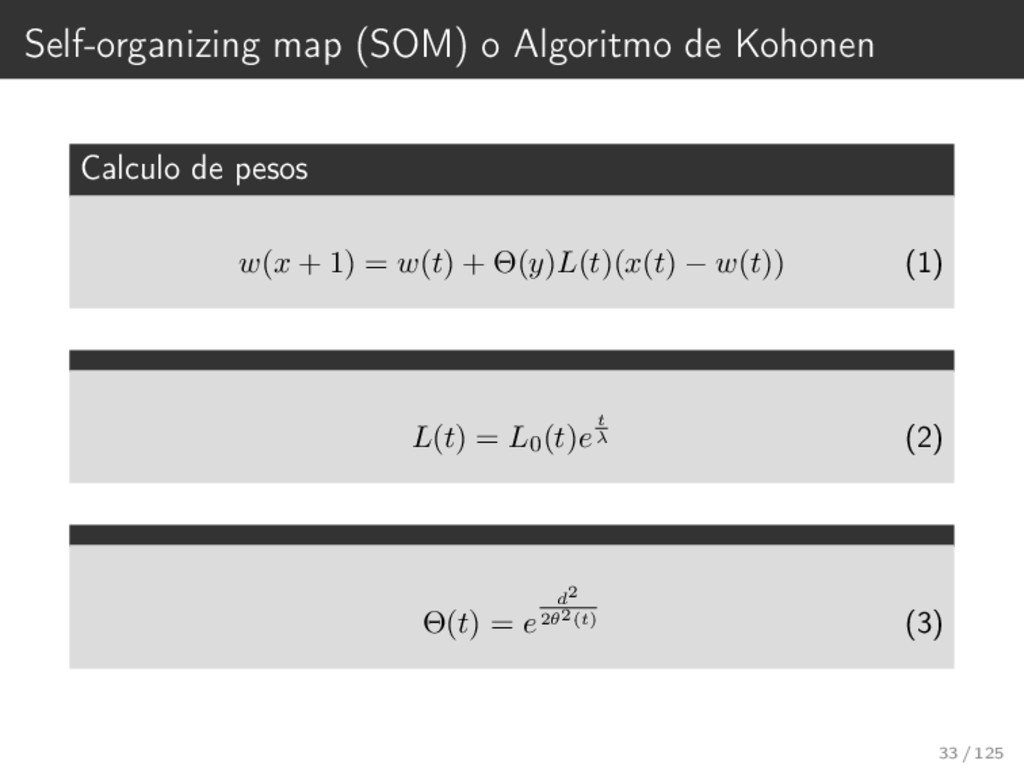
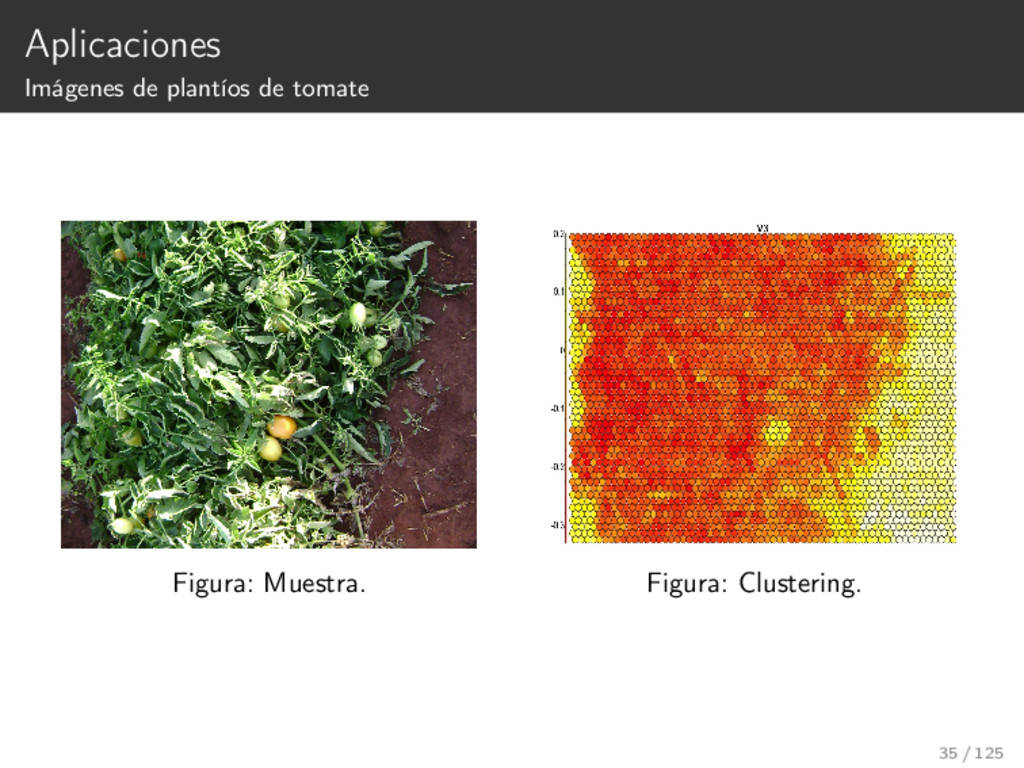
header=FALSE); 2 View(iris) 3 4 coolBlueHotRed <- function(n, alpha = 1) { 5 rainbow(n, end=4/6, alpha=alpha)[n:1] 6 } 7 8 ##data <- read.table("~/Documents/Talleres/Machine Learning - Fisica/Dataset/iris.csv", quote="\"", strin 9 10 data.train <- as.matrix(iris) 11 sM <- som(data.train, grid = somgrid(10, 5, "hexagonal"), rlen=1, alpha=c(0.05, 0.01), keep.data=FALSE) 12 13 14 plot(sM, type = "property", property = sM$codes[,1], 15 main = colnames(sM$codes)[1]) 16 plot(sM, type = "property", property = sM$codes[,2], 17 main = colnames(sM$codes)[2]) 18 plot(sM, type = "property", property = sM$codes[,3], 19 main = colnames(sM$codes)[3]) 20 plot(sM, type = "property", property = sM$codes[,4], 21 main = colnames(sM$codes)[4]) 36 / 125
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
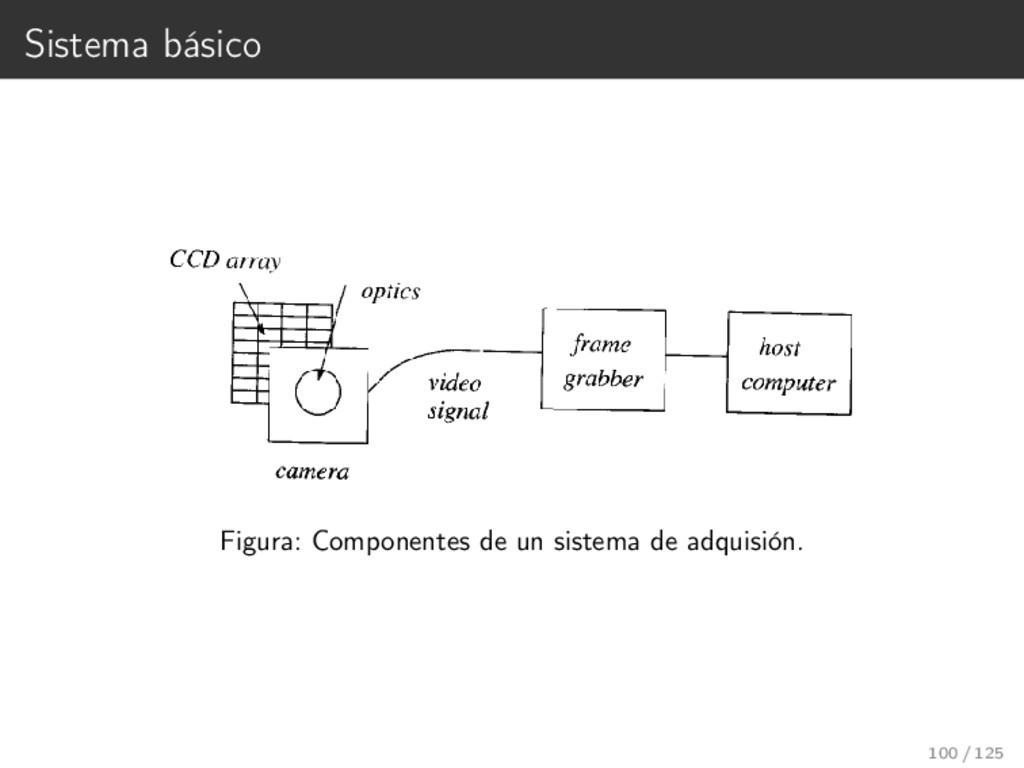{kind=link}
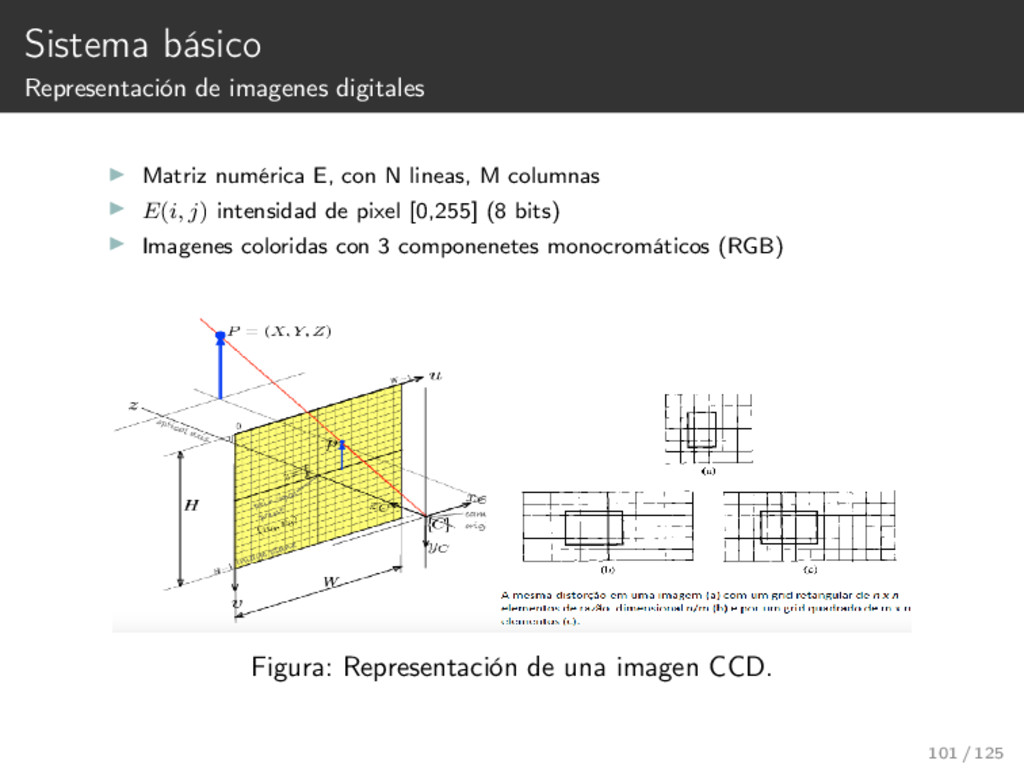{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
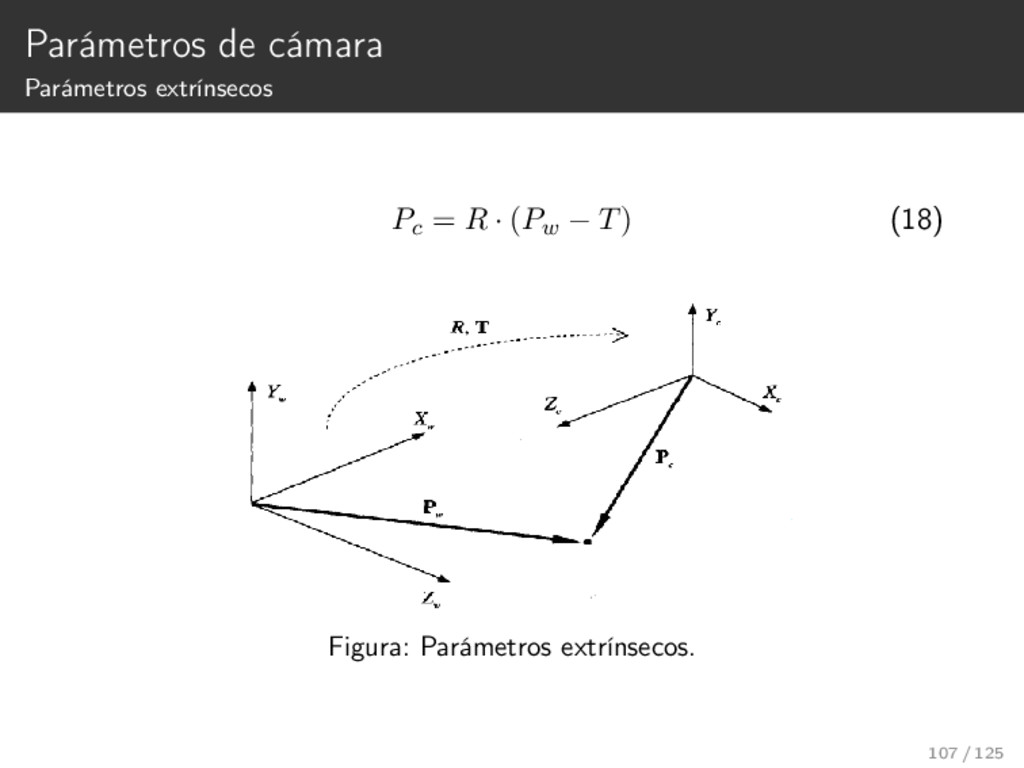{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
