Speaker: Takuma Yamaguchi
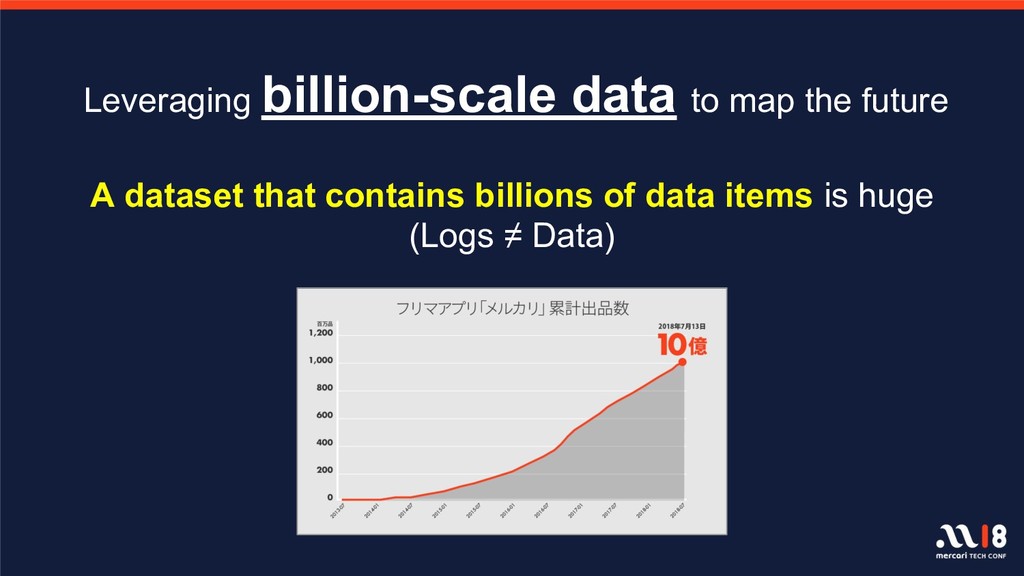
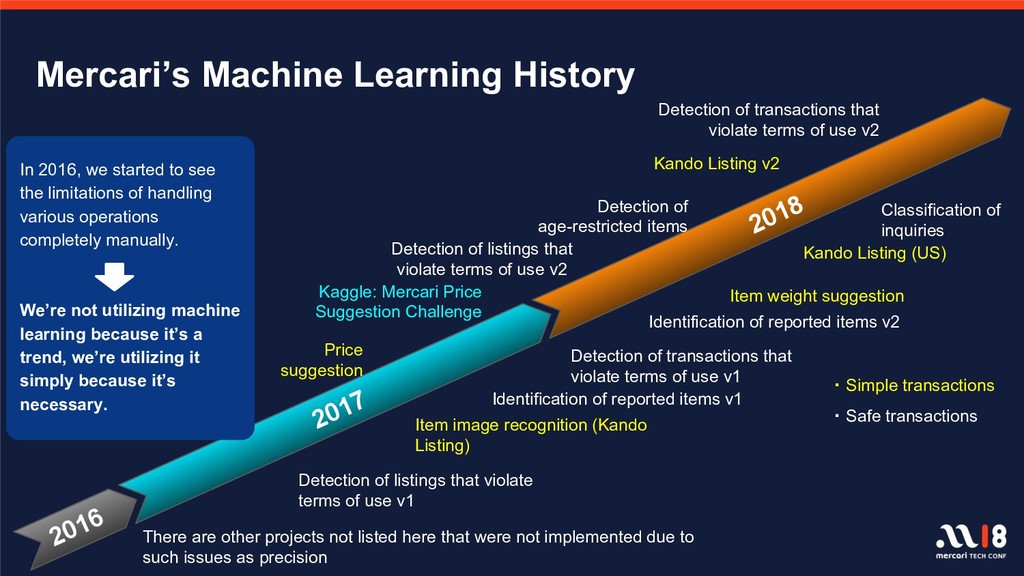
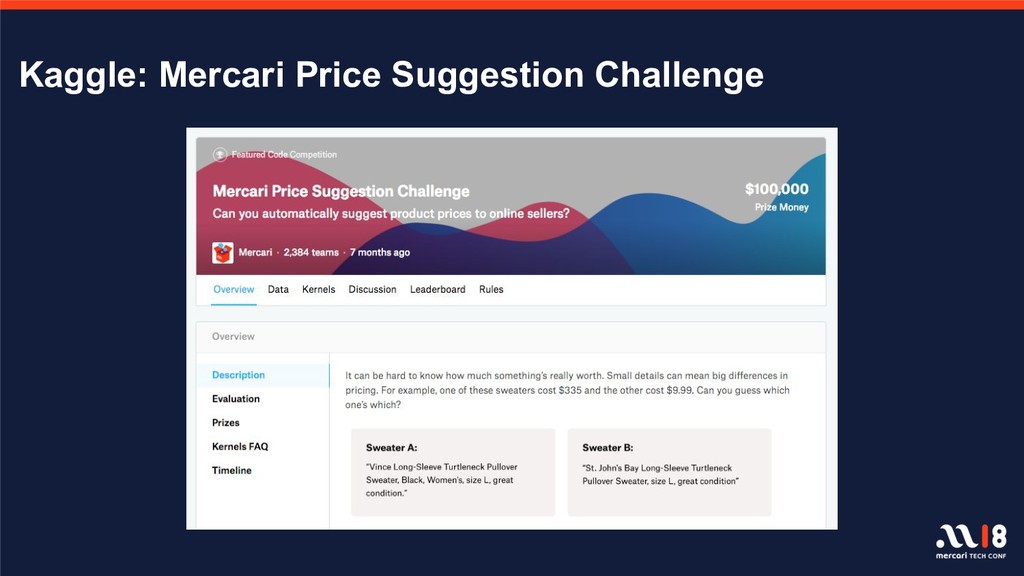
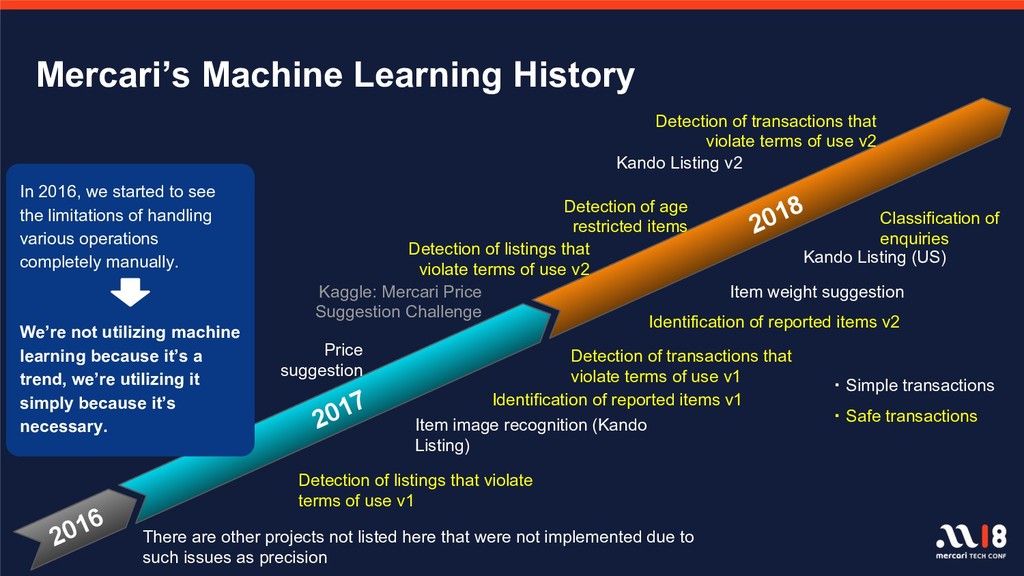
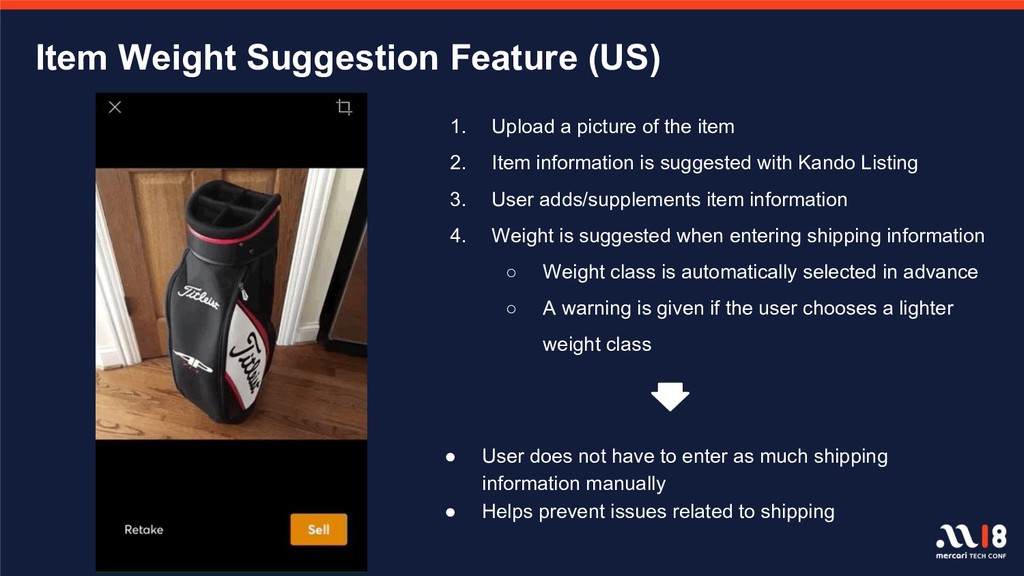
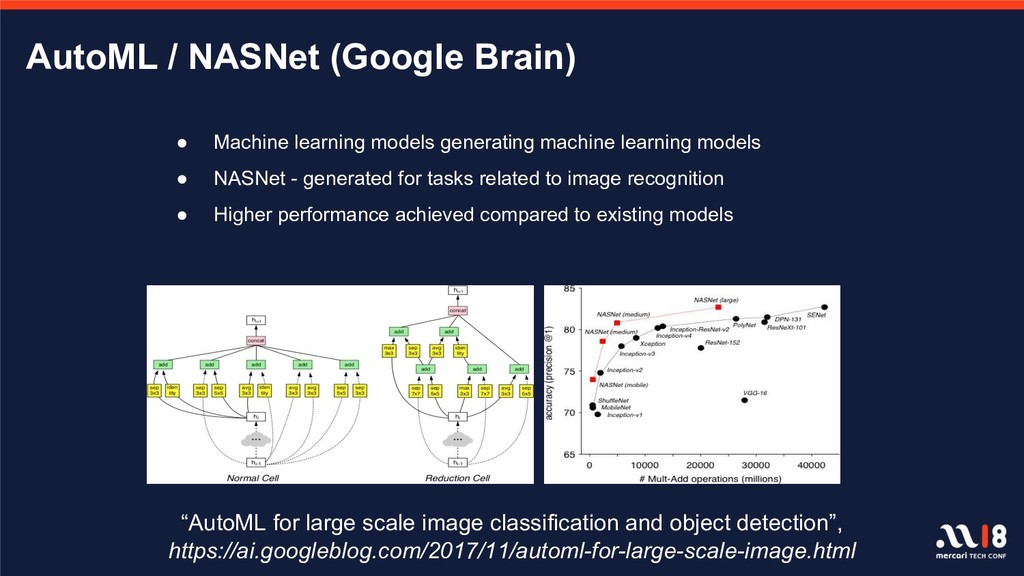
