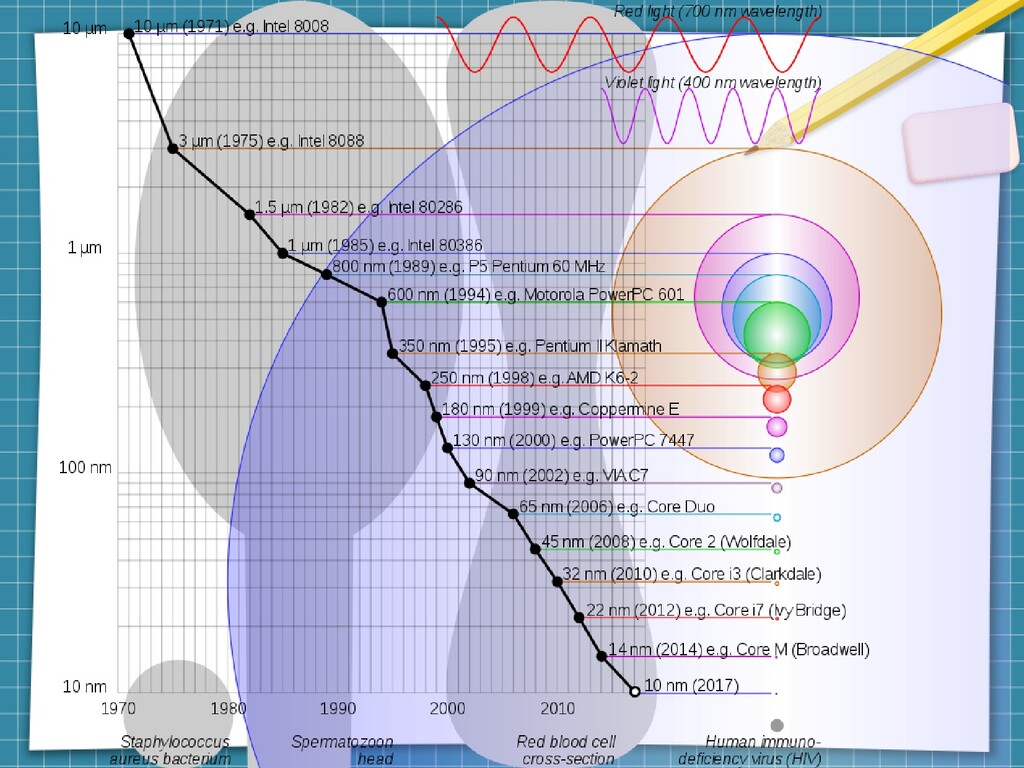
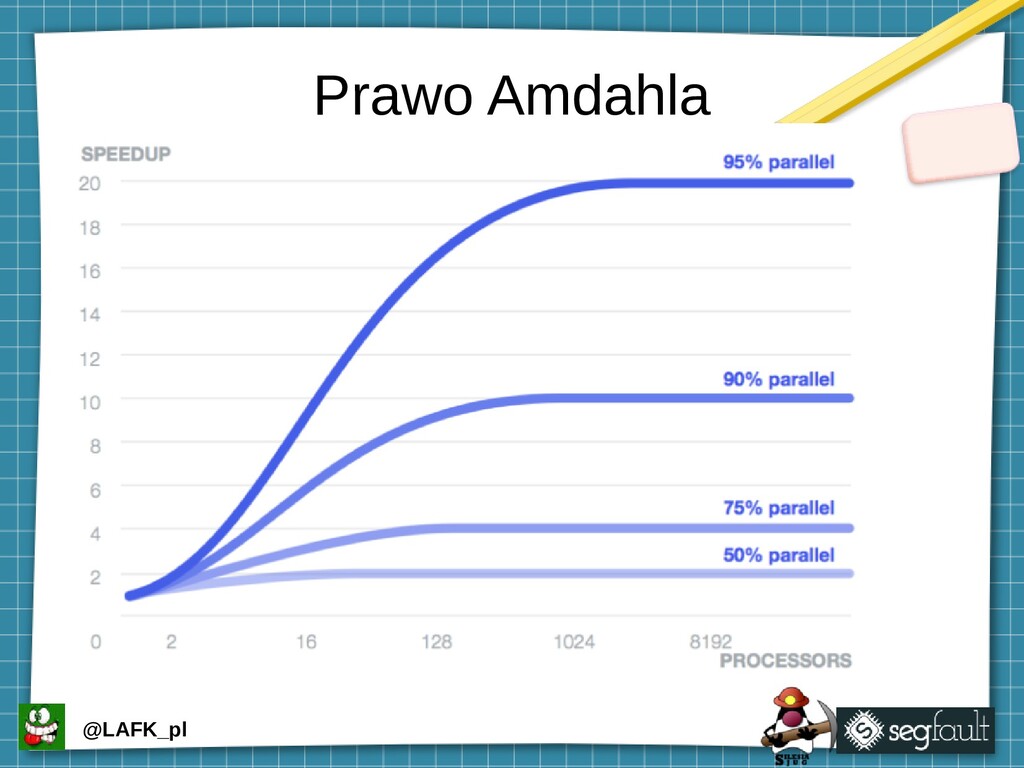
Gdy w 1967 Gene Amdahl pisał artykuł, który dał początek prawu Amdahla, zaczął go z grubej rury: “Przez ponad dekadę prorocy głosili, że osiągnięto