Universitário da FEI, MBA em Gestão Empresarial pela EASP (FGV) e Gestão de TI (FIAP) Docente do curso de pós graduação MBA em cursos relacionados a tecnologias corporativas/SOA, mobilidade/jogos e sistemas de informação na FIAP. Gerente de Engenharia na John Deere. Atuação como Arquiteto de Soluções de Sistemas de Suporte a Operação (OSS) em empresas de telecomunicações como Nextel e Vivo, além de ter criado a área de Pesquisa e Desenvolvimento na EY, o BeyondLabs, com foco em inovação, análise de dados (aprendizado autônomo), uso inteligente dos dispositivos móveis e automação de atividades. br.linkedin.com/in/michelpf/
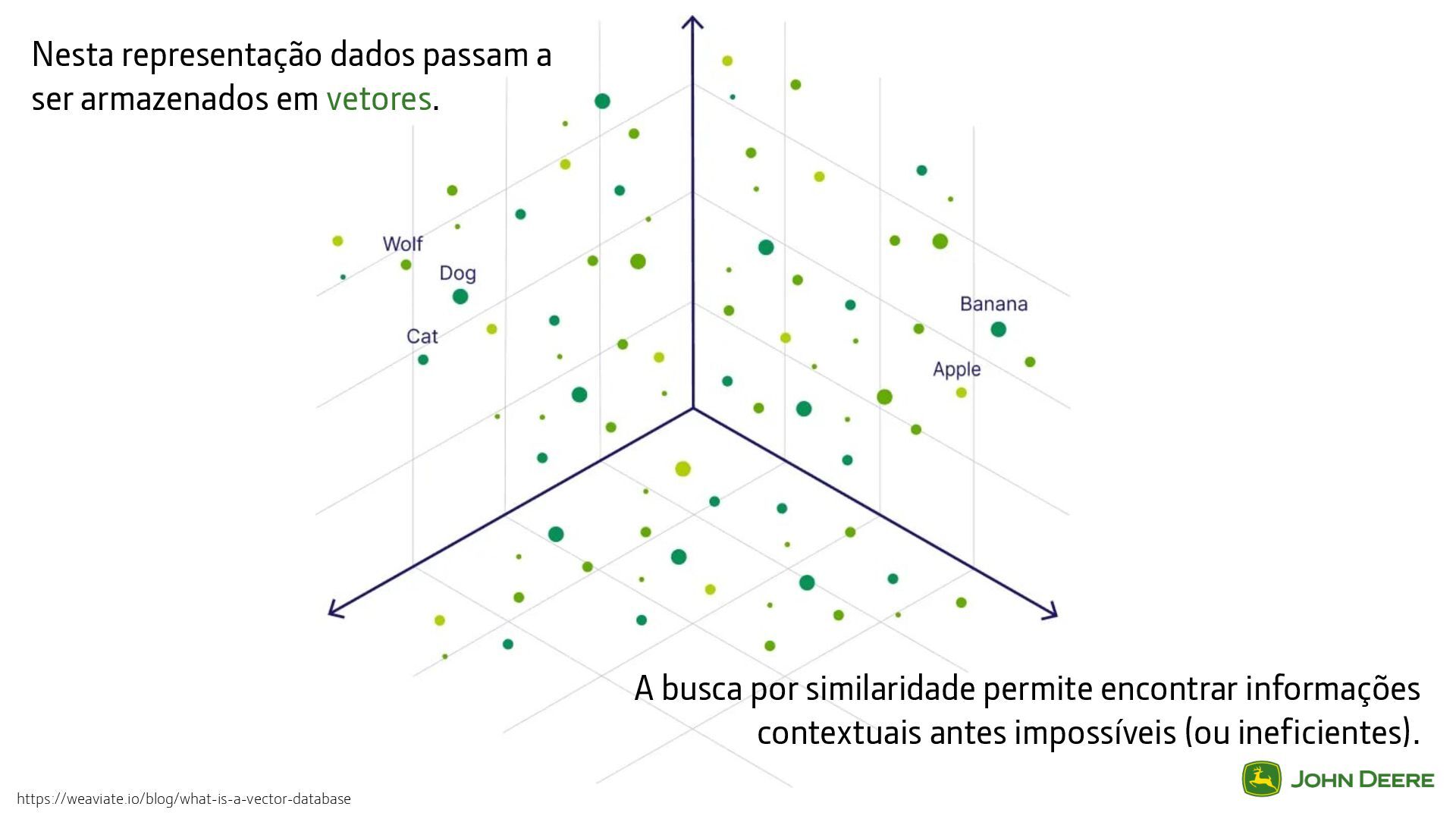
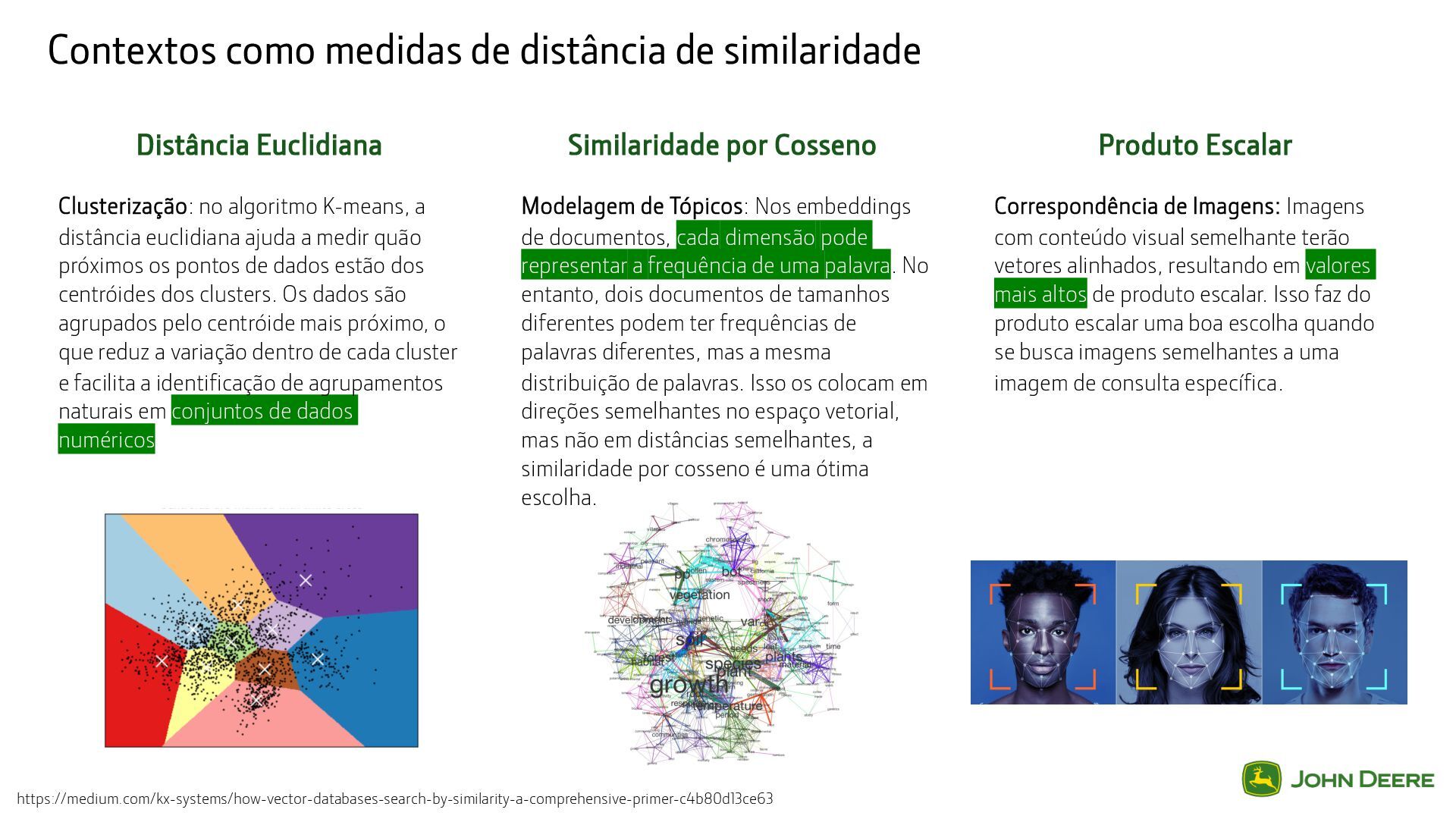
Escalar Similaridade por Cosseno Clusterização: no algoritmo K-means, a distância euclidiana ajuda a medir quão próximos os pontos de dados estão dos centróides dos clusters. Os