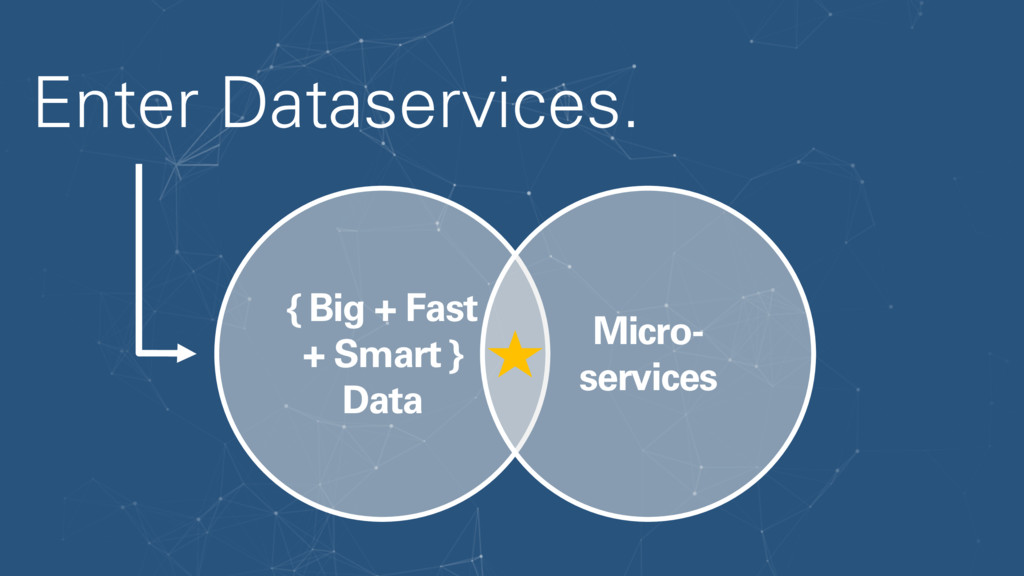
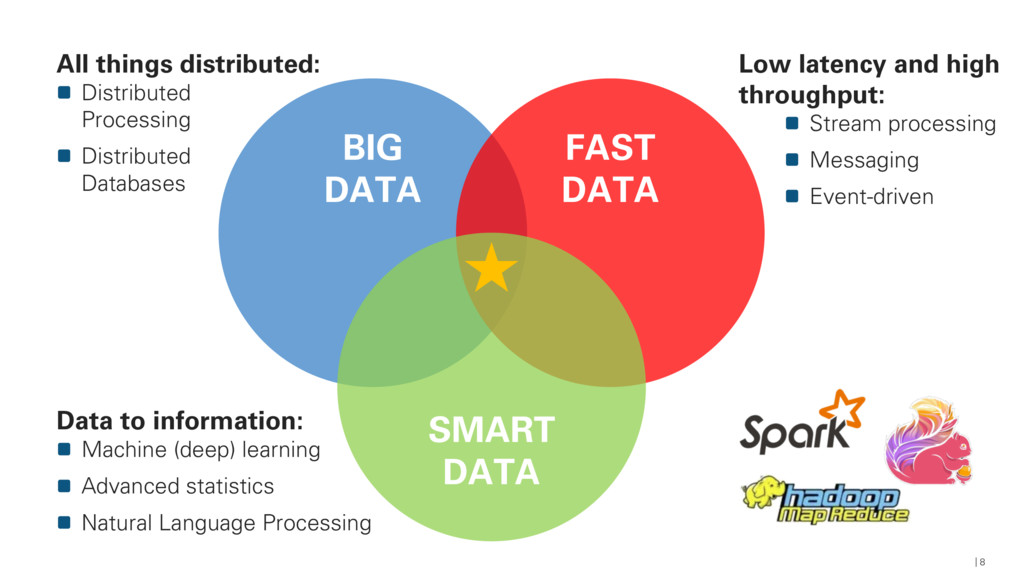
Big data processing, microservices, and cloud-native technology are a match made in computing heaven, enabling microservices to be used to build a flexible, scalable, and distributed system of loosely coupled data processing tasks, called data services.
