dataset we are collecting from scratch, Using data that we are allowed to use, Striving to be as transparent and compliant as possible The road to GPT-NL
Education Healthcare Government Law enforcement Defense Focus on three main capabilities: 1. Summarisation 2. Simplification 3. Retrieval-Augmented Generation (RAG)
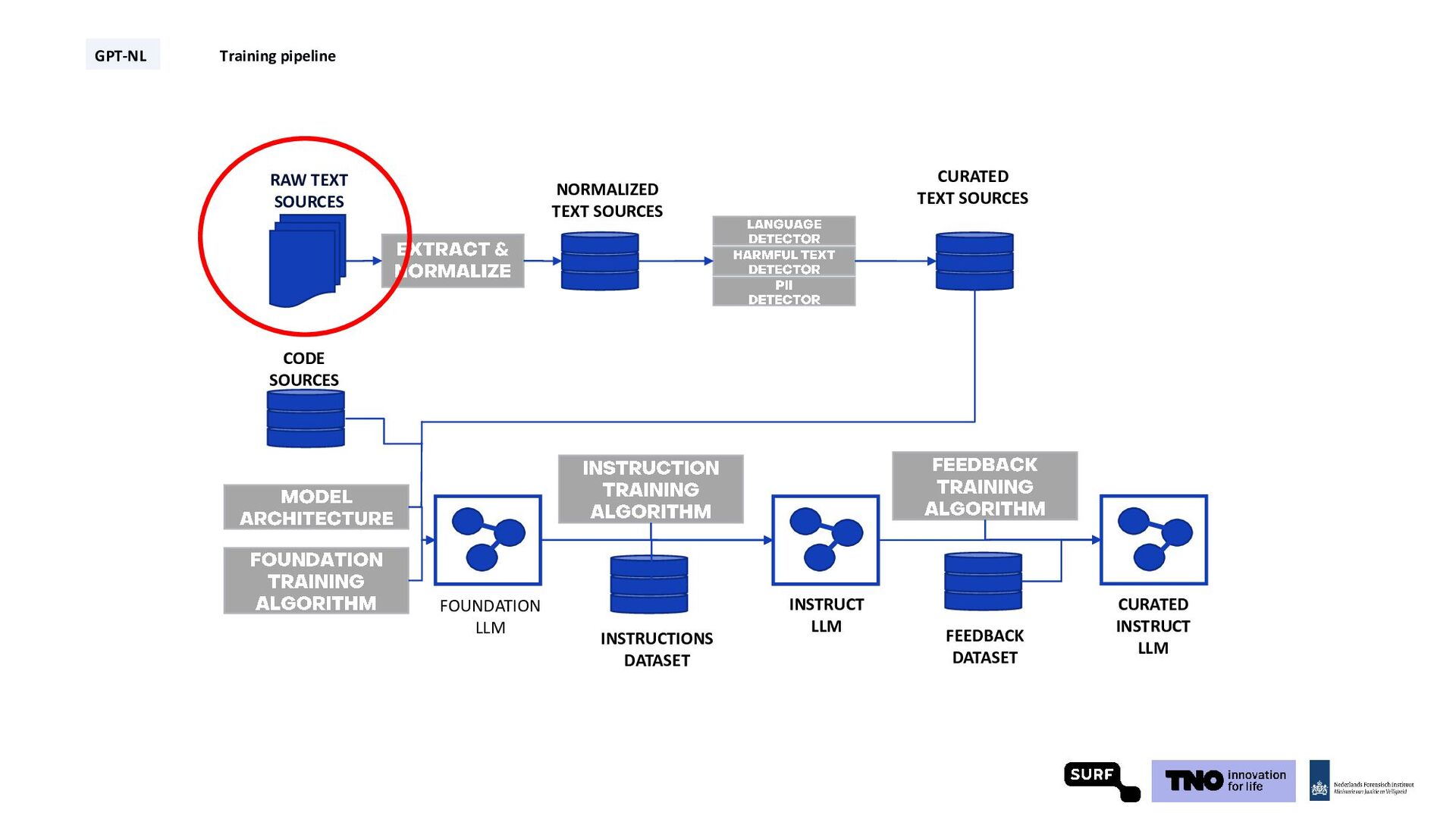
the first Harry Potter book … ± 6 x all Dutch newspapers and magazines … ± 5 km of pages when printed … 2% of Llama 3’s training data GPT-NL Training pipeline Dall-E imagines large amounts of text
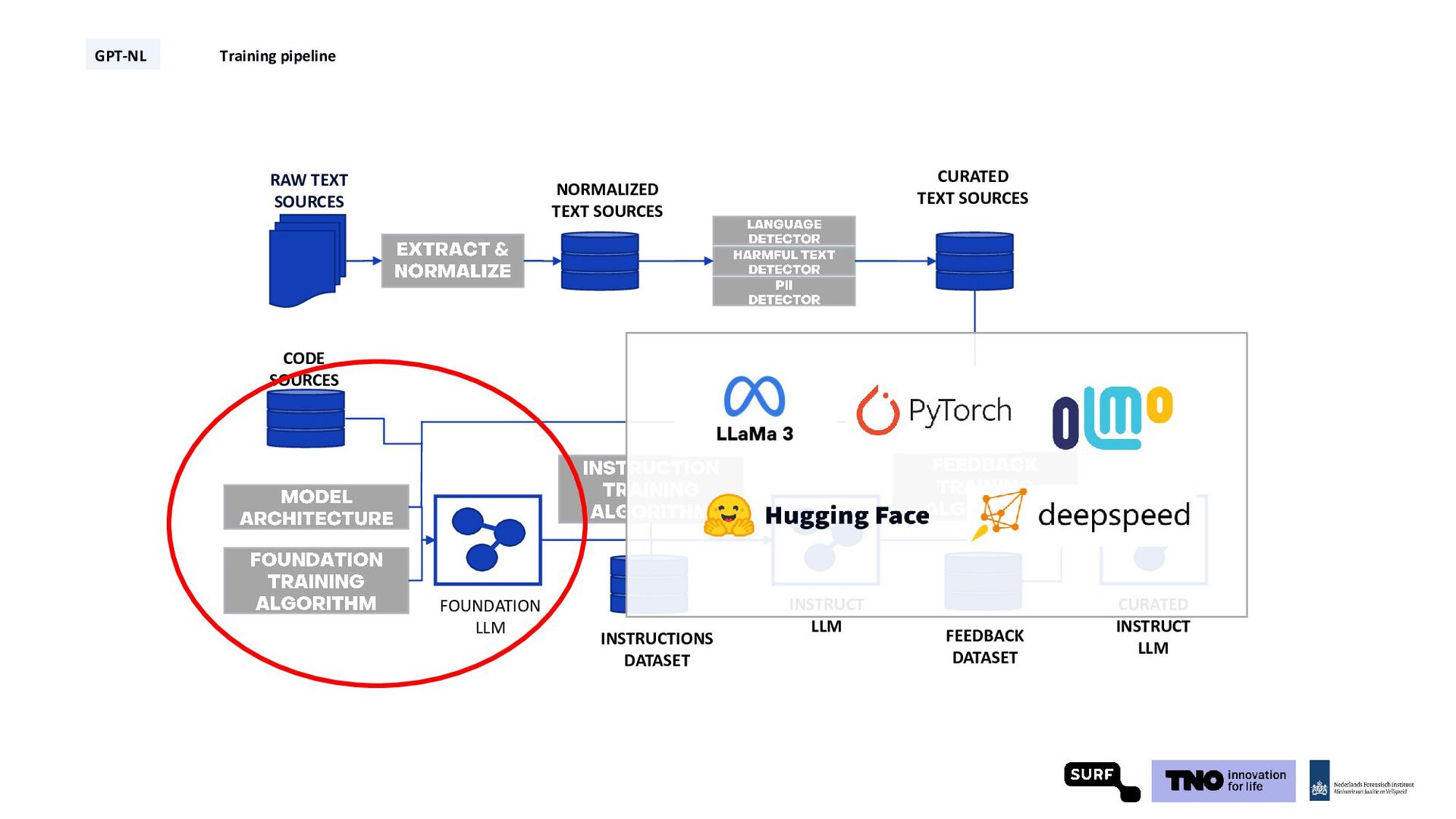
Technical Report: Pretraining in Days, Not Months (2024), Gunasekar et al., Textbooks Are All You Need (2023), Sachdeva et al., How to Train Data-Efficient LLMs (2024) GPT-NL Training pipeline synthetic data* code data high quality web data w/ permissive licenses proprietary data from contributors * Still under consideration