dados são agrupados pelo centróide mais próximo, o que reduz a variação dentro de cada cluster e facilita a identificação de agrupamentos naturais em conjuntos de dados numéricos. Correspondência de Imagens: Imagens com conteúdo visual semelhante terão vetores alinhados, resultando em valores mais altos de produto escalar. Isso faz do produto escalar uma boa escolha quando se busca imagens semelhantes a uma imagem de consulta específica. Modelagem de Tópicos: Nos embeddings de documentos, cada dimensão pode representar a frequência de uma palavra. No entanto, dois documentos de tamanhos diferentes podem ter frequências de palavras diferentes, mas a mesma distribuição de palavras. Isso os colocam em direções semelhantes no espaço vetorial, mas não em distâncias semelhantes, a similaridade por cosseno é uma ótima escolha. https://medium.com/kx-systems/how-vector-databases-search-by-similarity-a-comprehensive-primer-c4b80d13ce63
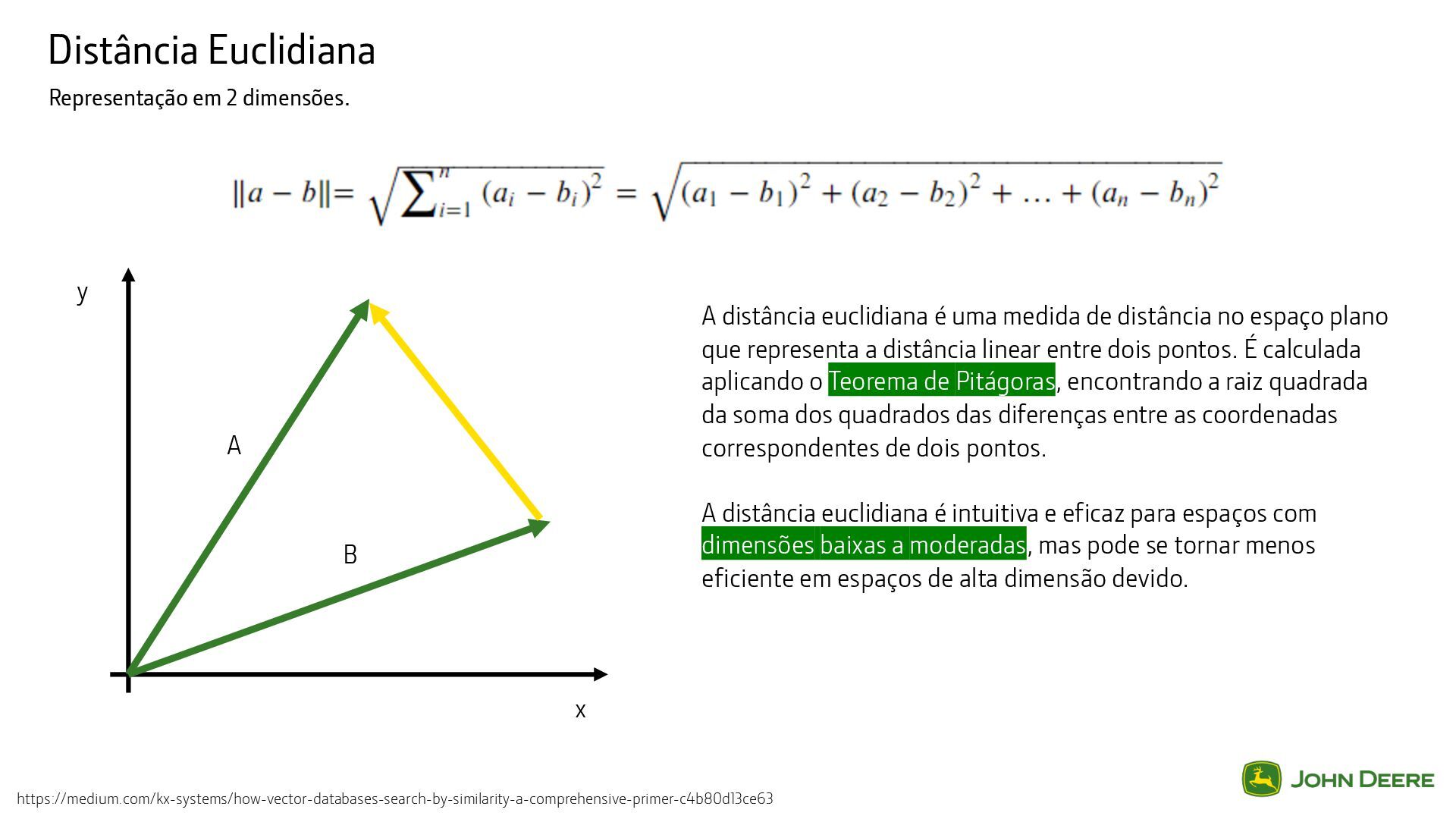
uma medida de distância no espaço plano que representa a distância linear entre dois pontos. É calculada aplicando o Teorema de Pitágoras, encontrando a raiz quadrada da soma dos quadrados das diferenças entre as coordenadas correspondentes de dois pontos. A distância euclidiana é intuitiva e eficaz para espaços com dimensões baixas a moderadas, mas pode se tornar menos eficiente em espaços de alta dimensão devido. x y A B https://medium.com/kx-systems/how-vector-databases-search-by-similarity-a-comprehensive-primer-c4b80d13ce63
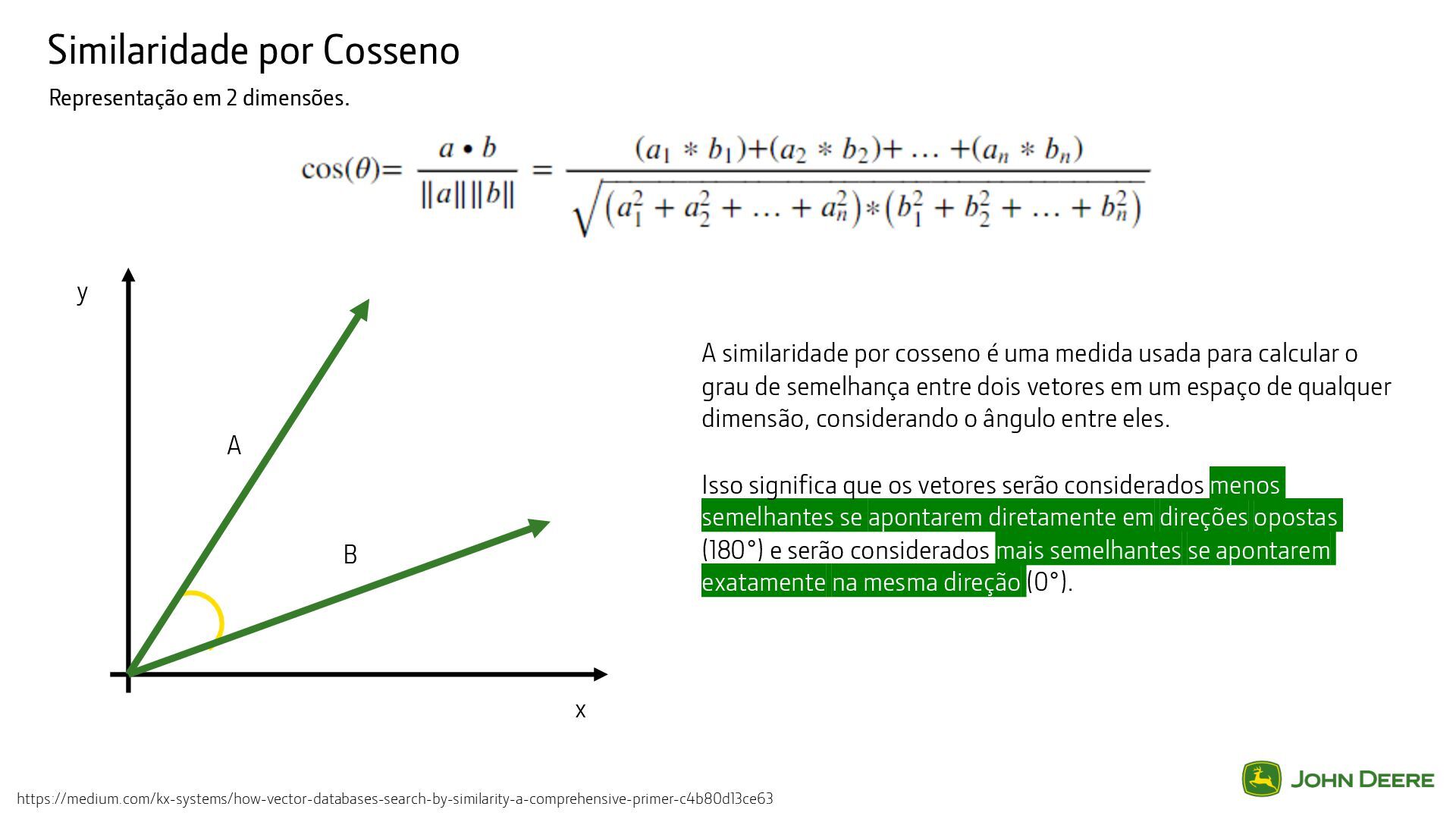
cosseno é uma medida usada para calcular o grau de semelhança entre dois vetores em um espaço de qualquer dimensão, considerando o ângulo entre eles. Isso significa que os vetores serão considerados menos semelhantes