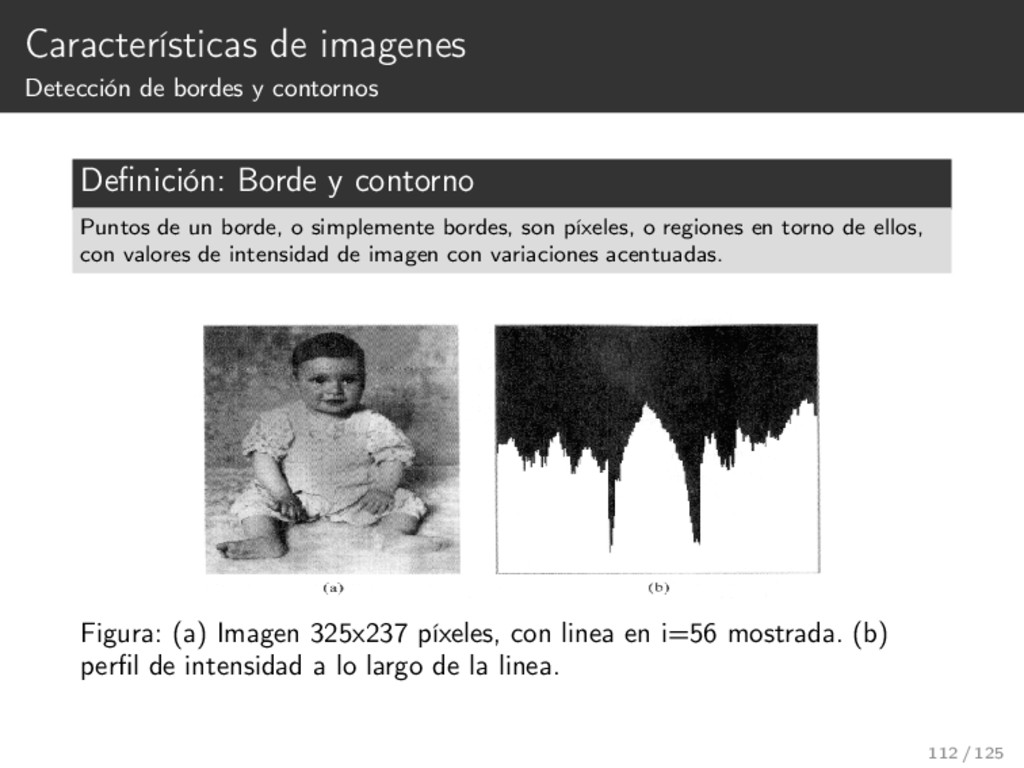{kind=link}
{kind=link}
{kind=link}
{kind=link}
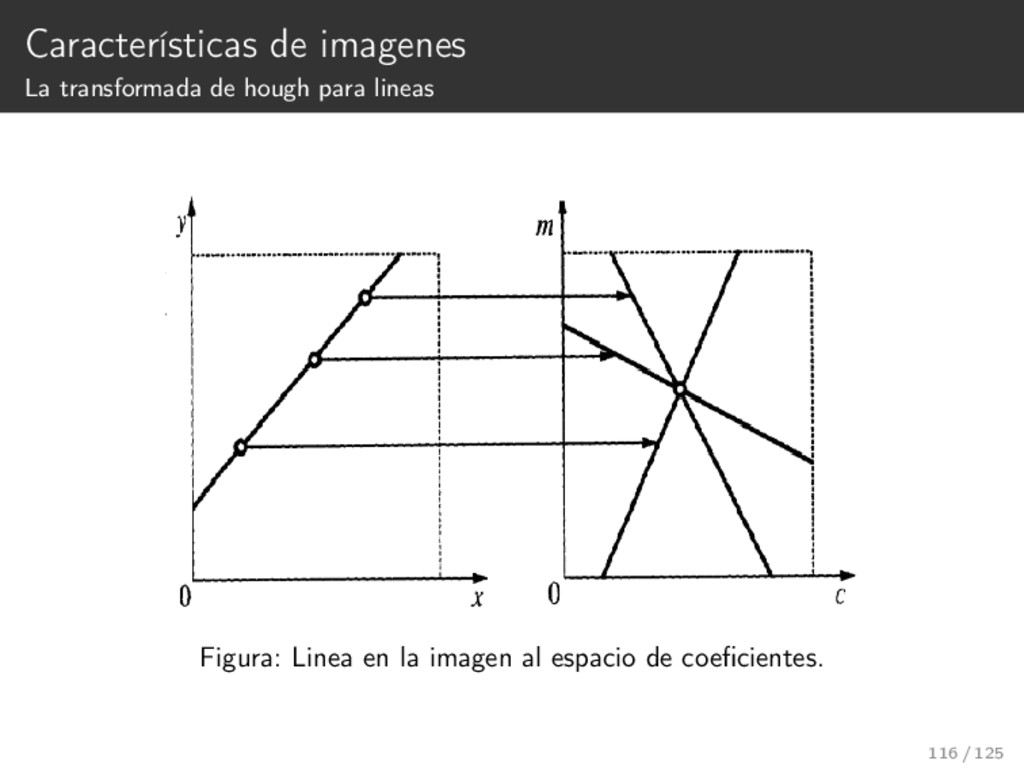{kind=link}
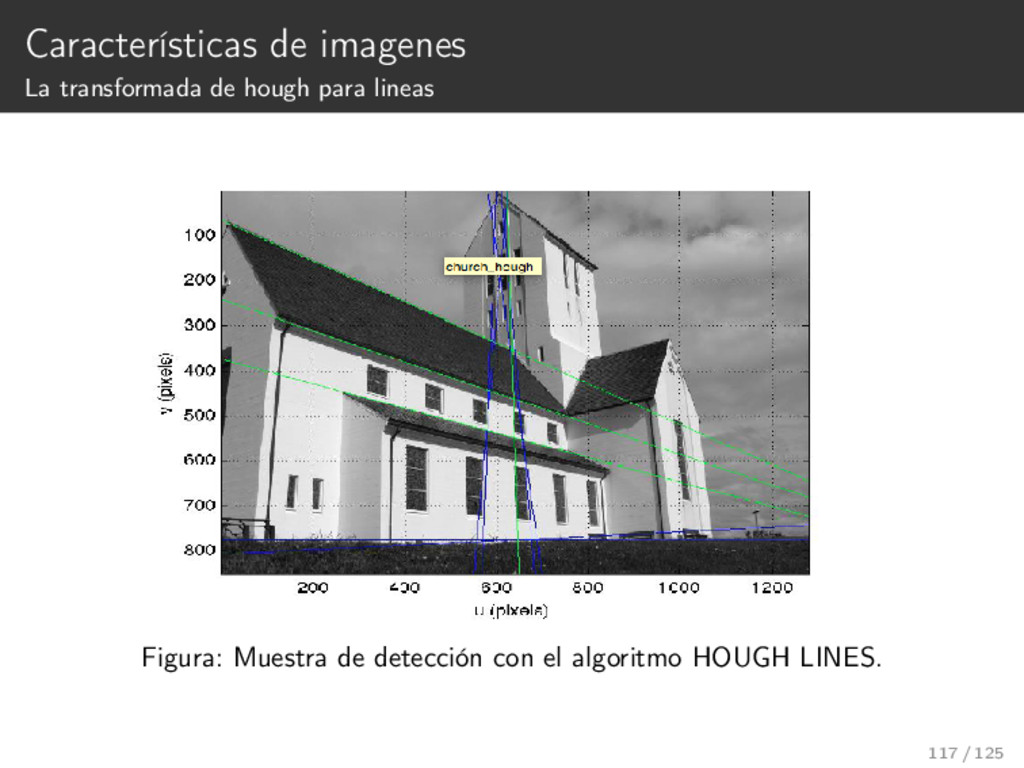{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}