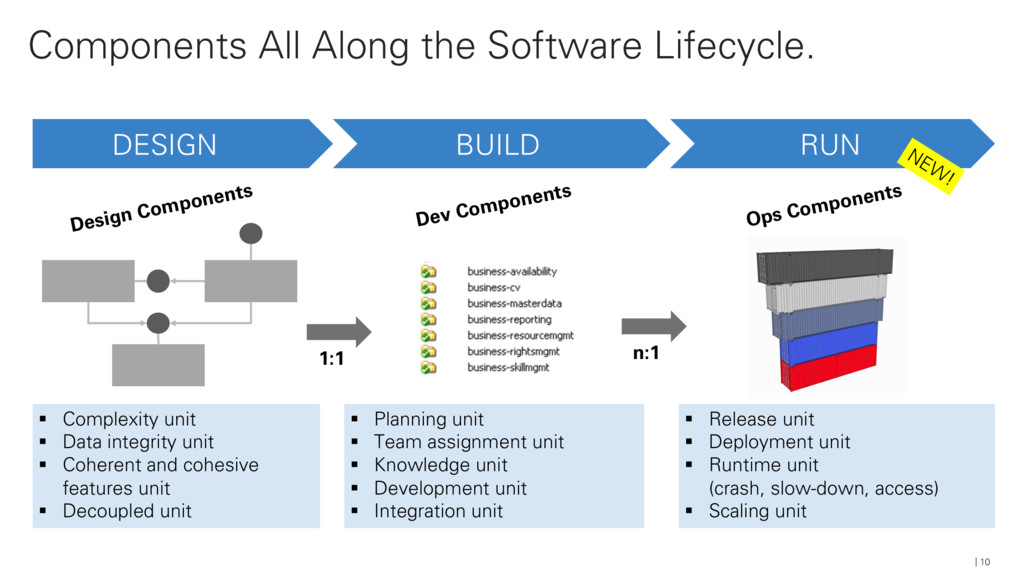
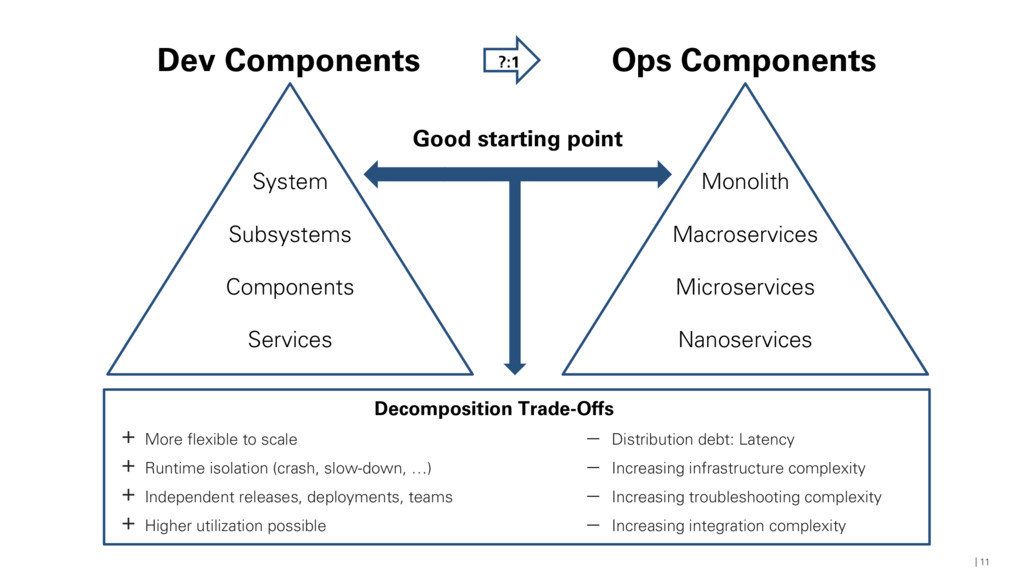
Mario-Leander Reimer explores key JEE technologies that can be used to build JEE-powered data services and walks you through implementing the individual data processing tasks of a simplified showcase application. You’ll then deploy and orchestrate the individual data services using