Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLM活用プロダクトを作るときに気をつけたこと〜問題は小さく分けて、いい分析にはいいデータを〜
Search
mento _official
September 02, 2024
1.6k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLM活用プロダクトを作るときに気をつけたこと〜問題は小さく分けて、いい分析にはいいデータを〜
mento _official
September 02, 2024
More Decks by mento _official
See All by mento _official
mento Design Team Portfolio
mento0fficial
2
1.9k
mento Company Deck
mento0fficial
3
49k
mentoで働くデザイナー募集
mento0fficial
0
360
1分で分かるmento for Business
mento0fficial
1
480
【mento】コーチングを活用した育成型組織への転換
mento0fficial
0
10k
【mento】パナソニックが向き合う多様な組織への変革における痛みと学び
mento0fficial
0
10k
【mento】初回アポイントで貴社へ提供できる情報一覧
mento0fficial
0
8k
ビジョン策定オフサイト資料
mento0fficial
0
5.7k
Featured
See All Featured
The Cult of Friendly URLs
andyhume
79
7k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Site-Speed That Sticks
csswizardry
13
1.4k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Side Projects
sachag
455
43k
Accessibility Awareness
sabderemane
1
170
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.8k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Utilizing Notion as your number one productivity tool
mfonobong
4
490
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
340
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
330
Building the Perfect Custom Keyboard
