Elasticsearch 因为其实时性、可扩展性和易用性正变得非常流行,而 Spark 强大的数据分析和处理能力大家也是有目共睹,是不是能够将两者的优点结合起来,让大数据发挥出更大价值,让Spark搜索更快,处理数据更快更实时,本次分享 Medcl 将为大家介绍Elastic的另一开源产品 Elasticsearch for Apache Hadoop (ES-Hadoop) , 除了介绍里面各种有趣的特性和原理细节,再介绍如何结合ElasticStack的可视化套件来对大数据做快速的实时分析和展现。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
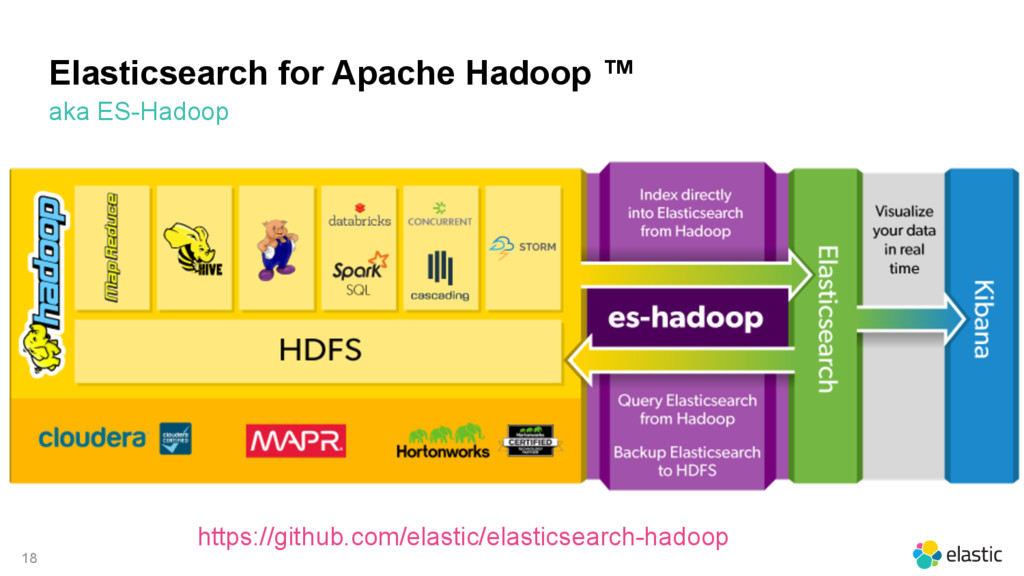{kind=link}
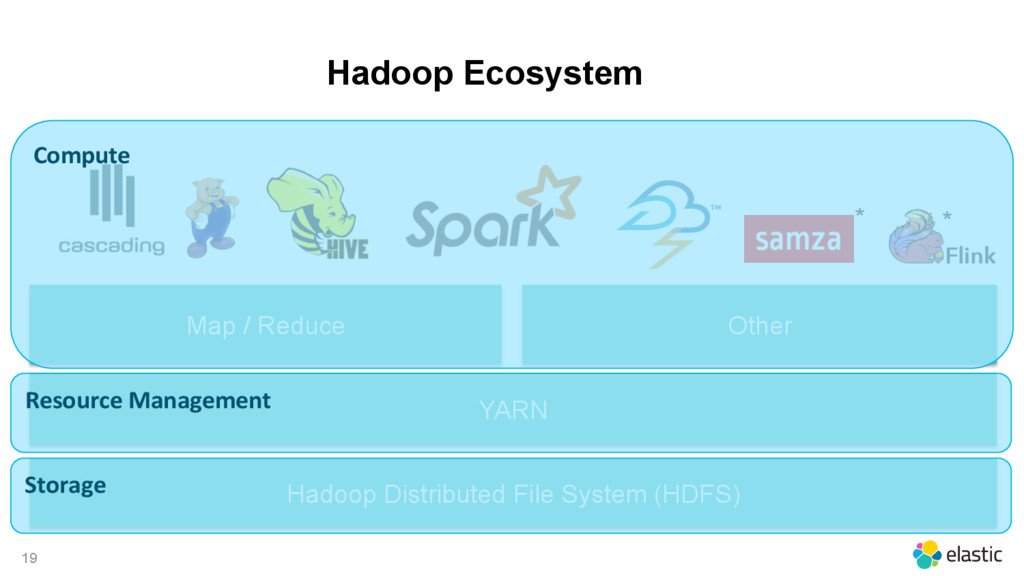{kind=link}