se apontarem diretamente em direções opostas (180°) e serão considerados mais semelhantes se apontarem exatamente na mesma direção (0°). x y A B https://medium.com/kx-systems/how-vector-databases-search-by-similarity-a-comprehensive-primer-c4b80d13ce63
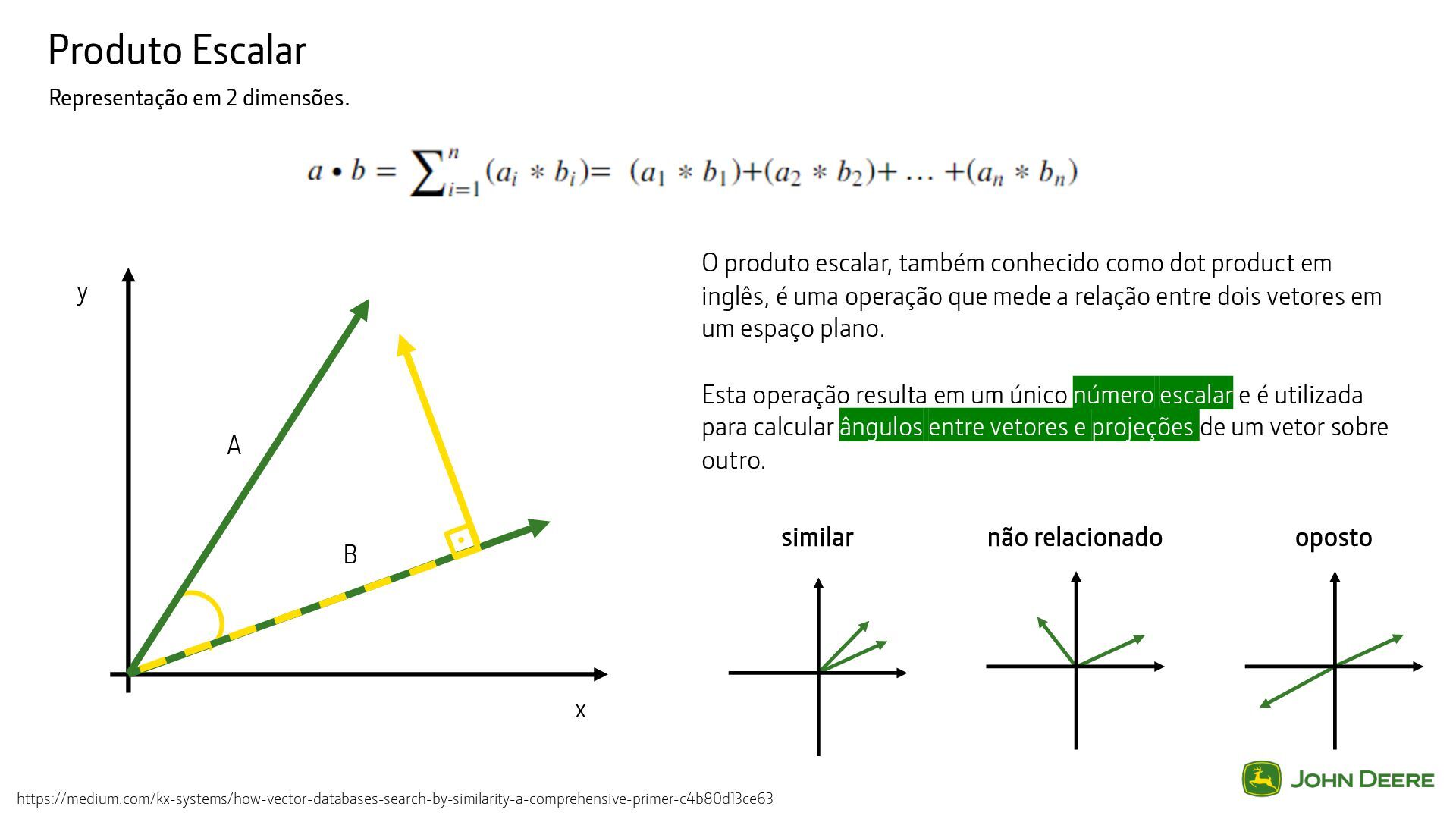
conhecido como dot product em inglês, é uma operação que mede a relação entre dois vetores em um espaço plano. Esta operação resulta em um único número escalar e é utilizada para calcular ângulos entre vetores e projeções de um vetor sobre outro. x y A B similar não relacionado oposto https://medium.com/kx-systems/how-vector-databases-search-by-similarity-a-comprehensive-primer-c4b80d13ce63
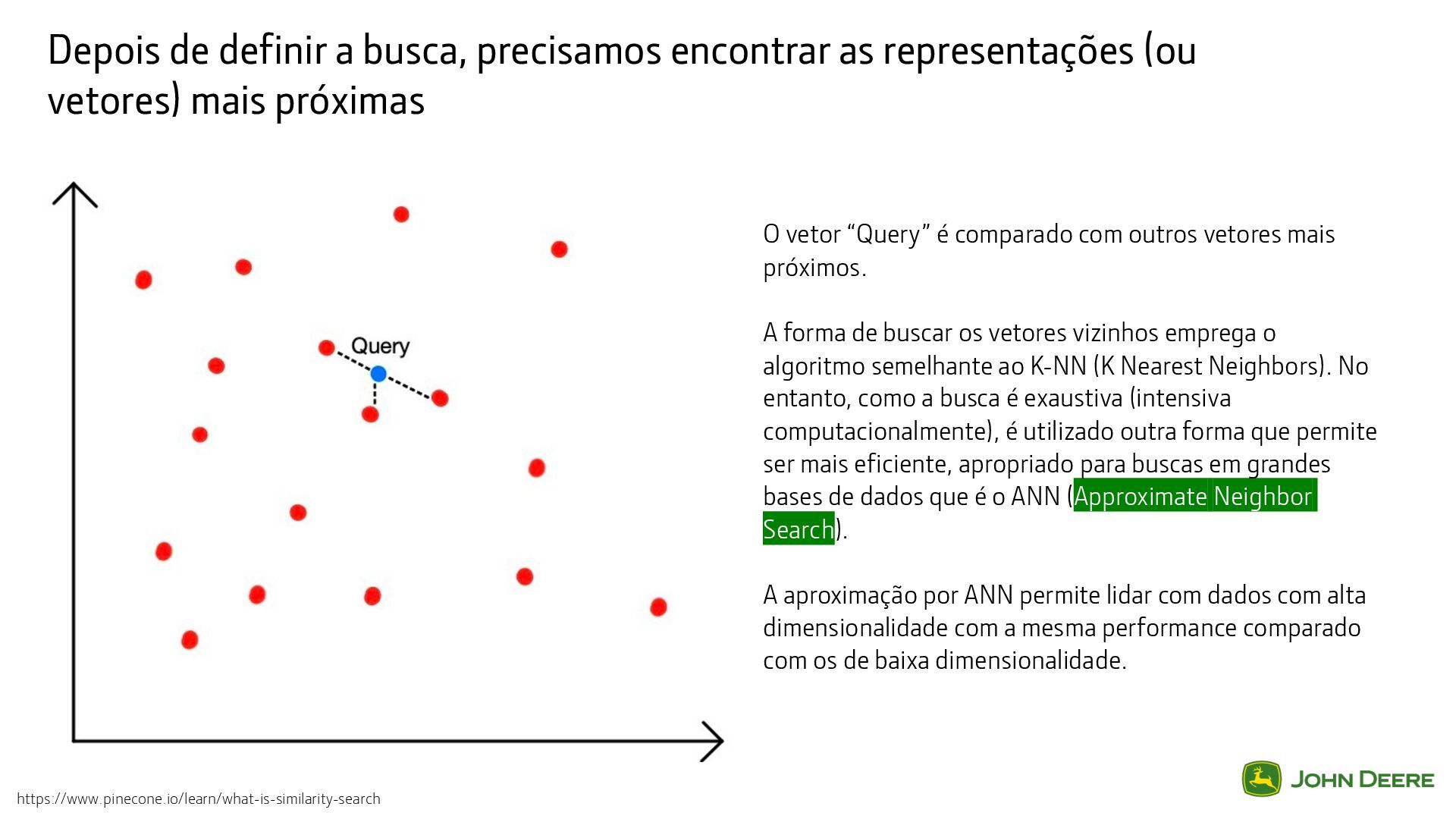
vetores) mais próximas O vetor “Query” é comparado com outros vetores mais próximos. A forma de buscar os vetores vizinhos emprega o algoritmo semelhante