takai
2
830
Transcript
LLM活用プロダクトを作るときに気をつけたこと 問題は小さく分けて、いい分析にはいいデータを NEWT Tech Talk vol.11 LLM時代に進化するプロダクト開発 ~最新の事例共有~ 1 2024/08/27
杉浦太樹 @futoiki
mento Inc. 自己紹介 新卒でリクルート入社後、データサイエンティストとして従 事。データ分析組織のマネージャーも担当。 2022年に株式会社mentoに参画。コーチング情報から取得さ れる動画・音声・テキスト情報に関する分析、データを中心 とした戦略策定を推進。 現在、大学院 博士課程にも在籍し機械学習に関する研究中。
(距離学習、情報幾何あたり) 好きなもの:SHIROBAKO, ハンドボール, ボードゲーム 杉浦 太樹 @futoiki データサイエンティスト + その他色々
mento Inc, 会社概要 株式会社mento 事業内容 コーチングプラットフォーム 代表者 木村憲仁 登録コーチ数 200名以上
累計セッション時間 50,000時間以上
mento Inc. 今日のテーマ 対話要約機能「AIサマリー」を 作るときに”具体的に”気をつけたこと
mento Inc. 今日持ち帰ってほしいこと 問題は小さく分けて いい分析にはいいデータを
mento Inc, 6 前提として コーチングって受けたことあります?
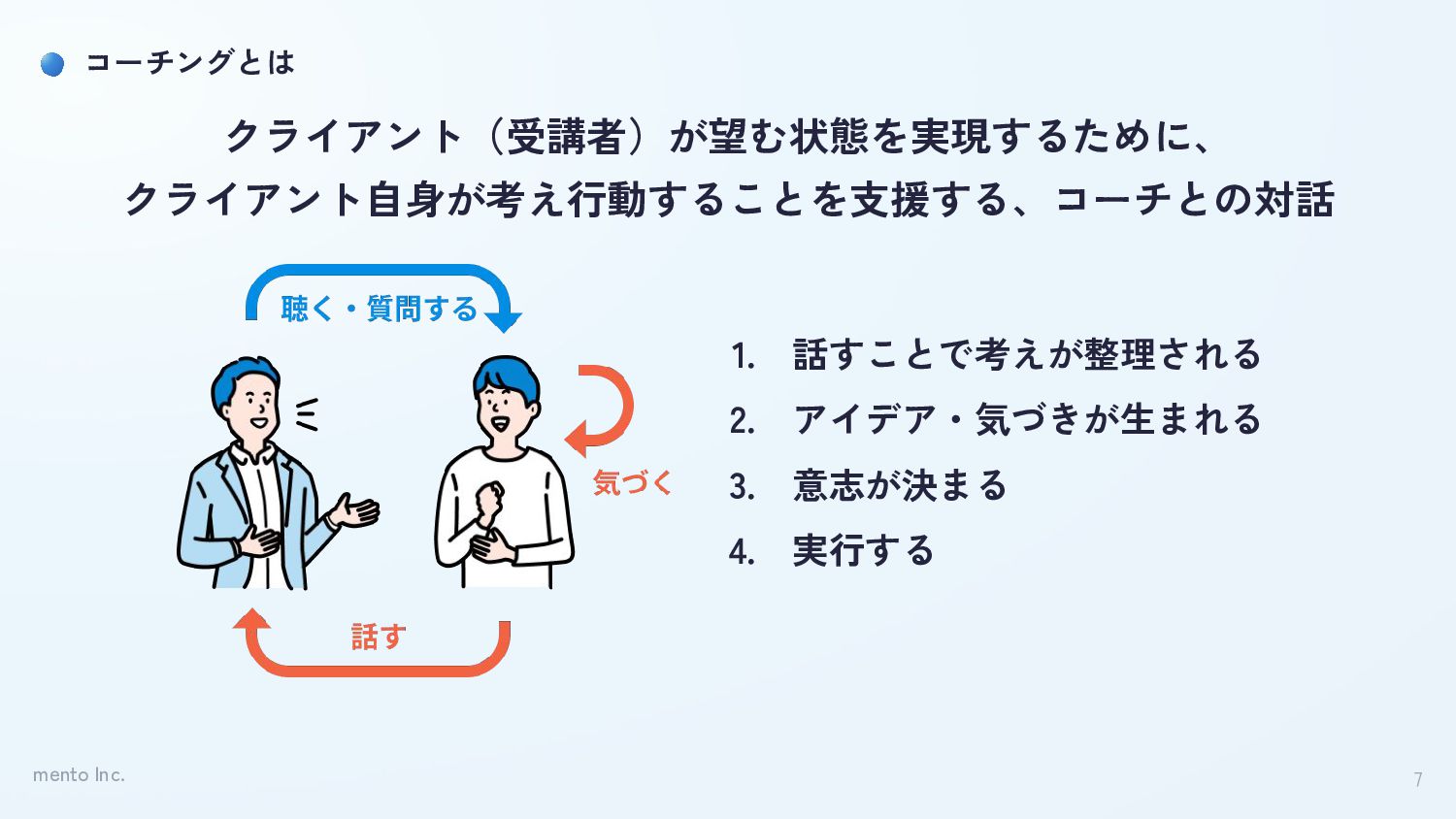
mento Inc. 7 コーチングとは クライアント(受講者)が望む状態を実現するために、 クライアント自身が考え行動することを支援する、コーチとの対話 1. 話すことで考えが整理される 2. アイデア・気づきが生まれる
3. 意志が決まる 4. 実行する
mento Inc. 8 コーチングとは クライアント(受講者)が望む状態を実現するために、 クライアント自身が考え行動することを支援する、コーチとの対話 1. 話すことで考えが整理される 2. アイデア・気づきが生まれる
3. 意志が決まる 4. 実行する 6ヶ月〜12ヶ月、利用いただくことが多い
mento Inc. コーチングのプロセスは白地で溢れてる セッション日 セッション日 セッション日 セッション日 セッション日 コーチングを継続的に受けているときの典型例
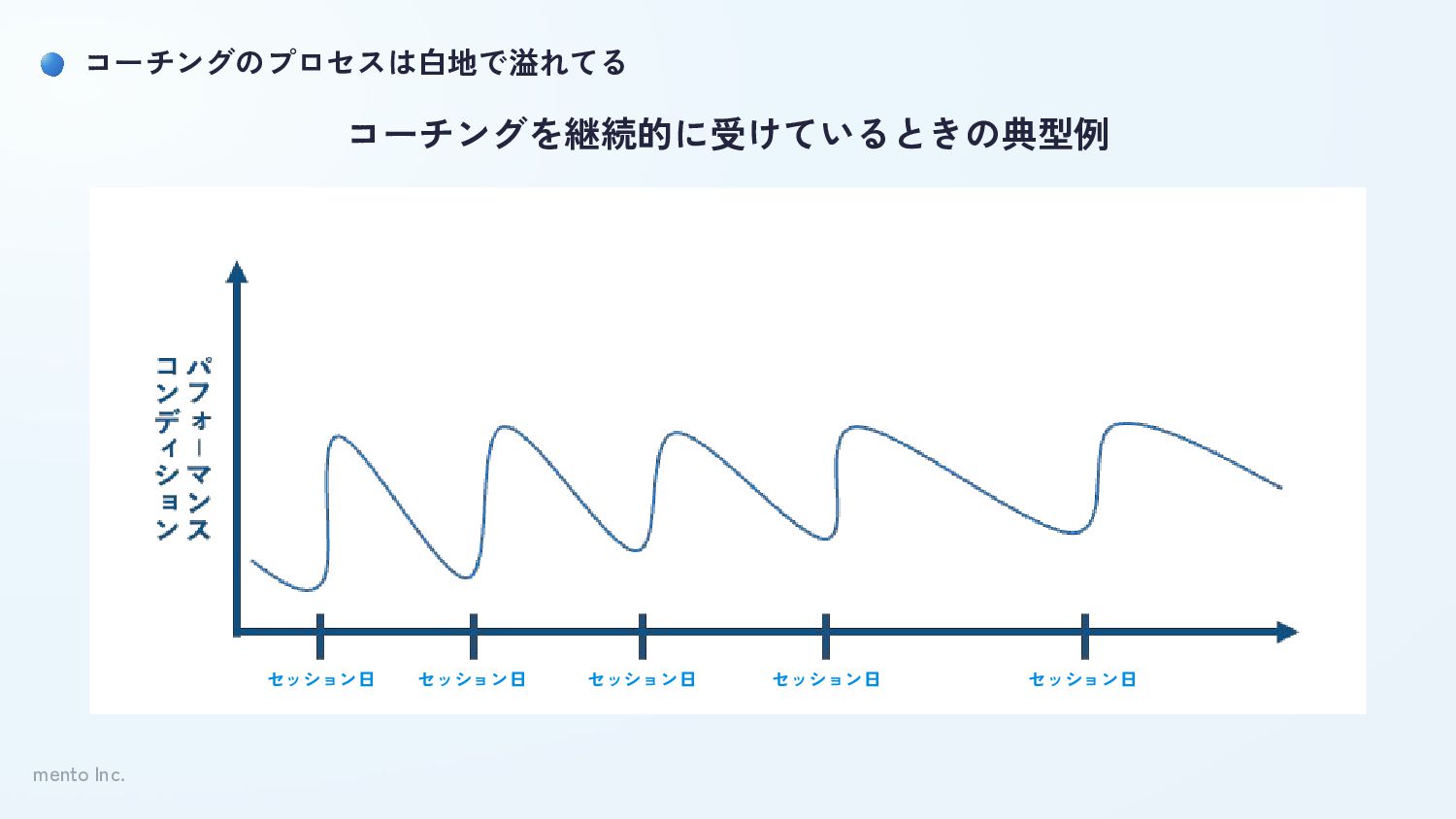
mento Inc. コーチングのプロセスは白地で溢れてる セッション日 セッション日 セッション日 セッション日 セッション日 コーチングを継続的に受けているときの典型例
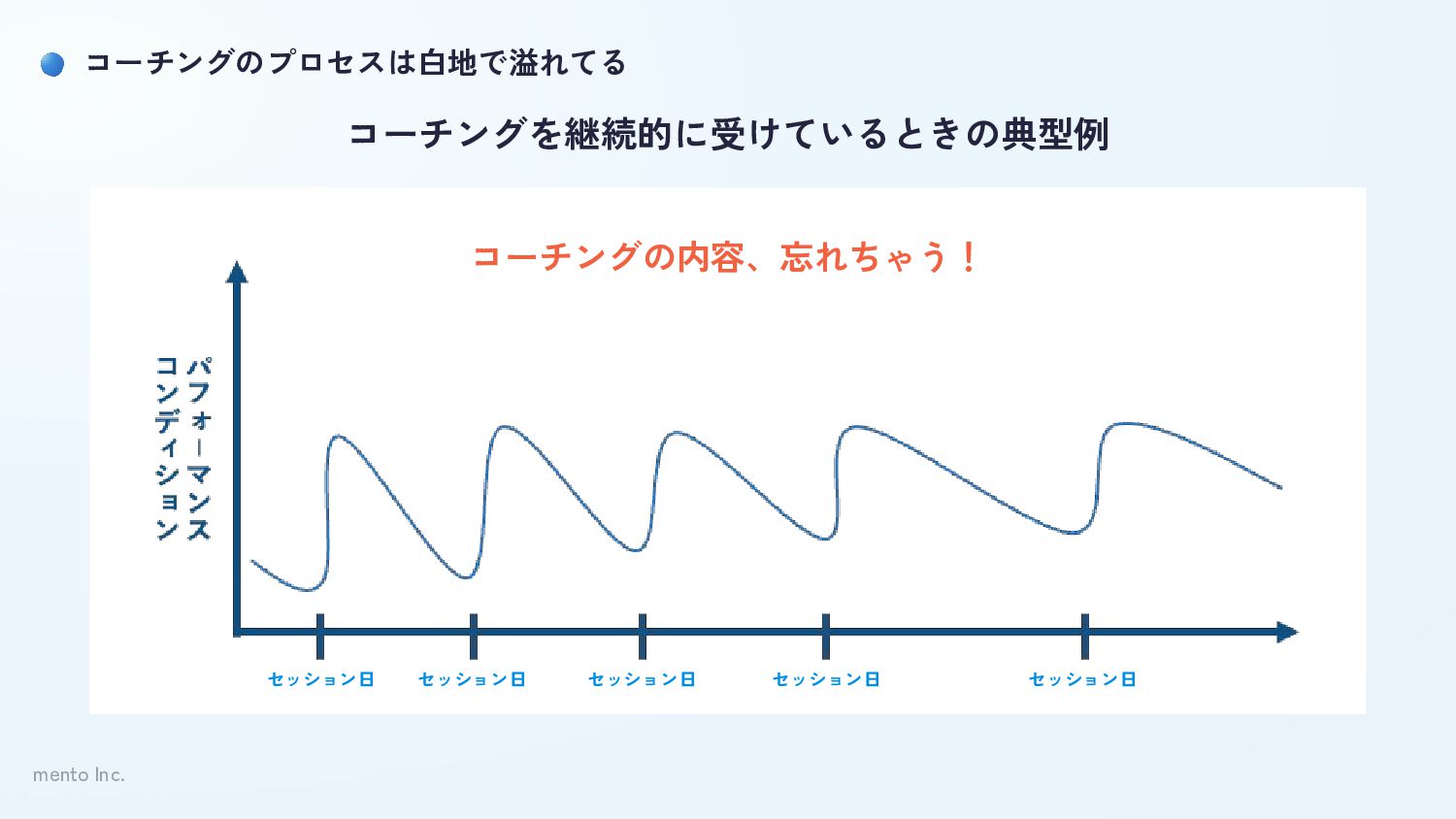
mento Inc. コーチングのプロセスは白地で溢れてる セッション日 セッション日 セッション日 セッション日 セッション日 コーチングを継続的に受けているときの典型例 コーチングの内容、忘れちゃう!
