Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
運用まで考慮したクラウドアーキテクチャ設計できてますか?
Search
mars_eu
April 26, 2021
Technology
3k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
運用まで考慮したクラウドアーキテクチャ設計できてますか?
mars_eu
April 26, 2021
Other Decks in Technology
See All in Technology
CTOキーノート:AI時代の「つなぐ」を再定義 ― 真のIoTとリアルワールドAI【SORACOM Discovery 2026】
soracom
PRO
0
280
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.7k
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
170
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
1.2k
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
790
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
160
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
320
文字起こし基盤の信頼性
abnoumaru
0
150
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
210
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
150
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
550
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
30
17k
Featured
See All Featured
WENDY [Excerpt]
tessaabrams
11
39k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Six Lessons from altMBA
skipperchong
29
4.4k
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Transcript
運用まで考慮したクラウド アーキテクチャ設計できてますか? 21/04/21 Wed. 村瀬 善則 Copyright ©︎ 2021 by
Future Corporation Confidential
自己紹介 • 名前 村瀬 善則 • 前職 独立系SIer • 一言で言うと
アプリもわかるインフラアーキテクト • LIKE リファクタリング、トラブルシューティング、性能改善
目次 • 会社紹介 • システムが増加していっても耐えられる設計をしよう • インシデント発生から早期復旧のために • 踏み台について •
設定一つで自動的に削除しよう • まとめ
会社紹介
特徴
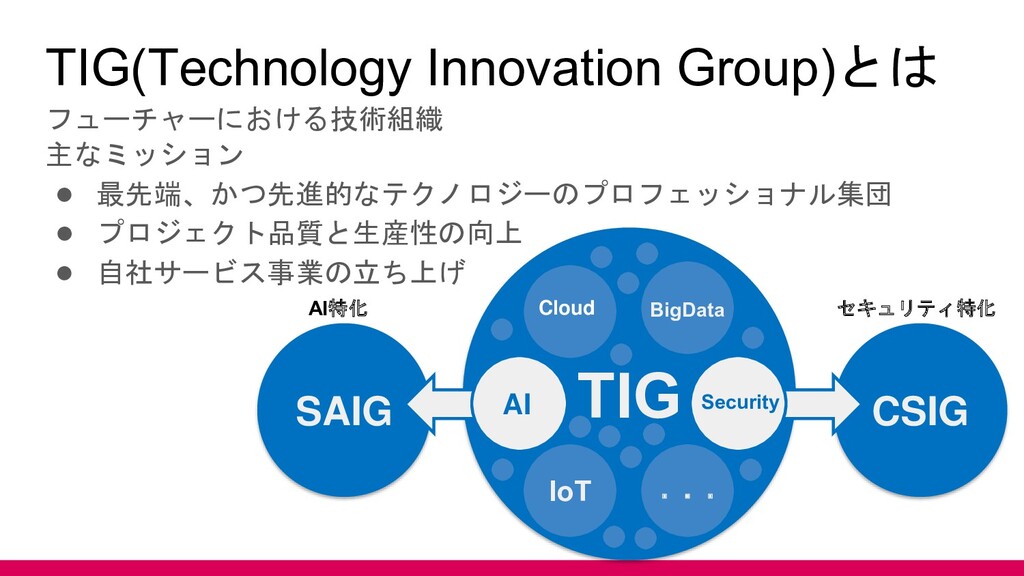
TIG(Technology Innovation Group)とは フューチャーにおける技術組織 主なミッション • 最先端、かつ先進的なテクノロジーのプロフェッショナル集団 • プロジェクト品質と生産性の向上 •
自社サービス事業の立ち上げ TIG CSIG SAIG AI特化 セキュリティ特化 Security IoT ・・・ BigData AI Cloud
宣伝
おことわり これからご紹介する内容は個人の見解を含みます。
システムが増加していっても耐えられる設計をしよう
サービスリリース時は良かったものの… AWS Cloud VPC SystemA
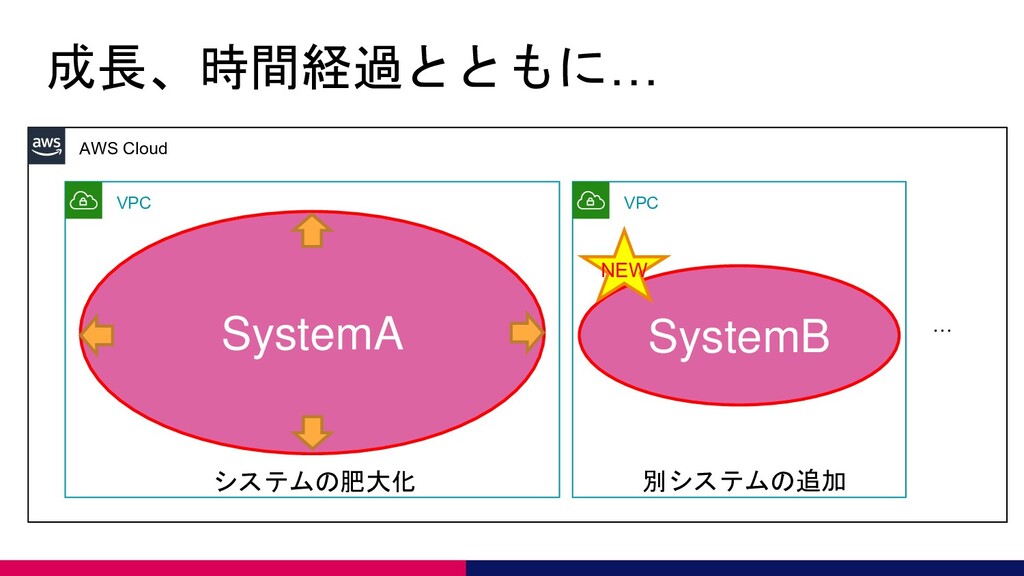
成長、時間経過とともに… AWS Cloud VPC SystemA VPC SystemB … システムの肥大化 別システムの追加
NEW
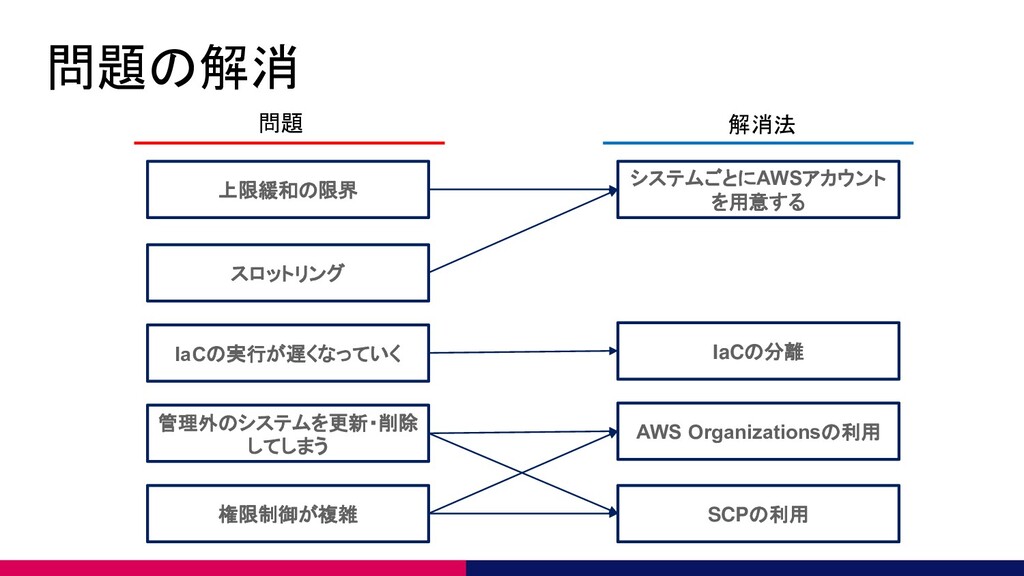
問題が発生する 💀上限緩和の限界 💀スロットリングの頻発 💀IaCの実行が遅くなっていく 💀管理外のシステムを変更してしまう 💀権限制御が複雑
上限緩和の限界 AWSの各サービスの上限は上限緩和申請によって増加させ ることができる。 しかし、無制限に緩和可能なわけではない。 たとえばS3のバケットは1,000個までしか作成できない。
スロットリングの頻発 AWSサービスによってはコンポーネント単位ではなくアカ ウント、リージョン単位でスロットリングの閾値を持ってい るものがある。 あるシステムで発生したスロットリングが別のシステムに影 響することが発生しうる。 以前はパラメータストアは10tps程度であった。 (現在は1000tpsまで拡張可能)
IaCの実行が遅くなっていく インフラをコードで管理できるのでIaCはとても便利◎ システムが肥大化するとプランやデプロイに掛かる時間が長 くなる。最初は数十秒で完了していた処理が気がつけば数十 分になっていることも。
管理外のシステムを変更してしまう 権限制御が適切になされていないと、管理外のシステムを変 更・削除できてしまい、本番環境であればサービス影響が発 生しうる。
権限制御が複雑 先の問題を解消するため、IAMによる権限制御を実施しよう とした場合、割に合わない作業が発生する。
これらの問題を解消します!