Muennighoff et al., Scaling Data-Constrained Language Models (2023) Training pipeline larger model size • Larger models are smarter with same number of processed tokens • However, costlier for inference Touvron et al, Llama 2: Open Foundation and Fine-Tuned Chat Models (2023) synthesis • Style transfer • Machine translation • Structured data to text data • Rewriting data
for training Architecture and code for data curation and model training Q2 2024 Future Data for finetuning Training GPT-NL set-up NextGen GPT-NL Q3 2025
To make it as relevant and useful as possible, your data and input is crucial Want to participate? We need • Use Case providers • Data providers • End users More info or contact? Go to www.gpt-nl.nl or mail [email protected] GPT-NL GPT-NL GPT-NL Future
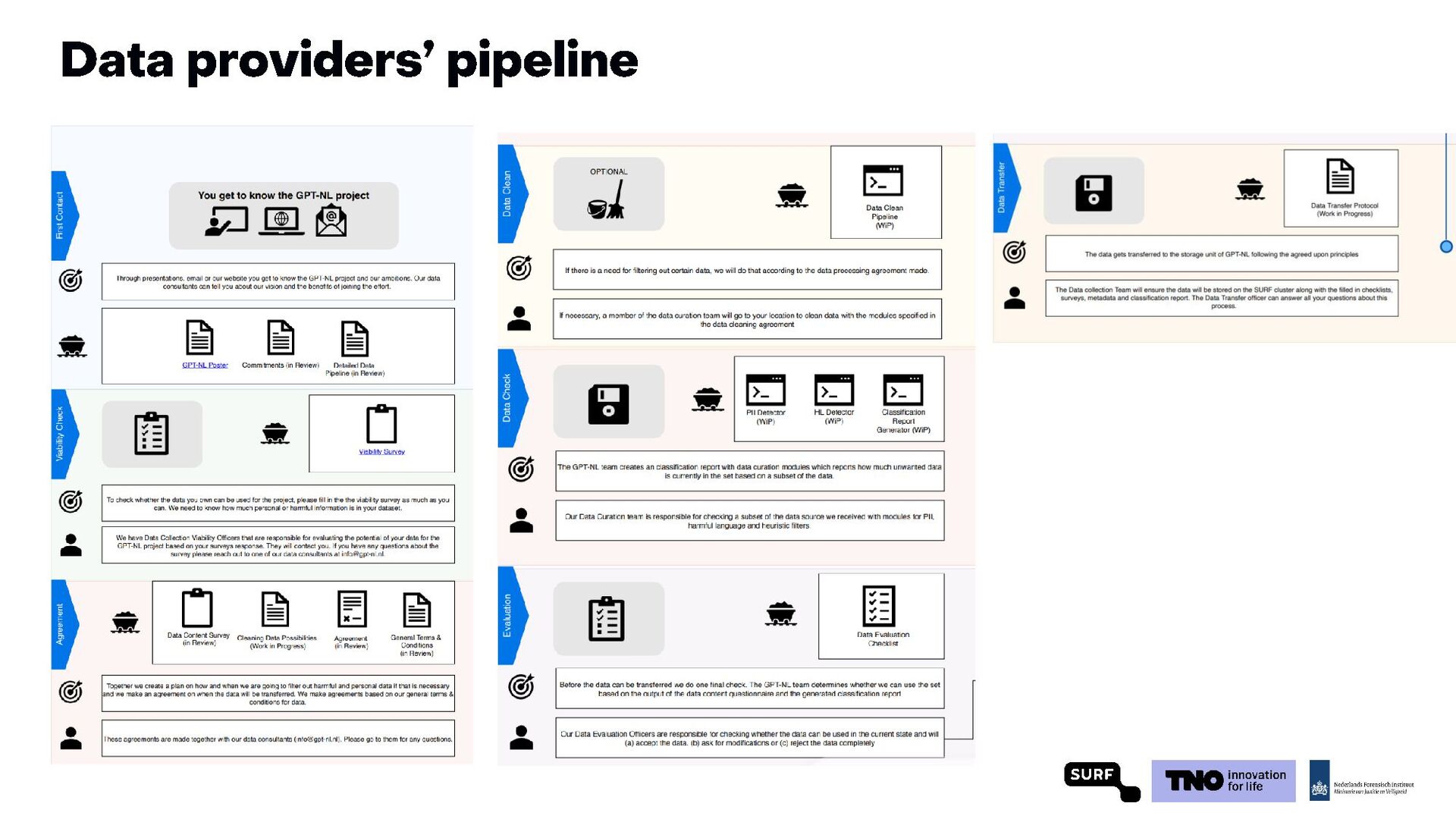
clear rules of engagement and communicate at regular intervals. • Publish a decision workflow document to support dataset building. • Publish a definition of success (both technical and societal benchmarks). • Announce stakeholder consultation opportunities with fixed time windows. • Report on ethical dilemmas and decisions as part of the base reporting process. • Open source code: All code will be published. • Publish dataset- and model-cards according to industry best practices. • Review commitments on a regular basis to incorporate broad feedback. 1
![[email protected]](https://files.speakerdeck.com/presentations/bacd0e73713a4beeb320b8810bf5abad/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}