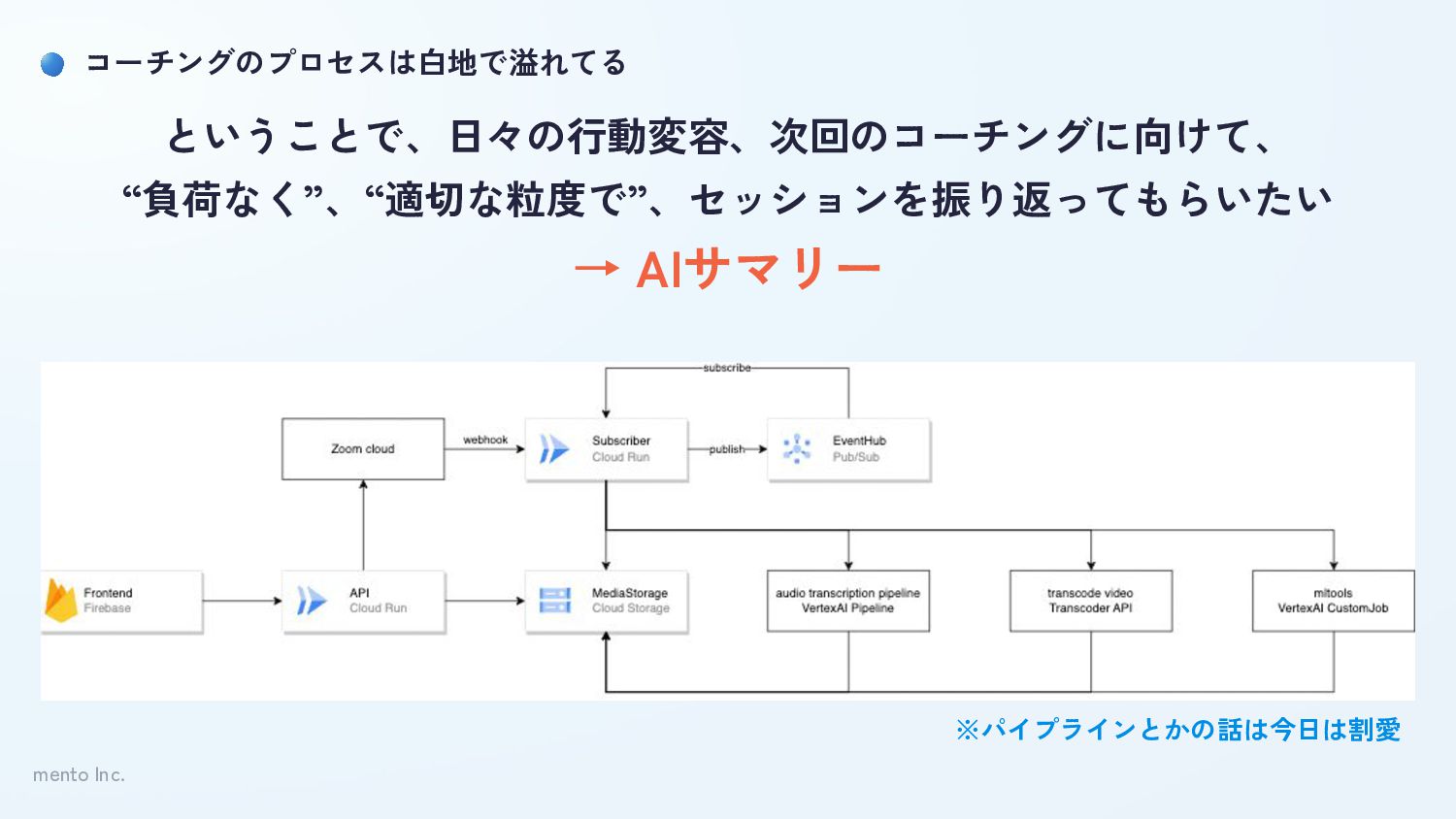
mento Inc. コーチングのプロセスは白地で溢れてる ということで、日々の行動変容、次回のコーチングに向けて、 “負荷なく”、“適切な粒度で”、セッションを振り返ってもらいたい → AIサマリー ※パイプラインとかの話は今日は割愛
mento Inc. AIサマリーとは
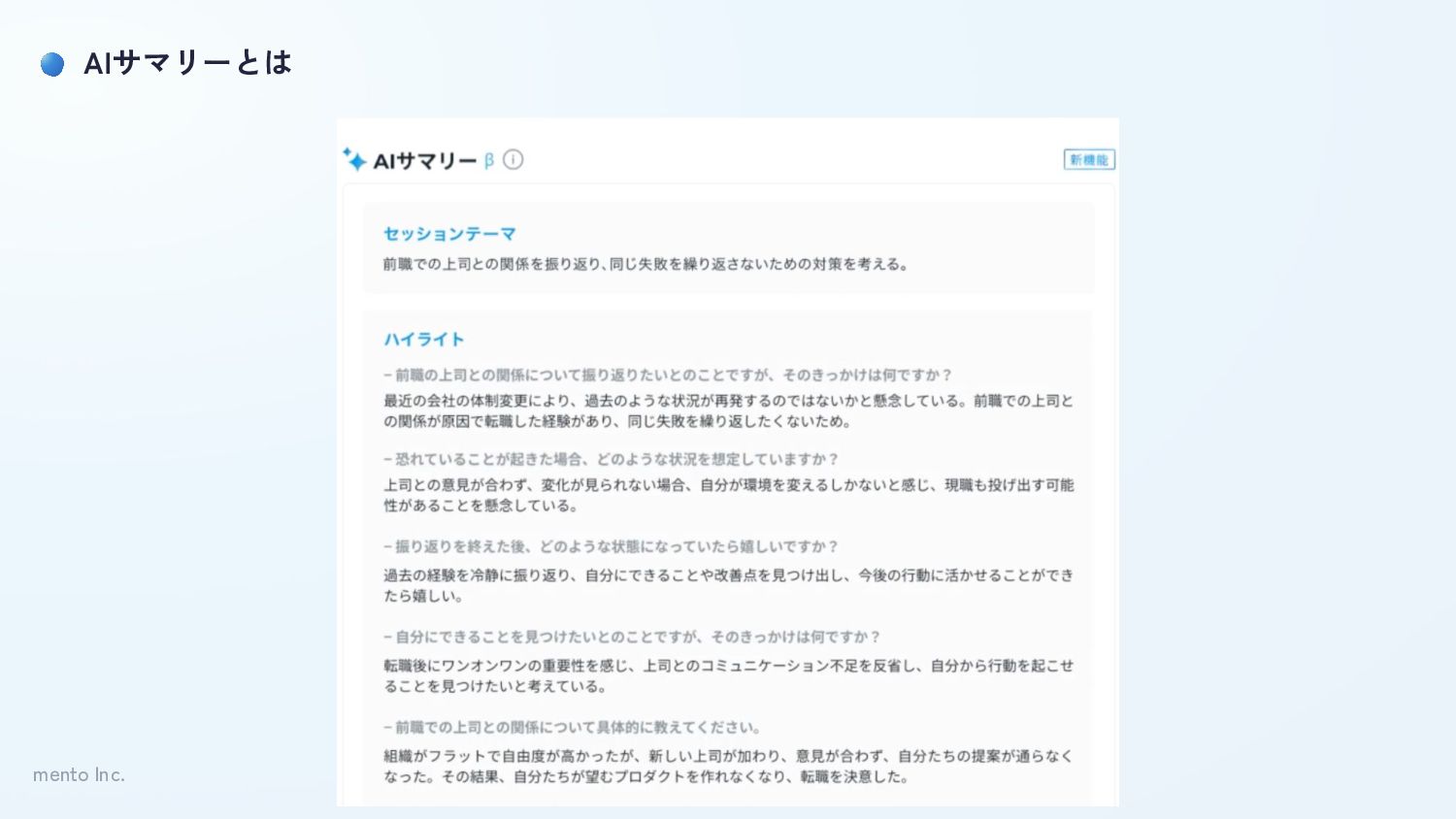
mento Inc. AIサマリーとは
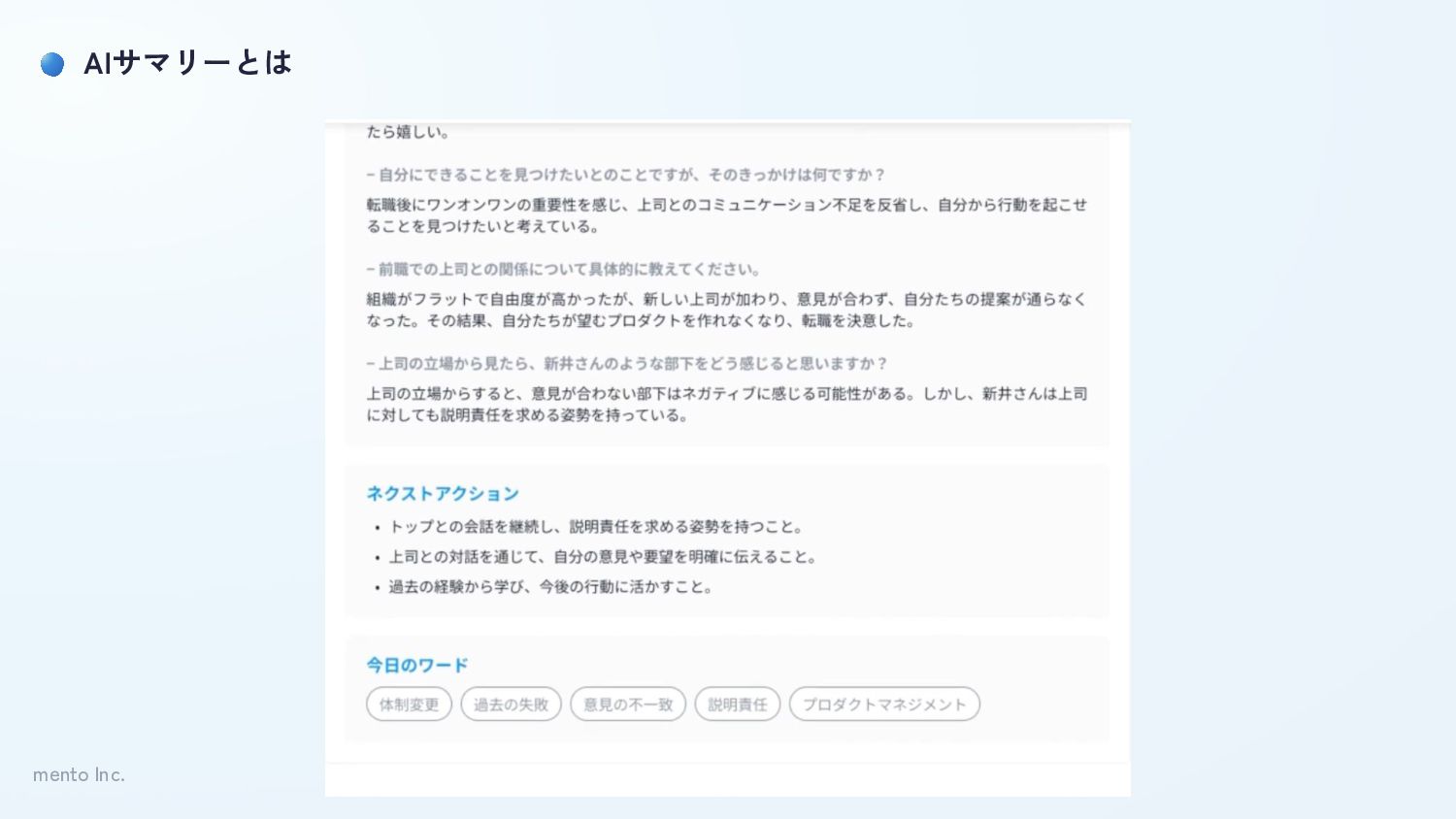
mento Inc. AIサマリーとは
