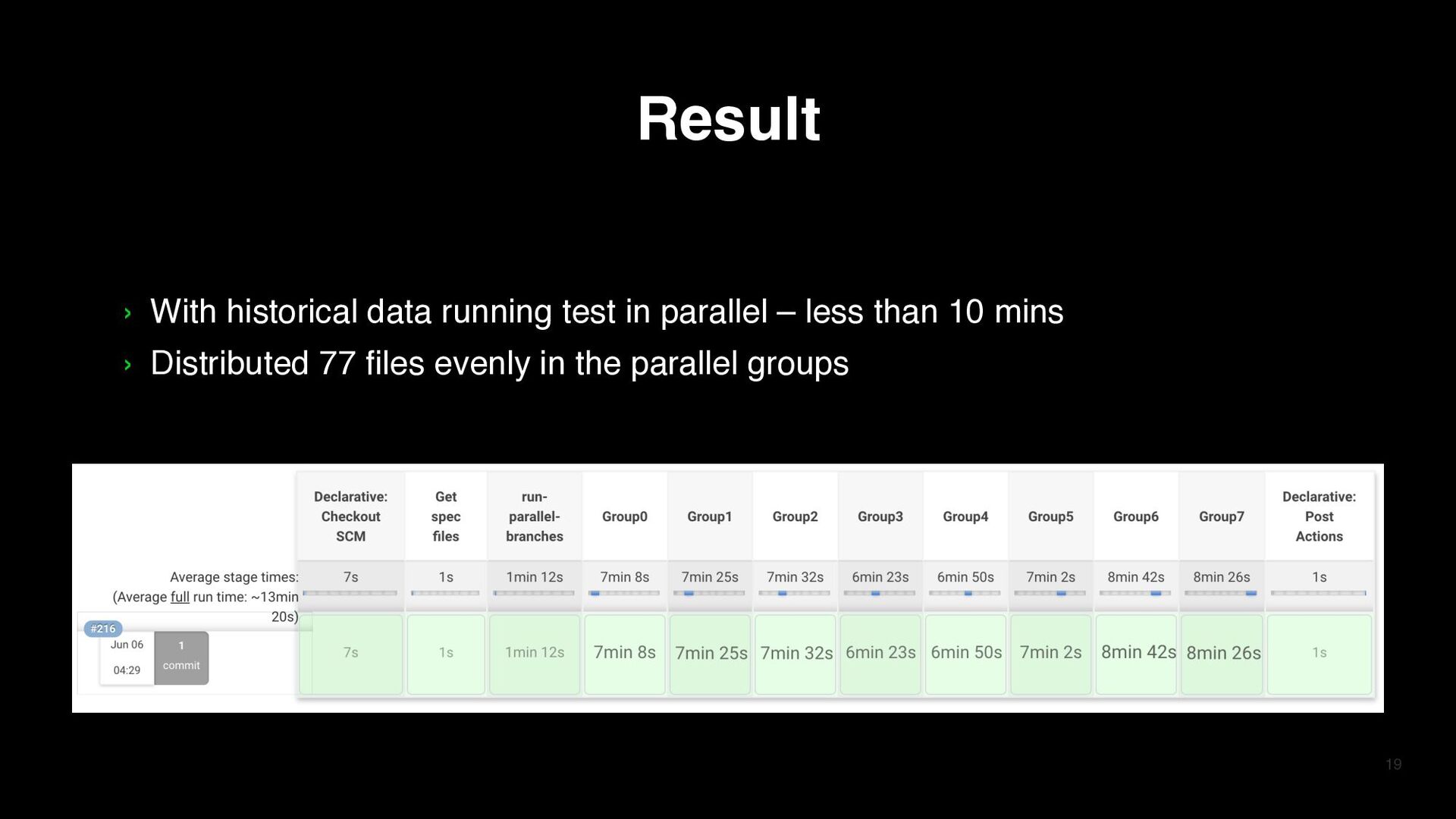
tests in parallel is equal to the longest time spent among the parallel groups › Manually allocating the test cases to each group requires man power › Cannot dynamically control how many parallel groups to run 3 3 parallel groups with 77 files which contains 291 test cases
run by allocating the testing time of each group more evenly › Automatically distribute the tests without requiring manpower › Dynamically control how many parallel groups to run 4 Group1 20 minutes Group2 20 minutes GroupN 20 minutes Parallel running docker Jenkins job