解消方法 • AWS Organizations • SCP(Service Control Policy) • Switch
Role • IaCの分離
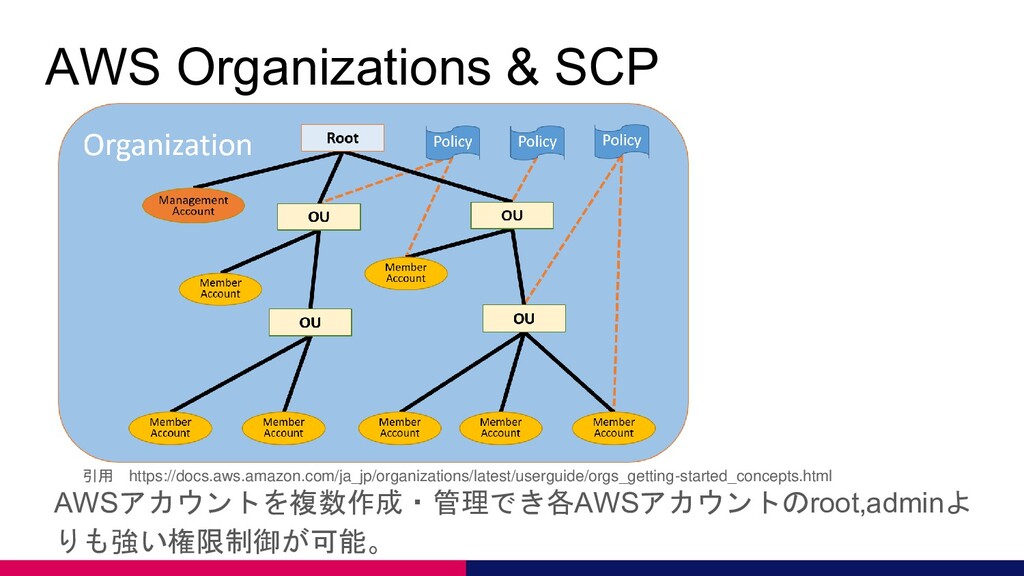
AWS Organizations & SCP AWSアカウントを複数作成・管理でき各AWSアカウントのroot,adminよ りも強い権限制御が可能。 引用 https://docs.aws.amazon.com/ja_jp/organizations/latest/userguide/orgs_getting-started_concepts.html
AWS Organizations & SCP おすすめの設定 • 本番用のOUを作成し、初期構築後のクリティカルな変更を禁止する。 ◦ KMSの削除禁止 ◦
CloudTrailの変更禁止 ◦ S3バケットの削除禁止 ◦ RDSの削除禁止 • サンドボックス用のOUを作成し、利用させたくないAWSサービス、高額なインスタン スタイプを禁止する。
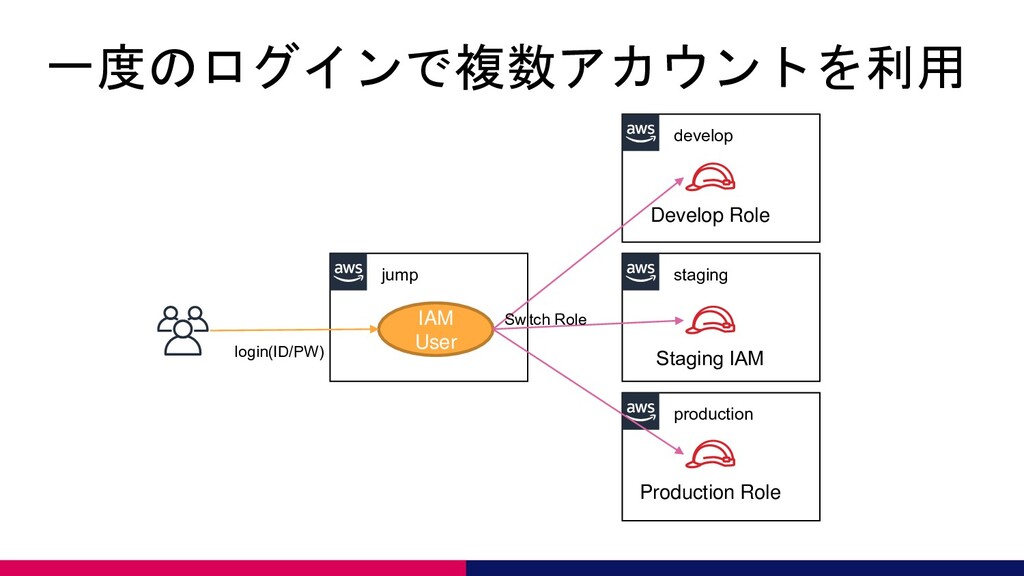
一度のログインで複数アカウントを利用 jump develop staging production Develop Role Staging IAM Production