mento Inc. HR テクノロジー大賞
mento Inc. AIサマリーとは 手間なく負荷なく、後で内容を思い出せるような要約を作成する • 1時間のコーチングを通じた「タイトル」「キーワード」 • 全体の流れがわかる「ピックアップ」 • 次回のコーチングに向けた「ネクストアクション」
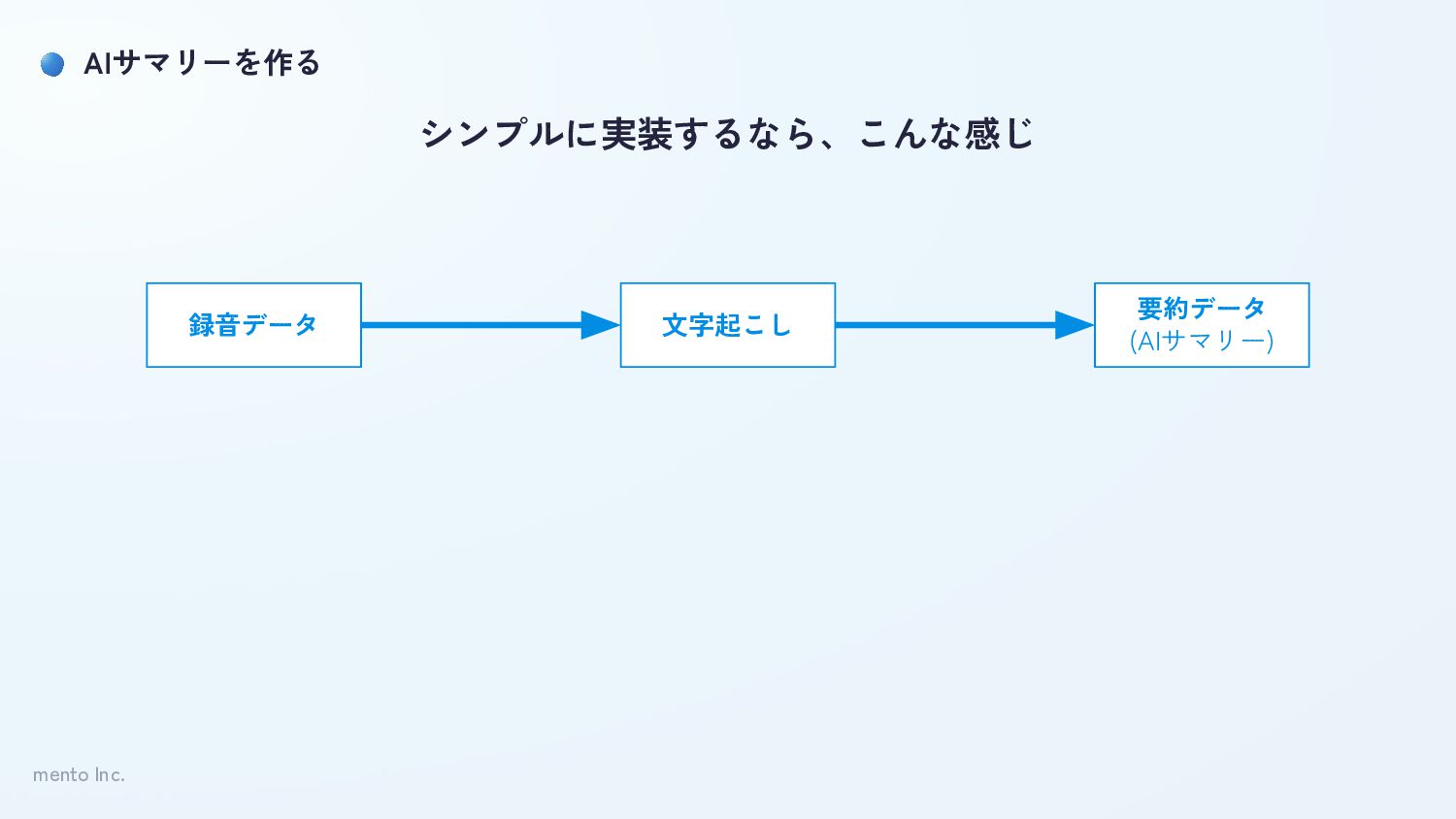
mento Inc. AIサマリーを作る シンプルに実装するなら、こんな感じ 録音データ 文字起こし 要約データ (AIサマリー)
mento Inc. 要約?割ともう普通に精度でるんじゃない?
