Processing (almost) real-time data streams usually turns out to be an extremely difficult task. Events are comming fast, in hundreds, thousands or tens of thousands per second. The logic behind each event can be extremely complex or/and time-consuming, so executing it in HTTP request-response flow sometimes does not seem to be the best possible way. Fortunately, there are at least several methods of supporting event processing in our applications.
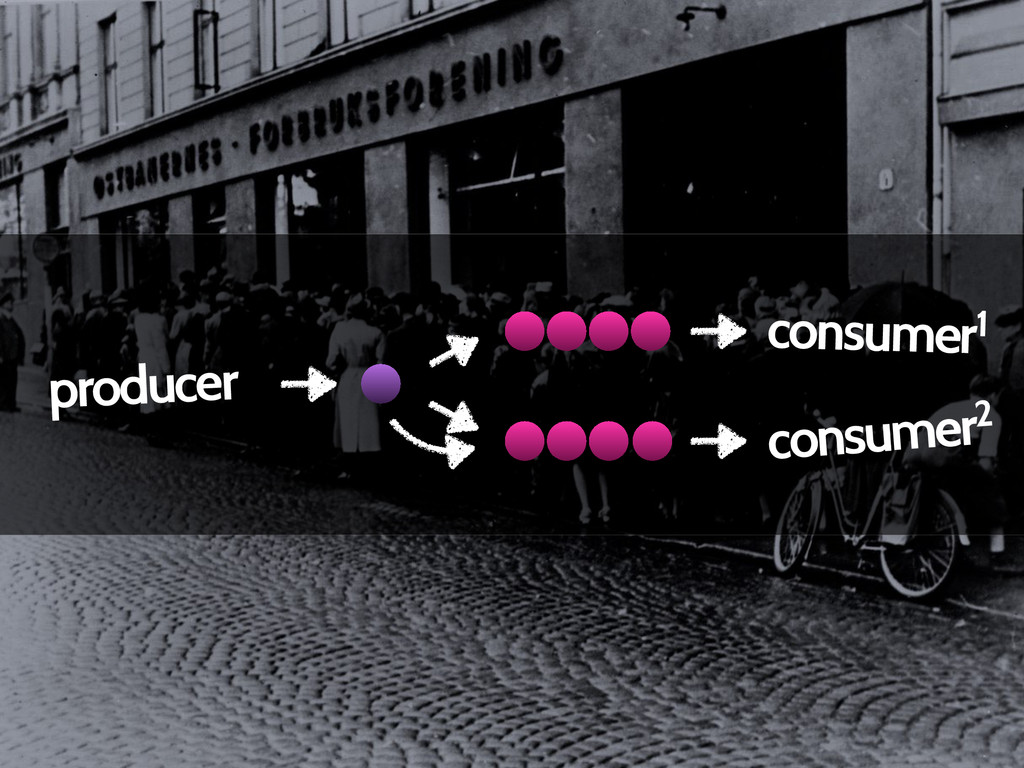
During this talk, I would like to introduce you to some basic concepts that are behind event processing distribution on server clusters. I am going to briefly cover the example of queue systems based on RabbitMQ queue where one can store and route messages between producers and consumers, or distributed real-time computation system like Apache Storm where you can build complex topologies and process even million tuples per second per each node. Technology is important but what seems to be even more important is moving the center of gravity of event processing from http request-response flow to some separated layer that could be scaled to the limits.
