going strong without major re-architect • Stateless, Horizontally Scalable down to datastore with no single point of contention is the key • Micro-service pattern helps with trade-off on redundancy and complexity Or you might regret corner-cutting decision 1. Design for Scale From Day 1
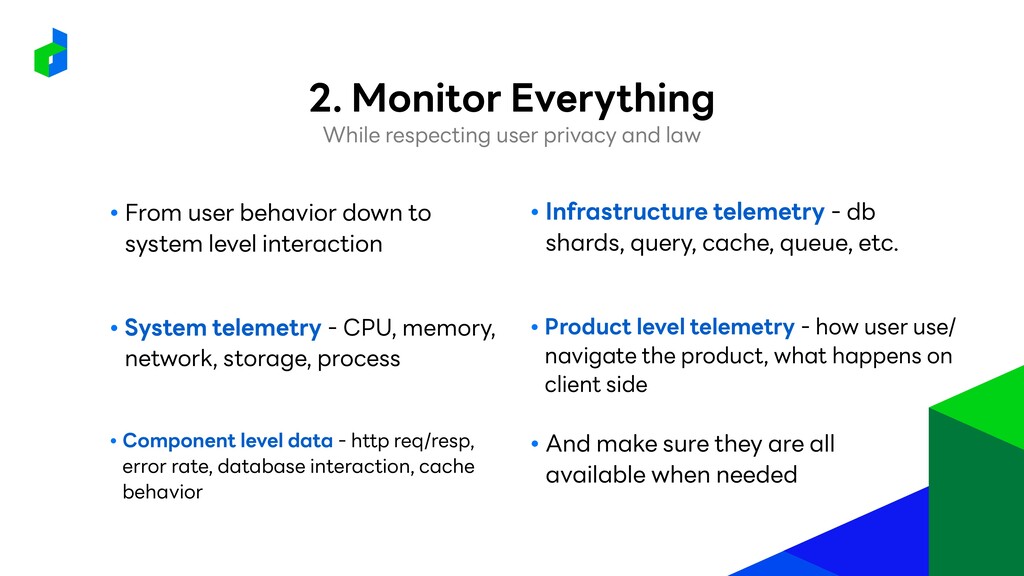
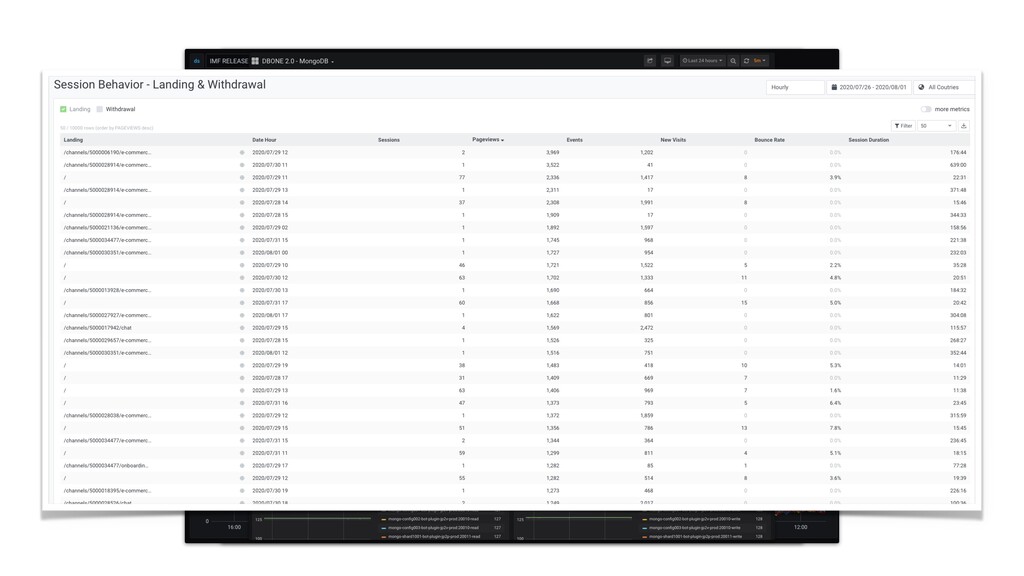
System telemetry - CPU, memory, network, storage, process • Component level data - http req/resp, error rate, database interaction, cache behavior • Infrastructure telemetry - db shards, query, cache, queue, etc. • Product level telemetry - how user use/ navigate the product, what happens on client side • And make sure they are all available when needed While respecting user privacy and law 2. Monitor Everything
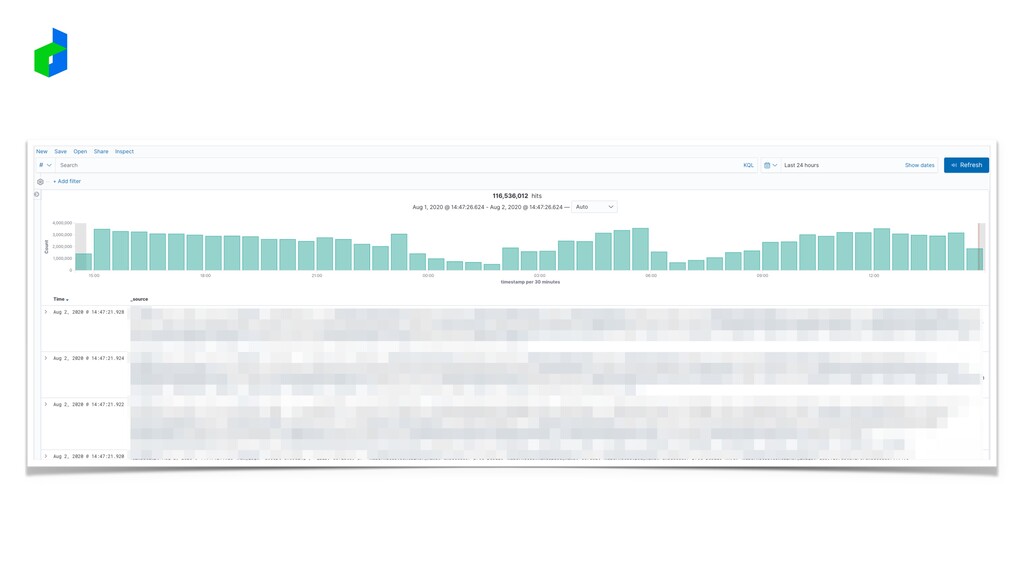
grows, the measurement grow at even the faster speed • We use thanos.io with S3-compatible object storage for scaling out • Query caching also helps scaling infrastructure much further. Have a look at trickster in github.com 4. Scaling Prometheus is Worth it All metrics at the longest possible retention