mento Inc, 20 要約?割ともう普通に精度でるんじゃない? でない
mento Inc. 要約?割ともう普通に精度でるんじゃない?でない。
mento Inc. 要約?割ともう普通に精度でるんじゃない?でない。 • 言ってもないことをLLMが勝手に... • これは「私」が発言じゃなくて「コーチ」の発言 • この粒度でほしいわけじゃない... ◦
自身のマネジメントの悩みを話した • ていうか、そもそも文字起こしの精度が... ◦ 部下とのワンワンで...
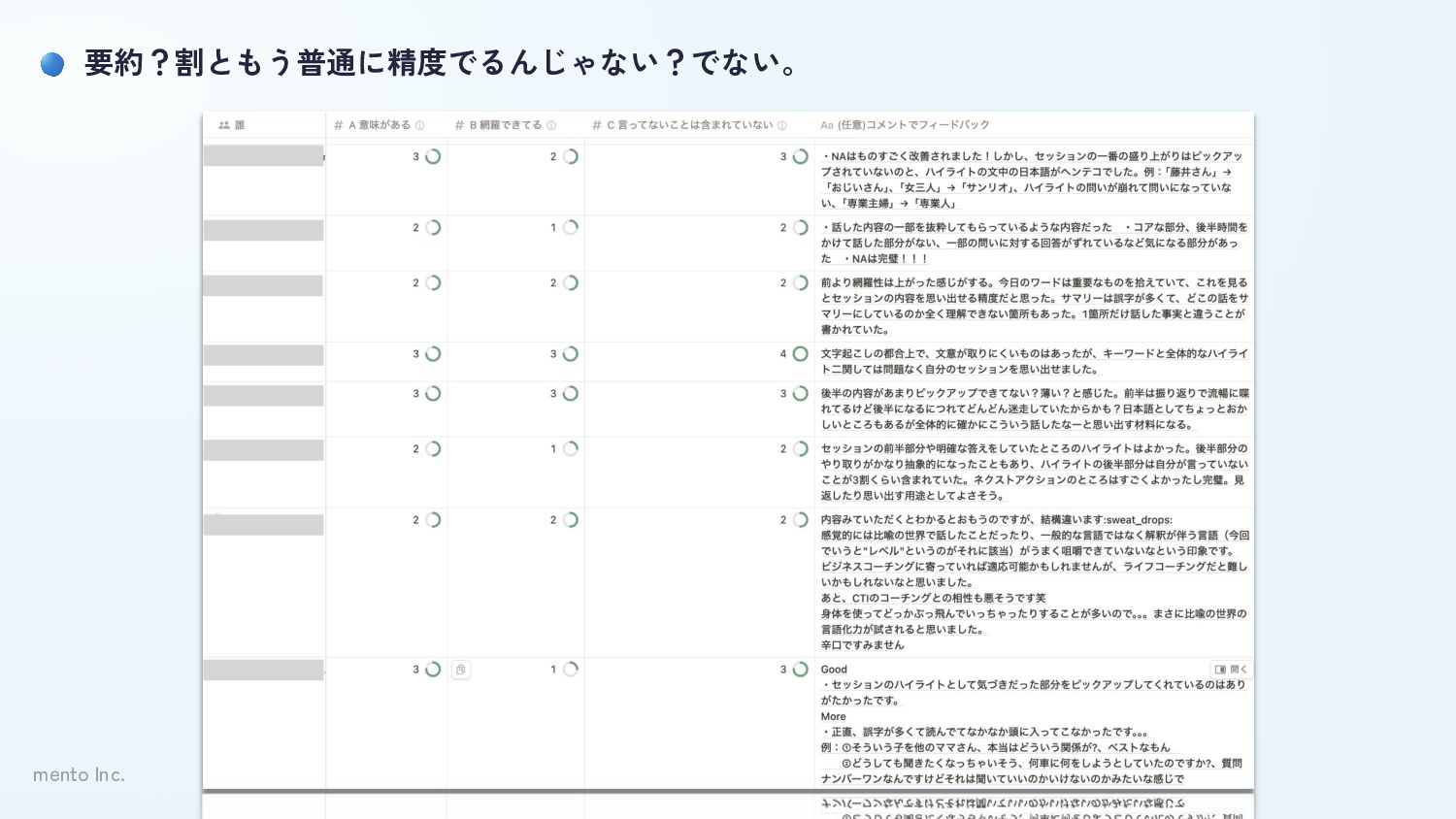
mento Inc. 何が起きているのか? 社内協力者のデータをもとに、何が起きているのか生データから手動で確認・検証
mento Inc. 何が起きているのか? 社内協力者のデータをもとに、何が起きているのか生データから手動で確認・検証
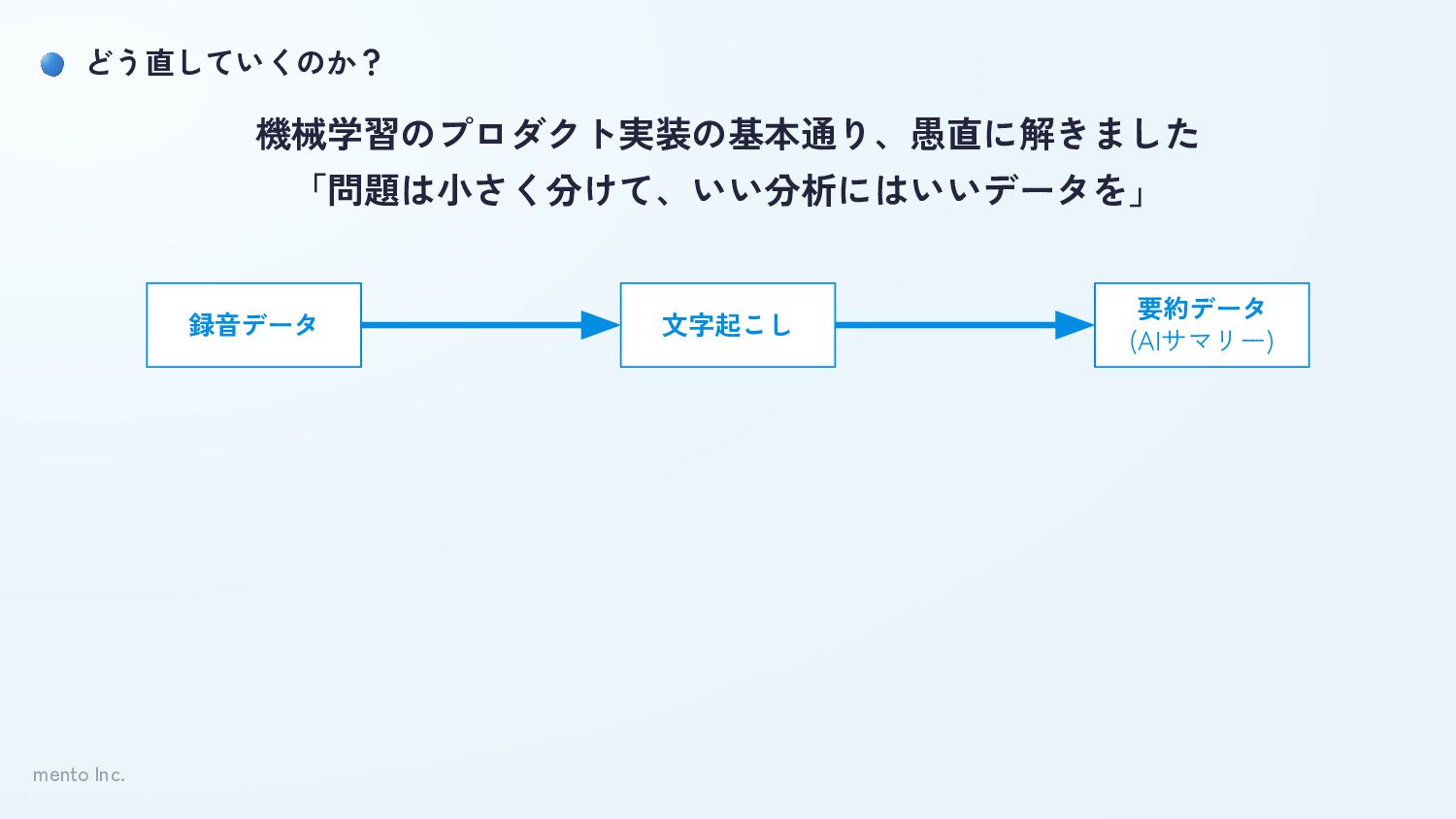
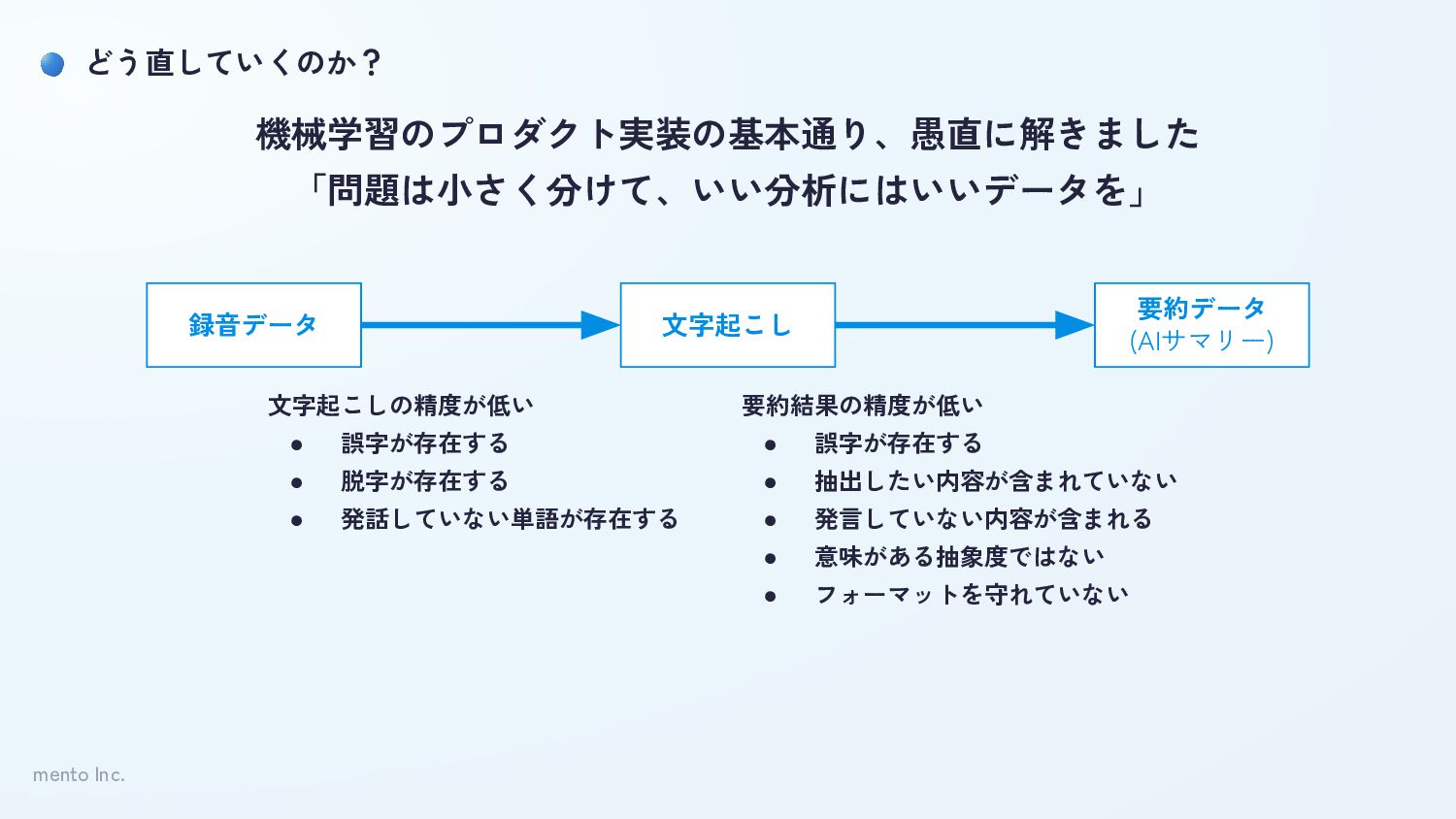
mento Inc. どう直していくのか? 録音データ 文字起こし 要約データ (AIサマリー) 機械学習のプロダクト実装の基本通り、愚直に解きました 「問題は小さく分けて、いい分析にはいいデータを」
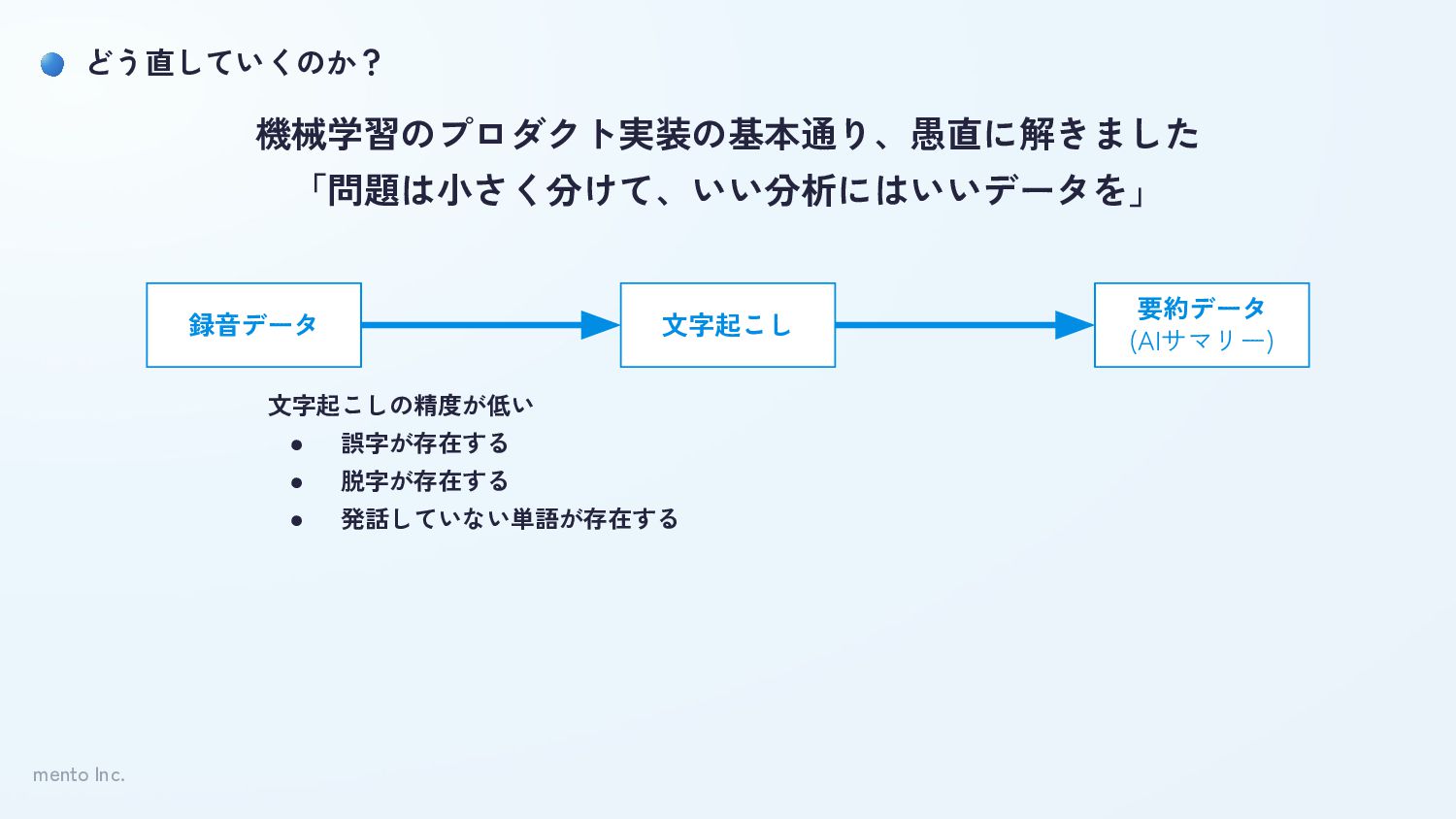
mento Inc. どう直していくのか? 録音データ 文字起こし 要約データ (AIサマリー) 機械学習のプロダクト実装の基本通り、愚直に解きました 「問題は小さく分けて、いい分析にはいいデータを」 文字起こしの精度が低い
• 誤字が存在する • 脱字が存在する • 発話していない単語が存在する