OpenShift, illustrating the scalability of the overall processing pipeline. The context and content is taken from a real-world project for a major German car manufacturer, implementing a microservices-based processing pipeline that uses car-related event data (sensor data, traffic events, and other real-time data) for a traffic information management and route optimization system. #CloudNativeNerd @OReillySACon
![Mario-Leander Reimer [email protected] @LeanderReimer Dataservices Processing Big Data the Microservice](https://files.speakerdeck.com/presentations/f529cf609fd148dabf196a0841618a06/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
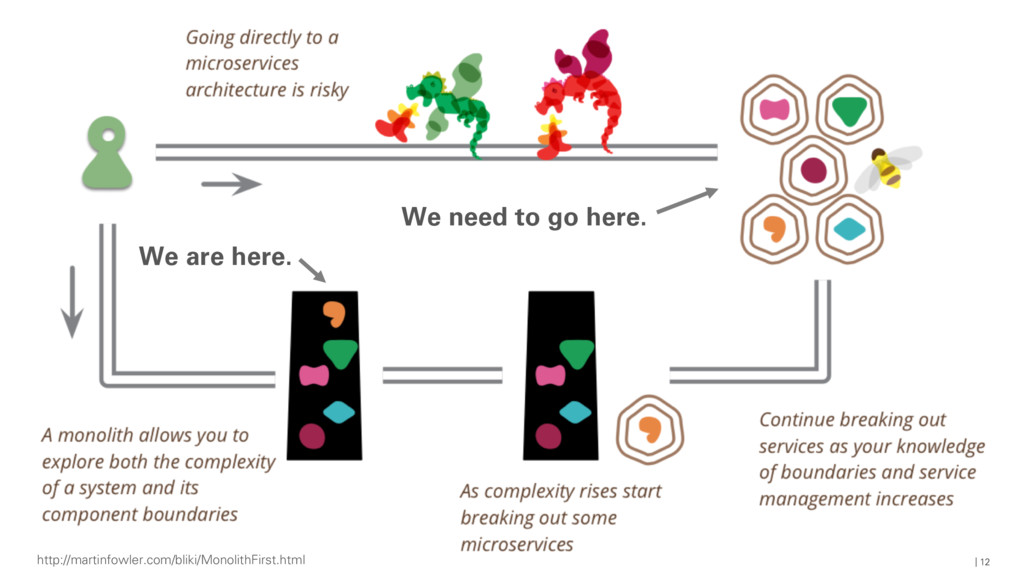{kind=link}
{kind=link}
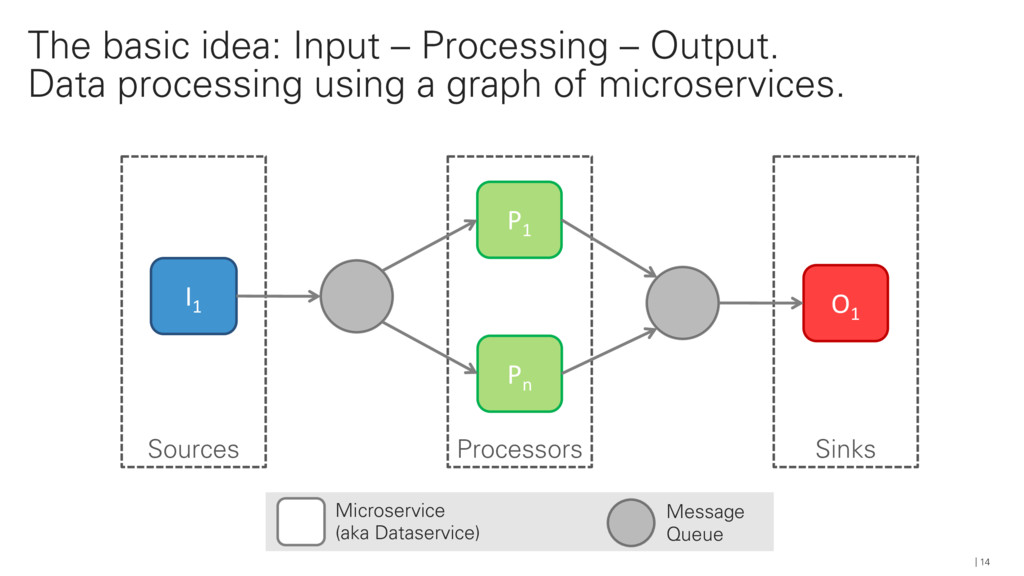{kind=link}