kres możliwości organizacji pojedynczego komputera i że prawdziwie znaczące postępy mogą być poczynione tylko łącząc komputery” (tłumaczenie - i uproszczenie - cytatu moje). W 1967. Cóż. Teraz, pół wieku później, faktycznie ciężko się z tymi prorokami nie zgodzić. Moore sam stwierdził, że jego “prawo” umrze w ciągu dekady w marcu 2015., Popatrzmy zatem jak możemy wycisnąć coś z naszych maszyn i co nam może w tym przeszkodzić i dlaczego.
Czyli:
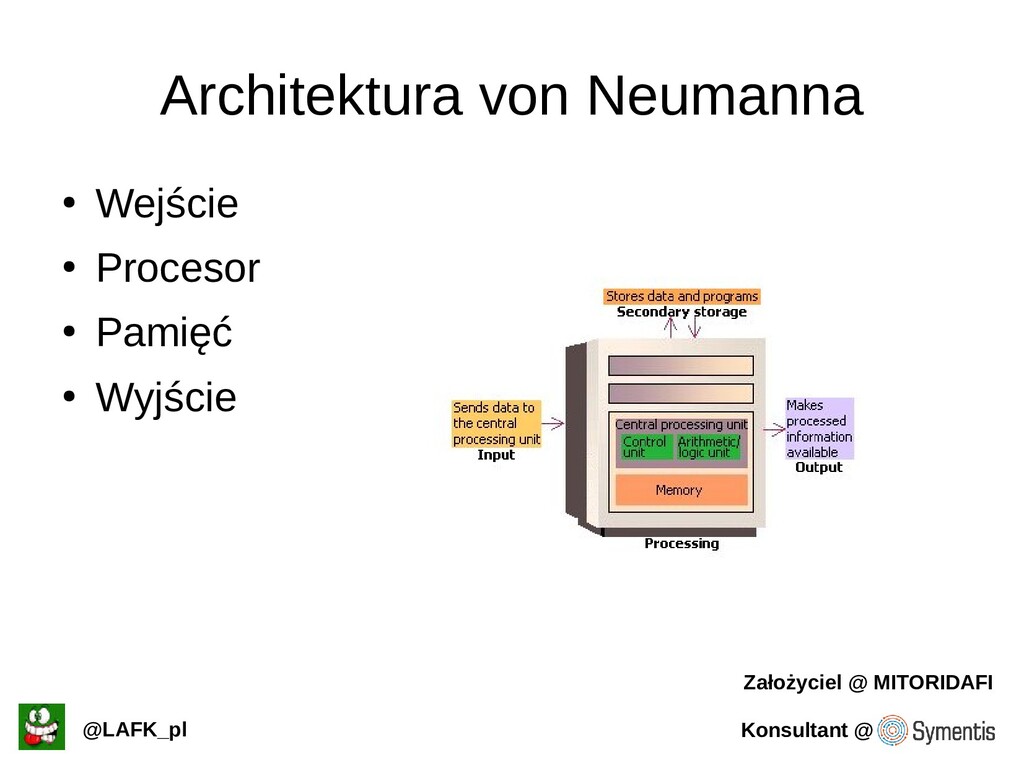
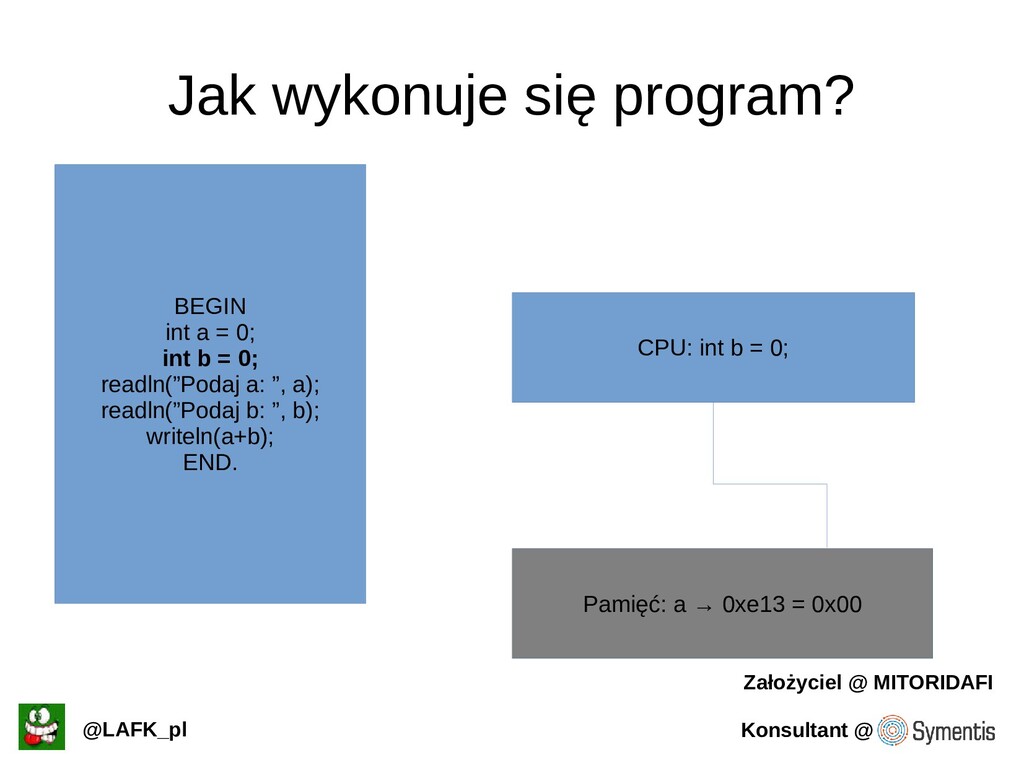
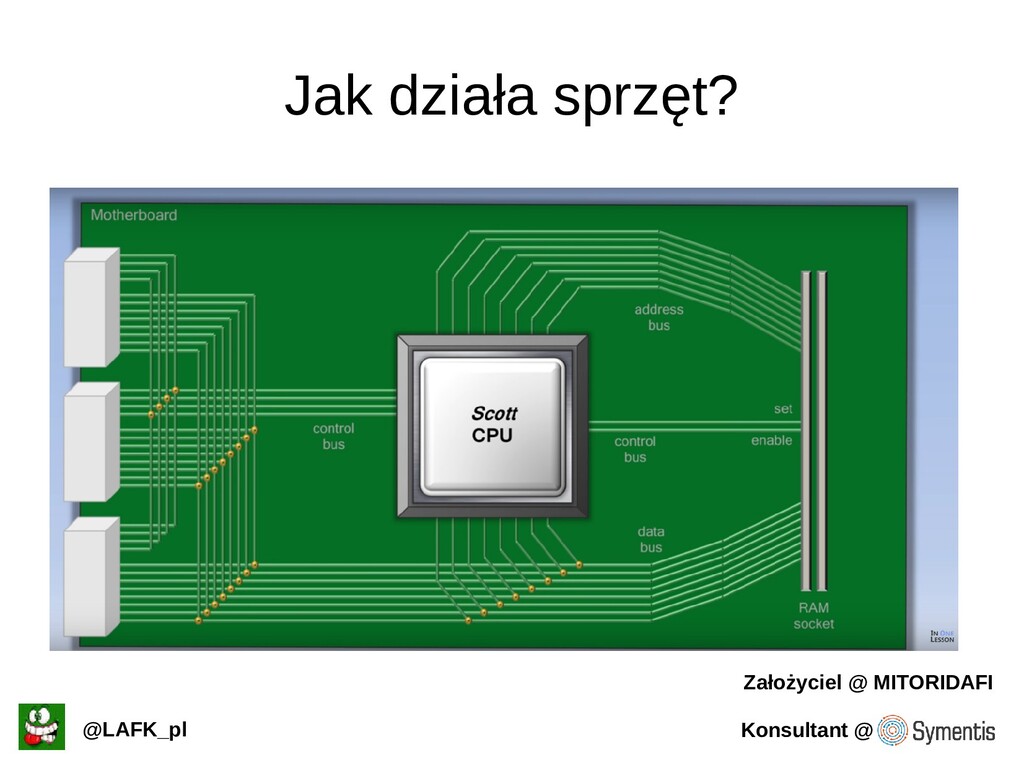
Podstawowe (i nie tylko) informacje o tym jak procesory pracują.
Kod na wiele procków na kilka sposobów.