Role IAM User login(ID/PW) Switch Role
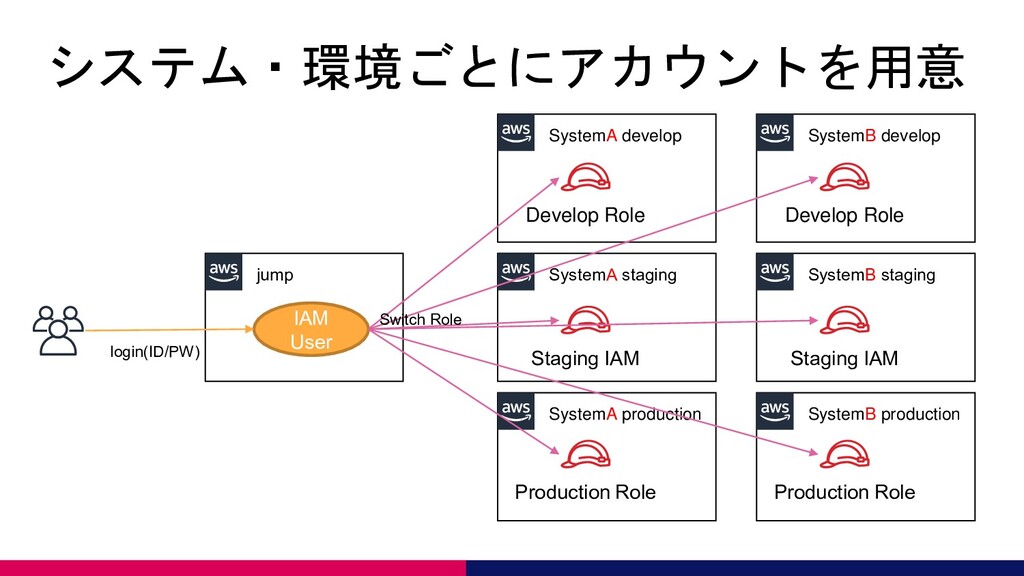
システム・環境ごとにアカウントを用意 jump SystemA develop SystemA staging SystemA production Develop Role
Staging IAM Production Role IAM User login(ID/PW) SystemB develop SystemB staging SystemB production Develop Role Staging IAM Production Role Switch Role
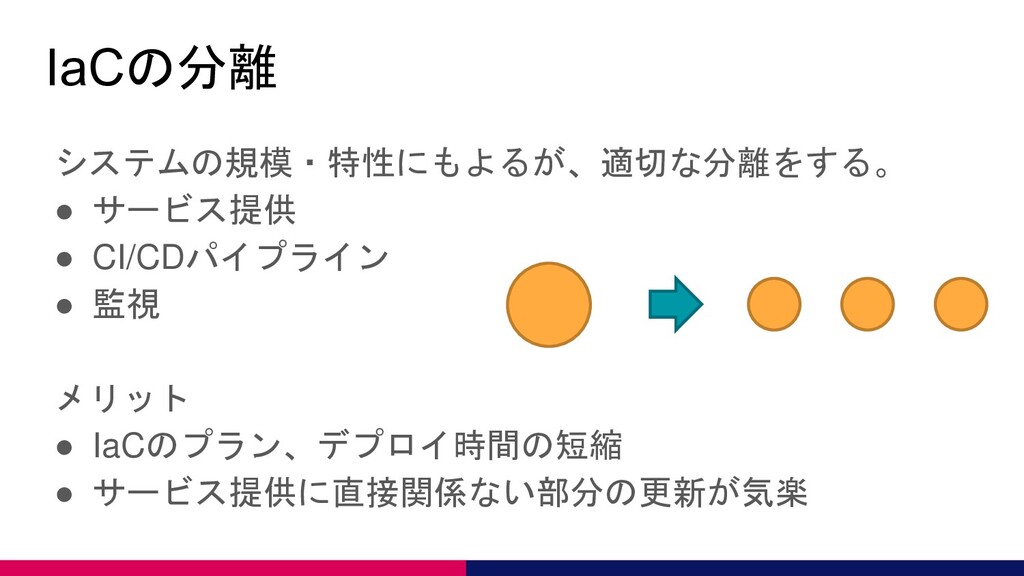
IaCの分離 システムの規模・特性にもよるが、適切な分離をする。 • サービス提供 • CI/CDパイプライン • 監視 メリット •
IaCのプラン、デプロイ時間の短縮 • サービス提供に直接関係ない部分の更新が気楽
問題の解消 上限緩和の限界 スロットリング IaCの実行が遅くなっていく 管理外のシステムを更新・削除 してしまう 権限制御が複雑 システムごとにAWSアカウント を用意する IaCの分離