Additionally, we will also talk about data stream events storage. Sharded SQL databases or base Hadoop-powered tools are good but there are dedicated tools on the market, like Druid, where we can store and aggregate billions of events without any problem.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
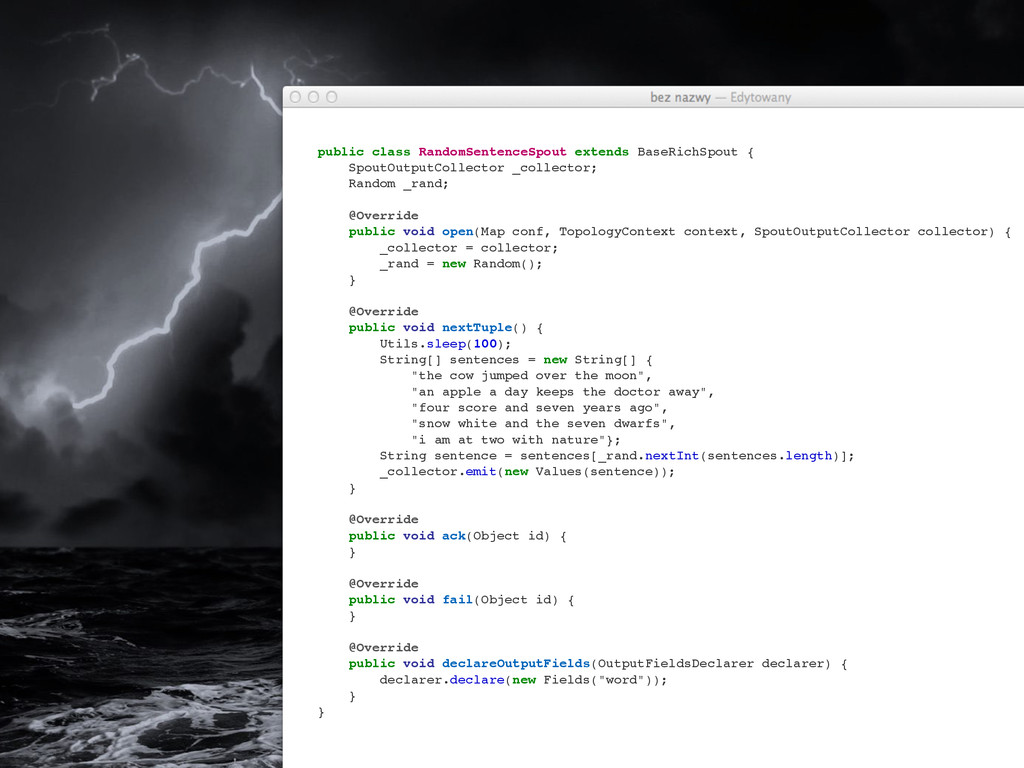{kind=link}
{kind=link}
![public class WordCountTopology { public static void main(String[] args) throws](https://files.speakerdeck.com/presentations/244547f010c34e47a1418833aa75fc0a/slide_37.jpg){kind=link}
{kind=link}
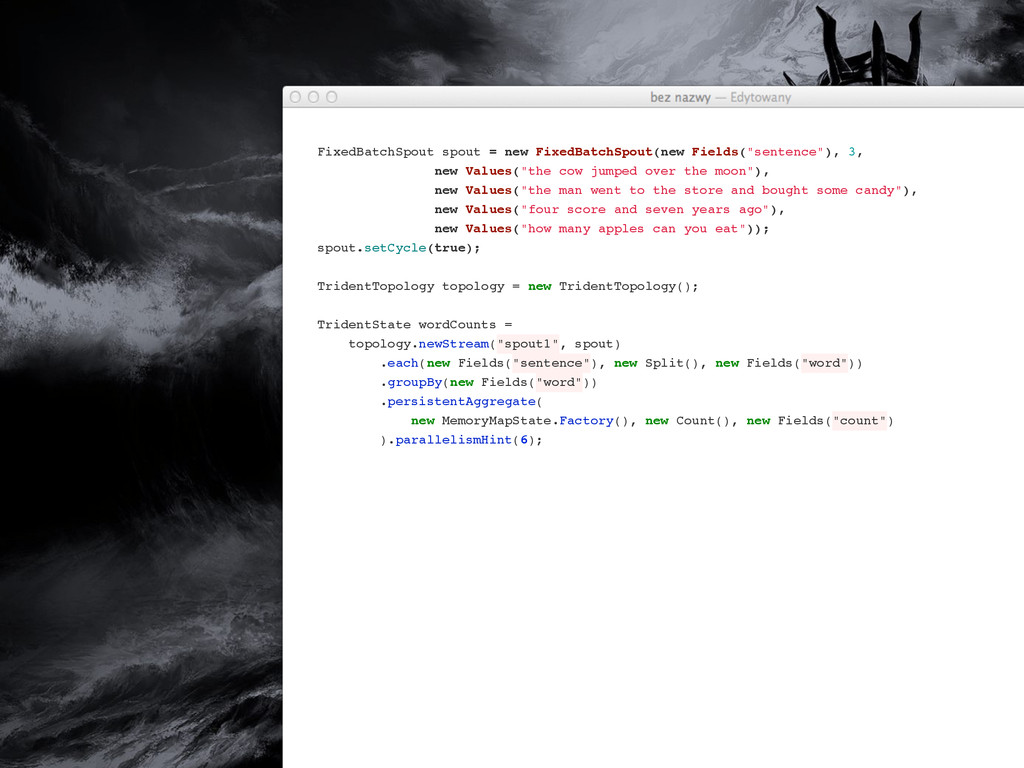{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}