ao K-NN (K Nearest Neighbors). No entanto, como a busca é exaustiva (intensiva computacionalmente), é utilizado outra forma que permite ser mais eficiente, apropriado para buscas em grandes bases de dados que é o ANN (Approximate Neighbor Search). A aproximação por ANN permite lidar com dados com alta dimensionalidade com a mesma performance comparado com os de baixa dimensionalidade. https://www.pinecone.io/learn/what-is-similarity-search
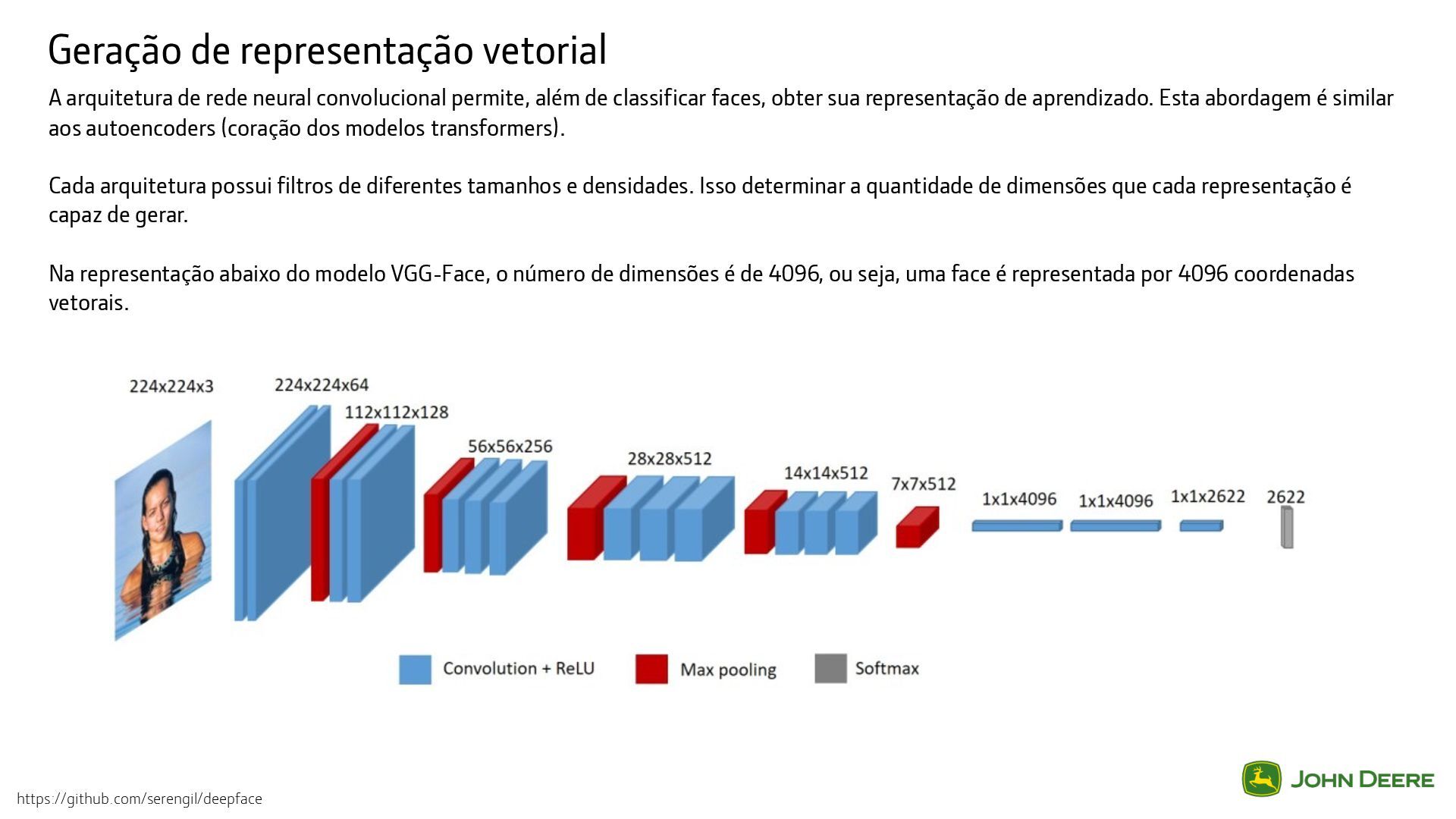
permite, além de classificar faces, obter sua representação de aprendizado. Esta abordagem é similar aos autoencoders (coração dos modelos transformers). Cada arquitetura possui filtros de diferentes tamanhos e densidades. Isso determinar a quantidade de dimensões que cada representação é capaz de gerar. Na representação abaixo do modelo VGG-Face, o número de dimensões é de 4096, ou seja, uma face é representada por 4096 coordenadas vetorais. https://github.com/serengil/deepface