mento Inc. どう直していくのか? 録音データ 文字起こし 要約データ (AIサマリー) 機械学習のプロダクト実装の基本通り、愚直に解きました 「問題は小さく分けて、いい分析にはいいデータを」 文字起こしの精度が低い
• 誤字が存在する • 脱字が存在する • 発話していない単語が存在する 要約結果の精度が低い • 誤字が存在する • 抽出したい内容が含まれていない • 発言していない内容が含まれる • 意味がある抽象度ではない • フォーマットを守れていない
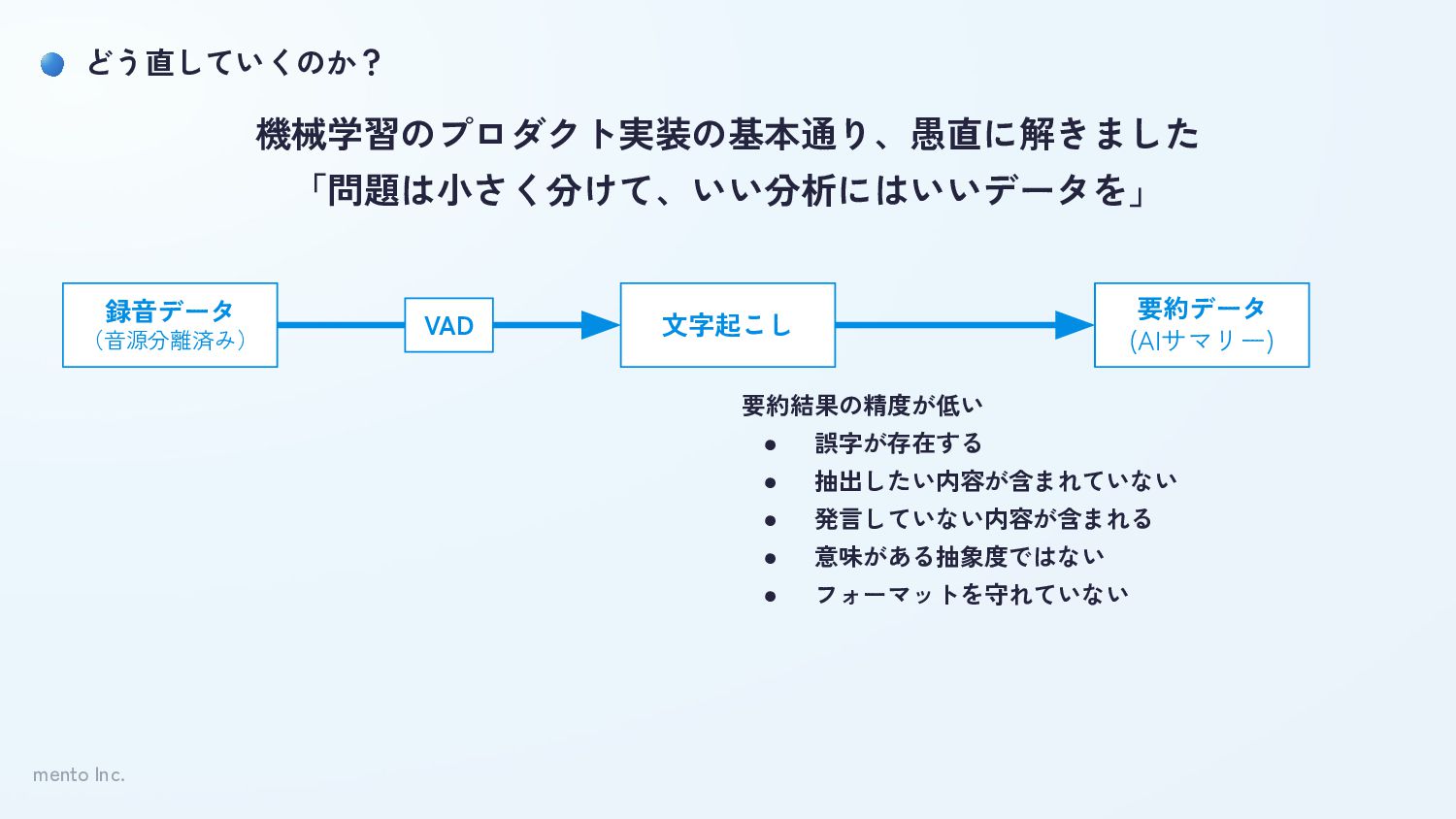
mento Inc. 文字起こしの精度について 誤字が存在 • コーチングのデータに対して、複数のモデルを適用し検証 ◦ Amazon transcribe/Gemini/Azure Speech
to text/AmiVoice/Whipser(v2/v3)/… 脱字が存在 • 話者が重なった場合に誤りが増えるケースが多い • 音声認識問題の前提として、音声ファイルが分離されているケースの精度が良い • そもそも録音時に、音声ファイルを話者分離できるサービスを利用 発言していない内容が存在 • コーチングが1on1のため、話者分離されている場合、無音期間が長くなる • 無音期間に対して、特定のモデルは文字起こしの精度が非常に不安定になる ◦ 「ご視聴ありがとうございました」問題 • 発話区間推定(Voice Activity Detection)を行い、発生部分のみを文字起こしを実施 ※もちろん精度以外の運用観点/法務観点も考慮し最終意思決定
mento Inc. どう直していくのか? 録音データ (音源分離済み) 文字起こし 要約データ (AIサマリー) 機械学習のプロダクト実装の基本通り、愚直に解きました 「問題は小さく分けて、いい分析にはいいデータを」