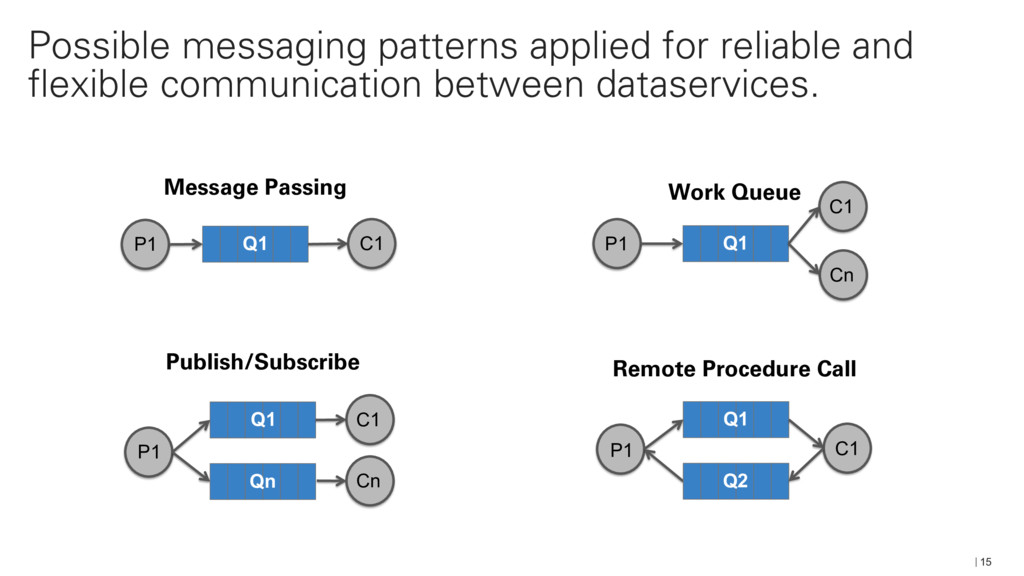{kind=link}
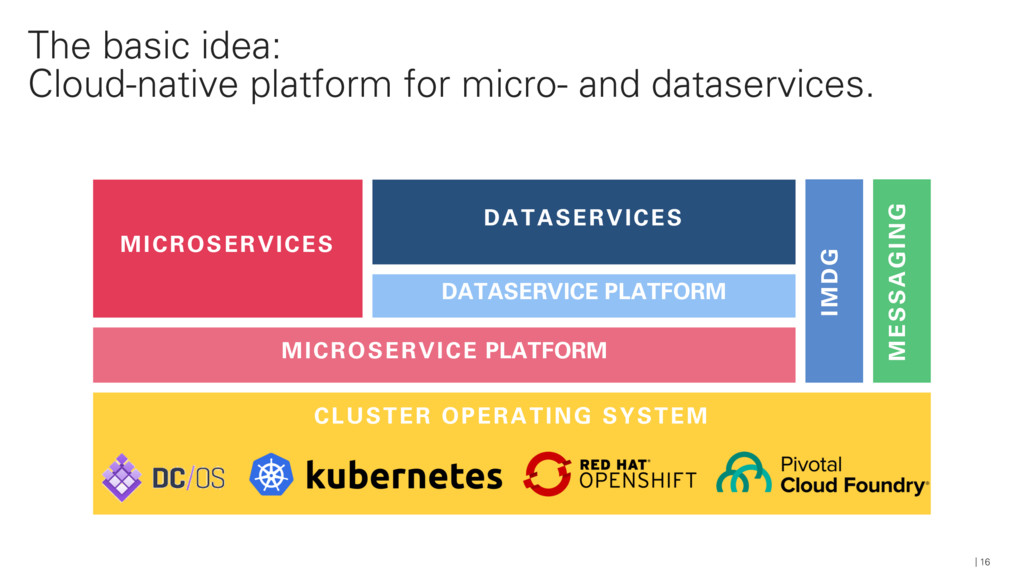{kind=link}
{kind=link}
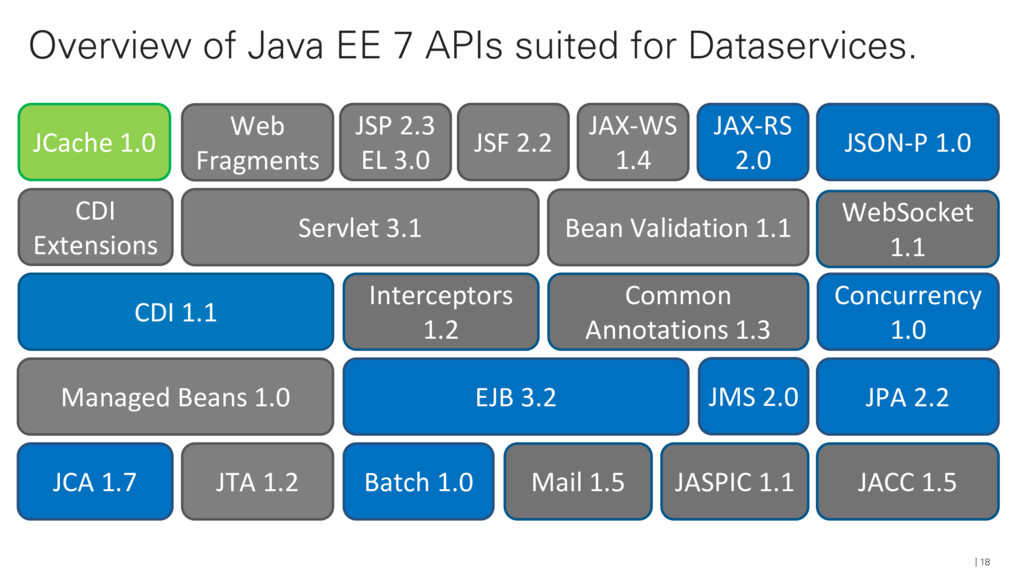{kind=link}
{kind=link}
{kind=link}
{kind=link}
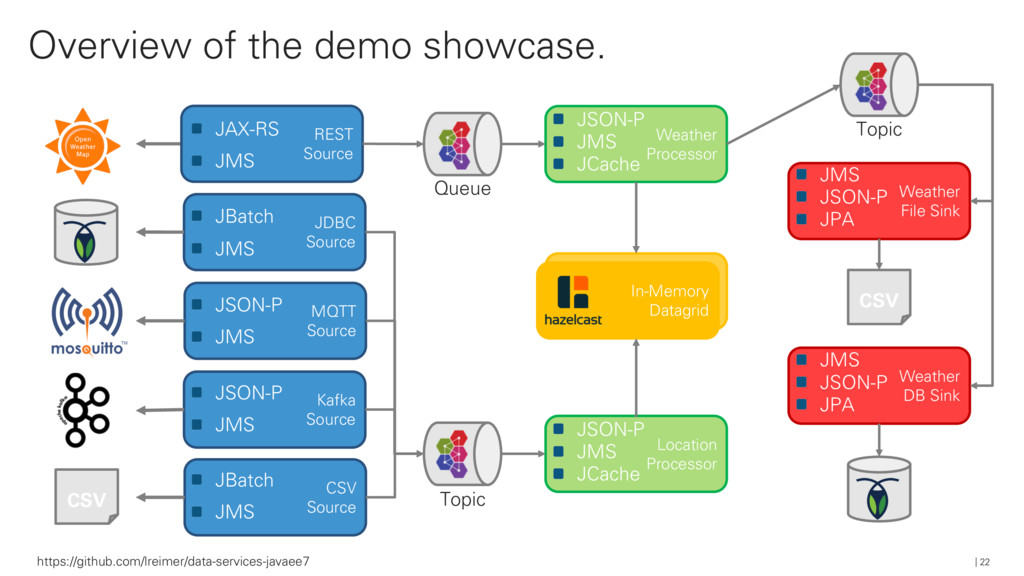{kind=link}
{kind=link}
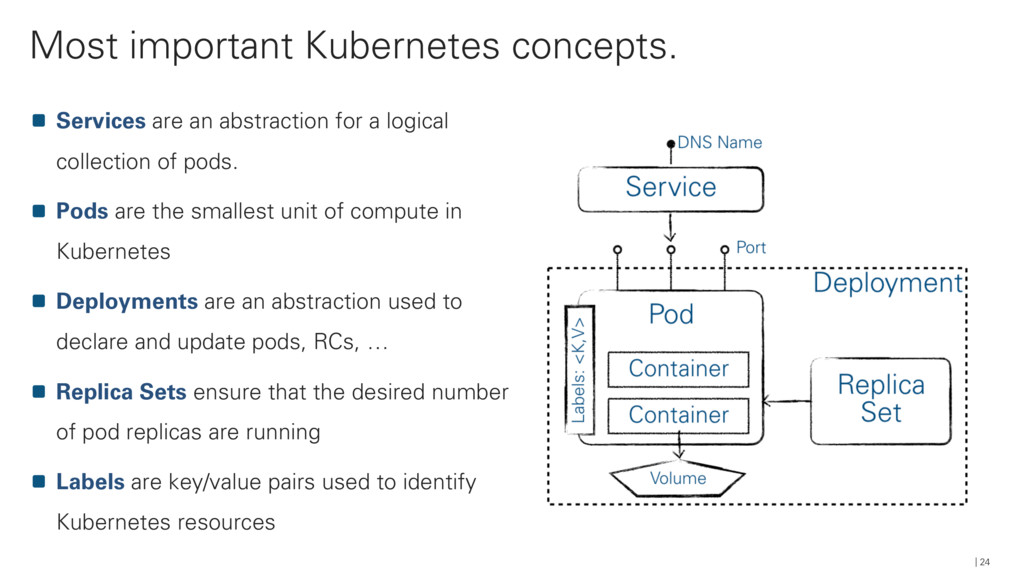{kind=link}
{kind=link}
{kind=link}