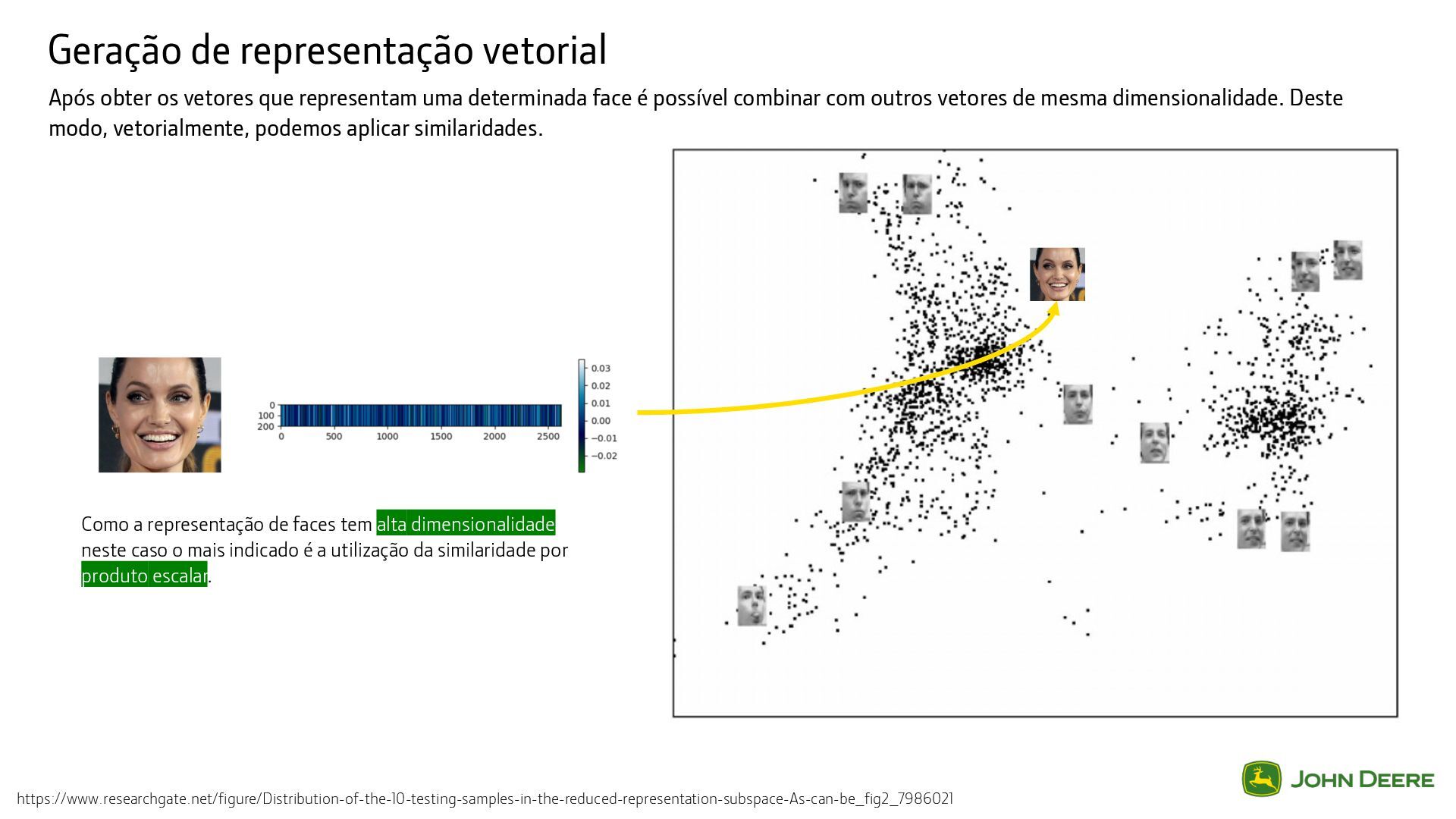
uma determinada face é possível combinar com outros vetores de mesma dimensionalidade. Deste modo, vetorialmente, podemos aplicar similaridades. https://www.researchgate.net/figure/Distribution-of-the-10-testing-samples-in-the-reduced-representation-subspace-As-can-be_fig2_7986021 Como a representação de faces tem alta dimensionalidade neste caso o mais indicado é a utilização da similaridade por produto escalar.
Bancos de dados relacionais, como o Postgres, são capazes de lidar com operações vetoriais por meio de uma extensão chamada pgvector. Esse serviço (Aurora) é disponibilizado em cloud pela AWS. Outras soluções, exclusivamente orientados a operações vetoriais como ChromaDB ou o Pinecone são opções mais especializadas. O ChromaDB é um banco de dados