要約結果の精度が低い • 誤字が存在する • 抽出したい内容が含まれていない • 発言していない内容が含まれる • 意味がある抽象度ではない • フォーマットを守れていない VAD
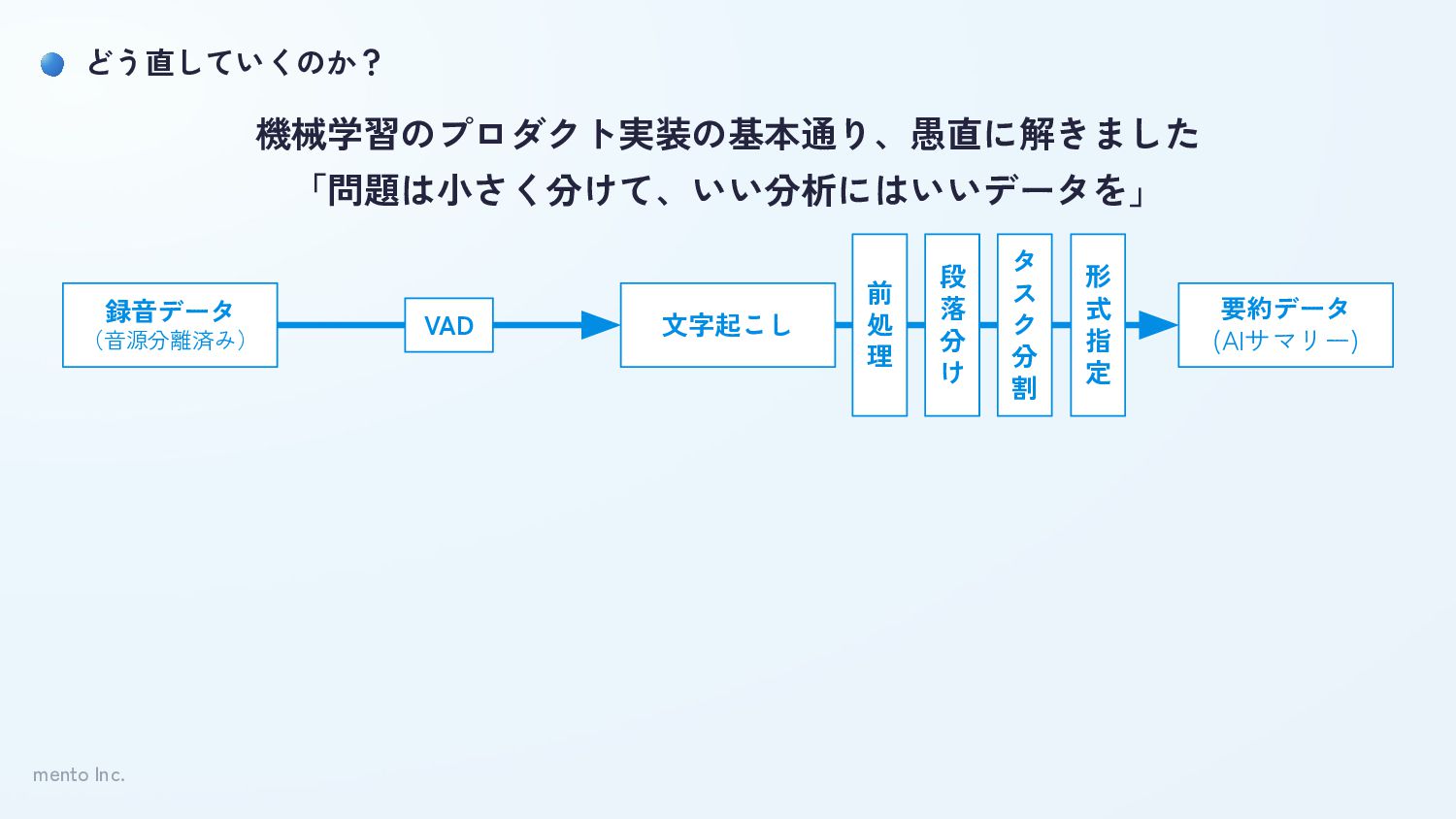
mento Inc. 要約の精度 誤字が存在 • 誤字の中でも「人名」「専門用語」など一定のパターン化が可能なものは、個別の前処理で対応 抽出したい内容が含まれていない • 文字起こし全体をいきなり要約させるのではなく段落分けから開始 発言していない内容が含まれる/意味がある抽象度ではない
• 要約を「キーワード特定」「ネクストアクション特定」「テーマ特定」の3タスクに分けて実施 フォーマットを守れていない • Function calling/Structured Outputなどフォーマットをある程度固められるものを利用 ※もちろん精度以外の運用観点/法務観点も考慮し最終意思決定
mento Inc. どう直していくのか? 録音データ (音源分離済み) 文字起こし 要約データ (AIサマリー) 機械学習のプロダクト実装の基本通り、愚直に解きました 「問題は小さく分けて、いい分析にはいいデータを」
VAD 前 処 理 段 落 分 け タ ス ク 分 割 形 式 指 定
mento Inc. 補足 軽く試したけどうまくいかなかったので、もしいいアイデアあったら教えて下さい、なこと • Whisperに対するprompting ◦ トークン数少ない... • 文字起こし自体のLLMによる修正
◦ 誤字脱字の修正 ◦ 事前情報(プロフィールなど)に応じた修正 逆に、mentoでは試してないし、弊社の今のフェーズではやらないと決めていること • 自社モデルの構築 • Fine-tuning
mento Inc, 33 待って まだ終わりじゃない