AWS Organizationsの利用 SCPの利用 問題 解消法
インシデント発生から早期復旧のために
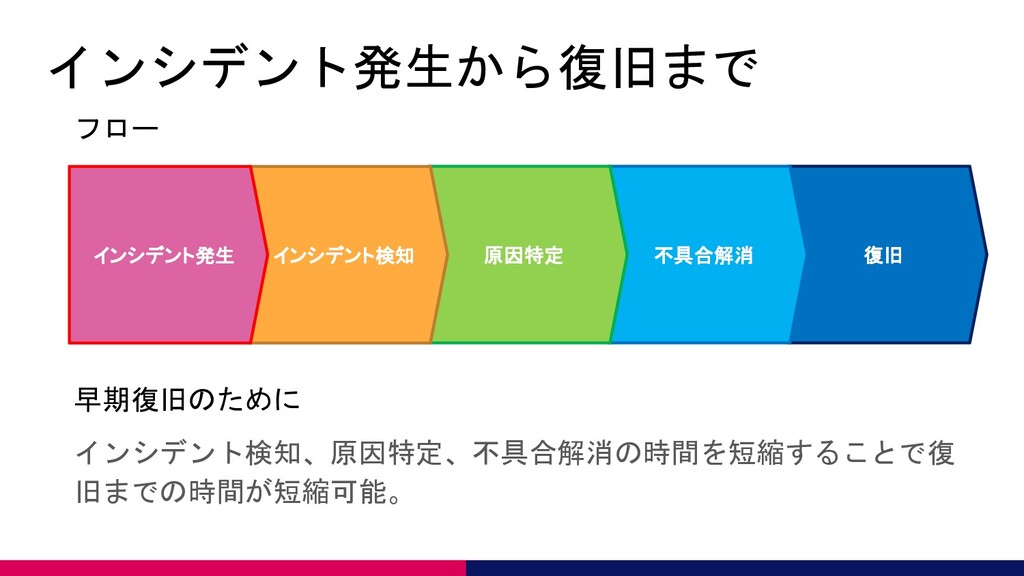
インシデント発生から復旧まで インシデント検知、原因特定、不具合解消の時間を短縮することで復 旧までの時間が短縮可能。 復旧 不具合解消 原因特定 インシデント検知 インシデント発生 フロー 早期復旧のために
インシデント検知の勘所 検知の目的 問題に気付き、対応をする 監視項目 • 異常監視 発生した異常を通知する。 • 予兆監視 このまま放置すると障害が発生することを通知する。
ありがちな失敗 何でもかんでも通知し、重要な通知を見逃す。
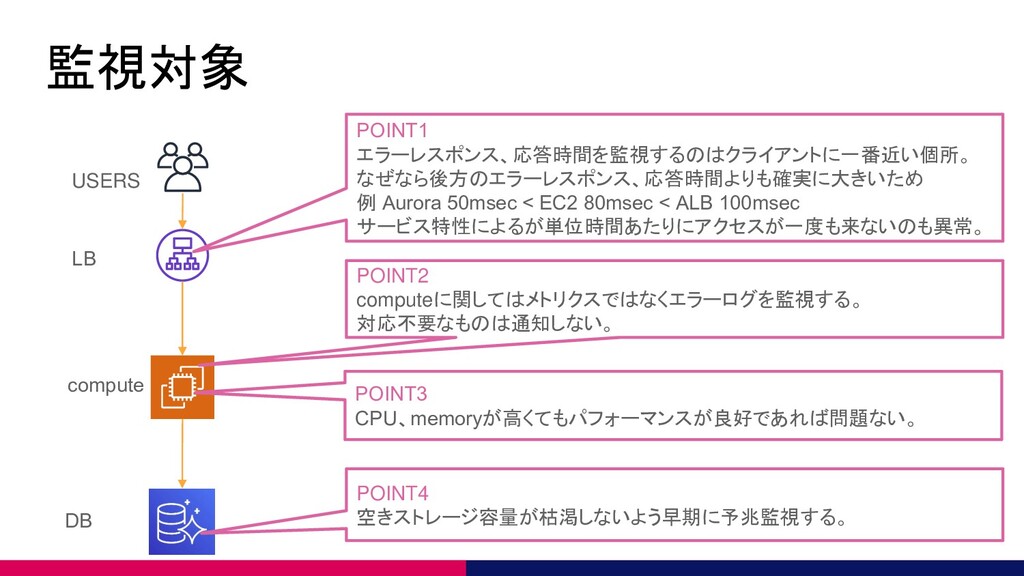
監視対象 LB DB compute USERS POINT1 エラーレスポンス、応答時間を監視するのはクライアントに一番近い個所。 なぜなら後方のエラーレスポンス、応答時間よりも確実に大きいため 例 Aurora
50msec < EC2 80msec < ALB 100msec サービス特性によるが単位時間あたりにアクセスが一度も来ないのも異常。 POINT4 空きストレージ容量が枯渇しないよう早期に予兆監視する。 POINT2 computeに関してはメトリクスではなくエラーログを監視する。 対応不要なものは通知しない。 POINT3 CPU、memoryが高くてもパフォーマンスが良好であれば問題ない。