de código aberto e requer que o desenvolvedor instale em infraestrutura adequada ou execute locamente. Já o Pinecone é serviço em cloud e possui um tier free para desenvolvedores e estudantes já preparado e pronto para lidar com quantidades grandes de dados. Escolhemos esse para nossos experimentos!
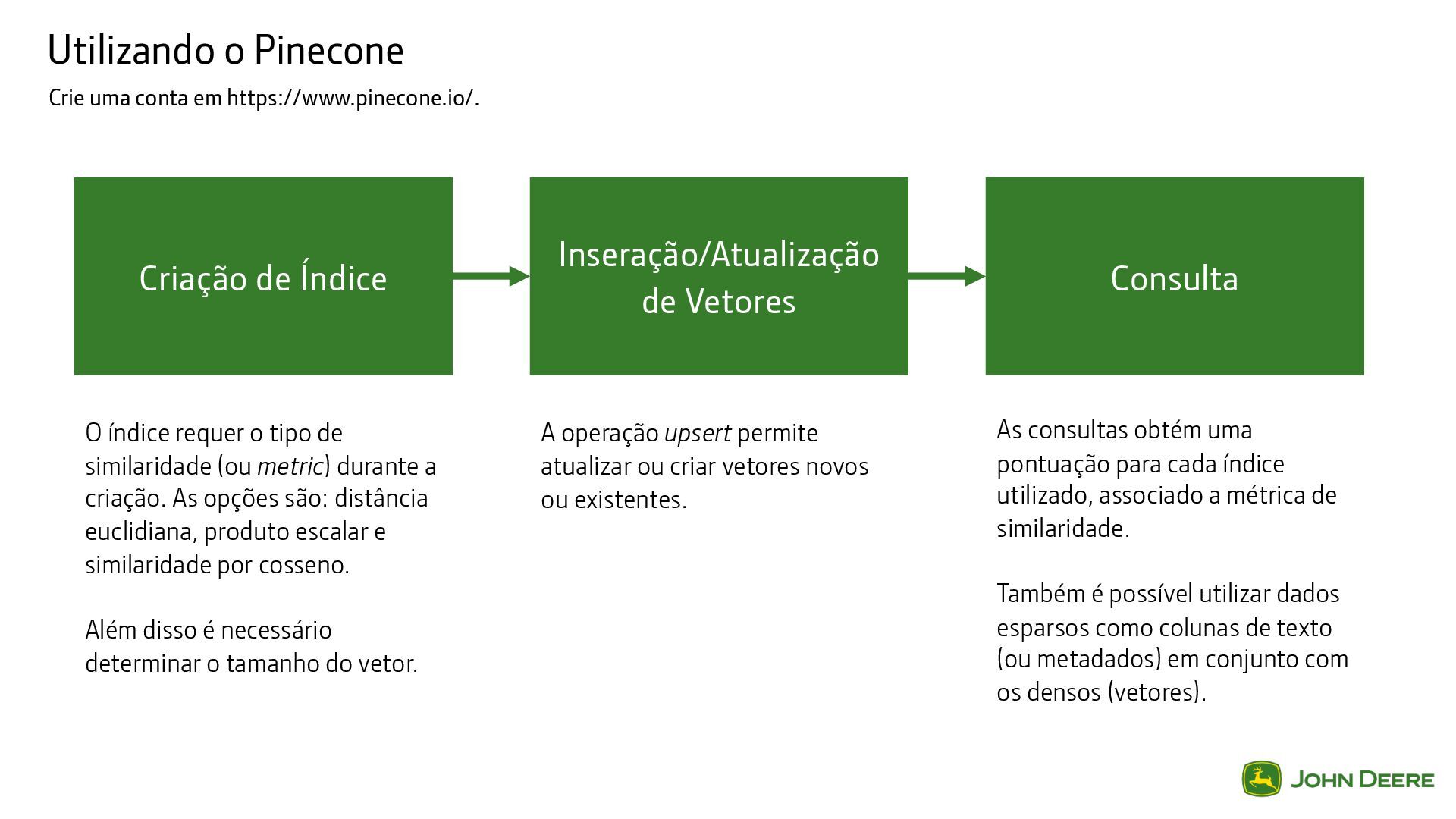
Índice Inseração/Atualização de Vetores Consulta O índice requer o tipo de similaridade (ou metric) durante a criação. As opções são: distância euclidiana, produto escalar e similaridade por cosseno. Além disso é necessário determinar o tamanho do vetor. A operação upsert permite atualizar ou criar vetores novos ou existentes. As consultas obtém uma pontuação para cada índice utilizado, associado a métrica de similaridade. Também é possível utilizar dados esparsos como colunas de texto (ou metadados) em conjunto com os densos (vetores).