With over one billion total listings on the Mercari app to date and with the remarkable advancements observed in recent years in the fields of machine learning and deep learning, there is increasingly greater focus on, and expectations for, data utility. There are a number of projects underway which utilize data on items and user behavior, and several features, including image recognition for listings and automatic detection of fraudulent listings, are already in operation on the service. This session will introduce those algorithms and execution platforms and will also introduce a number of features currently in development.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
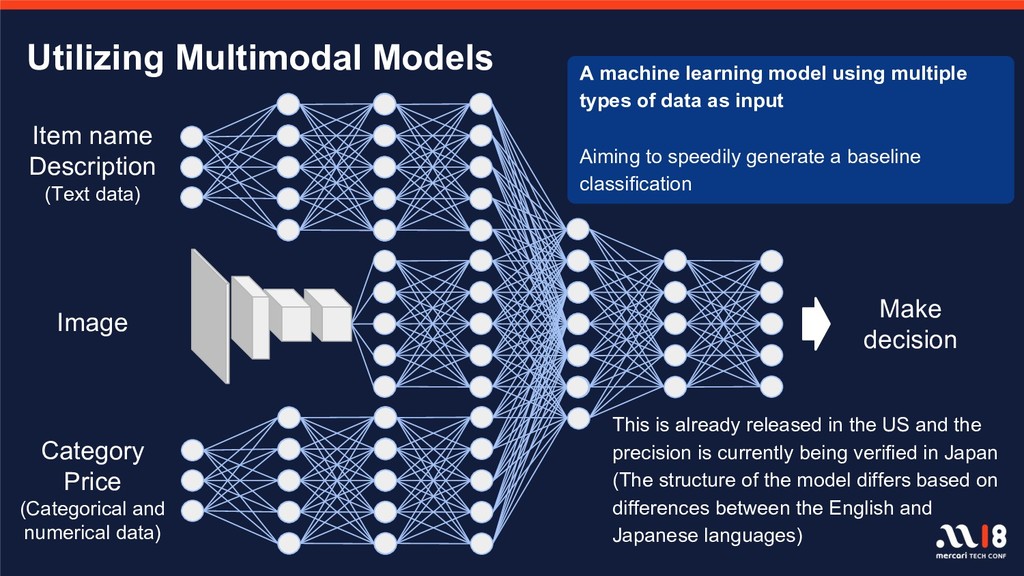{kind=link}
{kind=link}
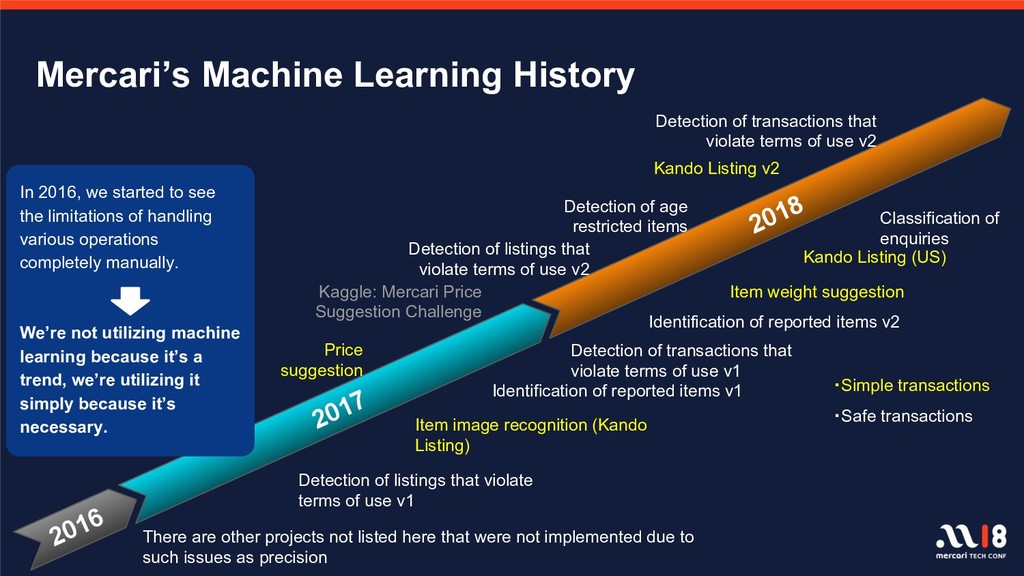{kind=link}
{kind=link}
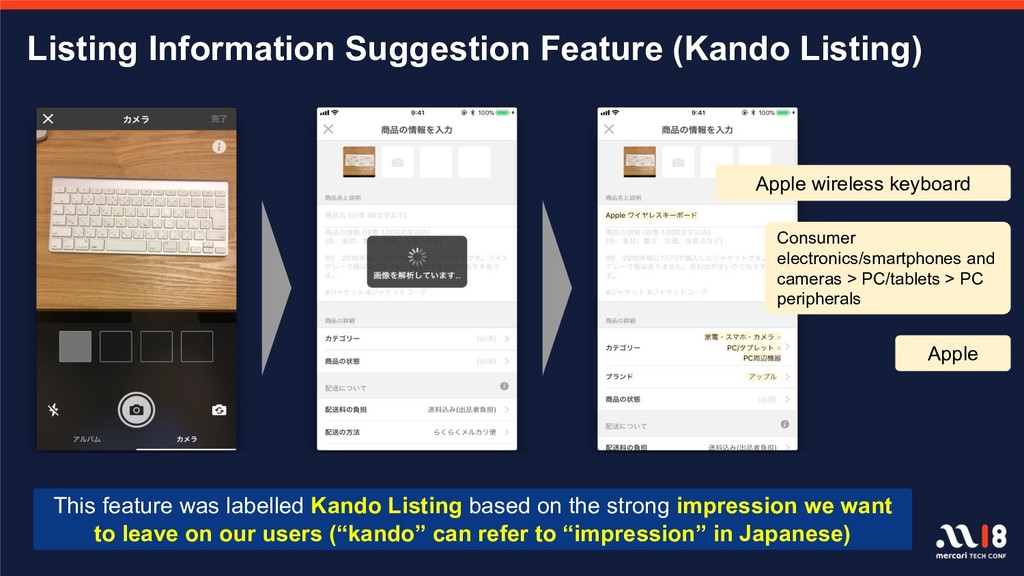{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}