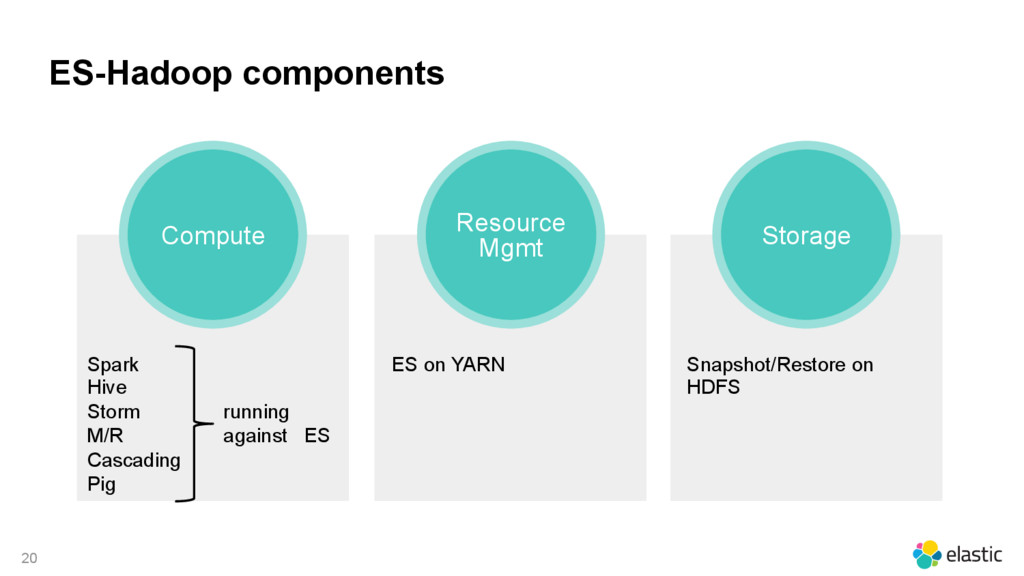{kind=link}
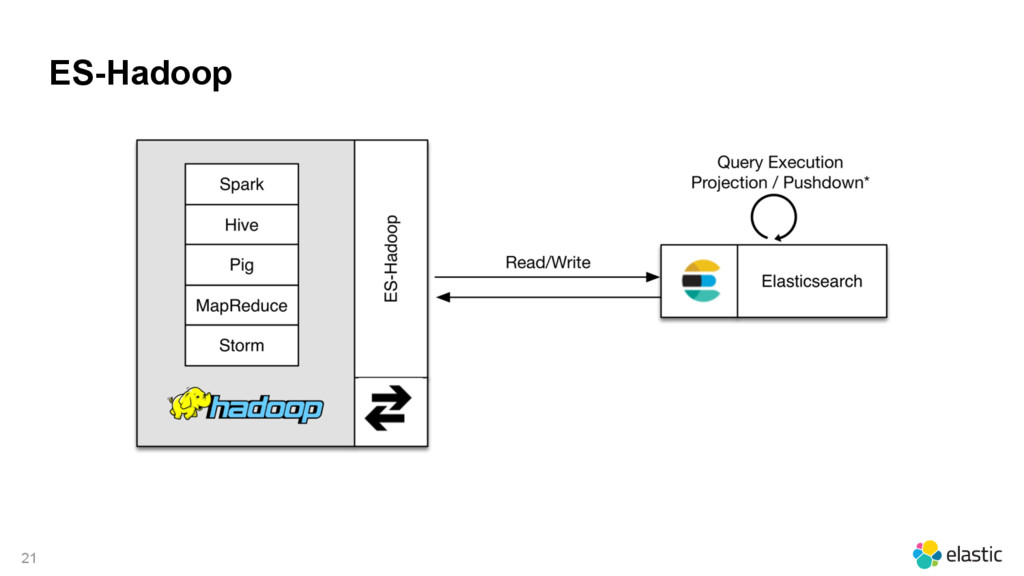{kind=link}
{kind=link}
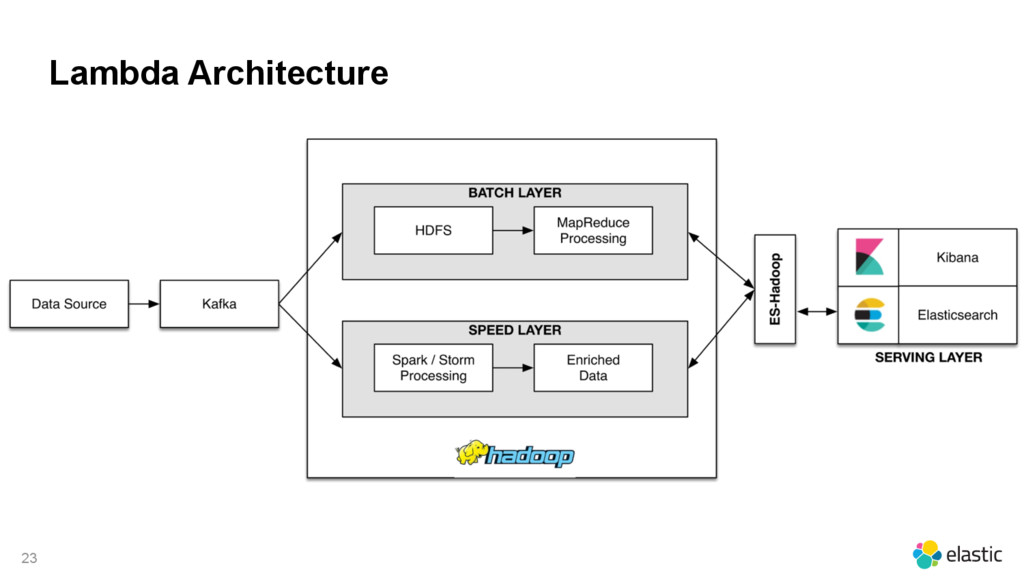{kind=link}
{kind=link}