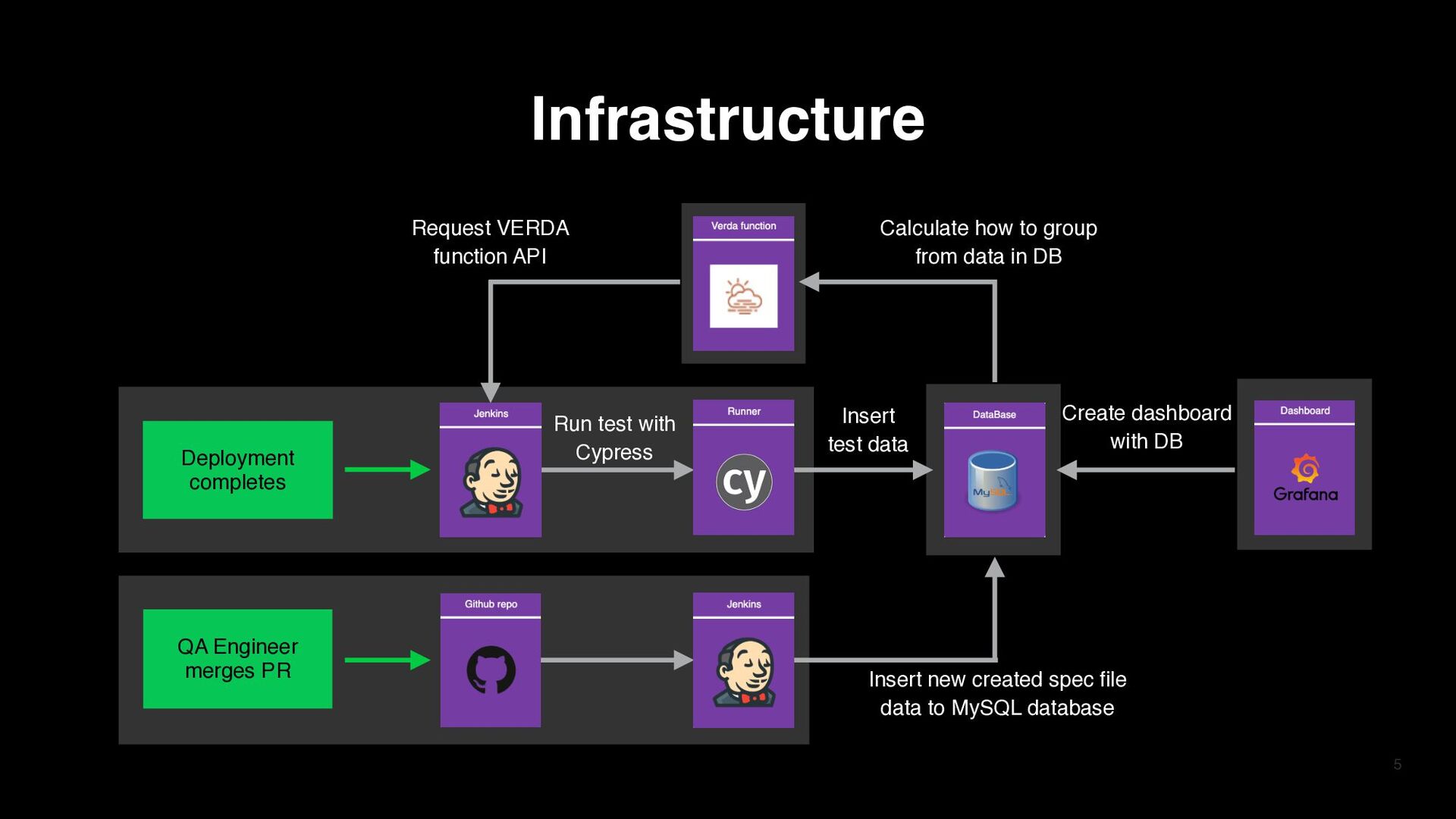
data in DB Insert new created spec file data to MySQL database Run test with Cypress Insert test data Create dashboard with DB Deployment completes QA Engineer merges PR Infrastructure
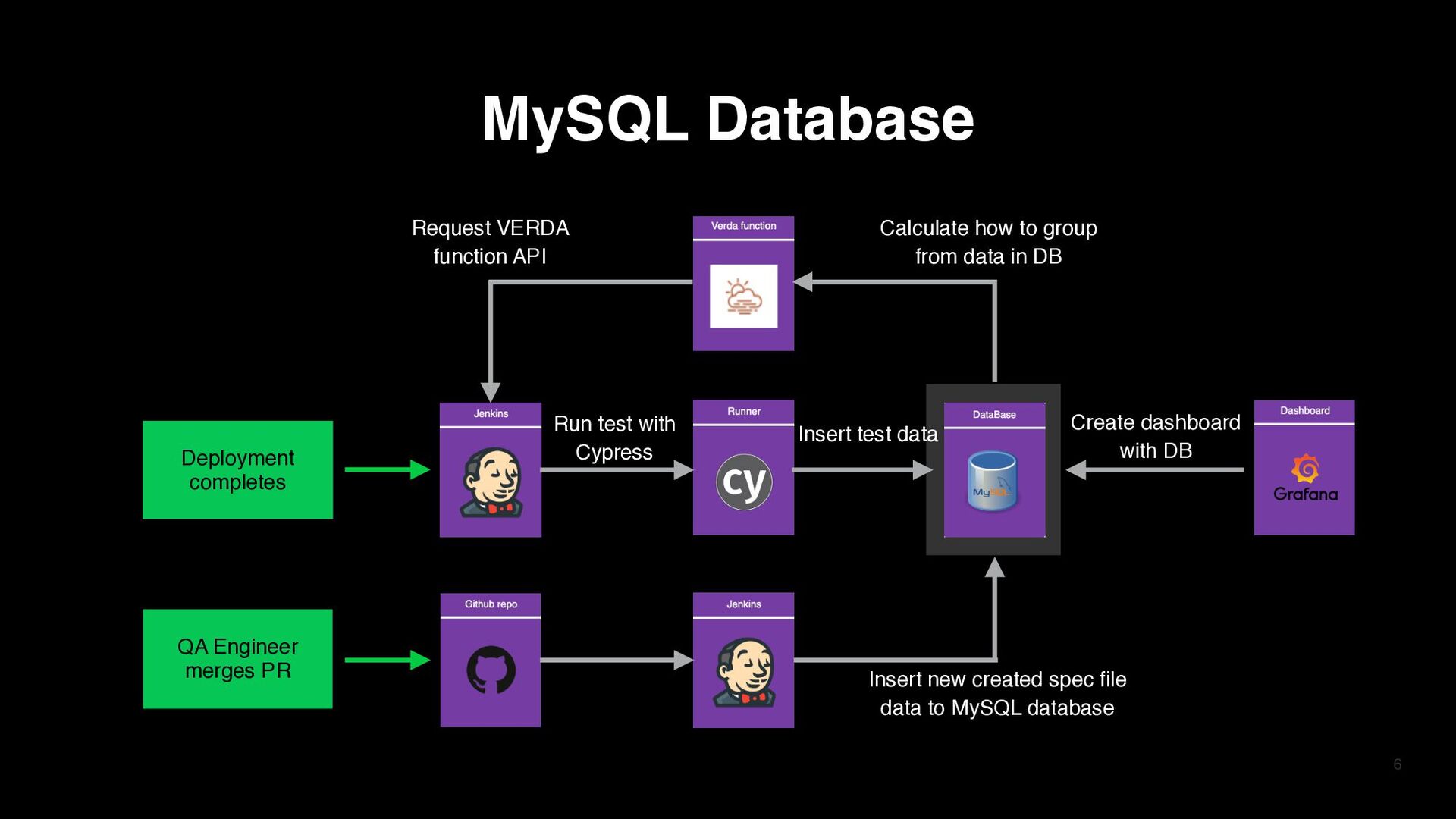
data in DB Insert new created spec file data to MySQL database Run test with Cypress Insert test data Create dashboard with DB MySQL Database Deployment completes QA Engineer merges PR Deployment completes QA Engineer merges PR
