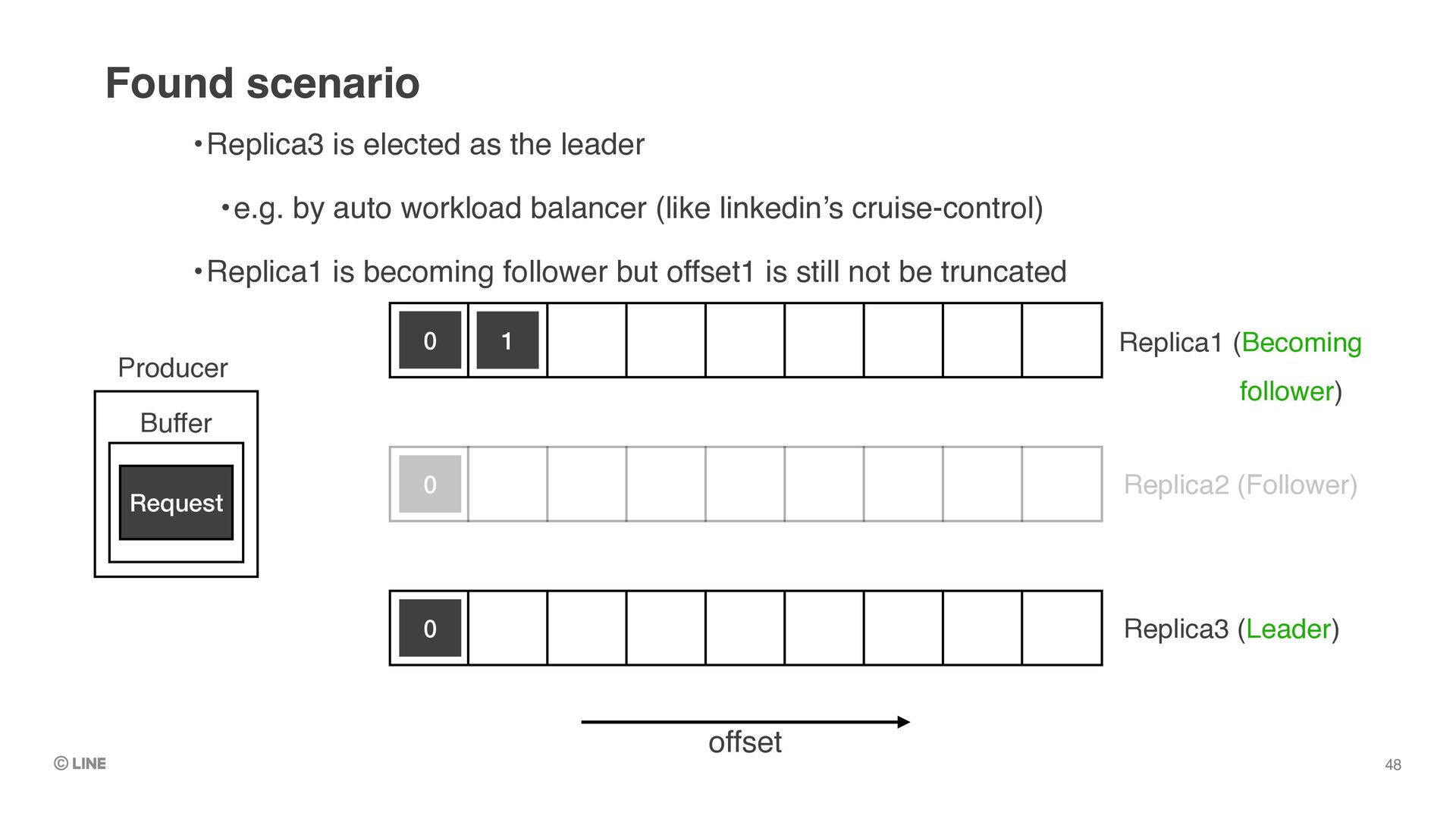
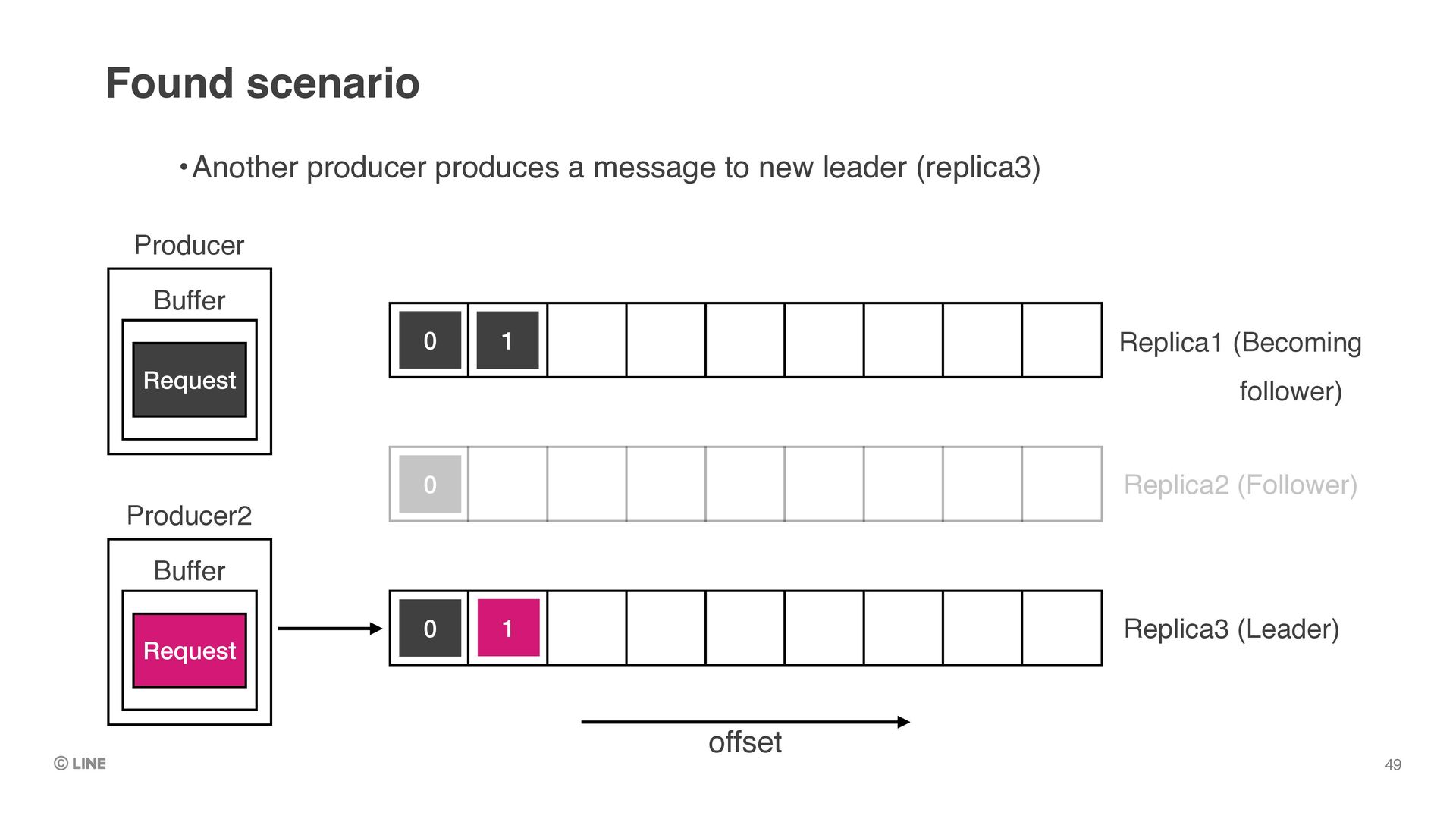
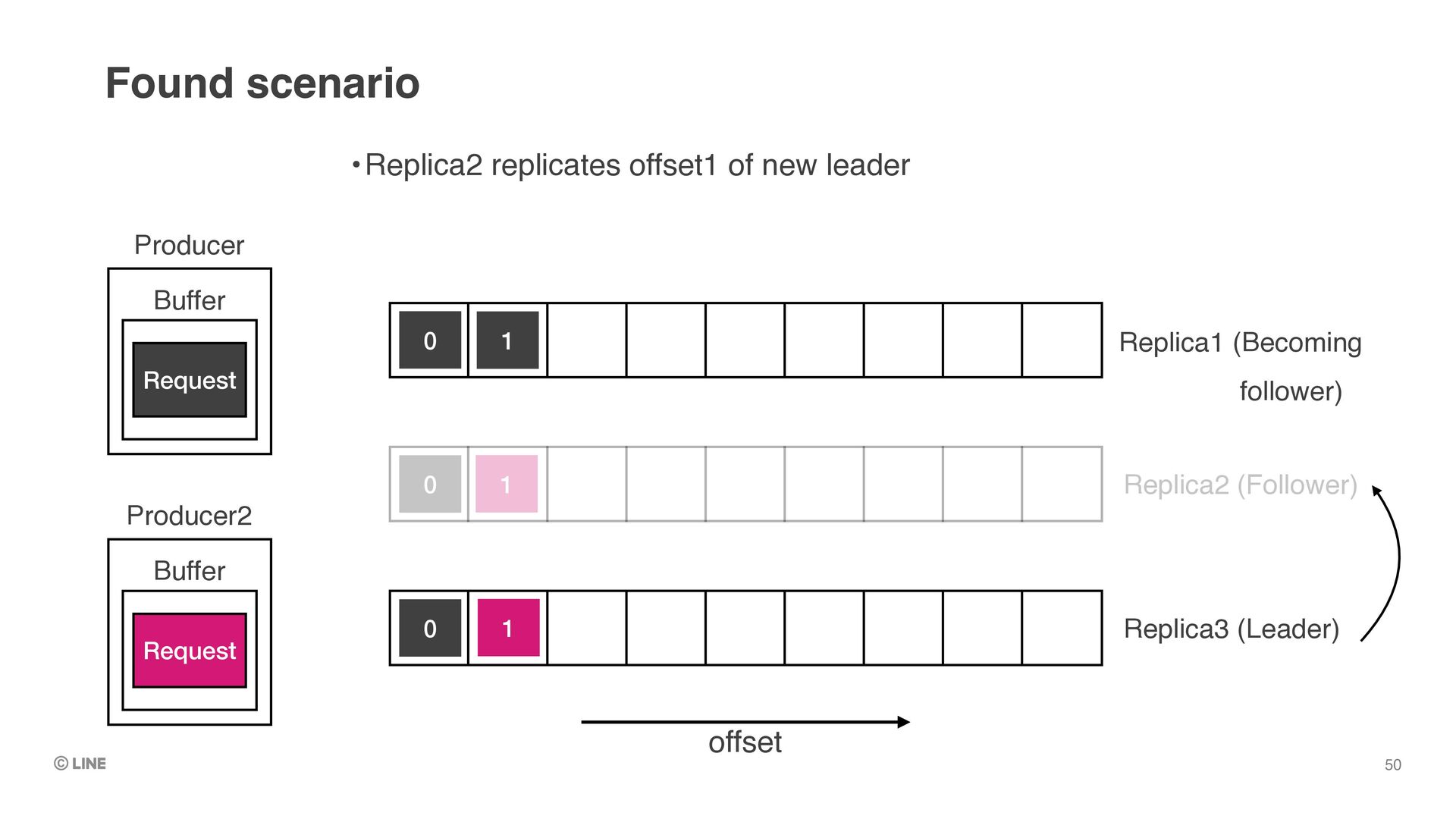
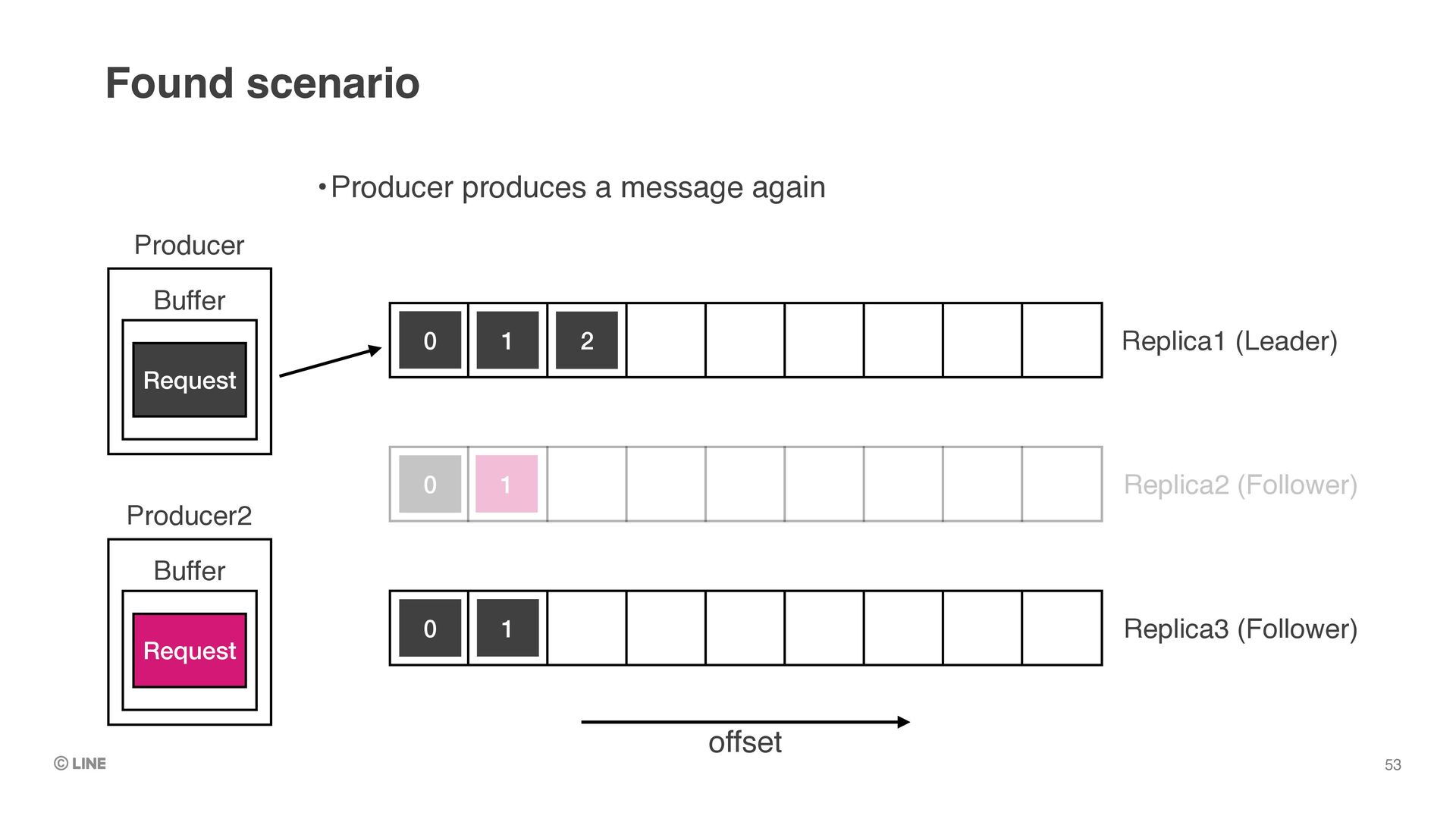