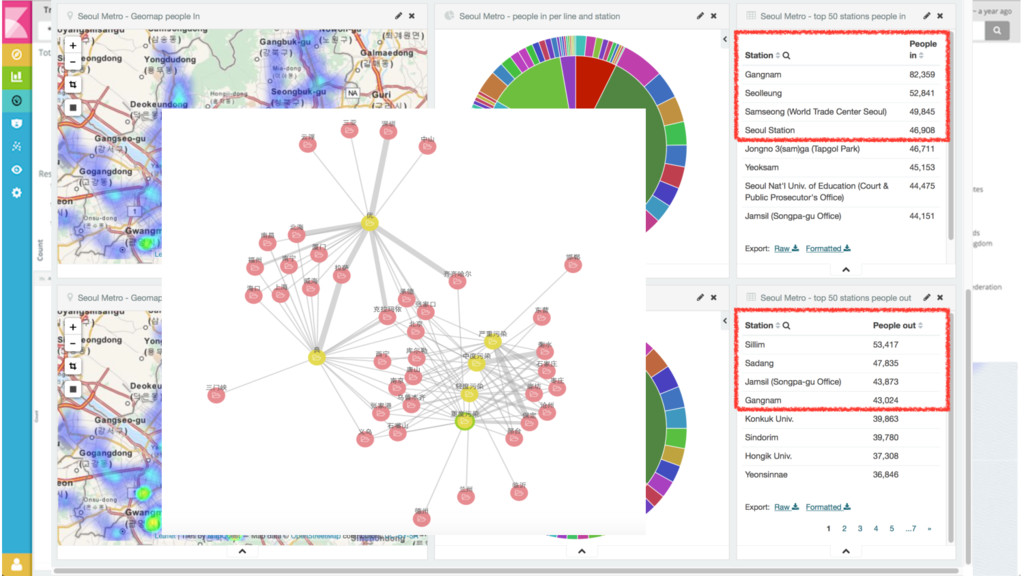{kind=link}
{kind=link}
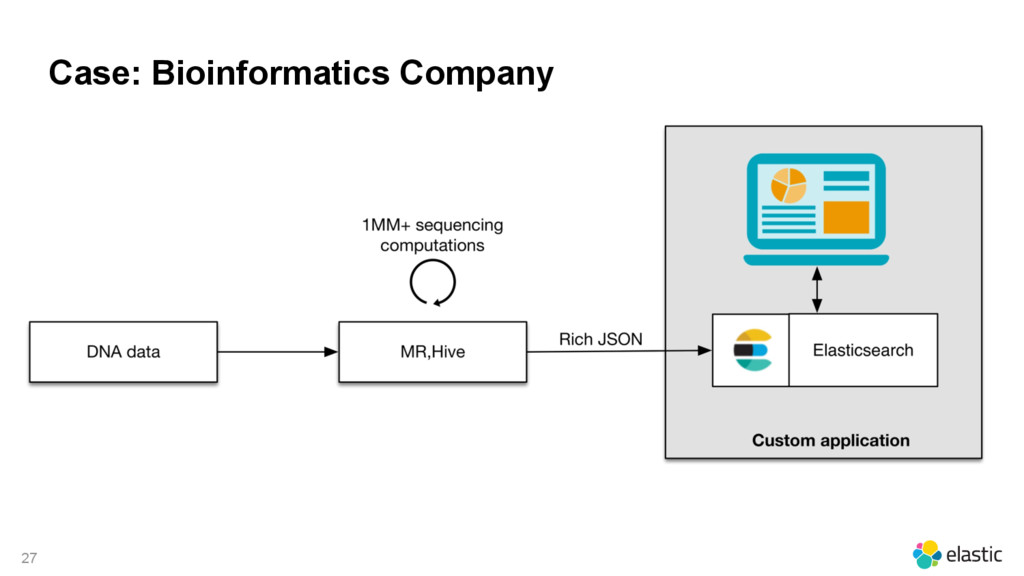{kind=link}
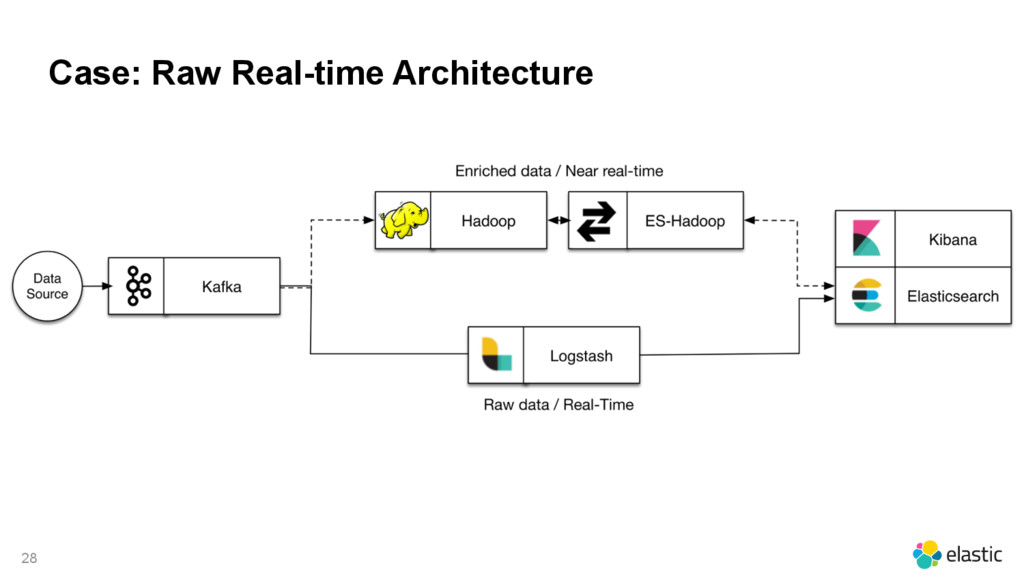{kind=link}