isn't unique › Data is inserted to MySQL database every time cypress test is conducted › Clear data which has start time 3 months ago 8 Data in MySQL MySQL Database
group from data in DB Insert new created spec file data to MySQL database Run test with Cypress Insert test data Create dashboard with DB QA Engineer merges PR Verda Function Deployment completes QA Engineer merges PR
response Verda Function › Create an API to calculate how to allocate each test file to each group and show the expected time for each group to run › API Query Parameters › folder => input the folder path you want to test ex: folder = e2e/2-advanced-examples › group => input how many parallel jobs you want to create ex: group = 3 › API Responses › Response: Distributed test file in each group › Times: Expected time for each group to finish running (milliseconds)
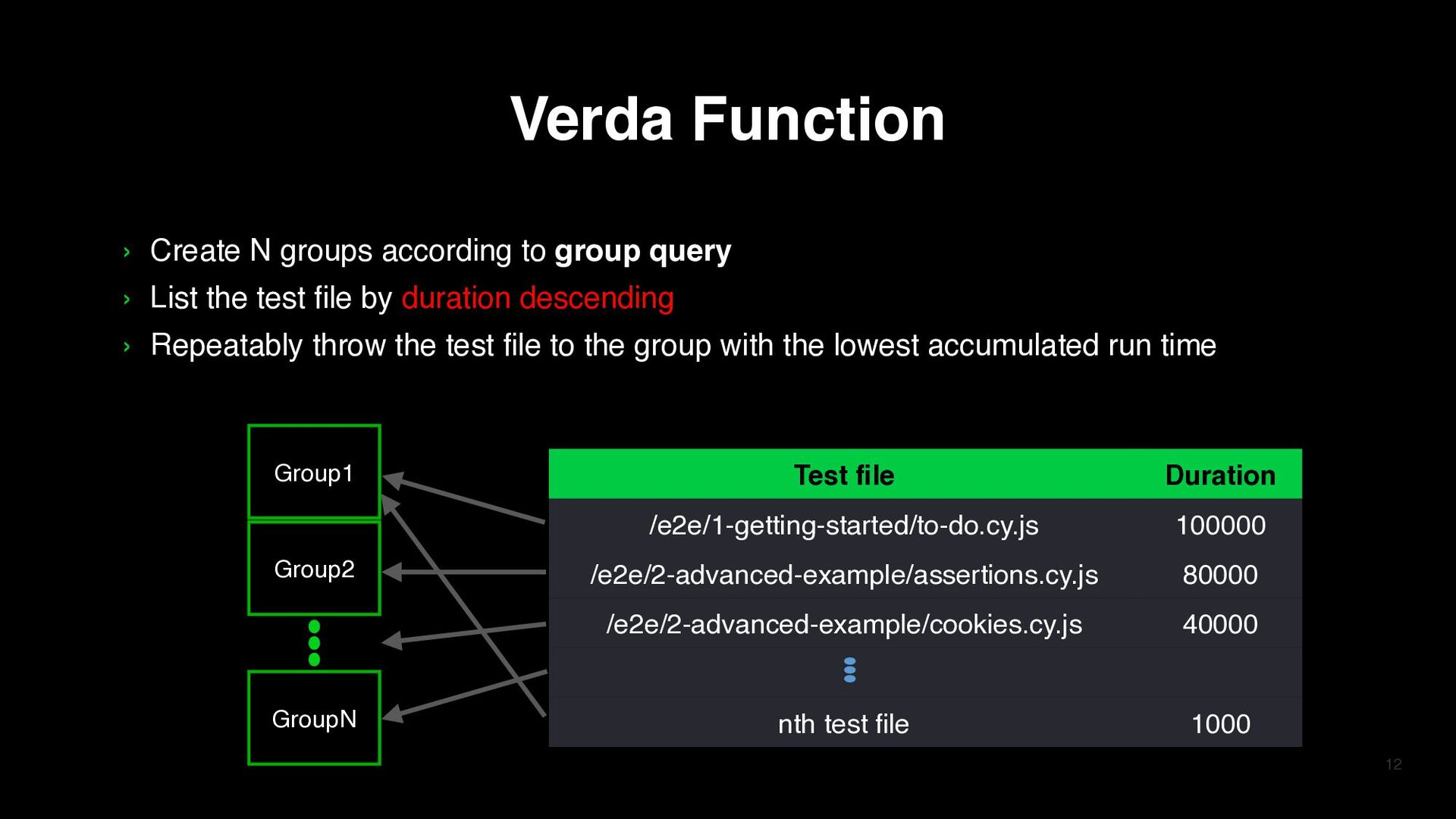
1200 2022/02/14 /e2e/1-getting-started/to-do.cy.js 1000 2022/02/13 /e2e/1-getting-started/to-do.cy.js 1500 2022/02/01 Example of MySQL data Test file Duration /e2e/1-getting-started/to-do.cy.js (800+1200+1000)/3=1000 Verda Function › Select data with test file matching the folder query and start time within 5 days › Group by test file using the average of these data’s duration