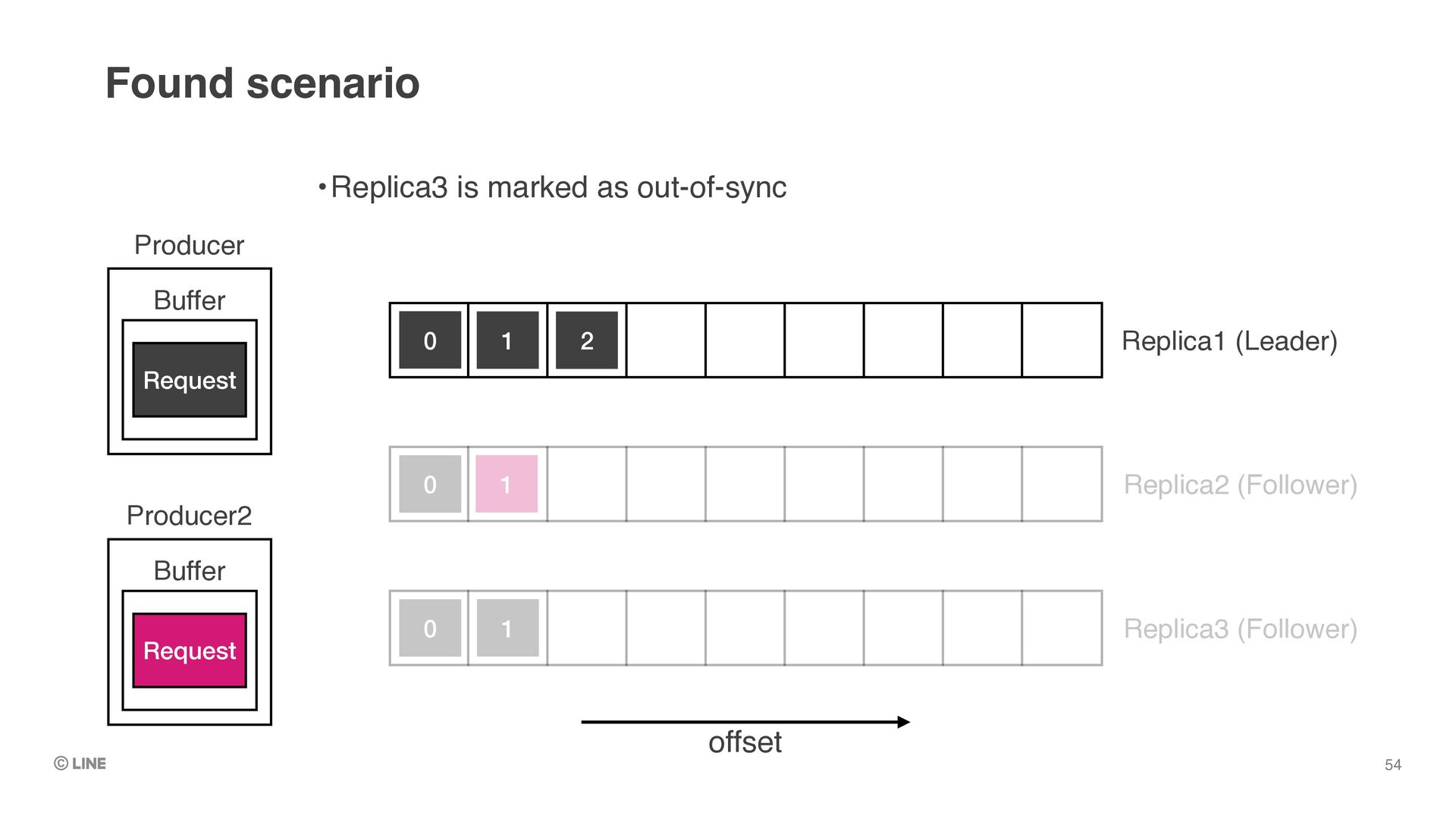
0 0 1 Producer Buffer Request •Replica3 is elected as the leader •e.g. by auto workload balancer (like linkedin’s cruise-control) •Replica1 is becoming