Although it took us several tries and a few years, we finally figured out how to manage schema evolution really well, providing:
Simple API for developers
Code review
Simple setup for each database
Deploy via tarballs
Integration into development and test environments (including subsets of safe data!)
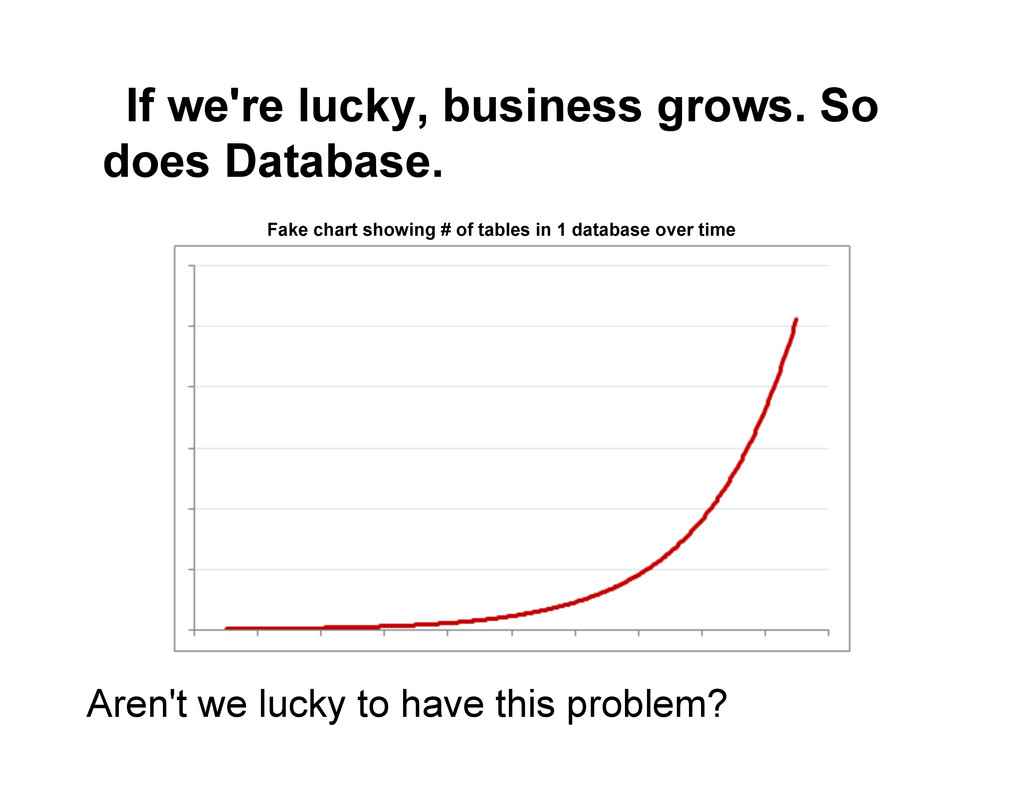