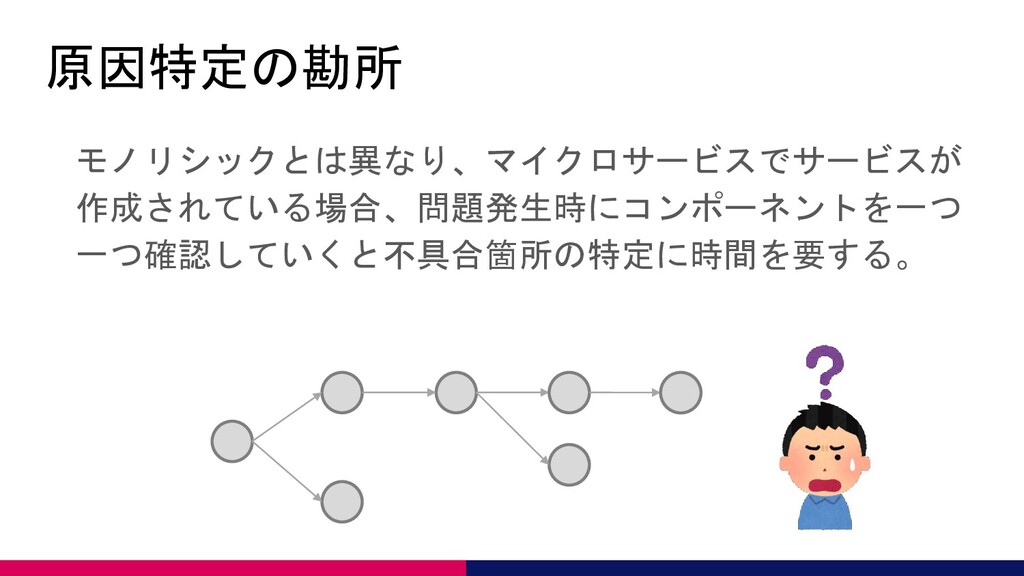
原因特定の勘所 モノリシックとは異なり、マイクロサービスでサービスが 作成されている場合、問題発生時にコンポーネントを一つ 一つ確認していくと不具合箇所の特定に時間を要する。
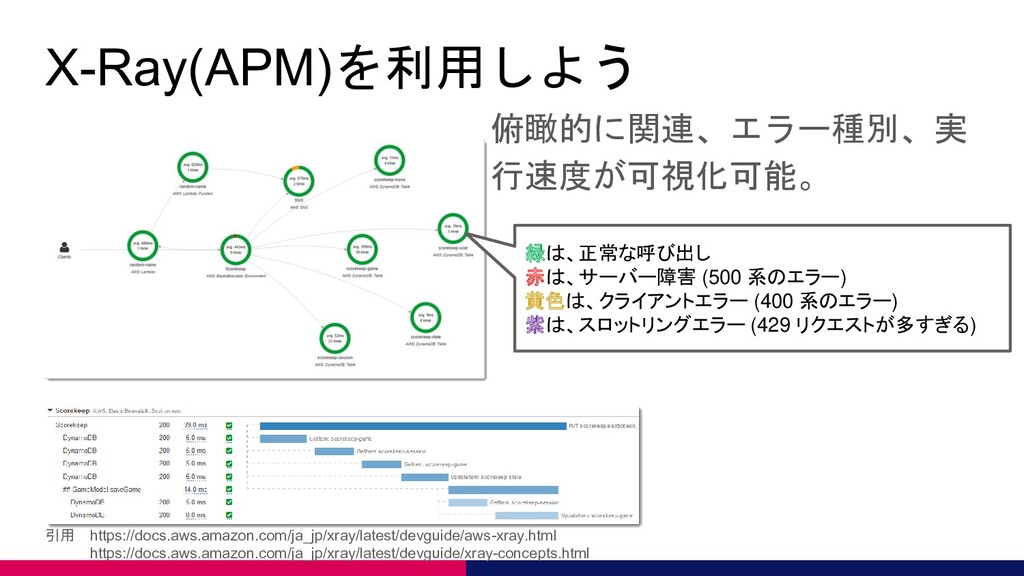
X-Ray(APM)を利用しよう 俯瞰的に関連、エラー種別、実 行速度が可視化可能。 引用 https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/aws-xray.html https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/xray-concepts.html 緑は、正常な呼び出し 赤は、サーバー障害 (500 系のエラー)
黄色は、クライアントエラー (400 系のエラー) 紫は、スロットリングエラー (429 リクエストが多すぎる)