follower but offset1 is still not be truncated Found scenario
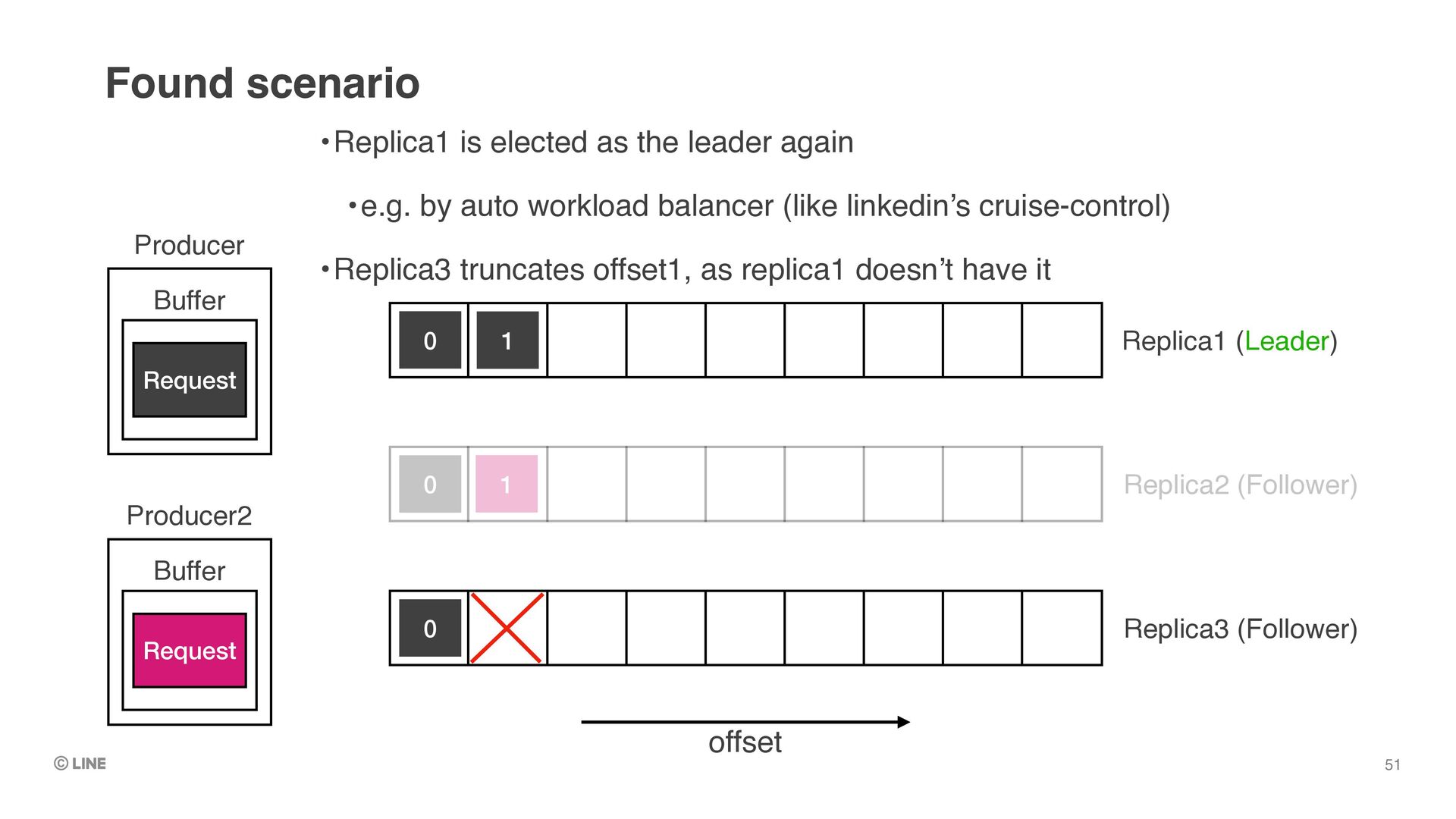
Buffer Request 1 Replica1 (Leader) Replica2 (Follower) Replica3 (Follower) •Replica1 is elected as the leader again •e.g. by auto workload balancer (like linkedin’s cruise-control) •Replica3 truncates offset1, as replica1 doesn’t have it Found scenario
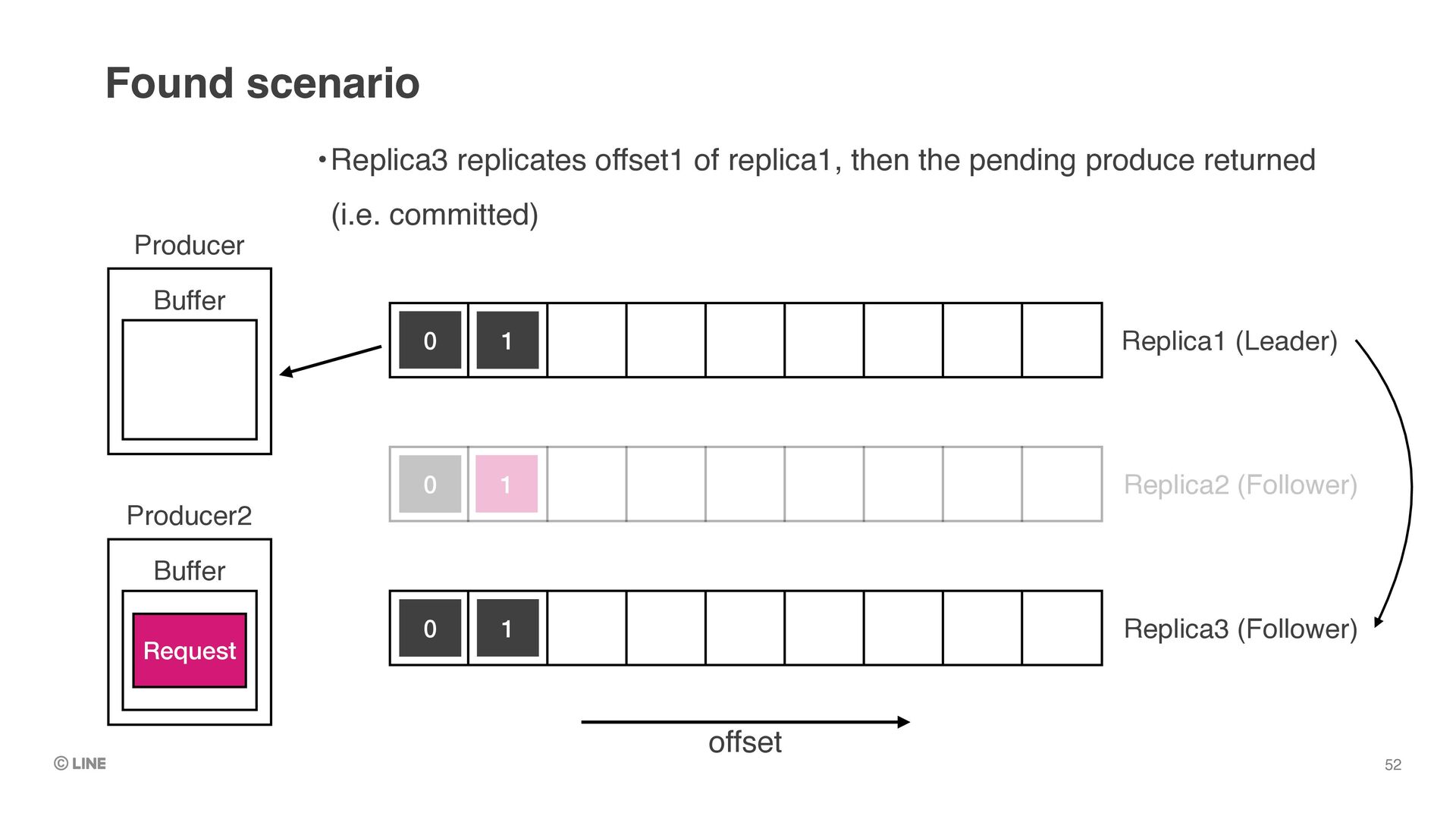
Request 1 Replica1 (Leader) Replica2 (Follower) Replica3 (Follower) 1 •Replica3 replicates offset1 of replica1, then the pending produce returned (i.e. committed) Found scenario
choose a replica which has the latest offset as the new leader •Future work: Figure out more appropriate criteria to detect “eligible” replica •Formal methods are very useful for debugging ideas regarding distributed systems like Kafka Conclusion 57
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}