Paradygmaty takiego kodowania: ich siły i słabości.
Różne języki.
Dobre praktyki.
Ciekawe biblioteki.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
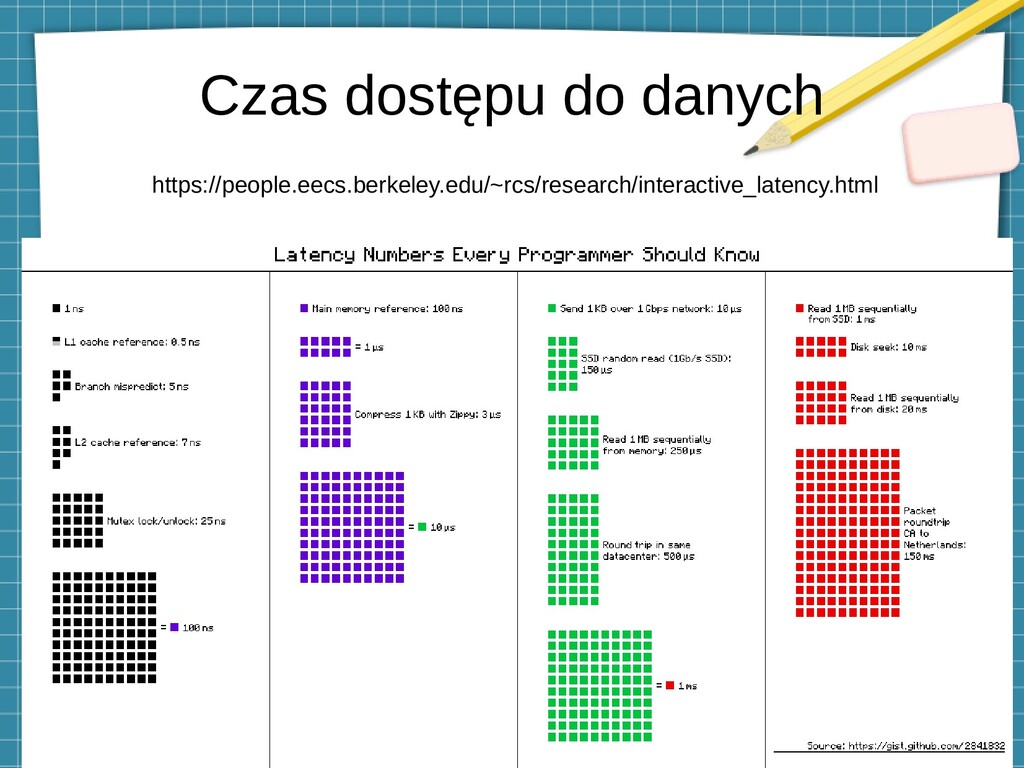{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