アプリのエラーログを出力しよう 問題のアプリがわかったとして、どの機能で問題が発生し ているかはエラーログを見るべき。適切なログが出力され てないと切り分けは難しい。エラー発生時には必要な情報 と共にログを出力するよう設計段階からもれなく実施す る。
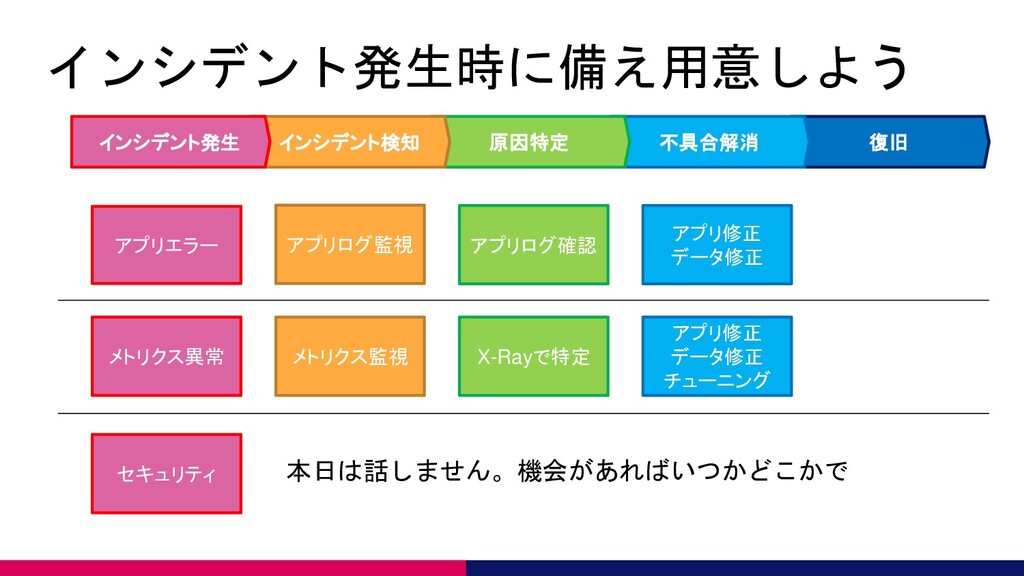
インシデント発生時に備え用意しよう 復旧 不具合解消 原因特定 インシデント検知 インシデント発生 アプリエラー メトリクス異常 アプリログ監視 メトリクス監視
アプリログ確認 X-Rayで特定 アプリ修正 データ修正 アプリ修正 データ修正 チューニング セキュリティ 本日は話しません。機会があればいつかどこかで
踏み台について
よくある問題 • 長い間セキュリティパッチがあたっていない。 もしかしてマルウェアが混入しているかも? • 不要なデータが放置される。 ストレージ容量が不足していて大きなデータを扱えない。
踏み台を使い捨てにしよう 業務特性にもよるが常時踏み台を用意する必要はない。 必要な際に設定済みのイメージから踏み台を生成し、不要 になったタイミングで破棄する。 メリット • セキュリティの向上 • セキュリティパッチのメンテナンスが不要 •
コスト低減 デメリット • Historyが毎回削除される。
内部犯行の抑止 DBへアクセスできるため便利な一方で、情報持ち出しなど 内部犯行に利用されうる。 内部犯行させないため、以下の対応が有効。 監査ログの保全 • CloudWatchLogsやS3にログを出力し削除させない。 ログインしたことがバレるようにする。 • slackなど皆が容易に確認可能なツールに投稿する。
設定一つで自動的に削除しよう
背景と目的 データやログに関して一定期間は保持しなければならない が、期間を過ぎた場合には不要になる。 ストレージコストの低減や検索速度の向上を図りたい。
実現方法 AWSではサービスの機能として用意されている。 • S3 ライフサイクルポリシーの設定 • DynamoDB TTLの設定 • CloudWatchLogs
保持期限の設定 便利な機能は積極利用。無駄なことはやめよう。
まとめ
まとめ 運用まで考慮した設計について説明しました。 • システムが増加していっても耐えられるようAWS Organizations、SCPを利用しましょう。 • インシデントの早期復旧のため適切な監視、X-Rayの利 用、アプリログを出力しましょう。 • 踏み台は内部犯行を抑止しましょう。使い捨てにするの
もいいかも。 • 削除に関して便利な機能を利用しましょう。
Thank you for listening.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}