a maior parte dos bancos SQL • Implementação ◦ Tabelas com colunas fixas. ◦ Todas as linhas tem as mesmas colunas • O banco só armazena atributos préviamente definidos/permitidos pelo schema • CREATE TABLE ...
de transações • Transações podem conter múltiplas operações ◦ Diferentes linhas ◦ Diferentes tabelas ◦ E ainda continuam a ser executadas atômicamente Lembra do exemplo clássico da transação bancária ?
checar os nossos dados ◦ A nível de Schema ( Colunas e Tipos de dados ) ◦ Referências ( Chaves-estrangeiras, integridade referencial ) ◦ Unique constraints ◦ E outras podem ser definidas pelo usuário
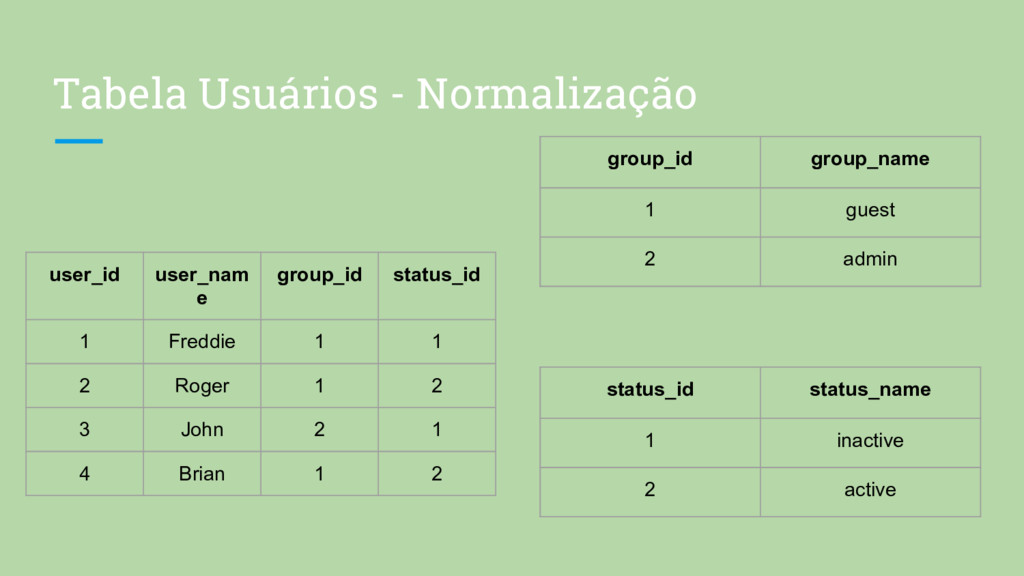
fazer um uso adequado do banco de dados relacional • A falta de normalização pode causar problemas com a integridade dos dados e pode também dificultar sua recuperação através de consultas SQL. • Desnormalização só é tolerada em favor de desempenho
manipulação de dados dinâmicos • Usar campos BLOB impede o uso de alguns recursos do banco em relação aos dados armazenados • ALTER TABLE ◦ Pode diminuir a performance ou até mesmo bloquear o banco. ◦ Dados precisam ser ajustados quando os Schemas são atualizados ◦ O código da aplicação precisa se manter “ciente” sobre o schema do banco
para converter os dados do banco para a estruturas e tipos de dados da linguagem. • Às vezes um objeto deve ser buscado em várias tabelas, consequentemente usando várias consultas.
tarefa difícil: ◦ Transações e Joins são custosas para o banco. Se tornam mais custosas ainda quando tem de ser executadas entre múltiplos nós ( Comunicação, Locks ) ◦ A maioria dos bancos relacionais não oferecem suporte nativo para escalabilidade ou particionamento ◦ Muitas vezes o particionamento é implementado na própria aplicação.