nth test file 1000 › Create N groups according to group query › List the test file by duration descending › Repeatably throw the test file to the group with the lowest accumulated run time Verda Function Group1 Group2 GroupN
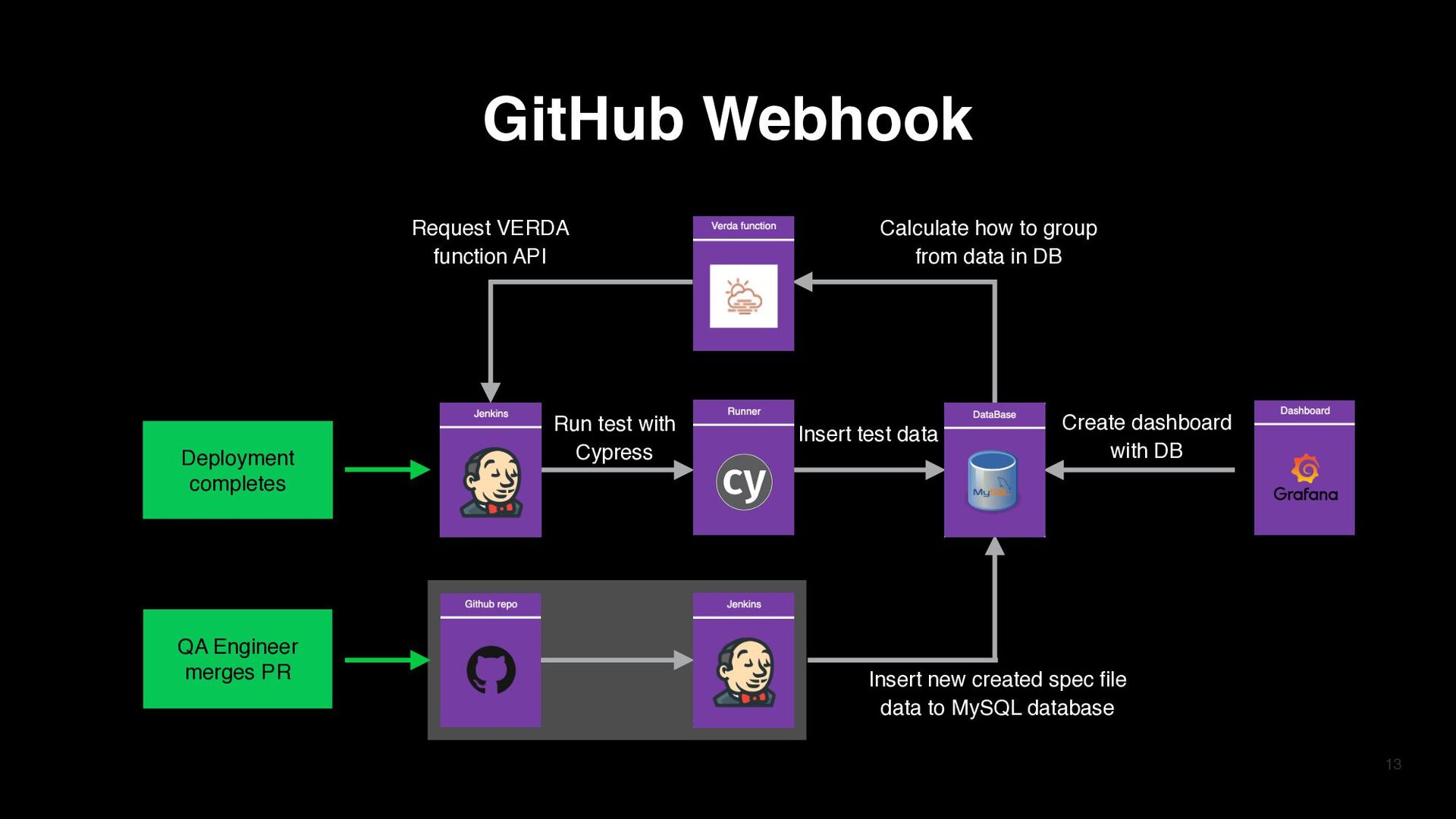
data in DB Insert new created spec file data to MySQL database Run test with Cypress Insert test data Create dashboard with DB GitHub Webhook Deployment completes QA Engineer merges PR