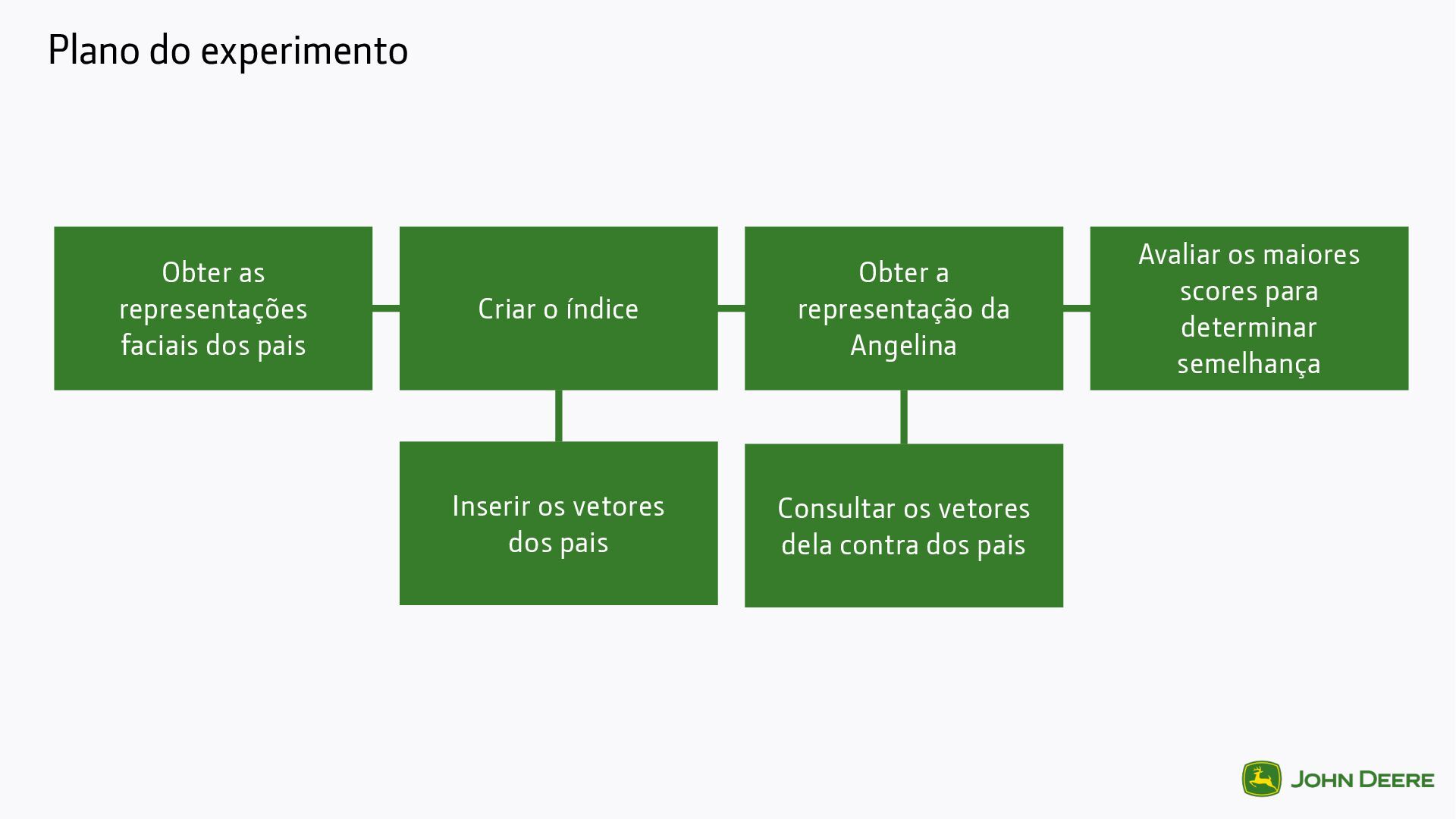
o índice Inserir os vetores dos pais Obter a representação da Angelina Consultar os vetores dela contra dos pais Avaliar os maiores scores para determinar semelhança
tema: https://www.deeplearning.ai/short-courses/building-applications-vector-databases/ Artigo sobre busca por similaridade, https://www.pinecone.io/learn/what-is-similarity-search/ Artigo sobre busca por similaridade de clustering, https://towardsdatascience.com/importance-of-distance-metrics-in- machine-learning-modelling-e51395ffe60d
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}