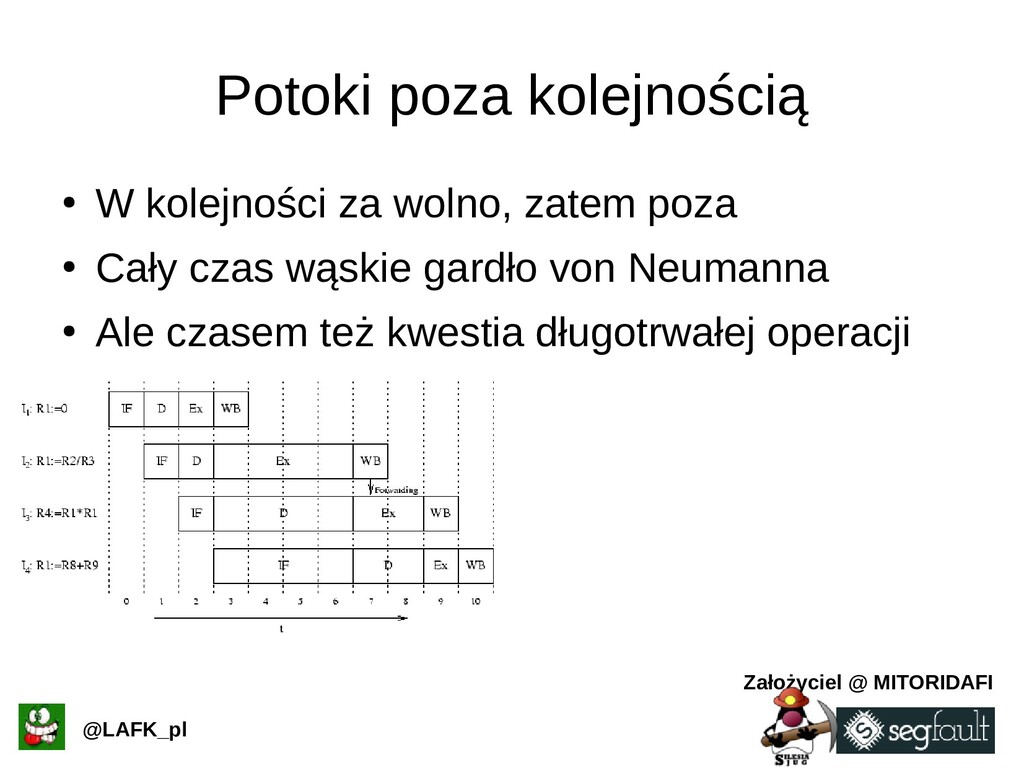{kind=link}
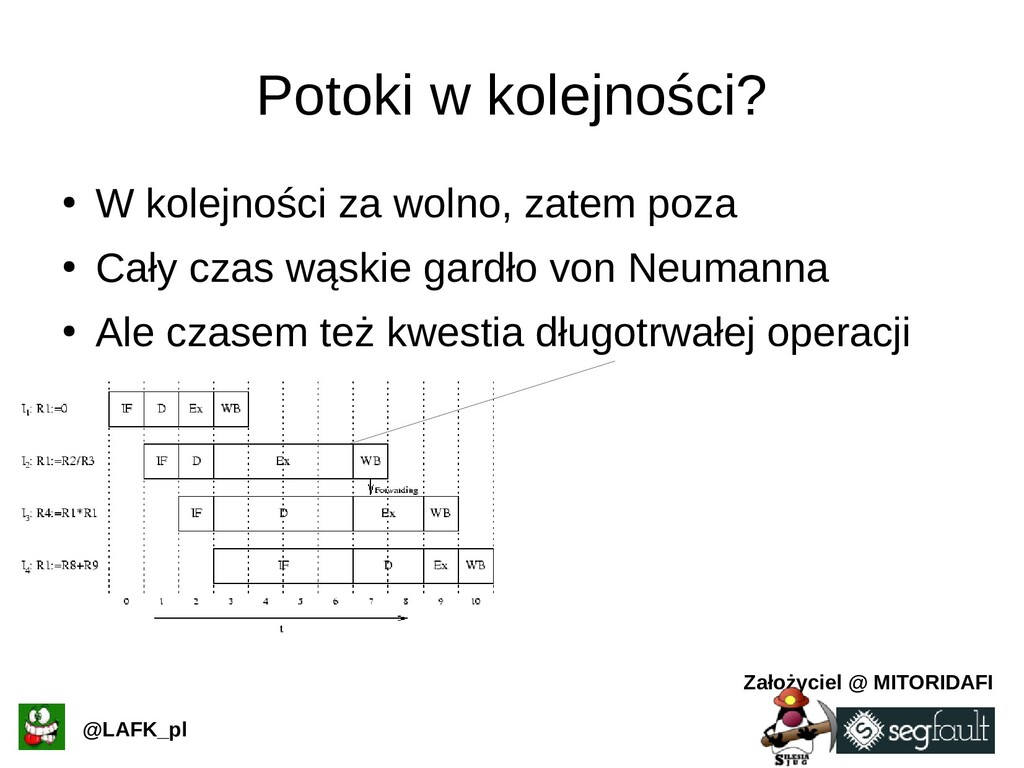{kind=link}
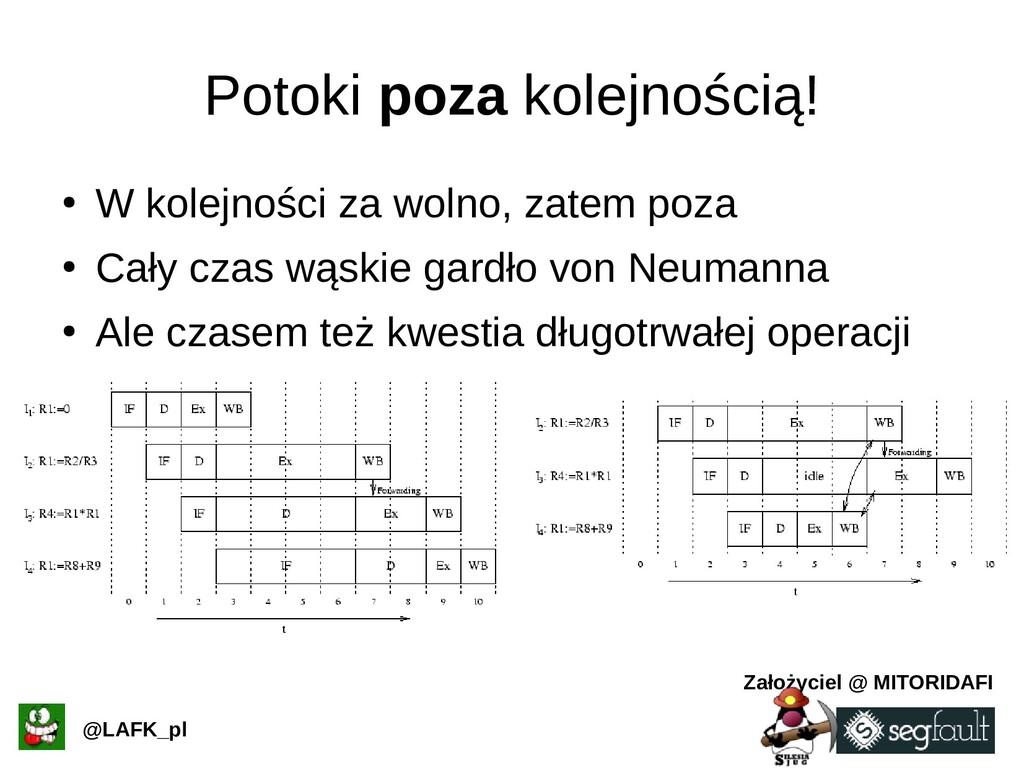{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}