PR to add new feature automation test › Merge code into develop branch of GitHub repo › Trigger Jenkins job with GitHub web hook (Jenkins Git SCM polling plugin) 14 Create new pull request Automation GitHub repo merged Update test files to MySQL db trigger Jenkins GitHub Webhook
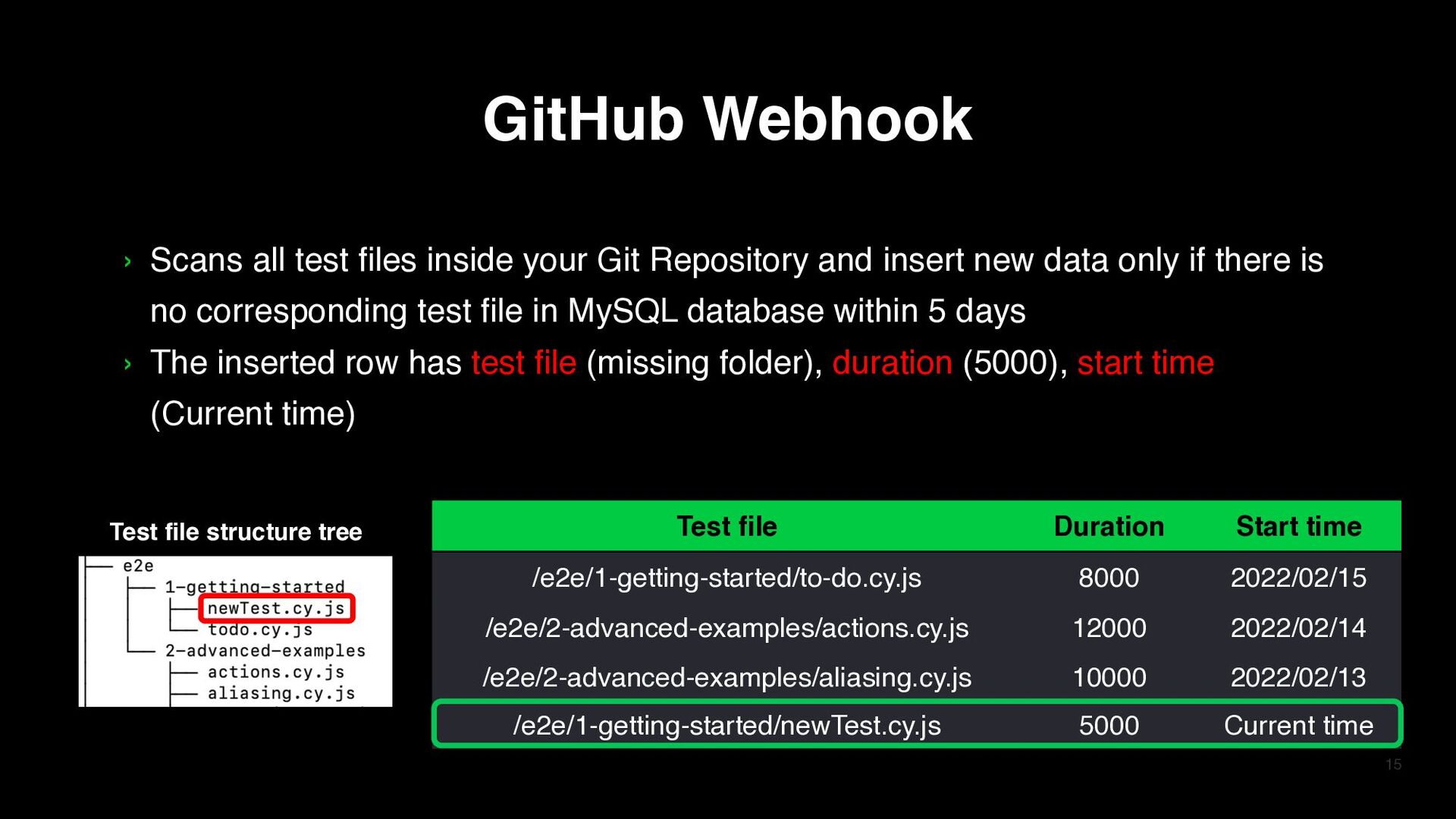
test files inside your Git Repository and insert new data only if there is no corresponding test file in MySQL database within 5 days › The inserted row has test file (missing folder), duration (5000), start time (Current time) GitHub Webhook Test file Duration Start time /e2e/1-getting-started/to-do.cy.js 8000 2022/02/15 /e2e/2-advanced-examples/actions.cy.js 12000 2022/02/14 /e2e/2-advanced-examples/aliasing.cy.js 10000 2022/02/13 /e2e/1-getting-started/newTest.cy.js 5000 Current time Test file Duration Start time /e2e/1-getting-started/to-do.cy.js 8000 2022/02/15 /e2e/2-advanced-examples/actions.cy.js 12000 2022/02/14 /e2e/2-advanced-examples/aliasing.cy.js 10000 2022/02/13
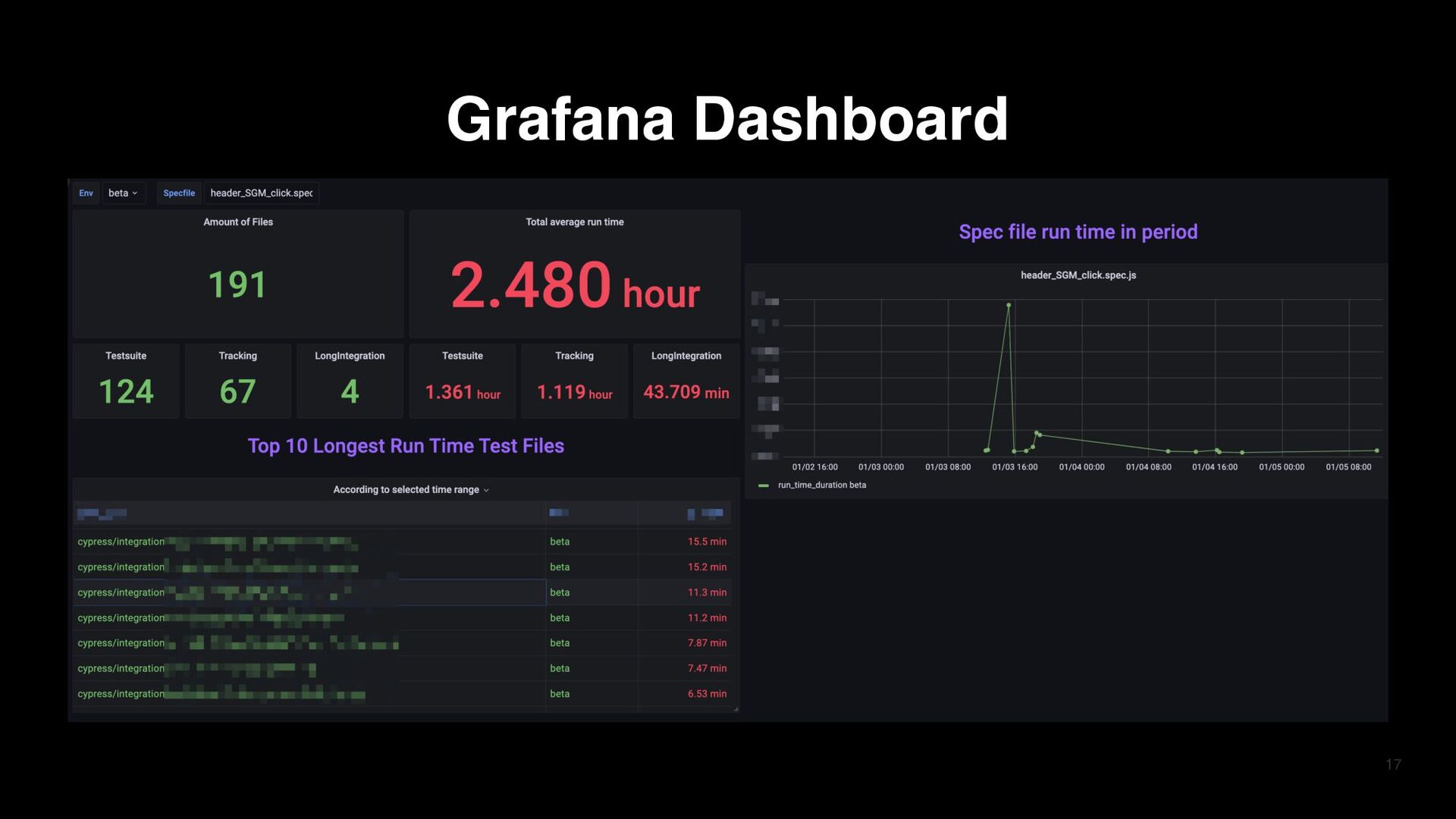
data in DB Insert new created spec file data to MySQL database Run test with Cypress Insert test data Create dashboard with DB Grafana Dashboard Deployment completes QA Engineer merges PR
data in DB Insert new created spec file data to MySQL database Run test with Cypress Insert test data Create dashboard with DB Infrastructure Deployment completes QA Engineer merges PR
running the test files evenly › Can have records of how your tests are running › Won't need to manually distribute what cases need to be run when new automation cases are created › Can directly choose what test you want to run from the folder parameter Tips › Dependency between tests files should be isolated Conclusion
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}