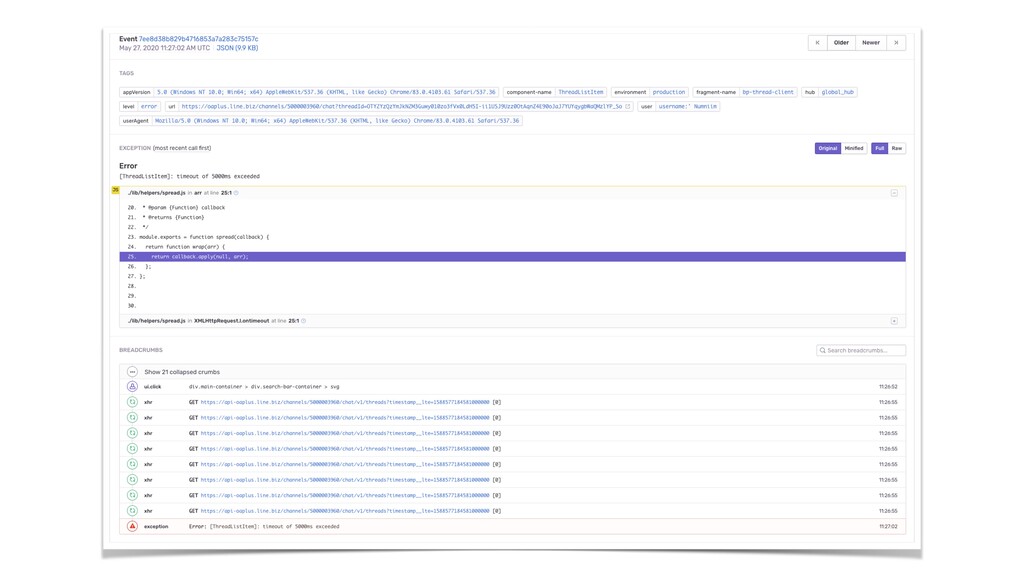
at central location • Log is expensive to ingest and query. We use ELK+Hadoop with large Kafka cluster as a transport mechanism/event source • Have standard logging pattern with consistent information level helps when you have 100s services The most detailed of telemetry class at significant cost • Pay attention to each node’s log shipper performance. Minimize on-node processing and parallelize shipping process. 5. Logging is Challenge but Worth Solving
Main Benefits: • Smart proxy fronting every pods • Decoupling RBAC from application • Treat Istio upgrade as major change. But can be really helpful 6. Service Mesh is Hard
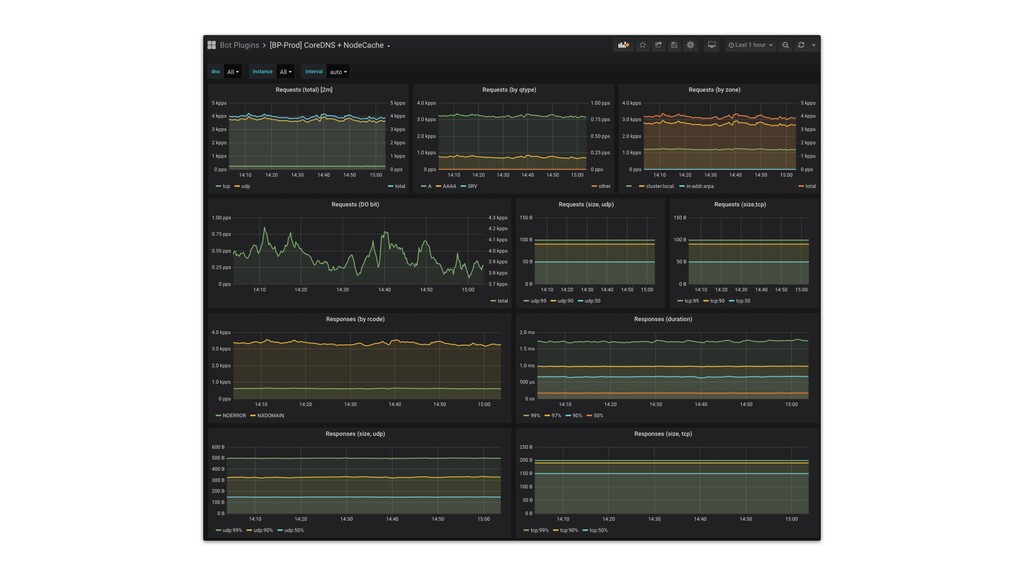
• You need DNS monitoring as first class citizen. DNS failure can be very hard to trace and cause very severe outage. • We use CoreDNS with autopath and node local cache with custom code to have multiple local cache instances for HA 7. (CORE) DNS is the Heart of Many Things
difference. We use both. • Kafka is the heart of LINE messaging and has proven to scale very far. They are complex to operate and come with some parallel processing cost. (LINE has open sourced https://github.com/line/decaton recently which might be useful) • RabbitMQ is more mature and easy to start. But beware of the scaling limitation. Major benefit over Kafka are controllable retry. 8. Kafka VS. Rabbit MQ
not straightforward without proper tool/process • Kafka offset (stores in Zookeeper) has expiration. Infrequent consumer beware! • Published message to Kafka might still lost. Check behavior of your publisher library. Some Kafka Tips
add more people/ team • Micro-service with proper API gateway at the back • Micro-frontend with proper strategy at the front 11. Prepare for Integration
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}