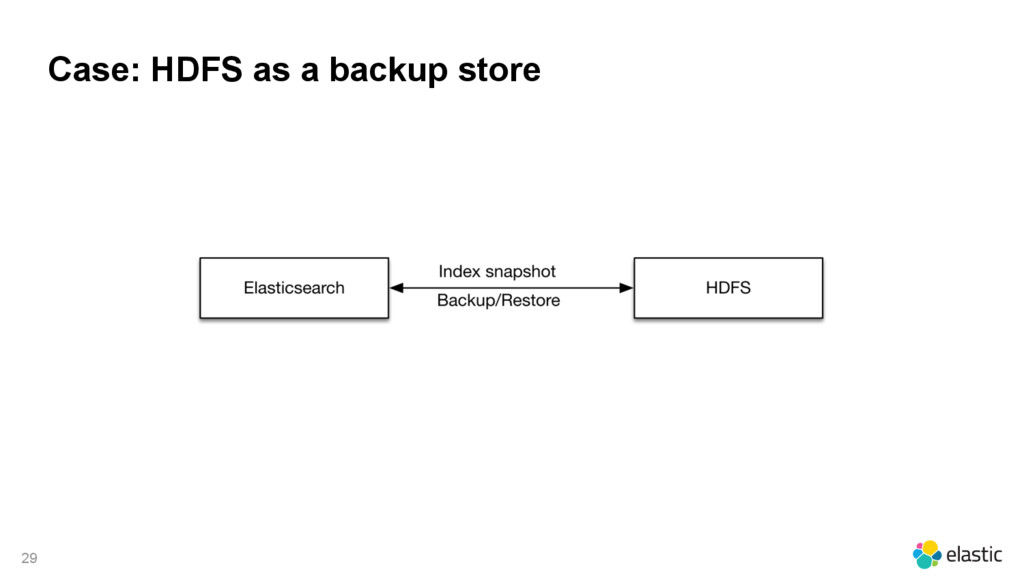{kind=link}
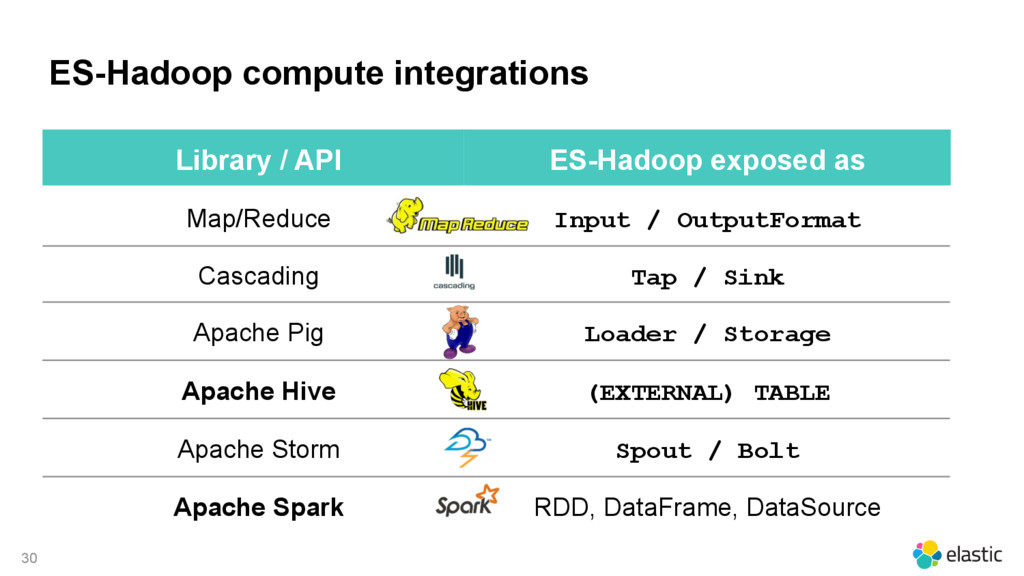{kind=link}
{kind=link}
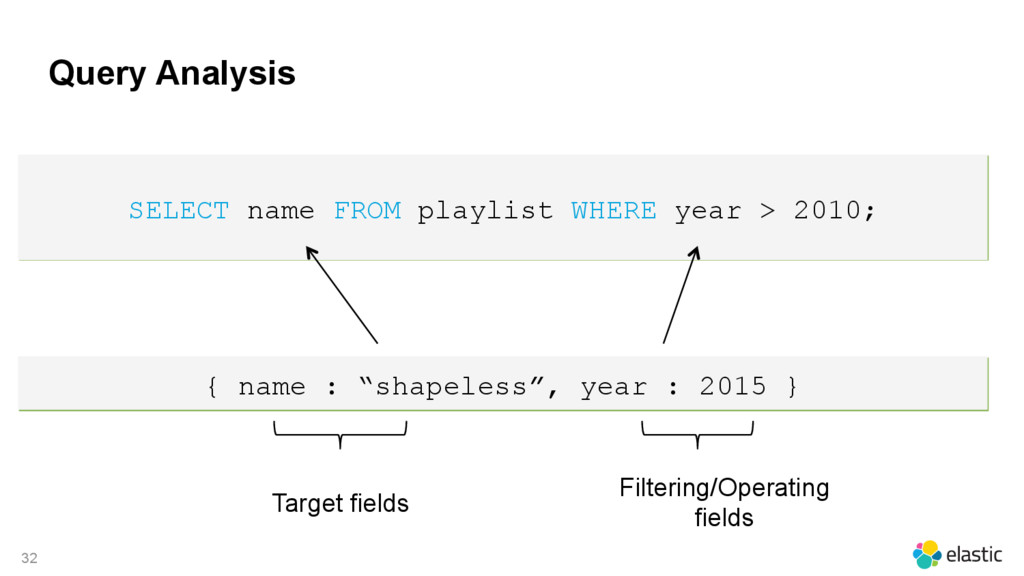{kind=link}
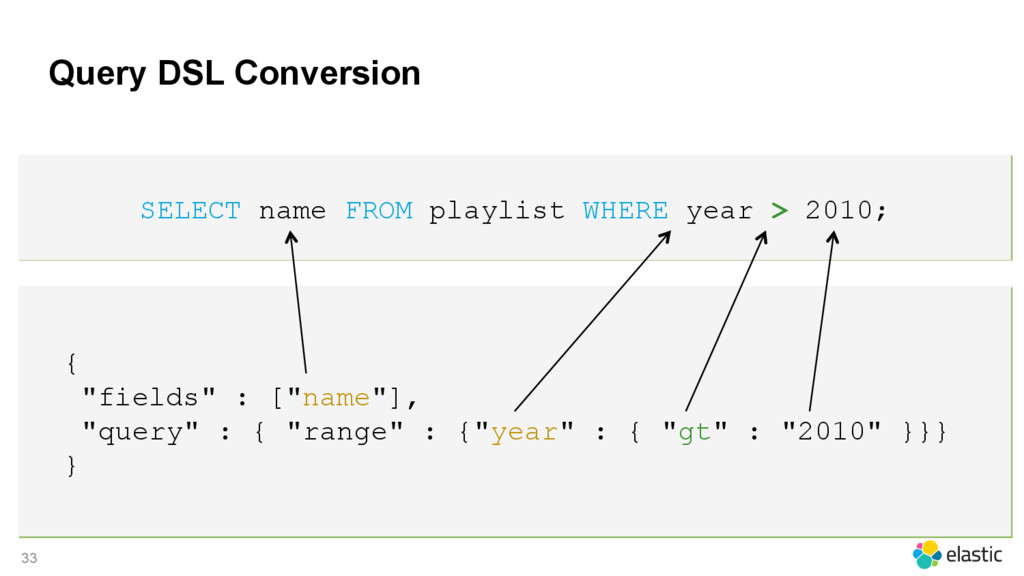{