resposta à esses problemas dos bancos relacionais. Os bancos relacionais tem sido a principal tecnologia de banco de dados há mais de 30 anos. No entanto, enfrentam alguns problemas: • Dificuldade para escalar • Dificuldade para lidar com grandes volumes de dados • Incompatibilidade de Impedância
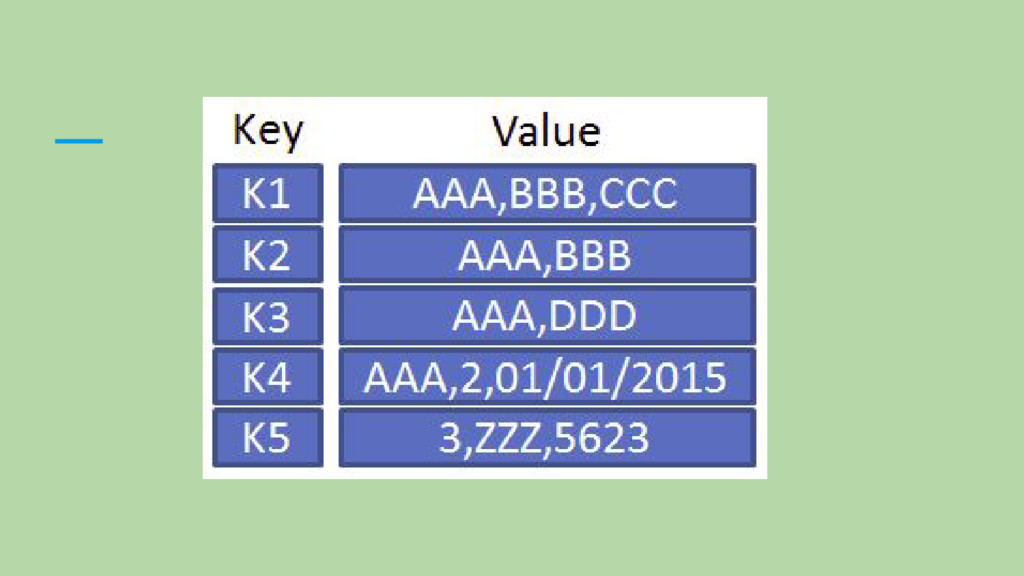
valor • Para o banco, o “value” não tem estrutura: Você pode armazenar qualquer coisa. • O valor só pode ser recuperado pela chave. Nem todos os bancos oferecem uma listagem das chaves para que você possa recuperá-las. ( Embora alguns bancos permitam índices secundários para recuperação dos dados ). • Alguns bancos dessa categoria trabalham com o conceito de banco em memória. • Exemplos: Riak, Redis, Memcached
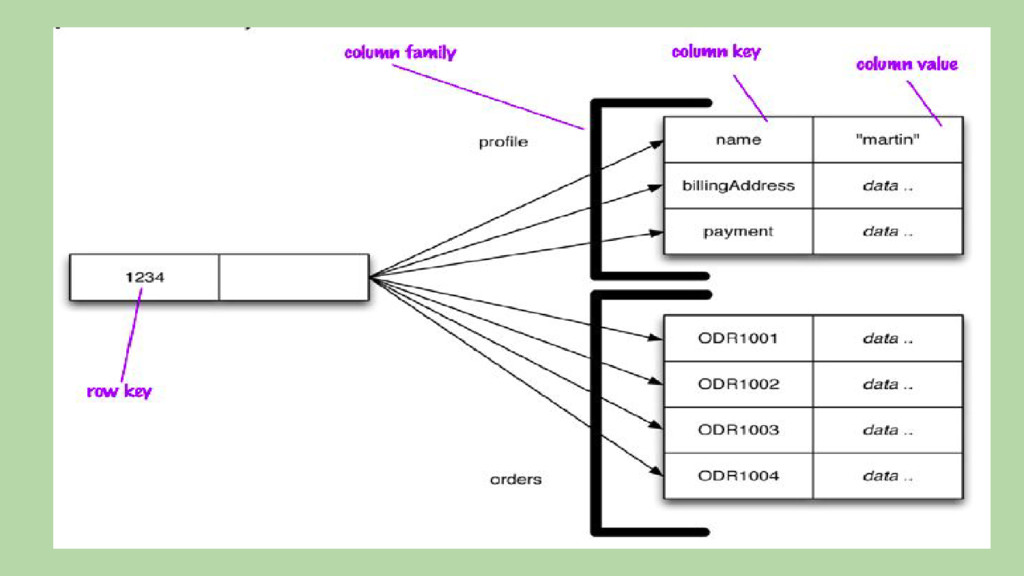
coluna e timestamp • Colunas são agrupadas em Super Colunas. • Família de colunas: ◦ Colunas de uma mesma família são armazenadas no mesmo sistema de arquivos. • Exemplos: Apache Cassandra, HBase
operação que afeta um único registro é atômica. Em operações que afetam mais de um registro o banco pode não garantir a atomicidade, consistência e isolação.