mento Inc. リリースについて • リリース基準となる精度は”定性評価”になりがち(=100%は無理) ◦ 定性を定量評価に落とし込んで、基準を決める • ToBなので一部の関係性の良いお客様から開始、社内の セールス/サクセス担当と事前に会話してから提供
mento Inc. AIサマリーではこのプロセスをもとに不確実性を下げ、開発/検証を繰り返しました かなり精度があがりました!セッショ ンを思い出すきっかけになります。 かなり精度が上がっている。文字面を追ってい くことでセッションを思い出すことができた。 精度高く要約されていたと思います。抽象度を 少し高くした要約はほぼ完璧だと思いました 誤字がいくつかあったが気にならないレベル。上記
同様、これ言ったっけな?はあるが、全体としてず れてないので許容範囲 ネクストアクション、今日のワードについては精度 があがったように思える。すべての項目で、コーチ ング全体からの網羅性は上がったように思える。
mento Inc. 今日のまとめ 問題は小さく分けて いい分析にはいいデータを
mento Inc. 今後の展望 • 「AIサマリー」に限らず、今後は非構造化データに対する機能開発が進む • 今後もLLM活用機能は事業の根幹として継続して開発 • 本番プロダクト上で動かせている企業が増えてきた(けど、情報はまだ少ない) •
今日はぜひいろいろと議論させてください!
mento Inc, 38 ついでに カジュアル面談やってます コーチングの話、組織の話 なんでも話しましょう! https://herp.careers/v1/mento/zgEhIVY4CLhN
Appendix.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}