organizations be successful with Data and AI • Mix of Data Engineers, Data Scientists, Machine Learning Engineers, Analytics Engineers & Analytics Translators • Based in Amsterdam & Eindhoven • Part of Xebia Data & AI • The best Payment Service Provider out there • Founded in 2004 by Adriaan Mol • Mission to simplify financial services by creating world-class products • Currently active for merchants in European Economic Area (EEA), Switzerland, and the United Kingdom
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
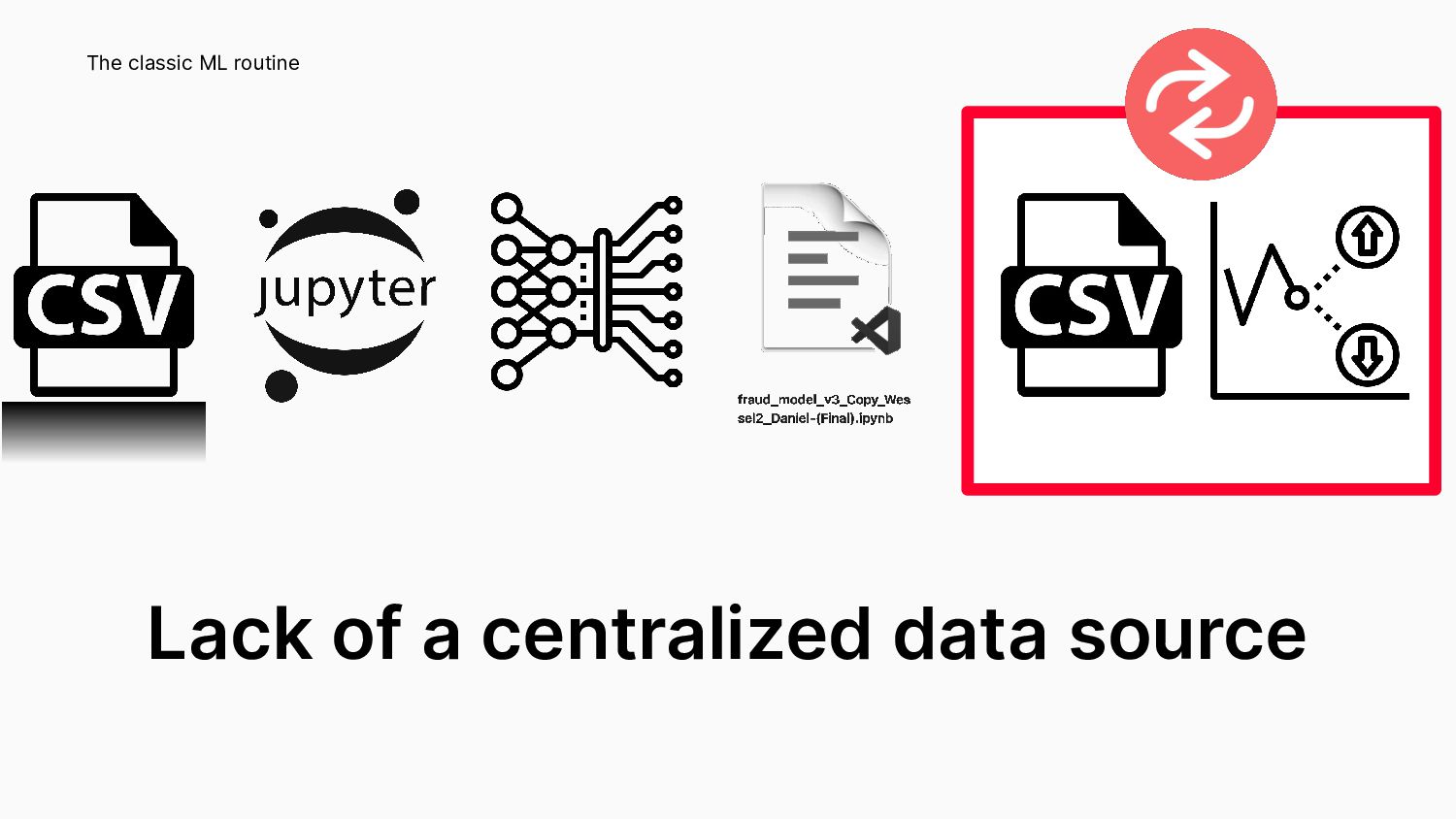{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
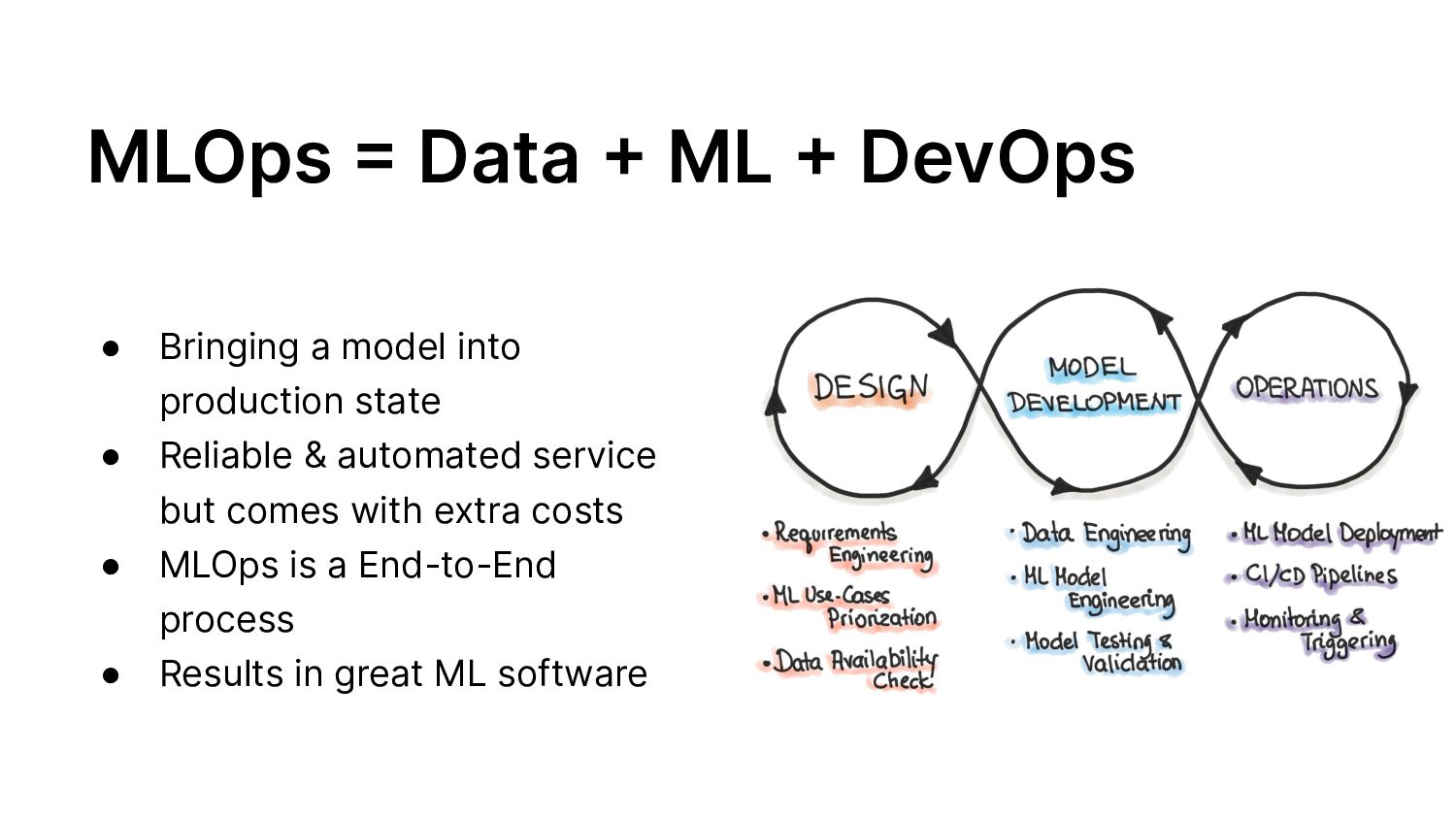{kind=link}
{kind=link}
{kind=link}
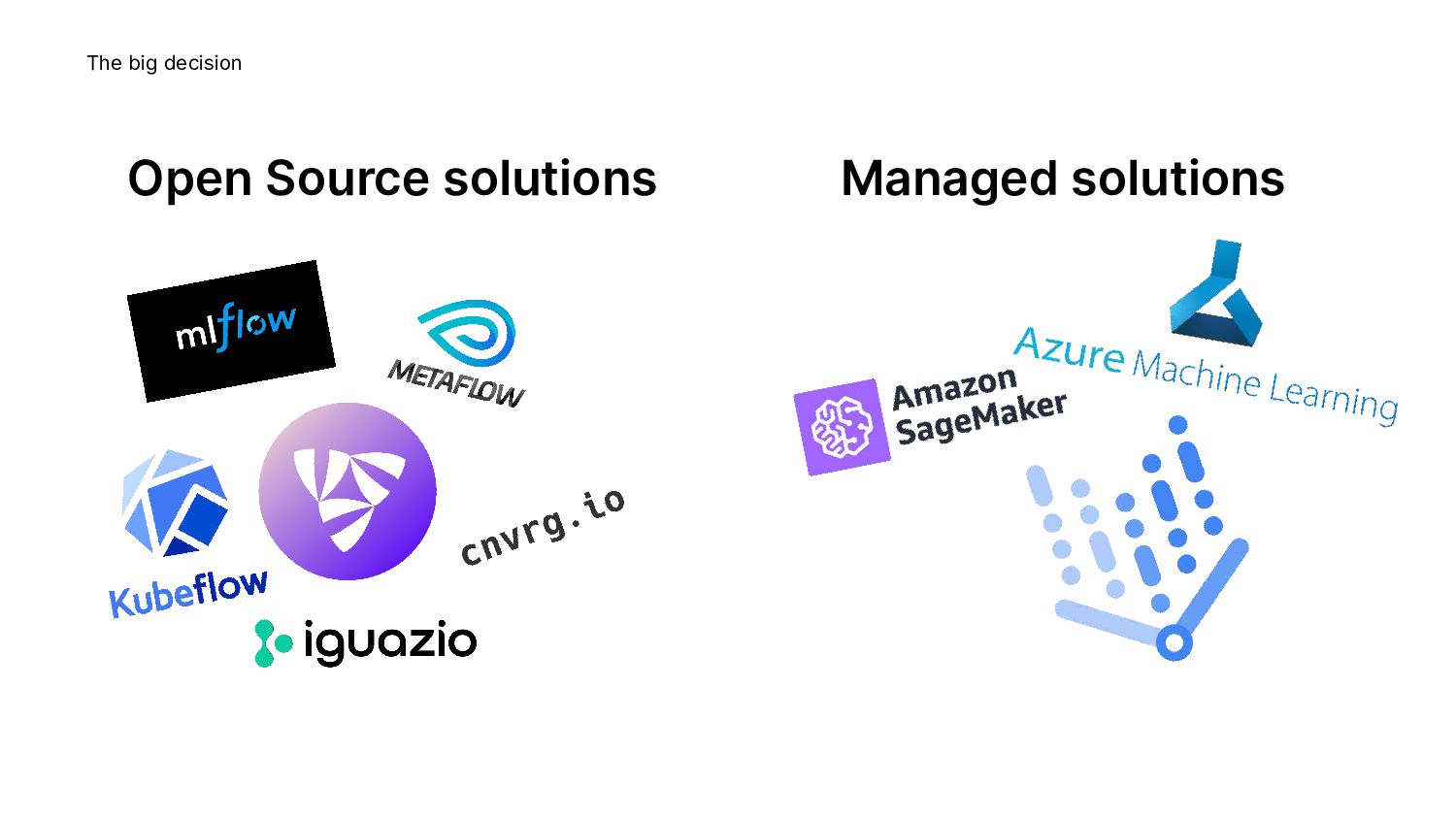{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}