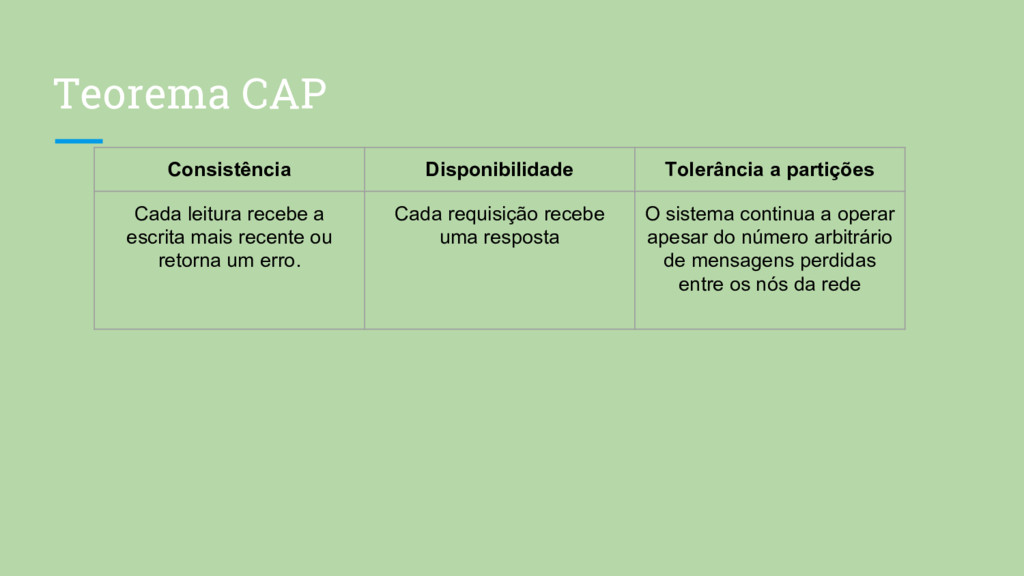
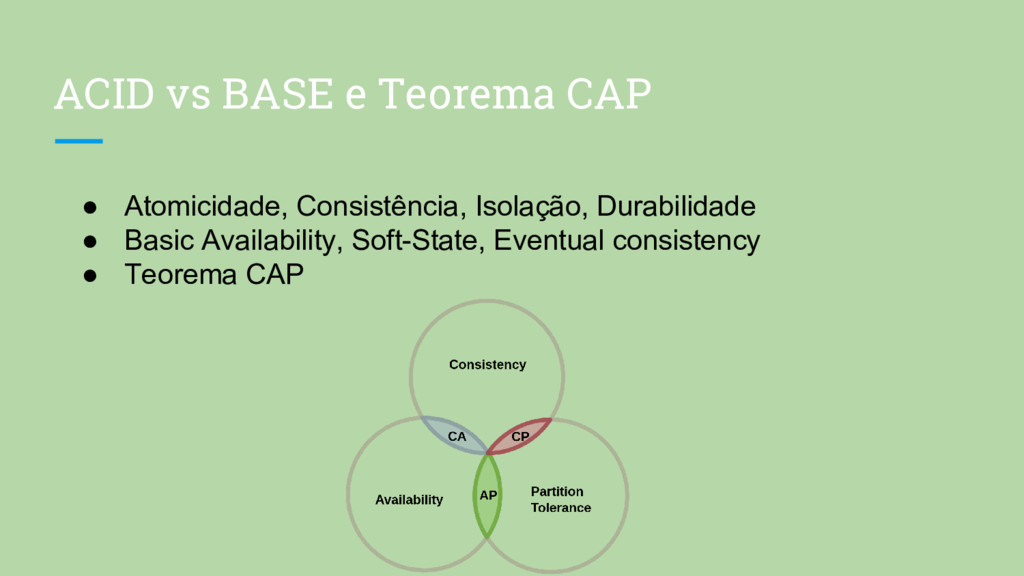
a escrita mais recente ou retorna um erro. Cada requisição recebe uma resposta O sistema continua a operar apesar do número arbitrário de mensagens perdidas entre os nós da rede
pela disponibilidade e tolerância a particionamento. • Dados entram em conflito normalmente. • Sua aplicação pode ter que tratar em algum momento dados conflitantes.
não garante a consistência, então os dados devem ser modelados de maneira que uma entidade lógica deva ser salva como um único registro. • Exemplo: Usuário, Produto • Essa abordagem permite escrever/ler a entidade atomicamente
duplicados no banco de dados. • Exemplo: Incorporar os dados de um ou mais autores no próprio registro de determinado livro. • Isto também facilita a consulta, já que ao recuperar o livro os dados do autor estão embutidos.