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![39 Apache Spark – JSON RDDs jsonRDD : RDD[(String, String)]](https://files.speakerdeck.com/presentations/b8c0855c80f14264802f5377cd8c7df0/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
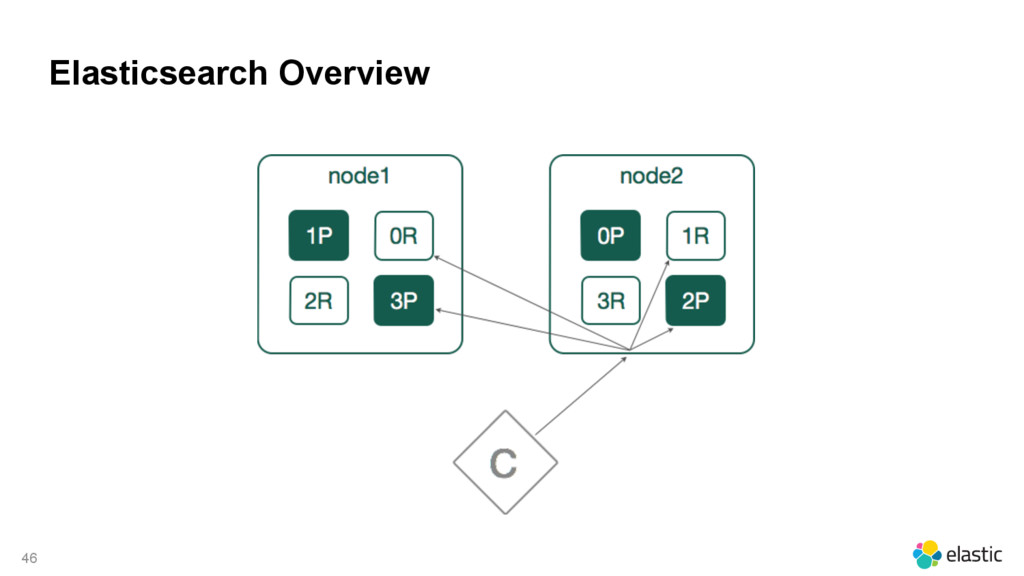{kind=link}
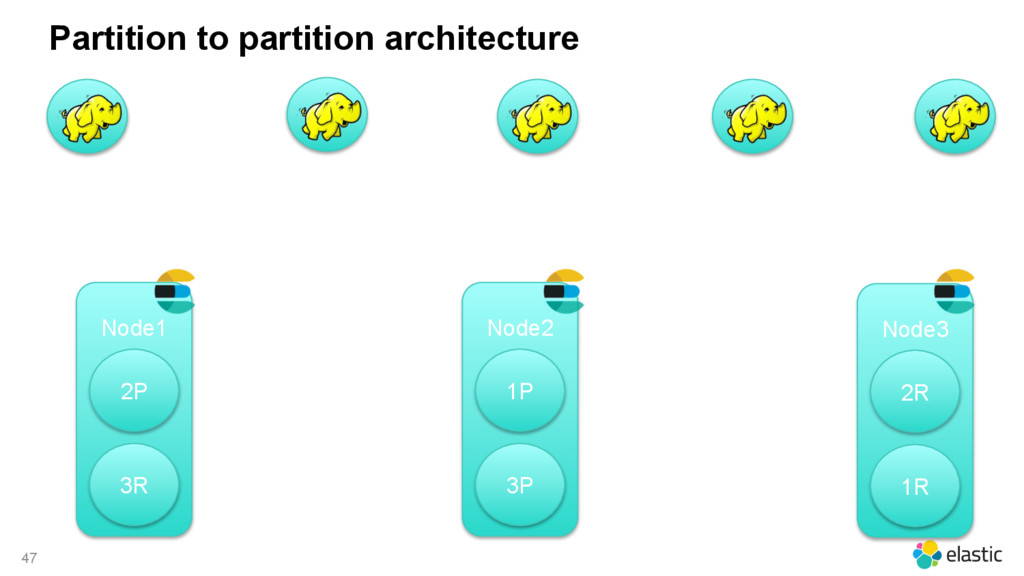{kind=link}
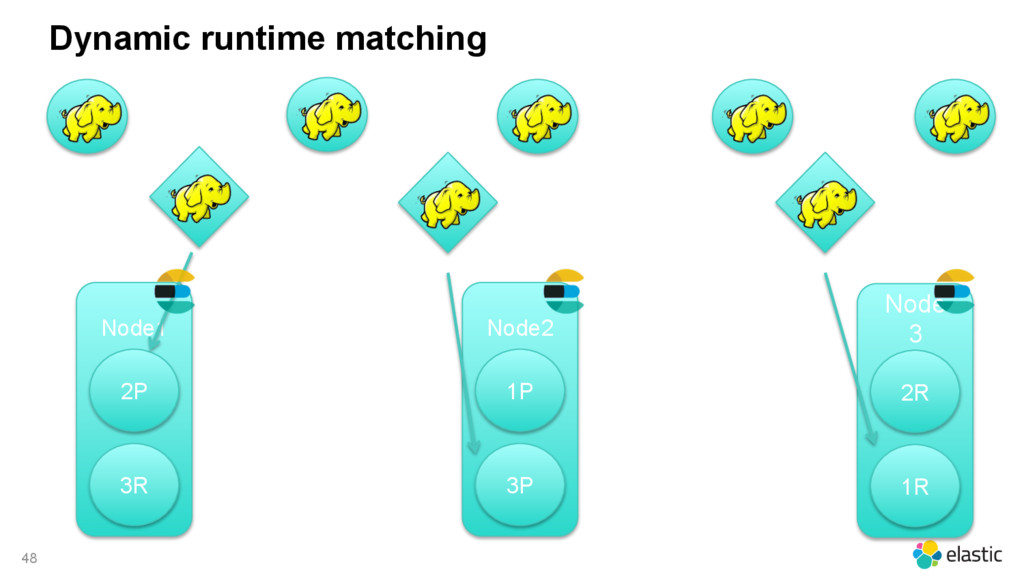{kind=link}