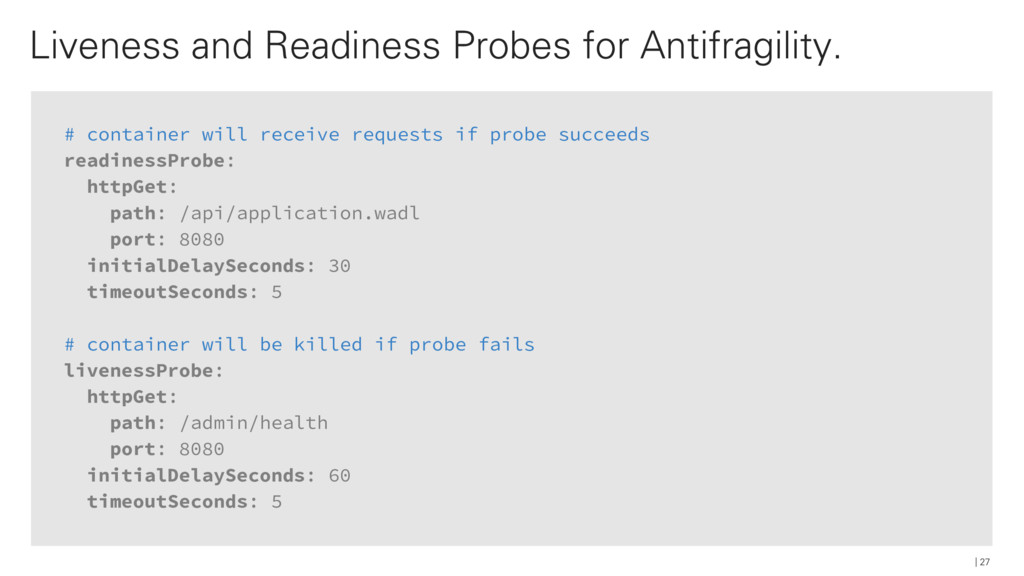{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mario-Leander Reimer [email protected] @LeanderReimer xing.com/companies/qawaregmbh linkedin.com/company/qaware-gmbh slideshare.net/qaware twitter.com/qaware youtube.com/qawaregmbh github.com/qaware](https://files.speakerdeck.com/presentations/f529cf609fd148dabf196a0841618a06/slide_29.jpg){kind=link}