million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
_rand; @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { _collector = collector; _rand = new Random(); } @Override public void nextTuple() { Utils.sleep(100); String[] sentences = new String[] { "the cow jumped over the moon", "an apple a day keeps the doctor away", "four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"}; String sentence = sentences[_rand.nextInt(sentences.length)]; _collector.emit(new Values(sentence)); } @Override public void ack(Object id) { } @Override public void fail(Object id) { } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
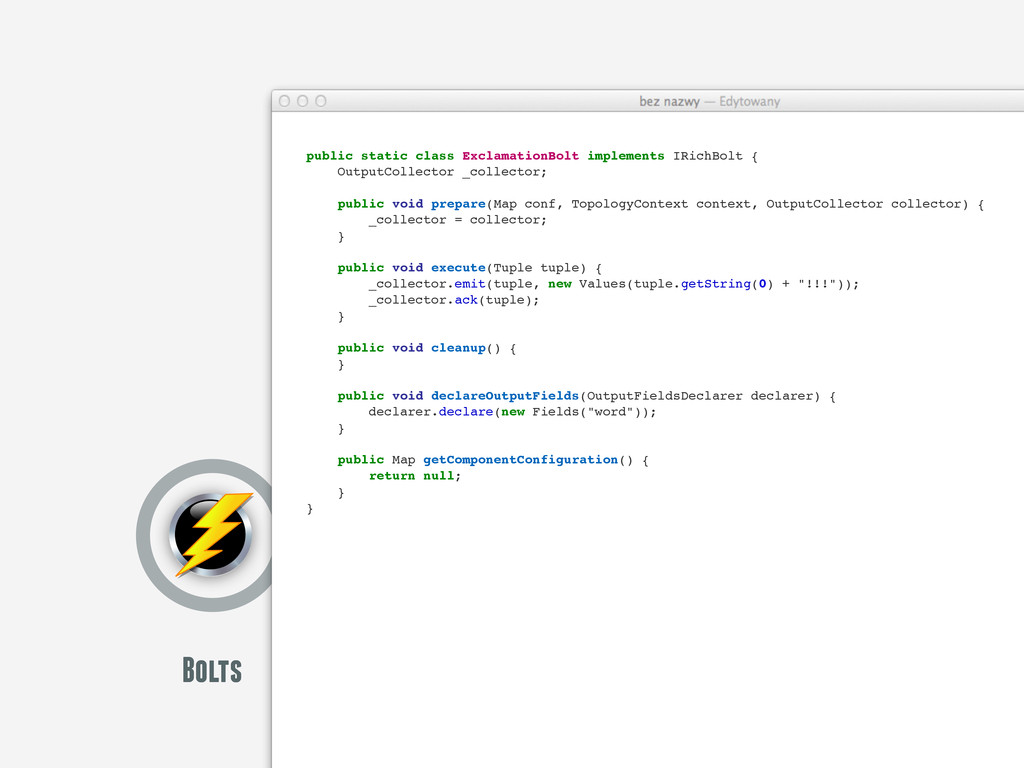
public SplitSentence() { super("python", "splitsentence.py"); } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } } import storm class SplitSentenceBolt(storm.BasicBolt): def process(self, tup): words = tup.values[0].split(" ") for word in words: storm.emit([word]) SplitSentenceBolt().run()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Topologies network of spouts and bolts TextSpout SplitSentenceBolt WordCountBolt [sentence]](https://files.speakerdeck.com/presentations/a4bfff70c854013098062ea774d31c7c/slide_19.jpg){kind=link}
![Topologies network of spouts and bolts TextSpout SplitSentenceBolt WordCountBolt [sentence]](https://files.speakerdeck.com/presentations/a4bfff70c854013098062ea774d31c7c/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Topology public class WordCountTopology { public static void main(String[] args)](https://files.speakerdeck.com/presentations/a4bfff70c854013098062ea774d31c7c/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Topology public class WordCountTopology { public static void main(String[] args)](https://files.speakerdeck.com/presentations/a4bfff70c854013098062ea774d31c7c/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
![RPC distributed arguments results [request-id, arguments] [request-id, results]](https://files.speakerdeck.com/presentations/a4bfff70c854013098062ea774d31c7c/slide_37.jpg){kind=link}
![RPC distributed arguments results [request-id, arguments] [request-id, results] public static](https://files.speakerdeck.com/presentations/a4bfff70c854013098062ea774d31c7c/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
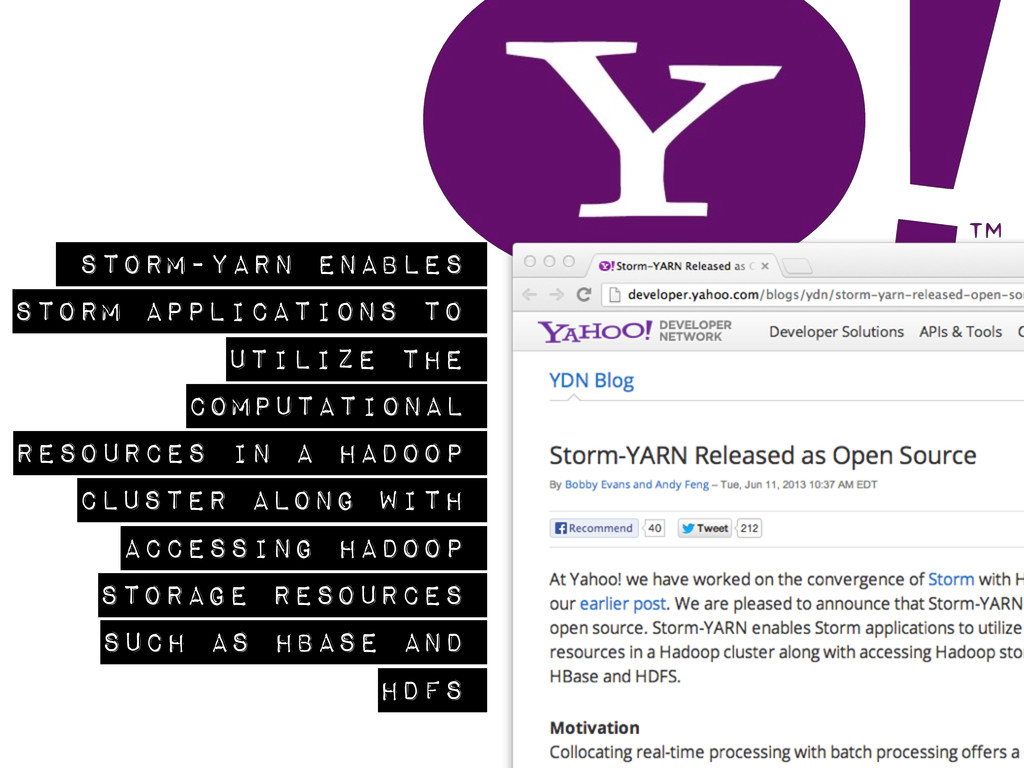{kind=link}
![thanks! mail: [email protected] twitter: @mariuszgil](https://files.speakerdeck.com/presentations/a4bfff70c854013098062ea774d31c7c/slide_43.jpg){kind=link}