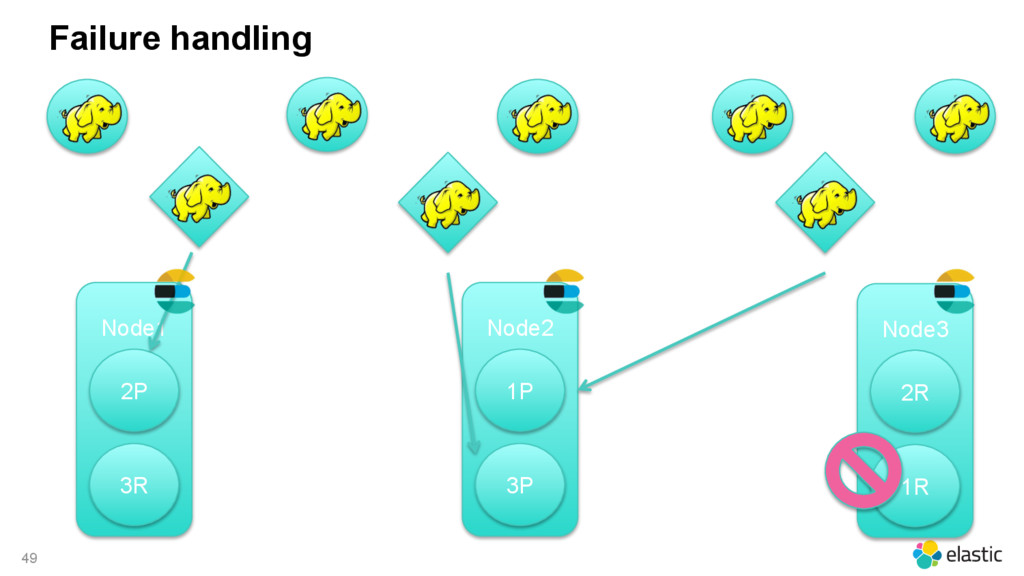{kind=link}
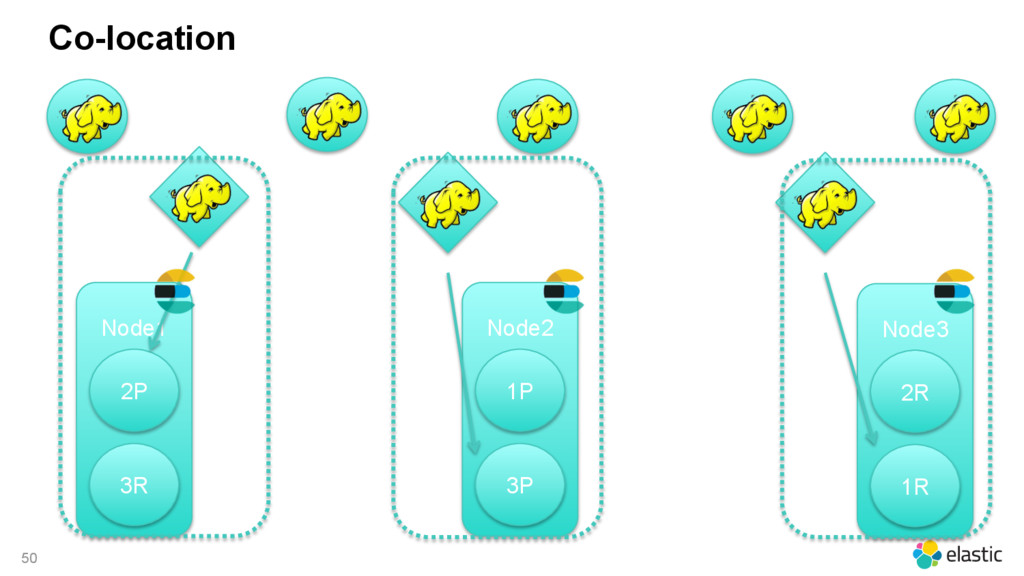{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
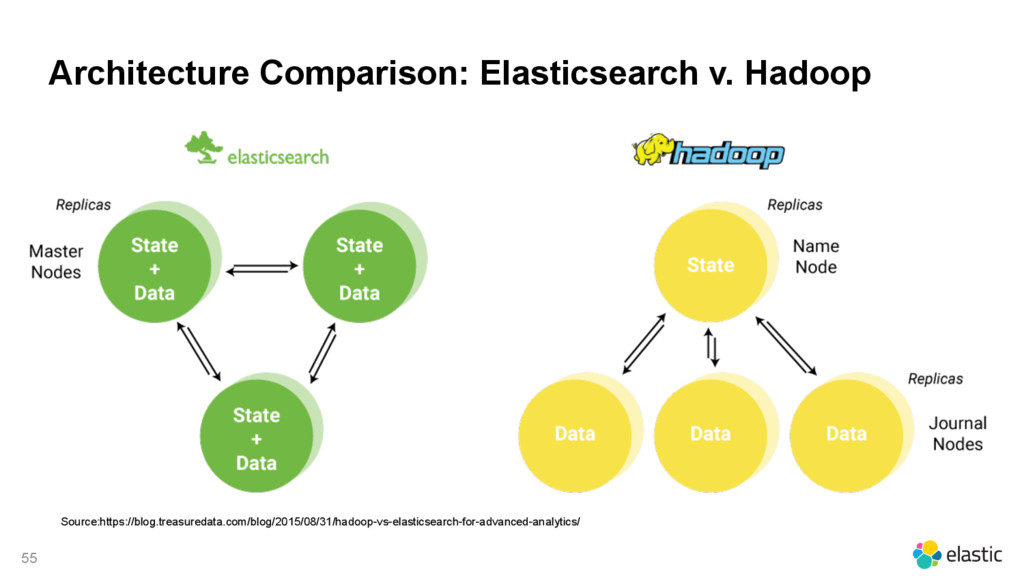{kind=link}