podem ser problemáticas, pois há cópias distribuídas pelo banco e todas elas precisam ser atualizadas. • As próprias cópias podem se tornar inconsistentes
◦ Quando os dados incorporados muito raramente (ou nunca) sofrem atualizações. ◦ Cache ◦ Quando o tempo de vida da incorporação é curto • Em qualquer outro caso, deve-se usar a linkagem
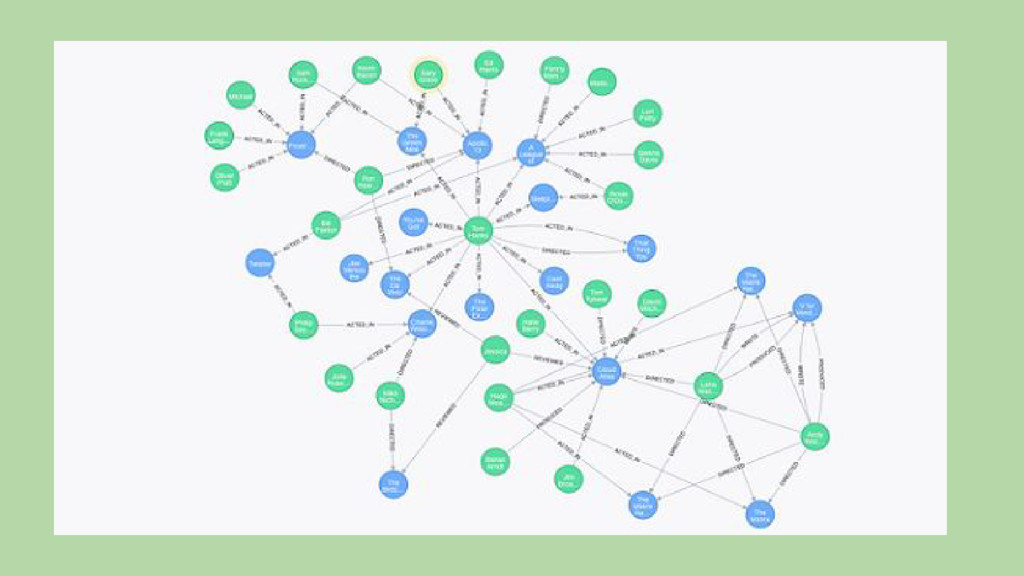
além de tabelas, colunas e relacionamentos. • A persistência poliglota é a possibilidade de se aplicar diversos modelos de dados para a construção de uma aplicação. Pode-se buscar vantagens em cada modelo para a resolução de uma parte do problema e aplicá-la. • Exemplo: ◦ Aplicação de E-commerce: ▪ Sistema de Recomendação: Grafos (Neo4J) ▪ Sessões de usuário: Chave-valor (Riak) ▪ Produtos, Clientes, Vendas: Documentos (MongoDB) ▪ Data-warehouse: Relacional (PostgreSQL)
modelos de dados • Focam em ser no mínimo tão eficientes em desempenho quanto os bancos NoSQL especializados nos modelos que aborda. • Reduzem os custos de aprendizagem e manutenção. • Exemplos: ArangoDB, CosmosDB, CouchBase, CrateDB
em uma única instância e uma só linguagem de consulta (AQL) • Escrito em C++ • Extensível através de JavaScript ( Foxx framework, Services ) • Lançamento: 2011 • Atualmente com cerca de 1.4 milhões de downloads • Mais de 180 casos de uso do banco em produção Compania: • ArangoDB GmbH - 2014 • Equipe: 30 pessoas • Sede: Colonia, Alemanha
uma startup • Oferecem: ◦ Suporte profissional com preço reduzido ◦ Ajudam a desenvolver seu produto rapidamente ◦ Resposta rápida a problemas críticos • ArangoDB GmbH recebeu entre 2016 e 2017 mais de € 6 milhões em investimentos. • Informações: ◦ https://www.arangodb.com/startup-accelerator-program/
ter informações como data de publicação, tags relacionadas, autor(es) e editora. O cliente pode ter vários endereços cadastrados para entrega, assim como pode cadastrar mais de um cartão de crédito para efetuar compras na nossa loja. A aplicação deve ainda armazenar os livros visitados pelo cliente, afim de que se possa fazer recomendações futuras ao cliente baseado no que ele procura.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}