This talk will cover how we actually manage schema for over a dozen unique postgreSQL databases in production at Gilt Groupe ranging from databases containing one table and several KB of data to the largest containing ~1000 tables and nearing a TB of data. We'll highlight what we've learned from previous attempts and some general thoughts on where we are headed from here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
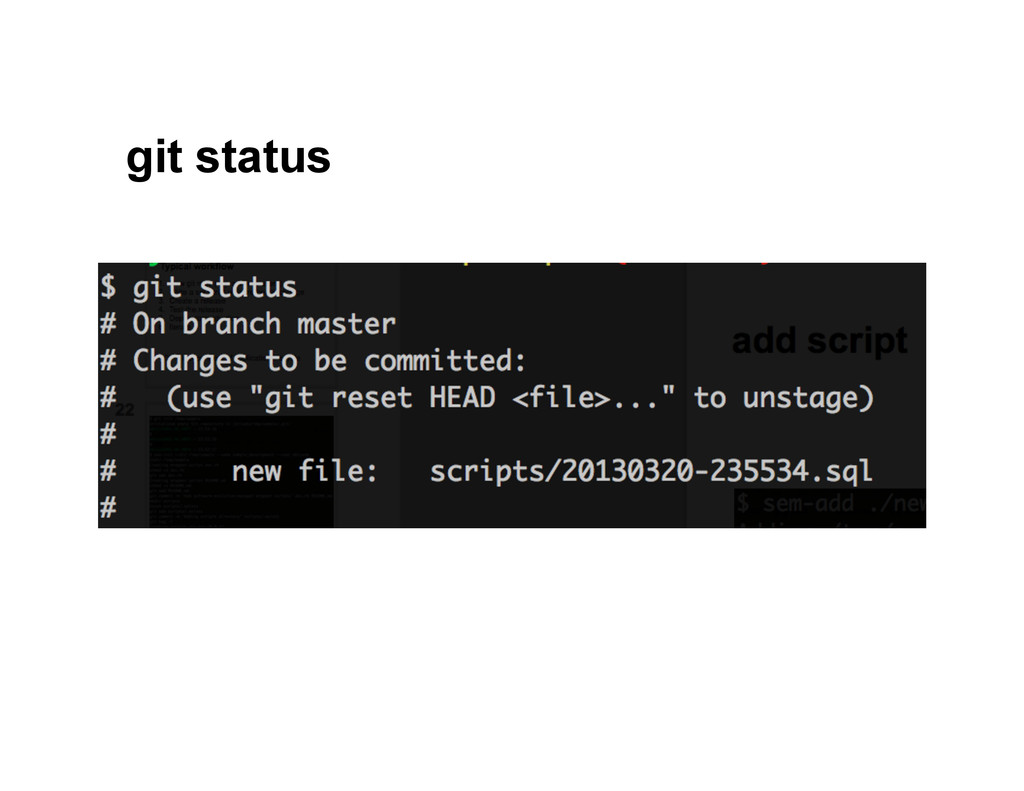{kind=link}
![Apply to local db [snip]](https://files.speakerdeck.com/presentations/a83d2c6077e501302c3422000a95002f/slide_26.jpg){kind=link}
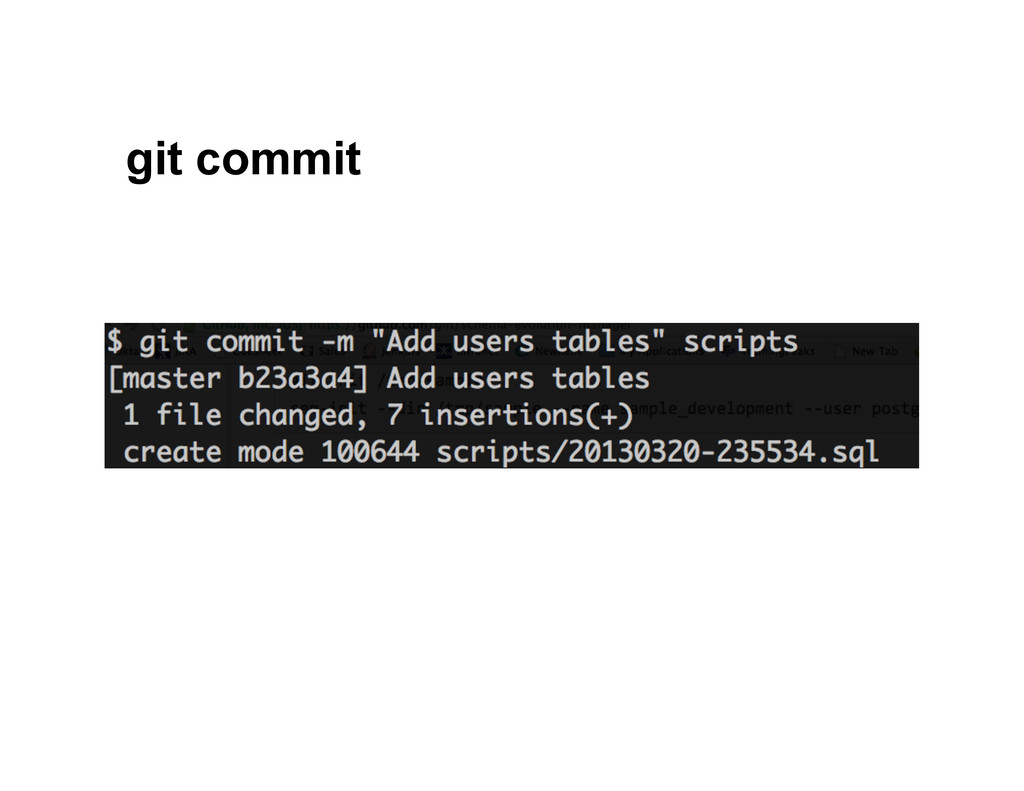{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
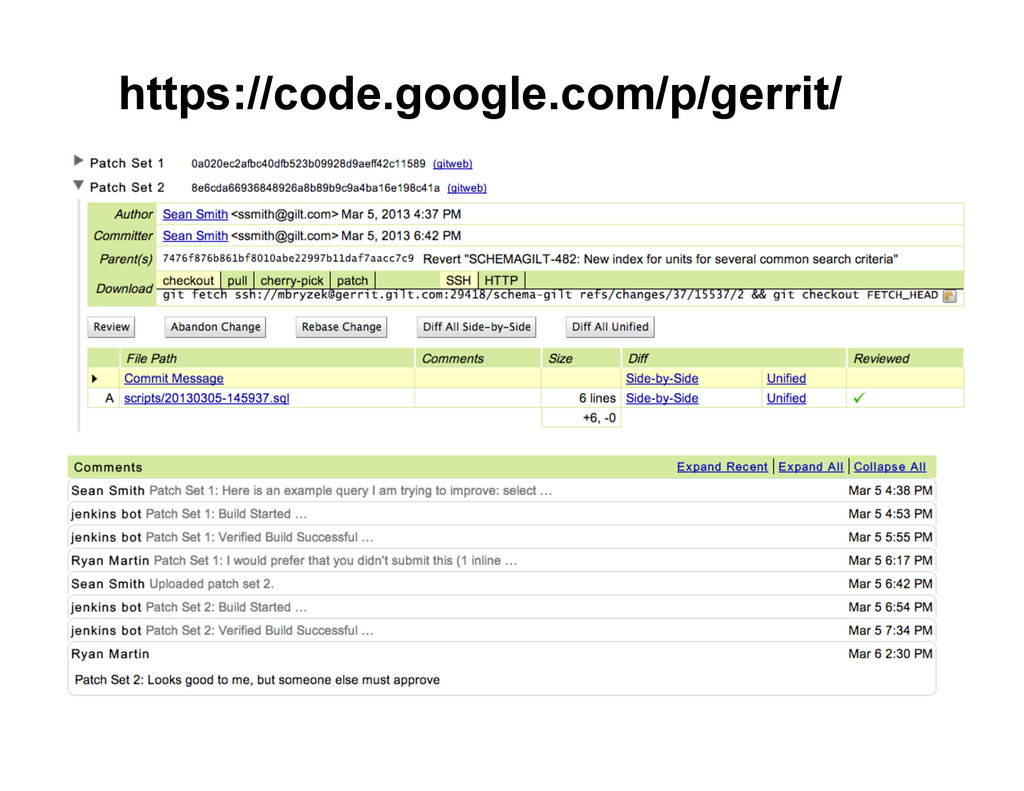{kind=link}
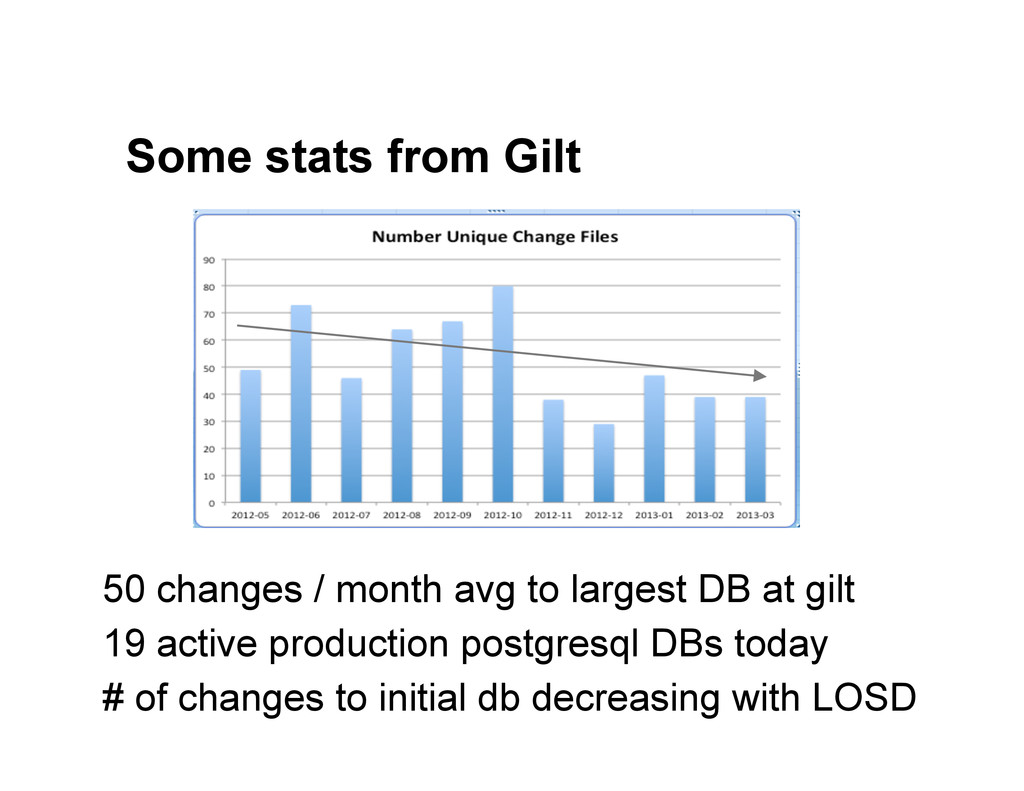{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}